 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Resolution Segmentation of Tooth Root Fuzzy Edge Based on Polynomial Curve Fitting with Landmark Detection
Mar 07, 2021
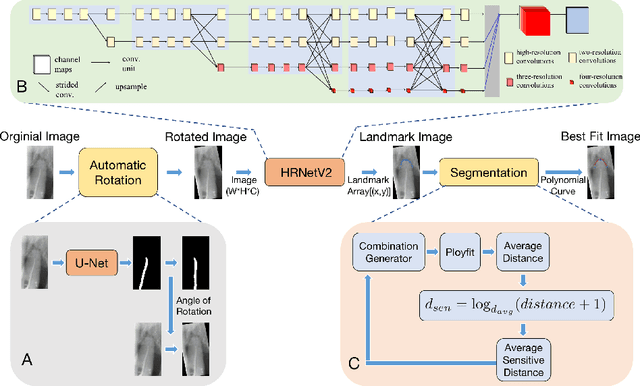
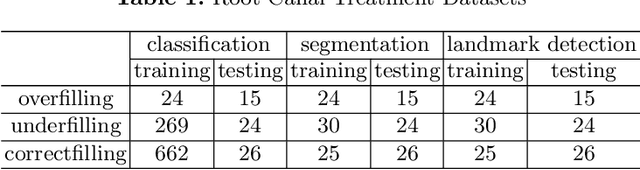
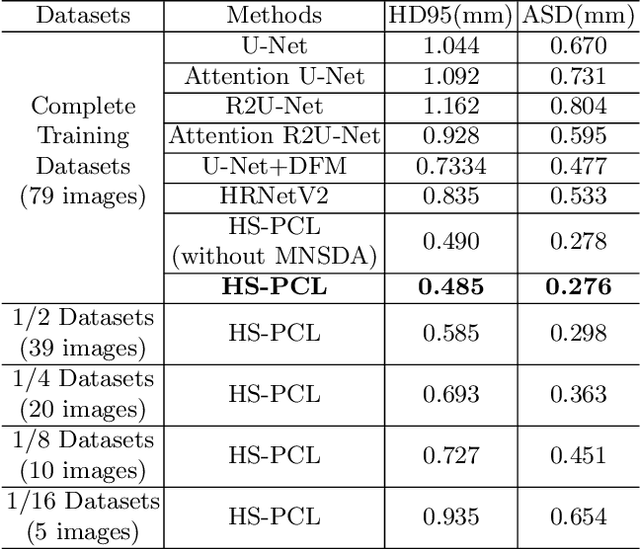
As the most economical and routine auxiliary examination in the diagnosis of root canal treatment, oral X-ray has been widely used by stomatologists. It is still challenging to segment the tooth root with a blurry boundary for the traditional image segmentation method. To this end, we propose a model for high-resolution segmentation based on polynomial curve fitting with landmark detection (HS-PCL). It is based on detecting multiple landmarks evenly distributed on the edge of the tooth root to fit a smooth polynomial curve as the segmentation of the tooth root, thereby solving the problem of fuzzy edge. In our model, a maximum number of the shortest distances algorithm (MNSDA) is proposed to automatically reduce the negative influence of the wrong landmarks which are detected incorrectly and deviate from the tooth root on the fitting result. Our numerical experiments demonstrate that the proposed approach not only reduces Hausdorff95 (HD95) by 33.9% and Average Surface Distance (ASD) by 42.1% compared with the state-of-the-art method, but it also achieves excellent results on the minute quantity of datasets, which greatly improves the feasibility of automatic root canal therapy evaluation by medical image computing.
