 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disease Forecast via Progression Learning
Dec 21, 2020
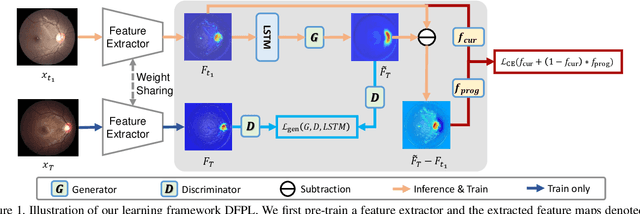
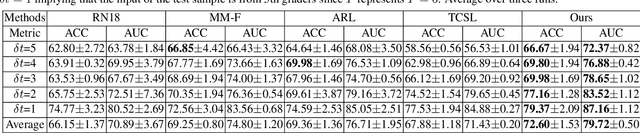

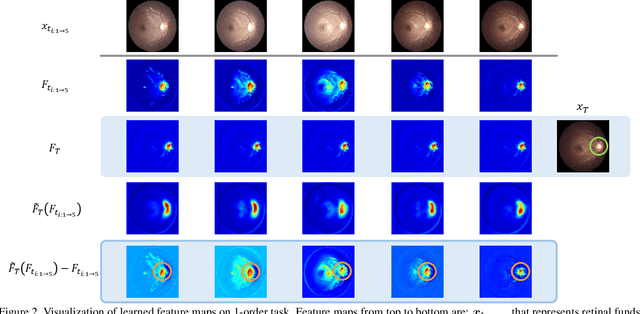
Forecasting Parapapillary atrophy (PPA), i.e., a symptom related to most irreversible eye diseases, provides an alarm for implementing an intervention to slow down the disease progression at early stage. A key question for this forecast is: how to fully utilize the historical data (e.g., retinal image) up to the current stage for future disease prediction? In this paper, we provide an answer with a novel framework, namely \textbf{D}isease \textbf{F}orecast via \textbf{P}rogression \textbf{L}earning (\textbf{DFPL}), which exploits the irreversibility prior (i.e., cannot be reversed once diagnosed). Specifically, based on this prior, we decompose two factors that contribute to the prediction of the future disease: i) the current disease label given the data (retinal image, clinical attributes) at present and ii) the future disease label given the progression of the retinal images that from the current to the future. To model these two factors, we introduce the current and progression predictors in DFPL, respectively. In order to account for the degree of progression of the disease, we propose a temporal generative model to accurately generate the future image and compare it with the current one to get a residual image. The generative model is implemented by a recurrent neural network, in order to exploit the dependency of the historical data. To verify our approach, we apply it to a PPA in-house dataset and it yields a significant improvement (\textit{e.g.}, \textbf{4.48\%} of accuracy; \textbf{3.45\%} of AUC) over others. Besides, our generative model can accurately localize the disease-related regions.
