 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Probabilistic Pruning: A general framework for hardware-constrained pruning at different granularities
May 26, 2021
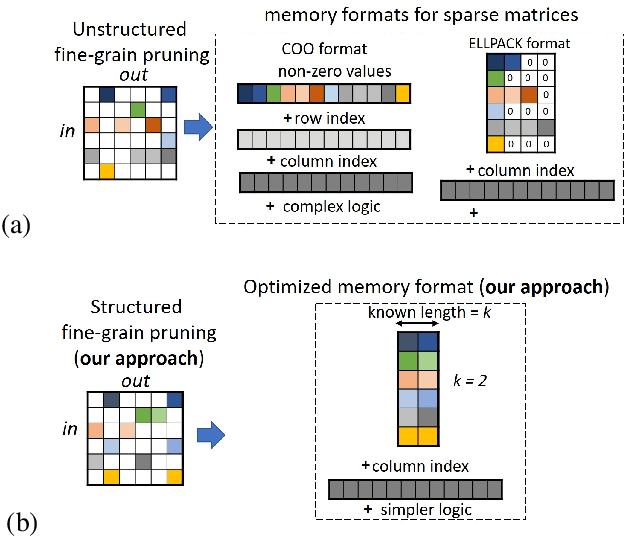
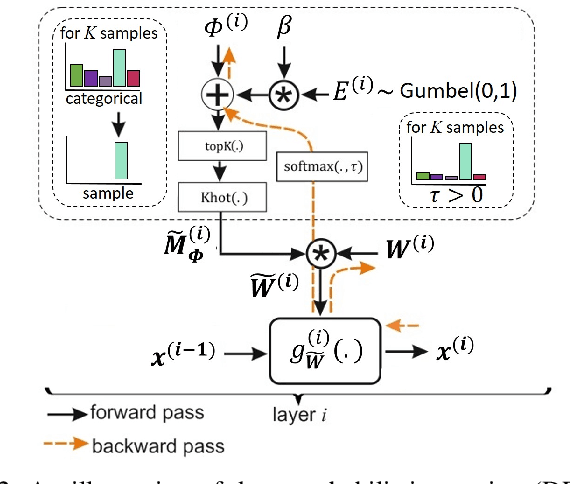
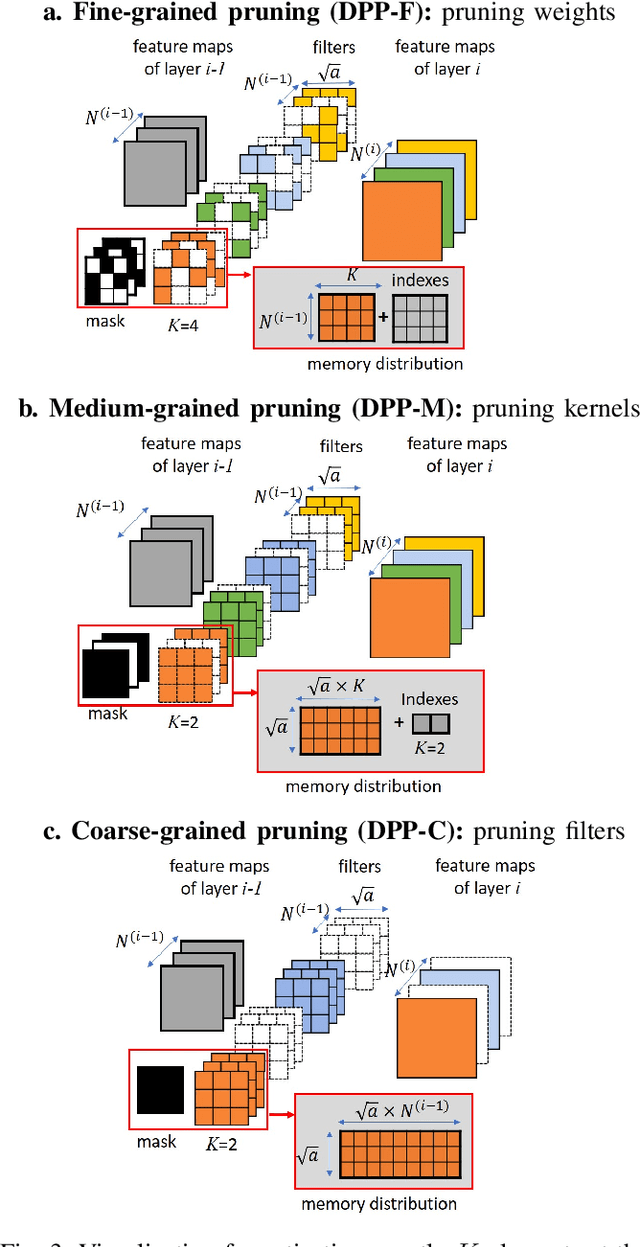
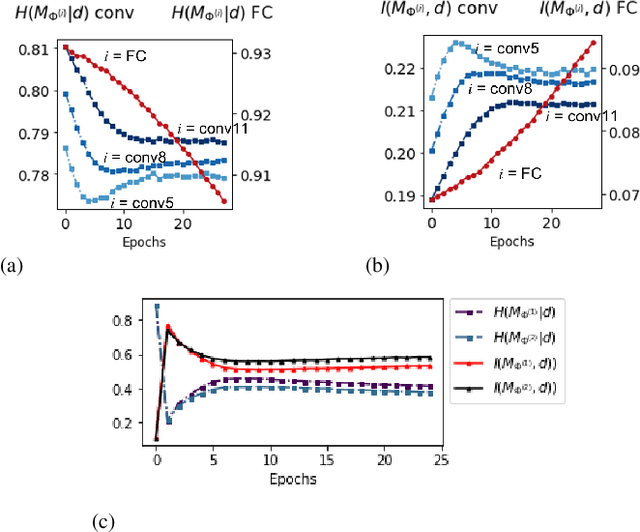
Unstructured neural network pruning algorithms have achieved impressive compression rates. However, the resulting - typically irregular - sparse matrices hamper efficient hardware implementations, leading to additional memory usage and complex control logic that diminishes the benefits of unstructured pruning. This has spurred structured coarse-grained pruning solutions that prune entire filters or even layers, enabling efficient implementation at the expense of reduced flexibility. Here we propose a flexible new pruning mechanism that facilitates pruning at different granularities (weights, kernels, filters/feature maps), while retaining efficient memory organization (e.g. pruning exactly k-out-of-n weights for every output neuron, or pruning exactly k-out-of-n kernels for every feature map). We