 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Select Good Regions for Deblurring based on Convolutional Neural Networks
Aug 12, 2020

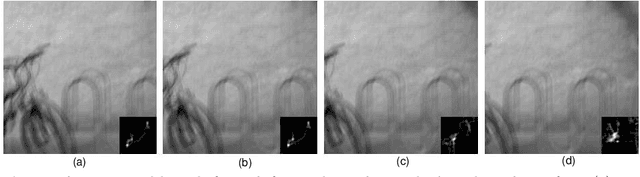


The goal of blind image deblurring is to recover sharp image from one input blurred image with an unknown blur kernel. Most of image deblurring approaches focus on developing image priors, however, there is not enough attention to the influence of image details and structures on the blur kernel estimation. What is the useful image structure and how to choose a good deblurring region? In this work, we propose a deep neural network model method for selecting good regions to estimate blur kernel. First we construct image patches with labels and train a deep neural networks, then the learned model is applied to determine which region of the image is most suitable to deblur. Experimental results illustrate that the proposed approach is effective, and could be able to select good regions for image deblurring.
Automatic Main Character Recognition for Photographic Studies
Jun 16, 2021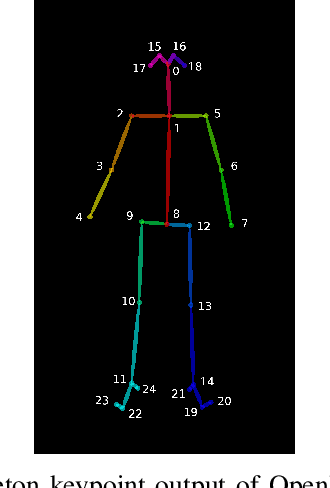


Main characters in images are the most important humans that catch the viewer's attention upon first look, and they are emphasized by properties such as size, position, color saturation, and sharpness of focus. Identifying the main character in images plays an important role in traditional photographic studies and media analysis, but the task is performed manually and can be slow and laborious. Furthermore, selection of main characters can be sometimes subjective. In this paper, we analyze the feasibility of solving the main character recognition needed for photographic studies automatically and propose a method for identifying the main characters. The proposed method uses machine learning based human pose estimation along with traditional computer vision approaches for this task. We approach the task as a binary classification problem where each detected human is classified either as a main character or not. To evaluate both the subjectivity of the task and the performance of our method, we collected a dataset of 300 varying images from multiple sources and asked five people, a photographic researcher and four other persons, to annotate the main characters. Our analysis showed a relatively high agreement between different annotators. The proposed method achieved a promising F1 score of 0.83 on the full image set and 0.96 on a subset evaluated as most clear and important cases by the photographic researcher.
Point Cloud Learning with Transformer
Apr 28, 2021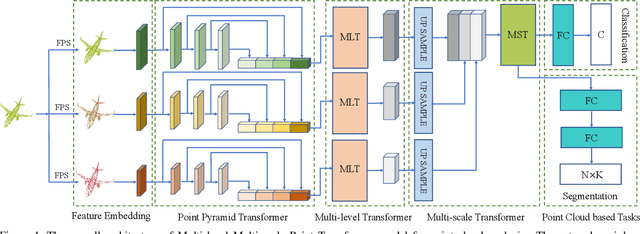
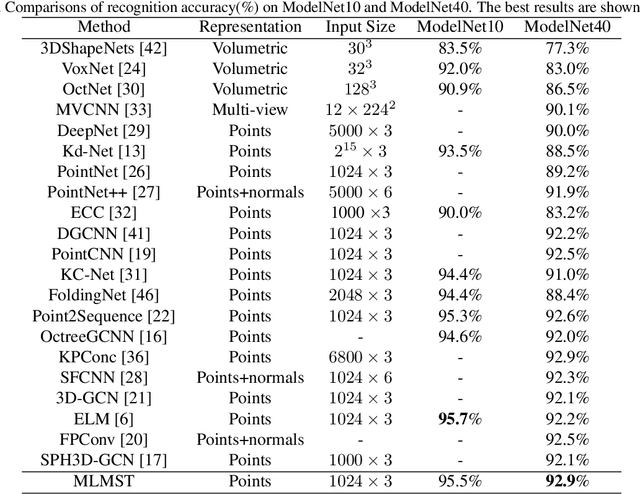
