 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 10, 2021
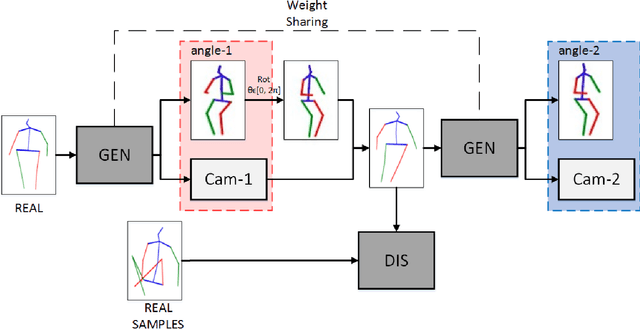
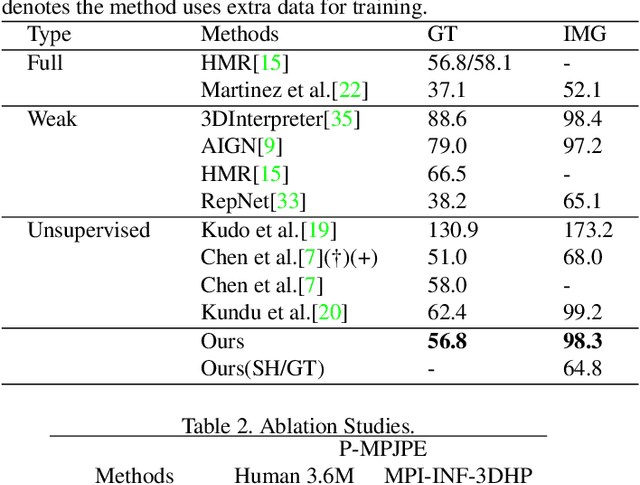
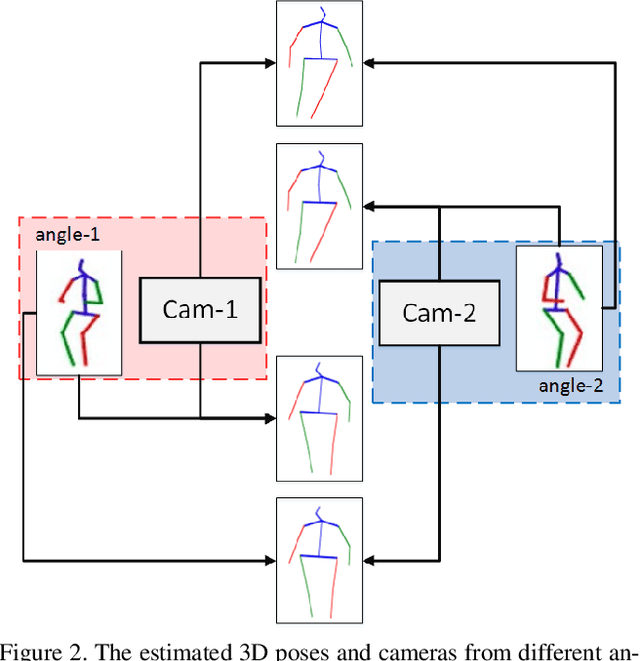
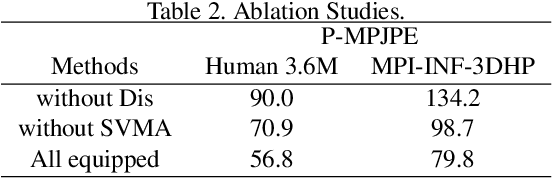
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.
