 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Web Table Classification based on Visual Features
Feb 25, 2021
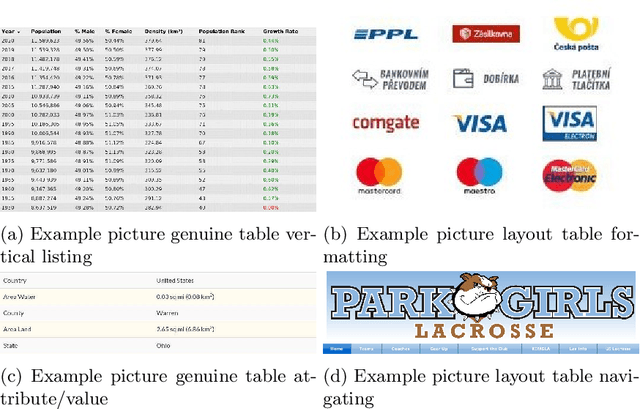
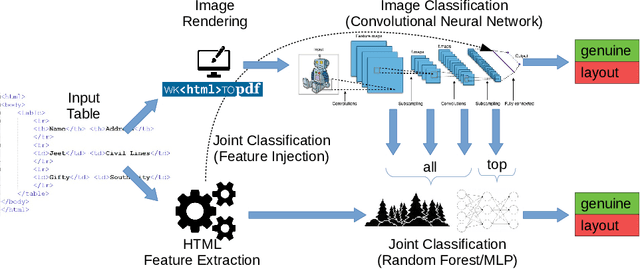
Tables on the web constitute a valuable data source for many applications, like factual search and knowledge base augmentation. However, as genuine tables containing relational knowledge only account for a small proportion of tables on the web, reliable genuine web table classification is a crucial first step of table extraction. Previous works usually rely on explicit feature construction from the HTML code. In contrast, we propose an approach for web table classification by exploiting the full visual appearance of a table, which works purely by applying a convolutional neural network on the rendered image of the web table. Since these visual features can be extracted automatically, our approach circumvents the need for explicit feature construction. A new hand labeled gold standard dataset containing HTML source code and images for 13,112 tables was generated for this task. Transfer learning techniques are applied to well known VGG16 and ResNet50 architectures. The evaluation of CNN image classification with fine tuned ResNet50 (F1 93.29%) shows that this approach achieves results comparable to previous solutions using explicitly defined HTML code based features. By combining visual and explicit features, an F-measure of 93.70% can be achieved by Random Forest classification, which beats current state of the art methods.
SauvolaNet: Learning Adaptive Sauvola Network for Degraded Document Binarization
May 12, 2021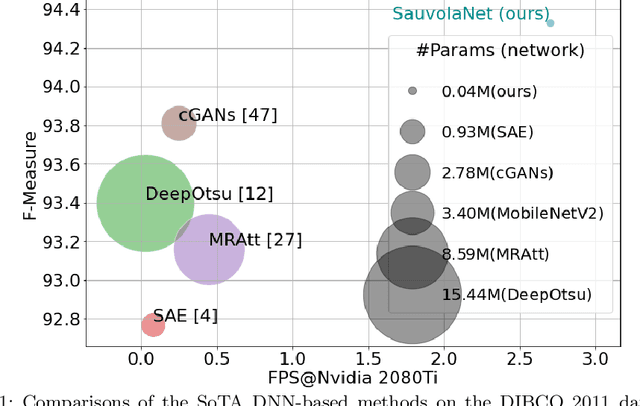

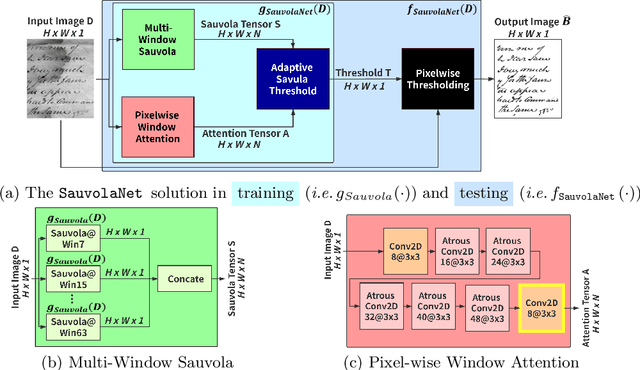
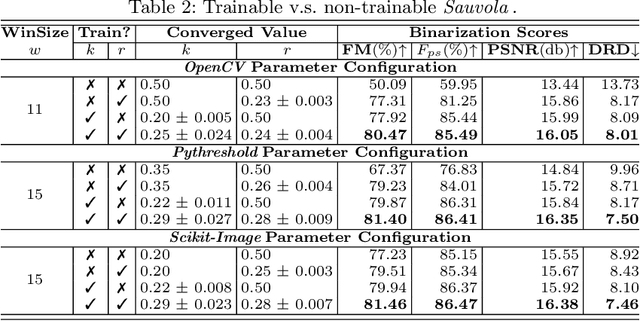
Inspired by the classic Sauvola local image thresholding approach, we systematically study it from the deep neural network (DNN) perspective and propose a new solution called SauvolaNet for degraded document binarization (DDB). It is composed of three explainable modules, namely, Multi-Window Sauvola (MWS), Pixelwise Window Attention (PWA), and Adaptive Sauolva Threshold (AST). The MWS module honestly reflects the