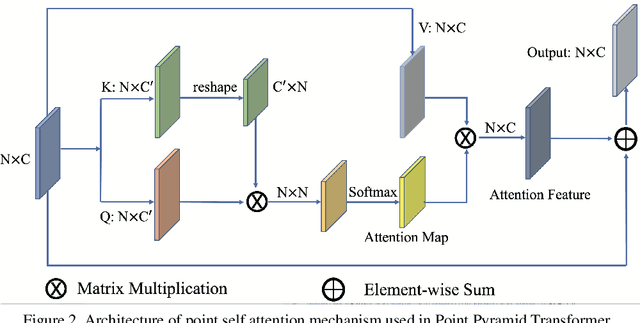
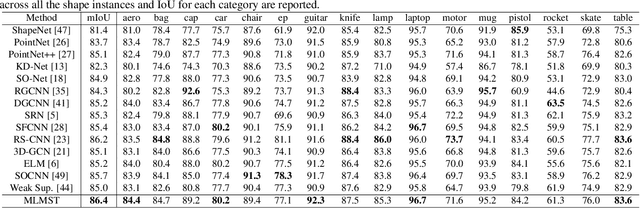
Remarkable performance from Transformer networks in Natural Language Processing promote the development of these models in dealing with computer vision tasks such as image recognition and segmentation. In this paper, we introduce a novel framework, called Multi-level Multi-scale Point Transformer (MLMSPT) that works directly on the irregular point clouds for representation learning. Specifically, a point pyramid transformer is investigated to model features with diverse resolutions or scales we defined, followed by a multi-level transformer module to aggregate contextual information from different levels of each scale and enhance their interactions. While a multi-scale transformer module is designed to capture the dependencies among representations across different scales. Extensive evaluation on public benchmark datasets demonstrate the effectiveness and the competitive performance of our methods on 3D shape classification, part segmentation and semantic segmentation tasks.
3D human tongue reconstruction from single "in-the-wild" images
Jun 23, 2021

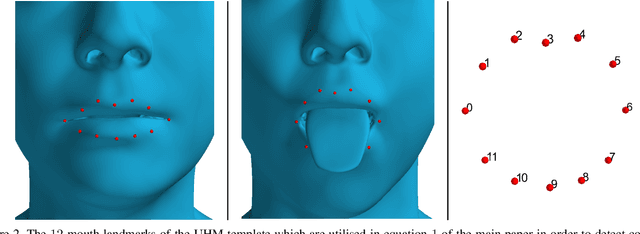

3D face reconstruction from a single image is a task that has garnered increased interest in the Computer Vision community, especially due to its broad use in a number of applications such as realistic 3D avatar creation, pose invariant face recognition and face hallucination. Since the introduction of the 3D Morphable Model in the late 90's, we witnessed an explosion of research aiming at particularly tackling this task. Nevertheless, despite the increasing level of detail in the 3D face reconstructions from single images mainly attributed to deep learning advances, finer and highly deformable components of the face such as the tongue are still absent from all 3D face models in the literature, although being very important for the realness of the 3D avatar representations. In this work we present the first, to the best of our knowledge, end-to-end trainable pipeline that accurately reconstructs the 3D face together with the tongue. Moreover, we make this pipeline robust in "in-the-wild" images by introducing a novel GAN method tailored for 3D tongue surface generation. Finally, we make publicly available to the community the first diverse tongue dataset, consisting of 1,800 raw scans of 700 individuals varying in gender, age, and ethnicity backgrounds. As we demonstrate in an extensive series of quantitative as well as qualitative experiments, our model proves to be robust and realistically captures the 3D tongue structure, even in adverse "in-the-wild" conditions.
