 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive-Scale Boundary Blackbox Attack via Projective Gradient Estimation
Jun 10, 2021
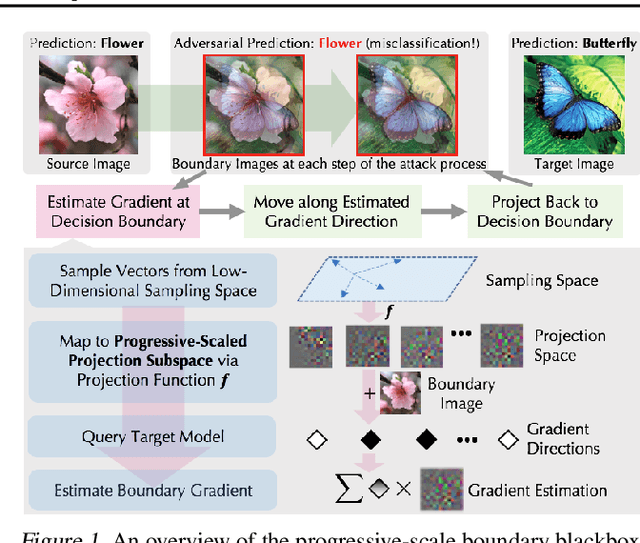
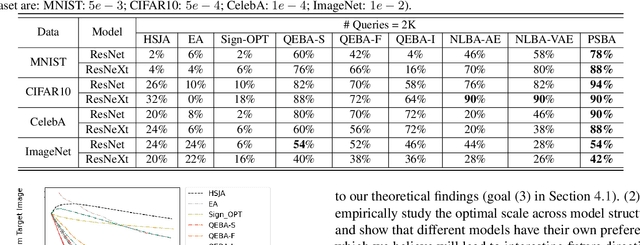
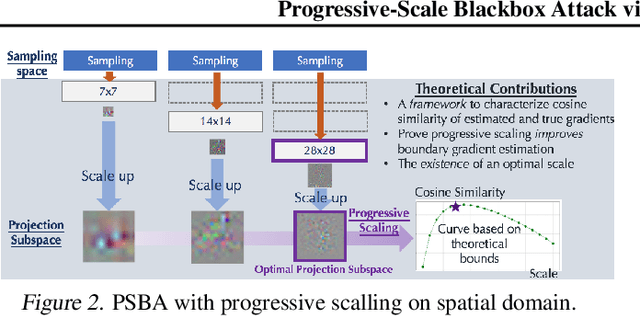

Boundary based blackbox attack has been recognized as practical and effective, given that an attacker only needs to access the final model prediction. However, the query efficiency of it is in general high especially for high dimensional image data. In this paper, we show that such efficiency highly depends on the scale at which the attack is applied, and attacking at the optimal scale significantly improves the efficiency. In particular, we propose a theoretical framework to analyze and show three key characteristics to improve the query efficiency. We prove that there exists an optimal scale for projective gradient estimation. Our framework also explains the satisfactory performance achieved by existing boundary black-box attacks. Based on our theoretical framework, we propose Progressive-Scale enabled projective Boundary Attack (PSBA) to improve the query efficiency via progressive scaling techniques. In particular, we employ Progressive-GAN to optimize the scale of projections, which we call PSBA-PGAN. We evaluate our approach on both spatial and frequency scales. Extensive experiments on MNIST, CIFAR-10, CelebA, and ImageNet against different models including a real-world face recognition API show that PSBA-PGAN significantly outperforms existing baseline attacks in terms of query efficiency and attack success rate. We also observe relatively stable optimal scales for different models and datasets. The code is publicly available at https://github.com/AI-secure/PSBA.