Improved Image Selection for Stack-Based HDR Imaging
Jun 19, 2018
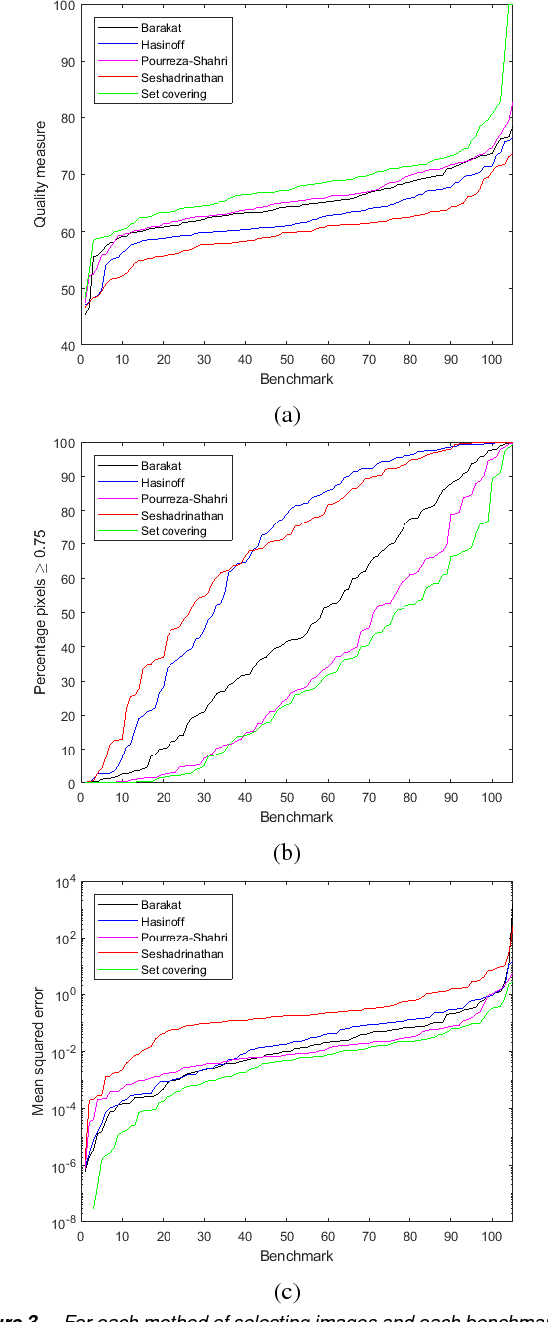
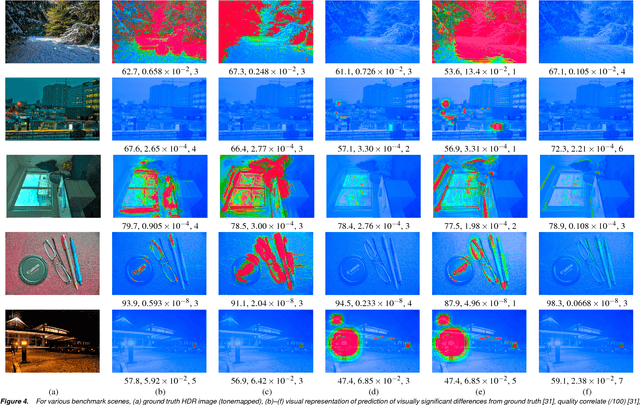
Stack-based high dynamic range (HDR) imaging is a technique for achieving a larger dynamic range in an image by combining several low dynamic range images acquired at different exposures. Minimizing the set of images to combine, while ensuring that the resulting HDR image fully captures the scene's irradiance, is important to avoid long image acquisition and post-processing times. The problem of selecting the set of images has received much attention. However, existing methods either are not fully automatic, can be slow, or can fail to fully capture more challenging scenes. In this paper, we propose a fully automatic method for selecting the set of exposures to acquire that is both fast and more accurate. We show on an extensive set of benchmark scenes that our proposed method leads to improved HDR images as measured against ground truth using the mean squared error, a pixel-based metric, and a visible difference predictor and a quality score, both perception-based metrics.
Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks
Jul 11, 2019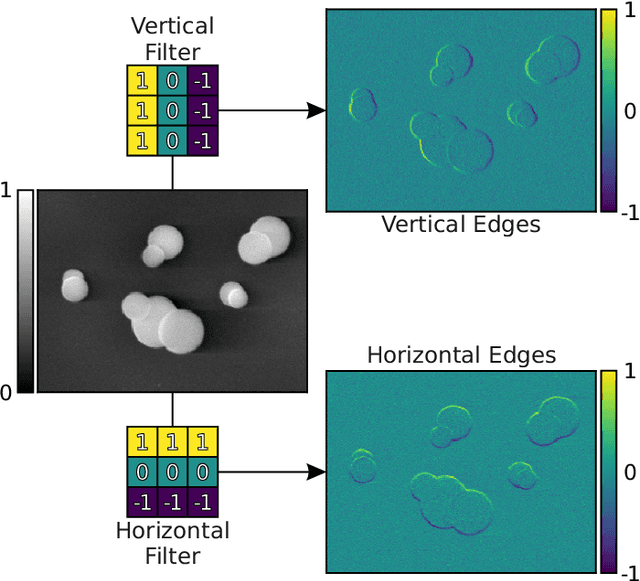
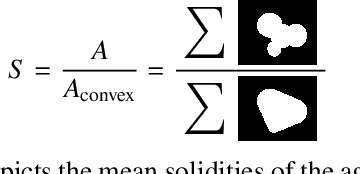
There is a high demand for fully automated methods for the analysis of particle size distributions of agglomerated, sintered or occluded primary particles. Therefore, a novel, deep learning-based, method for the pixel-perfect detection and sizing of agglomerated, aggregated or occluded primary particles was proposed and tested. As a specialty, the training of the utilized convolutional neural networks was carried out using only synthetic images, to avoid the laborious task of manual annotation and to increase the quality of the ground truth. Despite the training on synthetic images, the proposed method performs excellent on real world samples of sintered silica nanoparticles with various sintering degrees and varying image conditions. In a direct comparison, the proposed method clearly outperforms two state-of-the-art methods for automated image-based particle size analysis (Hough transformation and the ImageJ ParticleSizer plug-in), with respect to precision and speed, thereby advancing into regions of human-like performance and reliability.
An Iterative Boundary Random Walks Algorithm for Interactive Image Segmentation
Aug 09, 2018
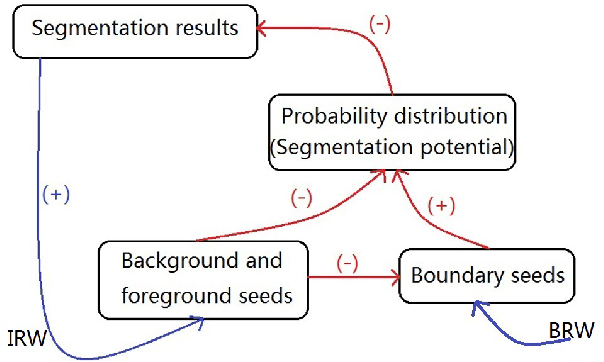
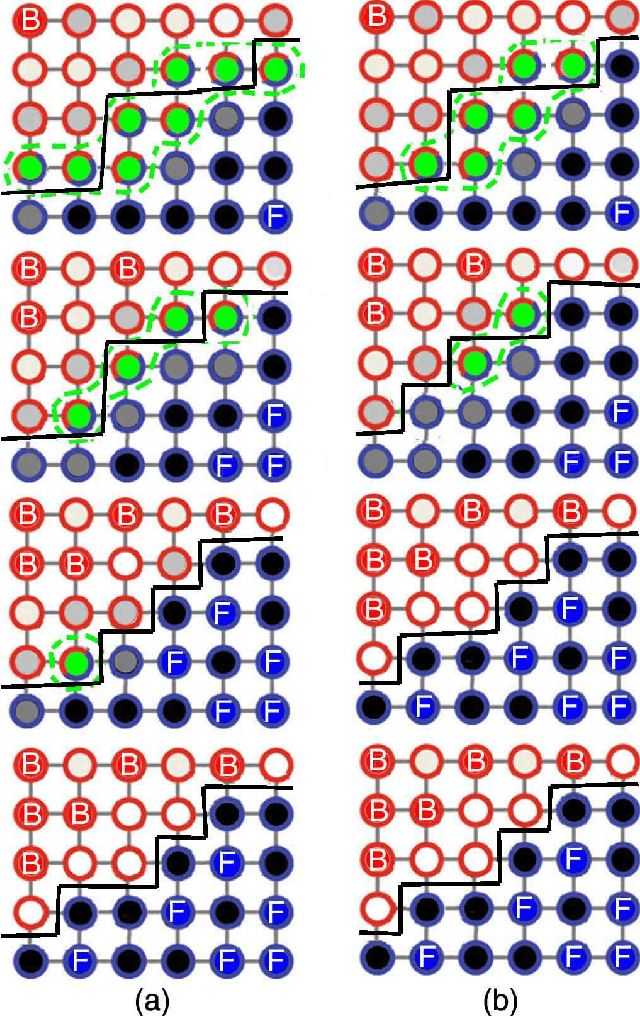
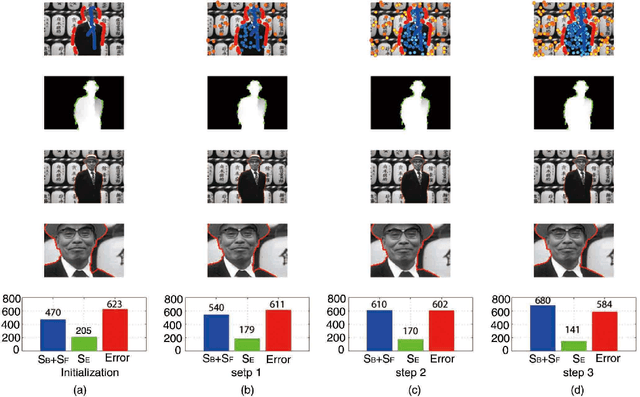
The interactive image segmentation algorithm can provide an intelligent ways to understand the intention of user input. Many interactive methods have the problem of that ask for large number of user input. To efficient produce intuitive segmentation under limited user input is important for industrial application. In this paper, we reveal a positive feedback system on image segmentation to show the pixels of self-learning. Two