 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Light-weight pixel context encoders for image inpainting
Jan 17, 2018

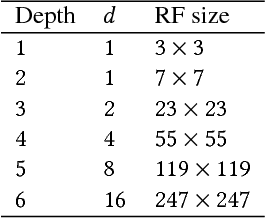

In this work we propose Pixel Content Encoders (PCE), a light-weight image inpainting model, capable of generating novel con-tent for large missing regions in images. Unlike previously presented convolutional neural network based models, our PCE model has an order of magnitude fewer trainable parameters. Moreover, by incorporating dilated convolutions we are able to preserve fine grained spatial information, achieving state-of-the-art performance on benchmark datasets of natural images and paintings. Besides image inpainting, we show that without changing the architecture, PCE can be used for image extrapolation, generating novel content beyond existing image boundaries.
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Jun 20, 2021
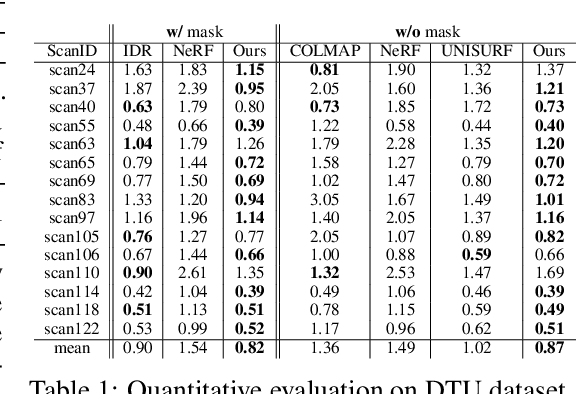
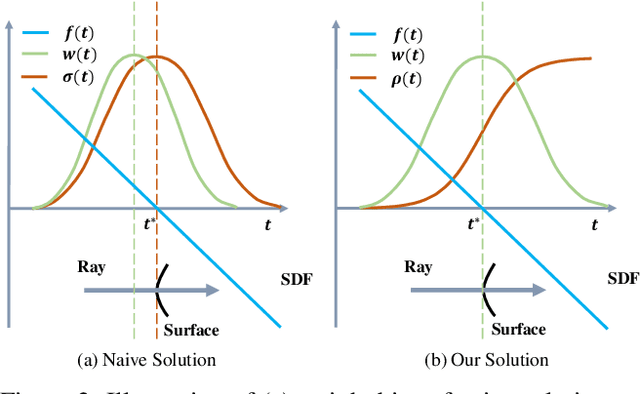
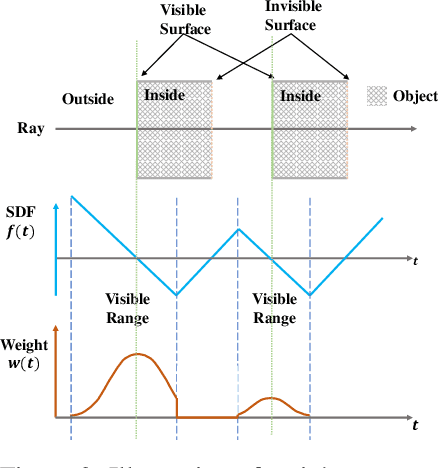
We present a novel neural surface reconstruction method, called NeuS, for reconstructing objects and scenes with high fidelity from 2D image inputs. Existing neural surface reconstruction approaches, such as DVR and IDR, require foreground mask as supervision, easily get trapped in local minima, and therefore struggle with the reconstruction of objects with severe self-occlusion or thin structures. Meanwhile, recent neural methods for novel view synthesis, such as NeRF and its variants, use volume rendering to produce a neural scene representation with robustness of optimization, even for highly complex objects. However, extracting high-quality surfaces from this learned implicit representation is difficult because there are not sufficient surface constraints in the representation. In NeuS, we propose to represent a surface as the zero-level set of a signed distance function (SDF) and develop a new volume rendering method to train a neural SDF representation. We observe that the conventional volume rendering method causes inherent geometric errors (i.e. bias) for surface reconstruction, and therefore propose a new formulation that is free of bias in the first order of approximation, thus leading to more accurate surface reconstruction even without the mask supervision. Experiments on the DTU dataset and the BlendedMVS dataset show that NeuS outperforms the state-of-the-arts in high-quality surface reconstruction, especially for objects and scenes with complex structures and self-occlusion.