refer to this algorithm as Dynamic Probabilistic Pruning (DPP). DPP leverages the Gumbel-softmax relaxation for differentiable k-out-of-n sampling, facilitating end-to-end optimization. We show that DPP achieves competitive compression rates and classification accuracy when pruning common deep learning models trained on different benchmark datasets for image classification. Relevantly, the non-magnitude-based nature of DPP allows for joint optimization of pruning and weight quantization in order to even further compress the network, which we show as well. Finally, we propose novel information theoretic metrics that show the confidence and pruning diversity of pruning masks within a layer.
Universal Adversarial Perturbations Through the Lens of Deep Steganography: Towards A Fourier Perspective
Feb 12, 2021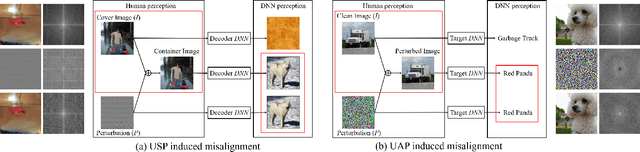

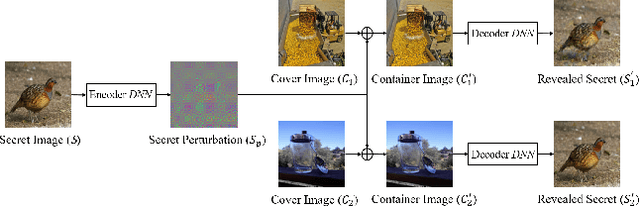
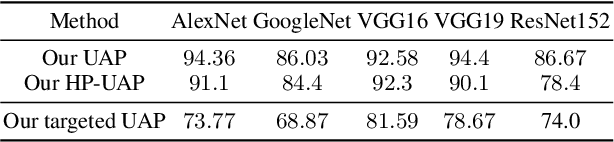
The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Identifying Recurring Patterns with Deep Neural Networks for Natural Image Denoising
Jun 13, 2018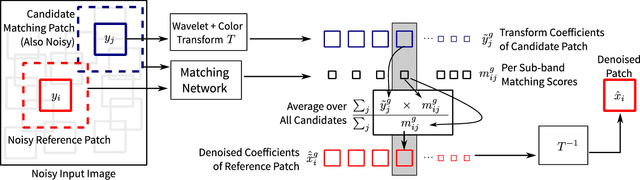