approaches, iterative random walks and boundary random walks, are proposed for segmentation potential, which is the key step in feedback system. Experiment results on image segmentation indicates that proposed algorithms can obtain more efficient input to random walks. And higher segmentation performance can be obtained by applying the iterative boundary random walks algorithm.
Class Regularization: Improve Few-shot Image Classification by Reducing Meta Shift
Dec 18, 2019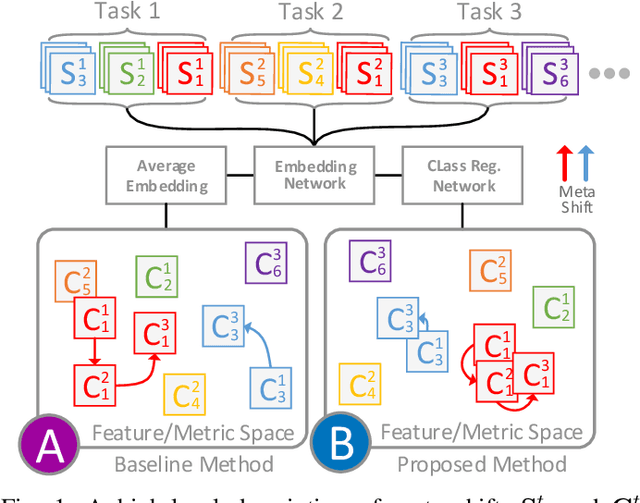
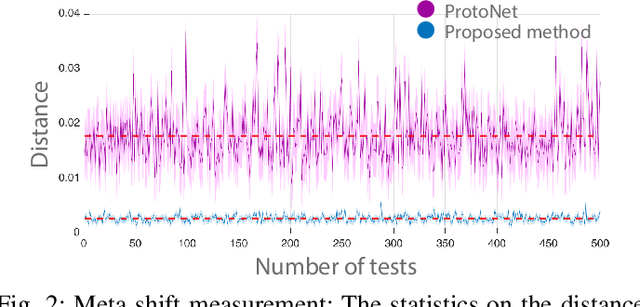
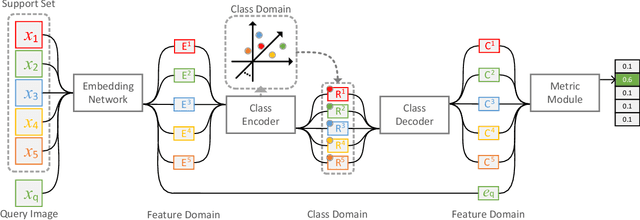
Few-shot image classification requires the classifier to robustly cope with unseen classes even if there are only a few samples for each class. Recent advances benefit from the meta-learning process where episodic tasks are formed to train a model that can adapt to class change. However, these tasks are independent to each other and existing works mainly rely on limited samples of individual support set in a single meta task. This strategy leads to severe meta shift issues across multiple tasks, meaning the learned prototypes or class descriptors are not stable as each task only involves their own support set. To avoid this problem, we propose a concise Class Regularization Network which aggregates the embedding features of all samples in the entire training set and further regularizes the generated class descriptor. The key is to train a class encoder and decoder structure that can encode the embedding sample features into a class domain with trained class basis, and generate a more stable and general class descriptor from the decoder. We evaluate our work by extensive comparisons with previous methods on two benchmark datasets (MiniImageNet and CUB). The results show that our method achieves state-of-the-art performance over previous work.