Distribution Matching Losses Can Hallucinate Features in Medical Image Translation
Oct 03, 2018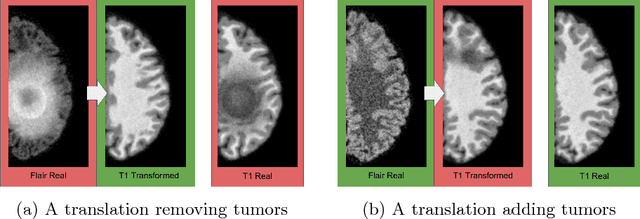
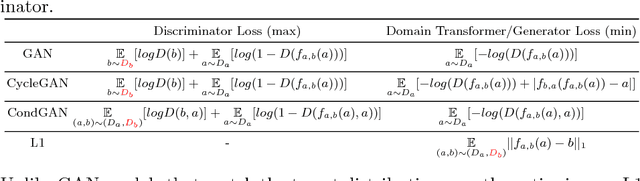
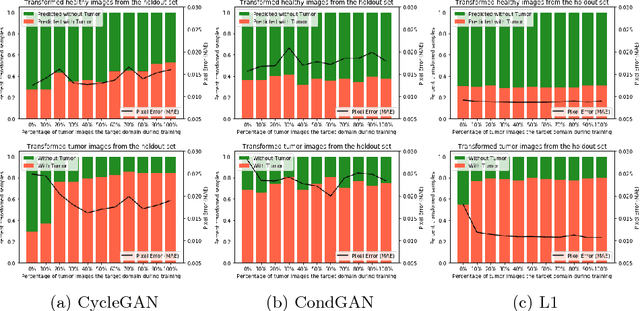

This paper discusses how distribution matching losses, such as those used in CycleGAN, when used to synthesize medical images can lead to mis-diagnosis of medical conditions. It seems appealing to use these new image synthesis methods for translating images from a source to a target domain because they can produce high quality images and some even do not require paired data. However, the basis of how these image translation models work is through matching the translation output to the distribution of the target domain. This can cause an issue when the data provided in the target domain has an over or under representation of some classes (e.g. healthy or sick). When the output of an algorithm is a transformed image there are uncertainties whether all known and unknown class labels have been preserved or changed. Therefore, we recommend that these translated images should not be used for direct interpretation (e.g. by doctors) because they may lead to misdiagnosis of patients based on hallucinated image features by an algorithm that matches a distribution. However there are many recent papers that seem as though this is the goal.
* Published at Medical Image Computing & Computer Assisted Intervention (MICCAI 2018). An abstract is published at the Medical Imaging with Deep Learning Conference (MIDL 2018) as "How to Cure Cancer (in images) with Unpaired Image Translation"
The joint role of geometry and illumination on material recognition
Feb 04, 2021



Observing and recognizing materials is a fundamental part of our daily life. Under typical viewing conditions, we are capable of effortlessly identifying the objects that surround us and recognizing the materials they are made of. Nevertheless, understanding the underlying perceptual processes that take place to accurately discern the visual properties of an object is a long-standing problem. In this work, we perform a comprehensive and systematic analysis of how the interplay of geometry, illumination, and their spatial frequencies affects human performance on material recognition tasks. We carry out large-scale behavioral experiments where participants are asked to recognize different reference materials among a pool of candidate samples. In the different experiments, we carefully sample the information in the frequency domain of the stimuli. From our analysis, we find significant first-order interactions between the geometry and the illumination, of both the reference and the candidates. In addition, we observe that simple image statistics and higher-order image histograms do not correlate with human performance. Therefore, we perform a high-level comparison of highly non-linear statistics by training a deep neural network on material recognition tasks. Our results show that such models can accurately classify materials, which suggests that they are capable of defining a meaningful representation of material appearance from labeled proximal image data. Last, we find preliminary evidence that these highly non-linear models and humans may use similar high-level factors for material recognition tasks.