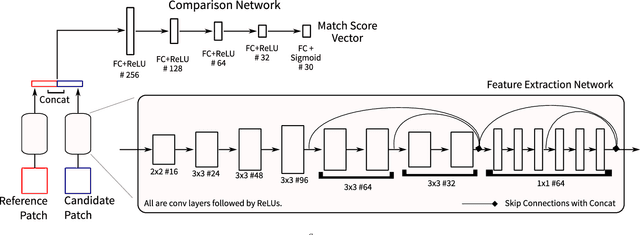

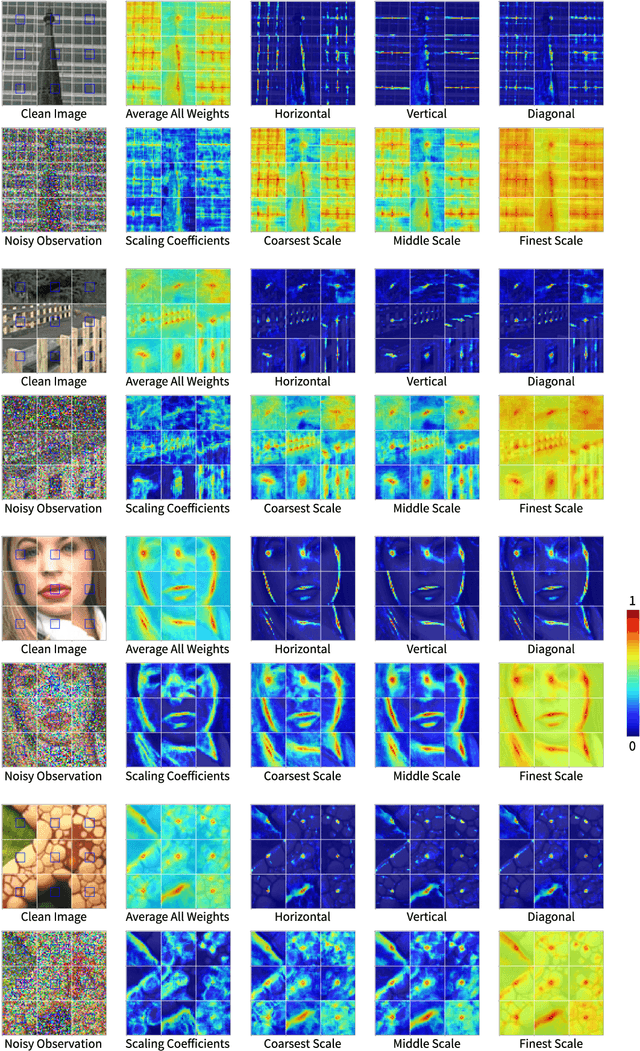
While there is a vast diversity in the patterns and textures that occur across different varieties of natural images, the variance of such patterns within a single image is far more limited. A variety of traditional methods have exploited this self-similarity or recurrence with considerable success for image modeling, estimation, and restoration. A key challenge, however, is in accurately identifying recurring patterns within degraded image observations. This work proposes a new method for natural image denoising, that trains a deep neural network to determine whether noisy patches share common underlying patterns. Specifically, given a pair of noisy patches, the network predicts whether different transform sub-band coefficients of the original noise-free patches are the same. The denoising algorithm averages these matched coefficients to obtain an initial estimate of the clean image, with much higher quality than traditional approaches. This estimate is then refined with a second post-processing network, yielding state-of-the-art denoising performance.
