 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Convolution Neural Network based Person Identification using Gait cycles
Jun 06, 2021
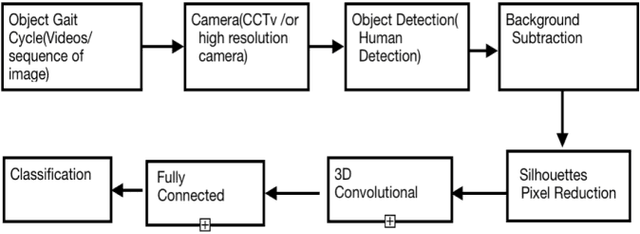

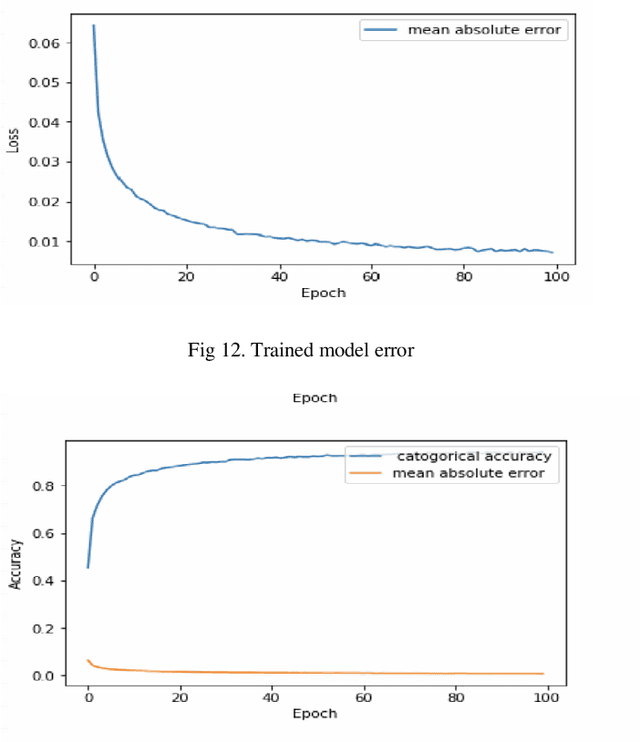
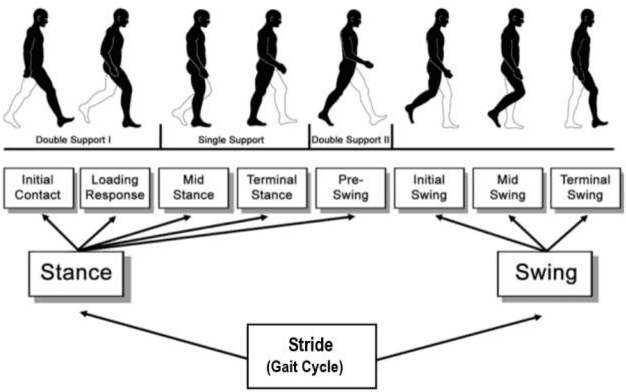
Human identification plays a prominent role in terms of security. In modern times security is becoming the key term for an individual or a country, especially for countries which are facing internal or external threats. Gait analysis is interpreted as the systematic study of the locomotive in humans. It can be used to extract the exact walking features of individuals. Walking features depends on biological as well as the physical feature of the object; hence, it is unique to every individual. In this work, gait features are used to identify an individual. The steps involve object detection, background subtraction, silhouettes extraction, skeletonization, and training 3D Convolution Neural Network on these gait features. The model is trained and evaluated on the dataset acquired by CASIA B Gait, which consists of 15000 videos of 124 subjects walking pattern captured from 11 different angles carrying objects such as bag and coat. The proposed method focuses more on the lower body part to extract features such as the angle between knee and thighs, hip angle, angle of contact, and many other features. The experimental results are compared with amongst accuracies of silhouettes as datasets for training and skeletonized image as training data. The results show that extracting the information from skeletonized data yields improved accuracy.