classic Sauvola but with trainable parameters and multi-window settings. The PWA module estimates the preferred window sizes for each pixel location. The AST module further consolidates the outputs from MWS and PWA and predicts the final adaptive threshold for each pixel location. As a result, SauvolaNet becomes end-to-end trainable and significantly reduces the number of required network parameters to 40K -- it is only 1\% of MobileNetV2. In the meantime, it achieves the State-of-The-Art (SoTA) performance for the DDB task -- SauvolaNet is at least comparable to, if not better than, SoTA binarization solutions in our extensive studies on the 13 public document binarization datasets. Our source code is available at https://github.com/Leedeng/SauvolaNet.
Seeing past words: Testing the cross-modal capabilities of pretrained V&L models
Dec 22, 2020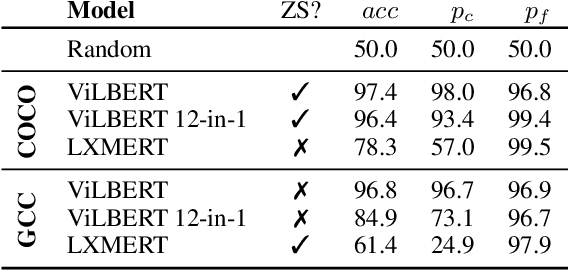

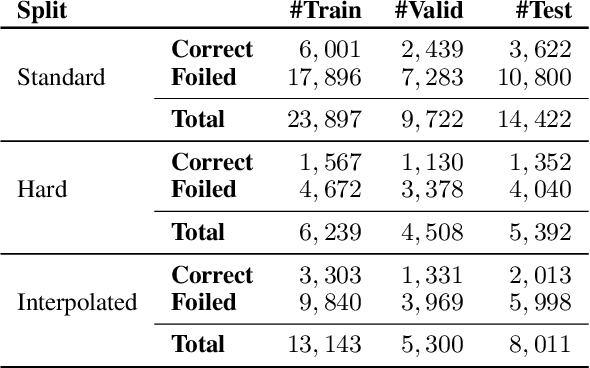
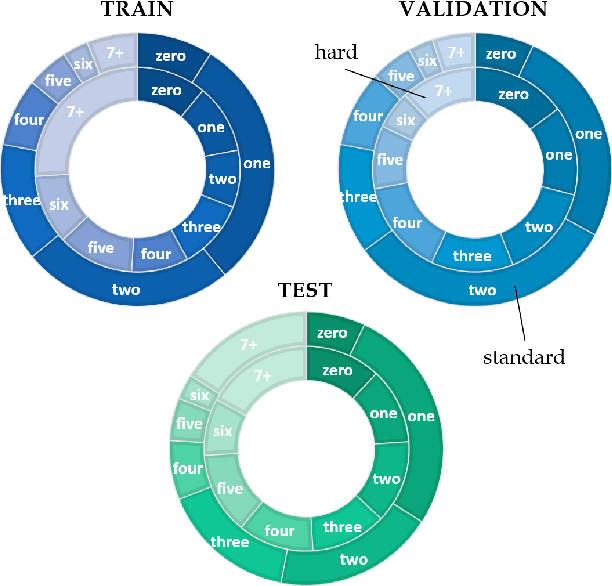
We investigate the ability of general-purpose pretrained vision and language V&L models to perform reasoning in two tasks that require multimodal integration: (1) discriminating a correct image-sentence pair from an incorrect one, and (2) counting entities in an image. We evaluate three pretrained V&L models on these tasks: ViLBERT, ViLBERT 12-in-1 and LXMERT, in zero-shot and finetuned settings. Our results show that models solve task (1) very well, as expected, since all models use task (1) for pretraining. However, none of the pretrained V&L models are able to adequately solve task (2), our counting probe, and they cannot generalise to out-of-distribution quantities. Our investigations suggest that pretrained V&L representations are less successful than expected at integrating the two modalities. We propose a number of explanations for these findings: LXMERT's results on the image-sentence alignment task (and to a lesser extent those obtained by ViLBERT 12-in-1) indicate that the model may exhibit catastrophic forgetting. As for our results on the counting probe, we find evidence that all models are impacted by dataset bias, and also fail to individuate entities in the visual input.
