 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatio-temporal Data Augmentation for Visual Surveillance
Jan 25, 2021


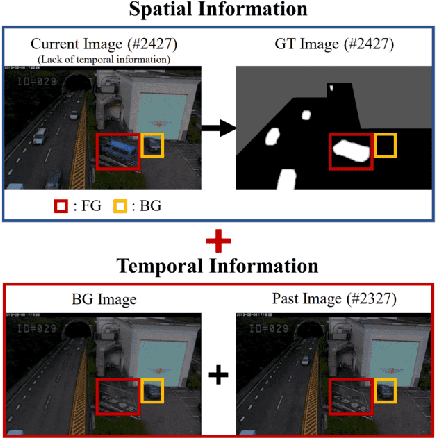
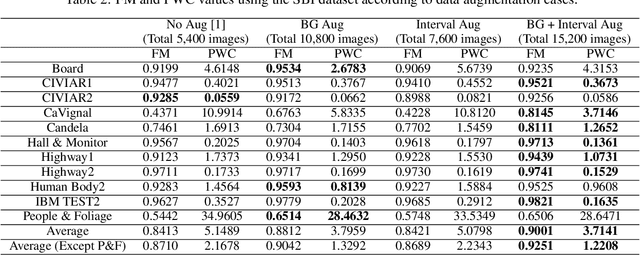
Visual surveillance aims to stably detect a foreground object using a continuous image acquired from a fixed camera. Recent deep learning methods based on supervised learning show superior performance compared to classical background subtraction algorithms. However, there is still a room for improvement in static foreground, dynamic background, hard shadow, illumination changes, camouflage, etc. In addition, most of the deep learning-based methods operates well on environments similar to training. If the testing environments are different from training ones, their performance degrades. As a result, additional training on those operating environments is required to ensure a good performance. Our previous work which uses spatio-temporal input data consisted of a number of past images, background images and current image showed promising results in different environments from training, although it uses a simple U-NET structure. In this paper, we propose a data augmentation technique suitable for visual surveillance for additional performance improvement using the same network used in our previous work. In deep learning, most data augmentation techniques deal with spatial-level data augmentation techniques for use in image classification and object detection. In this paper, we propose a new method of data augmentation in the spatio-temporal dimension suitable for our previous work. Two data augmentation methods of adjusting background model images and past images are proposed. Through this, it is shown that performance can be improved in difficult areas such as static foreground and ghost objects, compared to previous studies. Through quantitative and qualitative evaluation using SBI, LASIESTA, and our own dataset, we show that it gives superior performance compared to deep learning-based algorithms and background subtraction algorithms.
AS-Net: Fast Photoacoustic Reconstruction with Multi-feature Fusion from Sparse Data
Jan 22, 2021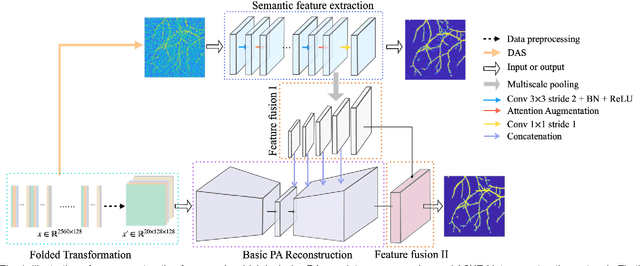
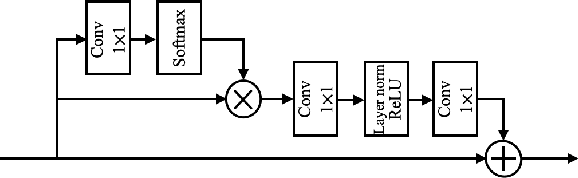

Photoacoustic (PA) imaging is a biomedical imaging modality capable of acquiring high contrast images of optical absorption at depths much greater than traditional optical imaging techniques. However, practical instrumentation and geometry limit the number of available acoustic sensors surrounding the imaging target, which results in sparsity of sensor data. Conventional PA image reconstruction methods give severe artifacts when they are applied directly to these sparse data. In this paper, we first employ a novel signal processing method to make sparse PA raw data more suitable for the neural network, and concurrently speeding up image reconstruction. Then we propose Attention Steered Network (AS-Net) for PA reconstruction with multi-feature fusion. AS-Net is validated on different datasets, including simulated photoacoustic data from fundus vasculature phantoms and real data from in vivo fish and mice imaging experiments. Notably, the method is also able to eliminate some artifacts present in the ground-truth for in vivo data. Results demonstrated that our method provides superior reconstructions at a faster speed.
