 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Image and Depth Estimation with Mask-Based Lensless Cameras
Oct 06, 2019
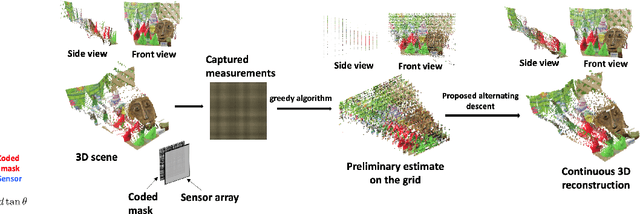


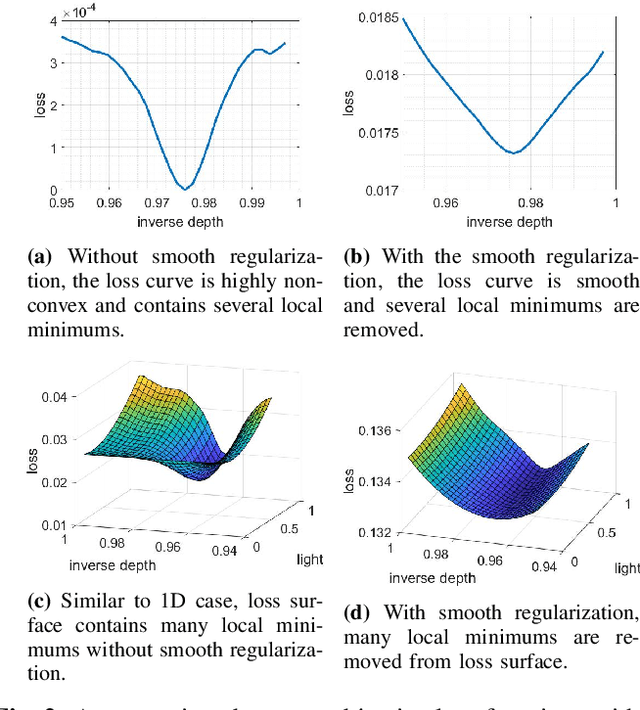
Mask-based lensless cameras replace the lens of a conventional camera with a customized mask. These cameras can potentially be very thin and even flexible. Recently, it has been demonstrated that such mask-based cameras can recover light intensity and depth information of a scene. Existing depth recovery algorithms either assume that the scene consists of a small number of depth planes or solve a sparse recovery problem over a large 3D volume. Both these approaches fail to recover scene with large depth variations. In this paper, we propose a new approach for depth estimation based on alternating gradient descent algorithm that jointly estimates a continuous depth map and light distribution of the unknown scene from its lensless measurements. The computational complexity of the algorithm scales linearly with the spatial dimension of the imaging system. We present simulation results on image and depth reconstruction for a variety of 3D test scenes. A comparison between the proposed algorithm and other method shows that our algorithm is faster and more robust for natural scenes with a large range of depths.
Big Plastic Masses Detection using Sentinel 2 Images
Mar 17, 2021

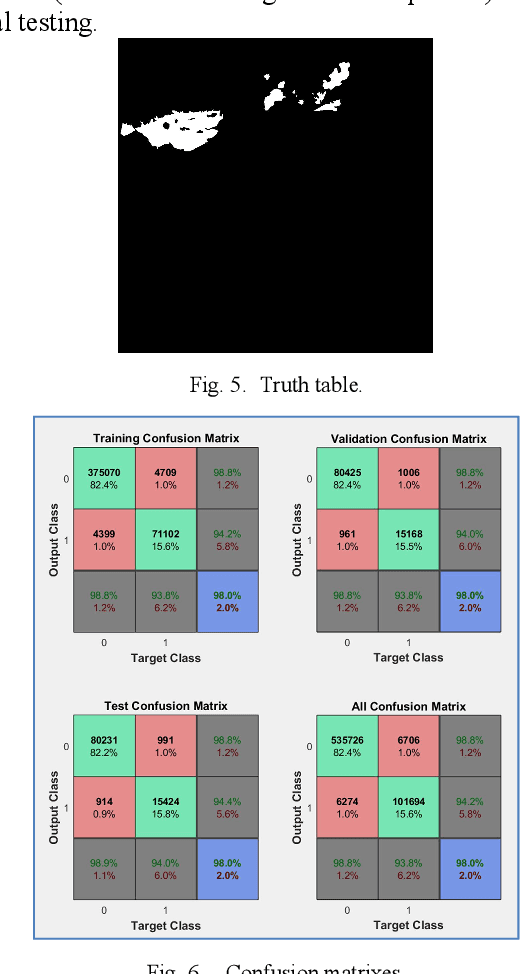
This communication describes a preliminary research on detection of big masses of plastic (marine litter) on the oceans and seas using EO (Earth Observation) satellite systems. Free images from the Sentinel 2 (Copernicus Project) platform are used. To develop a plastic recognizer, we start with an image where we can find a big accumulation of "nonfloating" plastic: Almer\'ia greenhouses. We made a test using remote sensing differential indexes, but we got much better results using all available wavelengths (thirteen frequency bands) and applying Neural Networks to that feature vector.