Advanced Hough-based method for on-device document localization
Jun 18, 2021
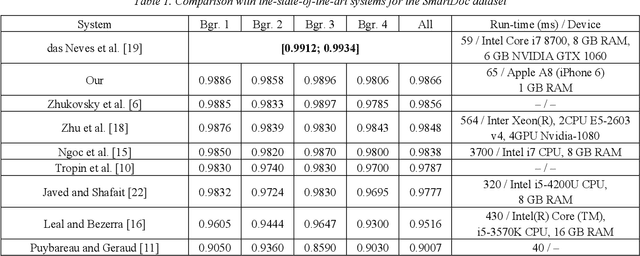
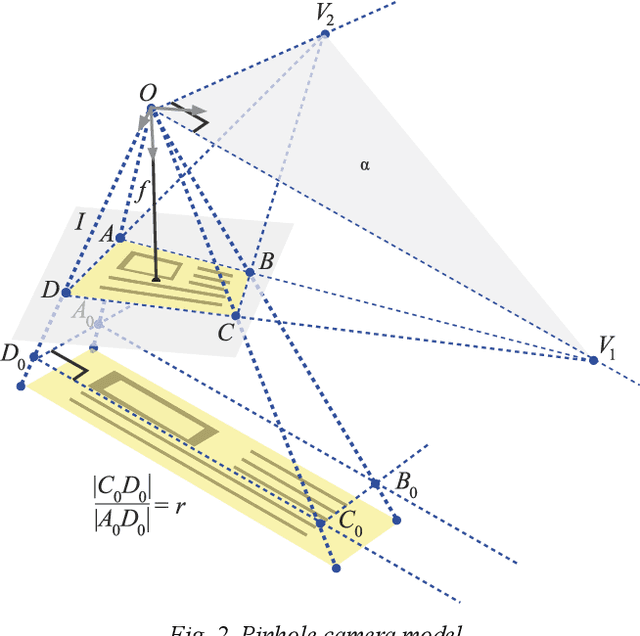

The demand for on-device document recognition systems increases in conjunction with the emergence of more strict privacy and security requirements. In such systems, there is no data transfer from the end device to a third-party information processing servers. The response time is vital to the user experience of on-device document recognition. Combined with the unavailability of discrete GPUs, powerful CPUs, or a large RAM capacity on consumer-grade end devices such as smartphones, the time limitations put significant constraints on the computational complexity of the applied algorithms for on-device execution. In this work, we consider document location in an image without prior knowledge of the document content or its internal structure. In accordance with the published works, at least 5 systems offer solutions for on-device document location. All these systems use a location method which can be considered Hough-based. The precision of such systems seems to be lower than that of the state-of-the-art solutions which were not designed to account for the limited computational resources. We propose an advanced Hough-based method. In contrast with other approaches, it accounts for the geometric invariants of the central projection model and combines both edge and color features for document boundary detection. The proposed method allowed for the second best result for SmartDoc dataset in terms of precision, surpassed by U-net like neural network. When evaluated on a more challenging MIDV-500 dataset, the proposed algorithm guaranteed the best precision compared to published methods. Our method retained the applicability to on-device computations.
