 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LBVCNN: Local Binary Volume Convolutional Neural Network for Facial Expression Recognition from Image Sequences
Apr 16, 2019

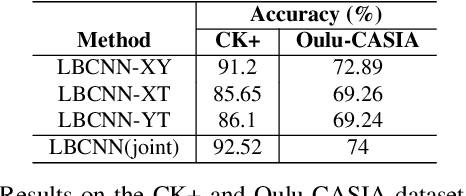
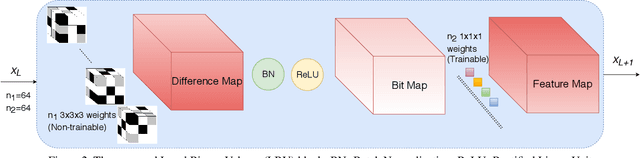
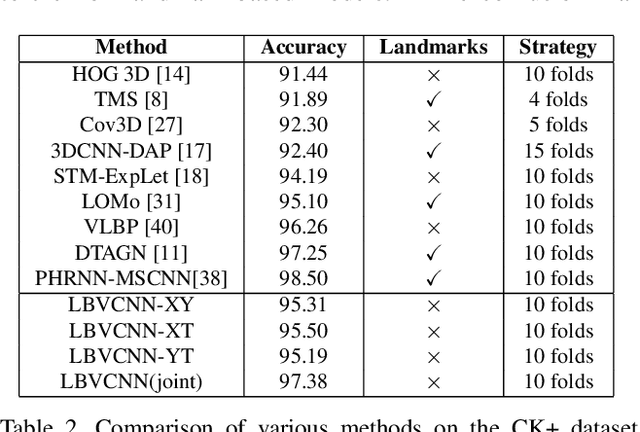
Recognizing facial expressions is one of the central problems in computer vision. Temporal image sequences have useful spatio-temporal features for recognizing expressions. In this paper, we propose a new 3D Convolution Neural Network (CNN) that can be trained end-to-end for facial expression recognition on temporal image sequences without using facial landmarks. More specifically, a novel 3D convolutional layer that we call Local Binary Volume (LBV) layer is proposed. The LBV layer, when used with our newly proposed LBVCNN network, achieve comparable results compared to state-of-the-art landmark-based or without landmark-based models on image sequences from CK+, Oulu-CASIA, and UNBC McMaster shoulder pain datasets. Furthermore, our LBV layer reduces the number of trainable parameters by a significant amount when compared to a conventional 3D convolutional layer. As a matter of fact, when compared to a 3x3x3 conventional 3D convolutional layer, the LBV layer uses 27 times less trainable parameters.
Unifying Structure Analysis and Surrogate-driven Function Regression for Glaucoma OCT Image Screening
Jul 26, 2019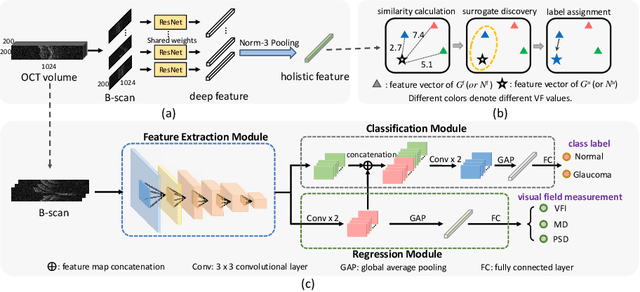
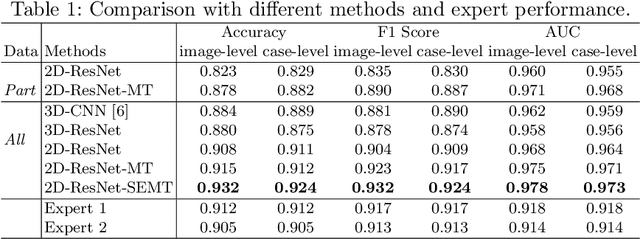
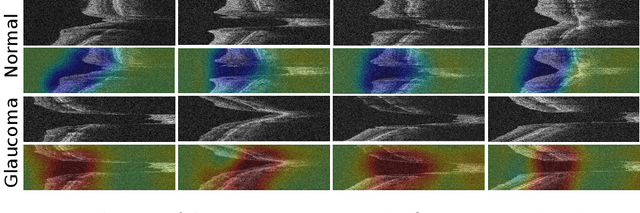
