 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Automatic Digital Documentation and Progress Reporting of Mechanical Construction Pipes using Smartphones
Dec 20, 2020
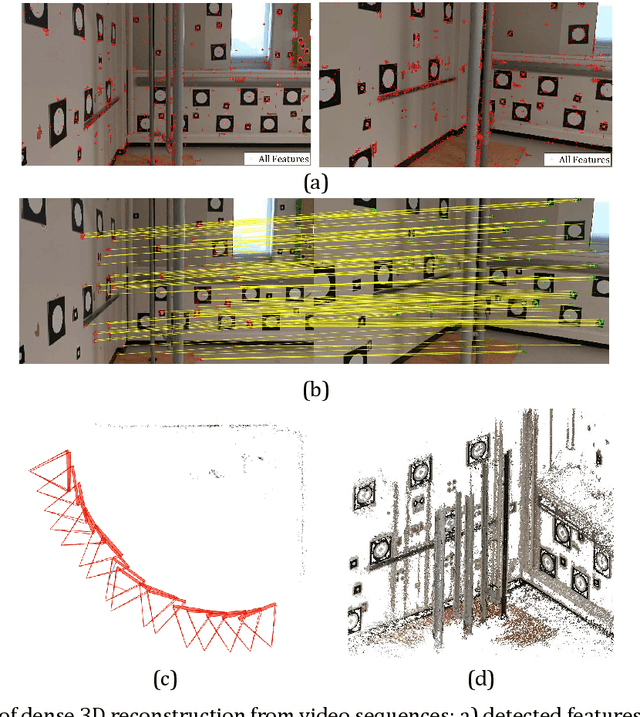
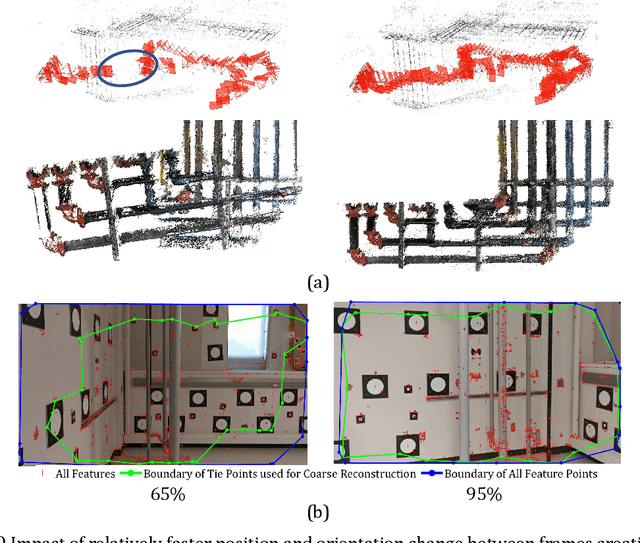
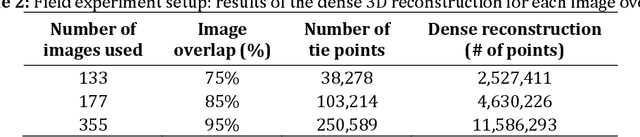
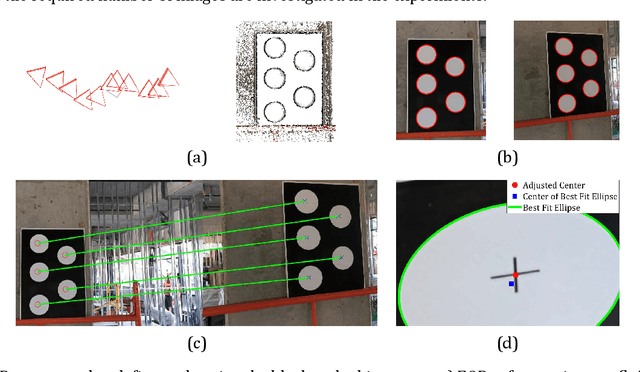
This manuscript presents a framework towards automated 3D digital documentation and progress reporting of mechanical pipes in building construction projects, using smartphones. New methods were proposed to determine the video frame rate required to achieve a desired image overlap; define metric scale for 3D reconstruction; extract pipes from point clouds; and classify pipes according to their planned bill of quantity radii. The effectiveness of the proposed methods in both laboratory (six pipes) and construction site (58 pipes) conditions was evaluated. It was observed that the proposed metric scale definition achieved sub-millimeter pipe radius estimation accuracy. Both laboratory and field experiments revealed that increasing the image overlap improved the pipe classification quality, radius, and length. Overall, using the proposed methods, it was possible to achieve pipe classification F-measure, radius estimation accuracy, and length estimation percent error of 96.4%, 5.4mm, and 5.0%, respectively, on construction sites using at least 95% image overlap.
