 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks
Jul 11, 2019
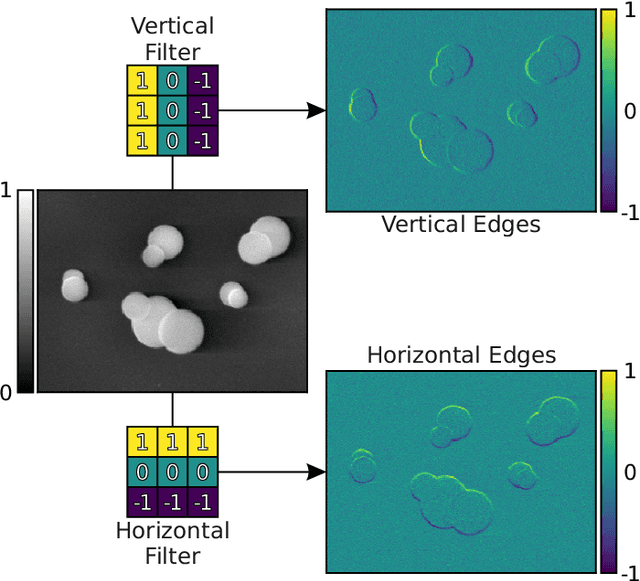
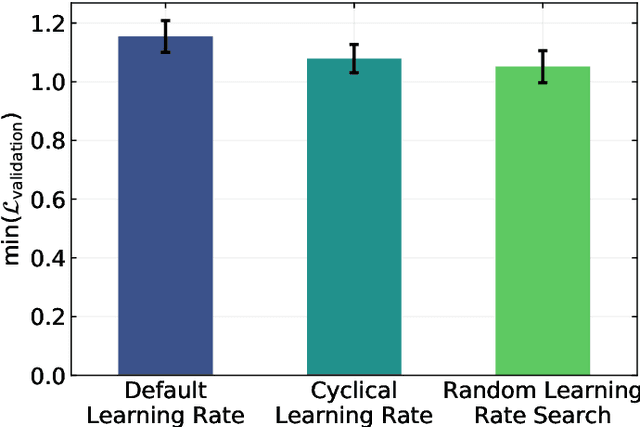
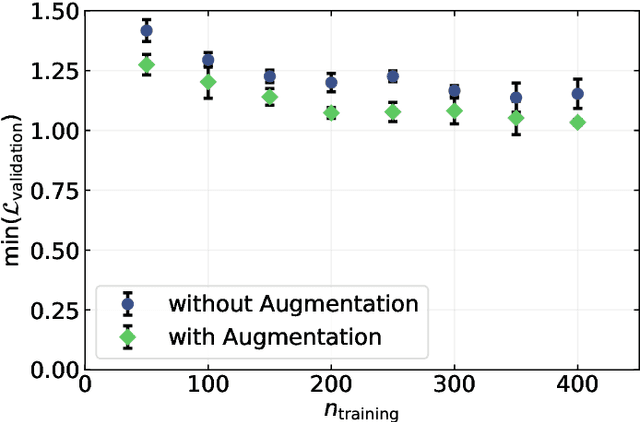
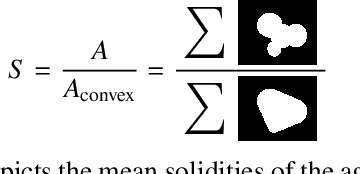
There is a high demand for fully automated methods for the analysis of particle size distributions of agglomerated, sintered or occluded primary particles. Therefore, a novel, deep learning-based, method for the pixel-perfect detection and sizing of agglomerated, aggregated or occluded primary particles was proposed and tested. As a specialty, the training of the utilized convolutional neural networks was carried out using only synthetic images, to avoid the laborious task of manual annotation and to increase the quality of the ground truth. Despite the training on synthetic images, the proposed method performs excellent on real world samples of sintered silica nanoparticles with various sintering degrees and varying image conditions. In a direct comparison, the proposed method clearly outperforms two state-of-the-art methods for automated image-based particle size analysis (Hough transformation and the ImageJ ParticleSizer plug-in), with respect to precision and speed, thereby advancing into regions of human-like performance and reliability.