Pattern Detection in the Activation Space for Identifying Synthesized Content
May 26, 2021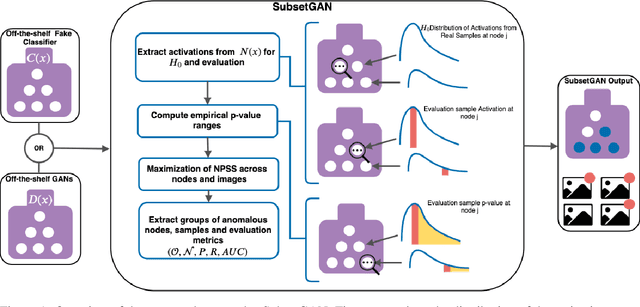
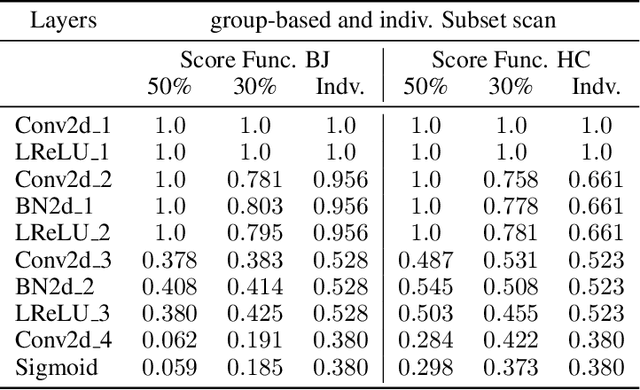
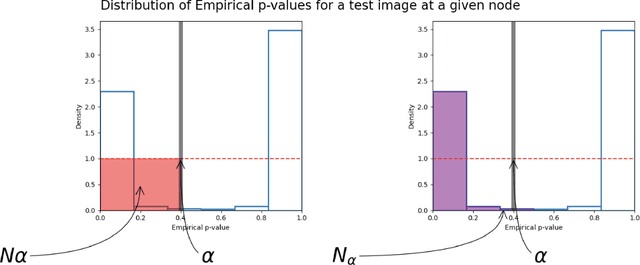

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.
Learning Ultrasound Rendering from Cross-Sectional Model Slices for Simulated Training
Jan 20, 2021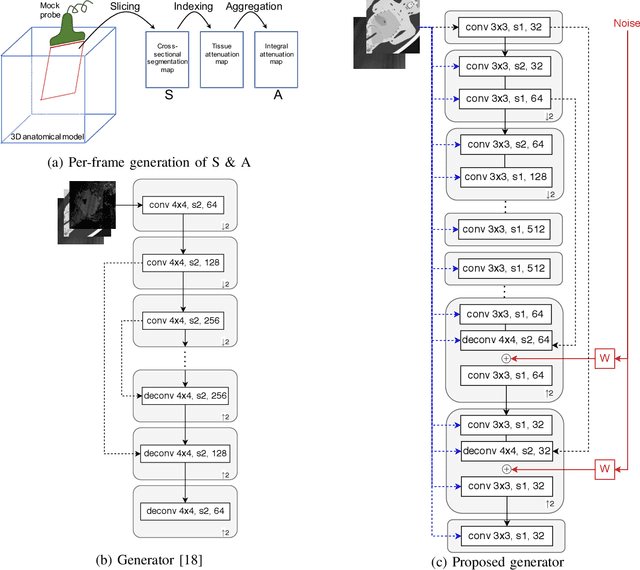

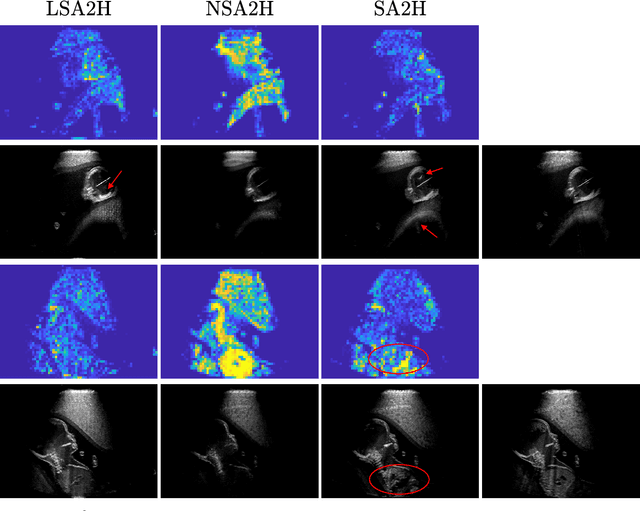
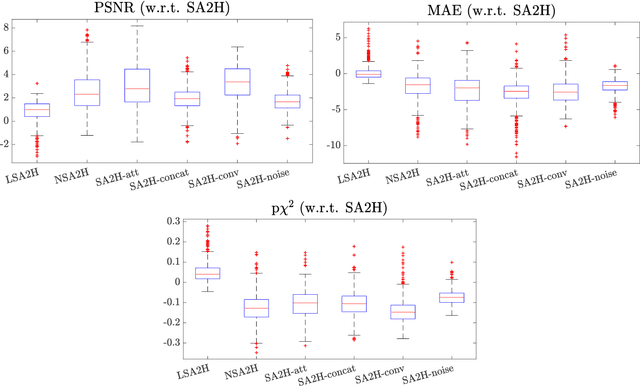
Purpose. Given the high level of expertise required for navigation and interpretation of ultrasound images, computational simulations can facilitate the training of such skills in virtual reality. With ray-tracing based simulations, realistic ultrasound images can be generated. However, due to computational constraints for interactivity, image quality typically needs to be compromised. Methods. We propose herein to bypass any rendering and simulation process at interactive time, by conducting such simulations during a non-time-critical offline stage and then learning image translation from cross-sectional model slices to such simulated frames. We use a generative adversarial framework with a dedicated generator architecture and input feeding scheme, which both substantially improve image quality without increase in network parameters. Integral attenuation maps derived from cross-sectional model slices, texture-friendly strided convolutions, providing stochastic noise and input maps to intermediate layers in order to preserve locality are all shown herein to greatly facilitate such translation task. Results. Given several quality metrics, the proposed method with only tissue maps as input is shown to provide comparable or superior results to a state-of-the-art that uses additional images of low-quality ultrasound renderings. An extensive ablation study shows the need and benefits from the individual contributions utilized in this work, based on qualitative examples and quantitative ultrasound similarity metrics. To that end, a local histogram statistics based error metric is proposed and demonstrated for visualization of local dissimilarities between ultrasound images.