Real-world Noisy Image Denoising: A New Benchmark
Apr 07, 2018



Most of previous image denoising methods focus on additive white Gaussian noise (AWGN). However,the real-world noisy image denoising problem with the advancing of the computer vision techiniques. In order to promote the study on this problem while implementing the concurrent real-world image denoising datasets, we construct a new benchmark dataset which contains comprehensive real-world noisy images of different natural scenes. These images are captured by different cameras under different camera settings. We evaluate the different denoising methods on our new dataset as well as previous datasets. Extensive experimental results demonstrate that the recently proposed methods designed specifically for realistic noise removal based on sparse or low rank theories achieve better denoising performance and are more robust than other competing methods, and the newly proposed dataset is more challenging. The constructed dataset of real photographs is publicly available at \url{https://github.com/csjunxu/PolyUDataset} for researchers to investigate new real-world image denoising methods. We will add more analysis on the noise statistics in the real photographs of our new dataset in the next version of this article.
Generative Adversarial Transformers
Mar 02, 2021
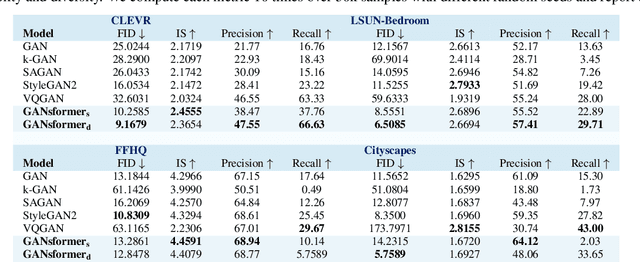
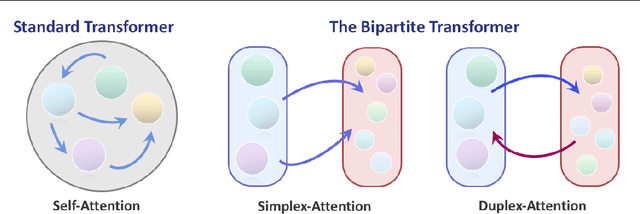
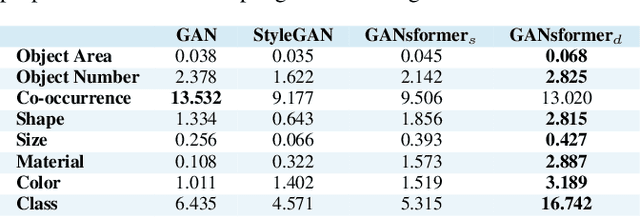
We introduce the GANsformer, a novel and efficient type of transformer, and explore it for the task of visual generative modeling. The network employs a bipartite structure that enables long-range interactions across the image, while maintaining computation of linearly efficiency, that can readily scale to high-resolution synthesis. It iteratively propagates information from a set of latent variables to the evolving visual features and vice versa, to support the refinement of each in light of the other and encourage the emergence of compositional representations of objects and scenes. In contrast to the classic transformer architecture, it utilizes multiplicative integration that allows flexible region-based modulation, and can thus be seen as a generalization of the successful StyleGAN network. We demonstrate the model's strength and robustness through a careful evaluation over a range of datasets, from simulated multi-object environments to rich real-world indoor and outdoor scenes, showing it achieves state-of-the-art results in terms of image quality and diversity, while enjoying fast learning and better data-efficiency. Further qualitative and quantitative experiments offer us an insight into the model's inner workings, revealing improved interpretability and stronger disentanglement, and illustrating the benefits and efficacy of our approach. An implementation of the model is available at https://github.com/dorarad/gansformer.