Error Correction Maximization for Deep Image Hashing
Aug 06, 2018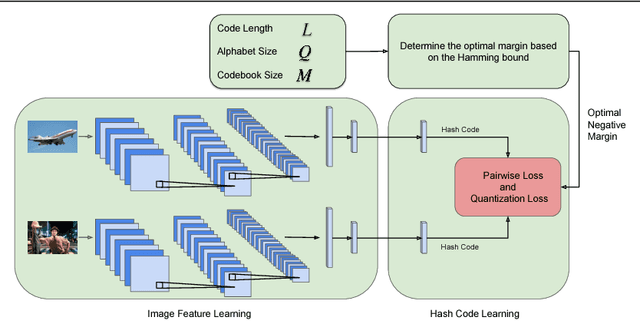
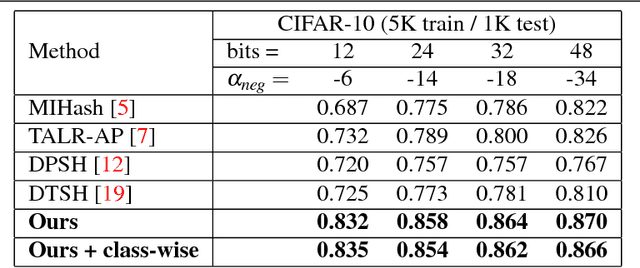
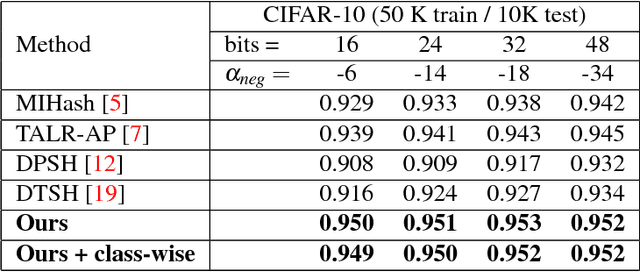
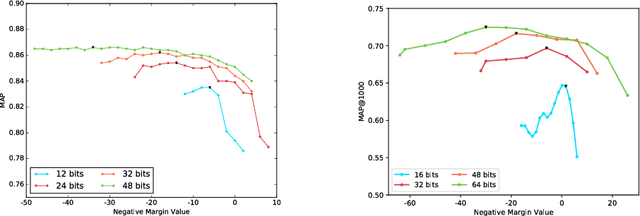
We propose to use the concept of the Hamming bound to derive the optimal criteria for learning hash codes with a deep network. In particular, when the number of binary hash codes (typically the number of image categories) and code length are known, it is possible to derive an upper bound on the minimum Hamming distance between the hash codes. This upper bound can then be used to define the loss function for learning hash codes. By encouraging the margin (minimum Hamming distance) between the hash codes of different image categories to match the upper bound, we are able to learn theoretically optimal hash codes. Our experiments show that our method significantly outperforms competing deep learning-based approaches and obtains top performance on benchmark datasets.
Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation
Jul 30, 2019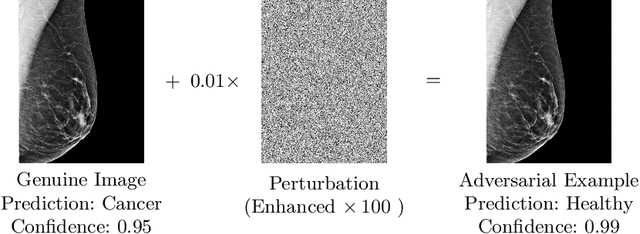
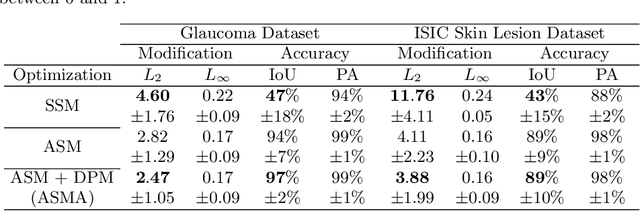

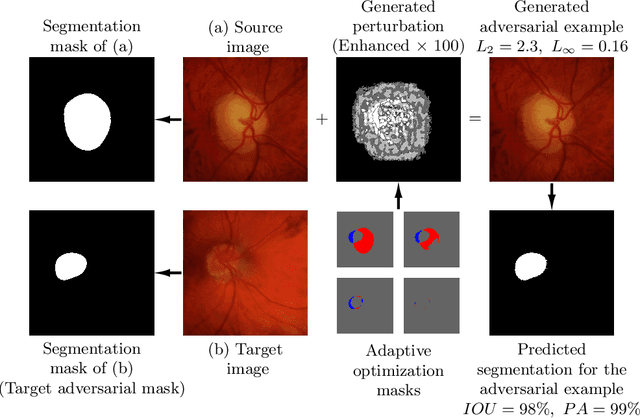
Deep learning models, which are increasingly being used in the field of medical image analysis, come with a major security risk, namely, their vulnerability to adversarial examples. Adversarial examples are carefully crafted samples that force machine learning models to make mistakes during testing time. These malicious samples have been shown to be highly effective in misguiding classification tasks. However, research on the influence of adversarial examples on segmentation is significantly lacking. Given that a large portion of medical imaging problems are effectively segmentation problems, we analyze the impact of adversarial examples on deep learning-based image segmentation models. Specifically, we expose the vulnerability of these models to adversarial examples by proposing the Adaptive Segmentation Mask Attack (ASMA). This novel algorithm makes it possible to craft targeted adversarial examples that come with (1) high intersection-over-union rates between the target adversarial mask and the prediction and (2) with perturbation that is, for the most part, invisible to the bare eye. We lay out experimental and visual evidence by showing results obtained for the ISIC skin lesion segmentation challenge and the problem of glaucoma optic disc segmentation. An implementation of this algorithm and additional examples can be found at https://github.com/utkuozbulak/adaptive-segmentation-mask-attack.
Brain over Brawn -- Using a Stereo Camera to Detect, Track and Intercept a Faster UAV by Reconstructing Its Trajectory
Jul 02, 2021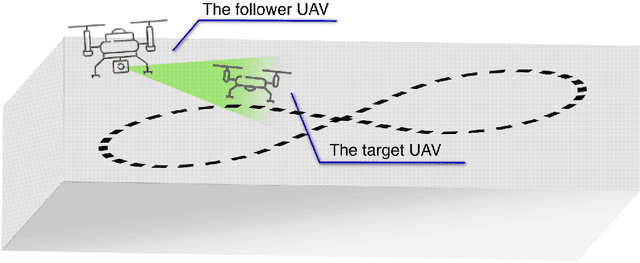
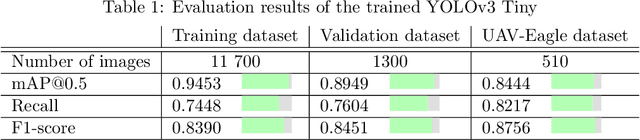

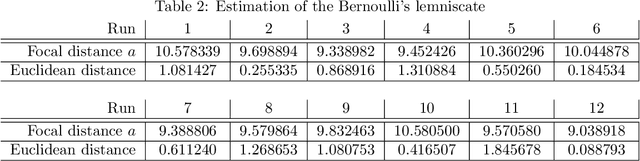
The work presented in this paper demonstrates our approach to intercepting a faster intruder UAV, inspired by the MBZIRC2020 Challenge 1. By leveraging the knowledge of the shape of the intruder's trajectory we are able to calculate the interception point. Target tracking is based on image processing by a YOLOv3 Tiny convolutional neural network, combined with depth calculation using a gimbal-mounted ZED Mini stereo camera. We use RGB and depth data from ZED Mini to extract the 3D position of the target, for which we devise a histogram-of-depth based processing to reduce noise. Obtained 3D measurements of target's position are used to calculate the position, the orientation and the size of a figure-eight shaped trajectory, which we approximate using lemniscate of Bernoulli. Once the approximation is deemed sufficiently precise, measured by Hausdorff distance between measurements and the approximation, an interception point is calculated to position the intercepting UAV right on the path of the target. The proposed method, which has been significantly improved based on the experience gathered during the MBZIRC competition, has been validated in simulation and through field experiments. The results confirmed that an efficient visual perception module which extracts information related to the motion of the target UAV as a basis for the interception, has been developed. The system is able to track and intercept the target which is 30% faster than the interceptor in majority of simulation experiments. Tests in the unstructured environment yielded 9 out of 12 successful results.
