 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Optical Character Recognition for Bengali Handwritten Words
May 09, 2021
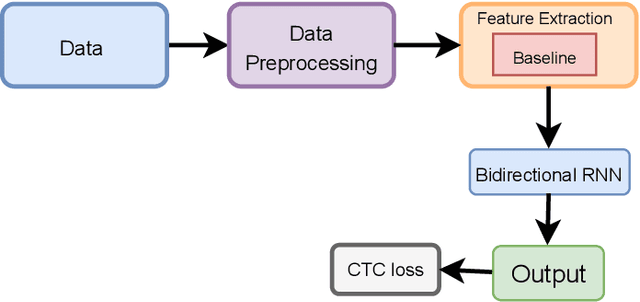

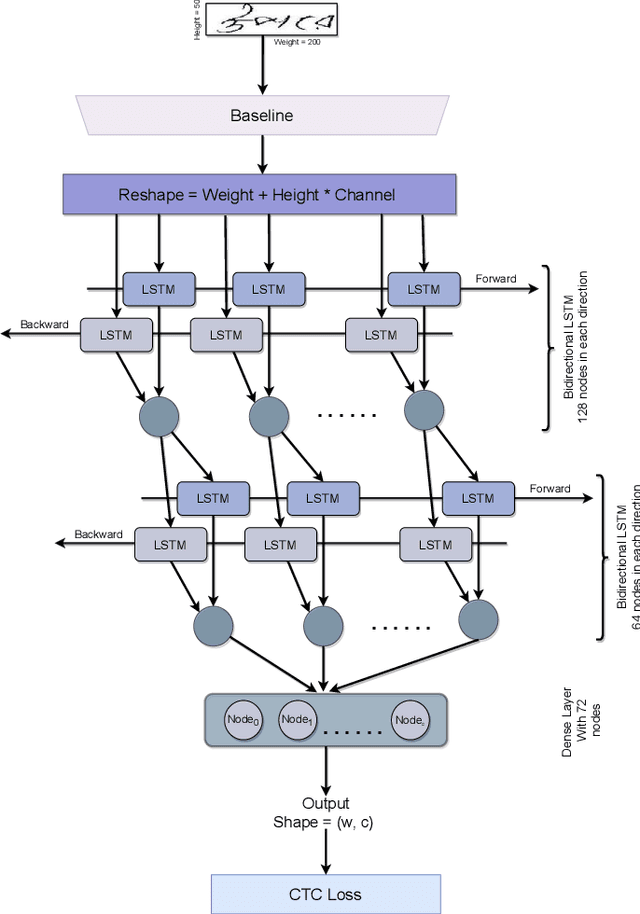
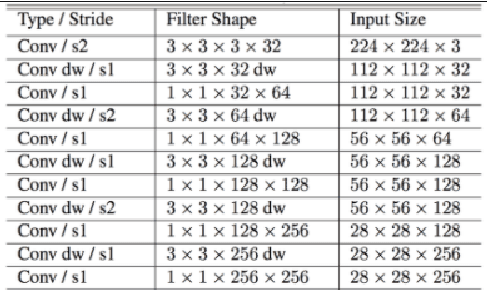
Optical character recognition (OCR) is a process of converting analogue documents into digital using document images. Currently, many commercial and non-commercial OCR systems exist for both handwritten and printed copies for different languages. Despite this, very few works are available in case of recognising Bengali words. Among them, most of the works focused on OCR of printed Bengali characters. This paper introduces an end-to-end OCR system for Bengali language. The proposed architecture implements an end to end strategy that recognises handwritten Bengali words from handwritten word images. We experiment with popular convolutional neural network (CNN) architectures, including DenseNet, Xception, NASNet, and MobileNet to build the OCR architecture. Further, we experiment with two different recurrent neural networks (RNN) methods, LSTM and GRU. We evaluate the proposed architecture using BanglaWritting dataset, which is a peer-reviewed Bengali handwritten image dataset. The proposed method achieves 0.091 character error rate and 0.273 word error rate performed using DenseNet121 model with GRU recurrent layer.