Image-based model parameter optimisation using Model-Assisted Generative Adversarial Networks
Nov 30, 2018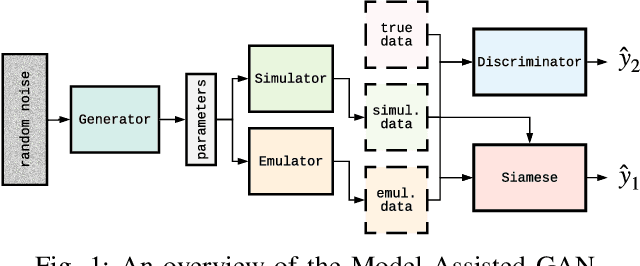
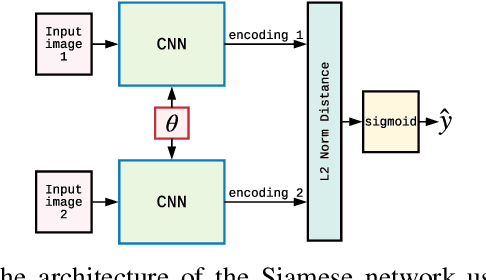
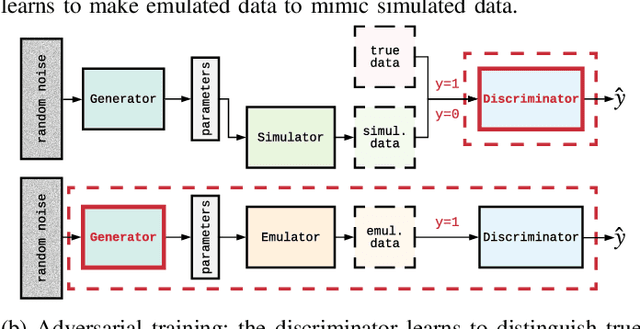
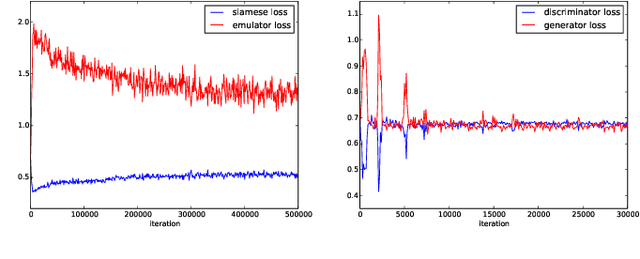
We propose and demonstrate the use of a Model-Assisted Generative Adversarial Network to produce simulated images that accurately match true images through the variation of underlying model parameters that describe the image generation process. The generator learns the parameter values that give images that best match the true images. Two case studies show the excellent agreement between the generated best match parameters and the true parameters. The best match parameter values that produce the most accurate simulated images can be extracted and used to re-tune the default simulation to minimise any bias when applying image recognition techniques to simulated and true images. In the case of a real-world experiment, the true data is replaced by experimental data with unknown true parameter values. The Model-Assisted Generative Adversarial Network uses a convolutional neural network to emulate the simulation for all parameter values that, when trained, can be used as a conditional generator for fast image production.
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss
Jun 08, 2021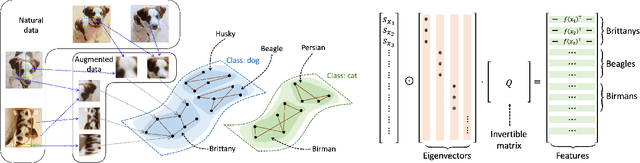
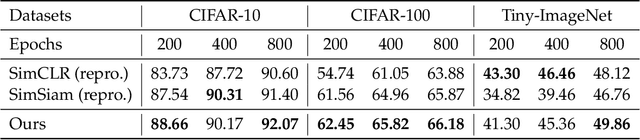
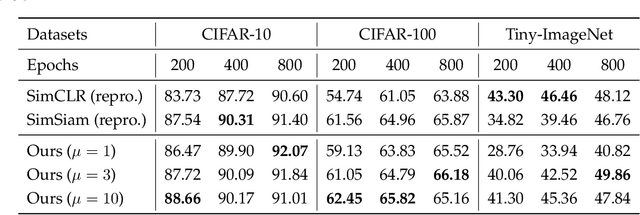
Recent works in self-supervised learning have advanced the state-of-the-art by relying on the contrastive learning paradigm, which learns representations by pushing positive pairs, or similar examples from the same class, closer together while keeping negative pairs far apart. Despite the empirical successes, theoretical foundations are limited -- prior analyses assume conditional independence of the positive pairs given the same class label, but recent empirical applications use heavily correlated positive pairs (i.e., data augmentations of the same image). Our work analyzes contrastive learning without assuming conditional independence of positive pairs using a novel concept of the augmentation graph on data. Edges in this graph connect augmentations of the same data, and ground-truth classes naturally form connected sub-graphs. We propose a loss that performs spectral decomposition on the population augmentation graph and can be succinctly written as a contrastive learning objective on neural net representations. Minimizing this objective leads to features with provable accuracy guarantees under linear probe evaluation. By standard generalization bounds, these accuracy guarantees also hold when minimizing the training contrastive loss. Empirically, the features learned by our objective can match or outperform several strong baselines on benchmark vision datasets. In all, this work provides the first provable analysis for contrastive learning where guarantees for linear probe evaluation can apply to realistic empirical settings.
