 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EVPropNet: Detecting Drones By Finding Propellers For Mid-Air Landing And Following
Jun 29, 2021
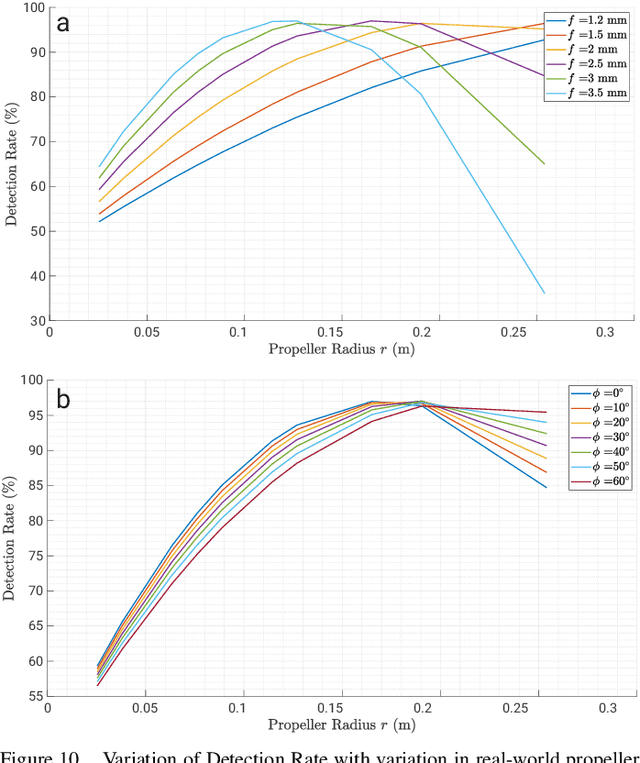
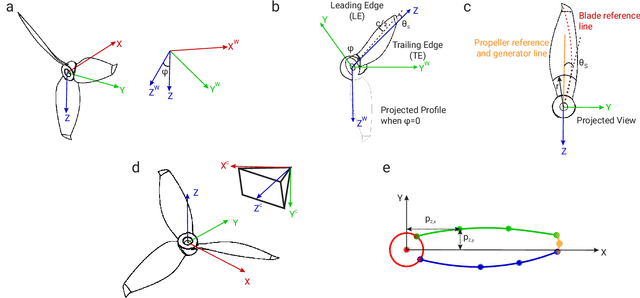
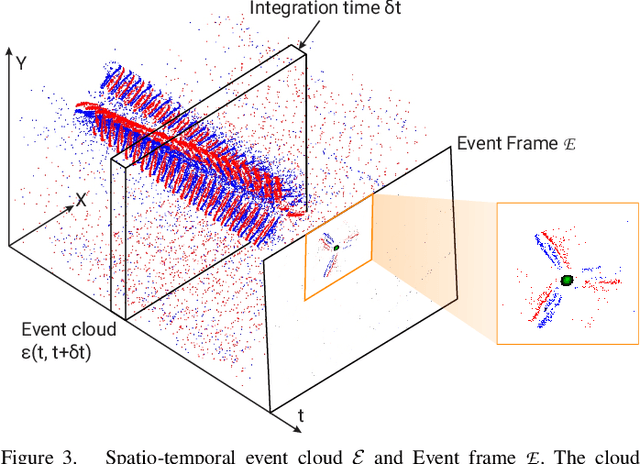
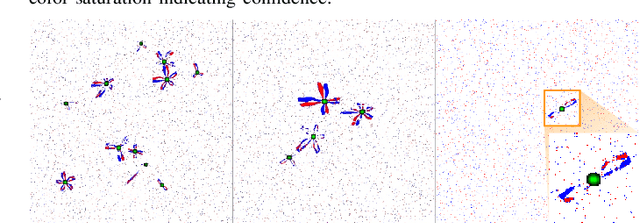
The rapid rise of accessibility of unmanned aerial vehicles or drones pose a threat to general security and confidentiality. Most of the commercially available or custom-built drones are multi-rotors and are comprised of multiple propellers. Since these propellers rotate at a high-speed, they are generally the fastest moving parts of an image and cannot be directly "seen" by a classical camera without severe motion blur. We utilize a class of sensors that are particularly suitable for such scenarios called event cameras, which have a high temporal resolution, low-latency, and high dynamic range. In this paper, we model the geometry of a propeller and use it to generate simulated events which are used to train a deep neural network called EVPropNet to detect propellers from the data of an event camera. EVPropNet directly transfers to the real world without any fine-tuning or retraining. We present two applications of our network: (a) tracking and following an unmarked drone and (b) landing on a near-hover drone. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different propeller shapes and sizes. Our network can detect propellers at a rate of 85.1% even when 60% of the propeller is occluded and can run at upto 35Hz on a 2W power budget. To our knowledge, this is the first deep learning-based solution for detecting propellers (to detect drones). Finally, our applications also show an impressive success rate of 92% and 90% for the tracking and landing tasks respectively.