A Residual Network based Deep Learning Model for Detection of COVID-19 from Cough Sounds
Jun 04, 2021
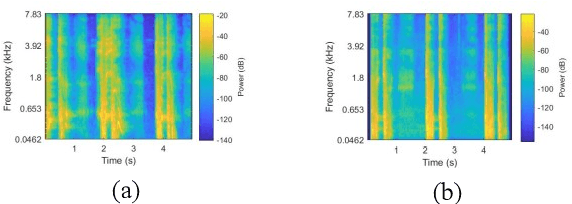
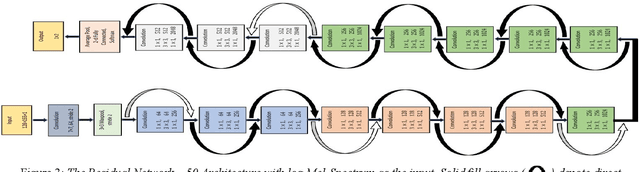
The present work proposes a deep-learning-based approach for the classification of COVID-19 coughs from non-COVID-19 coughs and that can be used as a low-resource-based tool for early detection of the onset of such respiratory diseases. The proposed system uses the ResNet-50 architecture, a popularly known Convolutional Neural Network (CNN) for image recognition tasks, fed with the log-Mel spectrums of the audio data to discriminate between the two types of coughs. For the training and validation of the proposed deep learning model, this work utilizes the Track-1 dataset provided by the DiCOVA Challenge 2021 organizers. Additionally, to increase the number of COVID-positive samples and to enhance variability in the training data, it has also utilized a large open-source database of COVID-19 coughs collected by the EPFL CoughVid team. Our developed model has achieved an average validation AUC of 98.88%. Also, applying this model on the Blind Test Set released by the DiCOVA Challenge, the system has achieved a Test AUC of 75.91%, Test Specificity of 62.50%, and Test Sensitivity of 80.49%. Consequently, this submission has secured 16th position in the DiCOVA Challenge 2021 leader-board.
Zero-Shot Sketch-Image Hashing
Mar 06, 2018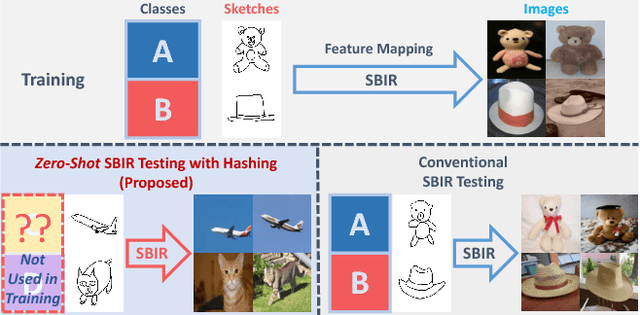
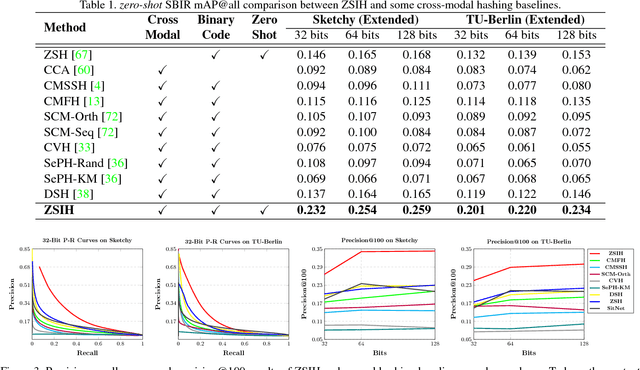
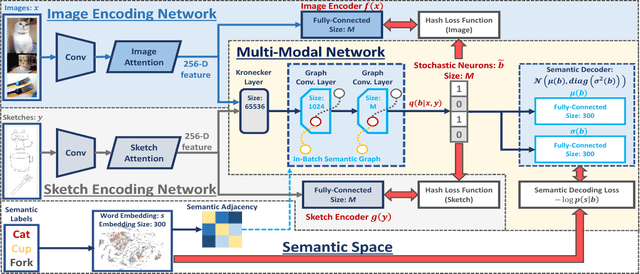
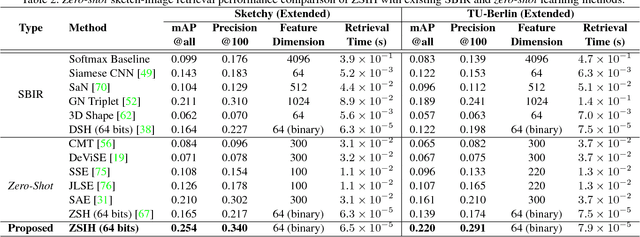
Recent studies show that large-scale sketch-based image retrieval (SBIR) can be efficiently tackled by cross-modal binary representation learning methods, where Hamming distance matching significantly speeds up the process of similarity search. Providing training and test data subjected to a fixed set of pre-defined categories, the cutting-edge SBIR and cross-modal hashing works obtain acceptable retrieval performance. However, most of the existing methods fail when the categories of query sketches have never been seen during training. In this paper, the above problem is briefed as a