Generative Adversarial Transformers
Mar 02, 2021
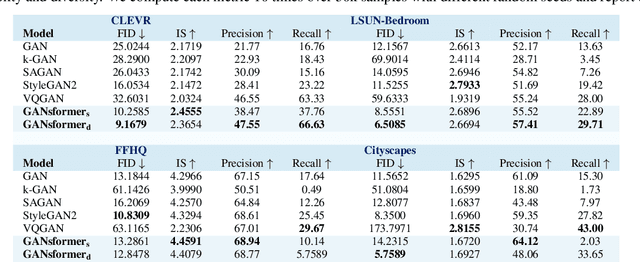
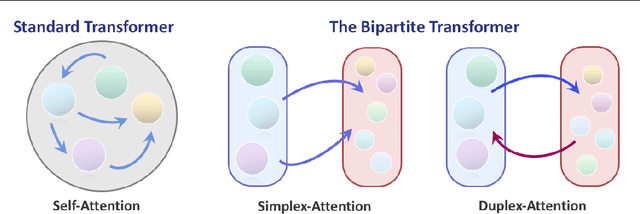
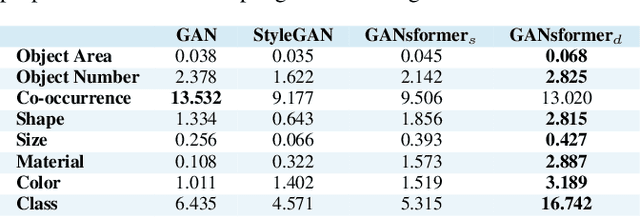
We introduce the GANsformer, a novel and efficient type of transformer, and explore it for the task of visual generative modeling. The network employs a bipartite structure that enables long-range interactions across the image, while maintaining computation of linearly efficiency, that can readily scale to high-resolution synthesis. It iteratively propagates information from a set of latent variables to the evolving visual features and vice versa, to support the refinement of each in light of the other and encourage the emergence of compositional representations of objects and scenes. In contrast to the classic transformer architecture, it utilizes multiplicative integration that allows flexible region-based modulation, and can thus be seen as a generalization of the successful StyleGAN network. We demonstrate the model's strength and robustness through a careful evaluation over a range of datasets, from simulated multi-object environments to rich real-world indoor and outdoor scenes, showing it achieves state-of-the-art results in terms of image quality and diversity, while enjoying fast learning and better data-efficiency. Further qualitative and quantitative experiments offer us an insight into the model's inner workings, revealing improved interpretability and stronger disentanglement, and illustrating the benefits and efficacy of our approach. An implementation of the model is available at https://github.com/dorarad/gansformer.
ISETAuto: Detecting vehicles with depth and radiance information
Jan 06, 2021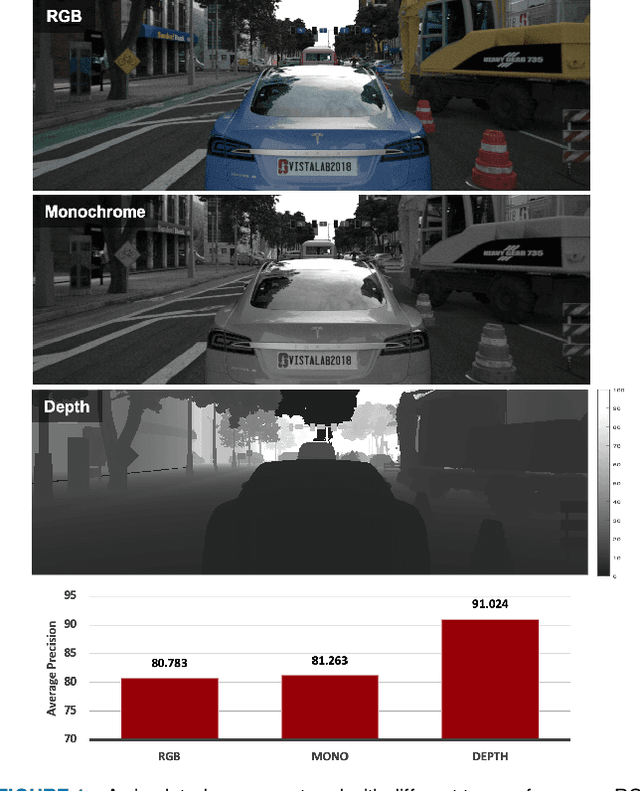

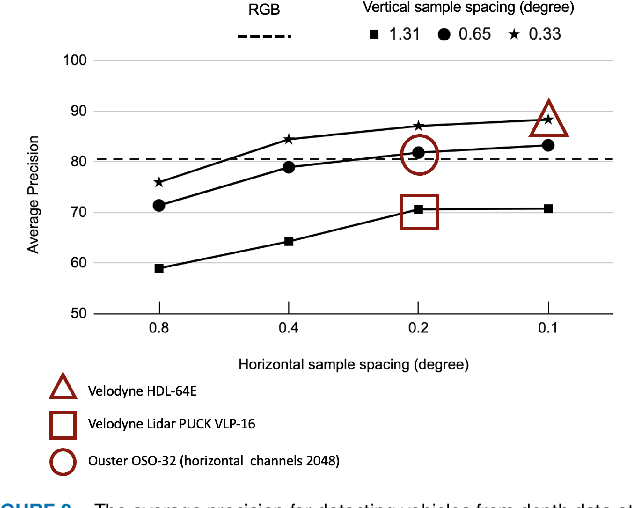
Autonomous driving applications use two types of sensor systems to identify vehicles - depth sensing LiDAR and radiance sensing cameras. We compare the performance (average precision) of a ResNet for vehicle detection in complex, daytime, driving scenes when the input is a depth map (D = d(x,y)), a radiance image (L = r(x,y)), or both [D,L]. (1) When the spatial sampling resolution of the depth map and radiance image are equal to typical camera resolutions, a ResNet detects vehicles at higher average precision from depth than radiance. (2) As the spatial sampling of the depth map declines to the range of current LiDAR devices, the ResNet average precision is higher for radiance than depth. (3) For a hybrid system that combines a depth map and radiance image, the average precision is higher than using depth or radiance alone. We established these observations in simulation and then confirmed them using realworld data. The advantage of combining depth and radiance can be explained by noting that the two type of information have complementary weaknesses. The radiance data are limited by dynamic range and motion blur. The LiDAR data have relatively low spatial resolution. The ResNet combines the two data sources effectively to improve overall vehicle detection.