Optical Coherence Tomography (OCT) imaging plays an important role in glaucoma diagnosis in clinical practice. Early detection and timely treatment can prevent glaucoma patients from permanent vision loss. However, only a dearth of automated methods has been developed based on OCT images for glaucoma study. In this paper, we present a novel framework to effectively classify glaucoma OCT images from normal ones. A semi-supervised learning strategy with smoothness assumption is applied for surrogate assignment of missing function regression labels. Besides, the proposed multi-task learning network is capable of exploring the structure and function relationship from the OCT image and visual field measurement simultaneously, which contributes to classification performance boosting. Essentially, we are the first to unify the structure analysis and function regression for glaucoma screening. It is also worth noting that we build the largest glaucoma OCT image dataset involving 4877 volumes to develop and evaluate the proposed method. Extensive experiments demonstrate that our framework outperforms the baseline methods and two glaucoma experts by a large margin, achieving 93.2%, 93.2% and 97.8% on accuracy, F1 score and AUC, respectively.
PADDIT: Probabilistic Augmentation of Data using Diffeomorphic Image Transformation
Oct 03, 2018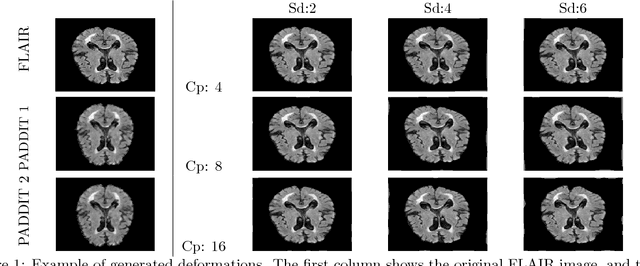
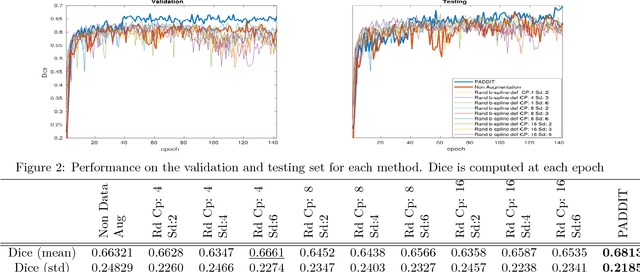
For proper generalization performance of convolutional neural networks (CNNs) in medical image segmentation, the learnt features should be invariant under particular non-linear shape variations of the input. To induce invariance in CNNs to such transformations, we propose Probabilistic Augmentation of Data using Diffeomorphic Image Transformation (PADDIT) -- a systematic framework for generating realistic transformations that can be used to augment data for training CNNs. We show that CNNs trained with PADDIT outperforms CNNs trained without augmentation and with generic augmentation in segmenting white matter hyperintensities from T1 and FLAIR brain MRI scans.