* 15 pages, 16 figures, Accepted to the Journal of Vision, 2021
MANAS: Multi-Scale and Multi-Level Neural Architecture Search for Low-Dose CT Denoising
Mar 24, 2021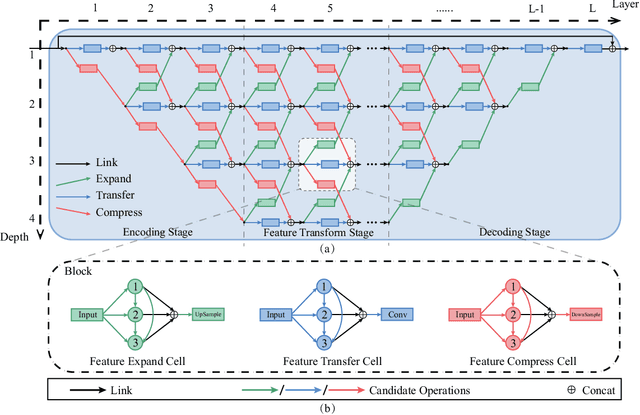

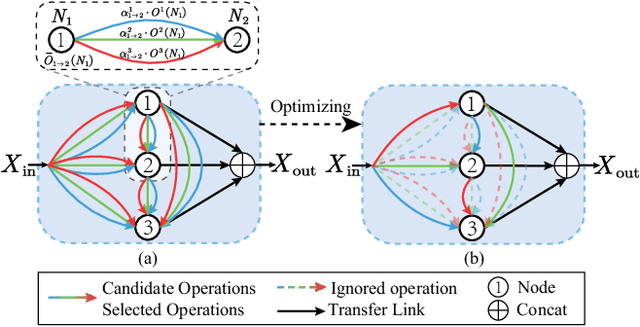
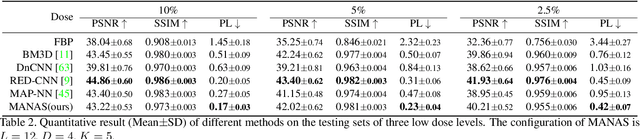
Lowering the radiation dose in computed tomography (CT) can greatly reduce the potential risk to public health. However, the reconstructed images from the dose-reduced CT or low-dose CT (LDCT) suffer from severe noise, compromising the subsequent diagnosis and analysis. Recently, convolutional neural networks have achieved promising results in removing noise from LDCT images; the network architectures used are either handcrafted or built on top of conventional networks such as ResNet and U-Net. Recent advance on neural network architecture search (NAS) has proved that the network architecture has a dramatic effect on the model performance, which indicates that current network architectures for LDCT may be sub-optimal. Therefore, in this paper, we make the first attempt to apply NAS to LDCT and propose a multi-scale and multi-level NAS for LDCT denoising, termed MANAS. On the one hand, the proposed MANAS fuses features extracted by different scale cells to capture multi-scale image structural details. On the other hand, the proposed MANAS can search a hybrid cell- and network-level structure for better performance. Extensively experimental results on three different dose levels demonstrate that the proposed MANAS can achieve better performance in terms of preserving image structural details than several state-of-the-art methods. In addition, we also validate the effectiveness of the multi-scale and multi-level architecture for LDCT denoising.
An Empirical Study of Vehicle Re-Identification on the AI City Challenge
May 20, 2021
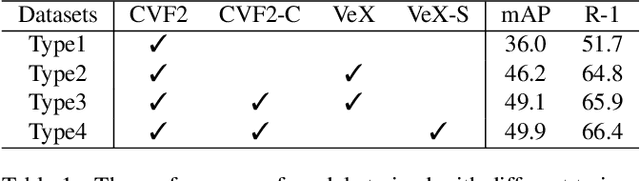
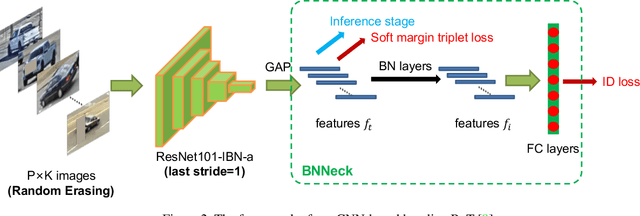

This paper introduces our solution for the Track2 in AI City Challenge 2021 (AICITY21). The Track2 is a vehicle re-identification (ReID) task with both the real-world data and synthetic data. We mainly focus on four points, i.e. training data, unsupervised domain-adaptive (UDA) training, post-processing, model ensembling in this challenge. (1) Both cropping training data and using synthetic data can help the model learn more discriminative features. (2) Since there is a new scenario in the test set that dose not appear in the training set, UDA methods perform well in the challenge. (3) Post-processing techniques including re-ranking, image-to-track retrieval, inter-camera fusion, etc, significantly improve final performance. (4) We ensemble CNN-based models and transformer-based models which provide different representation diversity. With aforementioned techniques, our method finally achieves 0.7445 mAP score, yielding the first place in the competition. Codes are available at https://github.com/michuanhaohao/AICITY2021_Track2_DMT.
