 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PlenoptiCam v1.0: A light-field imaging framework
Oct 14, 2020
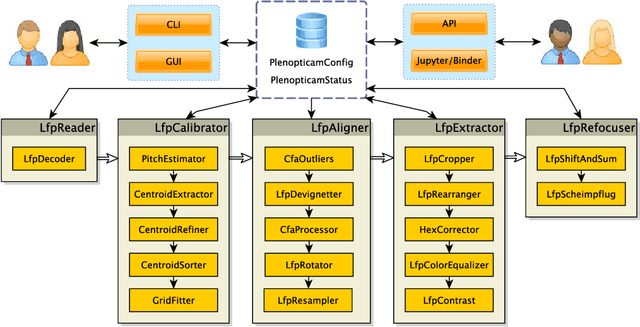
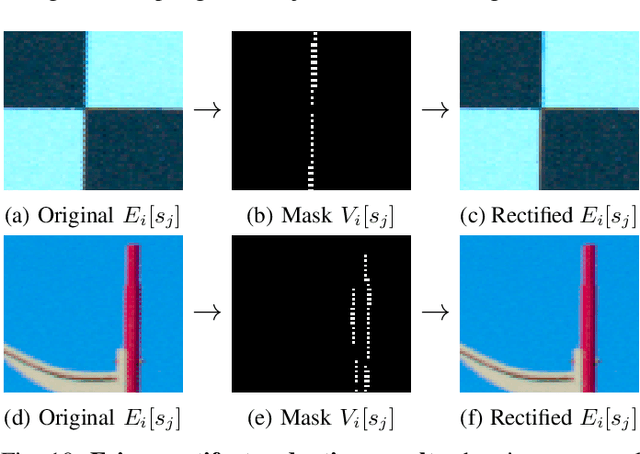


Light-field cameras play a vital role for rich 3-D information retrieval in narrow range depth sensing applications. The key obstacle in composing light-fields from exposures taken by a plenoptic camera is to computationally calibrate, re-align and rearrange four-dimensional image data. Several attempts have been proposed to enhance the overall image quality by tailoring pipelines dedicated to particular plenoptic cameras and improving the color consistency across viewpoints at the expense of high computational loads. The framework presented herein advances prior outcomes thanks to its cost-effective color equalization from parallax-invariant probability distribution transfers and a novel micro image scale-space analysis for generic camera calibration independent of the lens specifications. Our framework compensates for hot-pixels, resampling artifacts, micro image grid rotations just as vignetting in an innovative way to enable superior quality in sub-aperture image extraction, computational refocusing and Scheimpflug rendering with sub-sampling capabilities. Benchmark comparisons using established image metrics suggest that our proposed pipeline outperforms state-of-the-art tool chains in the majority of cases. The software described in this paper is released under an open-source license offering cross-platform compatibility, few dependencies and a lean graphical user interface to make the reproduction of results and the experimentation with plenoptic camera technology convenient for peer researchers, developers, photographers, data scientists and everyone else working in this field.