Scale-Consistent Fusion: from Heterogeneous Local Sampling to Global Immersive Rendering
Jun 17, 2021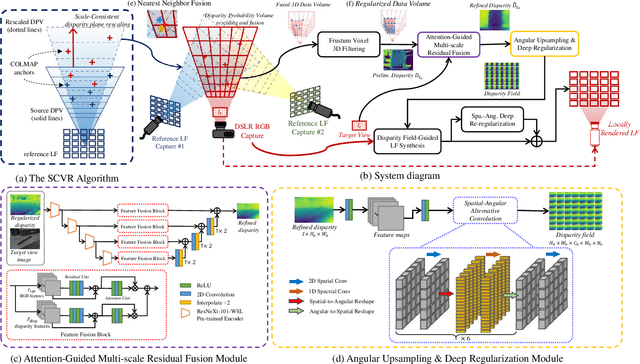



Image-based geometric modeling and novel view synthesis based on sparse, large-baseline samplings are challenging but important tasks for emerging multimedia applications such as virtual reality and immersive telepresence. Existing methods fail to produce satisfactory results due to the limitation on inferring reliable depth information over such challenging reference conditions. With the popularization of commercial light field (LF) cameras, capturing LF images (LFIs) is as convenient as taking regular photos, and geometry information can be reliably inferred. This inspires us to use a sparse set of LF captures to render high-quality novel views globally. However, fusion of LF captures from multiple angles is challenging due to the scale inconsistency caused by various capture settings. To overcome this challenge, we propose a novel scale-consistent volume rescaling algorithm that robustly aligns the disparity probability volumes (DPV) among different captures for scale-consistent global geometry fusion. Based on the fused DPV projected to the target camera frustum, novel learning-based modules have been proposed (i.e., the attention-guided multi-scale residual fusion module, and the disparity field guided deep re-regularization module) which comprehensively regularize noisy observations from heterogeneous captures for high-quality rendering of novel LFIs. Both quantitative and qualitative experiments over the Stanford Lytro Multi-view LF dataset show that the proposed method outperforms state-of-the-art methods significantly under different experiment settings for disparity inference and LF synthesis.