Single-Pixel Compressive Imaging in Shift-Invariant Spaces via Exact Wavelet Frames
Jun 01, 2021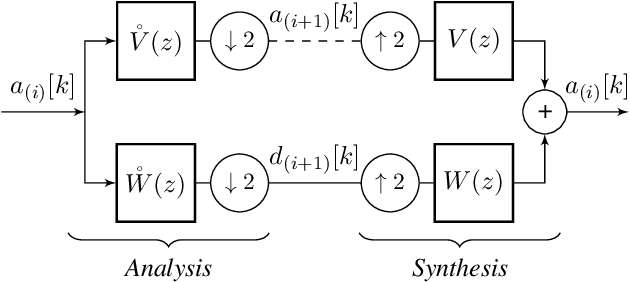


This paper introduces a novel framework for single-pixel imaging via compressive sensing (CS) in shift-invariant (SI) spaces by exploiting the sparsity property of a wavelet representation. We reinterpret the acquisition procedure of a single-pixel camera as filtering of the observed signal with continuous-domain functions that lie in an SI subspace spanned by the integer shifts of the box function. The signal is modeled by an arbitrary SI generator whose special case is the box function, which, as we show in the paper, is conventionally used in single-pixel imaging. We propose to use separable B-spline generators which are intuitively complemented by sparsity-inducing spline wavelets. The SI models of the acquisition and the underlying signal lead to an exact discretization of an inherently continuous-domain inverse problem to a finite-dimensional problem of CS type. By solving the CS optimization problem, a parametric representation of the signal is obtained. Such a representation offers many practical advantages in image processing applications. We propose an efficient matrix-free implementation of the framework and conduct it on the standard test images and real-world measurement data. Experimental results show that the proposed framework achieves a significant improvement of the reconstruction quality relative to the conventional CS setting.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
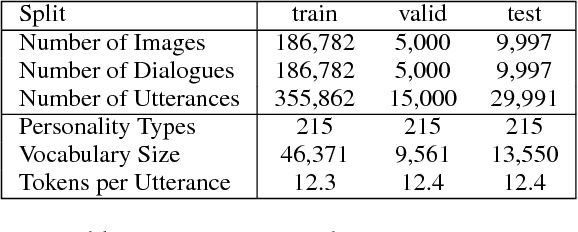
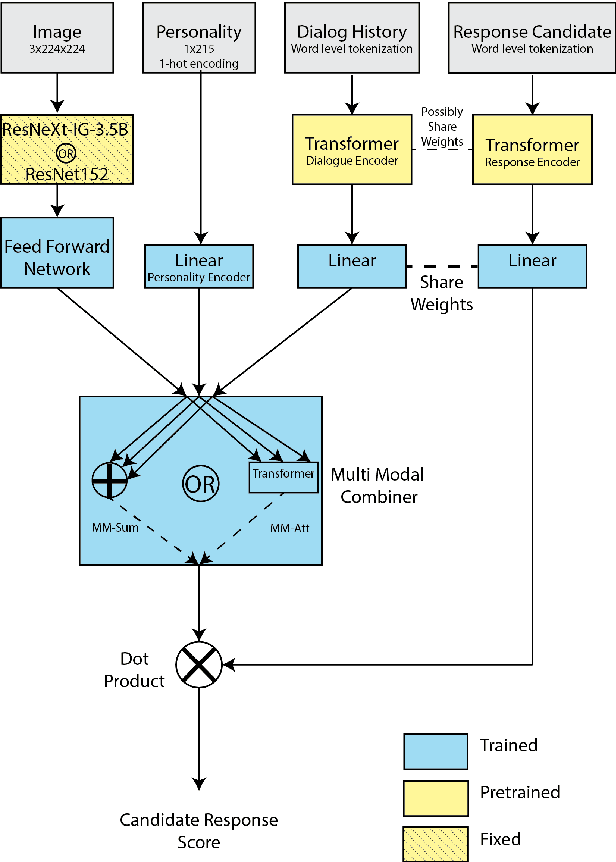

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time
