 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
In-game Residential Home Planning via Visual Context-aware Global Relation Learning
Feb 08, 2021
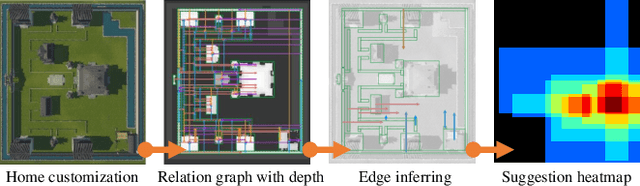
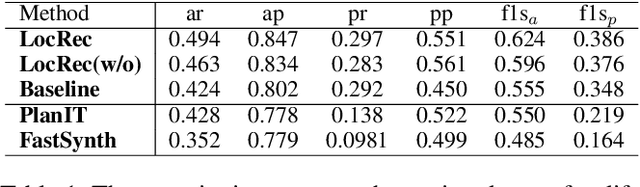
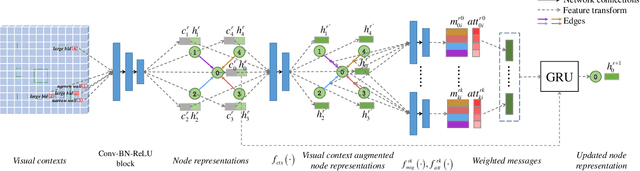
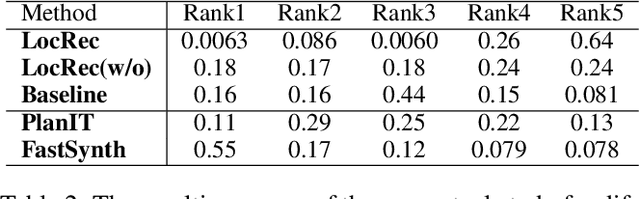
In this paper, we propose an effective global relation learning algorithm to recommend an appropriate location of a building unit for in-game customization of residential home complex. Given a construction layout, we propose a visual context-aware graph generation network that learns the implicit global relations among the scene components and infers the location of a new building unit. The proposed network takes as input the scene graph and the corresponding top-view depth image. It provides the location recommendations for a newly-added building units by learning an auto-regressive edge distribution conditioned on existing scenes. We also introduce a global graph-image matching loss to enhance the awareness of essential geometry semantics of the site. Qualitative and quantitative experiments demonstrate that the recommended location well reflects the implicit spatial rules of components in the residential estates, and it is instructive and practical to locate the building units in the 3D scene of the complex construction.
Algebraic Image Processing
Oct 11, 2017We propose an approach to image processing related to algebraic operators acting in the space of images. In view of the interest in the applications in optics and computer science, mathematical aspects of the paper have been simplified as much as possible. Underlying theory, related to rigged Hilbert spaces and Lie algebras, is discussed elsewhere
OLED: One-Class Learned Encoder-Decoder Network with Adversarial Context Masking for Novelty Detection
Apr 08, 2021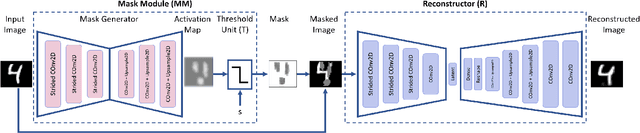
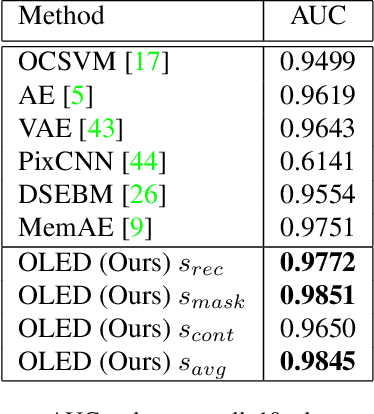

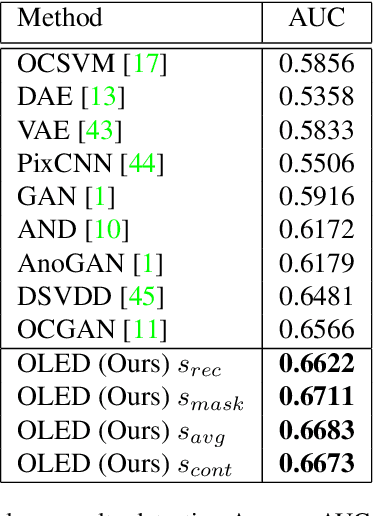