On the Design of Strategic Task Recommendations for Sustainable Crowdsourcing-Based Content Moderation
Jun 04, 2021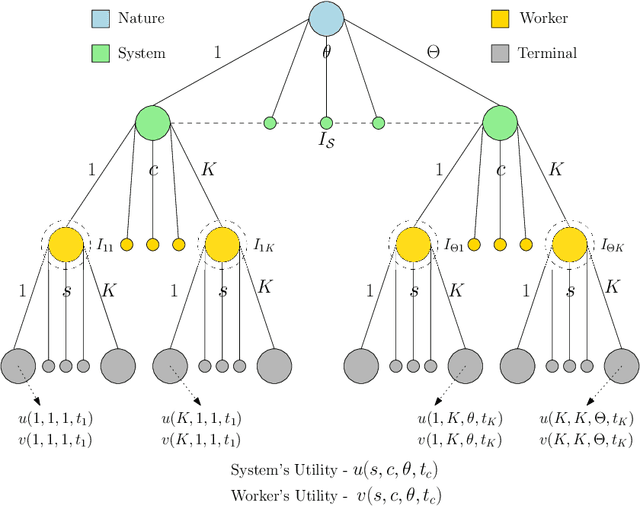
Crowdsourcing-based content moderation is a platform that hosts content moderation tasks for crowd workers to review user submissions (e.g. text, images and videos) and make decisions regarding the admissibility of the posted content, along with a gamut of other tasks such as image labeling and speech-to-text conversion. In an attempt to reduce cognitive overload at the workers and improve system efficiency, these platforms offer personalized task recommendations according to the worker's preferences. However, the current state-of-the-art recommendation systems disregard the effects on worker's mental health, especially when they are repeatedly exposed to content moderation tasks with extreme content (e.g. violent images, hate-speech). In this paper, we propose a novel, strategic recommendation system for the crowdsourcing platform that recommends jobs based on worker's mental status. Specifically, this paper models interaction between the crowdsourcing platform's recommendation system (leader) and the worker (follower) as a Bayesian Stackelberg game where the type of the follower corresponds to the worker's cognitive atrophy rate and task preferences. We discuss how rewards and costs should be designed to steer the game towards desired outcomes in terms of maximizing the platform's productivity, while simultaneously improving the working conditions of crowd workers.
Algebraic Image Processing
Oct 11, 2017We propose an approach to image processing related to algebraic operators acting in the space of images. In view of the interest in the applications in optics and computer science, mathematical aspects of the paper have been simplified as much as possible. Underlying theory, related to rigged Hilbert spaces and Lie algebras, is discussed elsewhere
3D Deep Affine-Invariant Shape Learning for Brain MR Image Segmentation
Sep 17, 2019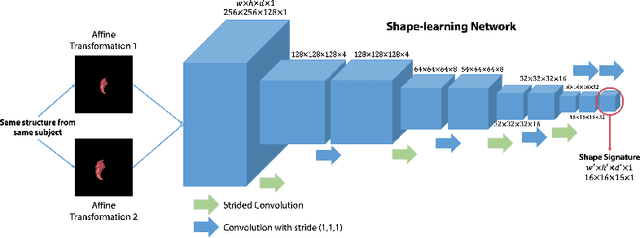
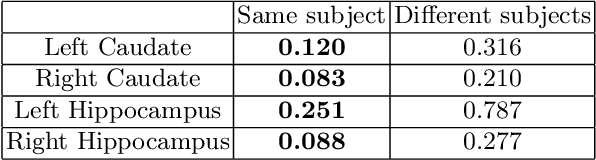
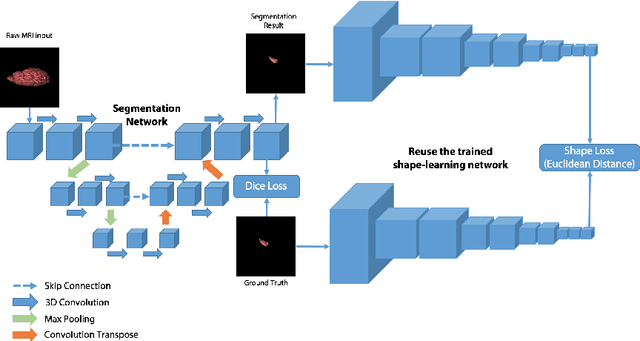
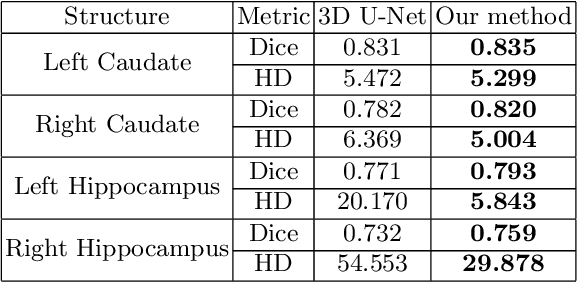
Recent advancements in medical image segmentation techniques have achieved compelling results. However, most of the widely used approaches do not take into account any prior knowledge about the shape of the biomedical structures being segmented. More recently, some works have presented approaches to incorporate shape information. However, many of them are indeed introducing more parameters to the segmentation network to learn the general features, which any segmentation network is able learn, instead of specifically shape features. In this paper, we present a novel approach that seamlessly integrates the shape information into the segmentation network. Experiments on human brain MRI segmentation demonstrate that our approach can achieve a lower Hausdorff distance and higher Dice coefficient than the state-of-the-art approaches.