Supervised Video Summarization via Multiple Feature Sets with Parallel Attention
May 13, 2021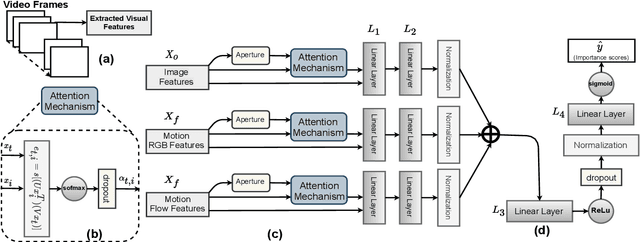
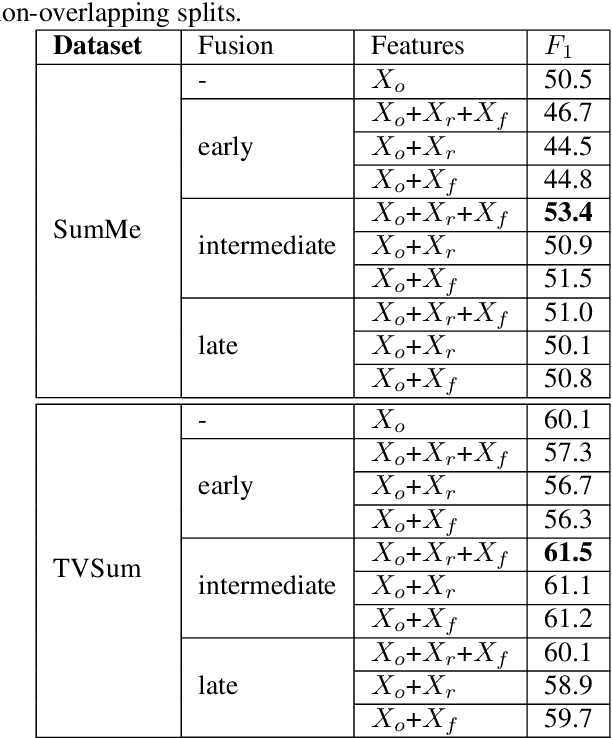
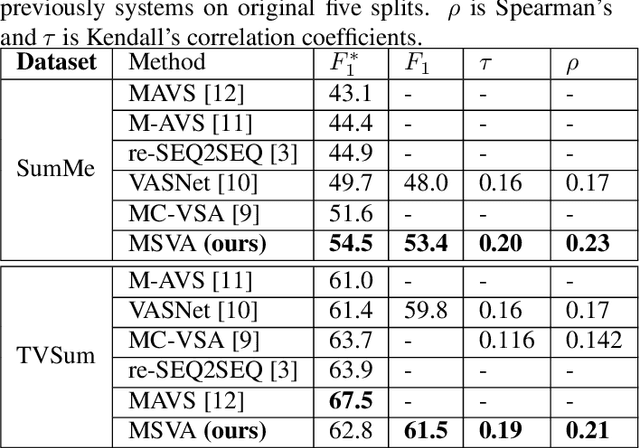
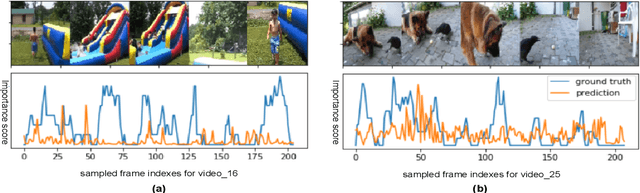
The assignment of importance scores to particular frames or (short) segments in a video is crucial for summarization, but also a difficult task. Previous work utilizes only one source of visual features. In this paper, we suggest a novel model architecture that combines three feature sets for visual content and motion to predict importance scores. The proposed architecture utilizes an attention mechanism before fusing motion features and features representing the (static) visual content, i.e., derived from an image classification model. Comprehensive experimental evaluations are reported for two well-known datasets, SumMe and TVSum. In this context, we identify methodological issues on how previous work used these benchmark datasets, and present a fair evaluation scheme with appropriate data splits that can be used in future work. When using static and motion features with parallel attention mechanism, we improve state-of-the-art results for SumMe, while being on par with the state of the art for the other dataset.