novel but realistic zero-shot SBIR hashing task. We elaborate the challenges of this special task and accordingly propose a zero-shot sketch-image hashing (ZSIH) model. An end-to-end three-network architecture is built, two of which are treated as the binary encoders. The third network mitigates the sketch-image heterogeneity and enhances the semantic relations among data by utilizing the Kronecker fusion layer and graph convolution, respectively. As an important part of ZSIH, we formulate a generative hashing scheme in reconstructing semantic knowledge representations for zero-shot retrieval. To the best of our knowledge, ZSIH is the first zero-shot hashing work suitable for SBIR and cross-modal search. Comprehensive experiments are conducted on two extended datasets, i.e., Sketchy and TU-Berlin with a novel zero-shot train-test split. The proposed model remarkably outperforms related works.
Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location Estimation
May 17, 2021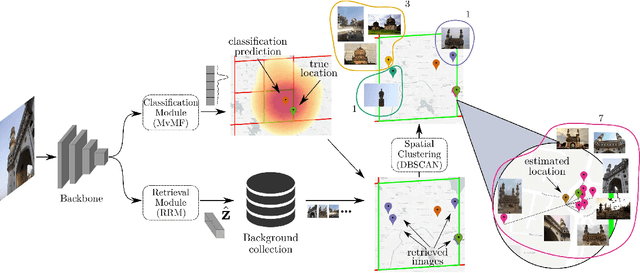
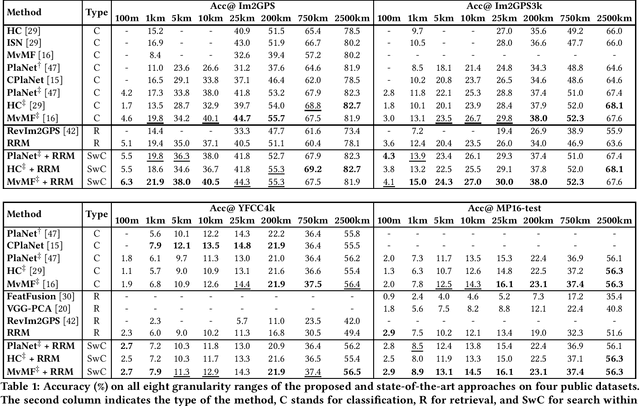
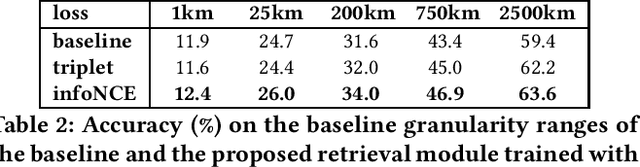
In this paper, we address the problem of global-scale image geolocation, proposing a mixed classification-retrieval scheme. Unlike other methods that strictly tackle the problem as a classification or retrieval task, we combine the two practices in a unified solution leveraging the advantages of each approach with two different modules. The first leverages the EfficientNet architecture to assign images to a specific geographic cell in a robust way. The second introduces a new residual architecture that is trained with contrastive learning to map input images to an embedding space that minimizes the pairwise geodesic distance of same-location images. For the final location estimation, the two modules are combined with a search-within-cell scheme, where the locations of most similar images from the predicted geographic cell are aggregated based on a spatial clustering scheme. Our approach demonstrates very competitive performance on four public datasets, achieving new state-of-the-art performance in fine granularity scales, i.e., 15.0% at 1km range on Im2GPS3k.