CAFE-GAN: Arbitrary Face Attribute Editing with Complementary Attention Feature
Nov 24, 2020
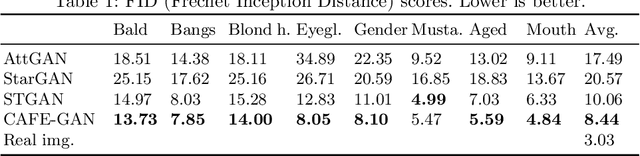

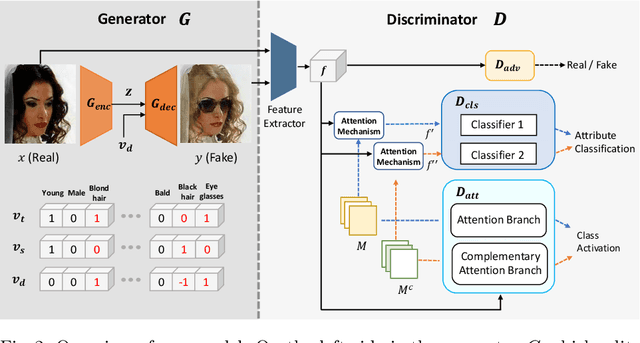
The goal of face attribute editing is altering a facial image according to given target attributes such as hair color, mustache, gender, etc. It belongs to the image-to-image domain transfer problem with a set of attributes considered as a distinctive domain. There have been some works in multi-domain transfer problem focusing on facial attribute editing employing Generative Adversarial Network (GAN). These methods have reported some successes but they also result in unintended changes in facial regions - meaning the generator alters regions unrelated to the specified attributes. To address this unintended altering problem, we propose a novel GAN model which is designed to edit only the parts of a face pertinent to the target attributes by the concept of Complementary Attention Feature (CAFE). CAFE identifies the facial regions to be transformed by considering both target attributes as well as complementary attributes, which we define as those attributes absent in the input facial image. In addition, we introduce a complementary feature matching to help in training the generator for utilizing the spatial information of attributes. Effectiveness of the proposed method is demonstrated by analysis and comparison study with state-of-the-art methods.
Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Jun 04, 2021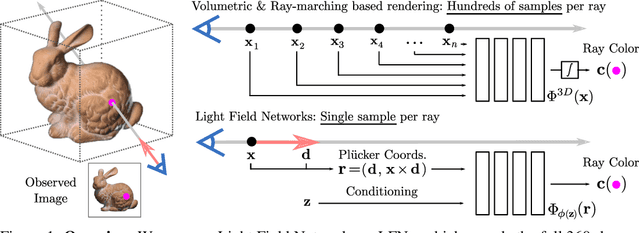

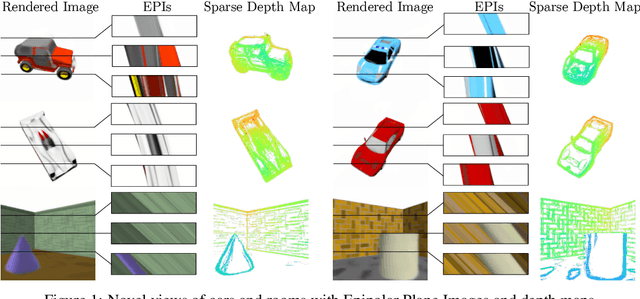
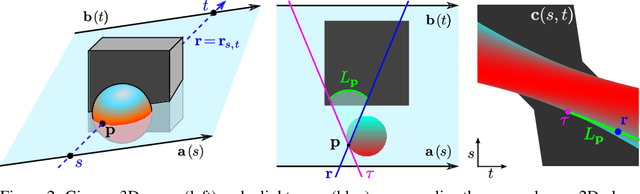
Inferring representations of 3D scenes from 2D observations is a fundamental problem of computer graphics, computer vision, and artificial intelligence. Emerging 3D-structured neural scene representations are a promising approach to 3D scene understanding. In this work, we propose a novel neural scene representation, Light Field Networks or LFNs, which represent both geometry and appearance of the underlying 3D scene in a 360-degree, four-dimensional light field parameterized via a neural implicit representation. Rendering a ray from an LFN requires only a *single* network evaluation, as opposed to hundreds of evaluations per ray for ray-marching or volumetric based renderers in 3D-structured neural scene representations. In the setting of simple scenes, we leverage meta-learning to learn a prior over LFNs that enables multi-view consistent light field reconstruction from as little as a single image observation. This results in dramatic reductions in time and memory complexity, and enables real-time rendering. The cost of storing a 360-degree light field via an LFN is two orders of magnitude lower than conventional methods such as the Lumigraph. Utilizing the analytical differentiability of neural implicit representations and a novel parameterization of light space, we further demonstrate the extraction of sparse depth maps from LFNs.
Principled network extraction from images
Dec 23, 2020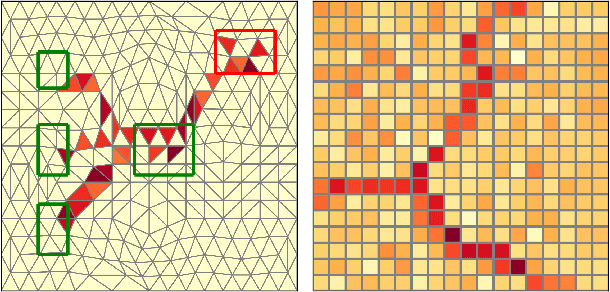
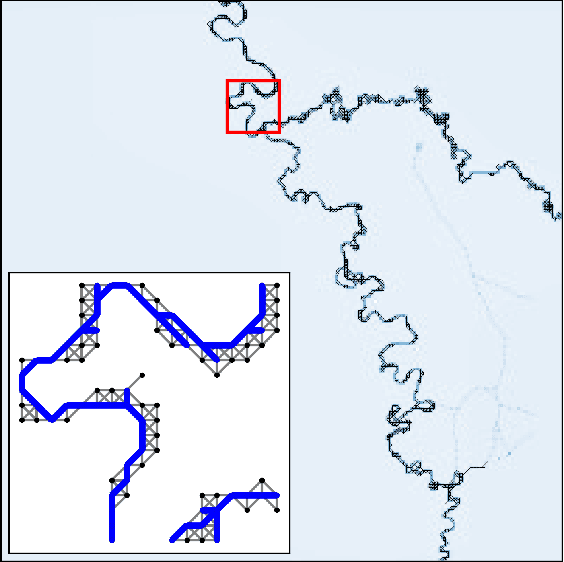
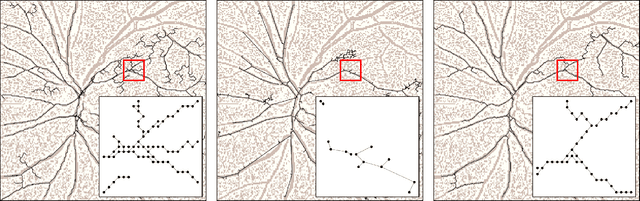
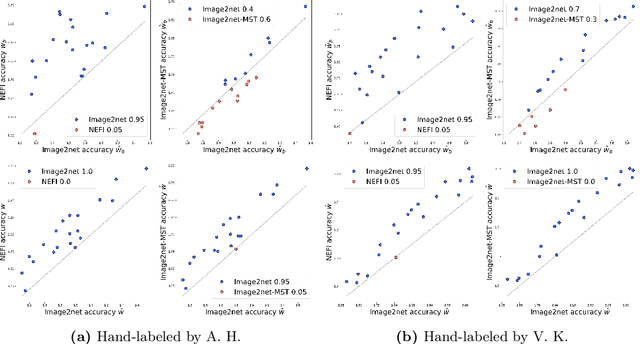
Images of natural systems may represent patterns of network-like structure, which could reveal important information about the topological properties of the underlying subject. However, the image itself does not automatically provide a formal definition of a network in terms of sets of nodes and edges. Instead, this information should be suitably extracted from the raw image data. Motivated by this, we present a principled model to extract network topologies from images that is scalable and efficient. We map this goal into solving a routing optimization problem where the solution is a network that minimizes an energy function which can be interpreted in terms of an operational and infrastructural cost. Our method relies on recent results from optimal transport theory and is a principled alternative to standard image-processing techniques that are based on heuristics. We test our model on real images of the retinal vascular system, slime mold and river networks and compare with routines combining image-processing techniques. Results are tested in terms of a similarity measure related to the amount of information preserved in the extraction. We find that our model finds networks from retina vascular network images that are more similar to hand-labeled ones, while also giving high performance in extracting networks from images of rivers and slime mold for which there is no ground truth available. While there is no unique method that fits all the images the best, our approach performs consistently across datasets, its algorithmic implementation is efficient and can be fully automatized to be run on several datasets with little supervision.
