 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bimodal network architectures for automatic generation of image annotation from text
Sep 05, 2018
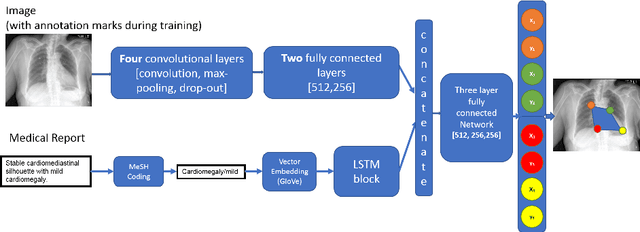

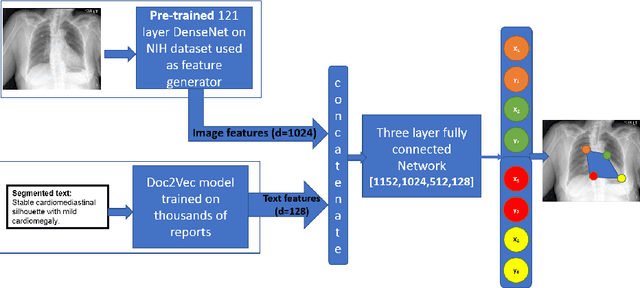
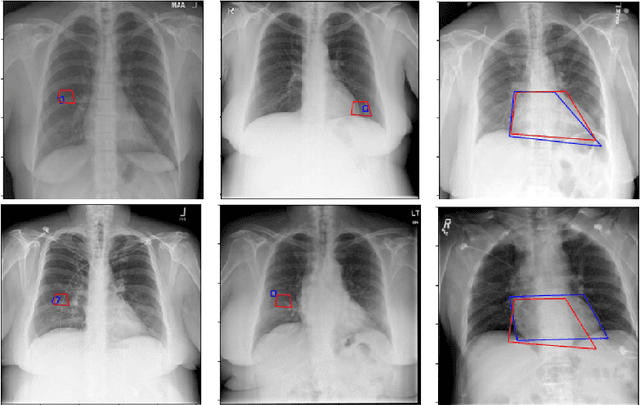
Medical image analysis practitioners have embraced big data methodologies. This has created a need for large annotated datasets. The source of big data is typically large image collections and clinical reports recorded for these images. In many cases, however, building algorithms aimed at segmentation and detection of disease requires a training dataset with markings of the areas of interest on the image that match with the described anomalies. This process of annotation is expensive and needs the involvement of clinicians. In this work we propose two separate deep neural network architectures for automatic marking of a region of interest (ROI) on the image best representing a finding location, given a textual report or a set of keywords. One architecture consists of LSTM and CNN components and is trained end to end with images, matching text, and markings of ROIs for those images. The output layer estimates the coordinates of the vertices of a polygonal region. The second architecture uses a network pre-trained on a large dataset of the same image types for learning feature representations of the findings of interest. We show that for a variety of findings from chest X-ray images, both proposed architectures learn to estimate the ROI, as validated by clinical annotations. There is a clear advantage obtained from the architecture with pre-trained imaging network. The centroids of the ROIs marked by this network were on average at a distance equivalent to 5.1% of the image width from the centroids of the ground truth ROIs.