Meta Adversarial Training
Jan 27, 2021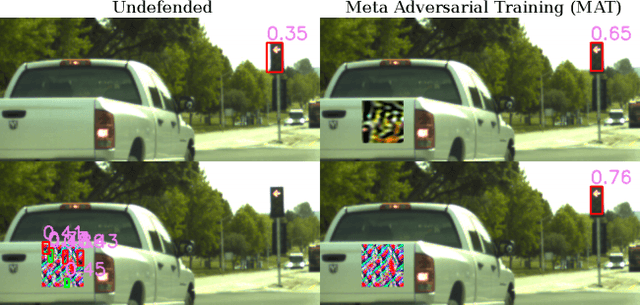
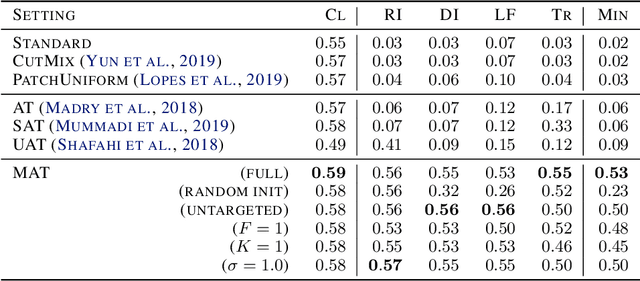
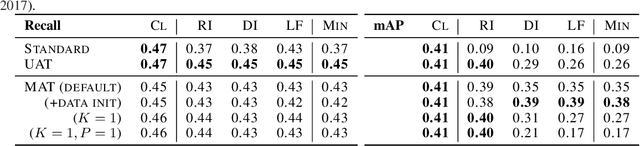
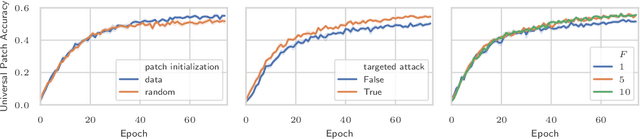
Recently demonstrated physical-world adversarial attacks have exposed vulnerabilities in perception systems that pose severe risks for safety-critical applications such as autonomous driving. These attacks place adversarial artifacts in the physical world that indirectly cause the addition of universal perturbations to inputs of a model that can fool it in a variety of contexts. Adversarial training is the most effective defense against image-dependent adversarial attacks. However, tailoring adversarial training to universal perturbations is computationally expensive since the optimal universal perturbations depend on the model weights which change during training. We propose meta adversarial training (MAT), a novel combination of adversarial training with meta-learning, which overcomes this challenge by meta-learning universal perturbations along with model training. MAT requires little extra computation while continuously adapting a large set of perturbations to the current model. We present results for universal patch and universal perturbation attacks on image classification and traffic-light detection. MAT considerably increases robustness against universal patch attacks compared to prior work.
Deep Learning-based Prediction of Key Performance Indicators for Electrical Machine
Jan 23, 2021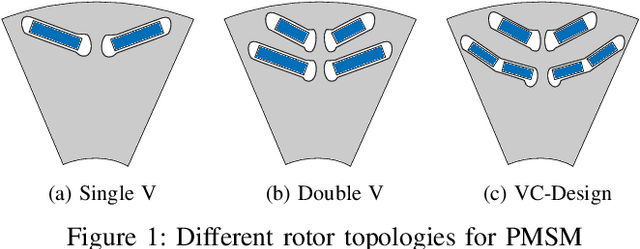
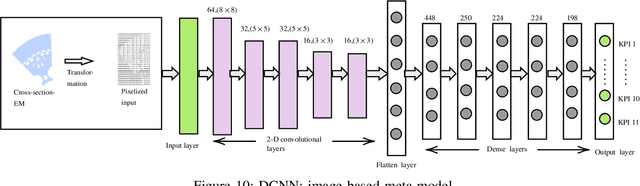
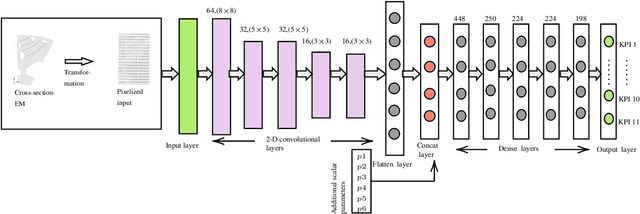