Learning to Sample the Most Useful Training Patches from Images
Nov 24, 2020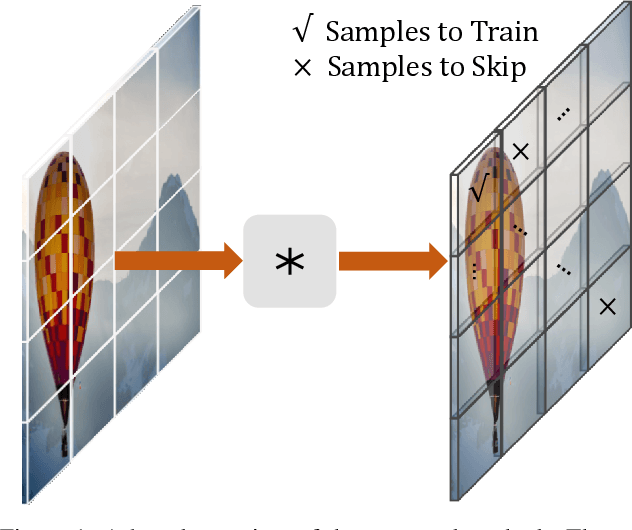


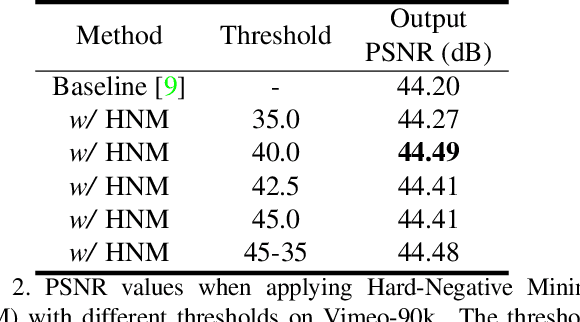
Some image restoration tasks like demosaicing require difficult training samples to learn effective models. Existing methods attempt to address this data training problem by manually collecting a new training dataset that contains adequate hard samples, however, there are still hard and simple areas even within one single image. In this paper, we present a data-driven approach called PatchNet that learns to select the most useful patches from an image to construct a new training set instead of manual or random selection. We show that our simple idea automatically selects informative samples out from a large-scale dataset, leading to a surprising 2.35dB generalisation gain in terms of PSNR. In addition to its remarkable effectiveness, PatchNet is also resource-friendly as it is applied only during training and therefore does not require any additional computational cost during inference.
Rapid AI Development Cycle for the Coronavirus (COVID-19) Pandemic: Initial Results for Automated Detection & Patient Monitoring using Deep Learning CT Image Analysis
Mar 12, 2020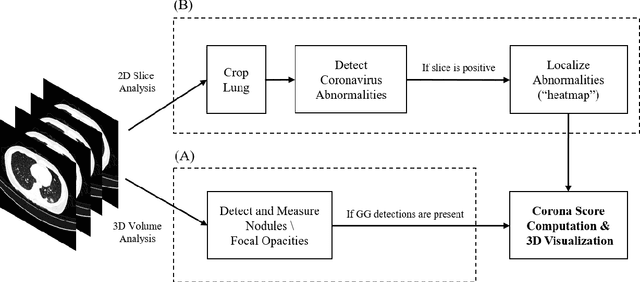
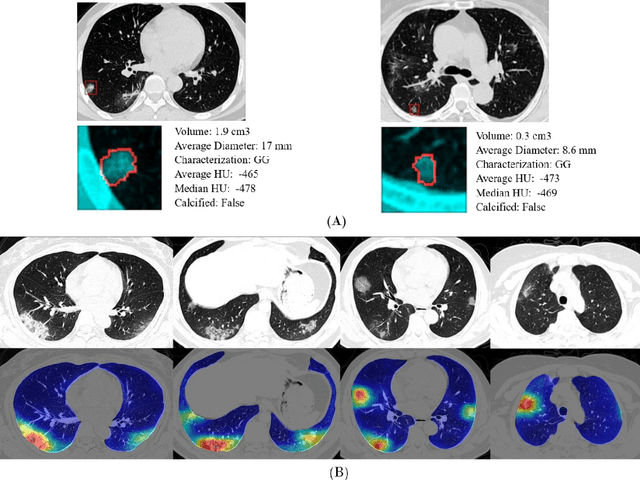
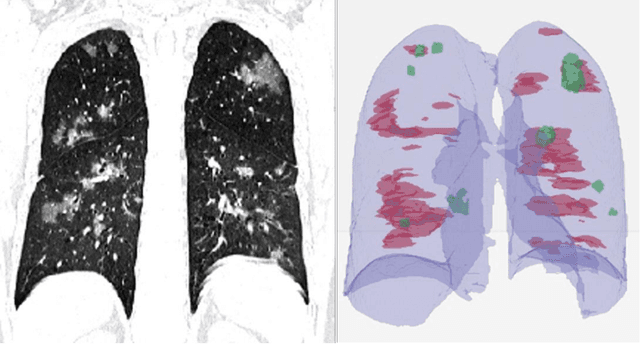
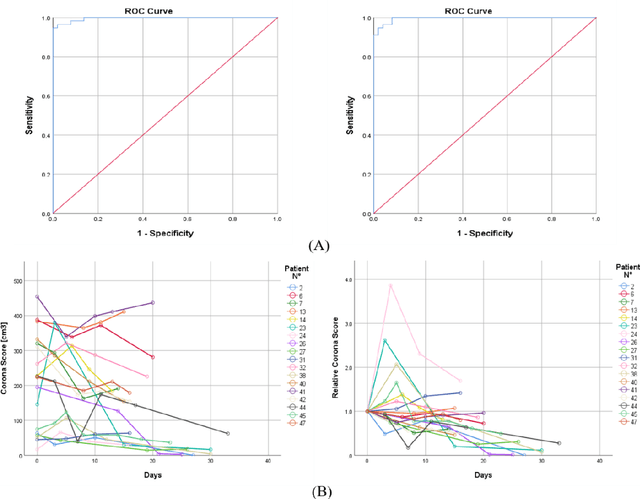