FREA-Unet: Frequency-aware U-net for Modality Transfer
Dec 31, 2020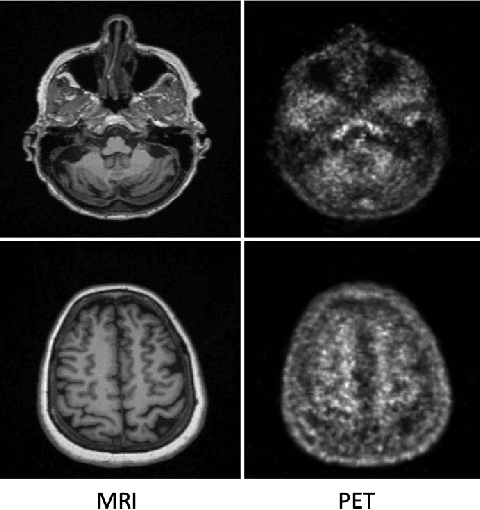
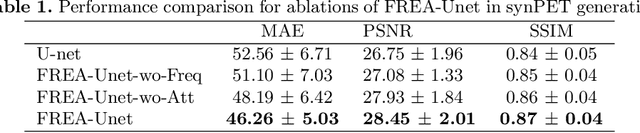
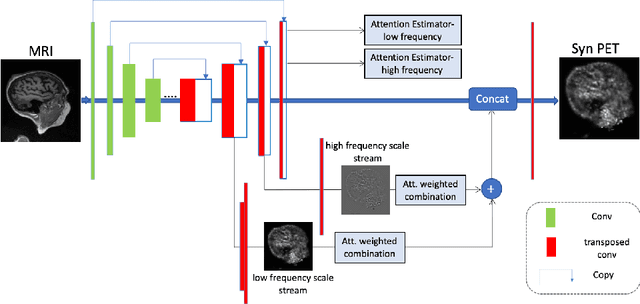

While Positron emission tomography (PET) imaging has been widely used in diagnosis of number of diseases, it has costly acquisition process which involves radiation exposure to patients. However, magnetic resonance imaging (MRI) is a safer imaging modality that does not involve patient's exposure to radiation. Therefore, a need exists for an efficient and automated PET image generation from MRI data. In this paper, we propose a new frequency-aware attention U-net for generating synthetic PET images. Specifically, we incorporate attention mechanism into different U-net layers responsible for estimating low/high frequency scales of the image. Our frequency-aware attention Unet computes the attention scores for feature maps in low/high frequency layers and use it to help the model focus more on the most important regions, leading to more realistic output images. Experimental results on 30 subjects from Alzheimers Disease Neuroimaging Initiative (ADNI) dataset demonstrate good performance of the proposed model in PET image synthesis that achieved superior performance, both qualitative and quantitative, over current state-of-the-arts.
A Pilot Study For Fragment Identification Using 2D NMR and Deep Learning
Mar 18, 2021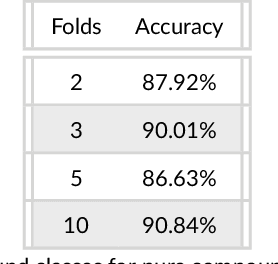
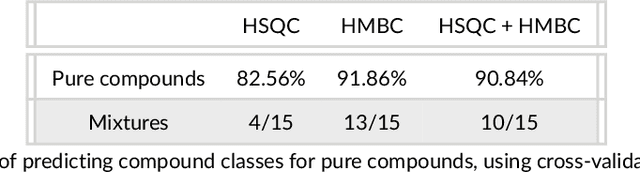
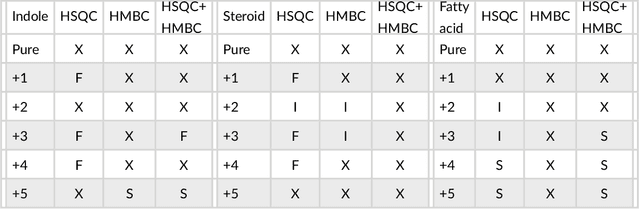
This paper presents a method to identify substructures in NMR spectra of mixtures, specifically 2D spectra, using a bespoke image-based Convolutional Neural Network application. This is done using HSQC and HMBC spectra separately and in combination. The application can reliably detect substructures in pure compounds, using a simple network. It can work for mixtures when trained on pure compounds only. HMBC data and the combination of HMBC and HSQC show better results than HSQC alone.