Gaze-based dual resolution deep imitation learning for high-precision dexterous robot manipulation
Feb 02, 2021
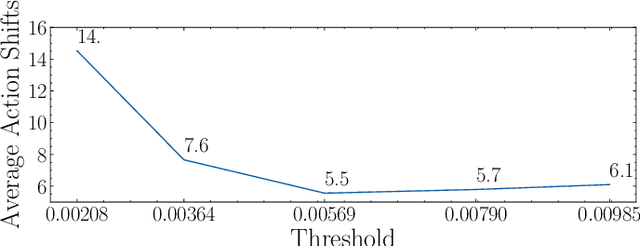

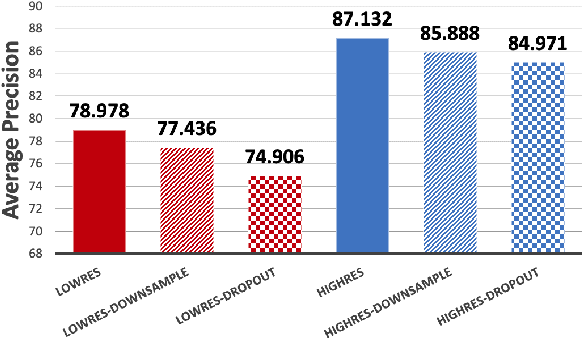
A high-precision manipulation task, such as needle threading, is challenging. Physiological studies have proposed connecting low-resolution peripheral vision and fast movement to transport the hand into the vicinity of an object, and using high-resolution foveated vision to achieve the accurate homing of the hand to the object. The results of this study demonstrate that a deep imitation learning based method, inspired by the gaze-based dual resolution visuomotor control system in humans, can solve the needle threading task. First, we recorded the gaze movements of a human operator who was teleoperating a robot. Then, we used only a high-resolution image around the gaze to precisely control the thread position when it was close to the target. We used a low-resolution peripheral image to reach the vicinity of the target. The experimental results obtained in this study demonstrate that the proposed method enables precise manipulation tasks using a general-purpose robot manipulator and improves computational efficiency.
Dual-Path Convolutional Image-Text Embedding with Instance Loss
Jul 17, 2018



Matching images and sentences demands a fine understanding of both modalities. In this paper, we propose a new system to discriminatively embed the image and text to a shared visual-textual space. In this field, most existing works apply the ranking loss to pull the positive image / text pairs close and push the negative pairs apart from each other. However, directly deploying the ranking loss is hard for network learning, since it starts from the two heterogeneous features to build inter-modal relationship. To address this problem, we propose the instance loss which explicitly considers the intra-modal data distribution. It is based on an unsupervised assumption that each image / text group can be viewed as a class. So the network can learn the fine granularity from every image/text group. The experiment shows that the instance loss offers better weight initialization for the ranking loss, so that more discriminative embeddings can be learned. Besides, existing works usually apply the off-the-shelf features, i.e., word2vec and fixed visual feature. So in a minor contribution, this paper constructs an end-to-end dual-path convolutional network to learn the image and text representations. End-to-end learning allows the system to directly learn from the data and fully utilize the supervision. On two generic retrieval datasets (Flickr30k and MSCOCO), experiments demonstrate that our method yields competitive accuracy compared to state-of-the-art methods. Moreover, in language based person retrieval, we improve the state of the art by a large margin. The code has been made publicly available.