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
Jun 03, 2021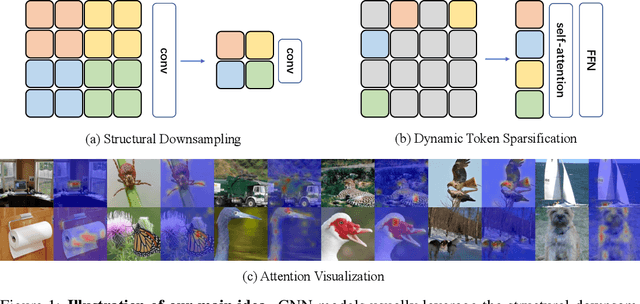
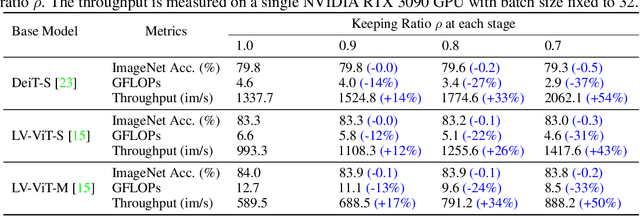
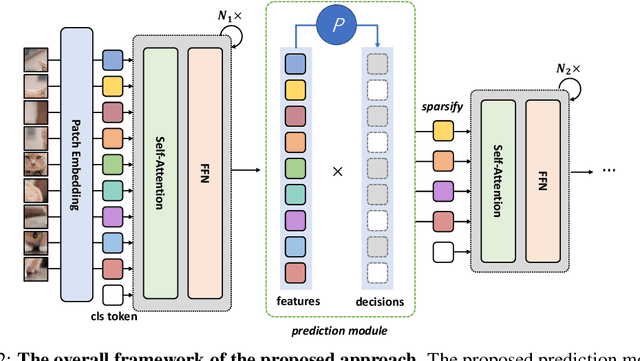
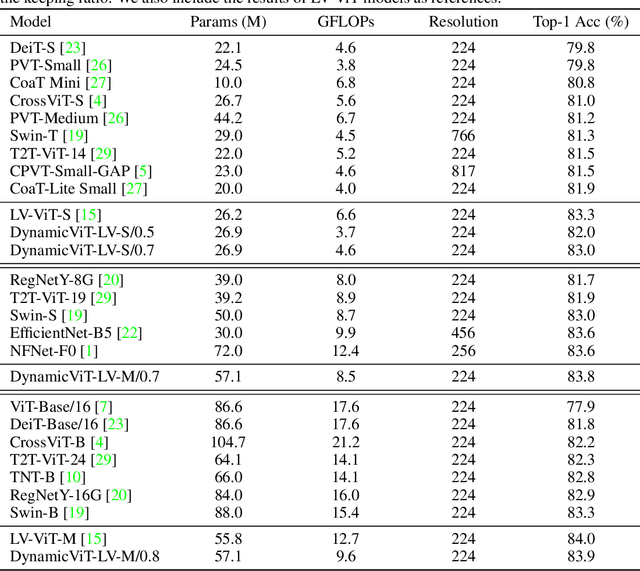
Attention is sparse in vision transformers. We observe the final prediction in vision transformers is only based on a subset of most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. To optimize the prediction module in an end-to-end manner, we propose an attention masking strategy to differentiably prune a token by blocking its interactions with other tokens. Benefiting from the nature of self-attention, the unstructured sparse tokens are still hardware friendly, which makes our framework easy to achieve actual speed-up. By hierarchically pruning 66% of the input tokens, our method greatly reduces 31%~37% FLOPs and improves the throughput by over 40% while the drop of accuracy is within 0.5% for various vision transformers. Equipped with the dynamic token sparsification framework, DynamicViT models can achieve very competitive complexity/accuracy trade-offs compared to state-of-the-art CNNs and vision transformers on ImageNet. Code is available at https://github.com/raoyongming/DynamicViT