Mutual Contrastive Learning for Visual Representation Learning
Apr 26, 2021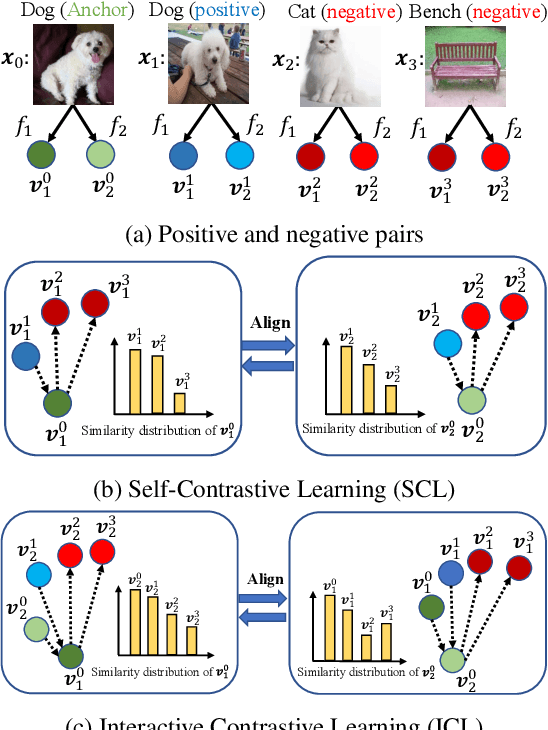
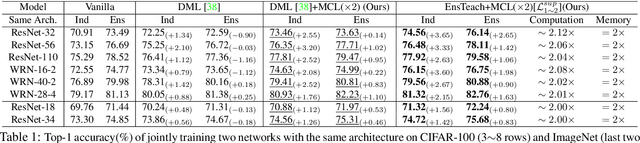
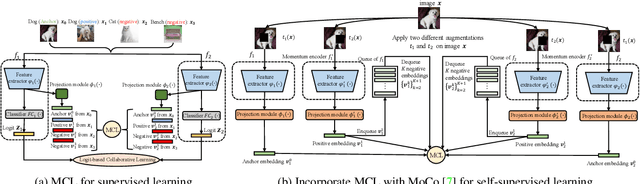
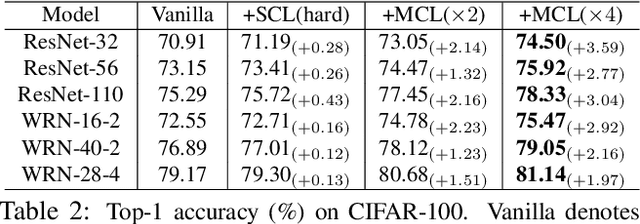
We present a collaborative learning method called Mutual Contrastive Learning (MCL) for general visual representation learning. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of models. Benefiting from MCL, each model can learn extra contrastive knowledge from others, leading to more meaningful feature representations for visual recognition tasks. We emphasize that MCL is conceptually simple yet empirically powerful. It is a generic framework that can be applied to both supervised and self-supervised representation learning. Experimental results on supervised and self-supervised image classification, transfer learning and few-shot learning show that MCL can lead to consistent performance gains, demonstrating that MCL can guide the network to generate better feature representations.
Graph-Based Blind Image Deblurring From a Single Photograph
Feb 22, 2018



Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, we propose a graph-based blind image deblurring algorithm by interpreting an image patch as a signal on a weighted graph. Specifically, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. Then, we design a reweighted graph total variation (RGTV) prior that can efficiently promote a bi-modal edge weight distribution given a blurry patch. Further, to analyze RGTV in the graph frequency domain, we introduce a new weight function to represent RGTV as a graph $l_1$-Laplacian regularizer. This leads to a graph spectral filtering interpretation of the prior with desirable properties, including robustness to noise and blur, strong piecewise smooth (PWS) filtering and sharpness promotion. Minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We leverage the new graph spectral interpretation for RGTV to design an efficient algorithm that solves for the skeleton image and the blur kernel alternately. Specifically for Gaussian blur, we propose a further speedup strategy for blind Gaussian deblurring using accelerated graph spectral filtering. Finally, with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results demonstrate that our algorithm successfully restores latent sharp images and outperforms state-of-the-art methods quantitatively and qualitatively.