Purpose: Develop AI-based automated CT image analysis tools for detection, quantification, and tracking of Coronavirus; demonstrate they can differentiate coronavirus patients from non-patients. Materials and Methods: Multiple international datasets, including from Chinese disease-infected areas were included. We present a system that utilizes robust 2D and 3D deep learning models, modifying and adapting existing AI models and combining them with clinical understanding. We conducted multiple retrospective experiments to analyze the performance of the system in the detection of suspected COVID-19 thoracic CT features and to evaluate evolution of the disease in each patient over time using a 3D volume review, generating a Corona score. The study includes a testing set of 157 international patients (China and U.S). Results: Classification results for Coronavirus vs Non-coronavirus cases per thoracic CT studies were 0.996 AUC (95%CI: 0.989-1.00) ; on datasets of Chinese control and infected patients. Possible working point: 98.2% sensitivity, 92.2% specificity. For time analysis of Coronavirus patients, the system output enables quantitative measurements for smaller opacities (volume, diameter) and visualization of the larger opacities in a slice-based heat map or a 3D volume display. Our suggested Corona score measures the progression of disease over time. Conclusion: This initial study, which is currently being expanded to a larger population, demonstrated that rapidly developed AI-based image analysis can achieve high accuracy in detection of Coronavirus as well as quantification and tracking of disease burden.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