Kernel based low-rank sparse model for single image super-resolution
Sep 27, 2018
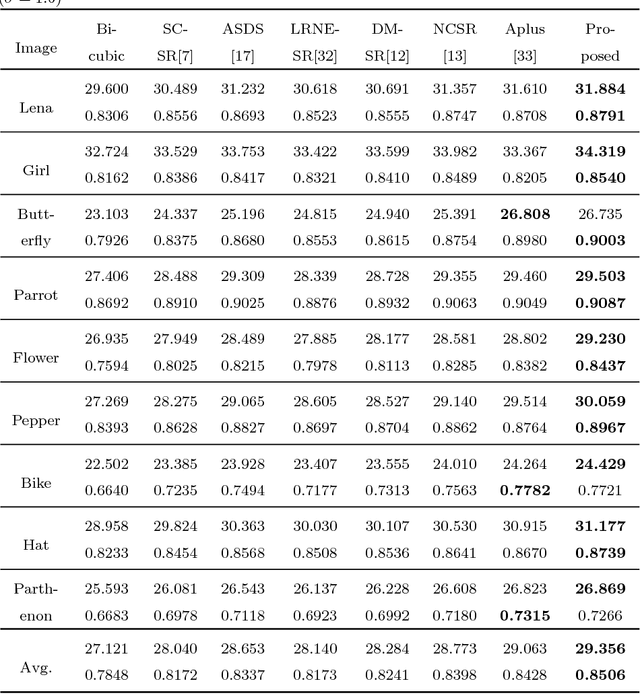
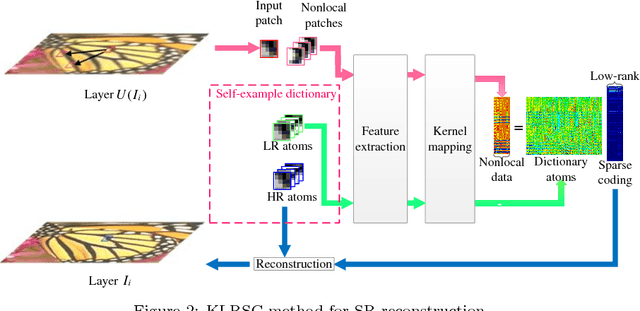
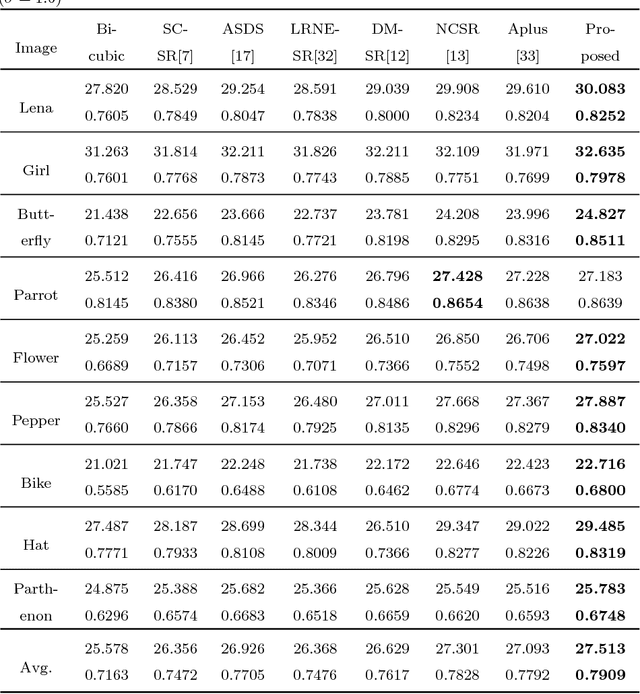
Self-similarity learning has been recognized as a promising method for single image super-resolution (SR) to produce high-resolution (HR) image in recent years. The performance of learning based SR reconstruction, however, highly depends on learned representation coeffcients. Due to the degradation of input image, conventional sparse coding is prone to produce unfaithful representation coeffcients. To this end, we propose a novel kernel based low-rank sparse model with self-similarity learning for single image SR which incorporates nonlocalsimilarity prior to enforce similar patches having similar representation weights. We perform a gradual magnification scheme, using self-examples extracted from the degraded input image and up-scaled versions. To exploit nonlocal-similarity, we concatenate the vectorized input patch and its nonlocal neighbors at different locations into a data matrix which consists of similar components. Then we map the nonlocal data matrix into a high-dimensional feature space by kernel method to capture their nonlinear structures. Under the assumption that the sparse coeffcients for the nonlocal data in the kernel space should be low-rank, we impose low-rank constraint on sparse coding to share similarities among representation coeffcients and remove outliers in order that stable weights for SR reconstruction can be obtained. Experimental results demonstrate the advantage of our proposed method in both visual quality and reconstruction error.
