 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Big Plastic Masses Detection using Sentinel 2 Images
Mar 17, 2021


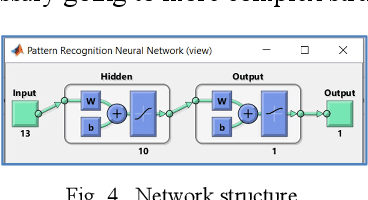
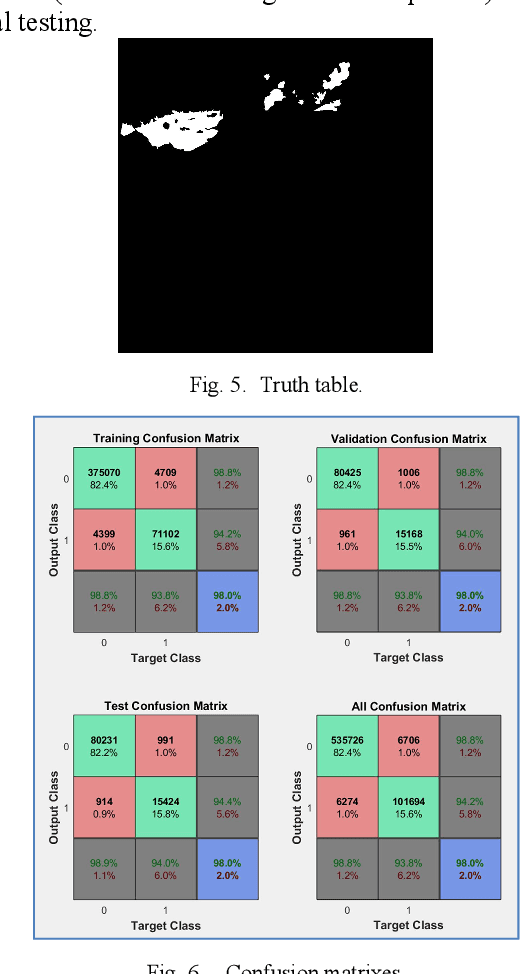
This communication describes a preliminary research on detection of big masses of plastic (marine litter) on the oceans and seas using EO (Earth Observation) satellite systems. Free images from the Sentinel 2 (Copernicus Project) platform are used. To develop a plastic recognizer, we start with an image where we can find a big accumulation of "nonfloating" plastic: Almer\'ia greenhouses. We made a test using remote sensing differential indexes, but we got much better results using all available wavelengths (thirteen frequency bands) and applying Neural Networks to that feature vector.
A hybrid classification-regression approach for 3D hand pose estimation using graph convolutional networks
May 23, 2021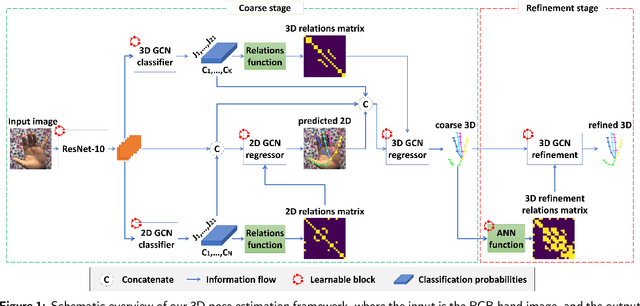
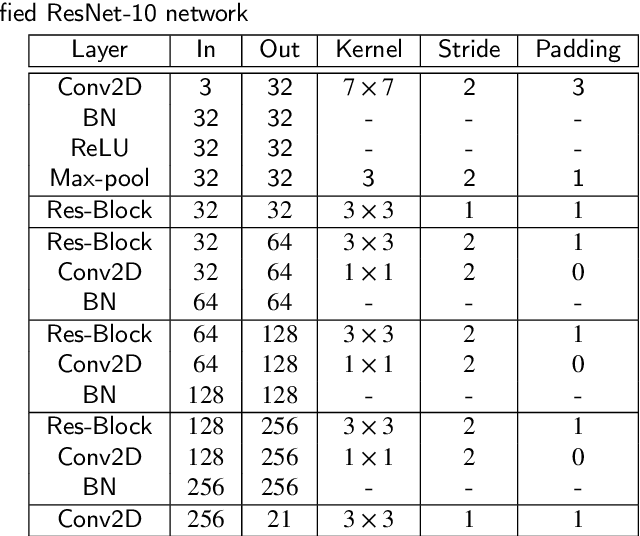
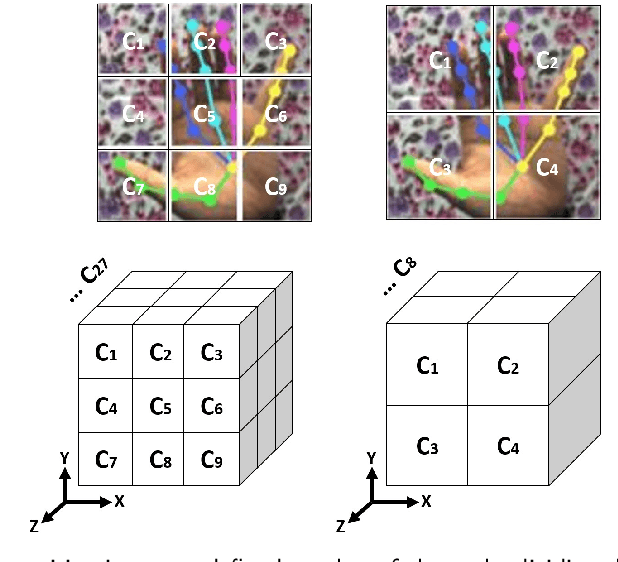
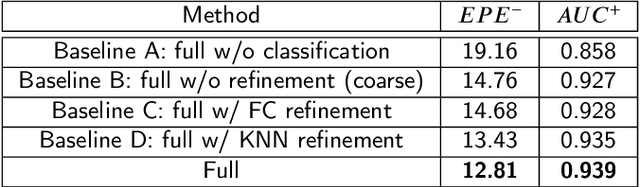
Hand pose estimation is a crucial part of a wide range of augmented reality and human-computer interaction applications. Predicting the 3D hand pose from a single RGB image is challenging due to occlusion and depth ambiguities. GCN-based (Graph Convolutional Networks) methods exploit the structural relationship similarity between graphs and hand joints to model kinematic dependencies between joints. These techniques use predefined or globally learned joint relationships, which may fail to capture pose-dependent constraints. To address this problem, we propose a two-stage GCN-based framework that learns per-pose relationship constraints. Specifically, the first phase quantizes the 2D/3D space to classify the joints into 2D/3D blocks based on their locality. This spatial dependency information guides this phase to estimate reliable 2D and 3D poses. The second stage further improves the 3D estimation through a GCN-based module that uses an adaptative nearest neighbor algorithm to determine joint relationships. Extensive experiments show that our multi-stage GCN approach yields an efficient model that produces accurate 2D/3D hand poses and outperforms the state-of-the-art on two public datasets.