LaLaLoc: Latent Layout Localisation in Dynamic, Unvisited Environments
Apr 19, 2021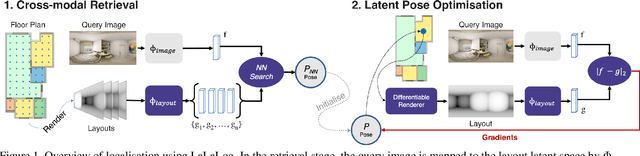
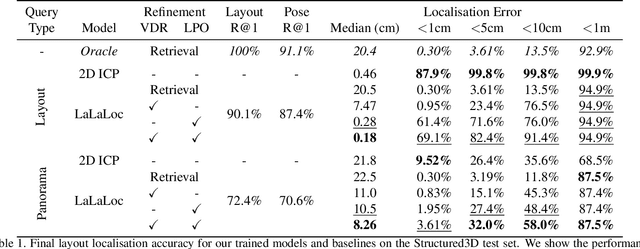
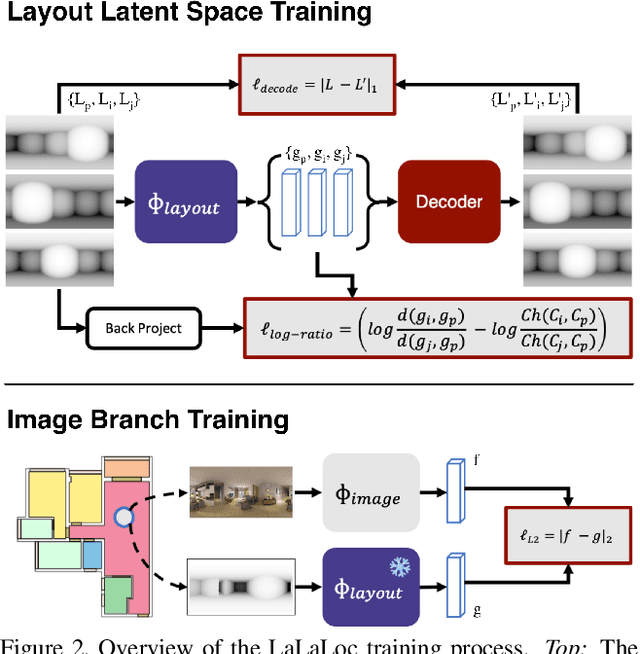
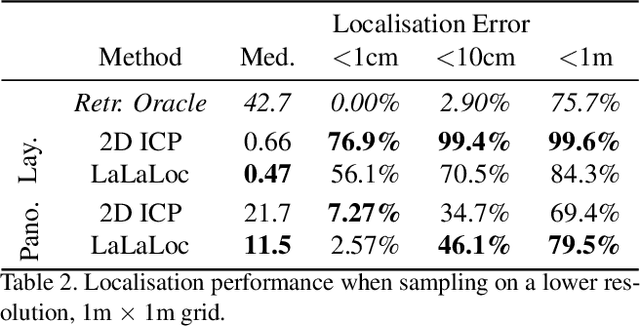
We present LaLaLoc to localise in environments without the need for prior visitation, and in a manner that is robust to large changes in scene appearance, such as a full rearrangement of furniture. Specifically, LaLaLoc performs localisation through latent representations of room layout. LaLaLoc learns a rich embedding space shared between RGB panoramas and layouts inferred from a known floor plan that encodes the structural similarity between locations. Further, LaLaLoc introduces direct, cross-modal pose optimisation in its latent space. Thus, LaLaLoc enables fine-grained pose estimation in a scene without the need for prior visitation, as well as being robust to dynamics, such as a change in furniture configuration. We show that in a domestic environment LaLaLoc is able to accurately localise a single RGB panorama image to within 8.3cm, given only a floor plan as a prior.