Novelty detection is the task of recognizing samples that do not belong to the distribution of the target class. During training, the novelty class is absent, preventing the use of traditional classification approaches. Deep autoencoders have been widely used as a base of many unsupervised novelty detection methods. In particular, context autoencoders have been successful in the novelty detection task because of the more effective representations they learn by reconstructing original images from randomly masked images. However, a significant drawback of context autoencoders is that random masking fails to consistently cover important structures of the input image, leading to suboptimal representations - especially for the novelty detection task. In this paper, to optimize input masking, we have designed a framework consisting of two competing networks, a Mask Module and a Reconstructor. The Mask Module is a convolutional autoencoder that learns to generate optimal masks that cover the most important parts of images. Alternatively, the Reconstructor is a convolutional encoder-decoder that aims to reconstruct unperturbed images from masked images. The networks are trained in an adversarial manner in which the Mask Module generates masks that are applied to images given to the Reconstructor. In this way, the Mask Module seeks to maximize the reconstruction error that the Reconstructor is minimizing. When applied to novelty detection, the proposed approach learns semantically richer representations compared to context autoencoders and enhances novelty detection at test time through more optimal masking. Novelty detection experiments on the MNIST and CIFAR-10 image datasets demonstrate the proposed approach's superiority over cutting-edge methods. In a further experiment on the UCSD video dataset for novelty detection, the proposed approach achieves state-of-the-art results.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 16, 2021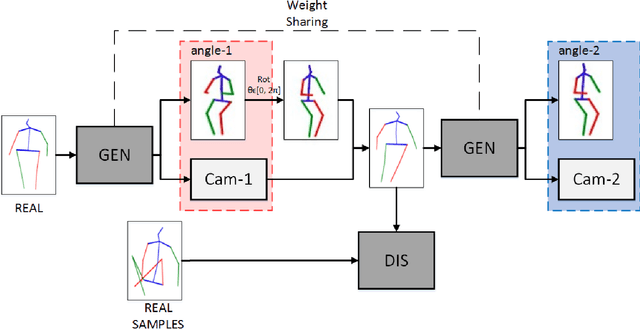
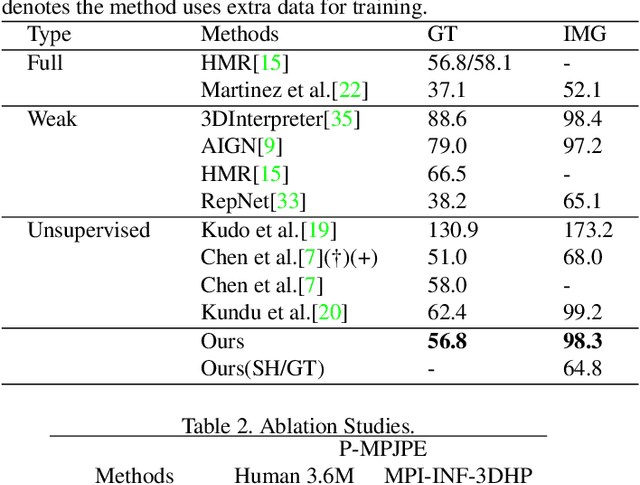
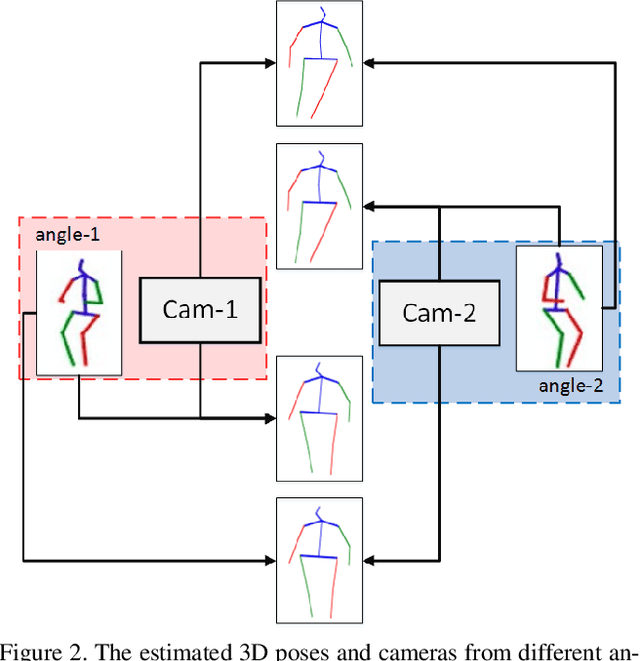
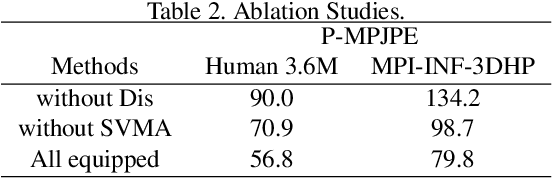
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.