DeepSeagrass Dataset
Mar 09, 2021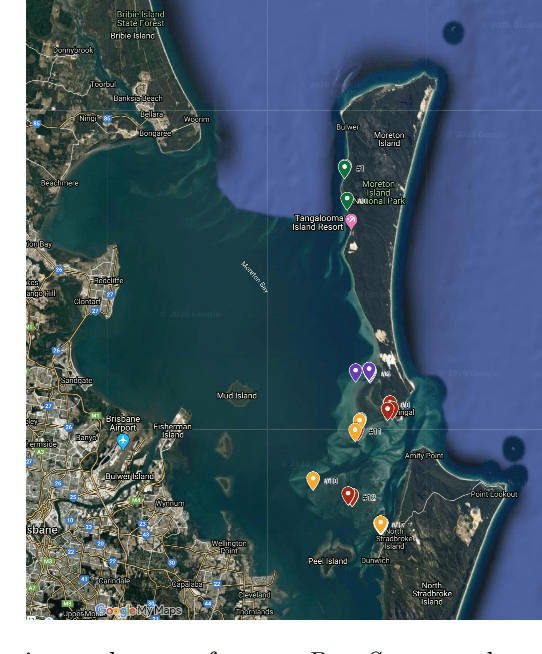
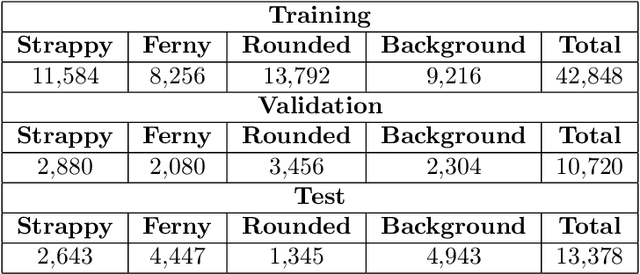
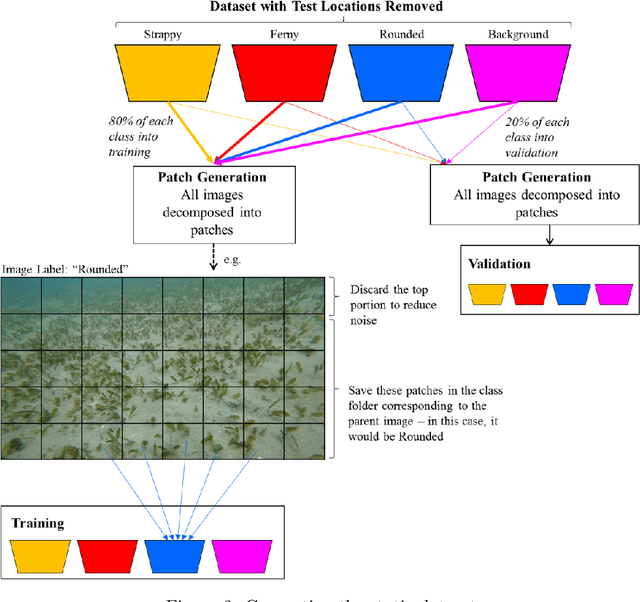

We introduce a dataset of seagrass images collected by a biologist snorkelling in Moreton Bay, Queensland, Australia, as described in our publication: arXiv:2009.09924. The images are labelled at the image-level by collecting images of the same morphotype in a folder hierarchy. We also release pre-trained models and training codes for detection and classification of seagrass species at the patch level at https://github.com/csiro-robotics/deepseagrass.