Fast and Accurate 3D Medical Image Segmentation with Data-swapping Method
Dec 19, 2018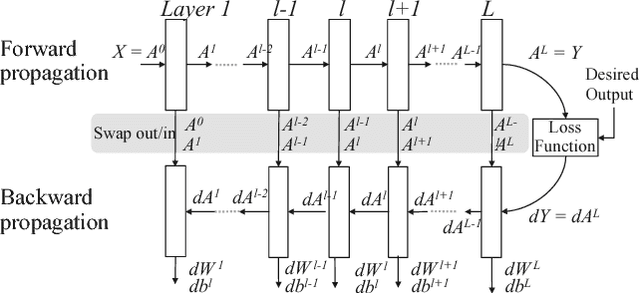
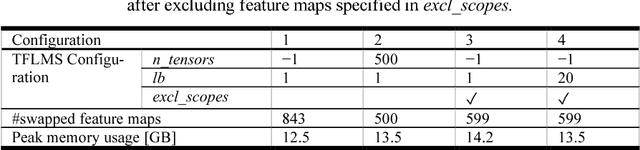
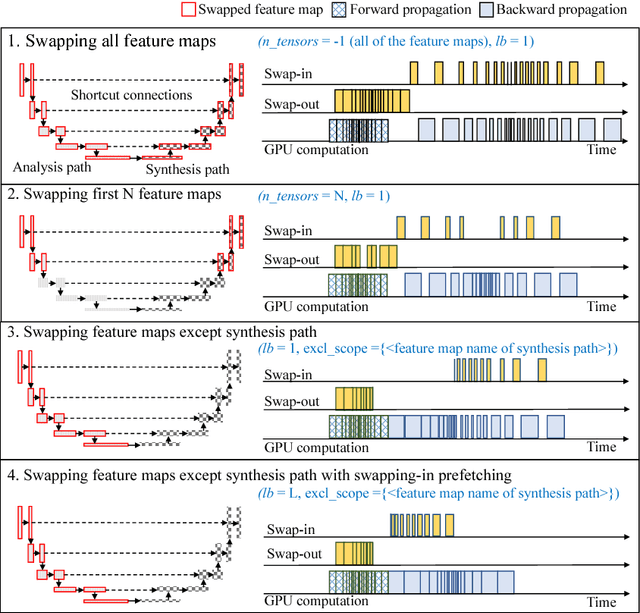
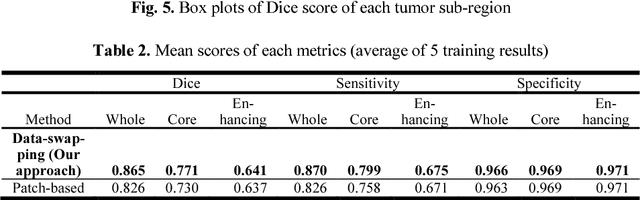
Deep neural network models used for medical image segmentation are large because they are trained with high-resolution three-dimensional (3D) images. Graphics processing units (GPUs) are widely used to accelerate the trainings. However, the memory on a GPU is not large enough to train the models. A popular approach to tackling this problem is patch-based method, which divides a large image into small patches and trains the models with these small patches. However, this method would degrade the segmentation quality if a target object spans multiple patches. In this paper, we propose a novel approach for 3D medical image segmentation that utilizes the data-swapping, which swaps out intermediate data from GPU memory to CPU memory to enlarge the effective GPU memory size, for training high-resolution 3D medical images without patching. We carefully tuned parameters in the data-swapping method to obtain the best training performance for 3D U-Net, a widely used deep neural network model for medical image segmentation. We applied our tuning to train 3D U-Net with full-size images of 192 x 192 x 192 voxels in brain tumor dataset. As a result, communication overhead, which is the most important issue, was reduced by 17.1%. Compared with the patch-based method for patches of 128 x 128 x 128 voxels, our training for full-size images achieved improvement on the mean Dice score by 4.48% and 5.32 % for detecting whole tumor sub-region and tumor core sub-region, respectively. The total training time was reduced from 164 hours to 47 hours, resulting in 3.53 times of acceleration.