Visual Navigation with Spatial Attention
Apr 20, 2021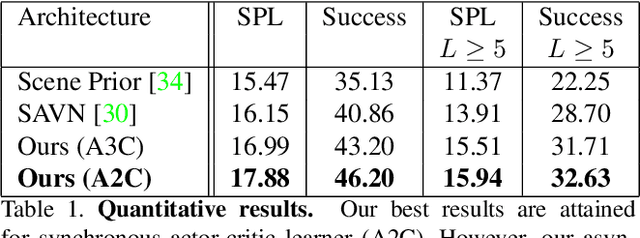
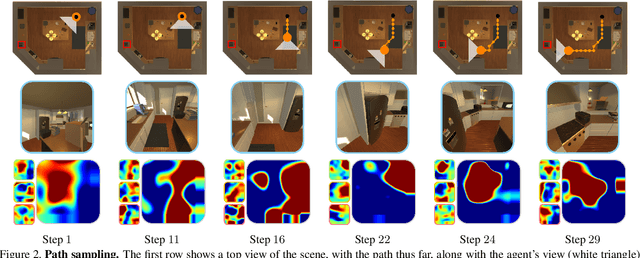
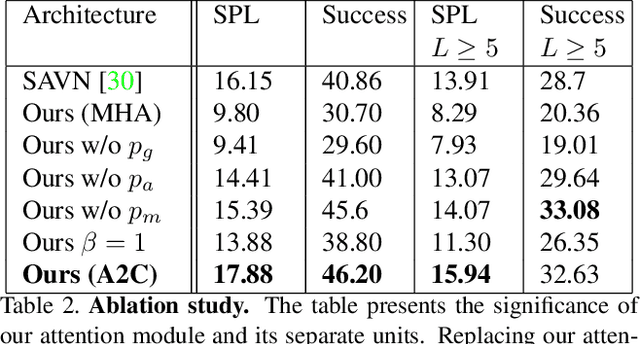
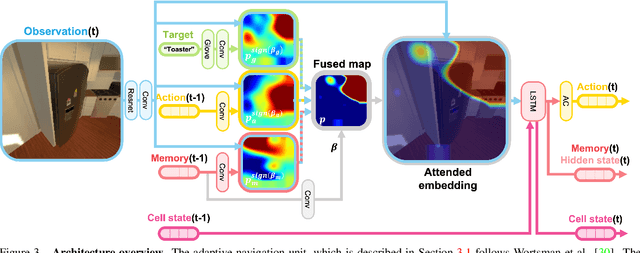
This work focuses on object goal visual navigation, aiming at finding the location of an object from a given class, where in each step the agent is provided with an egocentric RGB image of the scene. We propose to learn the agent's policy using a reinforcement learning algorithm. Our key contribution is a novel attention probability model for visual navigation tasks. This attention encodes semantic information about observed objects, as well as spatial information about their place. This combination of the "what" and the "where" allows the agent to navigate toward the sought-after object effectively. The attention model is shown to improve the agent's policy and to achieve state-of-the-art results on commonly-used datasets.
Monocular Depth Parameterizing Networks
Dec 21, 2020
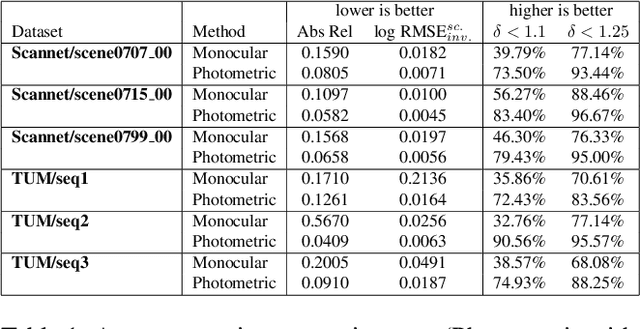
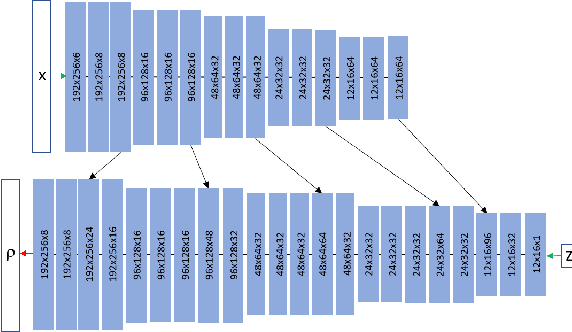
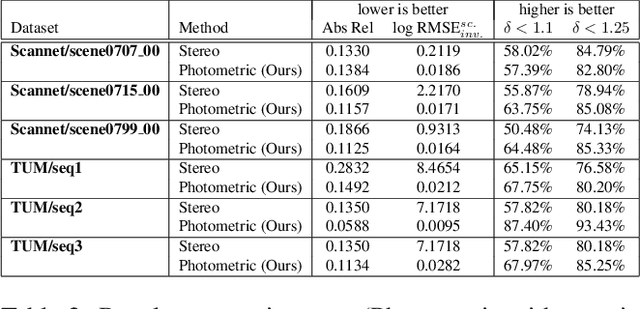
Monocular depth estimation is a highly challenging problem that is often addressed with deep neural networks. While these are able to use recognition of image features to predict reasonably looking depth maps the result often has low metric accuracy. In contrast traditional stereo methods using multiple cameras provide highly accurate estimation when pixel matching is possible. In this work we propose to combine the two approaches leveraging their respective strengths. For this purpose we propose a network structure that given an image provides a parameterization of a set of depth maps with feasible shapes. Optimizing over the parameterization then allows us to search the shapes for a photo consistent solution with respect to other images. This allows us to enforce geometric properties that are difficult to observe in single image as well as relaxes the learning problem allowing us to use relatively small networks. Our experimental evaluation shows that our method generates more accurate depth maps and generalizes better than competing state-of-the-art approaches.