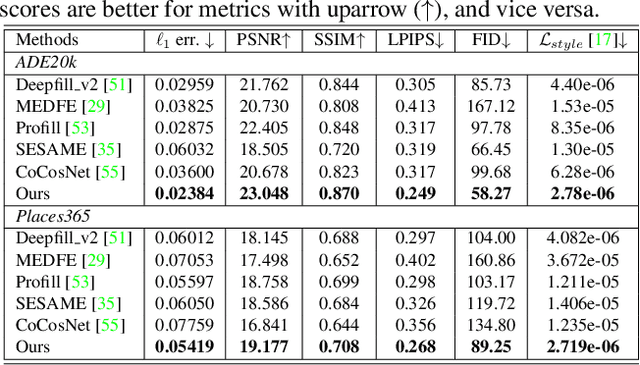
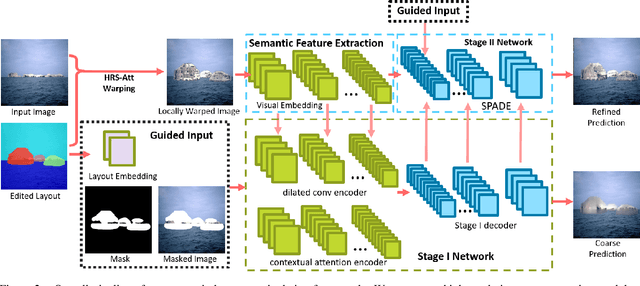
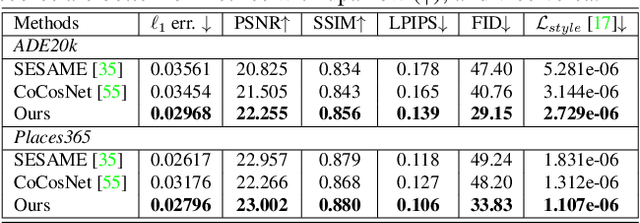
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
VQCPC-GAN: Variable-length Adversarial Audio Synthesis using Vector-Quantized Contrastive Predictive Coding
May 04, 2021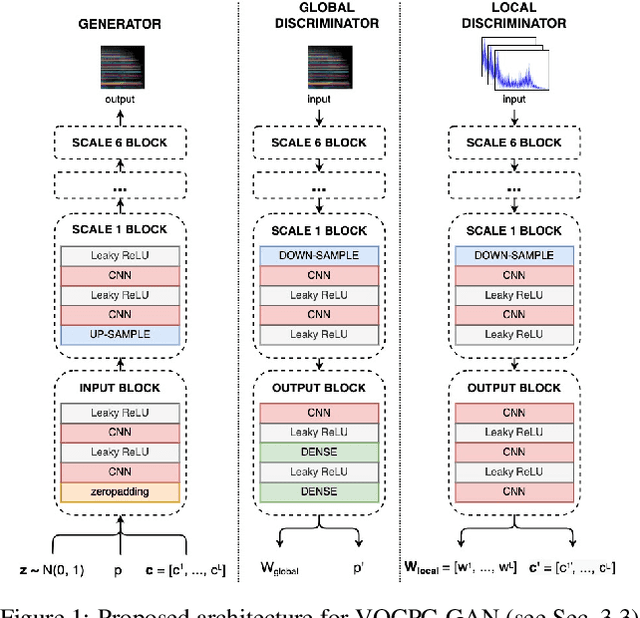
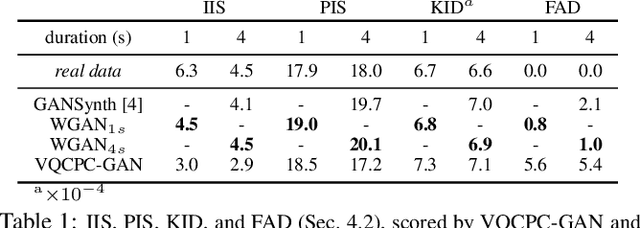
Influenced by the field of Computer Vision, Generative Adversarial Networks (GANs) are often adopted for the audio domain using fixed-size two-dimensional spectrogram representations as the "image data". However, in the (musical) audio domain, it is often desired to generate output of variable duration. This paper presents VQCPC-GAN, an adversarial framework for synthesizing variable-length audio by exploiting Vector-Quantized Contrastive Predictive Coding (VQCPC). A sequence of VQCPC tokens extracted from real audio data serves as conditional input to a GAN architecture, providing step-wise time-dependent features of the generated content. The input noise z (characteristic in adversarial architectures) remains fixed over time, ensuring temporal consistency of global features. We evaluate the proposed model by comparing a diverse set of metrics against various strong baselines. Results show that, even though the baselines score best, VQCPC-GAN achieves comparable performance even when generating variable-length audio. Numerous sound examples are provided in the accompanying website, and we release the code for reproducibility.