T2Net: Synthetic-to-Realistic Translation for Solving Single-Image Depth Estimation Tasks
Aug 04, 2018
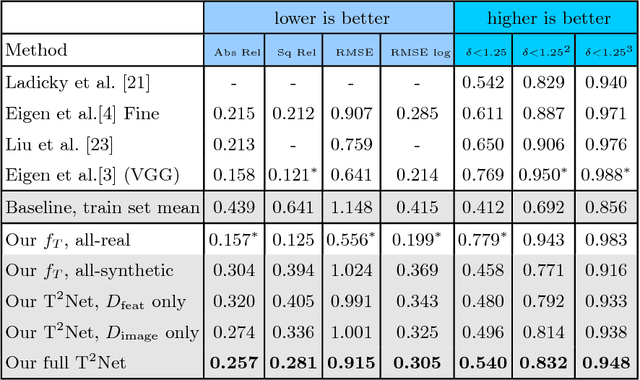
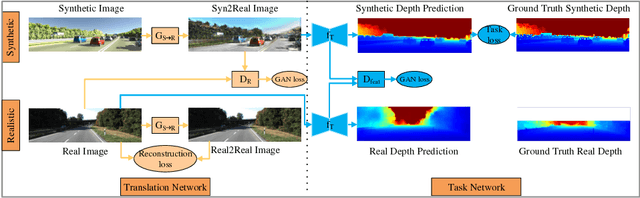
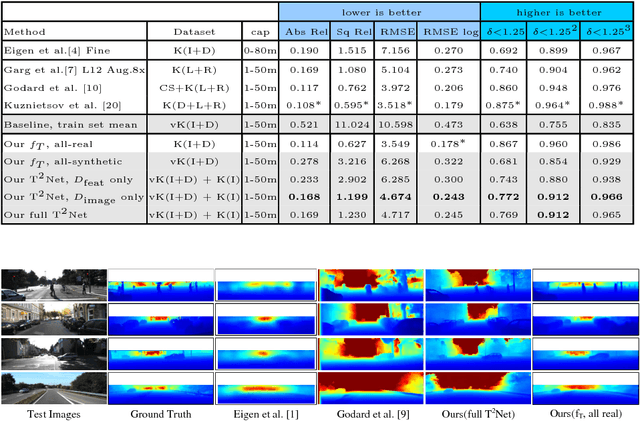
Current methods for single-image depth estimation use training datasets with real image-depth pairs or stereo pairs, which are not easy to acquire. We propose a framework, trained on synthetic image-depth pairs and unpaired real images, that comprises an image translation network for enhancing realism of input images, followed by a depth prediction network. A key idea is having the first network act as a wide-spectrum input translator, taking in either synthetic or real images, and ideally producing minimally modified realistic images. This is done via a reconstruction loss when the training input is real, and GAN loss when synthetic, removing the need for heuristic self-regularization. The second network is trained on a task loss for synthetic image-depth pairs, with extra GAN loss to unify real and synthetic feature distributions. Importantly, the framework can be trained end-to-end, leading to good results, even surpassing early deep-learning methods that use real paired data.