Deep Learning for Rheumatoid Arthritis: Joint Detection and Damage Scoring in X-rays
Apr 28, 2021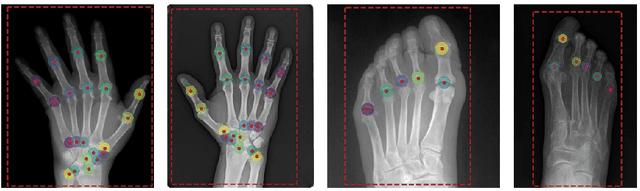
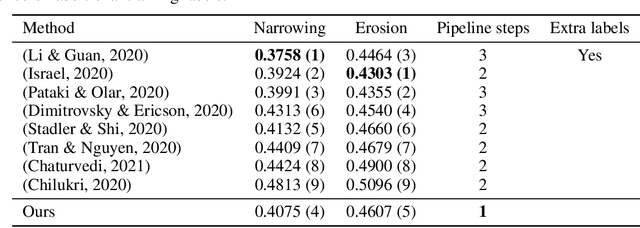
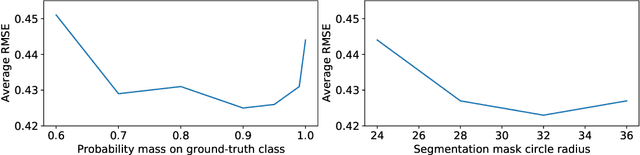
Recent advancements in computer vision promise to automate medical image analysis. Rheumatoid arthritis is an autoimmune disease that would profit from computer-based diagnosis, as there are no direct markers known, and doctors have to rely on manual inspection of X-ray images. In this work, we present a multi-task deep learning model that simultaneously learns to localize joints on X-ray images and diagnose two kinds of joint damage: narrowing and erosion. Additionally, we propose a modification of label smoothing, which combines classification and regression cues into a single loss and achieves 5% relative error reduction compared to standard loss functions. Our final model obtained 4th place in joint space narrowing and 5th place in joint erosion in the global RA2 DREAM challenge.
Learning Deep Representations for Semantic Image Parsing: a Comprehensive Overview
Oct 10, 2018


Semantic image parsing, which refers to the process of decomposing images into semantic regions and constructing the structure representation of the input, has recently aroused widespread interest in the field of computer vision. The recent application of deep representation learning has driven this field into a new stage of development. In this paper, we summarize three aspects of the progress of research on semantic image parsing, i.e., category-level semantic segmentation, instance-level semantic segmentation, and beyond segmentation. Specifically, we first review the general frameworks for each task and introduce the relevant variants. The advantages and limitations of each method are also discussed. Moreover, we present a comprehensive comparison of different benchmark datasets and evaluation metrics. Finally, we explore the future trends and challenges of semantic image parsing.
Classification and comparison of license plates localization algorithms
Apr 28, 2021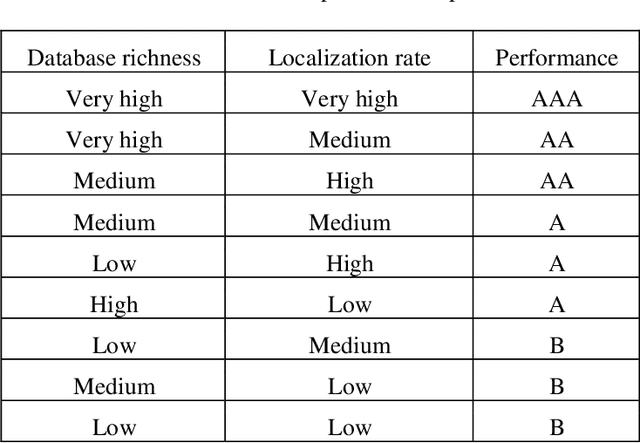
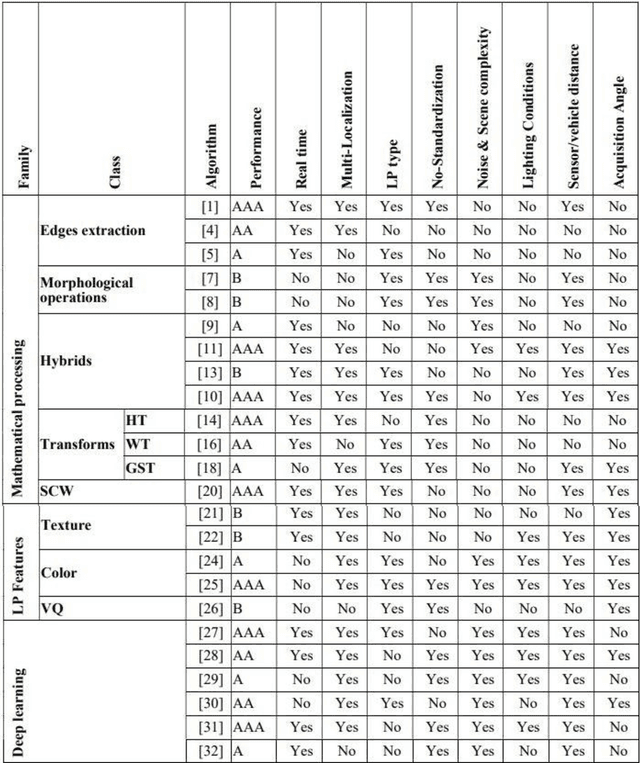