Analysis of Vision-based Abnormal Red Blood Cell Classification
Jun 01, 2021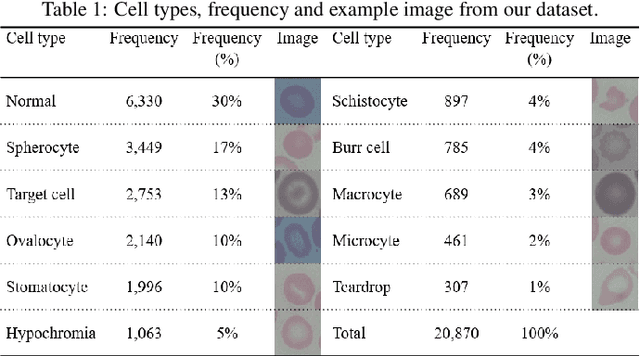
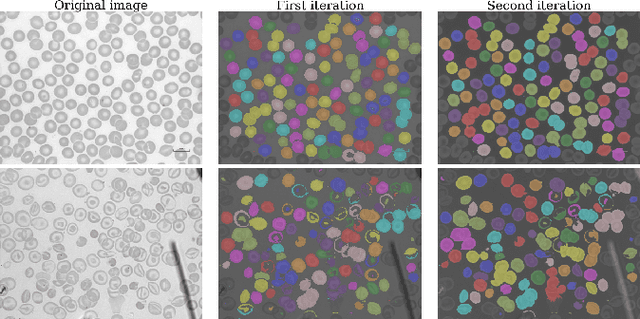
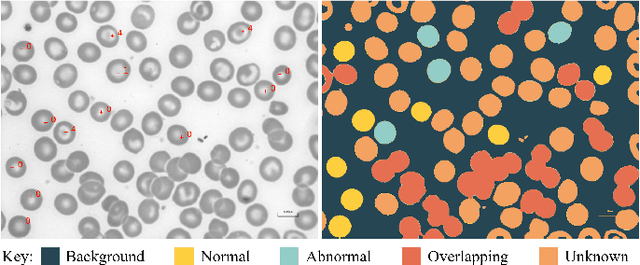
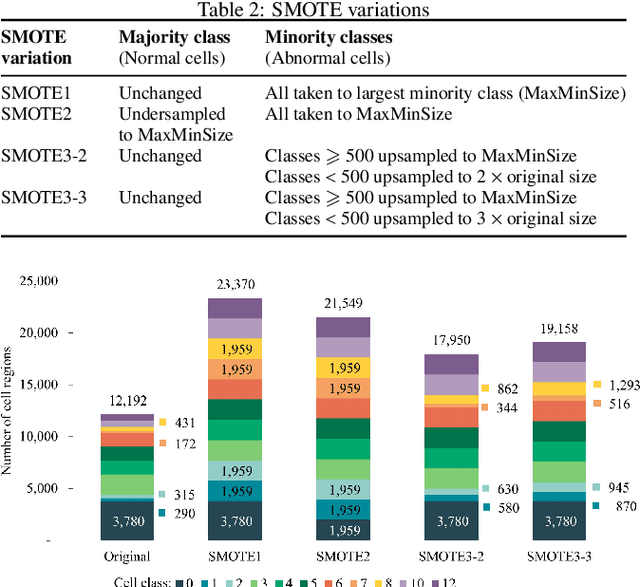
Identification of abnormalities in red blood cells (RBC) is key to diagnosing a range of medical conditions from anaemia to liver disease. Currently this is done manually, a time-consuming and subjective process. This paper presents an automated process utilising the advantages of machine learning to increase capacity and standardisation of cell abnormality detection, and its performance is analysed. Three different machine learning technologies were used: a Support Vector Machine (SVM), a classical machine learning technology; TabNet, a deep learning architecture for tabular data; U-Net, a semantic segmentation network designed for medical image segmentation. A critical issue was the highly imbalanced nature of the dataset which impacts the efficacy of machine learning. To address this, synthesising minority class samples in feature space was investigated via Synthetic Minority Over-sampling Technique (SMOTE) and cost-sensitive learning. A combination of these two methods is investigated to improve the overall performance. These strategies were found to increase sensitivity to minority classes. The impact of unknown cells on semantic segmentation is demonstrated, with some evidence of the model applying learning of labelled cells to these anonymous cells. These findings indicate both classical models and new deep learning networks as promising methods in automating RBC abnormality detection.