Heterogeneous Noisy Short Signal Camouflage in Multi-Domain Environment Decision-Making
Jun 02, 2021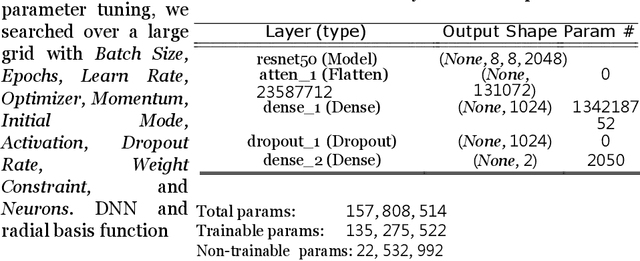
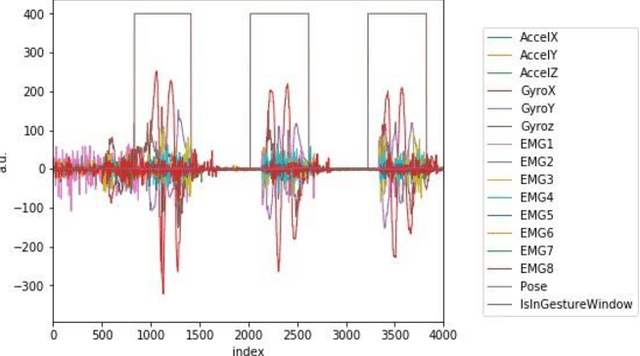
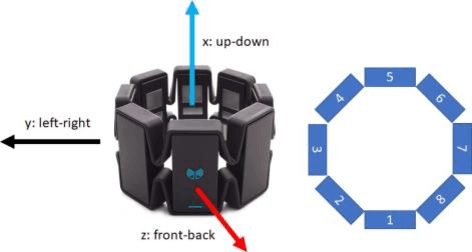
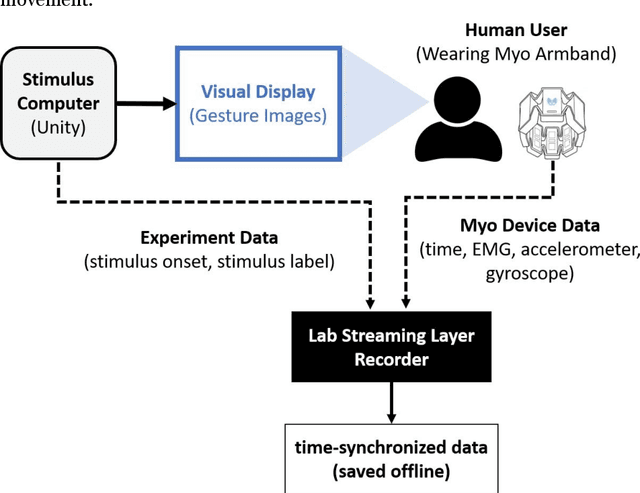
Data transmission between two or more digital devices in industry and government demands secure and agile technology. Digital information distribution often requires deployment of Internet of Things (IoT) devices and Data Fusion techniques which have also gained popularity in both, civilian and military environments, such as, emergence of Smart Cities and Internet of Battlefield Things (IoBT). This usually requires capturing and consolidating data from multiple sources. Because datasets do not necessarily originate from identical sensors, fused data typically results in a complex Big Data problem. Due to potentially sensitive nature of IoT datasets, Blockchain technology is used to facilitate secure sharing of IoT datasets, which allows digital information to be distributed, but not copied. However, blockchain has several limitations related to complexity, scalability, and excessive energy consumption. We propose an approach to hide information (sensor signal) by transforming it to an image or an audio signal. In one of the latest attempts to the military modernization, we investigate sensor fusion approach by investigating the challenges of enabling an intelligent identification and detection operation and demonstrates the feasibility of the proposed Deep Learning and Anomaly Detection models that can support future application for specific hand gesture alert system from wearable devices.