Transformer-based Methods for Recognizing Ultra Fine-grained Entities (RUFES)
Apr 13, 2021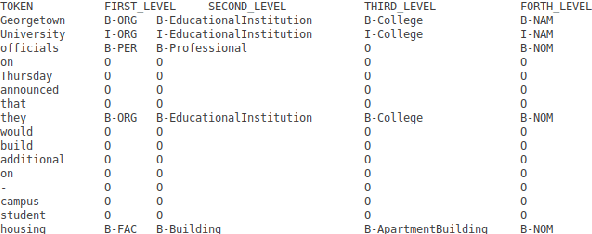
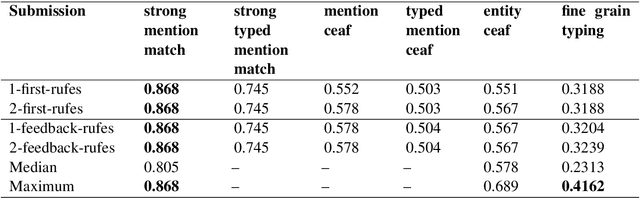
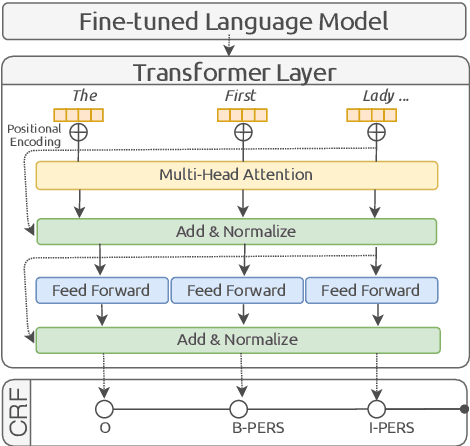
This paper summarizes the participation of the Laboratoire Informatique, Image et Interaction (L3i laboratory) of the University of La Rochelle in the Recognizing Ultra Fine-grained Entities (RUFES) track within the Text Analysis Conference (TAC) series of evaluation workshops. Our participation relies on two neural-based models, one based on a pre-trained and fine-tuned language model with a stack of Transformer layers for fine-grained entity extraction and one out-of-the-box model for within-document entity coreference. We observe that our approach has great potential in increasing the performance of fine-grained entity recognition. Thus, the future work envisioned is to enhance the ability of the models following additional experiments and a deeper analysis of the results.
Dual-stream Network for Visual Recognition
May 31, 2021
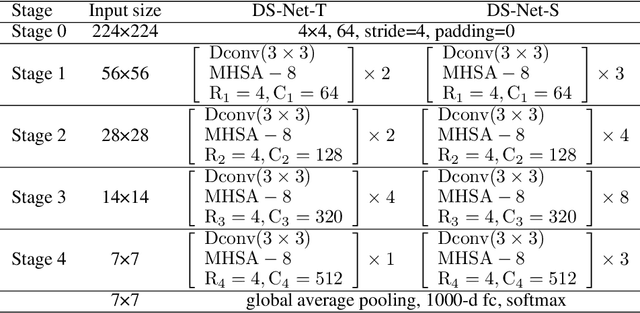
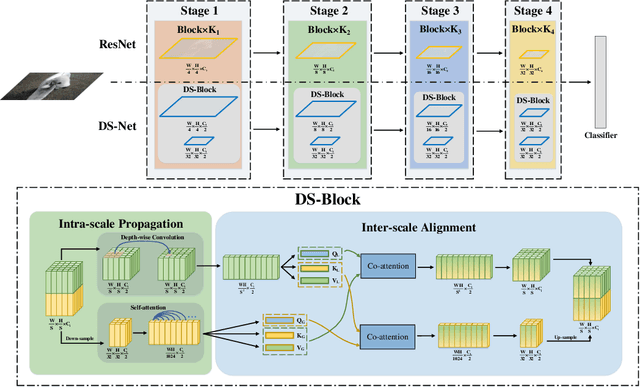
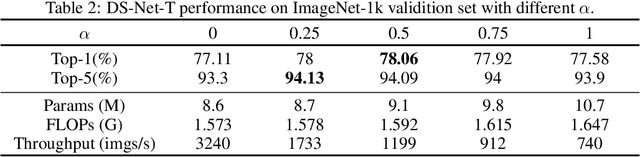
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.
MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space
May 05, 2021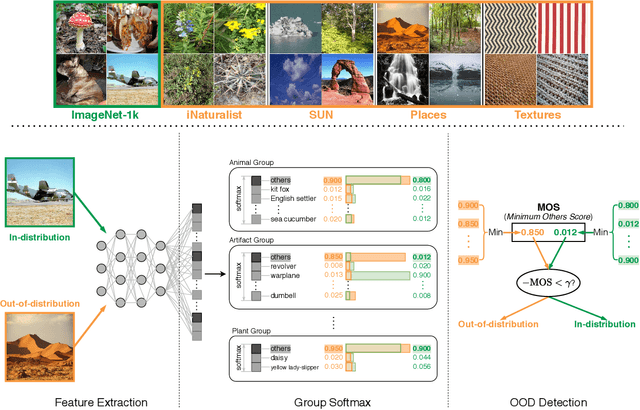
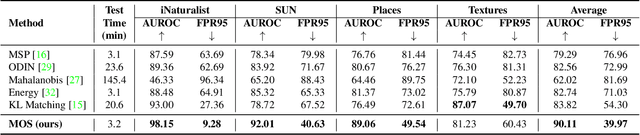
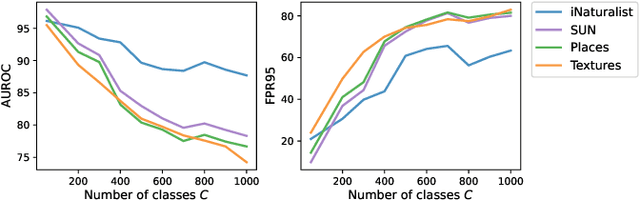
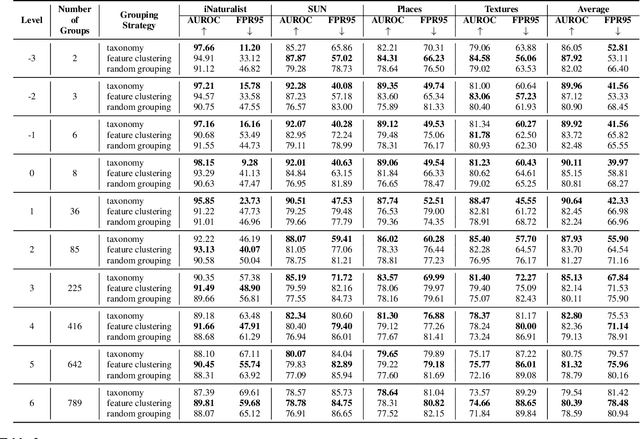
Detecting out-of-distribution (OOD) inputs is a central challenge for safely deploying machine learning models in the real world. Existing solutions are mainly driven by small datasets, with low resolution and very few class labels (e.g., CIFAR). As a result, OOD detection for large-scale image classification tasks remains largely unexplored. In this paper, we bridge this critical gap by proposing a group-based OOD detection framework, along with a novel OOD scoring function termed MOS. Our key idea is to decompose the large semantic space into smaller groups with similar concepts, which allows simplifying the decision boundaries between in- vs. out-of-distribution data for effective OOD detection. Our method scales substantially better for high-dimensional class space than previous approaches. We evaluate models trained on ImageNet against four carefully curated OOD datasets, spanning diverse semantics. MOS establishes state-of-the-art performance, reducing the average FPR95 by 14.33% while achieving 6x speedup in inference compared to the previous best method.
An Intelligent Hybrid Model for Identity Document Classification
Jun 07, 2021
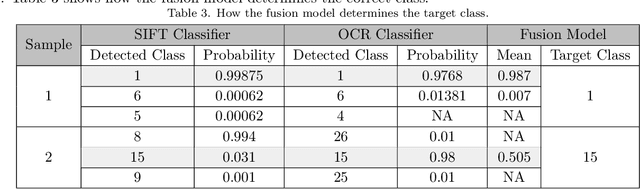
Digitization, i.e., the process of converting information into a digital format, may provide various opportunities (e.g., increase in productivity, disaster recovery, and environmentally friendly solutions) and challenges for businesses. In this context, one of the main challenges would be to accurately classify numerous scanned documents uploaded every day by customers as usual business processes. For example, processes in banking (e.g., applying for loans) or the Government Registry of BDM (Births, Deaths, and Marriages) applications may involve uploading several documents such as a driver's license and passport. There are not many studies available to address the challenge as an application of image classification. Although some studies are available which used various methods, a more accurate model is still required. The current study has proposed a robust fusion model to define the type of identity documents accurately. The proposed approach is based on two different methods in which images are classified based on their visual features and text features. A novel model based on statistics and regression has been proposed to calculate the confidence level for the feature-based classifier. A fuzzy-mean fusion model has been proposed to combine the classifier results based on their confidence score. The proposed approach has been implemented using Python and experimentally validated on synthetic and real-world datasets. The performance of the proposed model is evaluated using the Receiver Operating Characteristic (ROC) curve analysis.