* Accepted to MICCAI 2018, LNCS 11070
Evaluating Generalization Ability of Convolutional Neural Networks and Capsule Networks for Image Classification via Top-2 Classification
Jan 29, 2019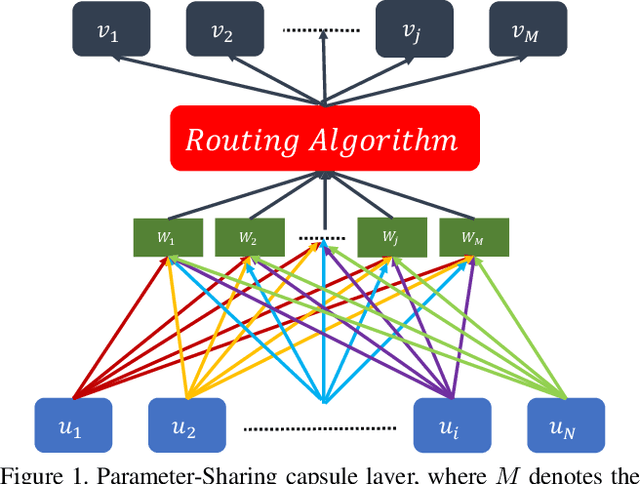
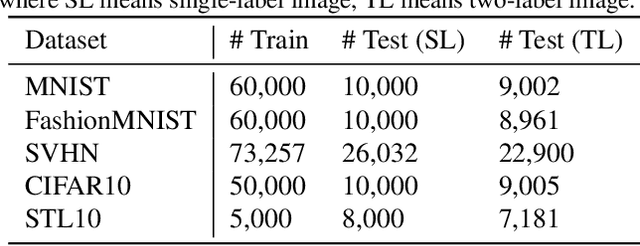


Image classification is a challenging problem which aims to identify the category of object in the image. In recent years, deep Convolutional Neural Networks (CNNs) have been applied to handle this task, and impressive improvement has been achieved. However, some research showed the output of CNNs can be easily altered by adding relatively small perturbations to the input image, such as modifying few pixels. Recently, Capsule Networks (CapsNets) are proposed, which can help eliminating this limitation. Experiments on MNIST dataset revealed that capsules can better characterize the features of object than CNNs. But it's hard to find a suitable quantitative method to compare the generalization ability of CNNs and CapsNets. In this paper, we propose a new image classification task called Top-2 classification to evaluate the generalization ability of CNNs and CapsNets. The models are trained on single label image samples same as the traditional image classification task. But in the test stage, we randomly concatenate two test image samples which contain different labels, and then use the trained models to predict the top-2 labels on the unseen newly-created two label image samples. This task can provide us precise quantitative results to compare the generalization ability of CNNs and CapsNets. Back to the CapsNet, because it uses Full Connectivity (FC) mechanism among all capsules, it requires many parameters. To reduce the number of parameters, we introduce the Parameter-Sharing (PS) mechanism between capsules. Experiments on five widely used benchmark image datasets demonstrate the method significantly reduces the number of parameters, without losing the effectiveness of extracting features. Further, on the Top-2 classification task, the proposed PS CapsNets obtain impressive higher accuracy compared to the traditional CNNs and FC CapsNets by a large margin.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 10, 2021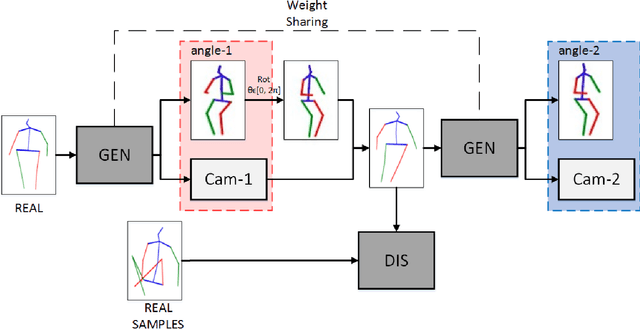