Model-Centric Volumetric Point Cloud Attributes
Jun 29, 2021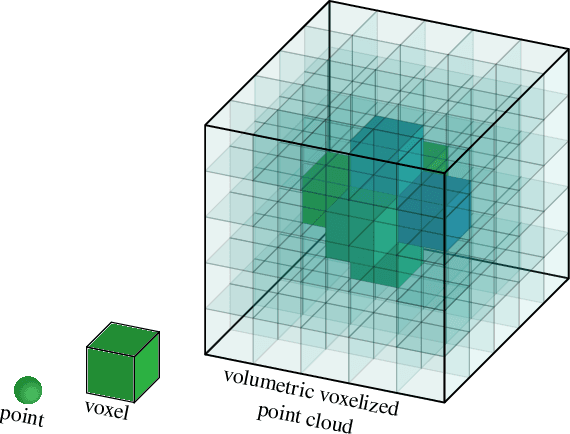


Point clouds have recently gained interest, especially for real-time applications and for 3D-scanned material, such as is used in autonomous driving, architecture, and engineering, to model real estate for renovation or display. Point clouds are associated with geometry information and attributes such as color. Be the color unique or direction-dependent (in the case of plenoptic point clouds), it reflects the colors observed by cameras displaced around the object. Hence, not only are the viewing references assumed, but the illumination spectrum and illumination geometry is also implicit. We propose a model-centric description of the 3D object, that is independent of the illumination and of the position of the cameras. We want to be able to describe the objects themselves such that, at a later stage, the rendering of the model may decide where to place illumination, from which it may calculate the image viewed by a given camera. We want to be able to describe transparent or translucid objects, mirrors, fishbowls, fog and smoke. Volumetric clouds may allow us to describe the air, however ``empty'', and introduce air particles, in a manner independent of the viewer position. For that, we rely on some eletromagnetic properties to arrive at seven attributes per voxel that would describe the material and its color or transparency. Three attributes are for the transmissivity of each color, three are for the attenuation of each color, and another attribute is for diffuseness. These attributes give information about the object to the renderer, with whom lies the decision on how to render and depict each object.
Image-embodied Knowledge Representation Learning
May 22, 2017

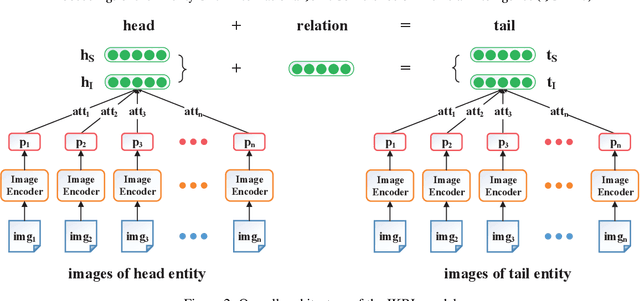
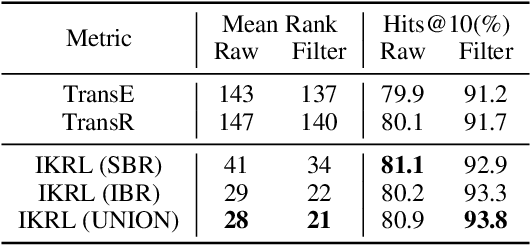
Entity images could provide significant visual information for knowledge representation learning. Most conventional methods learn knowledge representations merely from structured triples, ignoring rich visual information extracted from entity images. In this paper, we propose a novel Image-embodied Knowledge Representation Learning model (IKRL), where knowledge representations are learned with both triple facts and images. More specifically, we first construct representations for all images of an entity with a neural image encoder. These image representations are then integrated into an aggregated image-based representation via an attention-based method. We evaluate our IKRL models on knowledge graph completion and triple classification. Experimental results demonstrate that our models outperform all baselines on both tasks, which indicates the significance of visual information for knowledge representations and the capability of our models in learning knowledge representations with images.
Relighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
Dec 11, 2020
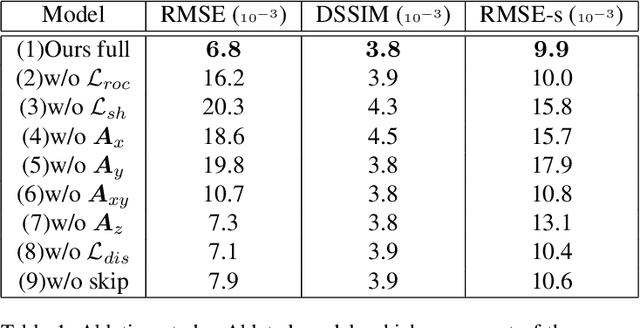
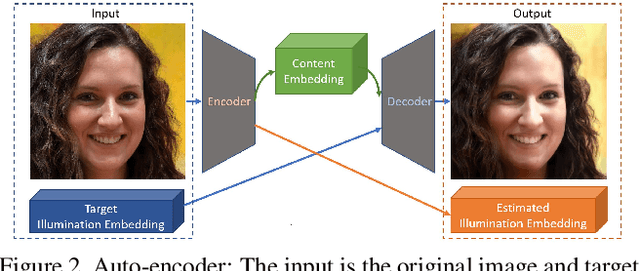
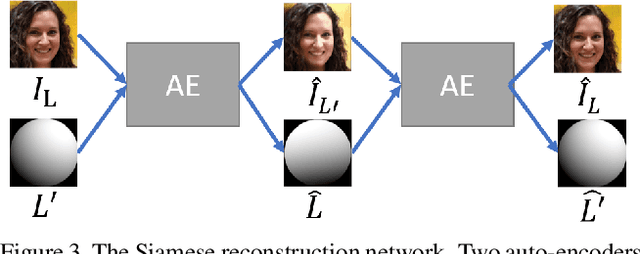
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.