Direct-PoseNet: Absolute Pose Regression with Photometric Consistency
Apr 08, 2021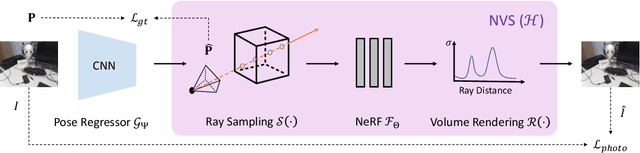
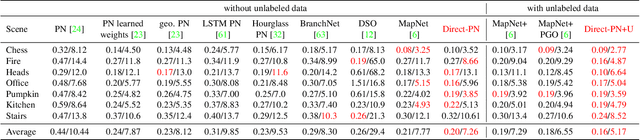
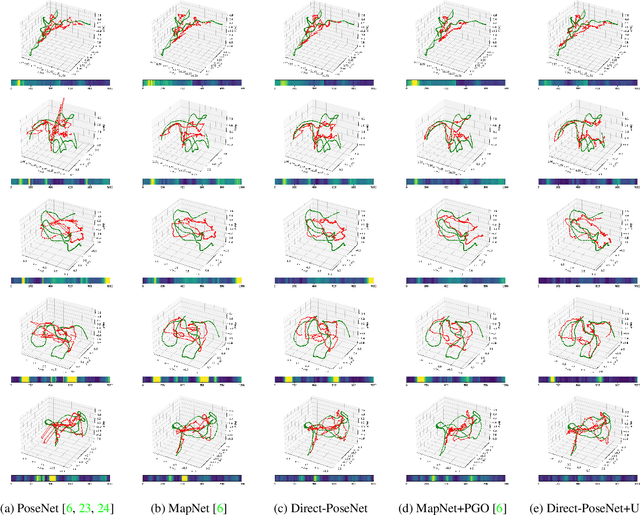
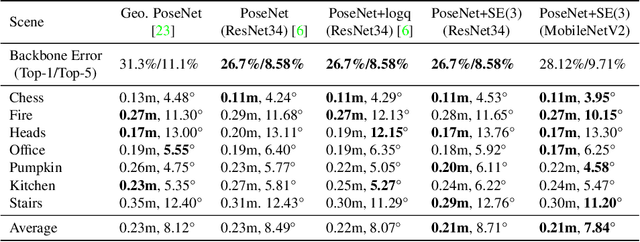
We present a relocalization pipeline, which combines an absolute pose regression (APR) network with a novel view synthesis based direct matching module, offering superior accuracy while maintaining low inference time. Our contribution is twofold: i) we design a direct matching module that supplies a photometric supervision signal to refine the pose regression network via differentiable rendering; ii) we modify the rotation representation from the classical quaternion to SO(3) in pose regression, removing the need for balancing rotation and translation loss terms. As a result, our network Direct-PoseNet achieves state-of-the-art performance among all other single-image APR methods on the 7-Scenes benchmark and the LLFF dataset.
