 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis
Mar 22, 2019

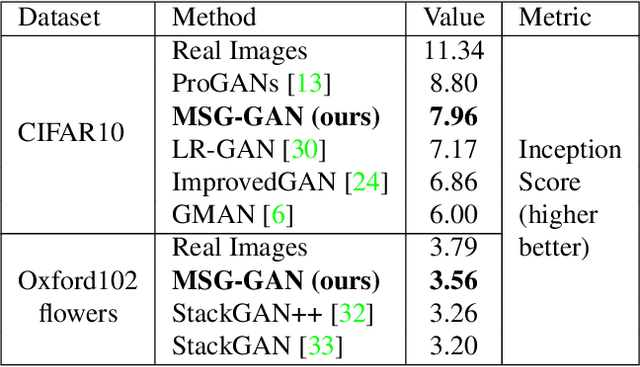
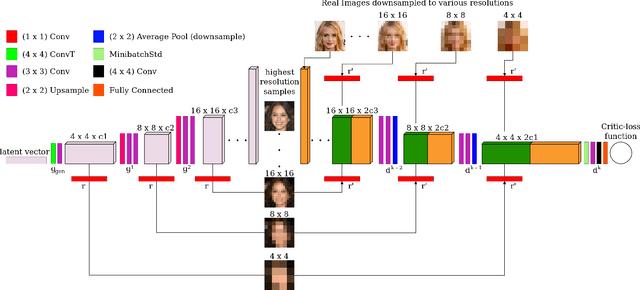

While Generative Adversarial Networks (GANs) have seen huge successes in image synthesis tasks, they are notoriously difficult to use, in part due to instability during training. One commonly accepted reason for this instability is that gradients passing from the discriminator to the generator can quickly become uninformative, due to a learning imbalance during training. In this work, we propose the Multi-Scale Gradient Generative Adversarial Network (MSG-GAN), a simple but effective technique for addressing this problem which allows the flow of gradients from the discriminator to the generator at multiple scales. This technique provides a stable approach for generating synchronized multi-scale images. We present a very intuitive implementation of the mathematical MSG-GAN framework which uses the concatenation operation in the discriminator computations. We empirically validate the effect of our MSG-GAN approach through experiments on the CIFAR10 and Oxford102 flowers datasets and compare it with other relevant techniques which perform multi-scale image synthesis. In addition, we also provide details of our experiment on CelebA-HQ dataset for synthesizing 1024 x 1024 high resolution images.
Dual-Path Convolutional Image-Text Embedding with Instance Loss
Jul 17, 2018



Matching images and sentences demands a fine understanding of both modalities. In this paper, we propose a new system to discriminatively embed the image and text to a shared visual-textual space. In this field, most existing works apply the ranking loss to pull the positive image / text pairs close and push the negative pairs apart from each other. However, directly deploying the ranking loss is hard for network learning, since it starts from the two heterogeneous features to build inter-modal relationship. To address this problem, we propose the instance loss which explicitly considers the intra-modal data distribution. It is based on an unsupervised assumption that each image / text group can be viewed as a class. So the network can learn the fine granularity from every image/text group. The experiment shows that the instance loss offers better weight initialization for the ranking loss, so that more discriminative embeddings can be learned. Besides, existing works usually apply the off-the-shelf features, i.e., word2vec and fixed visual feature. So in a minor contribution, this paper constructs an end-to-end dual-path convolutional network to learn the image and text representations. End-to-end learning allows the system to directly learn from the data and fully utilize the supervision. On two generic retrieval datasets (Flickr30k and MSCOCO), experiments demonstrate that our method yields competitive accuracy compared to state-of-the-art methods. Moreover, in language based person retrieval, we improve the state of the art by a large margin. The code has been made publicly available.