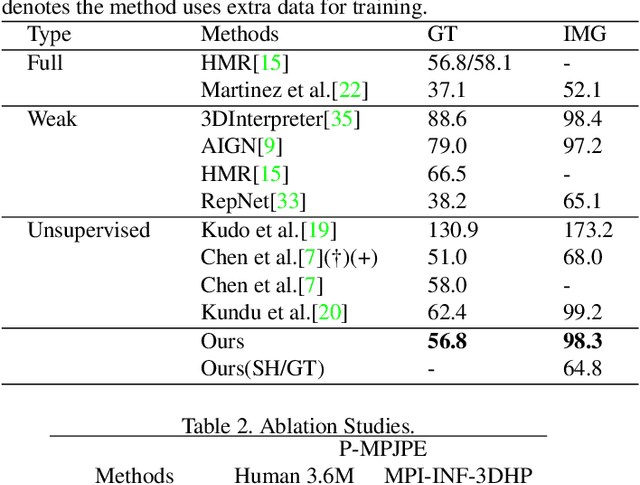
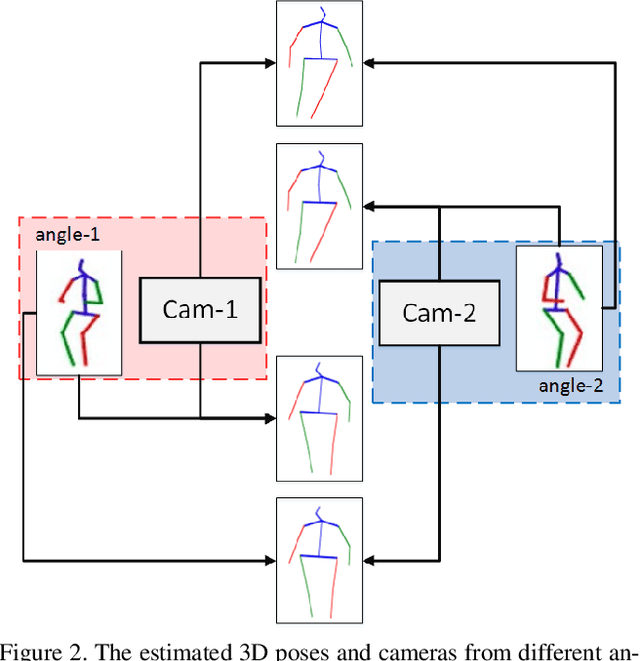
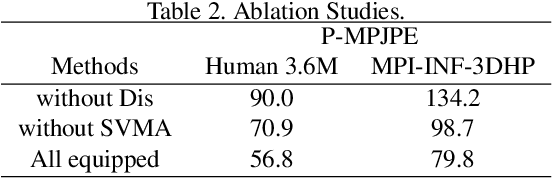
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.
Disease Forecast via Progression Learning
Dec 21, 2020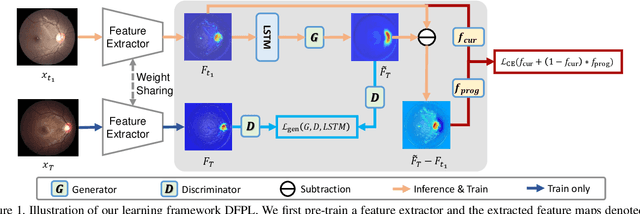
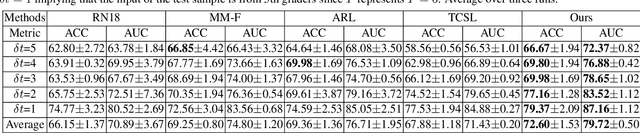

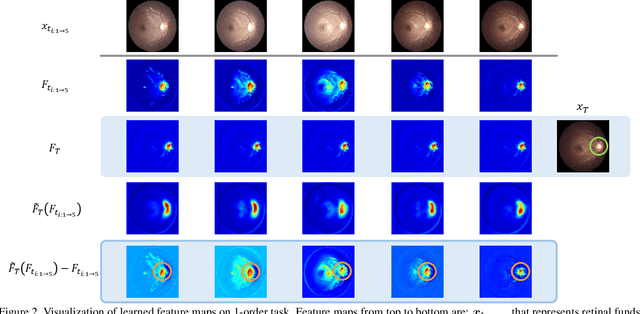
Forecasting Parapapillary atrophy (PPA), i.e., a symptom related to most irreversible eye diseases, provides an alarm for implementing an intervention to slow down the disease progression at early stage. A key question for this forecast is: how to fully utilize the historical data (e.g., retinal image) up to the current stage for future disease prediction? In this paper, we provide an answer with a novel framework, namely \textbf{D}isease \textbf{F}orecast via \textbf{P}rogression \textbf{L}earning (\textbf{DFPL}), which exploits the irreversibility prior (i.e., cannot be reversed once diagnosed). Specifically, based on this prior, we decompose two factors that contribute to the prediction of the future disease: i) the current disease label given the data (retinal image, clinical attributes) at present and ii) the future disease label given the progression of the retinal images that from the current to the future. To model these two factors, we introduce the current and progression predictors in DFPL, respectively. In order to account for the degree of progression of the disease, we propose a temporal generative model to accurately generate the future image and compare it with the current one to get a residual image. The generative model is implemented by a recurrent neural network, in order to exploit the dependency of the historical data. To verify our approach, we apply it to a PPA in-house dataset and it yields a significant improvement (\textit{e.g.}, \textbf{4.48\%} of accuracy; \textbf{3.45\%} of AUC) over others. Besides, our generative model can accurately localize the disease-related regions.