Synthetic Data for Model Selection
May 03, 2021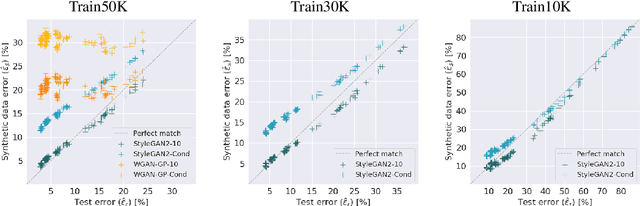
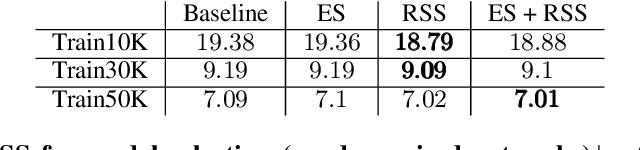
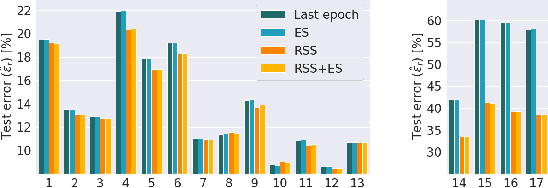

Recent improvements in synthetic data generation make it possible to produce images that are highly photorealistic and indistinguishable from real ones. Furthermore, synthetic generation pipelines have the potential to generate an unlimited number of images. The combination of high photorealism and scale turn the synthetic data into a promising candidate for potentially improving various machine learning (ML) pipelines. Thus far, a large body of research in this field has focused on using synthetic images for training, by augmenting and enlarging training data. In contrast to using synthetic data for training, in this work we explore whether synthetic data can be beneficial for model selection. Considering the task of image classification, we demonstrate that when data is scarce, synthetic data can be used to replace the held out validation set, thus allowing to train on a larger dataset.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
May 13, 2021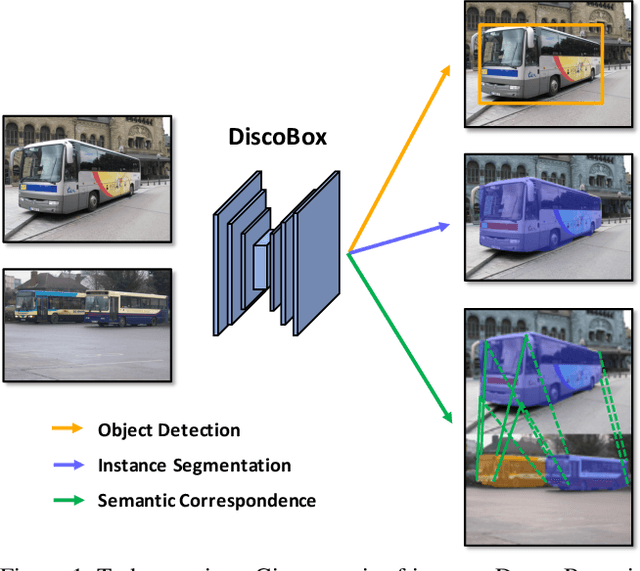
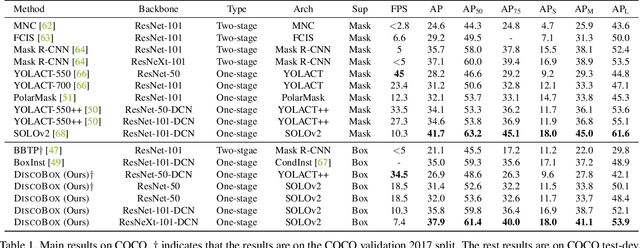
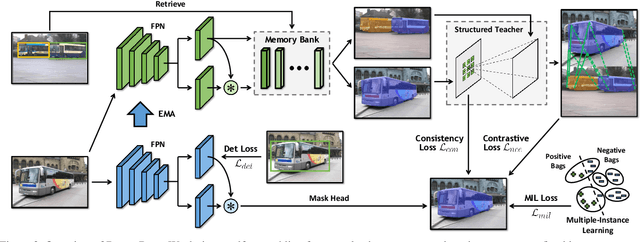
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