Noise Estimation for Generative Diffusion Models
Apr 06, 2021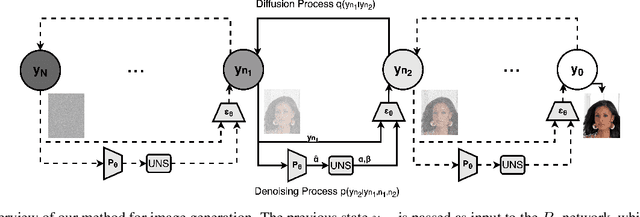
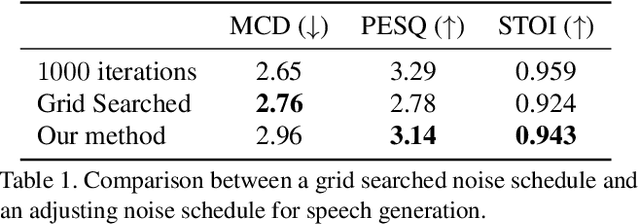
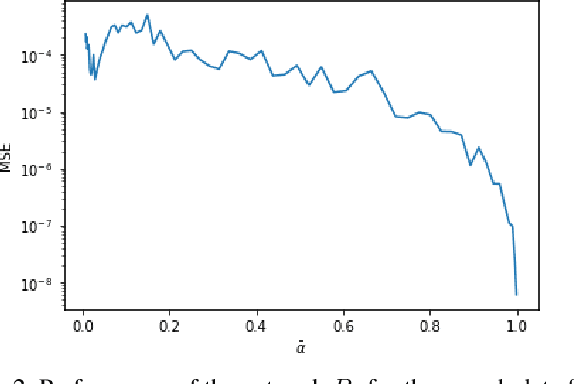

Generative diffusion models have emerged as leading models in speech and image generation. However, in order to perform well with a small number of denoising steps, a costly tuning of the set of noise parameters is needed. In this work, we present a simple and versatile learning scheme that can step-by-step adjust those noise parameters, for any given number of steps, while the previous work needs to retune for each number separately. Furthermore, without modifying the weights of the diffusion model, we are able to significantly improve the synthesis results, for a small number of steps. Our approach comes at a negligible computation cost.
Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks
Jun 06, 2021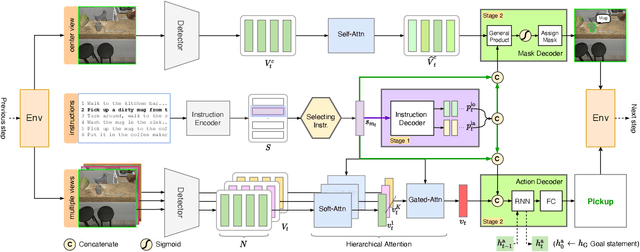
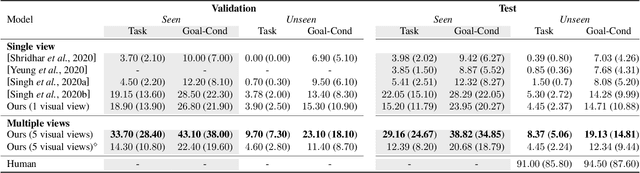
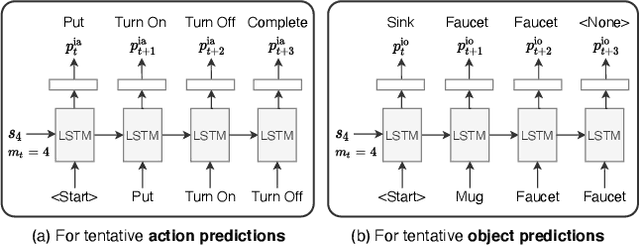
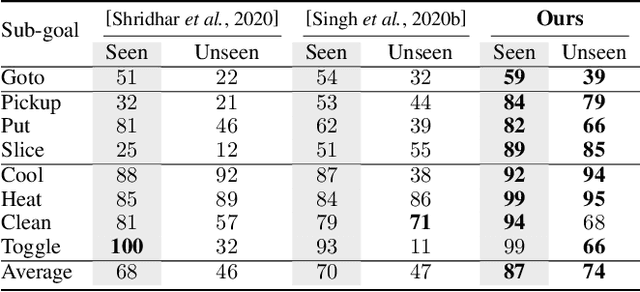
There is a growing interest in the community in making an embodied AI agent perform a complicated task while interacting with an environment following natural language directives. Recent studies have tackled the problem using ALFRED, a well-designed dataset for the task, but achieved only very low accuracy. This paper proposes a new method, which outperforms the previous methods by a large margin. It is based on a combination of several new ideas. One is a two-stage interpretation of the provided instructions. The method first selects and interprets an instruction without using visual information, yielding a tentative action sequence prediction. It then integrates the prediction with the visual information etc., yielding the final prediction of an action and an object. As the object's class to interact is identified in the first stage, it can accurately select the correct object from the input image. Moreover, our method considers multiple egocentric views of the environment and extracts essential information by applying hierarchical attention conditioned on the current instruction. This contributes to the accurate prediction of actions for navigation. A preliminary version of the method won the ALFRED Challenge 2020. The current version achieves the unseen environment's success rate of 4.45% with a single view, which is further improved to 8.37% with multiple views.