Cross-Level Cross-Scale Cross-Attention Network for Point Cloud Representation
Apr 27, 2021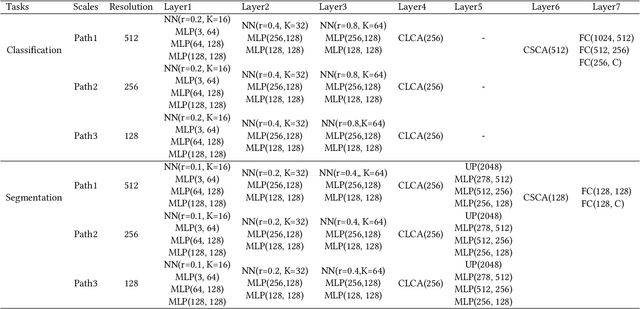
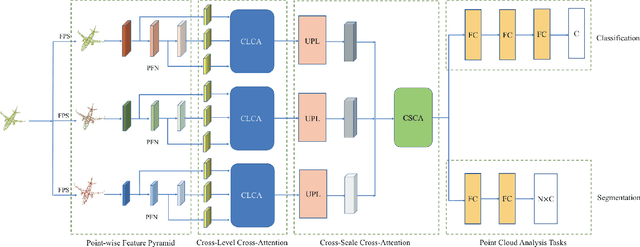
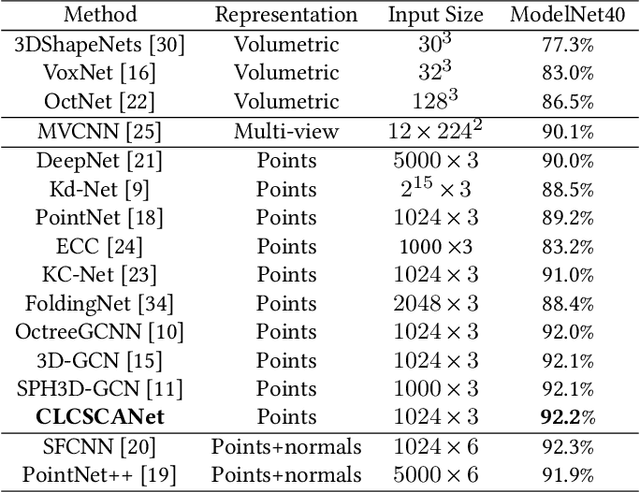
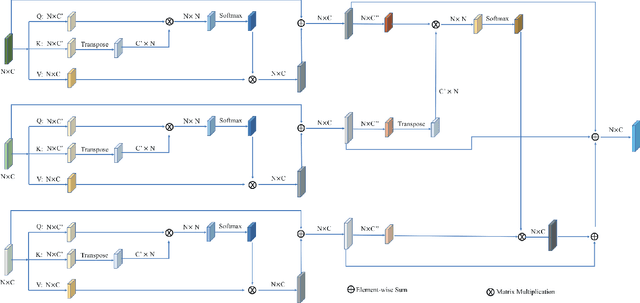
Self-attention mechanism recently achieves impressive advancement in Natural Language Processing (NLP) and Image Processing domains. And its permutation invariance property makes it ideally suitable for point cloud processing. Inspired by this remarkable success, we propose an end-to-end architecture, dubbed Cross-Level Cross-Scale Cross-Attention Network (CLCSCANet), for point cloud representation learning. First, a point-wise feature pyramid module is introduced to hierarchically extract features from different scales or resolutions. Then a cross-level cross-attention is designed to model long-range inter-level and intra-level dependencies. Finally, we develop a cross-scale cross-attention module to capture interactions between-and-within scales for representation enhancement. Compared with state-of-the-art approaches, our network can obtain competitive performance on challenging 3D object classification, point cloud segmentation tasks via comprehensive experimental evaluation.