Two-Stage Self-Supervised Cycle-Consistency Network for Reconstruction of Thin-Slice MR Images
Jun 29, 2021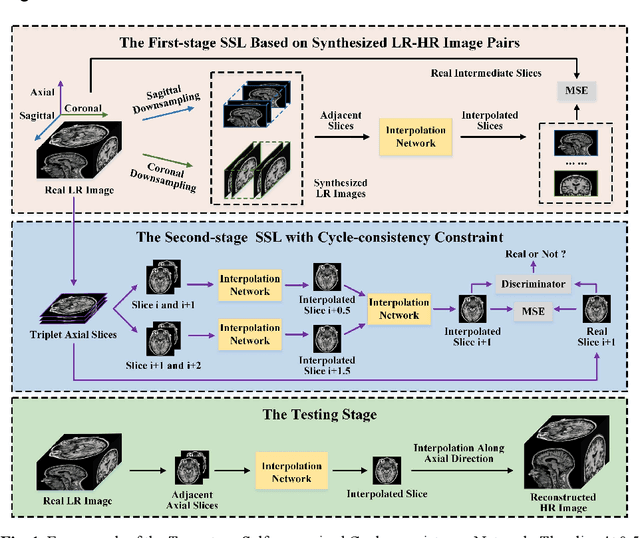
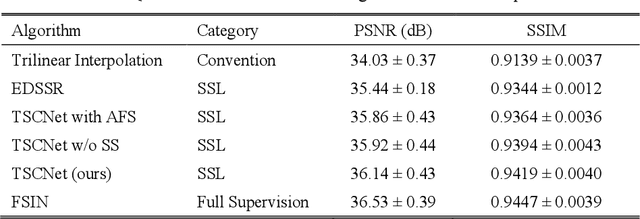
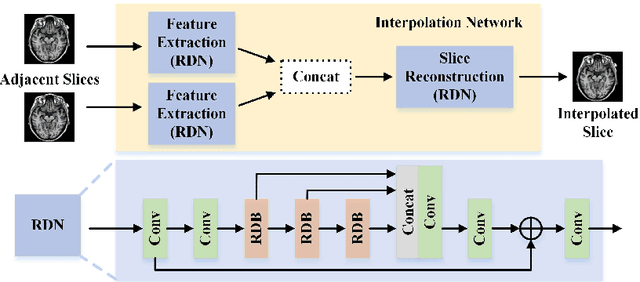
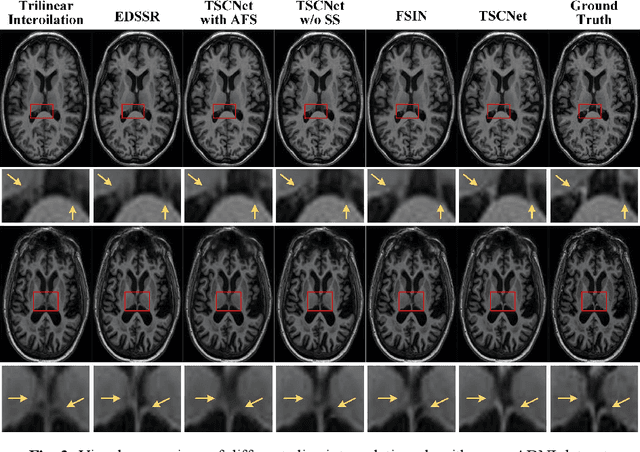
The thick-slice magnetic resonance (MR) images are often structurally blurred in coronal and sagittal views, which causes harm to diagnosis and image post-processing. Deep learning (DL) has shown great potential to re-construct the high-resolution (HR) thin-slice MR images from those low-resolution (LR) cases, which we refer to as the slice interpolation task in this work. However, since it is generally difficult to sample abundant paired LR-HR MR images, the classical fully supervised DL-based models cannot be effectively trained to get robust performance. To this end, we propose a novel Two-stage Self-supervised Cycle-consistency Network (TSCNet) for MR slice interpolation, in which a two-stage self-supervised learning (SSL) strategy is developed for unsupervised DL network training. The paired LR-HR images are synthesized along the sagittal and coronal directions of input LR images for network pretraining in the first-stage SSL, and then a cyclic in-terpolation procedure based on triplet axial slices is designed in the second-stage SSL for further refinement. More training samples with rich contexts along all directions are exploited as guidance to guarantee the improved in-terpolation performance. Moreover, a new cycle-consistency constraint is proposed to supervise this cyclic procedure, which encourages the network to reconstruct more realistic HR images. The experimental results on a real MRI dataset indicate that TSCNet achieves superior performance over the conventional and other SSL-based algorithms, and obtains competitive quali-tative and quantitative results compared with the fully supervised algorithm.