A Hitchhiker's Guide to Structural Similarity
Jan 16, 2021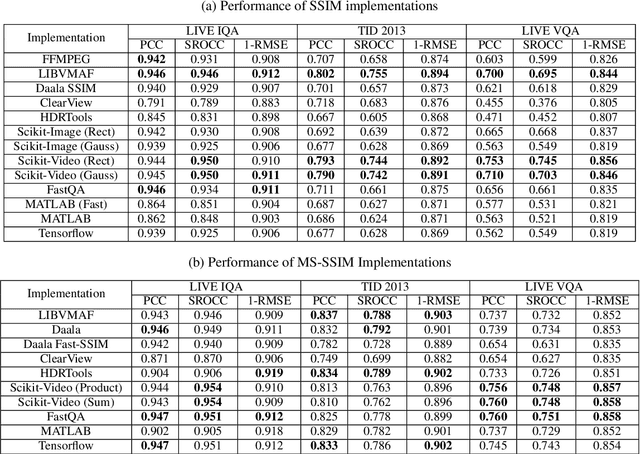
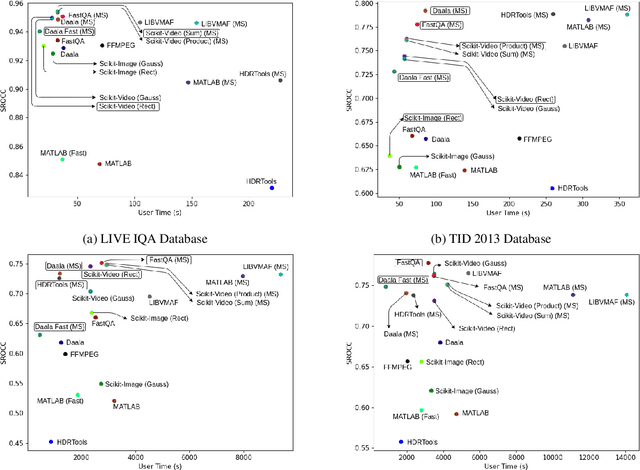
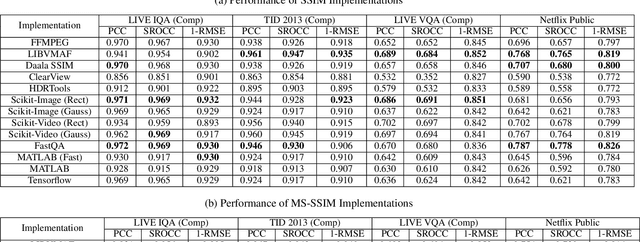
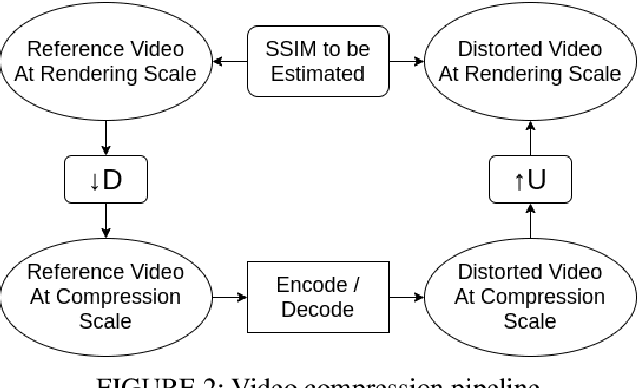
The Structural Similarity (SSIM) Index is a very widely used image/video quality model that continues to play an important role in the perceptual evaluation of compression algorithms, encoding recipes and numerous other image/video processing algorithms. Several public implementations of the SSIM and Multiscale-SSIM (MS-SSIM) algorithms have been developed, which differ in efficiency and performance. This "bendable ruler" makes the process of quality assessment of encoding algorithms unreliable. To address this situation, we studied and compared the functions and performances of popular and widely used implementations of SSIM, and we also considered a variety of design choices. Based on our studies and experiments, we have arrived at a collection of recommendations on how to use SSIM most effectively, including ways to reduce its computational burden.