An Image Fusion Scheme for Single-Shot High Dynamic Range Imaging with Spatially Varying Exposures
Aug 22, 2019
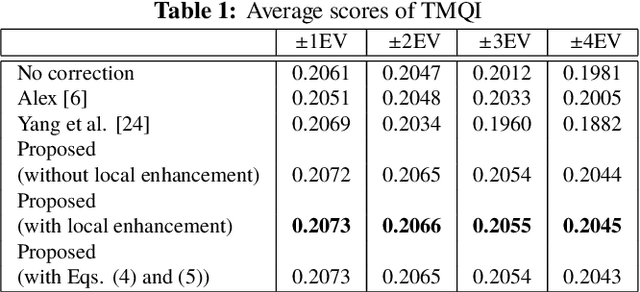
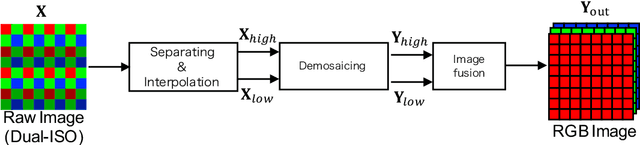
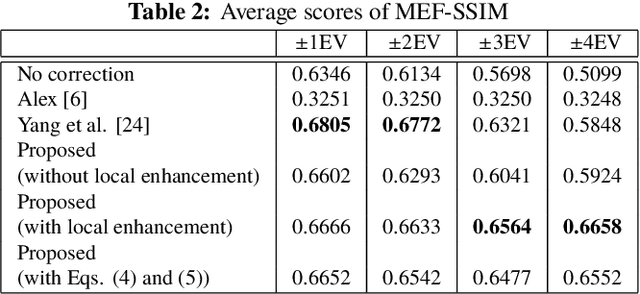
This paper proposes a novel multi-exposure image fusion (MEF) scheme for single-shot high dynamic range imaging with spatially varying exposures (SVE). Single-shot imaging with SVE enables us not only to produce images without color saturation regions from a single-shot image, but also to avoid ghost artifacts in the producing ones. However, the number of exposures is generally limited to two, and moreover it is difficult to decide the optimum exposure values before the photographing. In the proposed scheme, a scene segmentation method is applied to input multi-exposure images, and then the luminance of the input images is adjusted according to both of the number of scenes and the relationship between exposure values and pixel values. The proposed method with the luminance adjustment allows us to improve the above two issues. In this paper, we focus on dual-ISO imaging as one of single-shot imaging. In an experiment, the proposed scheme is demonstrated to be effective for single-shot high dynamic range imaging with SVE, compared with conventional MEF schemes with exposure compensation.