* Published at: http://www.ibai-publishing.org/journal/issue_massdata/2020_september/massdata_11_1_3_26.php. arXiv admin note: substantial text overlap with arXiv:2106.01497
Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation
Apr 16, 2019

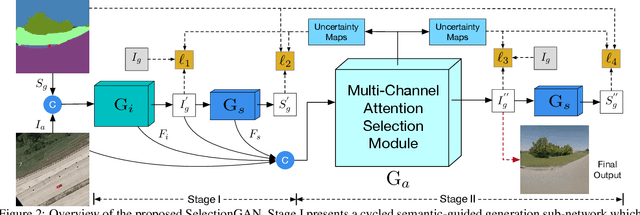
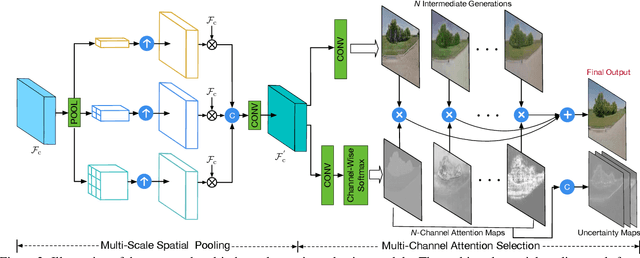
Cross-view image translation is challenging because it involves images with drastically different views and severe deformation. In this paper, we propose a novel approach named Multi-Channel Attention SelectionGAN (SelectionGAN) that makes it possible to generate images of natural scenes in arbitrary viewpoints, based on an image of the scene and a novel semantic map. The proposed SelectionGAN explicitly utilizes the semantic information and consists of two stages. In the first stage, the condition image and the target semantic map are fed into a cycled semantic-guided generation network to produce initial coarse results. In the second stage, we refine the initial results by using a multi-channel attention selection mechanism. Moreover, uncertainty maps automatically learned from attentions are used to guide the pixel loss for better network optimization. Extensive experiments on Dayton, CVUSA and Ego2Top datasets show that our model is able to generate significantly better results than the state-of-the-art methods. The source code, data and trained models are available at https://github.com/Ha0Tang/SelectionGAN.
* 20 pages, 16 figures, accepted to CVPR 2019 as an oral paper
Vector Image Generation by Learning Parametric Layer Decomposition
Dec 13, 2018
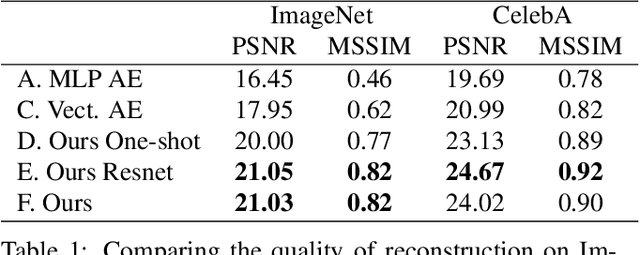
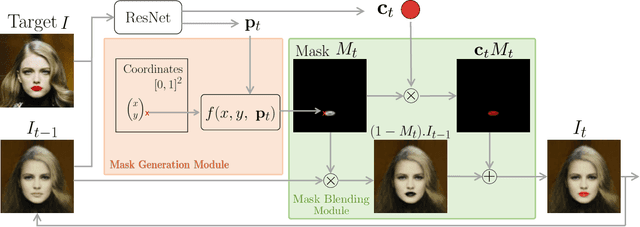
Deep image generation is becoming a tool to enhance artists and designers creativity potential. In this paper, we aim at making the generation process easier to understand and interact with. Inspired by vector graphics systems, we propose a new deep generation paradigm where the images are composed of simple layers, defined by their color and a parametric transparency mask. This presents a number of advantages compared to the commonly used convolutional network architectures. In particular, our layered decomposition allows simple user interaction, for example to update a given mask, or change the color of a selected layer. From a compact code, our architecture also generates images with a virtually infinite resolution, the color at each point in an image being a parametric function of its coordinates. We validate the viability of our approach in the auto-encoding framework by comparing reconstructions with state-of-the-art baselines given similar memory resources on CIFAR10, CelebA and ImageNet datasets and demonstrate several applications. We also show Generative Adversarial Network (GAN) results qualitatively different from the ones obtained with common approaches.