Examining and Combating Spurious Features under Distribution Shift
Jun 14, 2021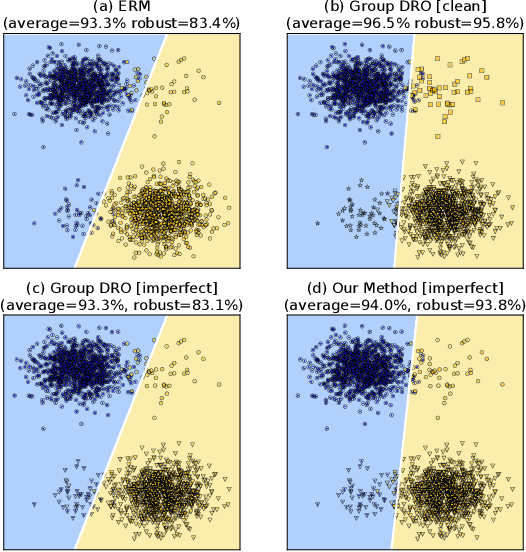

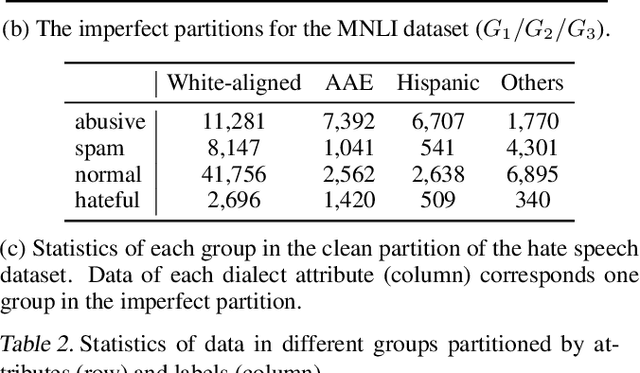
A central goal of machine learning is to learn robust representations that capture the causal relationship between inputs features and output labels. However, minimizing empirical risk over finite or biased datasets often results in models latching on to spurious correlations between the training input/output pairs that are not fundamental to the problem at hand. In this paper, we define and analyze robust and spurious representations using the information-theoretic concept of minimal sufficient statistics. We prove that even when there is only bias of the input distribution (i.e. covariate shift), models can still pick up spurious features from their training data. Group distributionally robust optimization (DRO) provides an effective tool to alleviate covariate shift by minimizing the worst-case training loss over a set of pre-defined groups. Inspired by our analysis, we demonstrate that group DRO can fail when groups do not directly account for various spurious correlations that occur in the data. To address this, we further propose to minimize the worst-case losses over a more flexible set of distributions that are defined on the joint distribution of groups and instances, instead of treating each group as a whole at optimization time. Through extensive experiments on one image and two language tasks, we show that our model is significantly more robust than comparable baselines under various partitions. Our code is available at https://github.com/violet-zct/group-conditional-DRO.