3D Convolution Neural Network based Person Identification using Gait cycles
Jun 06, 2021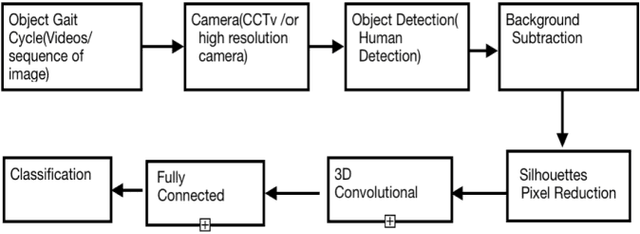

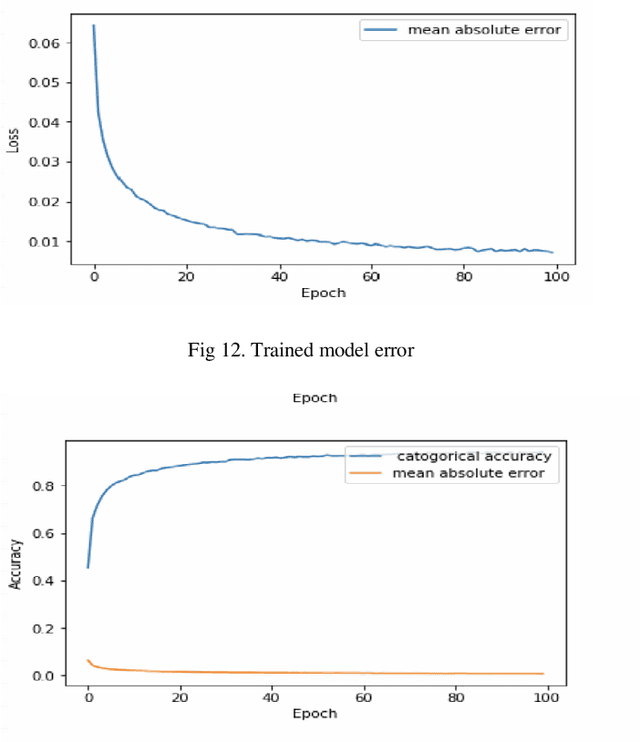
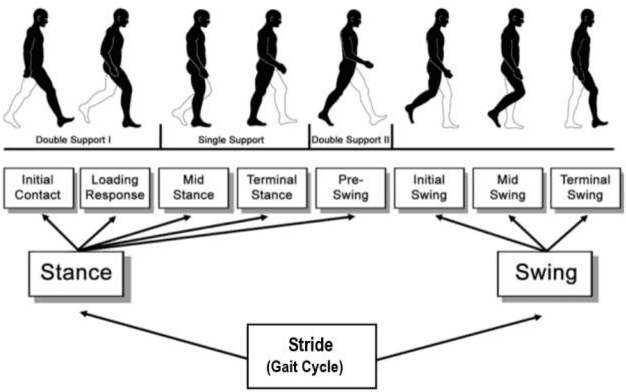
Human identification plays a prominent role in terms of security. In modern times security is becoming the key term for an individual or a country, especially for countries which are facing internal or external threats. Gait analysis is interpreted as the systematic study of the locomotive in humans. It can be used to extract the exact walking features of individuals. Walking features depends on biological as well as the physical feature of the object; hence, it is unique to every individual. In this work, gait features are used to identify an individual. The steps involve object detection, background subtraction, silhouettes extraction, skeletonization, and training 3D Convolution Neural Network on these gait features. The model is trained and evaluated on the dataset acquired by CASIA B Gait, which consists of 15000 videos of 124 subjects walking pattern captured from 11 different angles carrying objects such as bag and coat. The proposed method focuses more on the lower body part to extract features such as the angle between knee and thighs, hip angle, angle of contact, and many other features. The experimental results are compared with amongst accuracies of silhouettes as datasets for training and skeletonized image as training data. The results show that extracting the information from skeletonized data yields improved accuracy.
Do We Really Need Scene-specific Pose Encoders?