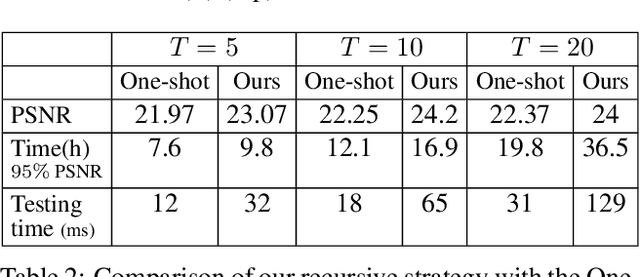
Cross-Level Cross-Scale Cross-Attention Network for Point Cloud Representation
Apr 27, 2021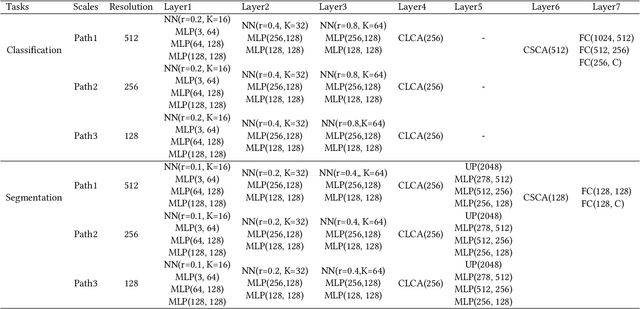
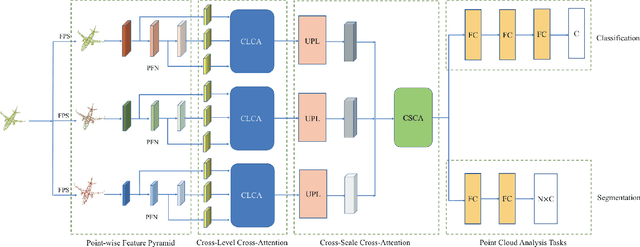
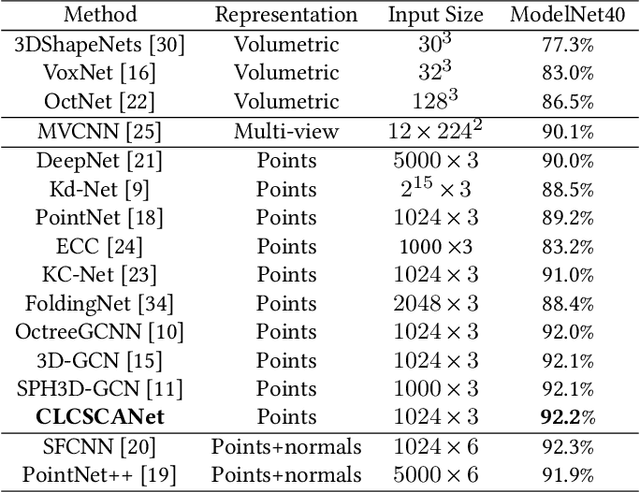
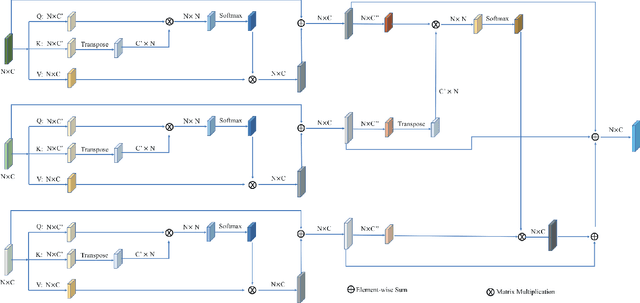
Self-attention mechanism recently achieves impressive advancement in Natural Language Processing (NLP) and Image Processing domains. And its permutation invariance property makes it ideally suitable for point cloud processing. Inspired by this remarkable success, we propose an end-to-end architecture, dubbed Cross-Level Cross-Scale Cross-Attention Network (CLCSCANet), for point cloud representation learning. First, a point-wise feature pyramid module is introduced to hierarchically extract features from different scales or resolutions. Then a cross-level cross-attention is designed to model long-range inter-level and intra-level dependencies. Finally, we develop a cross-scale cross-attention module to capture interactions between-and-within scales for representation enhancement. Compared with state-of-the-art approaches, our network can obtain competitive performance on challenging 3D object classification, point cloud segmentation tasks via comprehensive experimental evaluation.