Dual Transformer for Point Cloud Analysis
Apr 27, 2021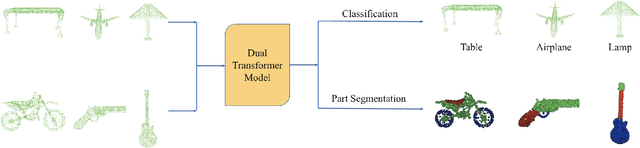
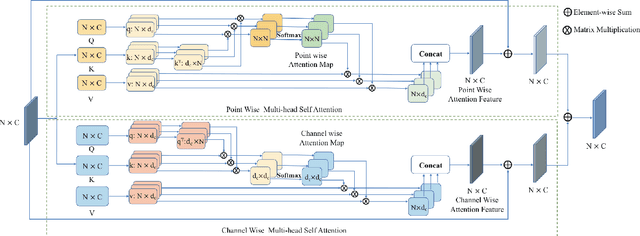
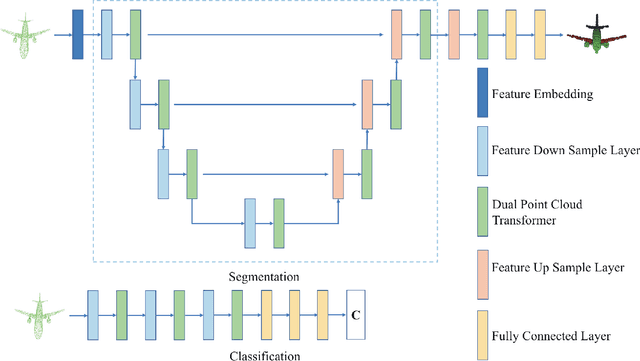

Following the tremendous success of transformer in natural language processing and image understanding tasks, in this paper, we present a novel point cloud representation learning architecture, named Dual Transformer Network (DTNet), which mainly consists of Dual Point Cloud Transformer (DPCT) module. Specifically, by aggregating the well-designed point-wise and channel-wise multi-head self-attention models simultaneously, DPCT module can capture much richer contextual dependencies semantically from the perspective of position and channel. With the DPCT module as a fundamental component, we construct the DTNet for performing point cloud analysis in an end-to-end manner. Extensive quantitative and qualitative experiments on publicly available benchmarks demonstrate the effectiveness of our proposed transformer framework for the tasks of 3D point cloud classification and segmentation, achieving highly competitive performance in comparison with the state-of-the-art approaches.