Dec 22, 2020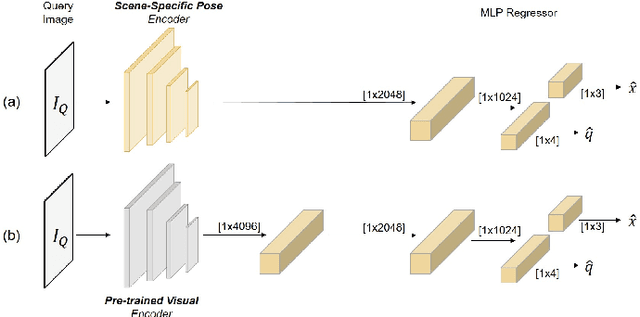
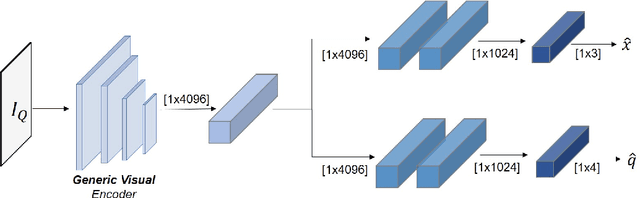
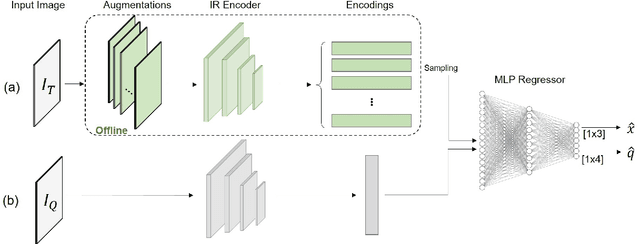
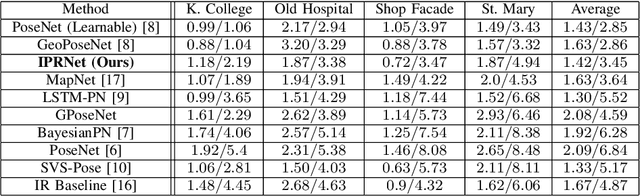
Visual pose regression models estimate the camera pose from a query image with a single forward pass. Current models learn pose encoding from an image using deep convolutional networks which are trained per scene. The resulting encoding is typically passed to a multi-layer perceptron in order to regress the pose. In this work, we propose that scene-specific pose encoders are not required for pose regression and that encodings trained for visual similarity can be used instead. In order to test our hypothesis, we take a shallow architecture of several fully connected layers and train it with pre-computed encodings from a generic image retrieval model. We find that these encodings are not only sufficient to regress the camera pose, but that, when provided to a branching fully connected architecture, a trained model can achieve competitive results and even surpass current \textit{state-of-the-art} pose regressors in some cases. Moreover, we show that for outdoor localization, the proposed architecture is the only pose regressor, to date, consistently localizing in under 2 meters and 5 degrees.
Automated lung segmentation from CT images of normal and COVID-19 pneumonia patients
Apr 05, 2021
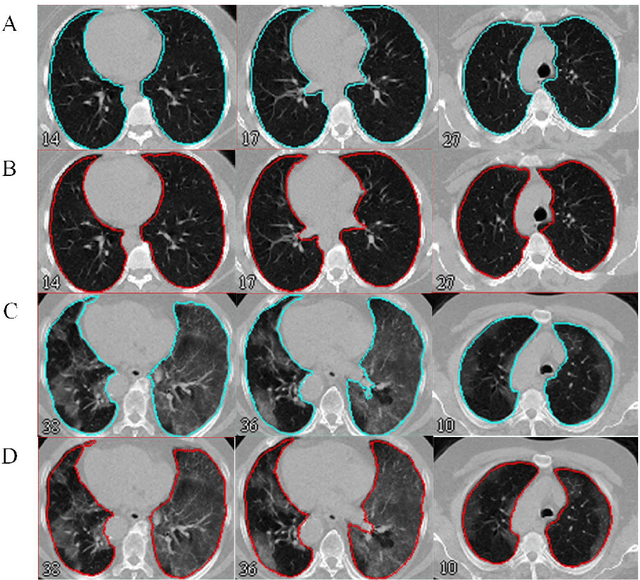
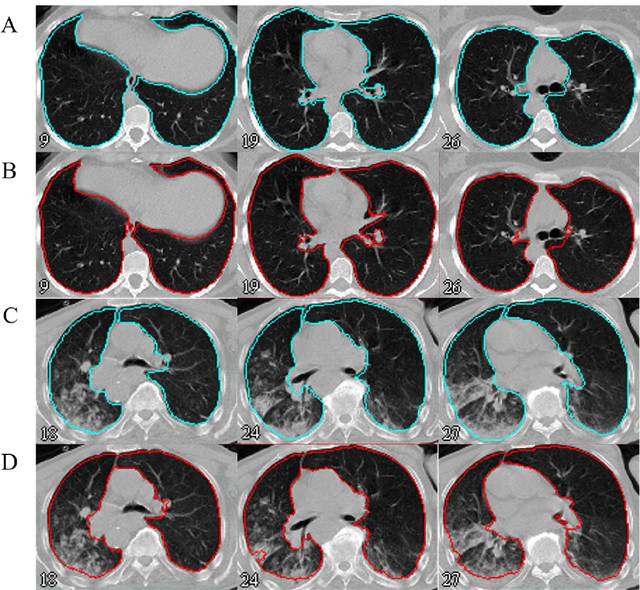
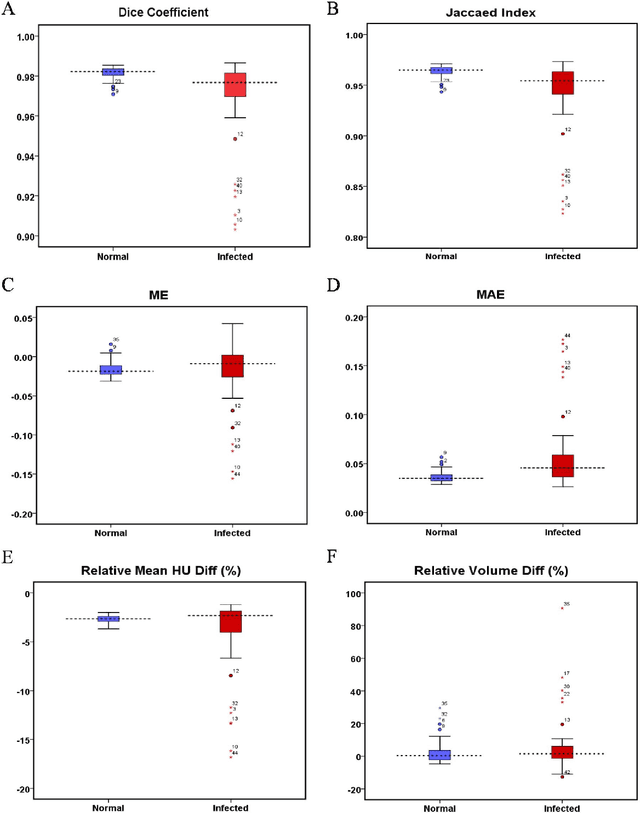