Person Re-Identification with a Locally Aware Transformer
Jun 08, 2021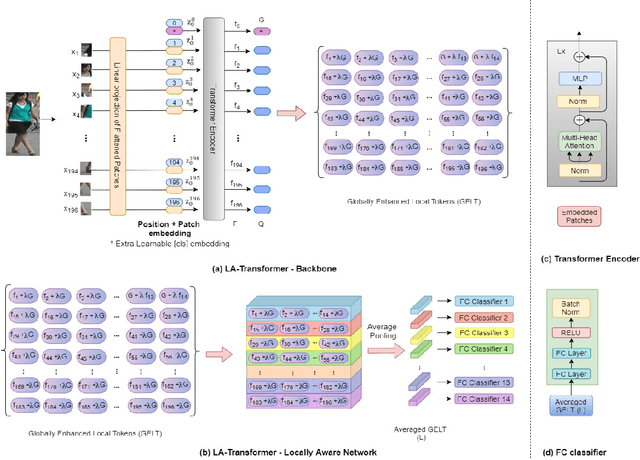
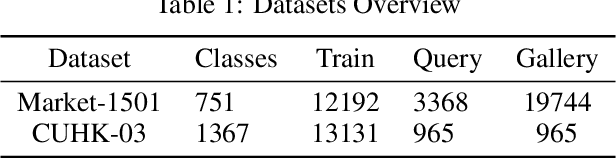
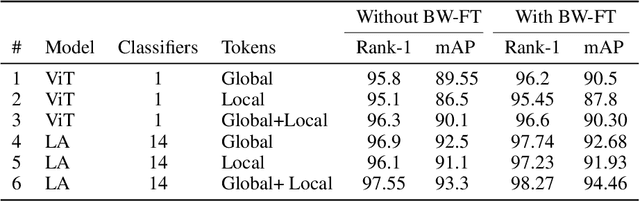
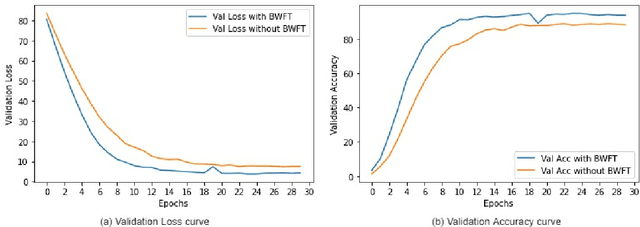
Person Re-Identification is an important problem in computer vision-based surveillance applications, in which the same person is attempted to be identified from surveillance photographs in a variety of nearby zones. At present, the majority of Person re-ID techniques are based on Convolutional Neural Networks (CNNs), but Vision Transformers are beginning to displace pure CNNs for a variety of object recognition tasks. The primary output of a vision transformer is a global classification token, but vision transformers also yield local tokens which contain additional information about local regions of the image. Techniques to make use of these local tokens to improve classification accuracy are an active area of research. We propose a novel Locally Aware Transformer (LA-Transformer) that employs a Parts-based Convolution Baseline (PCB)-inspired strategy for aggregating globally enhanced local classification tokens into an ensemble of $\sqrt{N}$ classifiers, where $N$ is the number of patches. An additional novelty is that we incorporate blockwise fine-tuning which further improves re-ID accuracy. LA-Transformer with blockwise fine-tuning achieves rank-1 accuracy of $98.27 \%$ with standard deviation of $0.13$ on the Market-1501 and $98.7\%$ with standard deviation of $0.2$ on the CUHK03 dataset respectively, outperforming all other state-of-the-art published methods at the time of writing.
Learning from Multiple Noisy Partial Labelers
Jun 08, 2021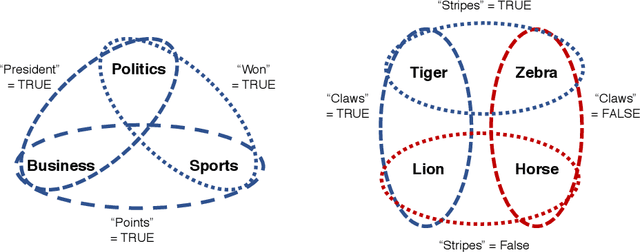
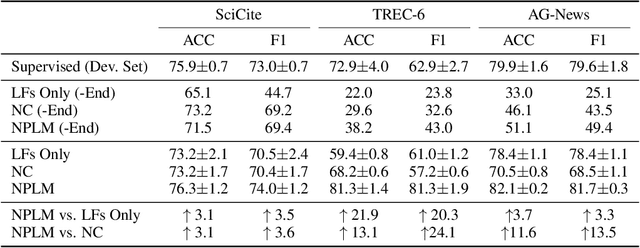
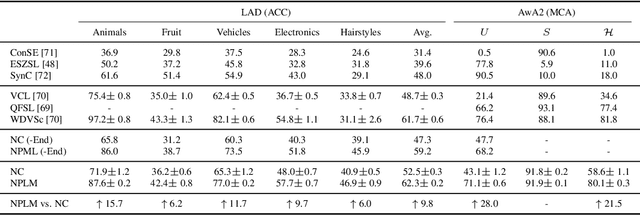
Programmatic weak supervision creates models without hand-labeled training data by combining the outputs of noisy, user-written rules and other heuristic labelers. Existing frameworks make the restrictive assumption that labelers output a single class label. Enabling users to create partial labelers that output subsets of possible class labels would greatly expand the expressivity of programmatic weak supervision. We introduce this capability by defining a probabilistic generative model that can estimate the underlying accuracies of multiple noisy partial labelers without ground truth labels. We prove that this class of models is generically identifiable up to label swapping under mild conditions. We also show how to scale up learning to 100k examples in one minute, a 300X speed up compared to a naive implementation. We evaluate our framework on three text classification and six object classification tasks. On text tasks, adding partial labels increases average accuracy by 9.6 percentage points. On image tasks, we show that partial labels allow us to approach some zero-shot object classification problems with programmatic weak supervision by using class attributes as partial labelers. Our framework is able to achieve accuracy comparable to recent embedding-based zero-shot learning methods using only pre-trained attribute detectors