Heterogeneous Noisy Short Signal Camouflage in Multi-Domain Environment Decision-Making
Jun 02, 2021
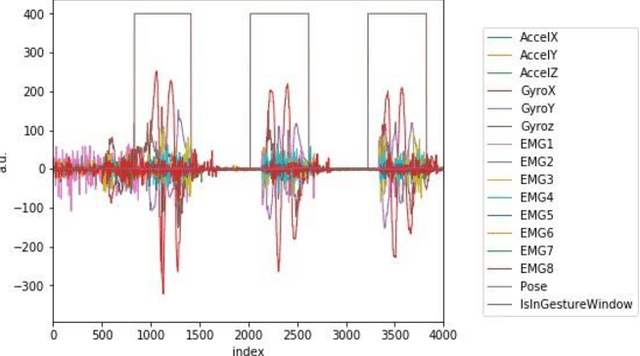
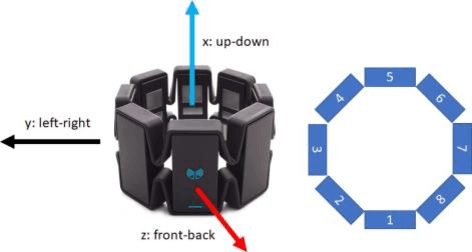
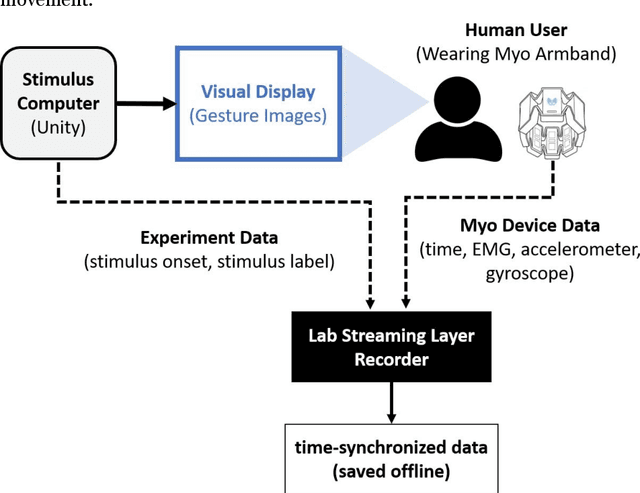
Data transmission between two or more digital devices in industry and government demands secure and agile technology. Digital information distribution often requires deployment of Internet of Things (IoT) devices and Data Fusion techniques which have also gained popularity in both, civilian and military environments, such as, emergence of Smart Cities and Internet of Battlefield Things (IoBT). This usually requires capturing and consolidating data from multiple sources. Because datasets do not necessarily originate from identical sensors, fused data typically results in a complex Big Data problem. Due to potentially sensitive nature of IoT datasets, Blockchain technology is used to facilitate secure sharing of IoT datasets, which allows digital information to be distributed, but not copied. However, blockchain has several limitations related to complexity, scalability, and excessive energy consumption. We propose an approach to hide information (sensor signal) by transforming it to an image or an audio signal. In one of the latest attempts to the military modernization, we investigate sensor fusion approach by investigating the challenges of enabling an intelligent identification and detection operation and demonstrates the feasibility of the proposed Deep Learning and Anomaly Detection models that can support future application for specific hand gesture alert system from wearable devices.