Deep Supervised Hashing leveraging Quadratic Spherical Mutual Information for Content-based Image Retrieval
Jan 16, 2019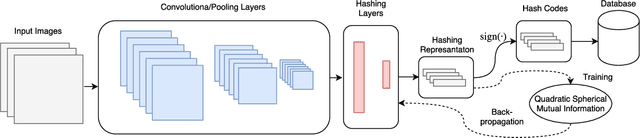

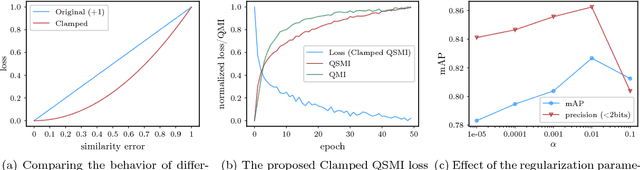
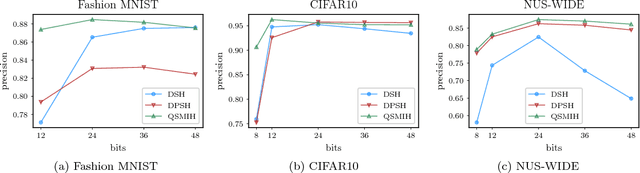
Several deep supervised hashing techniques have been proposed to allow for efficiently querying large image databases. However, deep supervised image hashing techniques are developed, to a great extent, heuristically often leading to suboptimal results. Contrary to this, we propose an efficient deep supervised hashing algorithm that optimizes the learned codes using an information-theoretic measure, the Quadratic Mutual Information (QMI). The proposed method is adapted to the needs of large-scale hashing and information retrieval leading to a novel information-theoretic measure, the Quadratic Spherical Mutual Information (QSMI). Apart from demonstrating the effectiveness of the proposed method under different scenarios and outperforming existing state-of-the-art image hashing techniques, this paper provides a structured way to model the process of information retrieval and develop novel methods adapted to the needs of each application.
Examining and Combating Spurious Features under Distribution Shift
Jun 14, 2021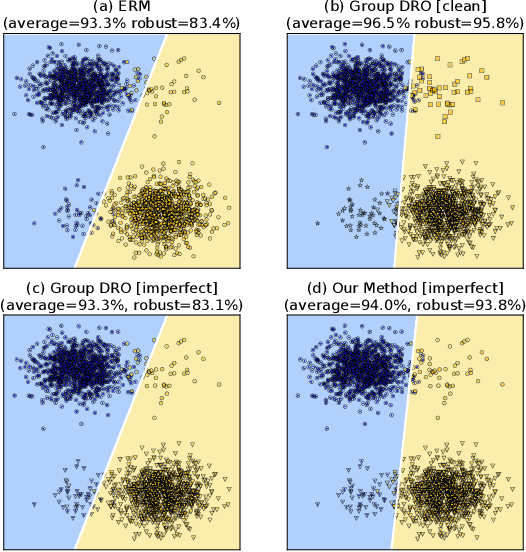

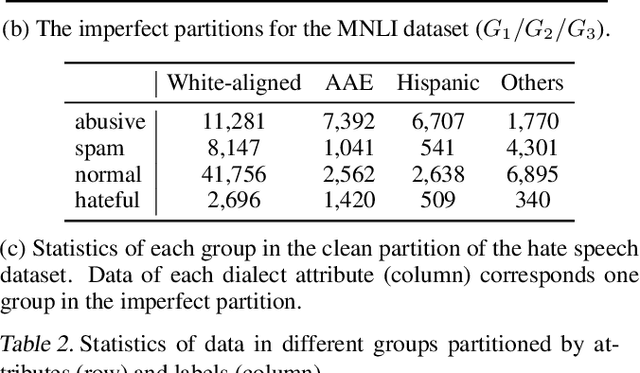
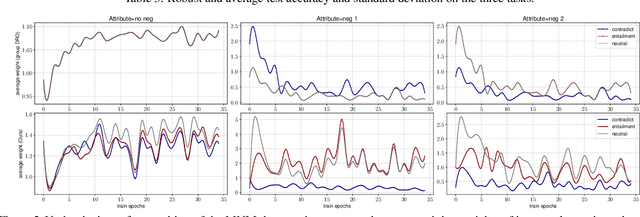