Low Resolution Information Also Matters: Learning Multi-Resolution Representations for Person Re-Identification
May 26, 2021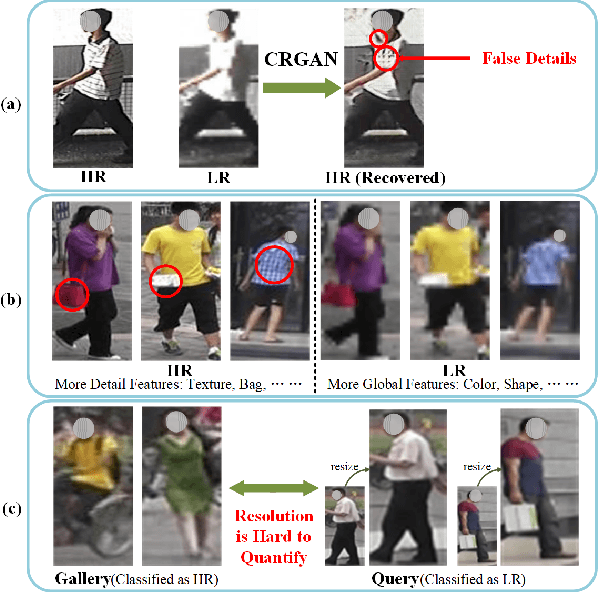
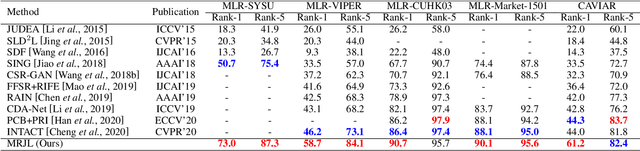
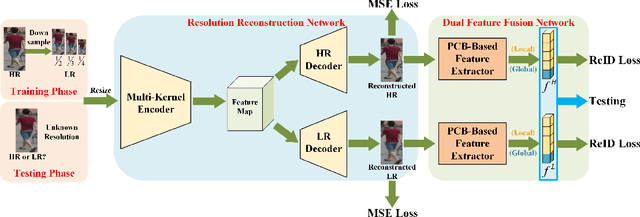
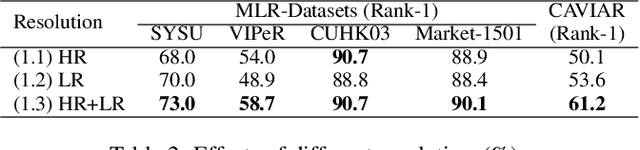
As a prevailing task in video surveillance and forensics field, person re-identification (re-ID) aims to match person images captured from non-overlapped cameras. In unconstrained scenarios, person images often suffer from the resolution mismatch problem, i.e., \emph{Cross-Resolution Person Re-ID}. To overcome this problem, most existing methods restore low resolution (LR) images to high resolution (HR) by super-resolution (SR). However, they only focus on the HR feature extraction and ignore the valid information from original LR images. In this work, we explore the influence of resolutions on feature extraction and develop a novel method for cross-resolution person re-ID called \emph{\textbf{M}ulti-Resolution \textbf{R}epresentations \textbf{J}oint \textbf{L}earning} (\textbf{MRJL}). Our method consists of a Resolution Reconstruction Network (RRN) and a Dual Feature Fusion Network (DFFN). The RRN uses an input image to construct a HR version and a LR version with an encoder and two decoders, while the DFFN adopts a dual-branch structure to generate person representations from multi-resolution images. Comprehensive experiments on five benchmarks verify the superiority of the proposed MRJL over the relevent state-of-the-art methods.