EagerMOT: 3D Multi-Object Tracking via Sensor Fusion
Apr 29, 2021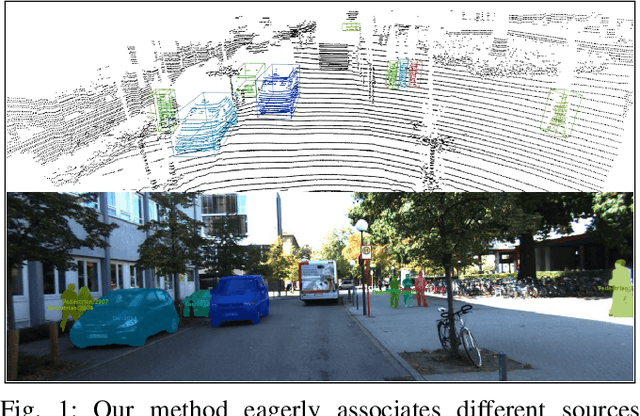
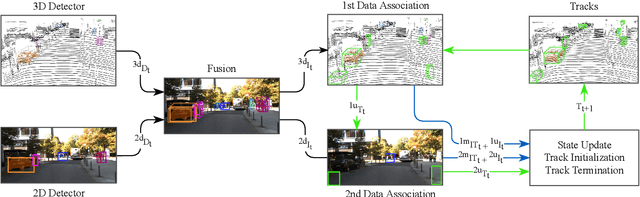
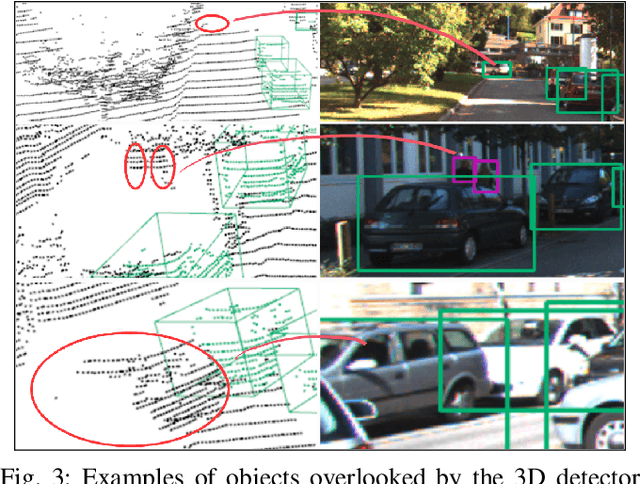
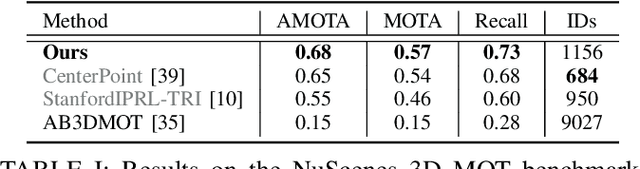
Multi-object tracking (MOT) enables mobile robots to perform well-informed motion planning and navigation by localizing surrounding objects in 3D space and time. Existing methods rely on depth sensors (e.g., LiDAR) to detect and track targets in 3D space, but only up to a limited sensing range due to the sparsity of the signal. On the other hand, cameras provide a dense and rich visual signal that helps to localize even distant objects, but only in the image domain. In this paper, we propose EagerMOT, a simple tracking formulation that eagerly integrates all available object observations from both sensor modalities to obtain a well-informed interpretation of the scene dynamics. Using images, we can identify distant incoming objects, while depth estimates allow for precise trajectory localization as soon as objects are within the depth-sensing range. With EagerMOT, we achieve state-of-the-art results across several MOT tasks on the KITTI and NuScenes datasets. Our code is available at https://github.com/aleksandrkim61/EagerMOT.
Unsupervised Image Super-Resolution using Cycle-in-Cycle Generative Adversarial Networks
Sep 03, 2018

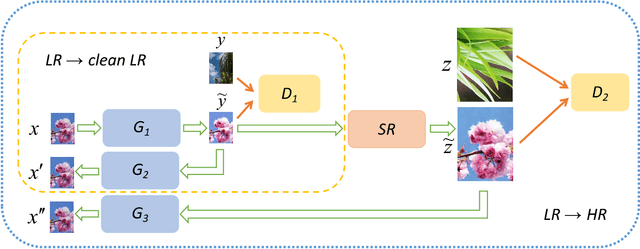
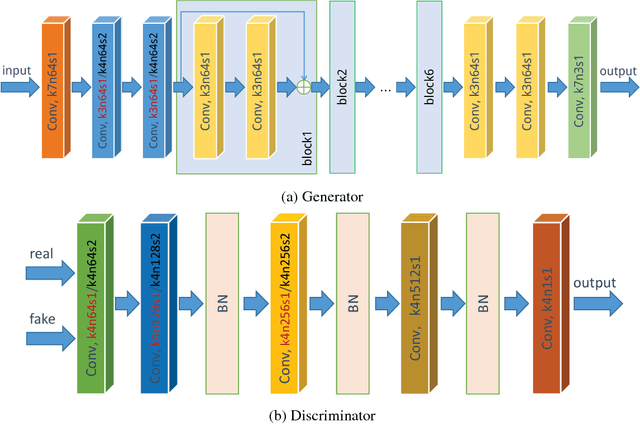
We consider the single image super-resolution problem in a more general case that the low-/high-resolution pairs and the down-sampling process are unavailable. Different from traditional super-resolution formulation, the low-resolution input is further degraded by noises and blurring. This complicated setting makes supervised learning and accurate kernel estimation impossible. To solve this problem, we resort to unsupervised learning without paired data, inspired by the recent successful image-to-image translation applications. With generative adversarial networks (GAN) as the basic component, we propose a Cycle-in-Cycle network structure to tackle the problem within three steps. First, the noisy and blurry input is mapped to a noise-free low-resolution space. Then the intermediate image is up-sampled with a pre-trained deep model. Finally, we fine-tune the two modules in an end-to-end manner to get the high-resolution output. Experiments on NTIRE2018 datasets demonstrate that the proposed unsupervised method achieves comparable results as the state-of-the-art supervised models.