A central goal of machine learning is to learn robust representations that capture the causal relationship between inputs features and output labels. However, minimizing empirical risk over finite or biased datasets often results in models latching on to spurious correlations between the training input/output pairs that are not fundamental to the problem at hand. In this paper, we define and analyze robust and spurious representations using the information-theoretic concept of minimal sufficient statistics. We prove that even when there is only bias of the input distribution (i.e. covariate shift), models can still pick up spurious features from their training data. Group distributionally robust optimization (DRO) provides an effective tool to alleviate covariate shift by minimizing the worst-case training loss over a set of pre-defined groups. Inspired by our analysis, we demonstrate that group DRO can fail when groups do not directly account for various spurious correlations that occur in the data. To address this, we further propose to minimize the worst-case losses over a more flexible set of distributions that are defined on the joint distribution of groups and instances, instead of treating each group as a whole at optimization time. Through extensive experiments on one image and two language tasks, we show that our model is significantly more robust than comparable baselines under various partitions. Our code is available at https://github.com/violet-zct/group-conditional-DRO.
Polyblur: Removing mild blur by polynomial reblurring
Dec 16, 2020

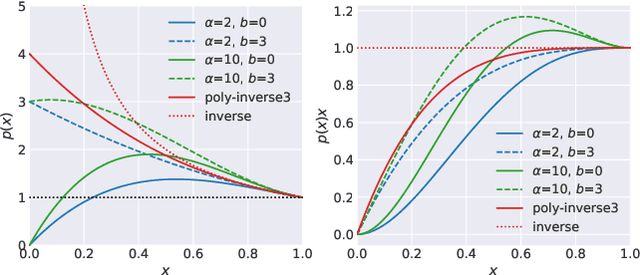
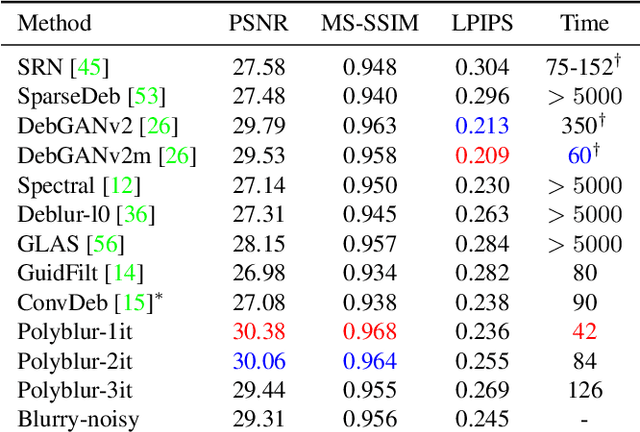
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.