Image Quality Transfer Enhances Contrast and Resolution of Low-Field Brain MRI in African Paediatric Epilepsy Patients
Mar 16, 2020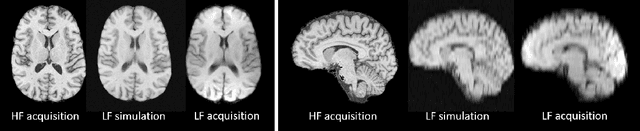
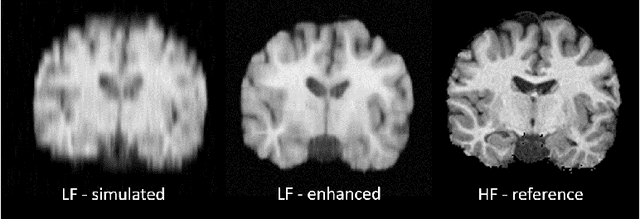
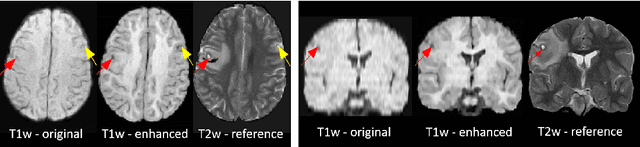
1.5T or 3T scanners are the current standard for clinical MRI, but low-field (<1T) scanners are still common in many lower- and middle-income countries for reasons of cost and robustness to power failures. Compared to modern high-field scanners, low-field scanners provide images with lower signal-to-noise ratio at equivalent resolution, leaving practitioners to compensate by using large slice thickness and incomplete spatial coverage. Furthermore, the contrast between different types of brain tissue may be substantially reduced even at equal signal-to-noise ratio, which limits diagnostic value. Recently the paradigm of Image Quality Transfer has been applied to enhance 0.36T structural images aiming to approximate the resolution, spatial coverage, and contrast of typical 1.5T or 3T images. A variant of the neural network U-Net was trained using low-field images simulated from the publicly available 3T Human Connectome Project dataset. Here we present qualitative results from real and simulated clinical low-field brain images showing the potential value of IQT to enhance the clinical utility of readily accessible low-field MRIs in the management of epilepsy.
VoxelMorph: A Learning Framework for Deformable Medical Image Registration
Sep 14, 2018