Representation and Correlation Enhanced Encoder-Decoder Framework for Scene Text Recognition
Jun 13, 2021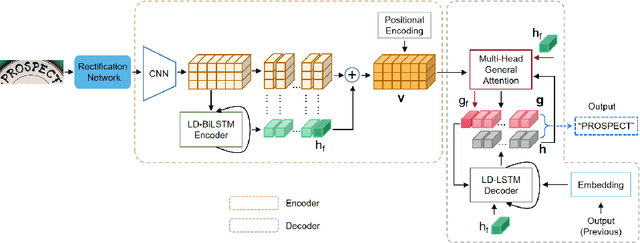
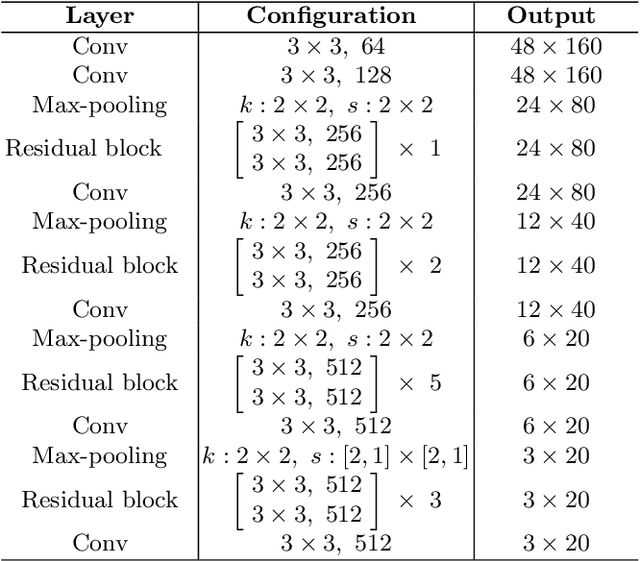

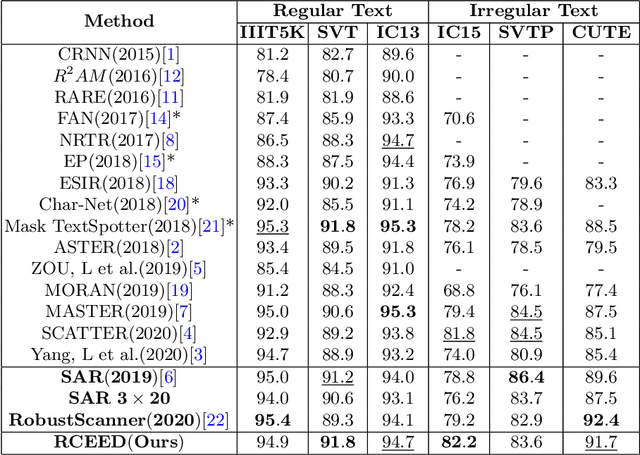
Attention-based encoder-decoder framework is widely used in the scene text recognition task. However, for the current state-of-the-art(SOTA) methods, there is room for improvement in terms of the efficient usage of local visual and global context information of the input text image, as well as the robust correlation between the scene processing module(encoder) and the text processing module(decoder). In this paper, we propose a Representation and Correlation Enhanced Encoder-Decoder Framework(RCEED) to address these deficiencies and break performance bottleneck. In the encoder module, local visual feature, global context feature, and position information are aligned and fused to generate a small-size comprehensive feature map. In the decoder module, two methods are utilized to enhance the correlation between scene and text feature space. 1) The decoder initialization is guided by the holistic feature and global glimpse vector exported from the encoder. 2) The feature enriched glimpse vector produced by the Multi-Head General Attention is used to assist the RNN iteration and the character prediction at each time step. Meanwhile, we also design a Layernorm-Dropout LSTM cell to improve model's generalization towards changeable texts. Extensive experiments on the benchmarks demonstrate the advantageous performance of RCEED in scene text recognition tasks, especially the irregular ones.