Online learning of Riemannian hidden Markov models in homogeneous Hadamard spaces
Feb 15, 2021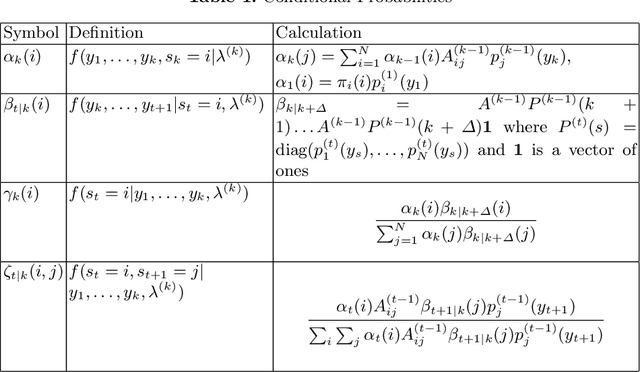
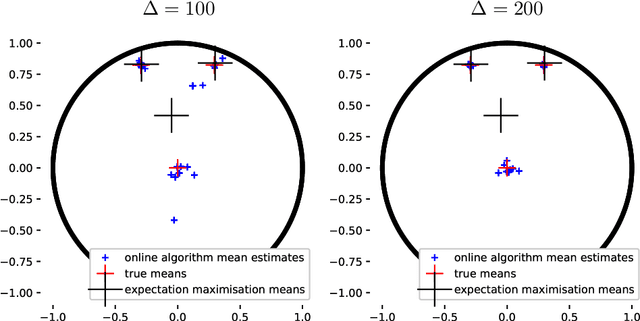
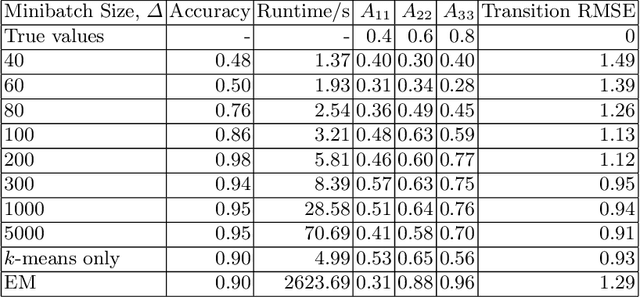
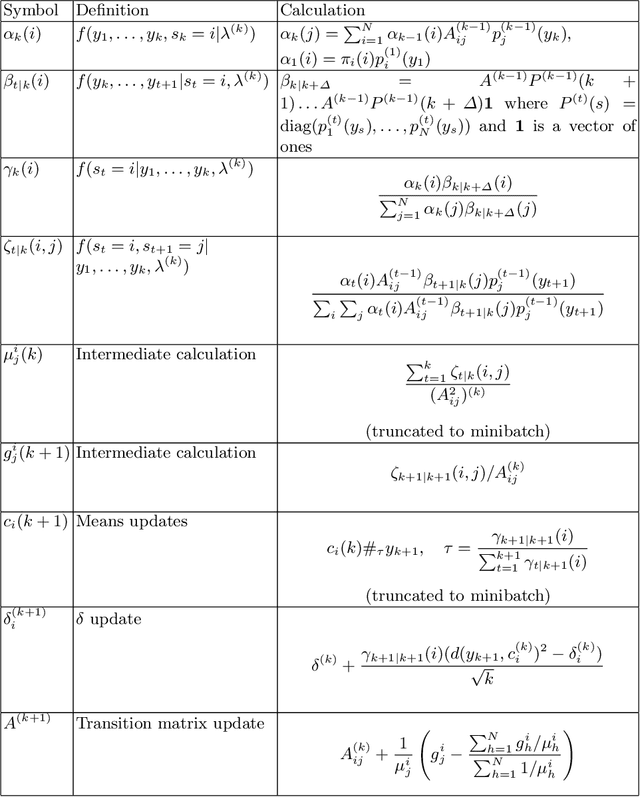
Hidden Markov models with observations in a Euclidean space play an important role in signal and image processing. Previous work extending to models where observations lie in Riemannian manifolds based on the Baum-Welch algorithm suffered from high memory usage and slow speed. Here we present an algorithm that is online, more accurate, and offers dramatic improvements in speed and efficiency.