Improved Point Transformation Methods For Self-Supervised Depth Prediction
Feb 18, 2021
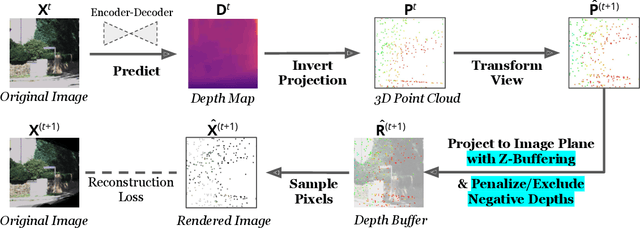
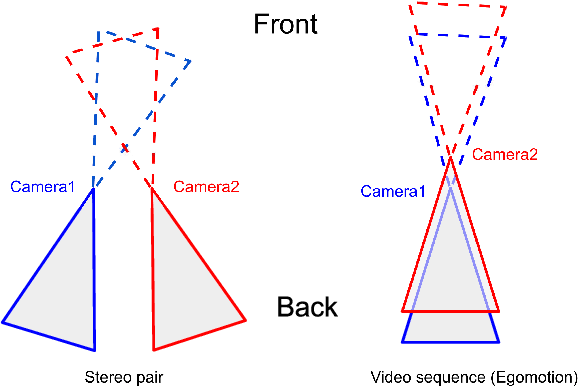
Given stereo or egomotion image pairs, a popular and successful method for unsupervised learning of monocular depth estimation is to measure the quality of image reconstructions resulting from the learned depth predictions. Continued research has improved the overall approach in recent years, yet the common framework still suffers from several important limitations, particularly when dealing with points occluded after transformation to a novel viewpoint. While prior work has addressed this problem heuristically, this paper introduces a z-buffering algorithm that correctly and efficiently handles occluded points. Because our algorithm is implemented with operators typical of machine learning libraries, it can be incorporated into any existing unsupervised depth learning framework with automatic support for differentiation. Additionally, because points having negative depth after transformation often signify erroneously shallow depth predictions, we introduce a loss function to penalize this undesirable behavior explicitly. Experimental results on the KITTI data set show that the z-buffer and negative depth loss both improve the performance of a state of the art depth-prediction network.