A Survey on the Visual Perceptions of Gaussian Noise Filtering on Photography
Dec 18, 2020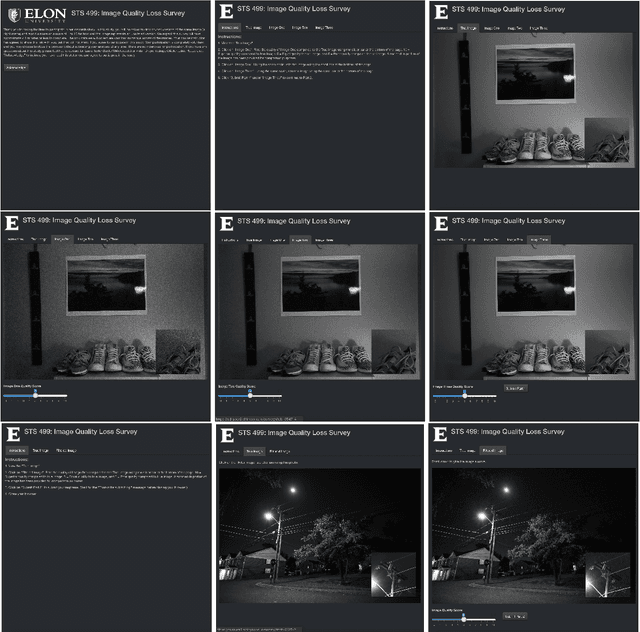



Statisticians, as well as machine learning and computer vision experts, have been studying image reconstitution through denoising different domains of photography, such as textual documentation, tomographic, astronomical, and low-light photography. In this paper, we apply common inferential kernel filters in the R and python languages, as well as Adobe Lightroom's denoise filter, and compare their effectiveness in removing noise from JPEG images. We ran standard benchmark tests to evaluate each method's effectiveness for removing noise. In doing so, we also surveyed students at Elon University about their opinion of a single filtered photo from a collection of photos processed by the various filter methods. Many scientists believe that noise filters cause blurring and image quality loss so we analyzed whether or not people felt as though denoising causes any quality loss as compared to their noiseless images. Individuals assigned scores indicating the image quality of a denoised photo compared to its noiseless counterpart on a 1 to 10 scale. Survey scores are compared across filters to evaluate whether there were significant differences in image quality scores received. Benchmark scores were compared to the visual perception scores. Then, an analysis of covariance test was run to identify whether or not survey training scores explained any unplanned variation in visual scores assigned by students across the filter methods.
Improved dual channel pulse coupled neural network and its application to multi-focus image fusion
Feb 04, 2020



This paper presents an improved dual channel pulse coupled neural network (IDC-PCNN) model for image fusion. The model can overcome some defects of standard PCNN model. In this fusion scheme, the multiplication rule is replaced by addition rule in the information fusion pool of dual channel PCNN (DC-PCNN) model. Meanwhile the sum of modified Laplacian (SML) measure is adopted, which is better than other focus measures. This method not only inherits the good characteristics of the standard PCNN model but also enhances the computing efficiency and fusion quality. The performance of the proposed method is evaluated by using four criteria including average cross entropy, root mean square error, peak value signal to noise ratio and structure similarity index. Comparative studies show that the proposed fusion algorithm outperforms the standard PCNN method and the DC-PCNN method.