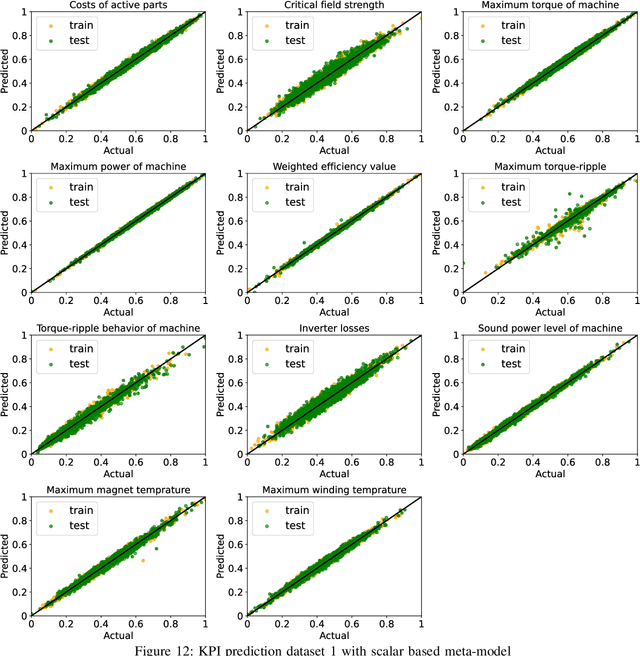
The design of an electrical machine can be quantified and evaluated by Key Performance Indicators (KPIs) such as maximum torque, critical field strength, costs of active parts, sound power, etc. Generally, cross-domain tool-chains are used to optimize all the KPIs from different domains (multi-objective optimization) by varying the given input parameters in the largest possible design space. This optimization process involves magneto-static finite element simulation to obtain these decisive KPIs. It makes the whole process a vehemently time-consuming computational task that counts on the availability of resources with the involvement of high computational cost. In this paper, a data-aided, deep learning-based meta-model is employed to predict the KPIs of an electrical machine quickly and with high accuracy to accelerate the full optimization process and reduce its computational costs. The focus is on analyzing various forms of input data that serve as a geometry representation of the machine. Namely, these are the cross-section image of the electrical machine that allows a very general description of the geometry relating to different topologies and the classical way with scalar parametrization of geometry. The impact of the resolution of the image is studied in detail. The results show a high prediction accuracy and proof that the validity of a deep learning-based meta-model to minimize the optimization time. The results also indicate that the prediction quality of an image-based approach can be made comparable to the classical way based on scalar parameters.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