EVPropNet: Detecting Drones By Finding Propellers For Mid-Air Landing And Following
Jun 29, 2021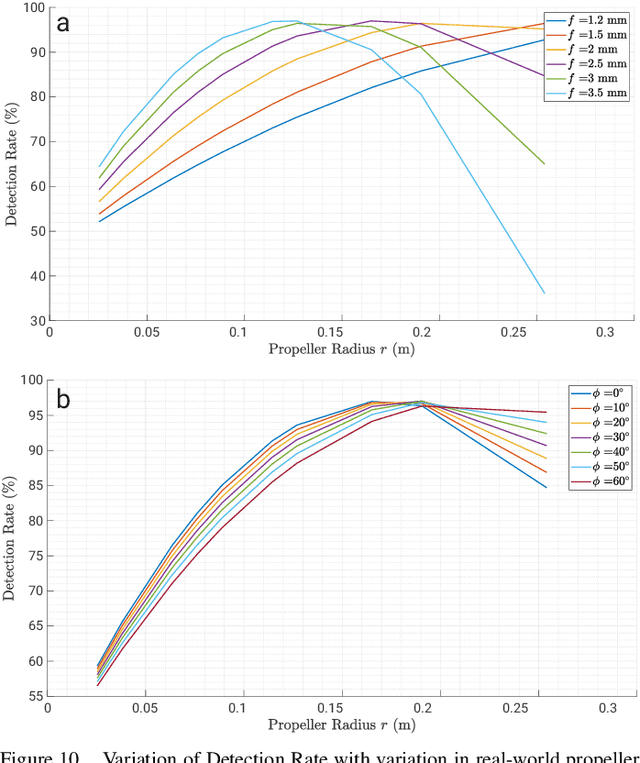
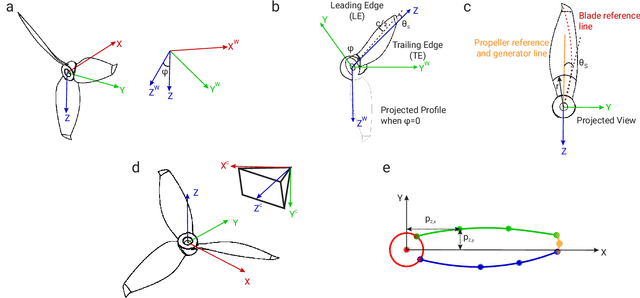
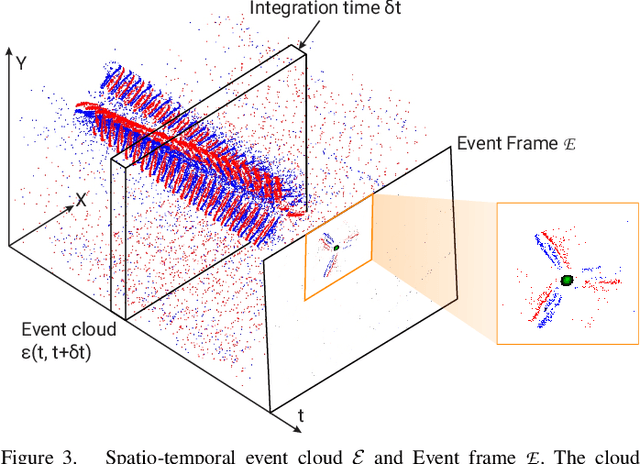
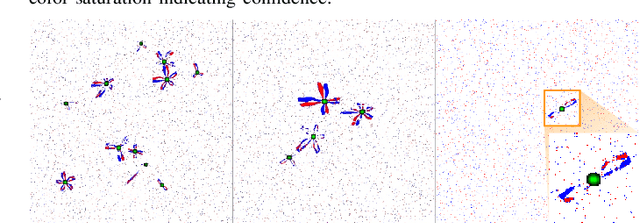
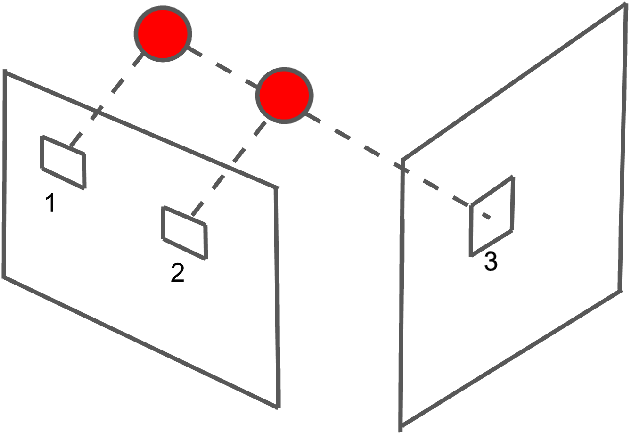
The rapid rise of accessibility of unmanned aerial vehicles or drones pose a threat to general security and confidentiality. Most of the commercially available or custom-built drones are multi-rotors and are comprised of multiple propellers. Since these propellers rotate at a high-speed, they are generally the fastest moving parts of an image and cannot be directly "seen" by a classical camera without severe motion blur. We utilize a class of sensors that are particularly suitable for such scenarios called event cameras, which have a high temporal resolution, low-latency, and high dynamic range. In this paper, we model the geometry of a propeller and use it to generate simulated events which are used to train a deep neural network called EVPropNet to detect propellers from the data of an event camera. EVPropNet directly transfers to the real world without any fine-tuning or retraining. We present two applications of our network: (a) tracking and following an unmarked drone and (b) landing on a near-hover drone. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different propeller shapes and sizes. Our network can detect propellers at a rate of 85.1% even when 60% of the propeller is occluded and can run at upto 35Hz on a 2W power budget. To our knowledge, this is the first deep learning-based solution for detecting propellers (to detect drones). Finally, our applications also show an impressive success rate of 92% and 90% for the tracking and landing tasks respectively.