Do Not Escape From the Manifold: Discovering the Local Coordinates on the Latent Space of GANs
Jun 13, 2021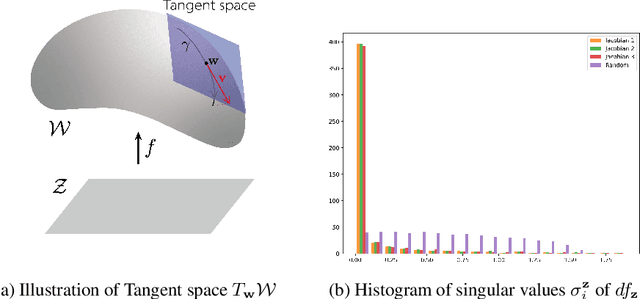



In this paper, we propose a method to find local-geometry-aware traversal directions on the intermediate latent space of Generative Adversarial Networks (GANs). These directions are defined as an ordered basis of tangent space at a latent code. Motivated by the intrinsic sparsity of the latent space, the basis is discovered by solving the low-rank approximation problem of the differential of the partial network. Moreover, the local traversal basis leads to a natural iterative traversal on the latent space. Iterative Curve-Traversal shows stable traversal on images, since the trajectory of latent code stays close to the latent space even under the strong perturbations compared to the linear traversal. This stability provides far more diverse variations of the given image. Although the proposed method can be applied to various GAN models, we focus on the W-space of the StyleGAN2, which is renowned for showing the better disentanglement of the latent factors of variation. Our quantitative and qualitative analysis provides evidence showing that the W-space is still globally warped while showing a certain degree of global consistency of interpretable variation. In particular, we introduce some metrics on the Grassmannian manifolds to quantify the global warpage of the W-space and the subspace traversal to test the stability of traversal directions.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021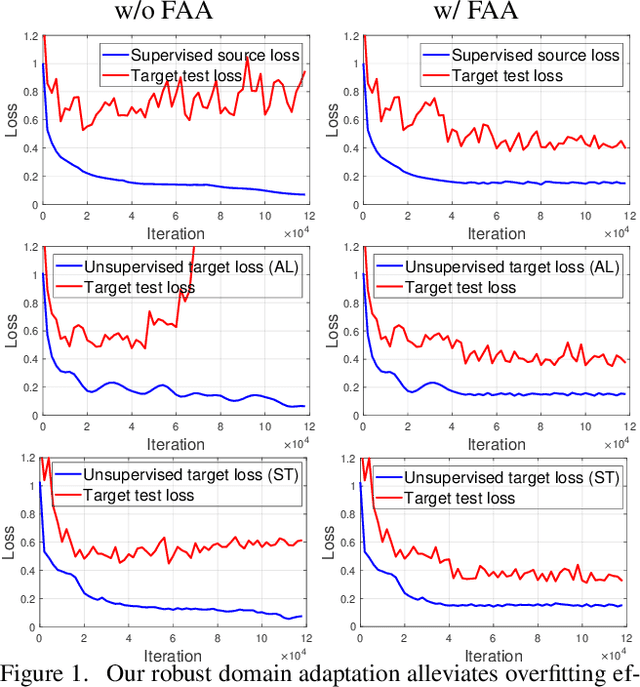
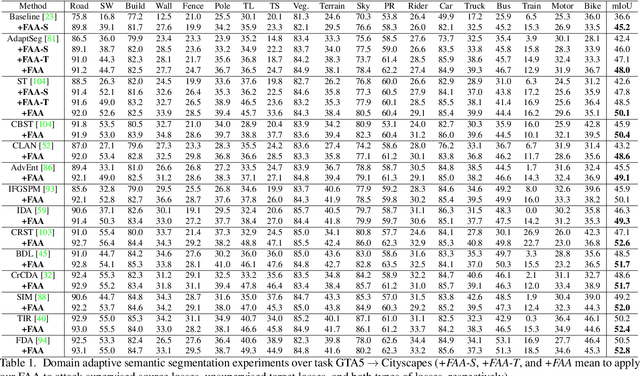
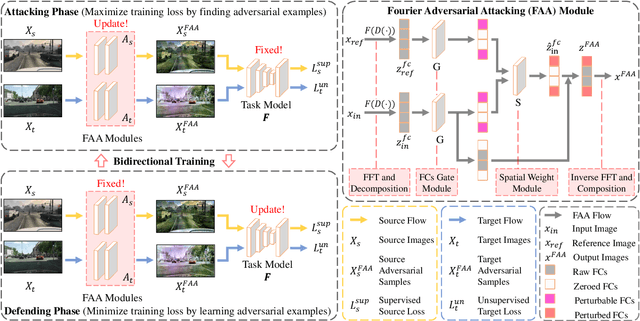
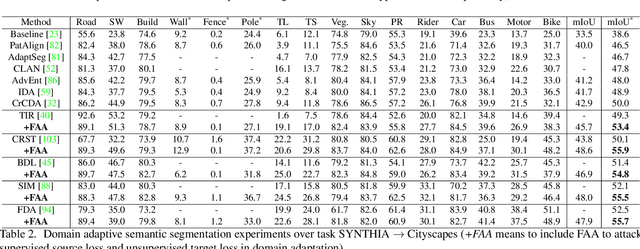
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.