* Published at: http://www.ibai-publishing.org/journal/issue_massdata/2020_september/massdata_11_1_3_26.php. arXiv admin note: substantial text overlap with arXiv:2106.01497
A Hitchhiker's Guide to Structural Similarity
Jan 16, 2021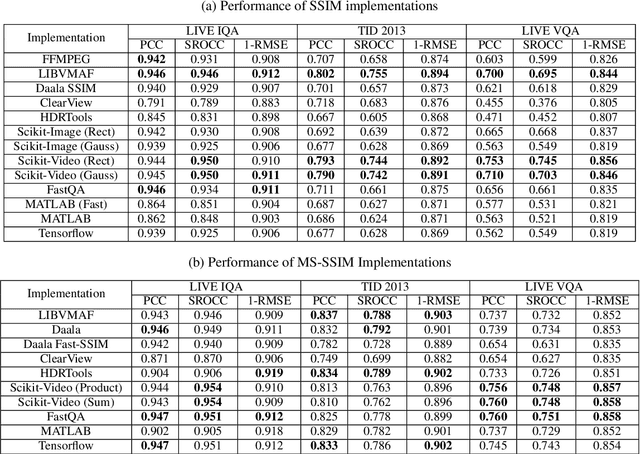
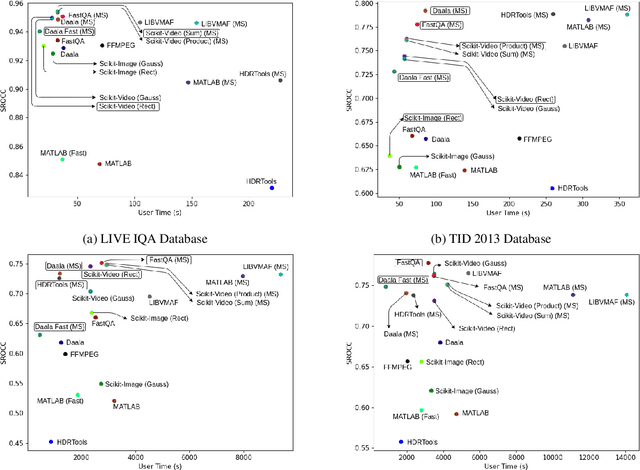
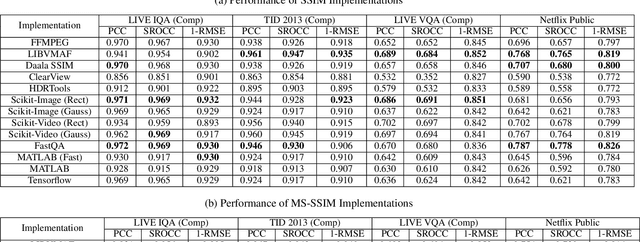
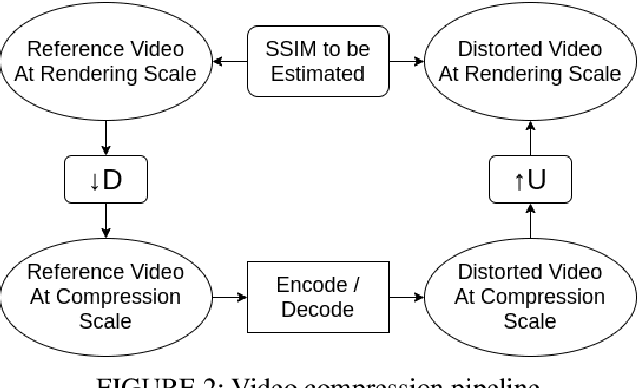
The Structural Similarity (SSIM) Index is a very widely used image/video quality model that continues to play an important role in the perceptual evaluation of compression algorithms, encoding recipes and numerous other image/video processing algorithms. Several public implementations of the SSIM and Multiscale-SSIM (MS-SSIM) algorithms have been developed, which differ in efficiency and performance. This "bendable ruler" makes the process of quality assessment of encoding algorithms unreliable. To address this situation, we studied and compared the functions and performances of popular and widely used implementations of SSIM, and we also considered a variety of design choices. Based on our studies and experiments, we have arrived at a collection of recommendations on how to use SSIM most effectively, including ways to reduce its computational burden.
Adapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution
May 07, 2019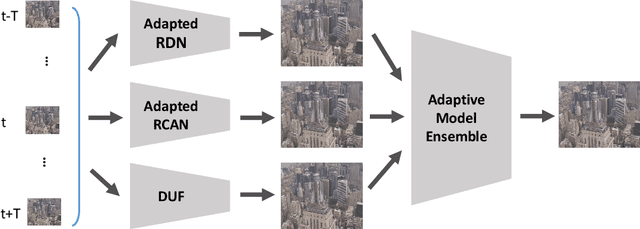
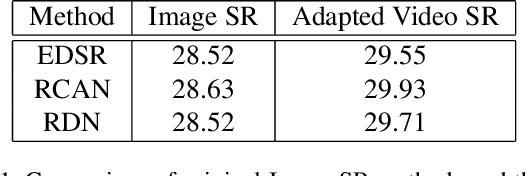
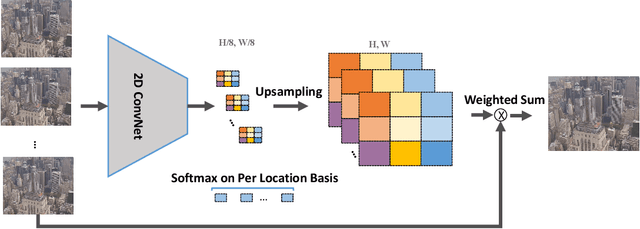
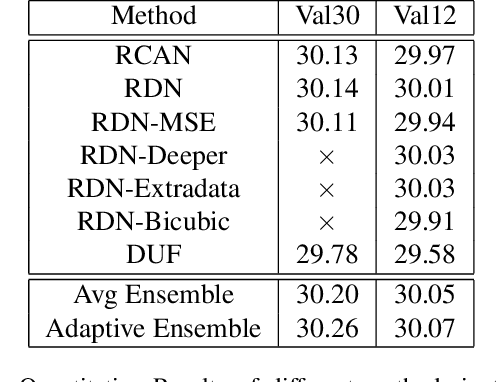