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021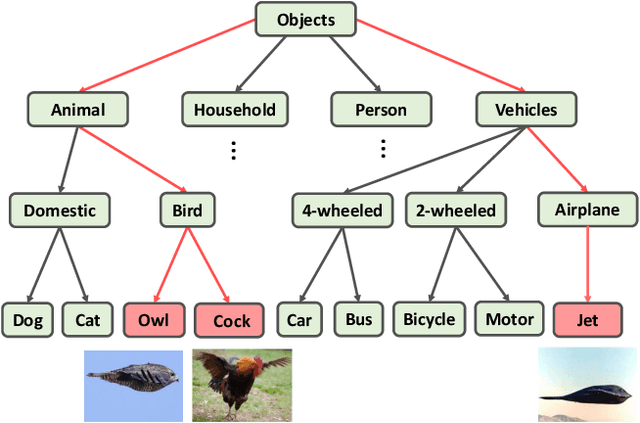
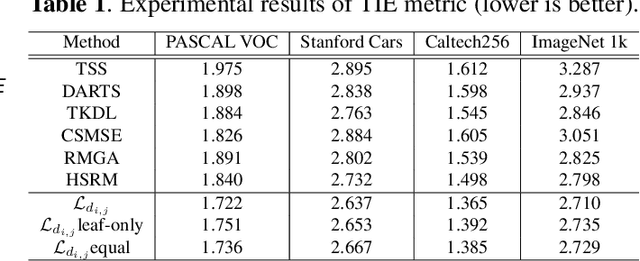
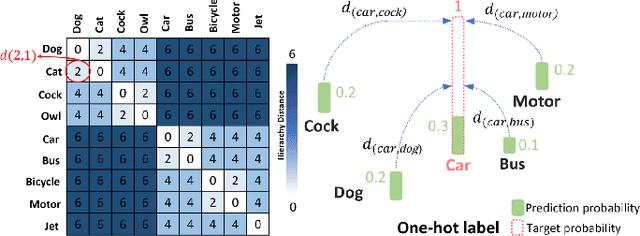
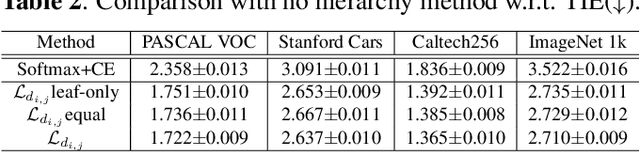
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
Classification of optics-free images with deep neural networks
Nov 10, 2020

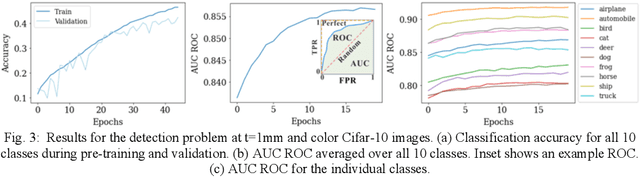
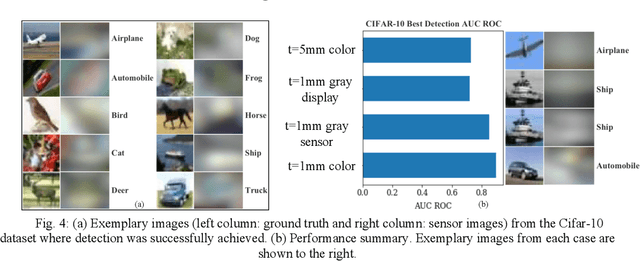
The thinnest possible camera is achieved by removing all optics, leaving only the image sensor. We train deep neural networks to perform multi-class detection and binary classification (with accuracy of 92%) on optics-free images without the need for anthropocentric image reconstructions. Inferencing from optics-free images has the potential for enhanced privacy and power efficiency.
TabAug: Data Driven Augmentation for Enhanced Table Structure Recognition
May 15, 2021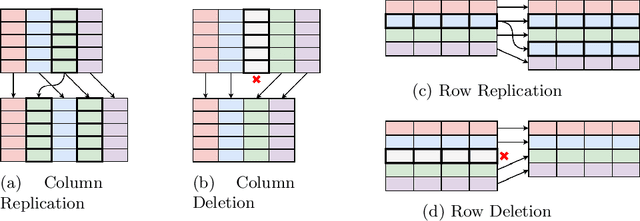
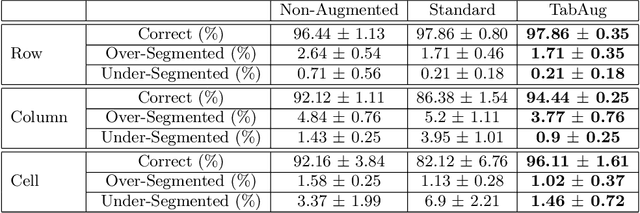
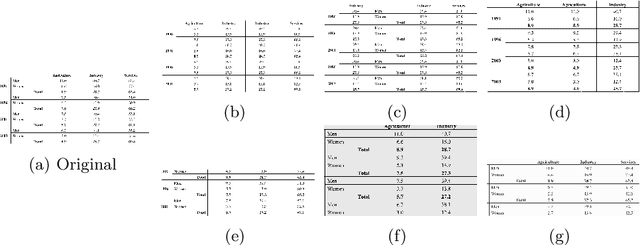
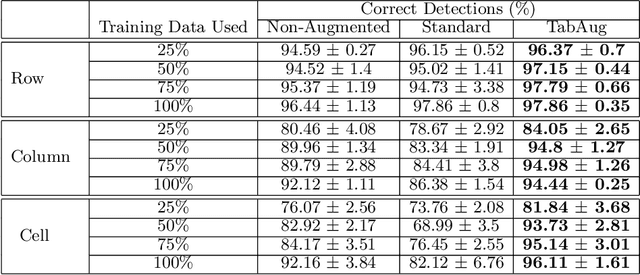
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.