LLC: Accurate, Multi-purpose Learnt Low-dimensional Binary Codes
Jun 02, 2021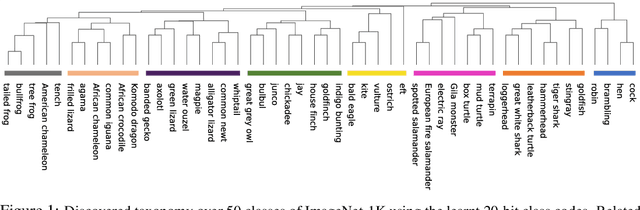

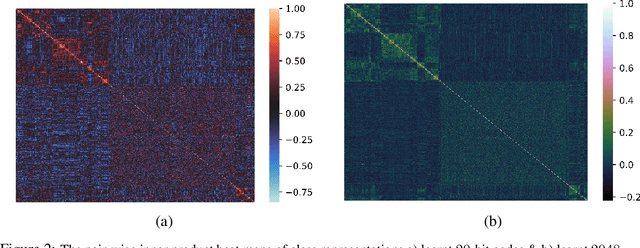

Learning binary representations of instances and classes is a classical problem with several high potential applications. In modern settings, the compression of high-dimensional neural representations to low-dimensional binary codes is a challenging task and often require large bit-codes to be accurate. In this work, we propose a novel method for Learning Low-dimensional binary Codes (LLC) for instances as well as classes. Our method does not require any side-information, like annotated attributes or label meta-data, and learns extremely low-dimensional binary codes (~20 bits for ImageNet-1K). The learnt codes are super-efficient while still ensuring nearly optimal classification accuracy for ResNet50 on ImageNet-1K. We demonstrate that the learnt codes capture intrinsically important features in the data, by discovering an intuitive taxonomy over classes. We further quantitatively measure the quality of our codes by applying it to the efficient image retrieval as well as out-of-distribution (OOD) detection problems. For ImageNet-100 retrieval problem, our learnt binary codes outperform 16 bit HashNet using only 10 bits and also are as accurate as 10 dimensional real representations. Finally, our learnt binary codes can perform OOD detection, out-of-the-box, as accurately as a baseline that needs ~3000 samples to tune its threshold, while we require none. Code and pre-trained models are available at https://github.com/RAIVNLab/LLC.