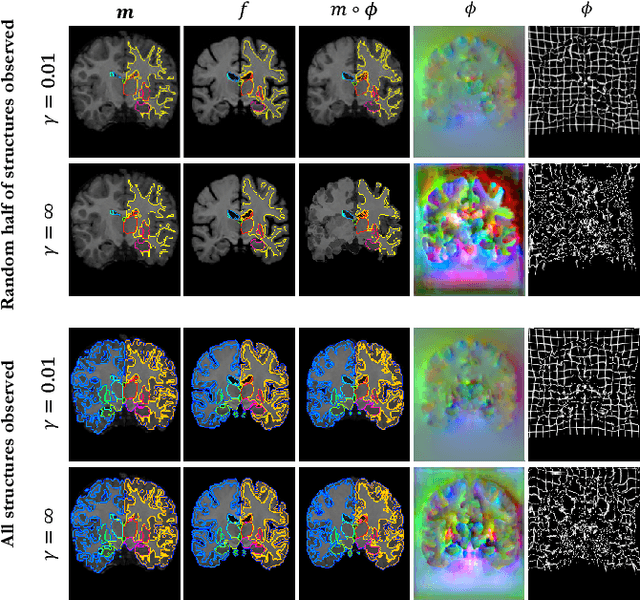
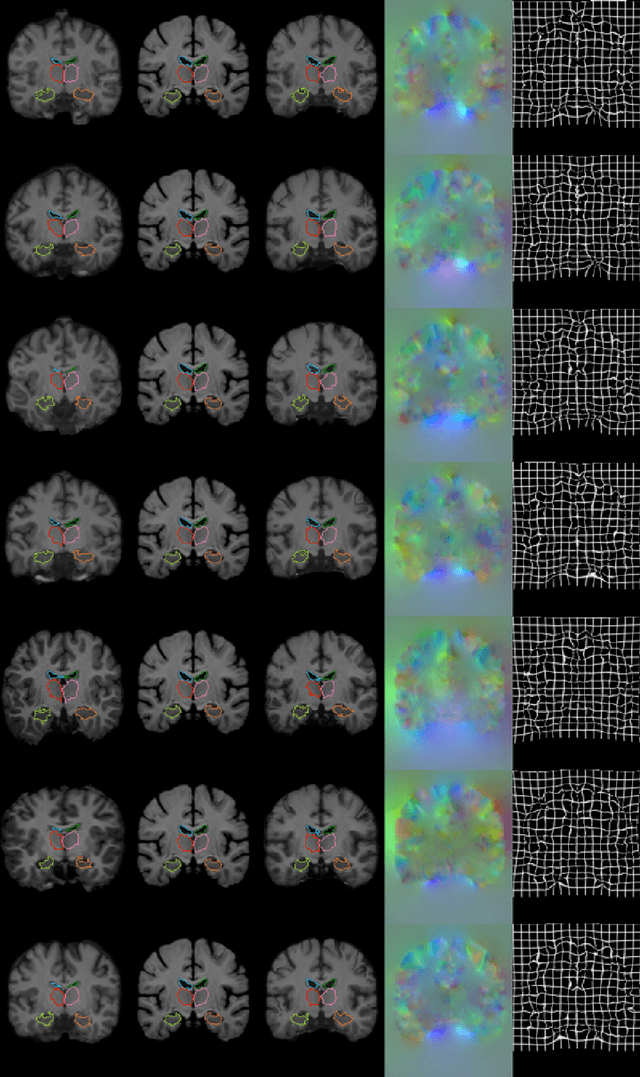
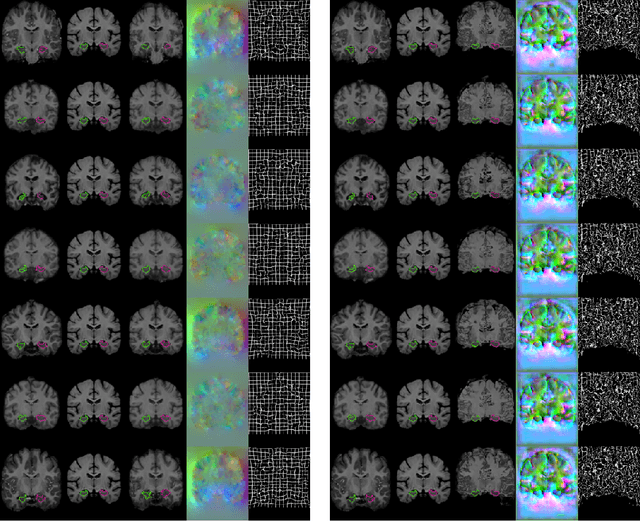
We present VoxelMorph, a fast, unsupervised, learning-based algorithm for deformable pairwise medical image registration. Traditional registration methods optimize an objective function independently for each pair of images, which is time-consuming for large datasets. We define registration as a parametric function, implemented as a convolutional neural network (CNN). We optimize its global parameters given a set of images from a collection of interest. Given a new pair of scans, VoxelMorph rapidly computes a deformation field by directly evaluating the function. Our model is flexible, enabling the use of any differentiable objective function to optimize these parameters. In this work, we propose and extensively evaluate a standard image matching objective function as well as an objective function that can use auxiliary data such as anatomical segmentations available only at training time. We demonstrate that the unsupervised model's accuracy is comparable to state-of-the-art methods, while operating orders of magnitude faster. We also show that VoxelMorph trained with auxiliary data significantly improves registration accuracy at test time. Our method promises to significantly speed up medical image analysis and processing pipelines, while facilitating novel directions in learning-based registration and its applications. Our code is freely available at voxelmorph.csail.mit.edu.
Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
Feb 10, 2021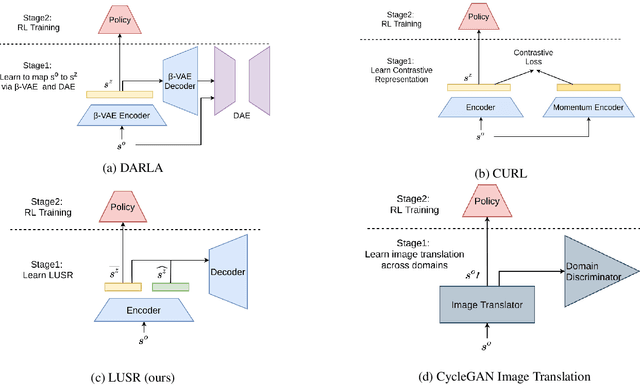

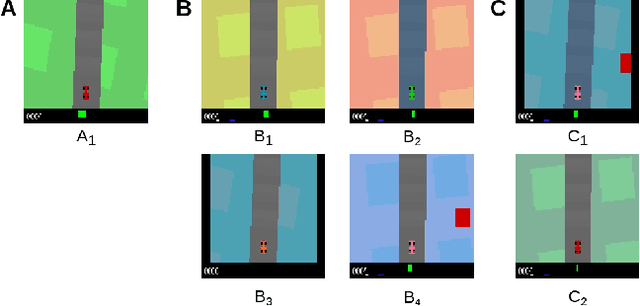
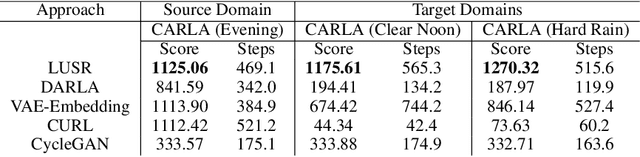
Despite the recent success of deep reinforcement learning (RL), domain adaptation remains an open problem. Although the generalization ability of RL agents is critical for the real-world applicability of Deep RL, zero-shot policy transfer is still a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. To address this issue, we propose a two-stage RL agent that first learns a latent unified state representation (LUSR) which is consistent across multiple domains in the first stage, and then do RL training in one source domain based on LUSR in the second stage. The cross-domain consistency of LUSR allows the policy acquired from the source domain to generalize to other target domains without extra training. We first demonstrate our approach in variants of CarRacing games with customized manipulations, and then verify it in CARLA, an autonomous driving simulator with more complex and realistic visual observations. Our results show that this approach can achieve state-of-the-art domain adaptation performance in related RL tasks and outperforms prior approaches based on latent-representation based RL and image-to-image translation.
Multi-Atlas Based Pathological Stratification of d-TGA Congenital Heart Disease
Apr 05, 2021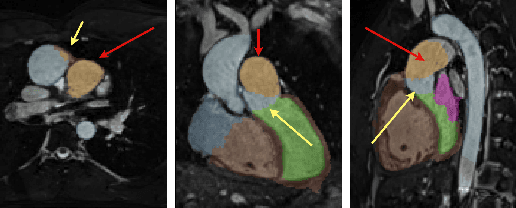