A selectional auto-encoder approach for document image binarization
Sep 06, 2018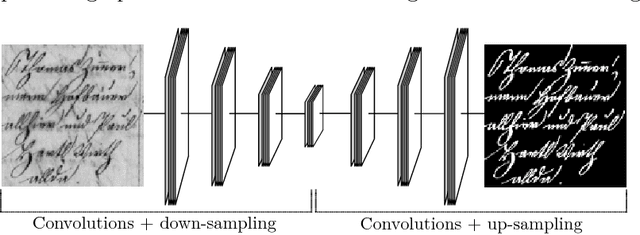
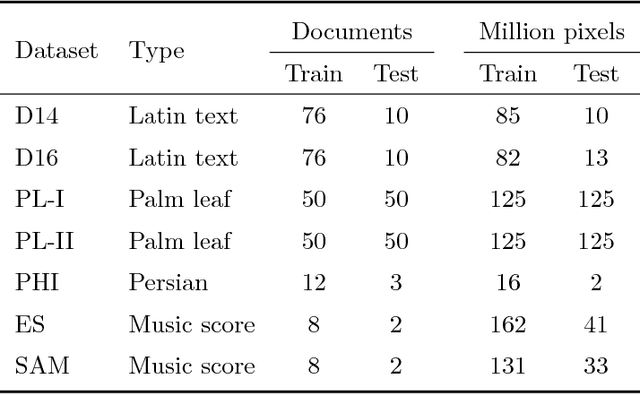

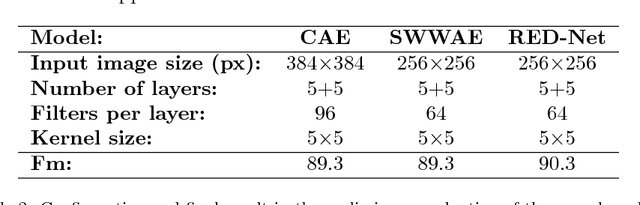
Binarization plays a key role in the automatic information retrieval from document images. This process is usually performed in the first stages of documents analysis systems, and serves as a basis for subsequent steps. Hence it has to be robust in order to allow the full analysis workflow to be successful. Several methods for document image binarization have been proposed so far, most of which are based on hand-crafted image processing strategies. Recently, Convolutional Neural Networks have shown an amazing performance in many disparate duties related to computer vision. In this paper we discuss the use of convolutional auto-encoders devoted to learning an end-to-end map from an input image to its selectional output, in which activations indicate the likelihood of pixels to be either foreground or background. Once trained, documents can therefore be binarized by parsing them through the model and applying a threshold. This approach has proven to outperform existing binarization strategies in a number of document domains.