Manifold Graph with Learned Prototypes for Semi-Supervised Image Classification
Jun 13, 2019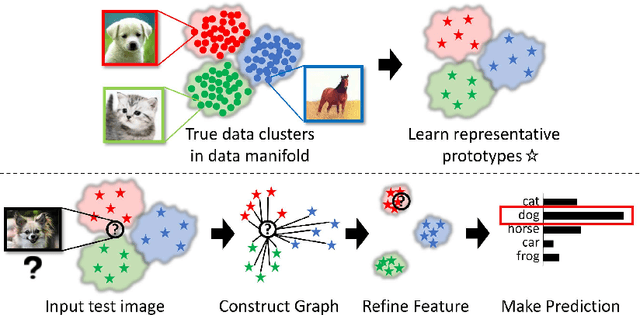
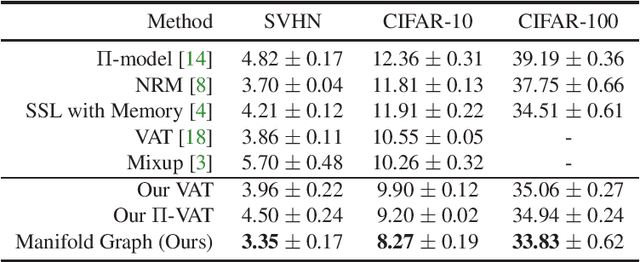
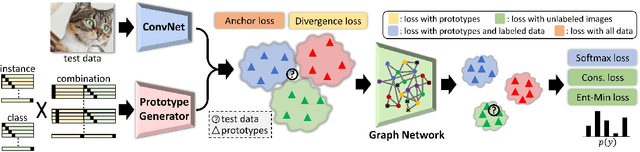
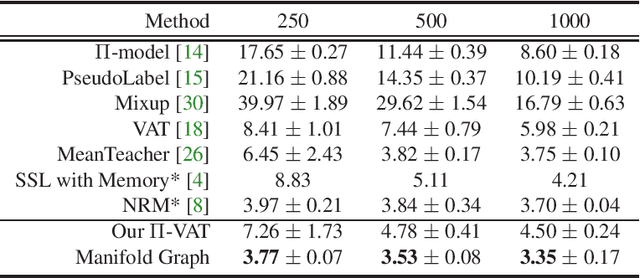
Recent advances in semi-supervised learning methods rely on estimating the categories of unlabeled data using a model trained on the labeled data (pseudo-labeling) and using the unlabeled data for various consistency-based regularization. In this work, we propose to explicitly leverage the structure of the data manifold based on a Manifold Graph constructed over the image instances within the feature space. Specifically, we propose an architecture based on graph networks that jointly optimizes feature extraction, graph connectivity, and feature propagation and aggregation to unlabeled data in an end-to-end manner. Further, we present a novel Prototype Generator for producing a diverse set of prototypes that compactly represent each category, which supports feature propagation. To evaluate our method, we first contribute a strong baseline that combines two consistency-based regularizers that already achieves state-of-the-art results especially with fewer labels. We then show that when combined with these regularizers, the proposed method facilitates the propagation of information from generated prototypes to image data to further improve results. We provide extensive qualitative and quantitative experimental results on semi-supervised benchmarks demonstrating the improvements arising from our design and show that our method achieves state-of-the-art performance when compared with existing methods using a single model and comparable with ensemble methods. Specifically, we achieve error rates of 3.35% on SVHN, 8.27% on CIFAR-10, and 33.83% on CIFAR-100. With much fewer labels, we surpass the state of the arts by significant margins of 41% relative error decrease on average.