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 26, 2021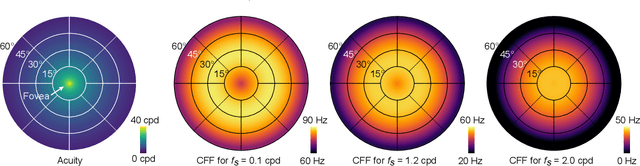
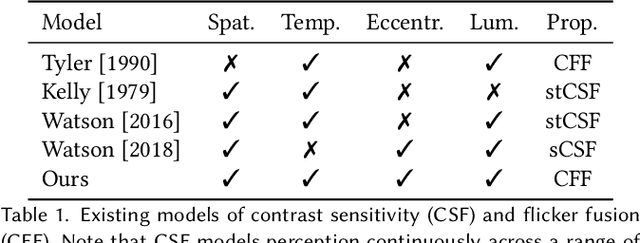

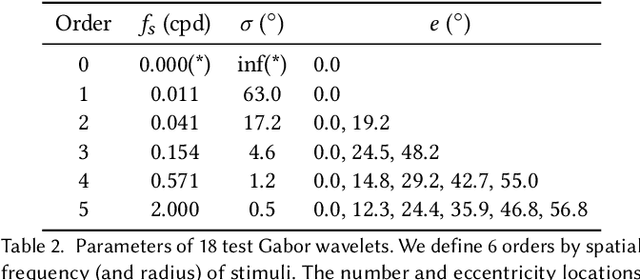
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 01, 2021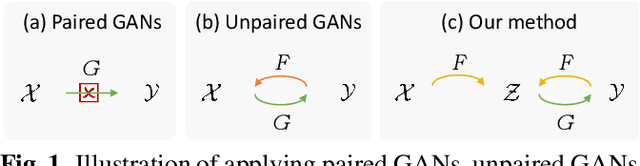
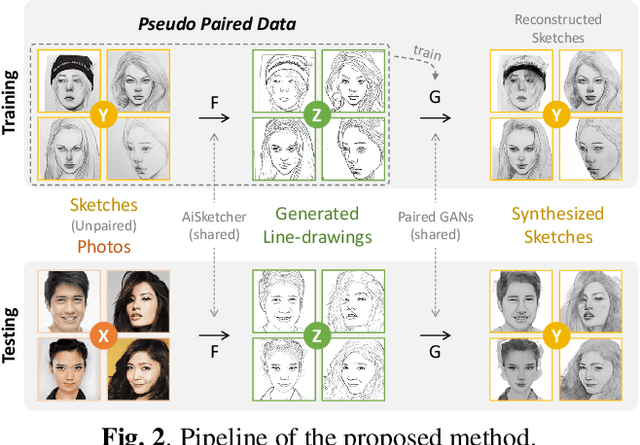
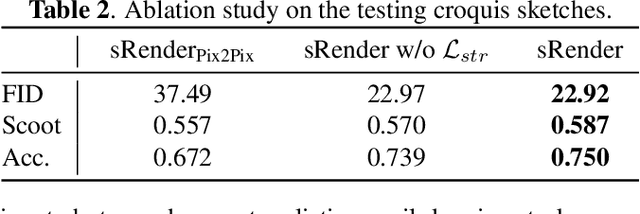
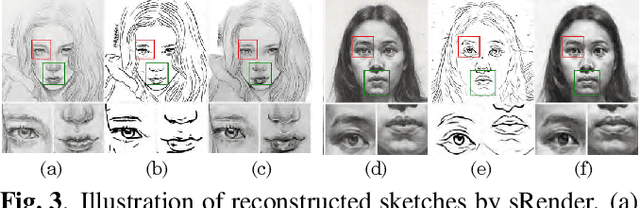
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
Semi-Supervised Deep Metrics for Image Registration
Apr 04, 2018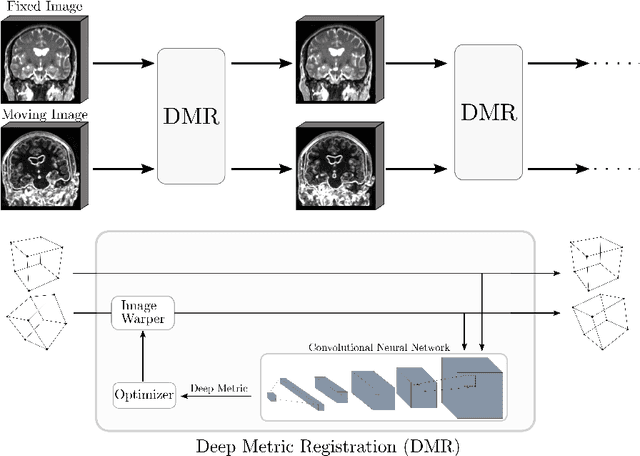
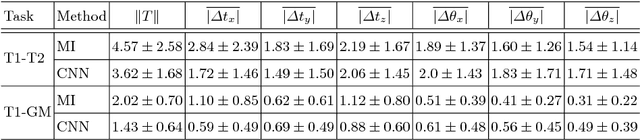
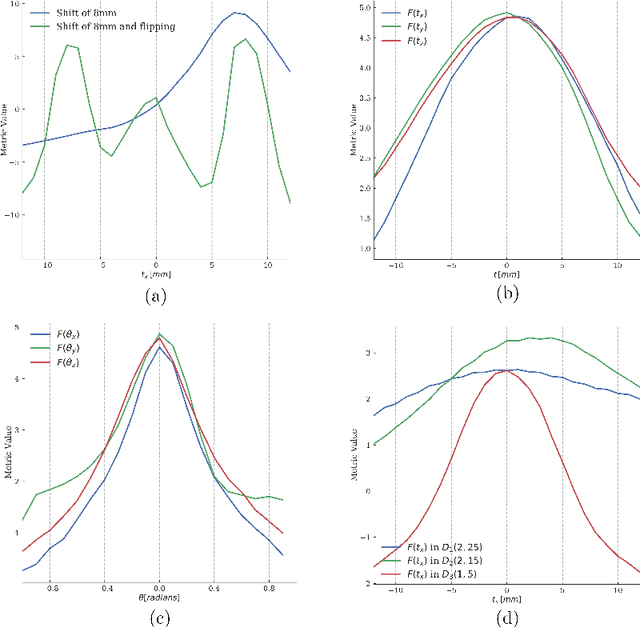
Deep metrics have been shown effective as similarity measures in multi-modal image registration; however, the metrics are currently constructed from aligned image pairs in the training data. In this paper, we propose a strategy for learning such metrics from roughly aligned training data. Symmetrizing the data corrects bias in the metric that results from misalignment in the data (at the expense of increased variance), while random perturbations to the data, i.e. dithering, ensures that the metric has a single mode, and is amenable to registration by optimization. Evaluation is performed on the task of registration on separate unseen test image pairs. The results demonstrate the feasibility of learning a useful deep metric from substantially misaligned training data, in some cases the results are significantly better than from Mutual Information. Data augmentation via dithering is, therefore, an effective strategy for discharging the need for well-aligned training data; this brings deep metric registration from the realm of supervised to semi-supervised machine learning.