Automated semantic image segmentation is an essential step in quantitative image analysis and disease diagnosis. This study investigates the performance of a deep learning-based model for lung segmentation from CT images for normal and COVID-19 patients. Chest CT images and corresponding lung masks of 1200 confirmed COVID-19 cases were used for training a residual neural network. The reference lung masks were generated through semi-automated/manual segmentation of the CT images. The performance of the model was evaluated on two distinct external test datasets including 120 normal and COVID-19 subjects, and the results of these groups were compared to each other. Different evaluation metrics such as dice coefficient (DSC), mean absolute error (MAE), relative mean HU difference, and relative volume difference were calculated to assess the accuracy of the predicted lung masks. The proposed deep learning method achieved DSC of 0.980 and 0.971 for normal and COVID-19 subjects, respectively, demonstrating significant overlap between predicted and reference lung masks. Moreover, MAEs of 0.037 HU and 0.061 HU, relative mean HU difference of -2.679% and -4.403%, and relative volume difference of 2.405% and 5.928% were obtained for normal and COVID-19 subjects, respectively. The comparable performance in lung segmentation of the normal and COVID-19 patients indicates the accuracy of the model for the identification of the lung tissue in the presence of the COVID-19 induced infections (though slightly better performance was observed for normal patients). The promising results achieved by the proposed deep learning-based model demonstrated its reliability in COVID-19 lung segmentation. This prerequisite step would lead to a more efficient and robust pneumonia lesion analysis.