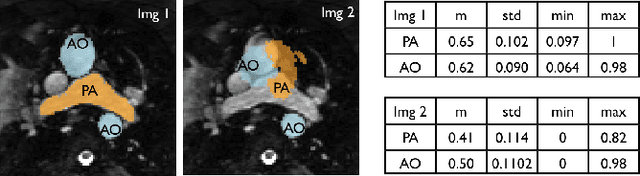
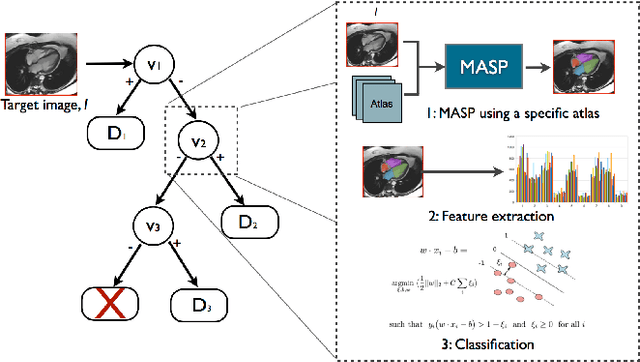
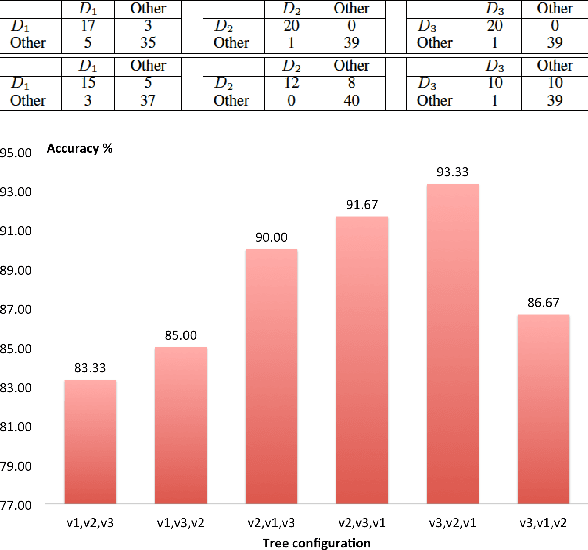
One of the main sources of error in multi-atlas segmentation propagation approaches comes from the use of atlas databases that are morphologically dissimilar to the target image. In this work, we exploit the segmentation errors associated with poor atlas selection to build a computer aided diagnosis (CAD) system for pathological classification in post-operative dextro-transposition of the great arteries (d-TGA). The proposed approach extracts a set of features, which describe the quality of a segmentation, and introduces them into a logical decision tree that provides the final diagnosis. We have validated our method on a set of 60 whole heart MR images containing healthy cases and two different forms of post-operative d-TGA. The reported overall CAD system accuracy was of 93.33%.
Point-Based Modeling of Human Clothing
Apr 22, 2021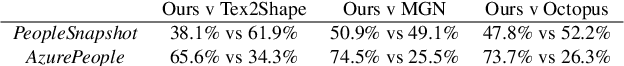
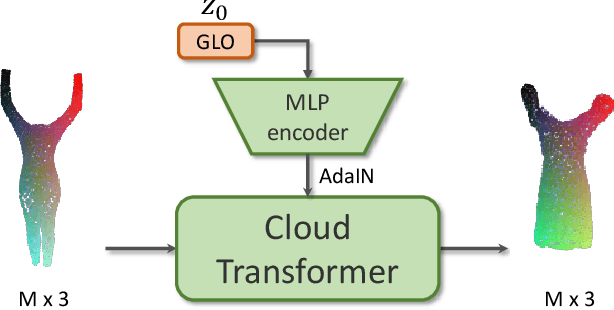
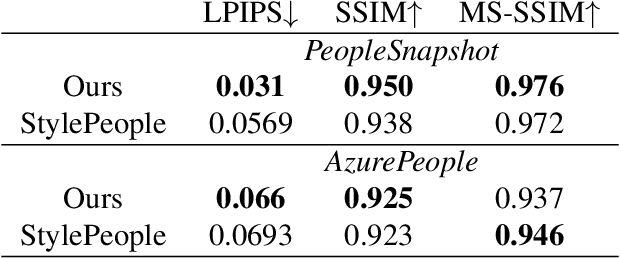
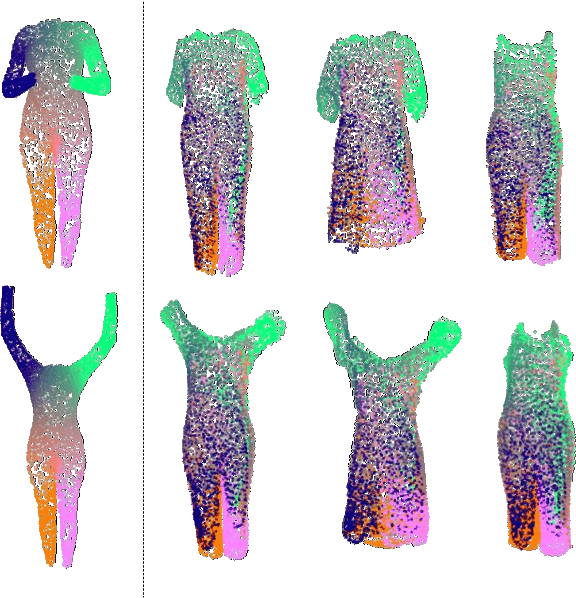
We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer geometry of new outfits from as little as a singe image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding, and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods, and establish the viability of point-based clothing modeling.