The Intelligent Transportation Systems (ITS) are the subject of a world economic competition. They are the application of new information and communication technologies in the transport sector, to make the infrastructures more efficient, more reliable and more ecological. License Plates Recognition (LPR) is the key module of these systems, in which the License Plate Localization (LPL) is the most important stage, because it determines the speed and robustness of this module. Thus, during this step the algorithm must process the image and overcome several constraints as climatic and lighting conditions, sensors and angles variety, LPs no-standardization, and the real time processing. This paper presents a classification and comparison of License Plates Localization (LPL) algorithms and describes the advantages, disadvantages and improvements made by each of them
Representation mitosis in wide neural networks
Jun 07, 2021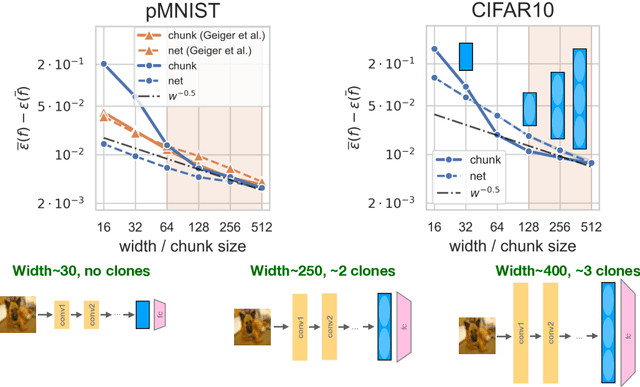
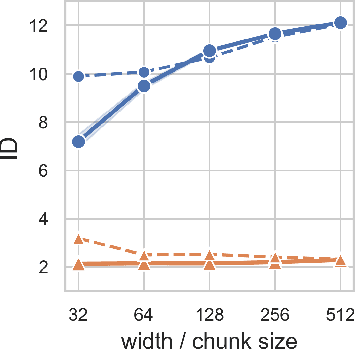
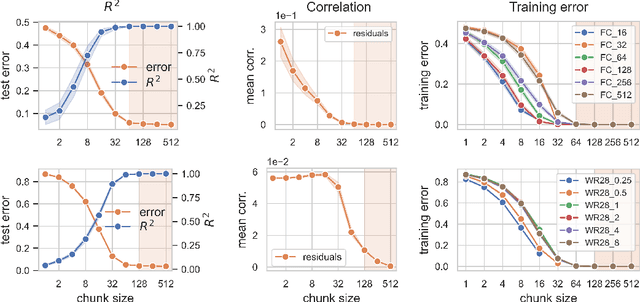
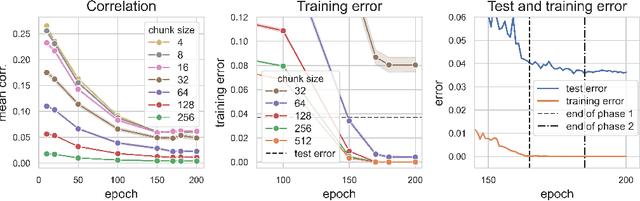
Deep neural networks (DNNs) defy the classical bias-variance trade-off: adding parameters to a DNN that exactly interpolates its training data will typically improve its generalisation performance. Explaining the mechanism behind the benefit of such over-parameterisation is an outstanding challenge for deep learning theory. Here, we study the last layer representation of various deep architectures such as Wide-ResNets for image classification and find evidence for an underlying mechanism that we call *representation mitosis*: if the last hidden representation is wide enough, its neurons tend to split into groups which carry identical information, and differ from each other only by a statistically independent noise. Like in a mitosis process, the number of such groups, or ``clones'', increases linearly with the width of the layer, but only if the width is above a critical value. We show that a key ingredient to activate mitosis is continuing the training process until the training error is zero. Finally, we show that in one of the learning tasks we considered, a wide model with several automatically developed clones performs significantly better than a deep ensemble based on architectures in which the last layer has the same size as the clones.