Person Re-Identification with a Locally Aware Transformer
Jun 08, 2021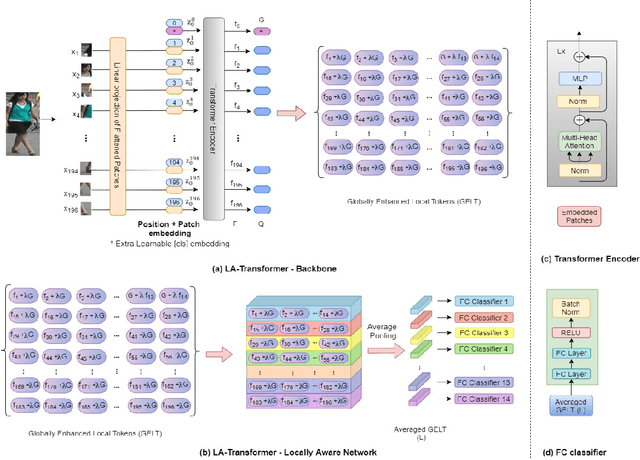
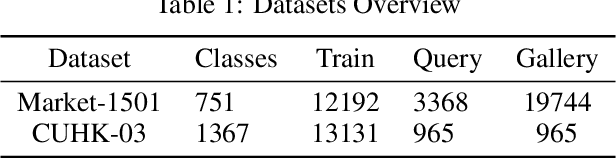
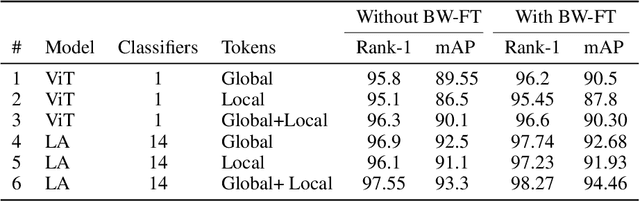
Person Re-Identification is an important problem in computer vision-based surveillance applications, in which the same person is attempted to be identified from surveillance photographs in a variety of nearby zones. At present, the majority of Person re-ID techniques are based on Convolutional Neural Networks (CNNs), but Vision Transformers are beginning to displace pure CNNs for a variety of object recognition tasks. The primary output of a vision transformer is a global classification token, but vision transformers also yield local tokens which contain additional information about local regions of the image. Techniques to make use of these local tokens to improve classification accuracy are an active area of research. We propose a novel Locally Aware Transformer (LA-Transformer) that employs a Parts-based Convolution Baseline (PCB)-inspired strategy for aggregating globally enhanced local classification tokens into an ensemble of $\sqrt{N}$ classifiers, where $N$ is the number of patches. An additional novelty is that we incorporate blockwise fine-tuning which further improves re-ID accuracy. LA-Transformer with blockwise fine-tuning achieves rank-1 accuracy of $98.27 \%$ with standard deviation of $0.13$ on the Market-1501 and $98.7\%$ with standard deviation of $0.2$ on the CUHK03 dataset respectively, outperforming all other state-of-the-art published methods at the time of writing.