A new solution to the curved Ewald sphere problem for 3D image reconstruction in electron microscopy
Feb 07, 2021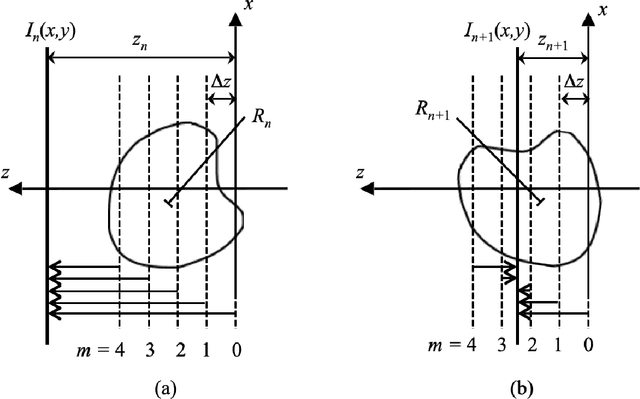
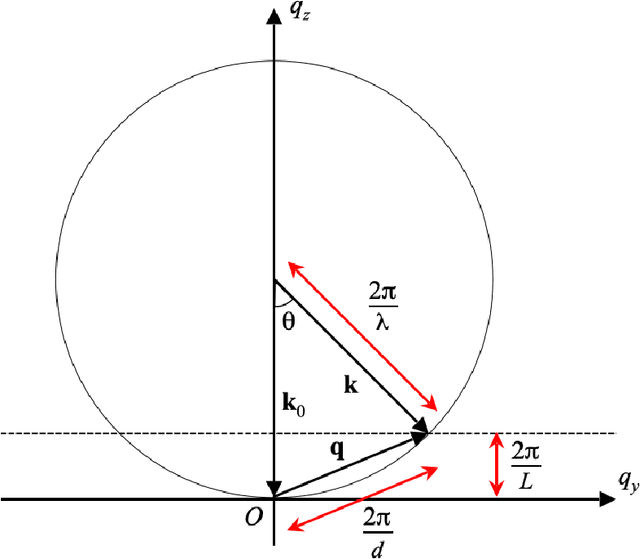
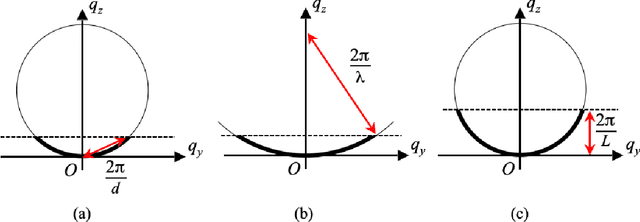
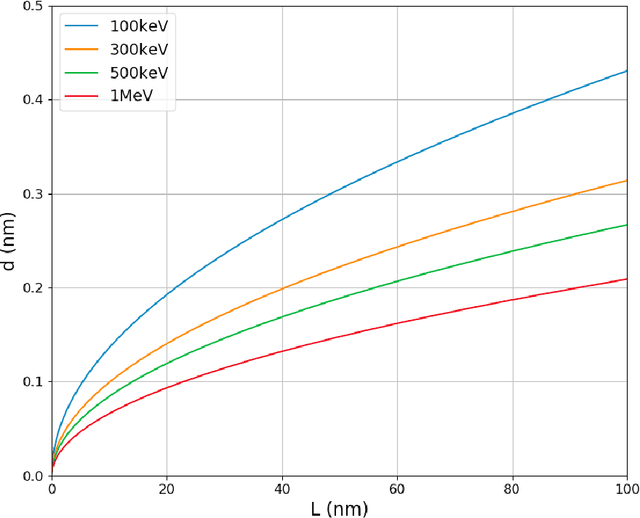
We develop an algorithm capable of imaging a three-dimensional object given a collection of two-dimensional images of that object that are significantly influenced by the curvature of the Ewald sphere. These two-dimensional images cannot be approximated as projections of the object. Such an algorithm is useful in cryo-electron microscopy where larger samples, higher resolution, or lower energy electron beams are desired, all of which contribute to the significance of Ewald curvature.