Generative Models as a Data Source for Multiview Representation Learning
Jun 09, 2021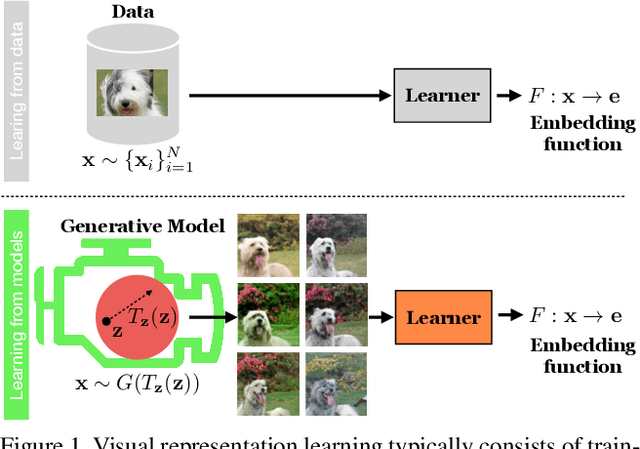
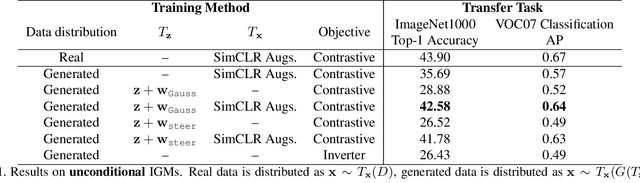
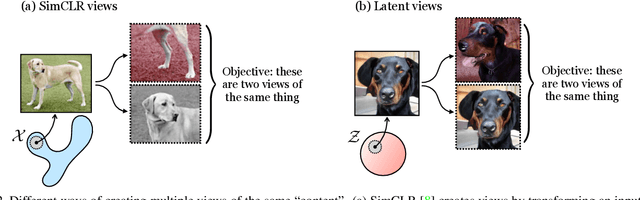
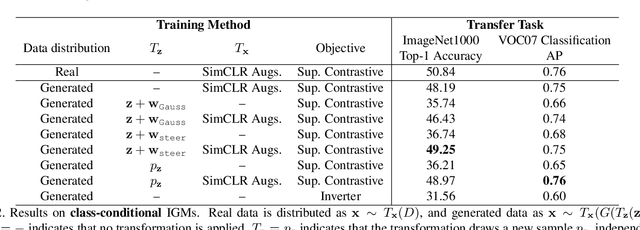
Generative models are now capable of producing highly realistic images that look nearly indistinguishable from the data on which they are trained. This raises the question: if we have good enough generative models, do we still need datasets? We investigate this question in the setting of learning general-purpose visual representations from a black-box generative model rather than directly from data. Given an off-the-shelf image generator without any access to its training data, we train representations from the samples output by this generator. We compare several representation learning methods that can be applied to this setting, using the latent space of the generator to generate multiple "views" of the same semantic content. We show that for contrastive methods, this multiview data can naturally be used to identify positive pairs (nearby in latent space) and negative pairs (far apart in latent space). We find that the resulting representations rival those learned directly from real data, but that good performance requires care in the sampling strategy applied and the training method. Generative models can be viewed as a compressed and organized copy of a dataset, and we envision a future where more and more "model zoos" proliferate while datasets become increasingly unwieldy, missing, or private. This paper suggests several techniques for dealing with visual representation learning in such a future. Code is released on our project page: https://ali-design.github.io/GenRep/
Analysis and evaluation of Deep Learning based Super-Resolution algorithms to improve performance in Low-Resolution Face Recognition
Jan 19, 2021
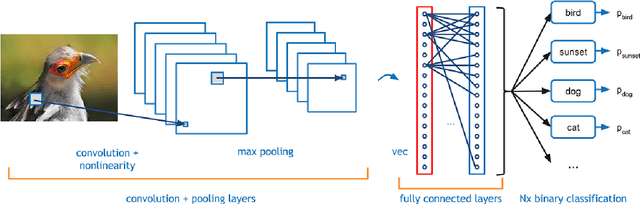
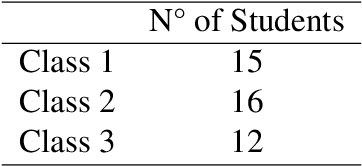
Surveillance scenarios are prone to several problems since they usually involve low-resolution footage, and there is no control of how far the subjects may be from the camera in the first place. This situation is suitable for the application of upsampling (super-resolution) algorithms since they may be able to recover the discriminant properties of the subjects involved. While general super-resolution approaches were proposed to enhance image quality for human-level perception, biometrics super-resolution methods seek the best "computer perception" version of the image since their focus is on improving automatic recognition performance. Convolutional neural networks and deep learning algorithms, in general, have been applied to computer vision tasks and are now state-of-the-art for several sub-domains, including image classification, restoration, and super-resolution. However, no work has evaluated the effects that the latest proposed super-resolution methods may have upon the accuracy and face verification performance in low-resolution "in-the-wild" data. This project aimed at evaluating and adapting different deep neural network architectures for the task of face super-resolution driven by face recognition performance in real-world low-resolution images. The experimental results in a real-world surveillance and attendance datasets showed that general super-resolution architectures might enhance face verification performance of deep neural networks trained on high-resolution faces. Also, since neural networks are function approximators and can be trained based on specific objective functions, the use of a customized loss function optimized for feature extraction showed promising results for recovering discriminant features in low-resolution face images.