Histo-fetch -- On-the-fly processing of gigapixel whole slide images simplifies and speeds neural network training
Feb 23, 2021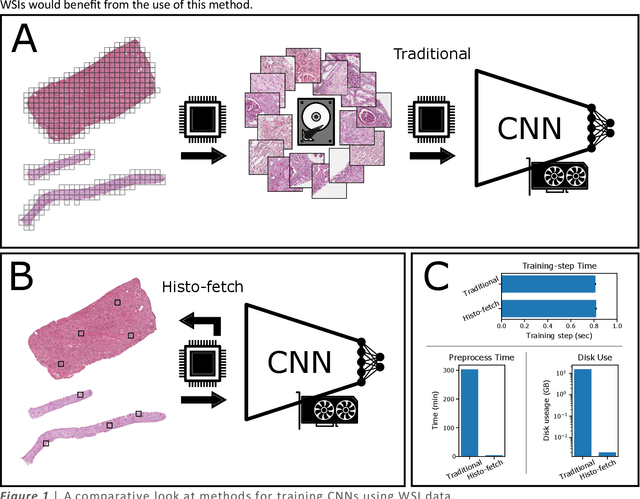
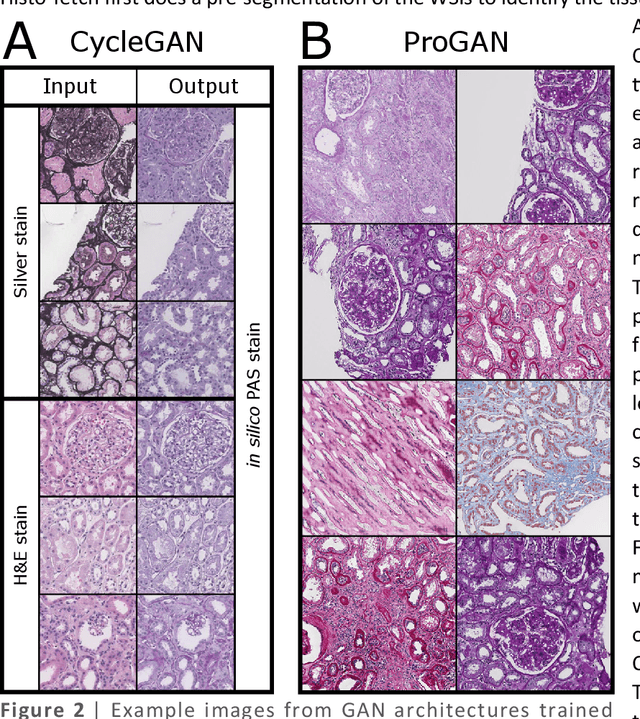
We created a custom pipeline (histo-fetch) to efficiently extract random patches and labels from pathology whole slide images (WSIs) for input to a neural network on-the-fly. We prefetch these patches as needed during network training, avoiding the need for WSI preparation such as chopping/tiling. We demonstrate the utility of this pipeline to perform artificial stain transfer and image generation using the popular networks CycleGAN and ProGAN, respectively.
Constructing a Visual Relationship Authenticity Dataset
Oct 11, 2020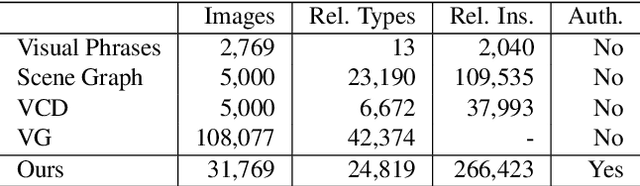

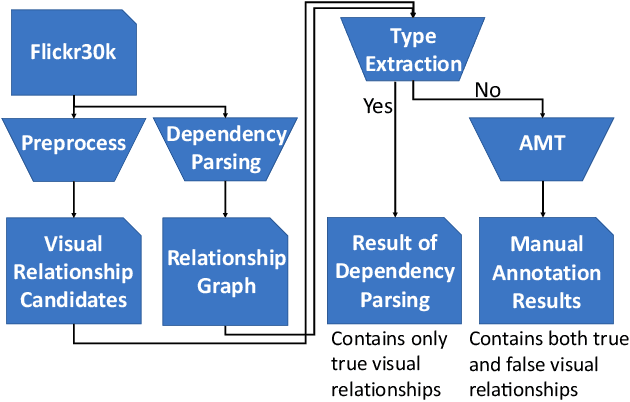
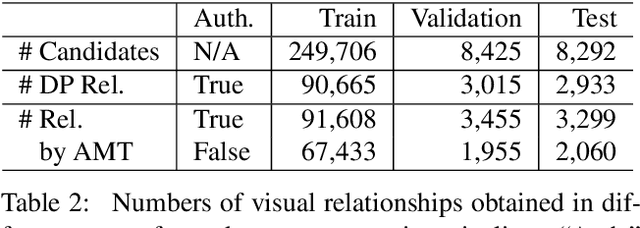
A visual relationship denotes a relationship between two objects in an image, which can be represented as a triplet of (subject; predicate; object). Visual relationship detection is crucial for scene understanding in images. Existing visual relationship detection datasets only contain true relationships that correctly describe the content in an image. However, distinguishing false visual relationships from true ones is also crucial for image understanding and grounded natural language processing. In this paper, we construct a visual relationship authenticity dataset, where both true and false relationships among all objects appeared in the captions in the Flickr30k entities image caption dataset are annotated. The dataset is available at https://github.com/codecreator2053/VR_ClassifiedDataset. We hope that this dataset can promote the study on both vision and language understanding.