Size Matters
Feb 02, 2021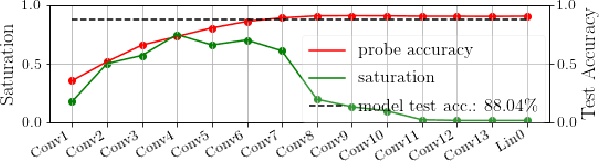
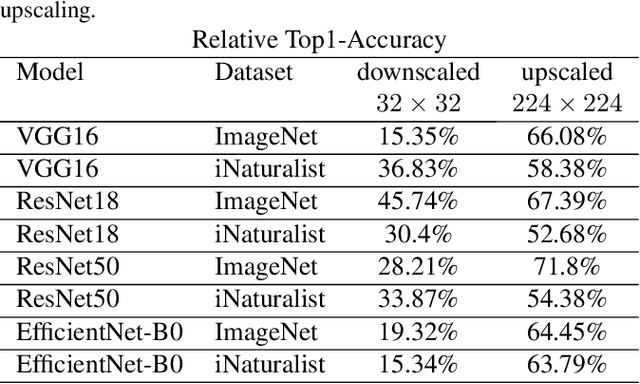
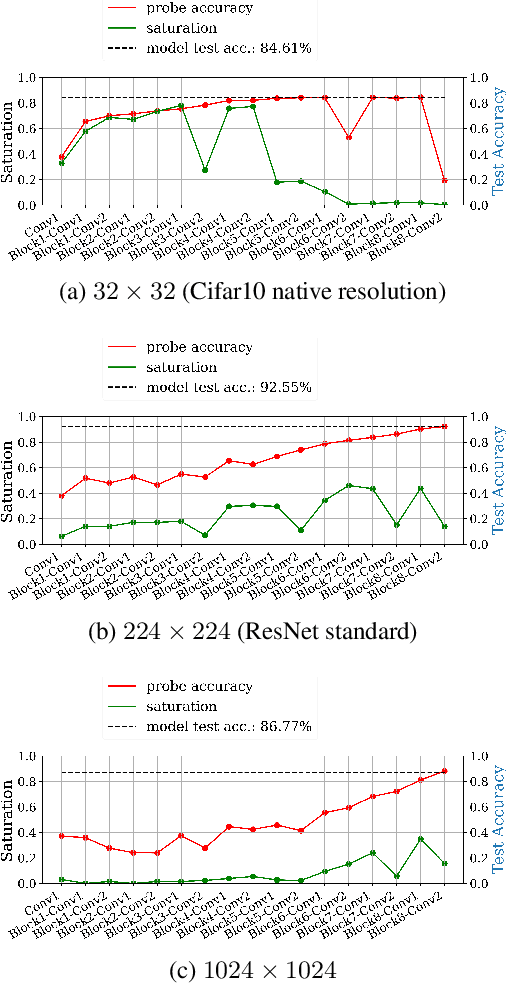
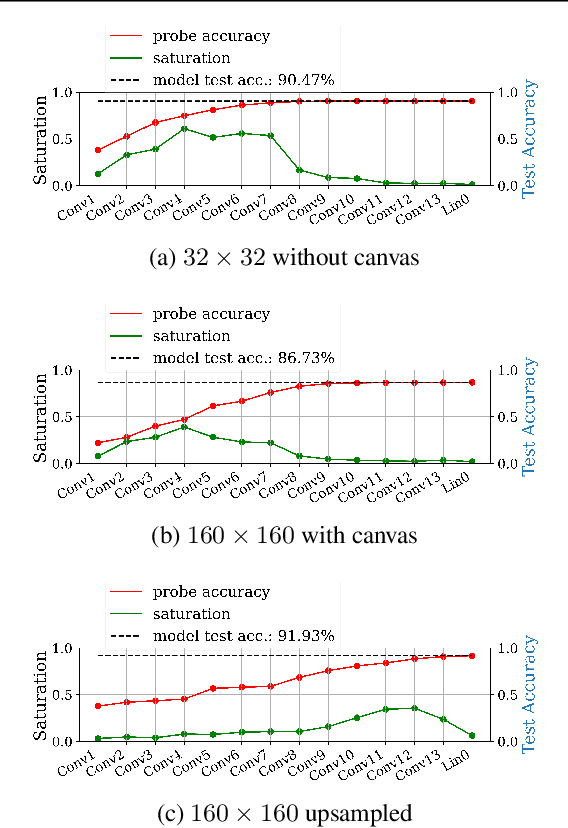
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 17, 2020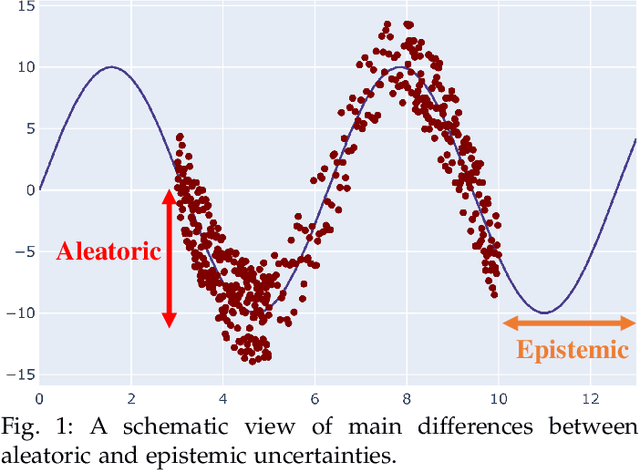
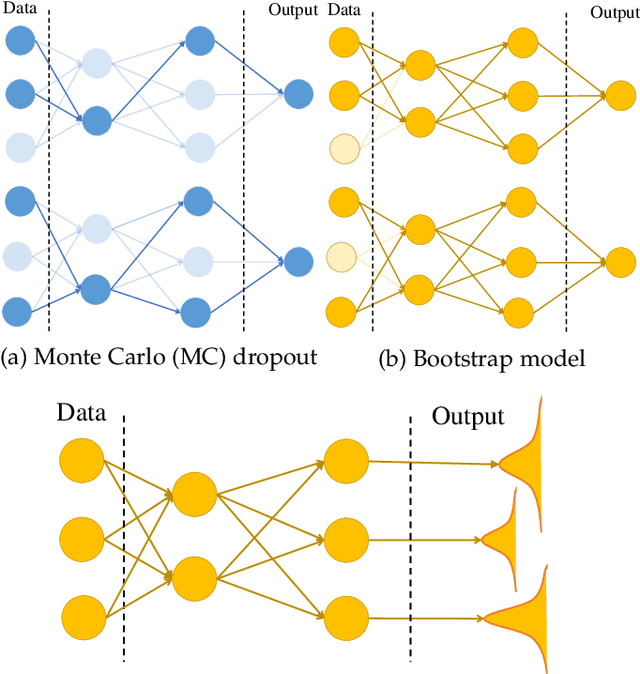
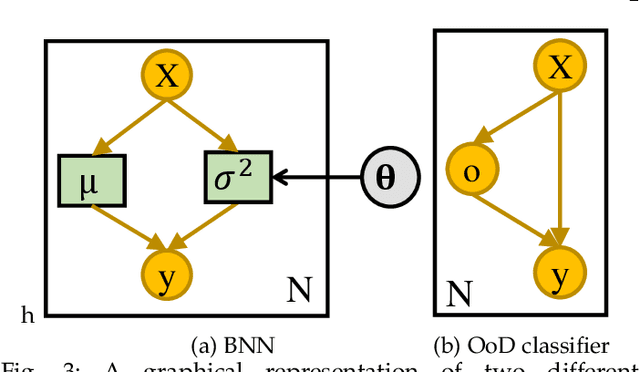
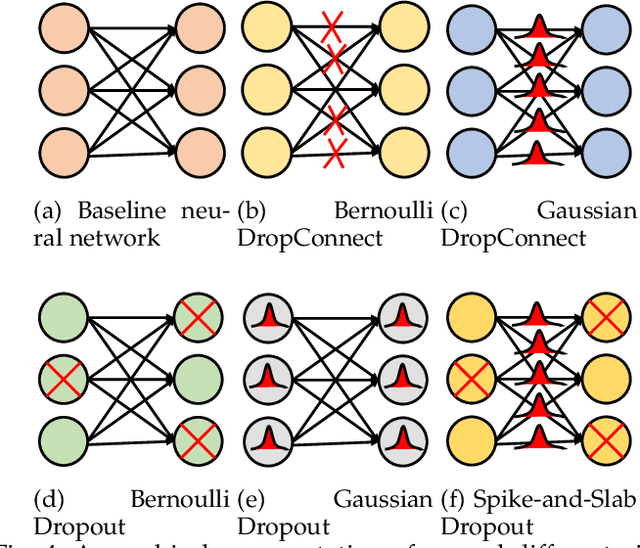
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
Preclinical Stage Alzheimer's Disease Detection Using Magnetic Resonance Image Scans
Nov 28, 2020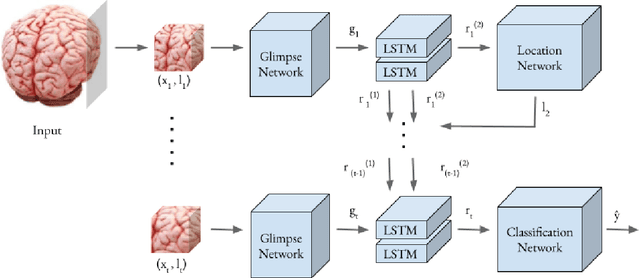
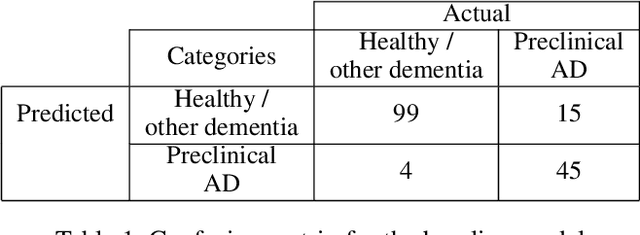
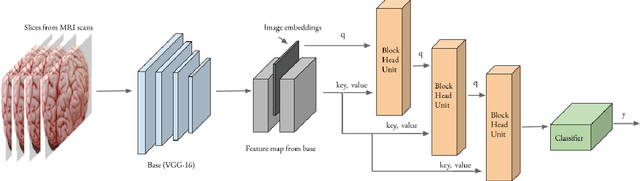

Alzheimer's disease is one of the diseases that mostly affects older people without being a part of aging. The most common symptoms include problems