Maximal function pooling with applications
Mar 01, 2021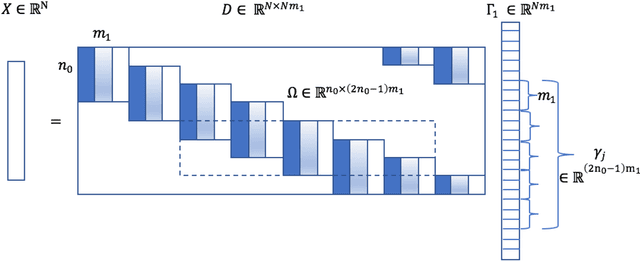

Inspired by the Hardy-Littlewood maximal function, we propose a novel pooling strategy which is called maxfun pooling. It is presented both as a viable alternative to some of the most popular pooling functions, such as max pooling and average pooling, and as a way of interpolating between these two algorithms. We demonstrate the features of maxfun pooling with two applications: first in the context of convolutional sparse coding, and then for image classification.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
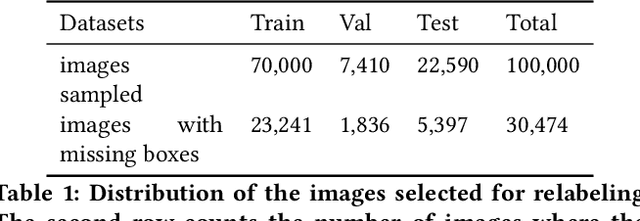
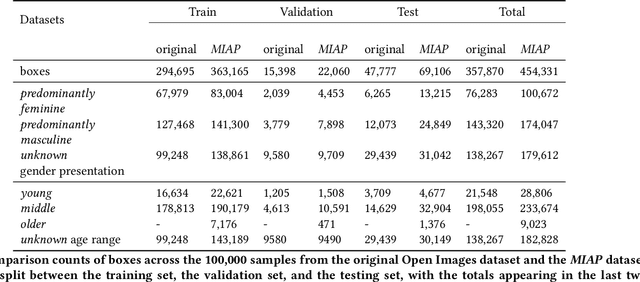
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
Recurrent Multiresolution Convolutional Networks for VHR Image Classification
Jun 15, 2018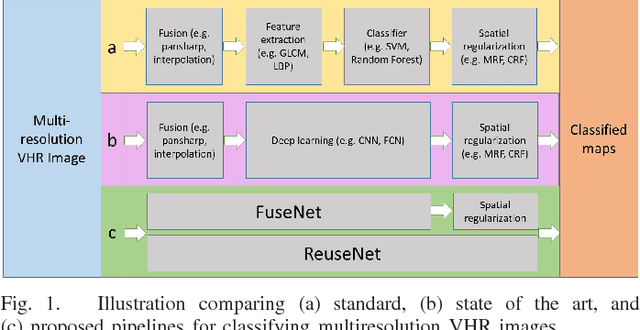
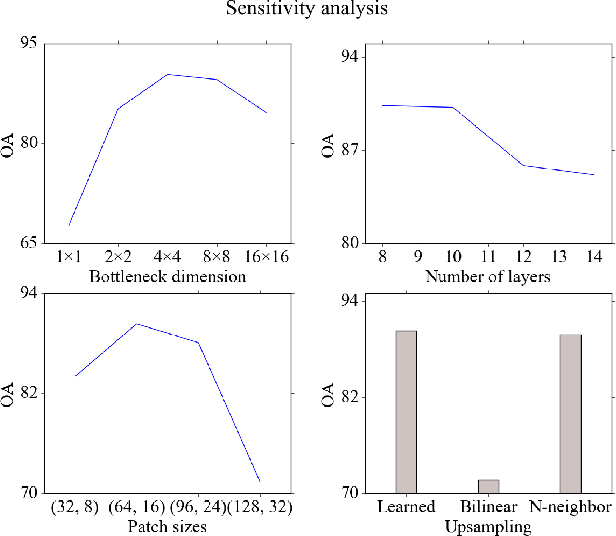
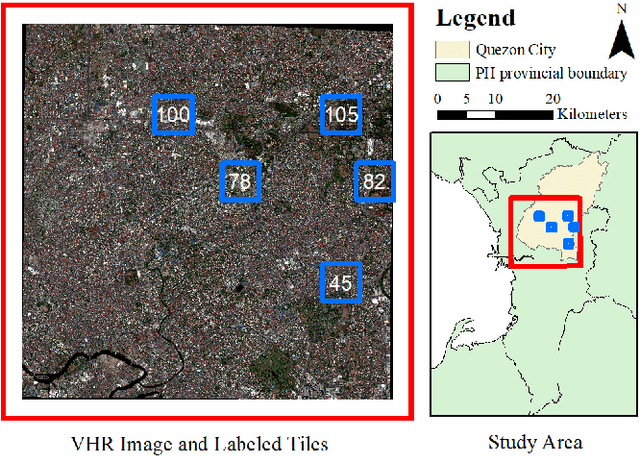
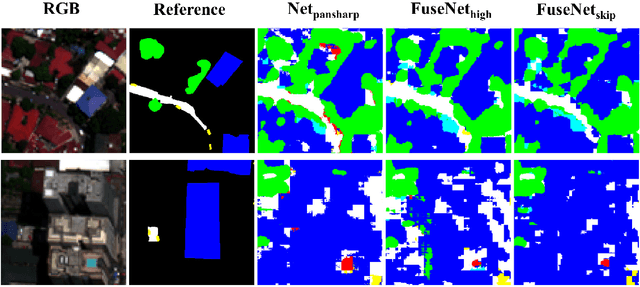
Classification of very high resolution (VHR) satellite images has three major challenges: 1) inherent low intra-class and high inter-class spectral similarities, 2) mismatching resolution of available bands, and 3) the need to regularize noisy classification maps. Conventional methods have addressed these challenges by adopting separate stages of image fusion, feature extraction, and post-classification map regularization. These processing stages, however, are not jointly optimizing the classification task at hand. In this study, we propose a single-stage framework embedding the processing stages in a recurrent multiresolution convolutional network trained in an end-to-end manner. The feedforward version of the network, called FuseNet, aims to match the resolution of the panchromatic and multispectral bands in a VHR image using convolutional layers with corresponding downsampling and upsampling operations. Contextual label information is incorporated into FuseNet by means of a recurrent version called ReuseNet. We compared FuseNet and ReuseNet against the use of separate processing steps for both image fusion, e.g. pansharpening and resampling through interpolation, and map regularization such as conditional random fields. We carried out our experiments on a land cover classification task using a Worldview-03 image of Quezon City, Philippines and the ISPRS 2D semantic labeling benchmark dataset of Vaihingen, Germany. FuseNet and ReuseNet surpass the baseline approaches in both quantitative and qualitative results.