DAAIN: Detection of Anomalous and Adversarial Input using Normalizing Flows
May 30, 2021
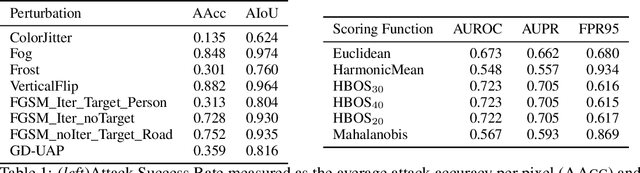
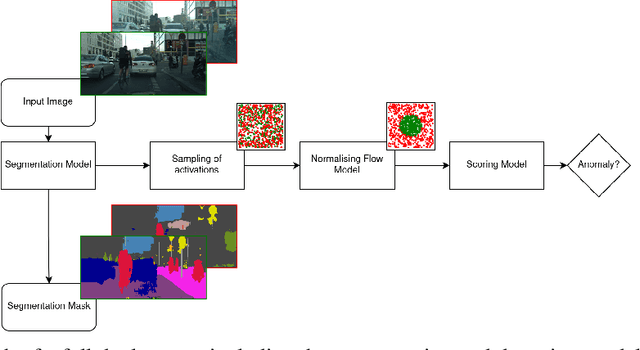
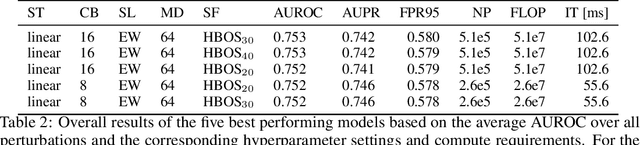
Despite much recent work, detecting out-of-distribution (OOD) inputs and adversarial attacks (AA) for computer vision models remains a challenge. In this work, we introduce a novel technique, DAAIN, to detect OOD inputs and AA for image segmentation in a unified setting. Our approach monitors the inner workings of a neural network and learns a density estimator of the activation distribution. We equip the density estimator with a classification head to discriminate between regular and anomalous inputs. To deal with the high-dimensional activation-space of typical segmentation networks, we subsample them to obtain a homogeneous spatial and layer-wise coverage. The subsampling pattern is chosen once per monitored model and kept fixed for all inputs. Since the attacker has access to neither the detection model nor the sampling key, it becomes harder for them to attack the segmentation network, as the attack cannot be backpropagated through the detector. We demonstrate the effectiveness of our approach using an ESPNet trained on the Cityscapes dataset as segmentation model, an affine Normalizing Flow as density estimator and use blue noise to ensure homogeneous sampling. Our model can be trained on a single GPU making it compute efficient and deployable without requiring specialized accelerators.