with communicating and abstract thinking, as well as disorientation. It is important to detect Alzheimer's disease in early stages so that cognitive functioning would be improved by medication and training. In this paper, we propose two attention model networks for detecting Alzheimer's disease from MRI images to help early detection efforts at the preclinical stage. We also compare the performance of these two attention network models with a baseline model. Recently available OASIS-3 Longitudinal Neuroimaging, Clinical, and Cognitive Dataset is used to train, evaluate and compare our models. The novelty of this research resides in the fact that we aim to detect Alzheimer's disease when all the parameters, physical assessments, and clinical data state that the patient is healthy and showing no symptoms
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Jun 20, 2021
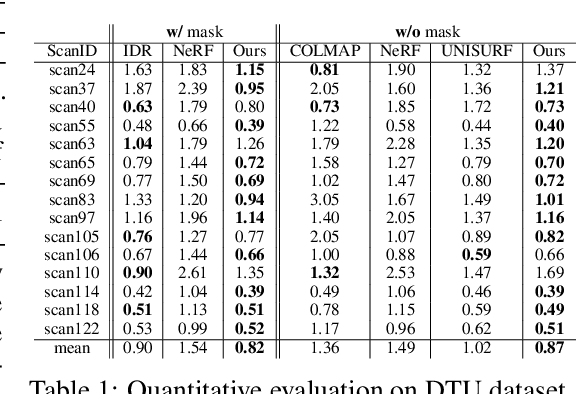
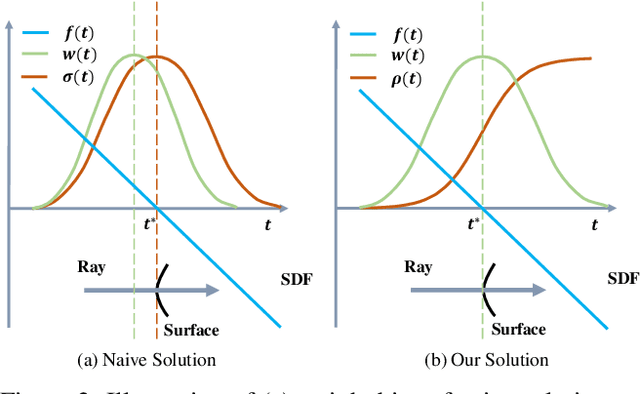
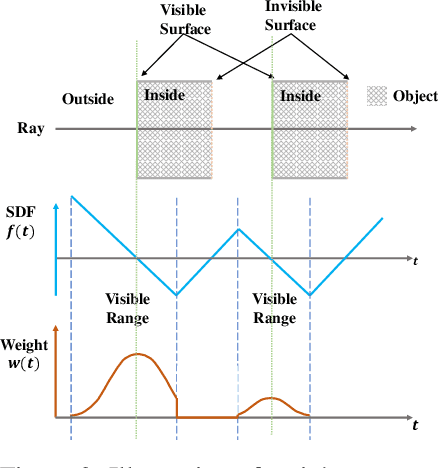
We present a novel neural surface reconstruction method, called NeuS, for reconstructing objects and scenes with high fidelity from 2D image inputs. Existing neural surface reconstruction approaches, such as DVR and IDR, require foreground mask as supervision, easily get trapped in local minima, and therefore struggle with the reconstruction of objects with severe self-occlusion or thin structures. Meanwhile, recent neural methods for novel view synthesis, such as NeRF and its variants, use volume rendering to produce a neural scene representation with robustness of optimization, even for highly complex objects. However, extracting high-quality surfaces from this learned implicit representation is difficult because there are not sufficient surface constraints in the representation. In NeuS, we propose to represent a surface as the zero-level set of a signed distance function (SDF) and develop a new volume rendering method to train a neural SDF representation. We observe that the conventional volume rendering method causes inherent geometric errors (i.e. bias) for surface reconstruction, and therefore propose a new formulation that is free of bias in the first order of approximation, thus leading to more accurate surface reconstruction even without the mask supervision. Experiments on the DTU dataset and the BlendedMVS dataset show that NeuS outperforms the state-of-the-arts in high-quality surface reconstruction, especially for objects and scenes with complex structures and self-occlusion.