RadioNet: Transformer based Radio Map Prediction Model For Dense Urban Environments
May 15, 2021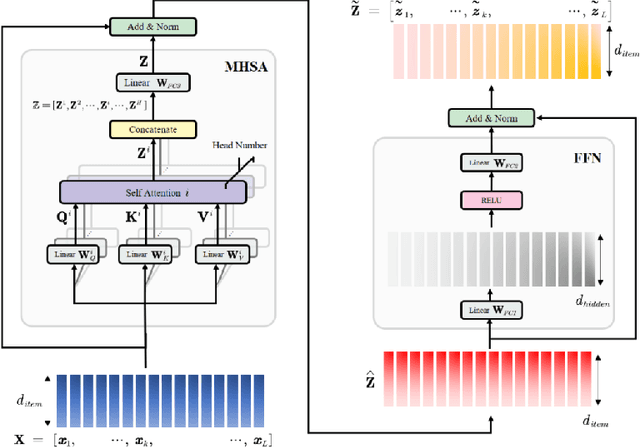
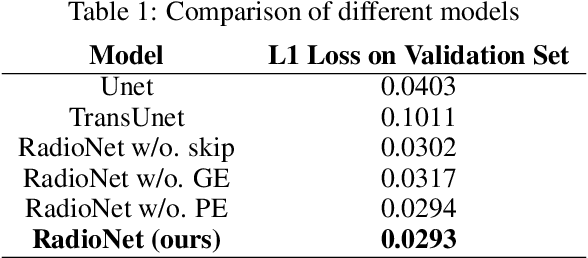
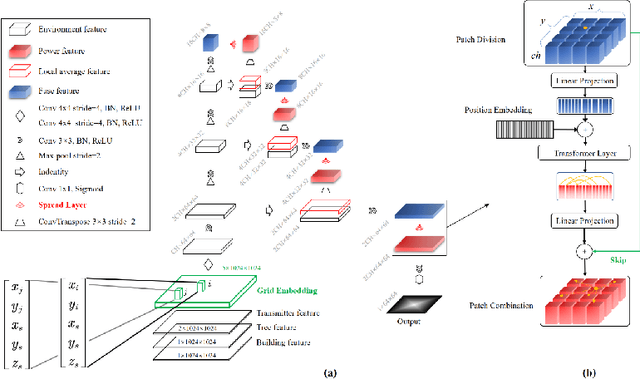

Radio Map Prediction (RMP), aiming at estimating coverage of radio wave, has been widely recognized as an enabling technology for improving radio spectrum efficiency. However, fast and reliable radio map prediction can be very challenging due to the complicated interaction between radio waves and the environment. In this paper, a novel Transformer based deep learning model termed as RadioNet is proposed for radio map prediction in urban scenarios. In addition, a novel Grid Embedding technique is proposed to substitute the original Position Embedding in Transformer to better anchor the relative position of the radiation source, destination and environment. The effectiveness of proposed method is verified on an urban radio wave propagation dataset. Compared with the SOTA model on RMP task, RadioNet reduces the validation loss by 27.3\%, improves the prediction reliability from 90.9\% to 98.9\%. The prediction speed is increased by 4 orders of magnitude, when compared with ray-tracing based method. We believe that the proposed method will be beneficial to high-efficiency wireless communication, real-time radio visualization, and even high-speed image rendering.
CEL-Net: Continuous Exposure for Extreme Low-Light Imaging
Dec 07, 2020



Deep learning methods for enhancing dark images learn a mapping from input images to output images with pre-determined discrete exposure levels. Often, at inference time the input and optimal output exposure levels of the given image are different from the seen ones during training. As a result the enhanced image might suffer from visual distortions, such as low contrast or dark areas. We address this issue by introducing a deep learning model that can continuously generalize at inference time to unseen exposure levels without the need to retrain the model. To this end, we introduce a dataset of 1500 raw images captured in both outdoor and indoor scenes, with five different exposure levels and various camera parameters. Using the dataset, we develop a model for extreme low-light imaging that can continuously tune the input or output exposure level of the image to an unseen one. We investigate the properties of our model and validate its performance, showing promising results.