Evaluation of quality measures for color quantization
Nov 25, 2020
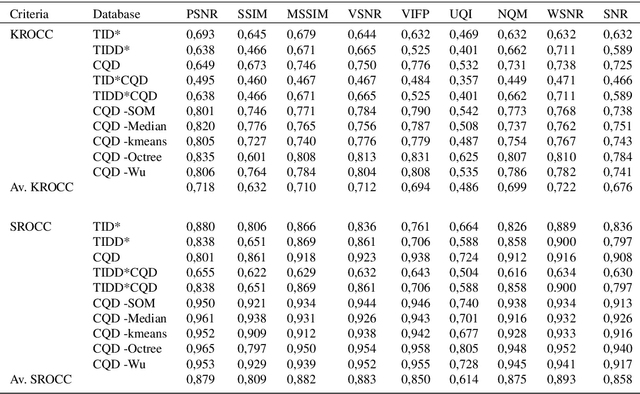
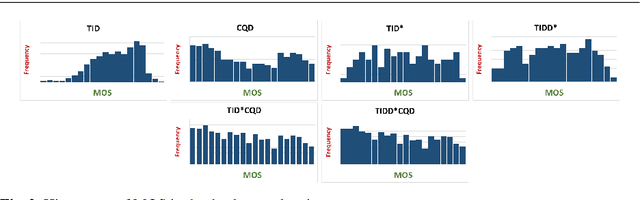
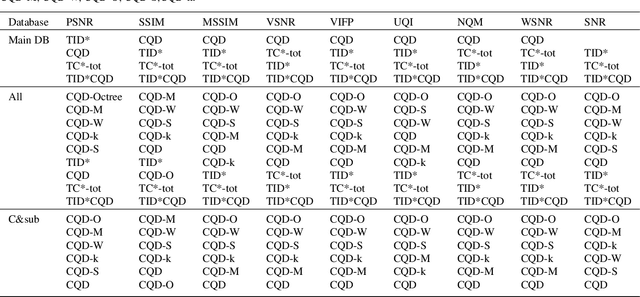
Visual quality evaluation is one of the challenging basic problems in image processing. It also plays a central role in the shaping, implementation, optimization, and testing of many methods. The existing image quality assessment methods focused on images corrupted by common degradation types while little attention was paid to color quantization. This in spite there is a wide range of applications requiring color quantization assessment being used as a preprocessing step when color-based tasks are more efficiently accomplished on a reduced number of colors. In this paper, we propose and carry-out a quantitative performance evaluation of nine well-known and commonly used full-reference image quality assessment measures. The evaluation is done by using two publicly available and subjectively rated image quality databases for color quantization degradation and by considering suitable combinations or subparts of them. The results indicate the quality measures that have closer performances in terms of their correlation to the subjective human rating and show that the evaluation of the statistical performance of the quality measures for color quantization is significantly impacted by the selected image quality database while maintaining a similar trend on each database. The detected strong similarity both on individual databases and on databases obtained by integration provides the ability to validate the integration process and to consider the quantitative performance evaluation on each database as an indicator for performance on the other databases. The experimental results are useful to address the choice of suitable quality measures for color quantization and to improve their future employment.