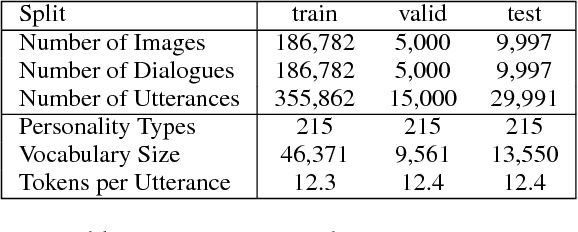
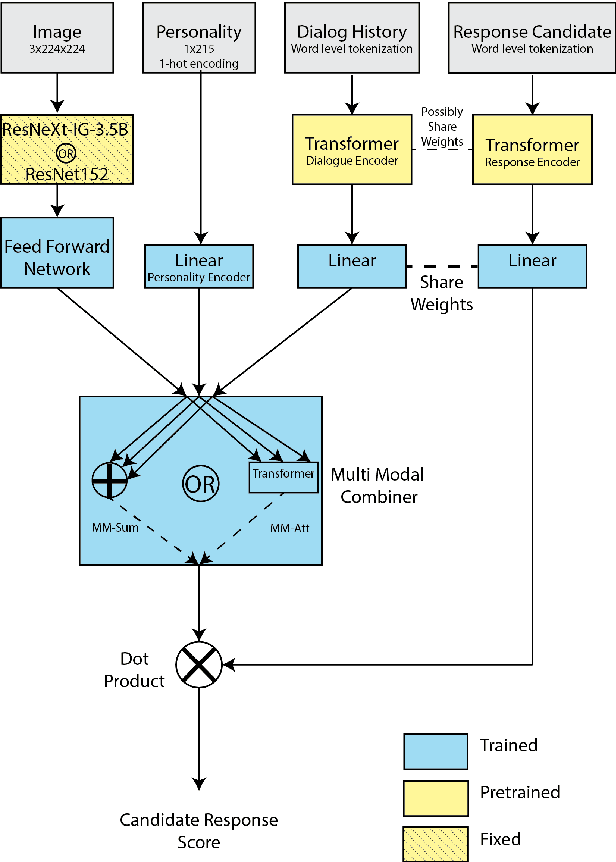

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time
High-Performance FPGA-based Accelerator for Bayesian Neural Networks
May 12, 2021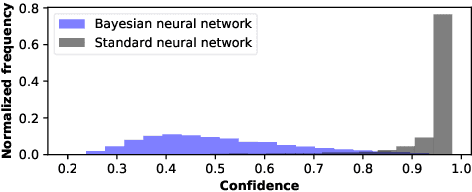
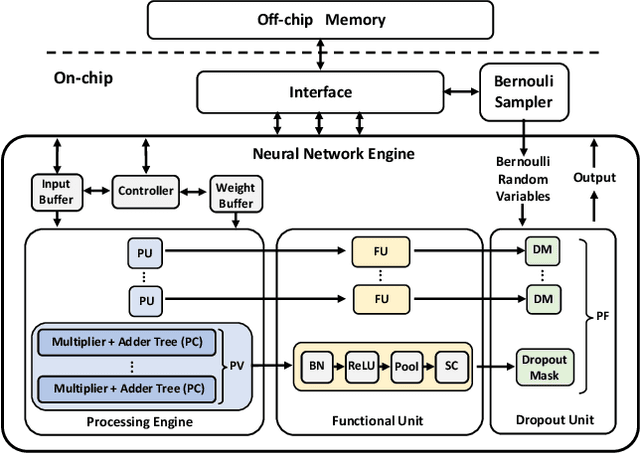
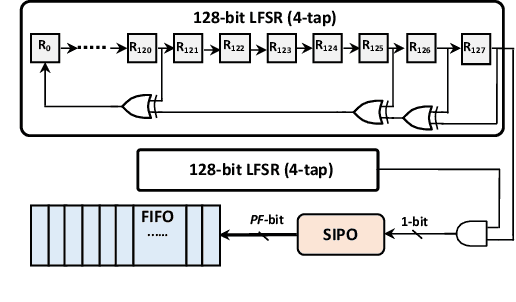
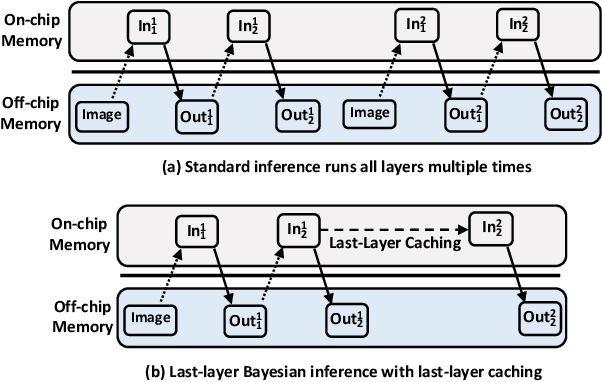
Neural networks (NNs) have demonstrated their potential in a wide range of applications such as image recognition, decision making or recommendation systems. However, standard NNs are unable to capture their model uncertainty which is crucial for many safety-critical applications including healthcare and autonomous vehicles. In comparison, Bayesian neural networks (BNNs) are able to express uncertainty in their prediction via a mathematical grounding. Nevertheless, BNNs have not been as widely used in industrial practice, mainly because of their expensive computational cost and limited hardware performance. This work proposes a novel FPGA-based hardware architecture to accelerate BNNs inferred through Monte Carlo Dropout. Compared with other state-of-the-art BNN accelerators, the proposed accelerator can achieve up to 4 times higher energy efficiency and 9 times better compute efficiency. Considering partial Bayesian inference, an automatic framework is proposed, which explores the trade-off between hardware and algorithmic performance. Extensive experiments are conducted to demonstrate that our proposed framework can effectively find the optimal points in the design space.