Human Pose Transfer by Adaptive Hierarchical Deformation
Dec 13, 2020Human pose transfer, as a misaligned image generation task, is very challenging. Existing methods cannot effectively utilize the input information, which often fail to preserve the style and shape of hair and clothes. In this paper, we propose an adaptive human pose transfer network with two hierarchical deformation levels. The first level generates human semantic parsing aligned with the target pose, and the second level generates the final textured person image in the target pose with the semantic guidance. To avoid the drawback of vanilla convolution that treats all the pixels as valid information, we use gated convolution in both two levels to dynamically select the important features and adaptively deform the image layer by layer. Our model has very few parameters and is fast to converge. Experimental results demonstrate that our model achieves better performance with more consistent hair, face and clothes with fewer parameters than state-of-the-art methods. Furthermore, our method can be applied to clothing texture transfer.
* 13 pages, 10 figures. Code is available at https://github.com/Zhangjinso/PINet_PG
Kernel based low-rank sparse model for single image super-resolution
Sep 27, 2018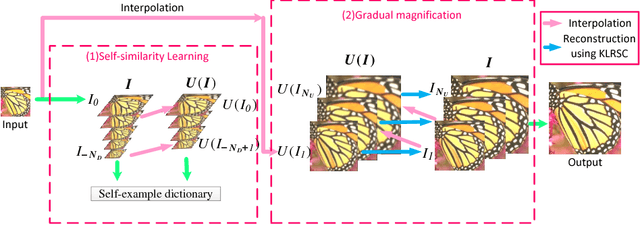
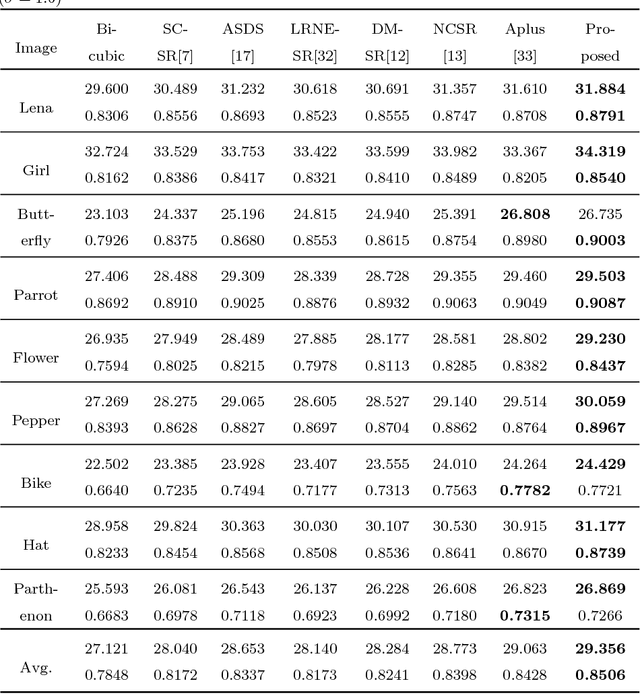
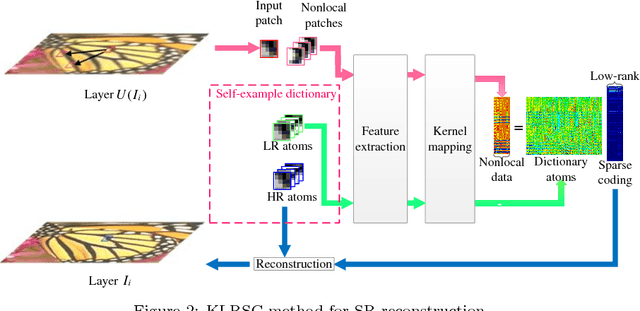
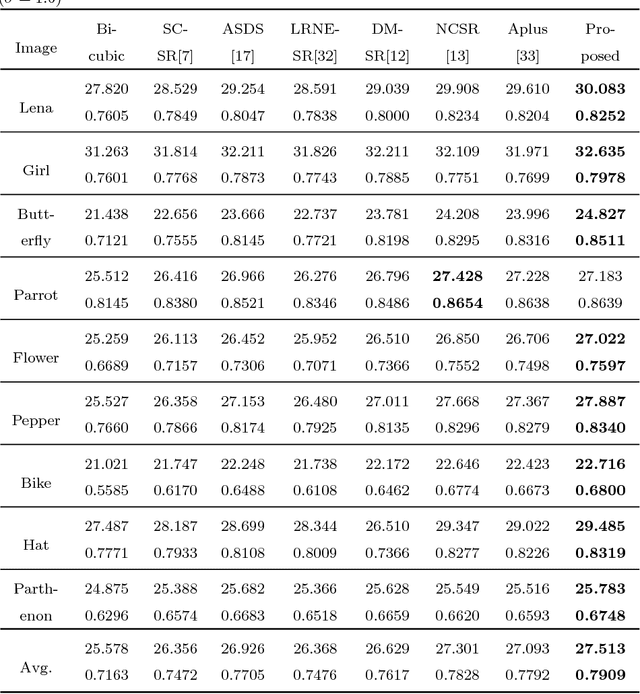
Self-similarity learning has been recognized as a promising method for single image super-resolution (SR) to produce high-resolution (HR) image in recent years. The performance of learning based SR reconstruction, however, highly depends on learned representation coeffcients. Due to the degradation of input image, conventional sparse coding is prone to produce unfaithful representation coeffcients. To this end, we propose a novel kernel based low-rank sparse model with self-similarity learning for single image SR which incorporates nonlocalsimilarity prior to enforce similar patches having similar representation weights. We perform a gradual magnification scheme, using self-examples extracted from the degraded input image and up-scaled