Evolutionary Variational Optimization of Generative Models
Dec 22, 2020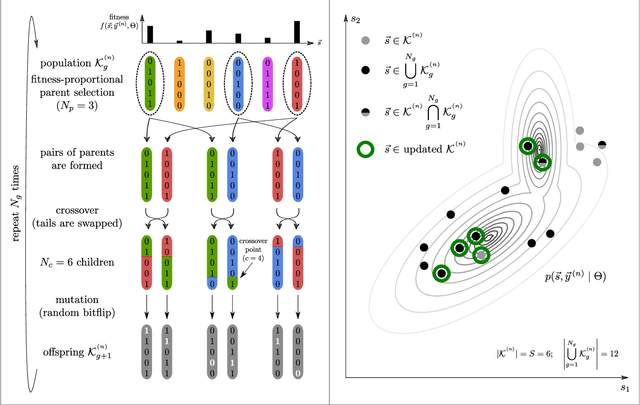
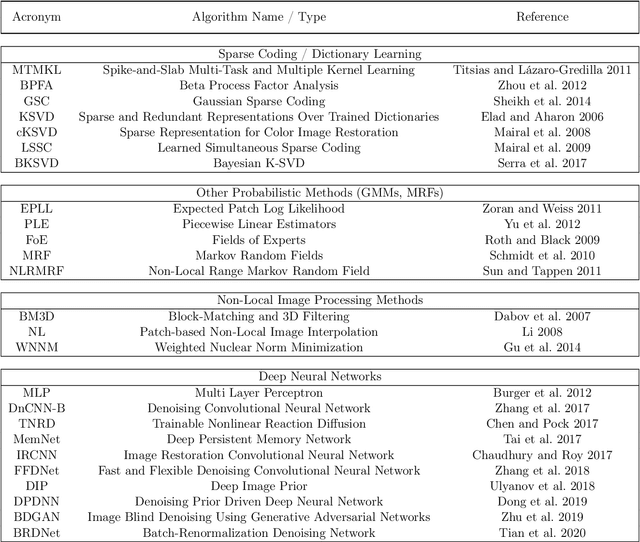
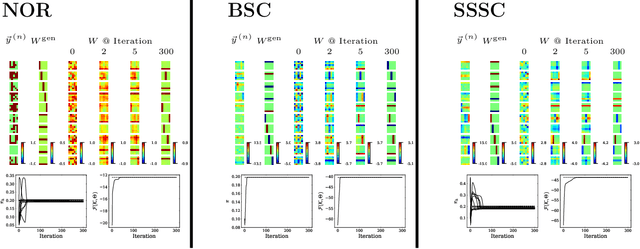
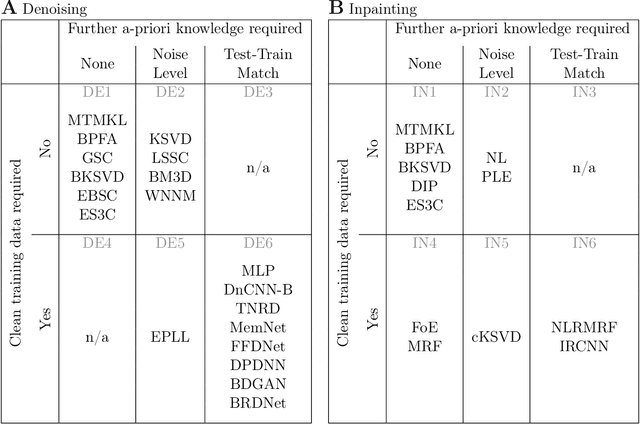
We combine two popular optimization approaches to derive learning algorithms for generative models: variational optimization and evolutionary algorithms. The combination is realized for generative models with discrete latents by using truncated posteriors as the family of variational distributions. The variational parameters of truncated posteriors are sets of latent states. By interpreting these states as genomes of individuals and by using the variational lower bound to define a fitness, we can apply evolutionary algorithms to realize the variational loop. The used variational distributions are very flexible and we show that evolutionary algorithms can effectively and efficiently optimize the variational bound. Furthermore, the variational loop is generally applicable ("black box") with no analytical derivations required. To show general applicability, we apply the approach to three generative models (we use noisy-OR Bayes Nets, Binary Sparse Coding, and Spike-and-Slab Sparse Coding). To demonstrate effectiveness and efficiency of the novel variational approach, we use the standard competitive benchmarks of image denoising and inpainting. The benchmarks allow quantitative comparisons to a wide range of methods including probabilistic approaches, deep deterministic and generative networks, and non-local image processing methods. In the category of "zero-shot" learning (when only the corrupted image is used for training), we observed the evolutionary variational algorithm to significantly improve the state-of-the-art in many benchmark settings. For one well-known inpainting benchmark, we also observed state-of-the-art performance across all categories of algorithms although we only train on the corrupted image. In general, our investigations highlight the importance of research on optimization methods for generative models to achieve performance improvements.