Chronological age estimation of lateral cephalometric radiographs with deep learning
Jan 28, 2021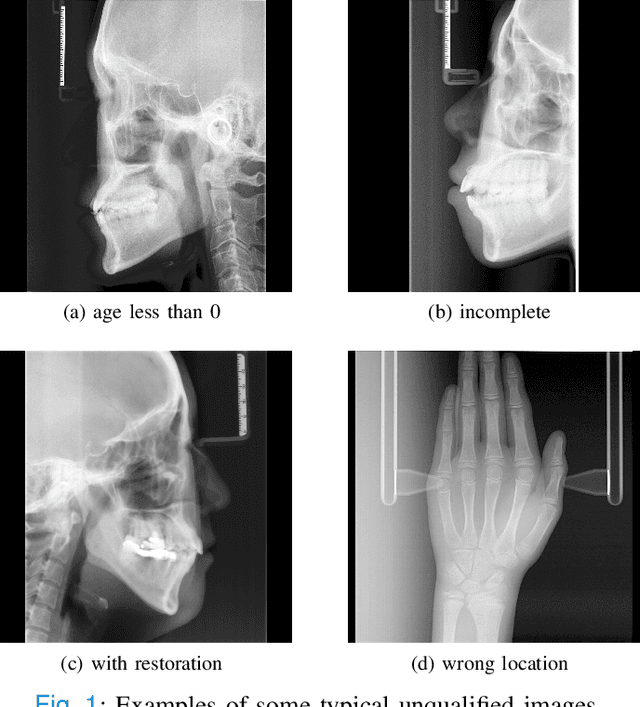
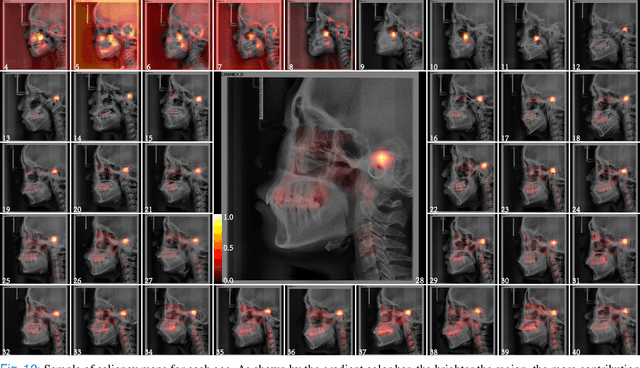
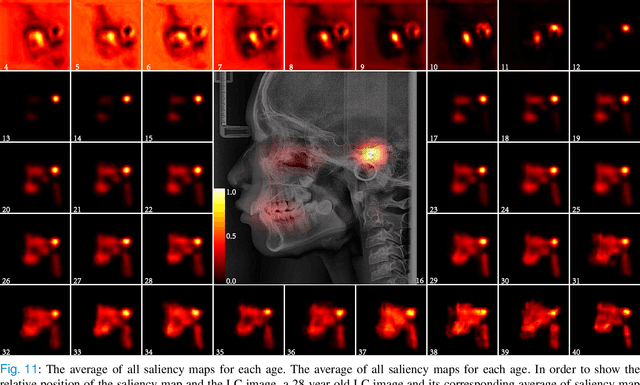
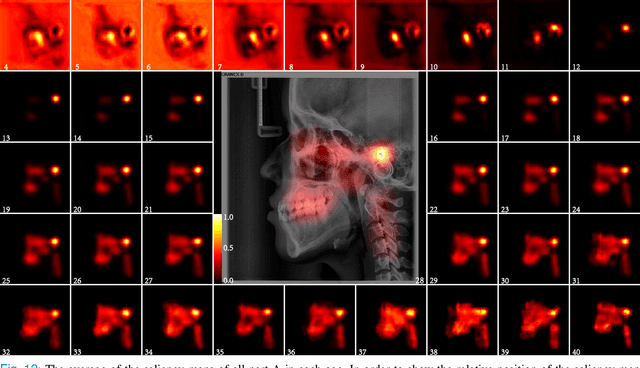
The traditional manual age estimation method is crucial labor based on many kinds of the X-Ray image. Some current studies have shown that lateral cephalometric(LC) images can be used to estimate age. However, these methods are based on manually measuring some image features and making age estimates based on experience or scoring. Therefore, these methods are time-consuming and labor-intensive, and the effect will be affected by subjective opinions. In this work, we propose a saliency map-enhanced age estimation method, which can automatically perform age estimation based on LC images. Meanwhile, it can also show the importance of each region in the image for age estimation, which undoubtedly increases the method's Interpretability. Our method was tested on 3014 LC images from 4 to 40 years old. The MEA of the experimental result is 1.250, which is less than the result of the state-of-the-art benchmark because it performs significantly better in the age group with fewer data. Besides, our model is trained in each area with a high contribution to age estimation in LC images, so the effect of these different areas on the age estimation task was verified. Consequently, we conclude that the proposed saliency map enhancements chronological age estimation method of lateral cephalometric radiographs can work well in chronological age estimation task, especially when the amount of data is small. Besides, compared with traditional deep learning, our method is also interpretable.