Tracking 6-DoF Object Motion from Events and Frames
Mar 29, 2021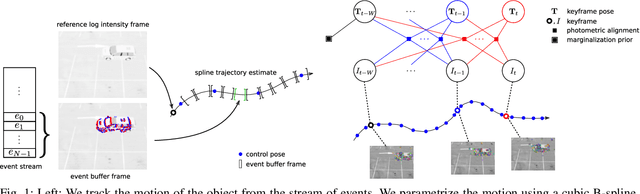
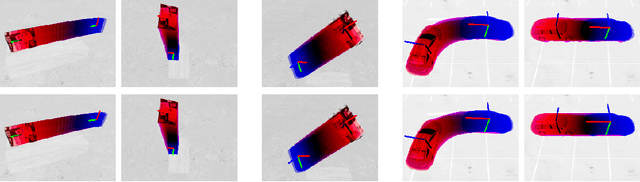
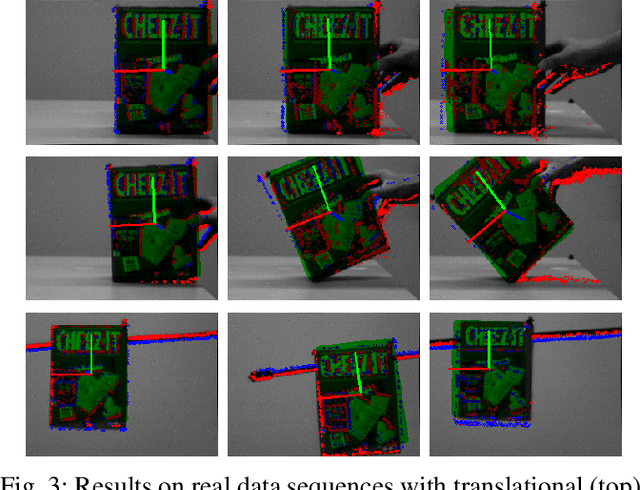

Event cameras are promising devices for lowlatency tracking and high-dynamic range imaging. In this paper,we propose a novel approach for 6 degree-of-freedom (6-DoF)object motion tracking that combines measurements of eventand frame-based cameras. We formulate tracking from highrate events with a probabilistic generative model of the eventmeasurement process of the object. On a second layer, we refinethe object trajectory in slower rate image frames through directimage alignment. We evaluate the accuracy of our approach inseveral object tracking scenarios with synthetic data, and alsoperform experiments with real data.
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
May 12, 2021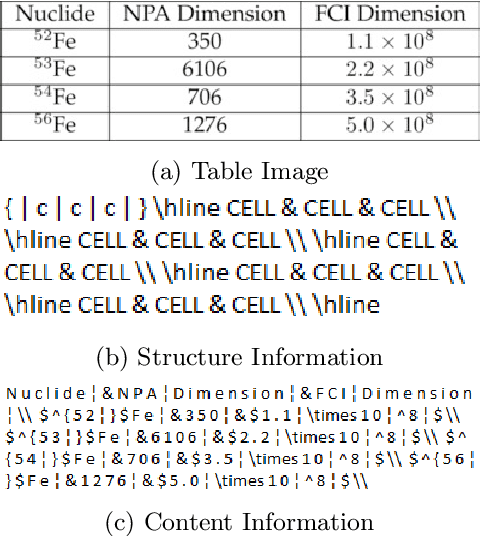
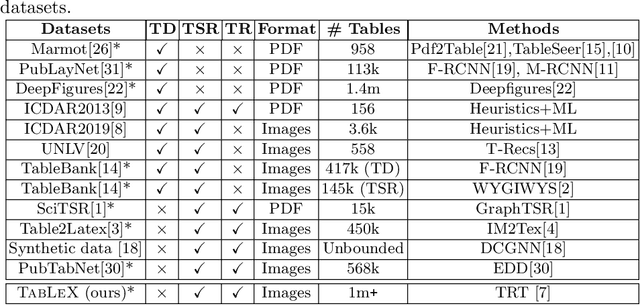
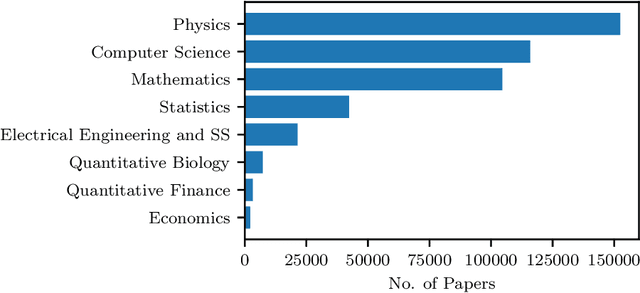
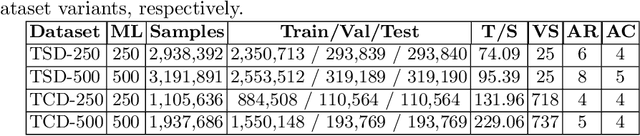
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.