Recently, image super-resolution has been widely studied and achieved significant progress by leveraging the power of deep convolutional neural networks. However, there has been limited advancement in video super-resolution (VSR) due to the complex temporal patterns in videos. In this paper, we investigate how to adapt state-of-the-art methods of image super-resolution for video super-resolution. The proposed adapting method is straightforward. The information among successive frames is well exploited, while the overhead on the original image super-resolution method is negligible. Furthermore, we propose a learning-based method to ensemble the outputs from multiple super-resolution models. Our methods show superior performance and rank second in the NTIRE2019 Video Super-Resolution Challenge Track 1.
Multimodal Fusion with BERT and Attention Mechanism for Fake News Detection
Apr 27, 2021
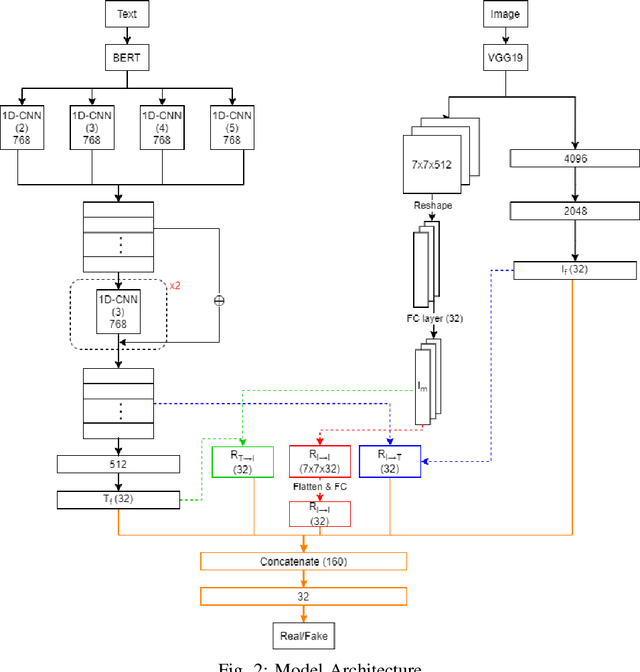
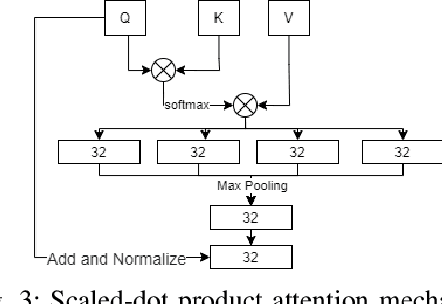

Fake news detection is an important task for increasing the credibility of information on the media since fake news is constantly spreading on social media every day and it is a very serious concern in our society. Fake news is usually created by manipulating images, texts, and videos. In this paper, we present a novel method for detecting fake news by fusing multimodal features derived from textual and visual data. Specifically, we used a pre-trained BERT model to learn text features and a VGG-19 model pre-trained on the ImageNet dataset to extract image features. We proposed a scale-dot product attention mechanism to capture the relationship between text features and visual features. Experimental results showed that our approach performs better than the current state-of-the-art method on a public Twitter dataset by 3.1% accuracy.