Watershed of Artificial Intelligence: Human Intelligence, Machine Intelligence, and Biological Intelligence
Apr 27, 2021
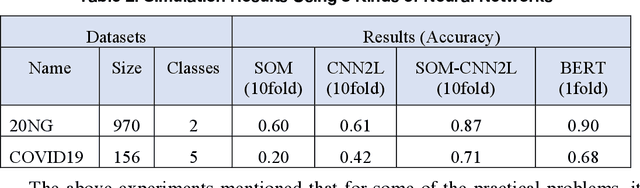
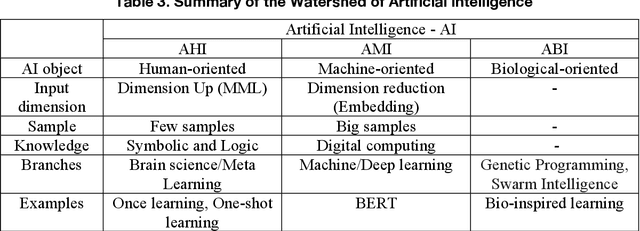
This article reviews the Once Learning mechanism that was proposed 23 years ago and the subsequent successes of One-shot Learning in image classification and You Only Look Once-YOLO in objective detection. Analyzing the current development of AI, the proposal is that AI should be clearly divided into the following categories: Artificial Human Intelligence (AHI), Artificial Machine Intelligence (AMI), and Artificial Biological Intelligence (ABI), which will also be the main directions of theory and application development for AI. As a watershed for the branches of AI, some classification standards and methods are discussed: 1) AI R&D should be human-oriented, machine-oriented, and biological-oriented; 2) The information input is processed by Dimensionality-up or dimensionality-reduction; and 3) One/Few or large samples are used for knowledge learning.
Exploring Robustness of Unsupervised Domain Adaptation in Semantic Segmentation
May 23, 2021
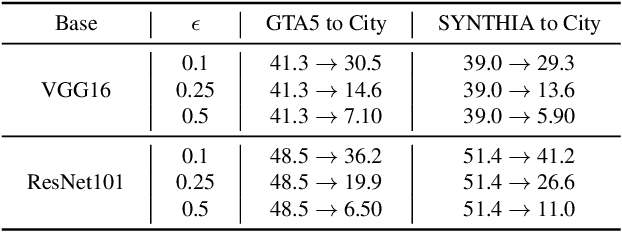
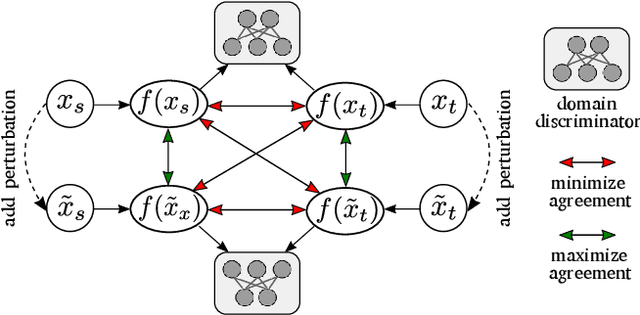
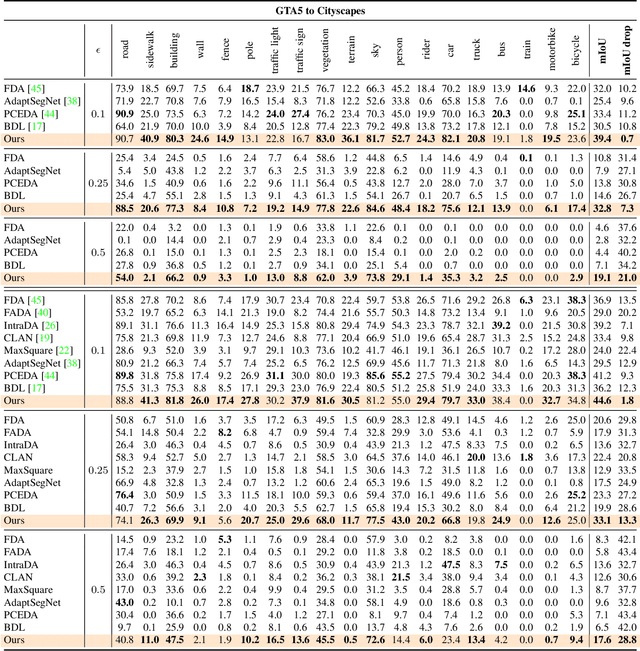
Recent studies imply that deep neural networks are vulnerable to adversarial examples -- inputs with a slight but intentional perturbation are incorrectly classified by the network. Such vulnerability makes it risky for some security-related applications (e.g., semantic segmentation in autonomous cars) and triggers tremendous concerns on the model reliability. For the first time, we comprehensively evaluate the robustness of existing UDA methods and propose a robust UDA approach. It is rooted in two observations: (i) the robustness of UDA methods in semantic segmentation remains unexplored, which pose a security concern in this field; and (ii) although commonly used self-supervision (e.g., rotation and jigsaw) benefits image tasks such as classification and recognition, they fail to provide the critical supervision signals that could learn discriminative representation for segmentation tasks. These observations motivate us to propose adversarial self-supervision UDA (or ASSUDA) that maximizes the agreement between clean images and their adversarial examples by a contrastive loss in the output space. Extensive empirical studies on commonly used benchmarks demonstrate that ASSUDA is resistant to adversarial attacks.