A Lightweight ReLU-Based Feature Fusion for Aerial Scene Classification
Jun 15, 2021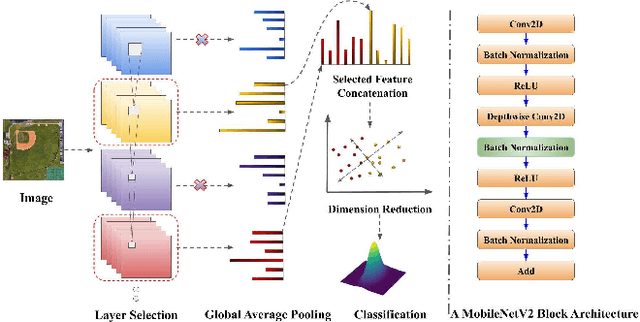

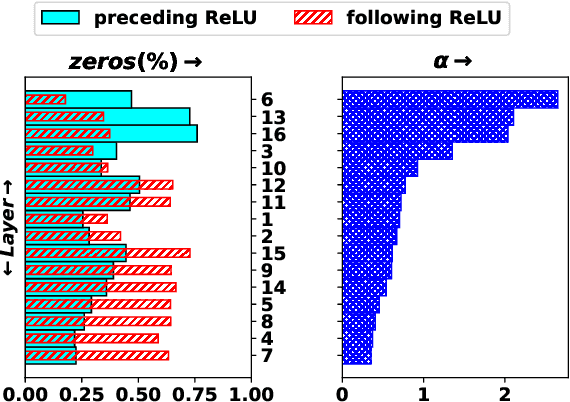
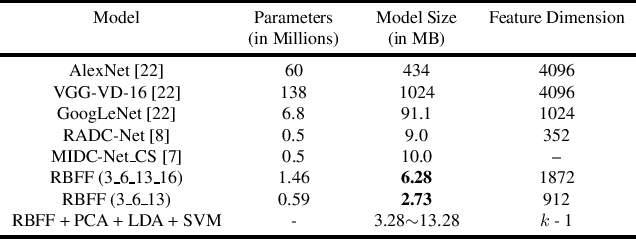
In this paper, we propose a transfer-learning based model construction technique for the aerial scene classification problem. The core of our technique is a layer selection strategy, named ReLU-Based Feature Fusion (RBFF), that extracts feature maps from a pretrained CNN-based single-object image classification model, namely MobileNetV2, and constructs a model for the aerial scene classification task. RBFF stacks features extracted from the batch normalization layer of a few selected blocks of MobileNetV2, where the candidate blocks are selected based on the characteristics of the ReLU activation layers present in those blocks. The feature vector is then compressed into a low-dimensional feature space using dimension reduction algorithms on which we train a low-cost SVM classifier for the classification of the aerial images. We validate our choice of selected features based on the significance of the extracted features with respect to our classification pipeline. RBFF remarkably does not involve any training of the base CNN model except for a few parameters for the classifier, which makes the technique very cost-effective for practical deployments. The constructed model despite being lightweight outperforms several recently proposed models in terms of accuracy for a number of aerial scene datasets.