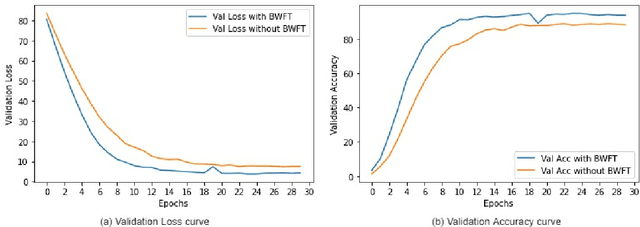
Supervised Video Summarization via Multiple Feature Sets with Parallel Attention
May 13, 2021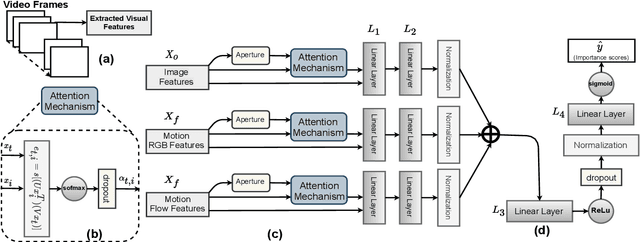
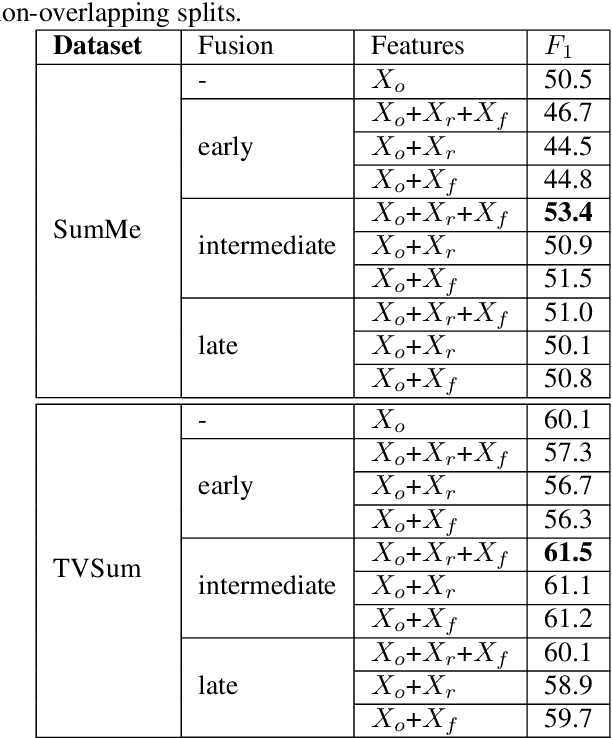
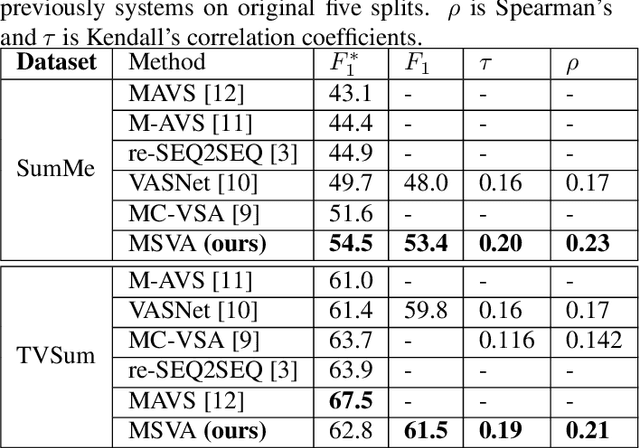
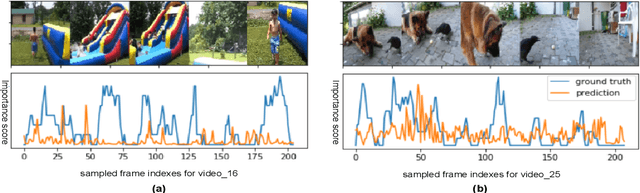
The assignment of importance scores to particular frames or (short) segments in a video is crucial for summarization, but also a difficult task. Previous work utilizes only one source of visual features. In this paper, we suggest a novel model architecture that combines three feature sets for visual content and motion to predict importance scores. The proposed architecture utilizes an attention mechanism before fusing motion features and features representing the (static) visual content, i.e., derived from an image classification model. Comprehensive experimental evaluations are reported for two well-known datasets, SumMe and TVSum. In this context, we identify methodological issues on how previous work used these benchmark datasets, and present a fair evaluation scheme with appropriate data splits that can be used in future work. When using static and motion features with parallel attention mechanism, we improve state-of-the-art results for SumMe, while being on par with the state of the art for the other dataset.