UMLE: Unsupervised Multi-discriminator Network for Low Light Enhancement
Dec 25, 2020


Low-light image enhancement, such as recovering color and texture details from low-light images, is a complex and vital task. For automated driving, low-light scenarios will have serious implications for vision-based applications. To address this problem, we propose a real-time unsupervised generative adversarial network (GAN) containing multiple discriminators, i.e. a multi-scale discriminator, a texture discriminator, and a color discriminator. These distinct discriminators allow the evaluation of images from different perspectives. Further, considering that different channel features contain different information and the illumination is uneven in the image, we propose a feature fusion attention module. This module combines channel attention with pixel attention mechanisms to extract image features. Additionally, to reduce training time, we adopt a shared encoder for the generator and the discriminator. This makes the structure of the model more compact and the training more stable. Experiments indicate that our method is superior to the state-of-the-art methods in qualitative and quantitative evaluations, and significant improvements are achieved for both autopilot positioning and detection results.
Active Generative Adversarial Network for Image Classification
Jun 17, 2019
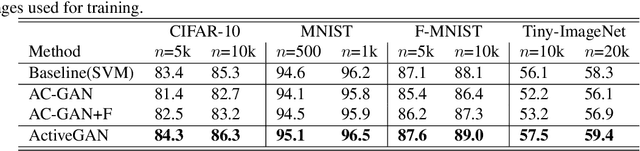
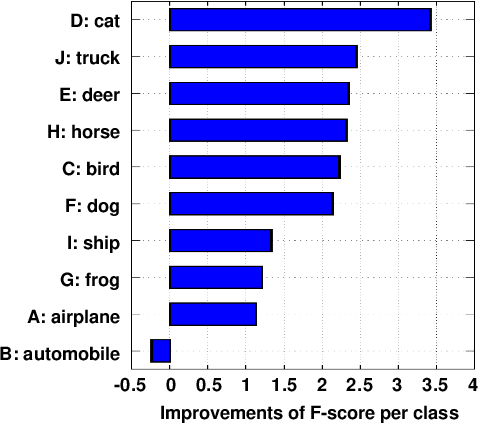

Sufficient supervised information is crucial for any machine learning models to boost performance. However, labeling data is expensive and sometimes difficult to obtain. Active learning is an approach to acquire annotations for data from a human oracle by selecting informative samples with a high probability to enhance performance. In recent emerging studies, a generative adversarial network (GAN) has been integrated with active learning to generate good candidates to be presented to the oracle. In this paper, we propose a novel model that is able to obtain labels for data in a cheaper manner without the need to query an oracle. In the model, a novel reward for each sample is devised to measure the degree of uncertainty, which is obtained from a classifier trained with existing labeled data. This reward is used to guide a conditional GAN to generate informative samples with a higher probability for a certain label. With extensive evaluations, we have confirmed the effectiveness of the model, showing that the generated samples are capable of improving the classification performance in popular image classification tasks.