Control of computer pointer using hand gesture recognition in motion pictures
Dec 24, 2020

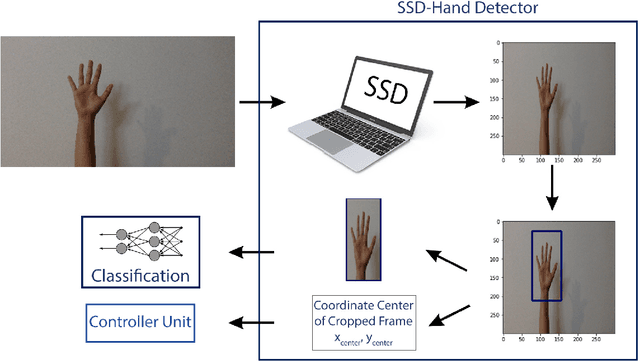

A user interface is designed to control the computer cursor by hand detection and classification of its gesture. A hand dataset with 6720 image samples is collected, including four classes: fist, palm, pointing to the left, and pointing to the right. The images are captured from 15 persons in simple backgrounds and different perspectives and light conditions. A CNN network is trained on this dataset to predict a label for each captured image and measure the similarity of them. Finally, commands are defined to click, right-click and move the cursor. The algorithm has 91.88% accuracy and can be used in different backgrounds.
When Dictionary Learning Meets Deep Learning: Deep Dictionary Learning and Coding Network for Image Recognition with Limited Data
May 21, 2020
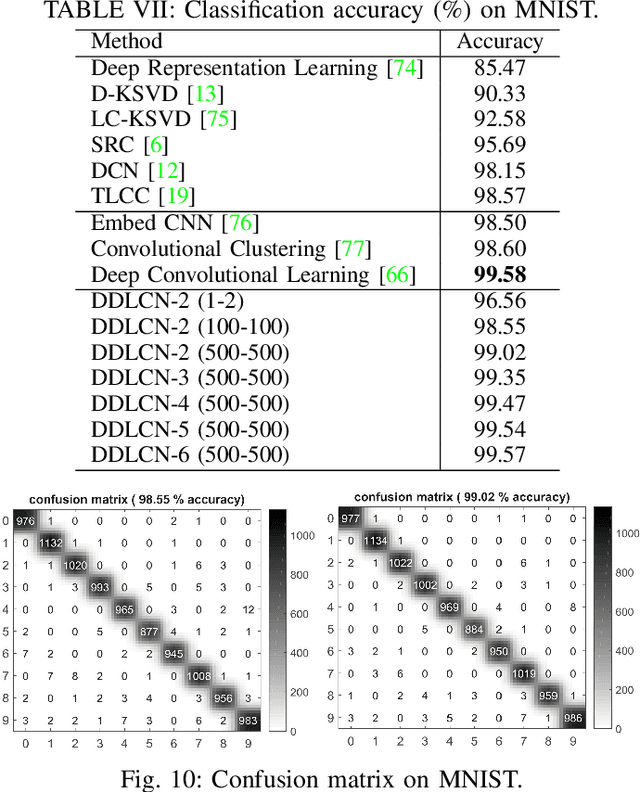


We present a new Deep Dictionary Learning and Coding Network (DDLCN) for image recognition tasks with limited data. The proposed DDLCN has most of the standard deep learning layers (e.g., input/output, pooling, fully connected, etc.), but the fundamental convolutional layers are replaced by our proposed compound dictionary learning and coding layers. The dictionary learning learns an over-complete dictionary for input training data. At the deep coding layer, a locality constraint is added to guarantee that the activated dictionary bases are close to each other. Then the activated dictionary atoms are assembled and passed to the compound dictionary learning and coding layers. In this way, the activated atoms in the first layer can be represented by the deeper atoms in the second dictionary. Intuitively, the second dictionary is designed to learn the fine-grained components shared among the input dictionary atoms, thus a more informative and discriminative low-level representation of the dictionary atoms can be obtained. We empirically compare DDLCN with several leading dictionary learning methods and deep learning models. Experimental results on five popular datasets show that DDLCN achieves competitive results compared with state-of-the-art methods when the training data is limited. Code is available at https://github.com/Ha0Tang/DDLCN.