Blind Image Deconvolution using Deep Generative Priors
Mar 15, 2018

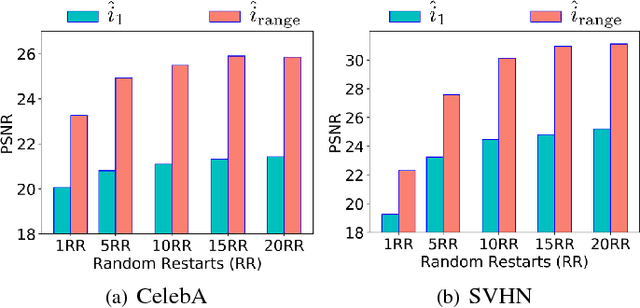
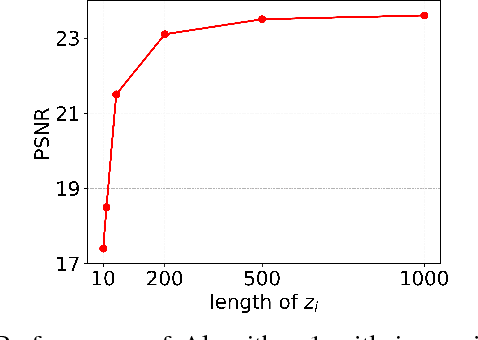
This paper proposes a new framework to regularize the \textit{ill-posed} and \textit{non-linear} blind image deconvolution problem by using deep generative priors. We employ two separate deep generative models --- one trained to produce sharp images while the other trained to generate blur kernels from lower-dimensional parameters. The regularized problem is efficiently solved by simple alternating gradient descent algorithm operating in the latent lower-dimensional space of each generative model. We empirically show that by doing so, excellent image deblurring results are achieved even under extravagantly large blurs, and heavy noise. Our proposed method is in stark contrast to the conventional end-to-end approaches, where a deep neural network is trained on blurred input, and the corresponding sharp output images while completely ignoring the knowledge of the underlying forward map (convolution operator) in image blurring.
Closer Look at the Uncertainty Estimation in Semantic Segmentation under Distributional Shift
May 31, 2021
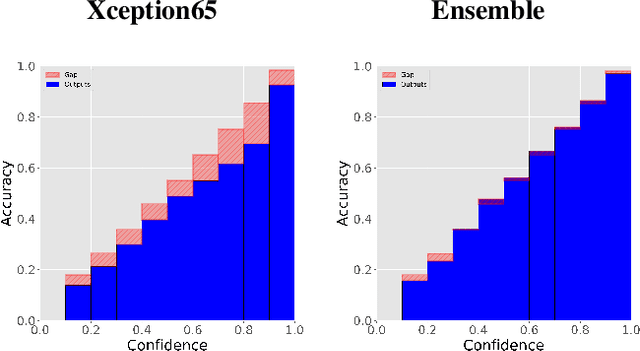
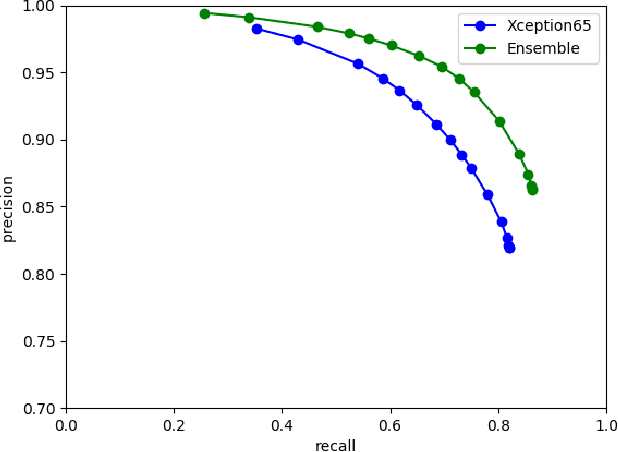

While recent computer vision algorithms achieve impressive performance on many benchmarks, they lack robustness - presented with an image from a different distribution, (e.g. weather or lighting conditions not considered during training), they may produce an erroneous prediction. Therefore, it is desired that such a model will be able to reliably predict its confidence measure. In this work, uncertainty estimation for the task of semantic segmentation is evaluated under a varying level of domain shift: in a cross-dataset setting and when adapting a model trained on data from the simulation. It was shown that simple color transformations already provide a strong baseline, comparable to using more sophisticated style-transfer data augmentation. Further, by constructing an ensemble consisting of models using different backbones and/or augmentation methods, it was possible to improve significantly model performance in terms of overall accuracy and uncertainty estimation under the domain shift setting. The Expected Calibration Error (ECE) on challenging GTA to Cityscapes adaptation was reduced from 4.05 to the competitive value of 1.1. Further, an ensemble of models was utilized in the self-training setting to improve the pseudo-labels generation, which resulted in a significant gain in the final model accuracy, compared to the standard fine-tuning (without ensemble).