Cross-Level Cross-Scale Cross-Attention Network for Point Cloud Representation
Apr 27, 2021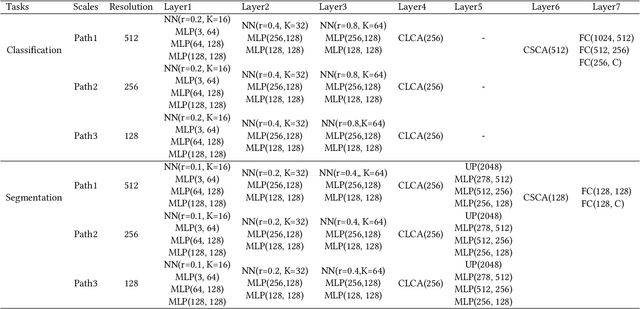
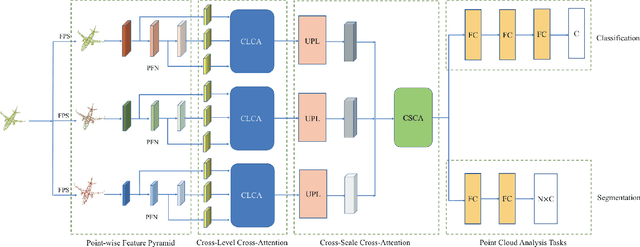
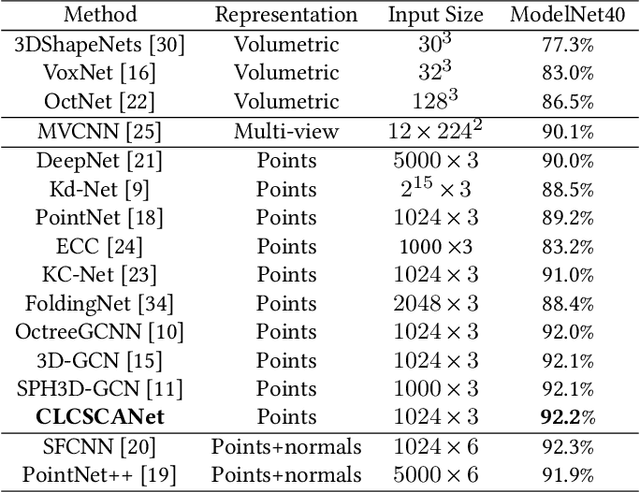
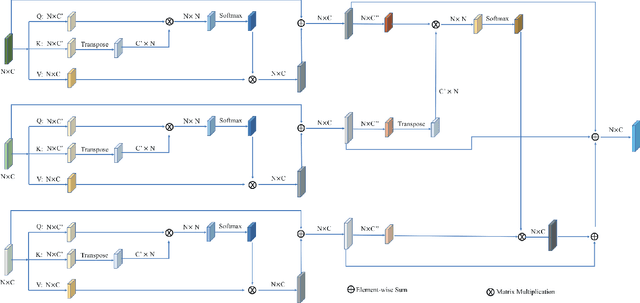
Self-attention mechanism recently achieves impressive advancement in Natural Language Processing (NLP) and Image Processing domains. And its permutation invariance property makes it ideally suitable for point cloud processing. Inspired by this remarkable success, we propose an end-to-end architecture, dubbed Cross-Level Cross-Scale Cross-Attention Network (CLCSCANet), for point cloud representation learning. First, a point-wise feature pyramid module is introduced to hierarchically extract features from different scales or resolutions. Then a cross-level cross-attention is designed to model long-range inter-level and intra-level dependencies. Finally, we develop a cross-scale cross-attention module to capture interactions between-and-within scales for representation enhancement. Compared with state-of-the-art approaches, our network can obtain competitive performance on challenging 3D object classification, point cloud segmentation tasks via comprehensive experimental evaluation.