versions. To exploit nonlocal-similarity, we concatenate the vectorized input patch and its nonlocal neighbors at different locations into a data matrix which consists of similar components. Then we map the nonlocal data matrix into a high-dimensional feature space by kernel method to capture their nonlinear structures. Under the assumption that the sparse coeffcients for the nonlocal data in the kernel space should be low-rank, we impose low-rank constraint on sparse coding to share similarities among representation coeffcients and remove outliers in order that stable weights for SR reconstruction can be obtained. Experimental results demonstrate the advantage of our proposed method in both visual quality and reconstruction error.
Redesigning the classification layer by randomizing the class representation vectors
Nov 16, 2020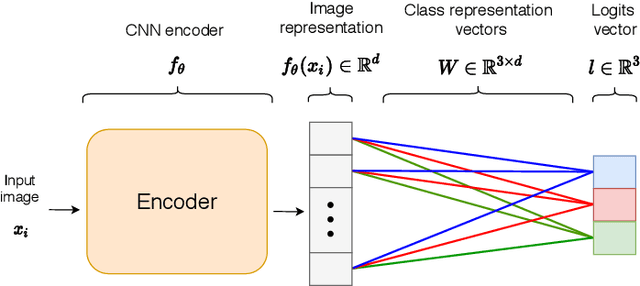
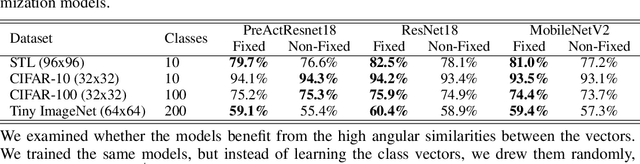
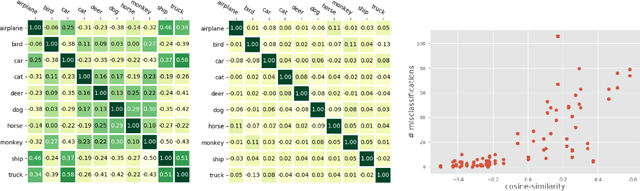
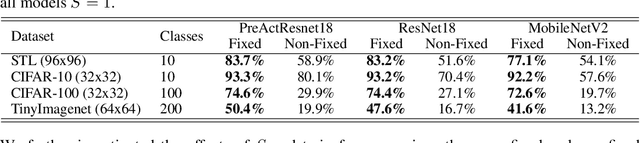
Neural image classification models typically consist of two components. The first is an image encoder, which is responsible for encoding a given raw image into a representative vector. The second is the classification component, which is often implemented by projecting the representative vector onto target class vectors. The target class vectors, along with the rest of the model parameters, are estimated so as to minimize the loss function. In this paper, we analyze how simple design choices for the classification layer affect the learning dynamics. We show that the standard cross-entropy training implicitly captures visual similarities between different classes, which might deteriorate accuracy or even prevents some models from converging. We propose to draw the class vectors randomly and set them as fixed during training, thus invalidating the visual similarities encoded in these vectors. We analyze the effects of keeping the class vectors fixed and show that it can increase the inter-class separability, intra-class compactness, and the overall model accuracy, while maintaining the robustness to image corruptions and the generalization of the learned concepts.