Visual-Thermal Camera Dataset Release and Multi-Modal Alignment without Calibration Information
Dec 29, 2020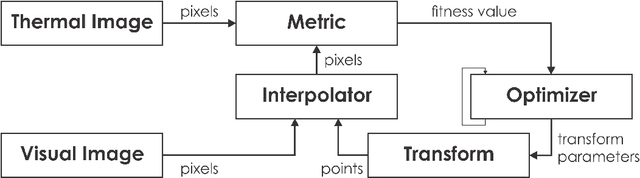

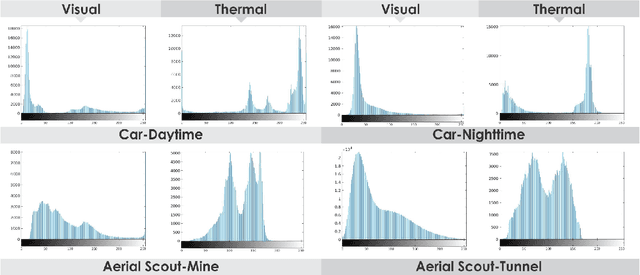

This report accompanies a dataset release on visual and thermal camera data and details a procedure followed to align such multi-modal camera frames in order to provide pixel-level correspondence between the two without using intrinsic or extrinsic calibration information. To achieve this goal we benefit from progress in the domain of multi-modal image alignment and specifically employ the Mattes Mutual Information Metric to guide the registration process. In the released dataset we release both the raw visual and thermal camera data, as well as the aligned frames, alongside calibration parameters with the goal to better facilitate the investigation on common local/global features across such multi-modal image streams.
PlenoptiCam v1.0: A light-field imaging framework
Oct 14, 2020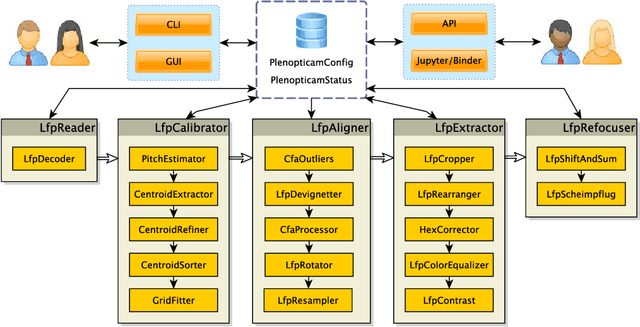
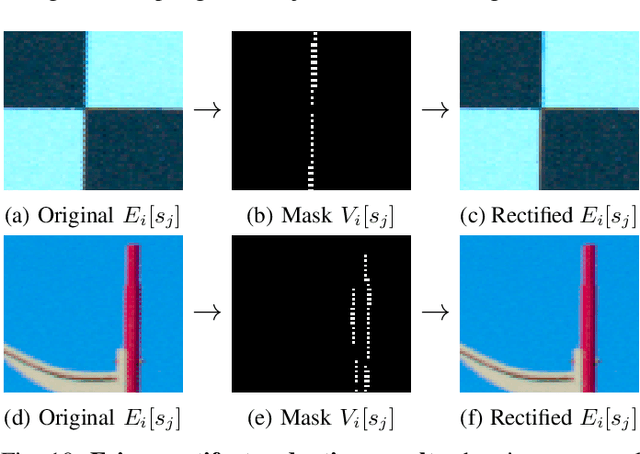


Light-field cameras play a vital role for rich 3-D information retrieval in narrow range depth sensing applications. The key obstacle in composing light-fields from exposures taken by a plenoptic camera is to computationally calibrate, re-align and rearrange four-dimensional image data. Several attempts have been proposed to enhance the overall image quality by tailoring pipelines dedicated to particular plenoptic cameras and improving the color consistency across viewpoints at the expense of high computational loads. The framework presented herein advances prior outcomes thanks to its cost-effective color equalization from parallax-invariant probability distribution transfers and a novel micro image scale-space analysis for generic camera calibration independent of the lens specifications. Our framework compensates for hot-pixels, resampling artifacts, micro image grid rotations just as vignetting in an innovative way to enable superior quality in sub-aperture image extraction, computational refocusing and Scheimpflug rendering with sub-sampling capabilities. Benchmark comparisons using established image metrics suggest that our proposed pipeline outperforms state-of-the-art tool chains in the majority of cases. The software described in this paper is released under an open-source license offering cross-platform compatibility, few dependencies and a lean graphical user interface to make the reproduction of results and the experimentation with plenoptic camera technology convenient for peer researchers, developers, photographers, data scientists and everyone else working in this field.