Adversarial Heart Attack: Neural Networks Fooled to Segment Heart Symbols in Chest X-Ray Images
Apr 07, 2021
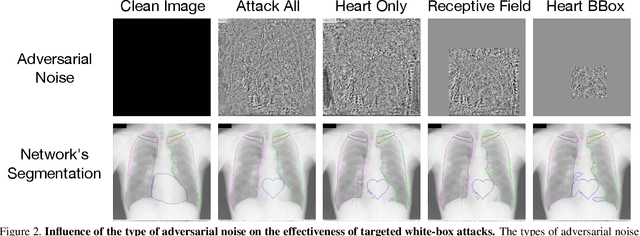
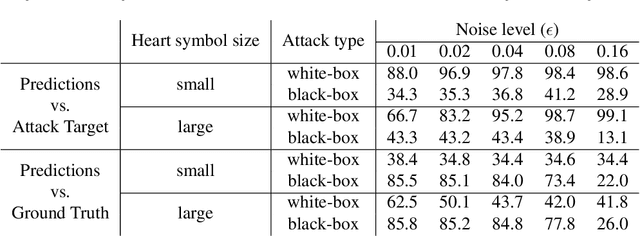
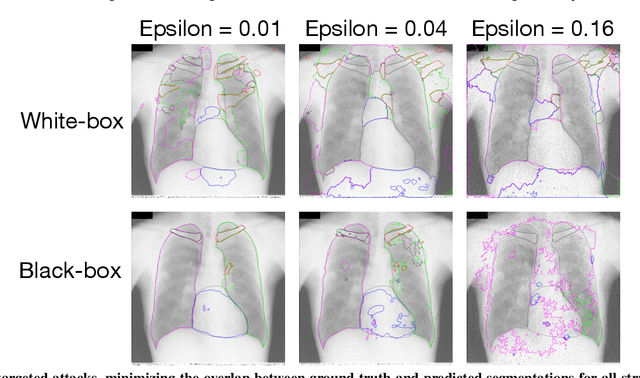
Adversarial attacks consist in maliciously changing the input data to mislead the predictions of automated decision systems and are potentially a serious threat for automated medical image analysis. Previous studies have shown that it is possible to adversarially manipulate automated segmentations produced by neural networks in a targeted manner in the white-box attack setting. In this article, we studied the effectiveness of adversarial attacks in targeted modification of segmentations of anatomical structures in chest X-rays. Firstly, we experimented with using anatomically implausible shapes as targets for adversarial manipulation. We showed that, by adding almost imperceptible noise to the image, we can reliably force state-of-the-art neural networks to segment the heart as a heart symbol instead of its real anatomical shape. Moreover, such heart-shaping attack did not appear to require higher adversarial noise level than an untargeted attack based the same attack method. Secondly, we attempted to explore the limits of adversarial manipulation of segmentations. For that, we assessed the effectiveness of shrinking and enlarging segmentation contours for the three anatomical structures. We observed that adversarially extending segmentations of structures into regions with intensity and texture uncharacteristic for them presented a challenge to our attacks, as well as, in some cases, changing segmentations in ways that conflict with class adjacency priors learned by the target network. Additionally, we evaluated performances of the untargeted attacks and targeted heart attacks in the black-box attack scenario, using a surrogate network trained on a different subset of images. In both cases, the attacks were substantially less effective. We believe these findings bring novel insights into the current capabilities and limits of adversarial attacks for semantic segmentation.