Improve the Interpretability of Attention: A Fast, Accurate, and Interpretable High-Resolution Attention Model
Jun 07, 2021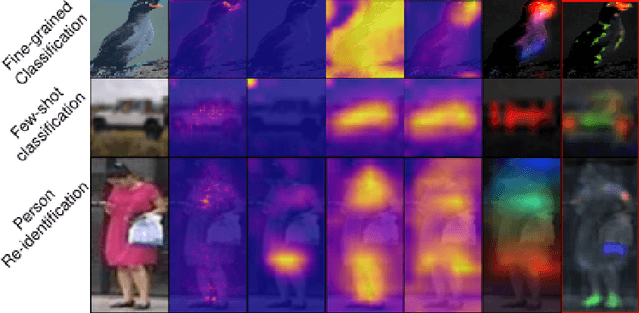
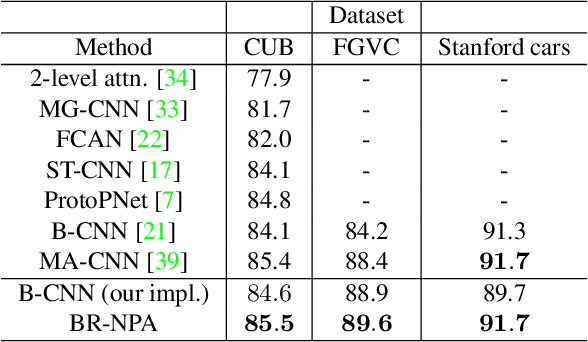
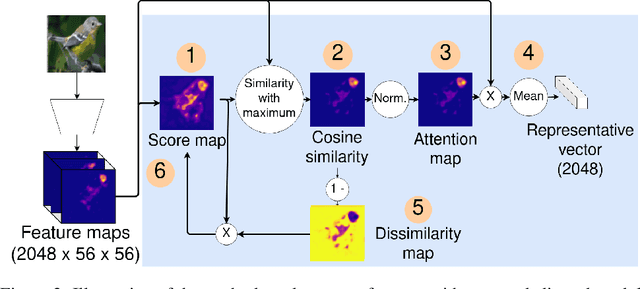
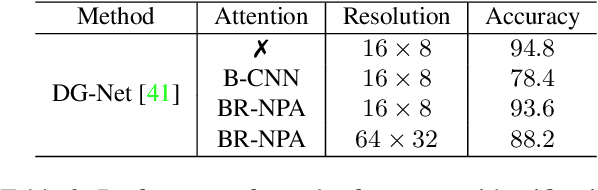
The prevalence of employing attention mechanisms has brought along concerns on the interpretability of attention distributions. Although it provides insights about how a model is operating, utilizing attention as the explanation of model predictions is still highly dubious. The community is still seeking more interpretable strategies for better identifying local active regions that contribute the most to the final decision. To improve the interpretability of existing attention models, we propose a novel Bilinear Representative Non-Parametric Attention (BR-NPA) strategy that captures the task-relevant human-interpretable information. The target model is first distilled to have higher-resolution intermediate feature maps. From which, representative features are then grouped based on local pairwise feature similarity, to produce finer-grained, more precise attention maps highlighting task-relevant parts of the input. The obtained attention maps are ranked according to the `active level' of the compound feature, which provides information regarding the important level of the highlighted regions. The proposed model can be easily adapted in a wide variety of modern deep models, where classification is involved. It is also more accurate, faster, and with a smaller memory footprint than usual neural attention modules. Extensive experiments showcase more comprehensive visual explanations compared to the state-of-the-art visualization model across multiple tasks including few-shot classification, person re-identification, fine-grained image classification. The proposed visualization model sheds imperative light on how neural networks `pay their attention' differently in different tasks.