Dual Transformer for Point Cloud Analysis
Apr 27, 2021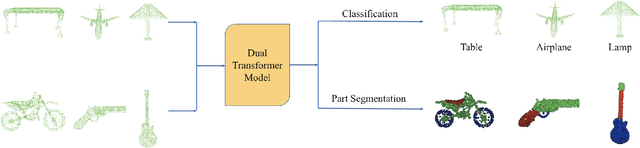
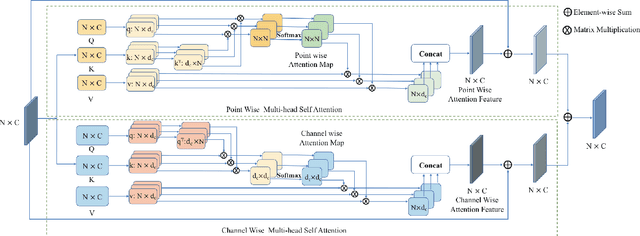
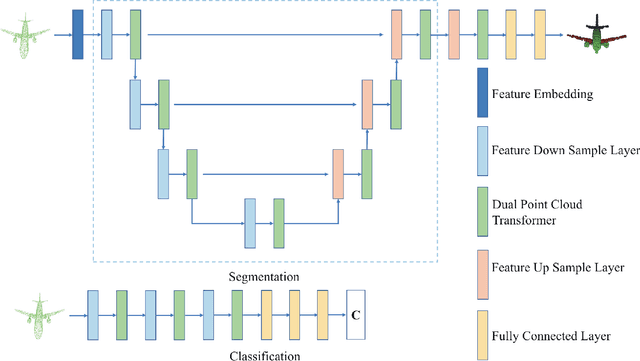

Following the tremendous success of transformer in natural language processing and image understanding tasks, in this paper, we present a novel point cloud representation learning architecture, named Dual Transformer Network (DTNet), which mainly consists of Dual Point Cloud Transformer (DPCT) module. Specifically, by aggregating the well-designed point-wise and channel-wise multi-head self-attention models simultaneously, DPCT module can capture much richer contextual dependencies semantically from the perspective of position and channel. With the DPCT module as a fundamental component, we construct the DTNet for performing point cloud analysis in an end-to-end manner. Extensive quantitative and qualitative experiments on publicly available benchmarks demonstrate the effectiveness of our proposed transformer framework for the tasks of 3D point cloud classification and segmentation, achieving highly competitive performance in comparison with the state-of-the-art approaches.
Analyzing Non-Textual Content Elements to Detect Academic Plagiarism
Jun 10, 2021Identifying academic plagiarism is a pressing problem, among others, for research institutions, publishers, and funding organizations. Detection approaches proposed so far analyze lexical, syntactical, and semantic text similarity. These approaches find copied, moderately reworded, and literally translated text. However, reliably detecting disguised plagiarism, such as strong paraphrases, sense-for-sense translations, and the reuse of non-textual content and ideas, is an open research problem. The thesis addresses this problem by proposing plagiarism detection approaches that implement a different concept: analyzing non-textual content in academic documents, specifically citations, images, and mathematical content. To validate the effectiveness of the proposed detection approaches, the thesis presents five evaluations that use real cases of academic plagiarism and exploratory searches for unknown cases. The evaluation results show that non-textual content elements contain a high degree of semantic information, are language-independent, and largely immutable to the alterations that authors typically perform to conceal plagiarism. Analyzing non-textual content complements text-based detection approaches and increases the detection effectiveness, particularly for disguised forms of academic plagiarism. To demonstrate the benefit of combining non-textual and text-based detection methods, the thesis describes the first plagiarism detection system that integrates the analysis of citation-based, image-based, math-based, and text-based document similarity. The system's user interface employs visualizations that significantly reduce the effort and time users must invest in examining content similarity.