2018 PIRM Challenge on Perceptual Image Super-resolution
Oct 03, 2018
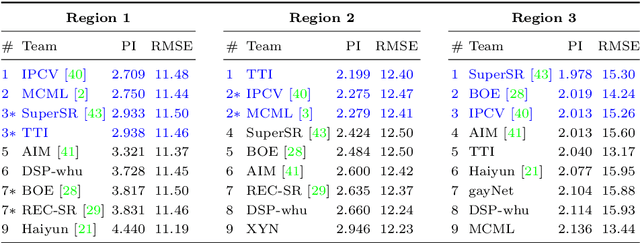
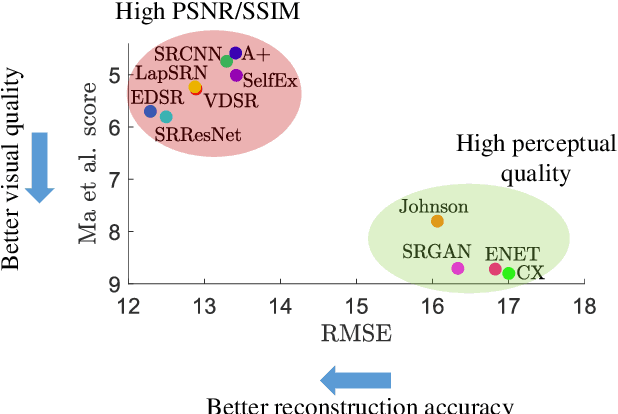

This paper reports on the 2018 PIRM challenge on perceptual super-resolution (SR), held in conjunction with the Perceptual Image Restoration and Manipulation (PIRM) workshop at ECCV 2018. In contrast to previous SR challenges, our evaluation methodology jointly quantifies accuracy and perceptual quality, therefore enabling perceptual-driven methods to compete alongside algorithms that target PSNR maximization. Twenty-one participating teams introduced algorithms which well-improved upon the existing state-of-the-art methods in perceptual SR, as confirmed by a human opinion study. We also analyze popular image quality measures and draw conclusions regarding which of them correlates best with human opinion scores. We conclude with an analysis of the current trends in perceptual SR, as reflected from the leading submissions.
Estimating and Improving Fairness with Adversarial Learning
Mar 07, 2021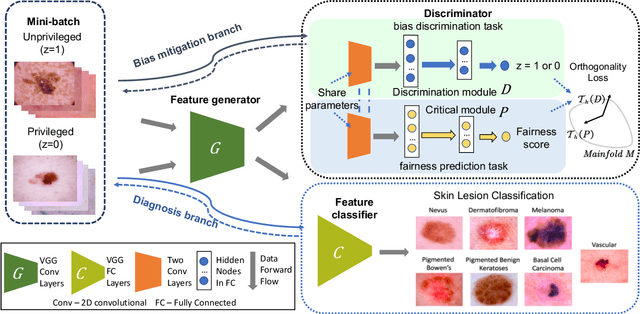
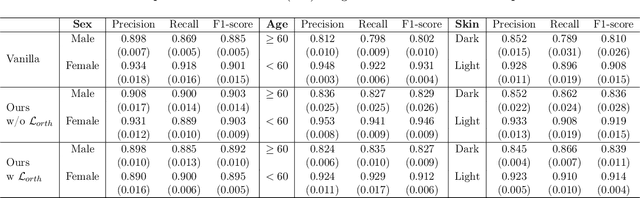
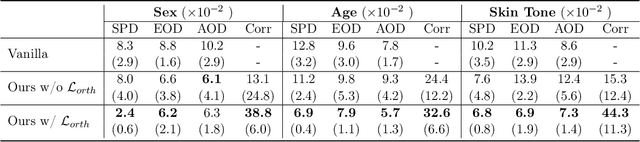
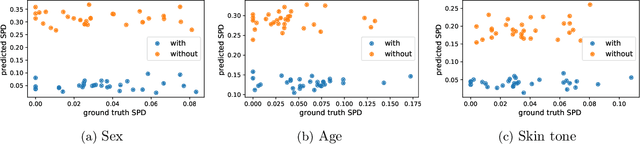
Fairness and accountability are two essential pillars for trustworthy Artificial Intelligence (AI) in healthcare. However, the existing AI model may be biased in its decision marking. To tackle this issue, we propose an adversarial multi-task training strategy to simultaneously mitigate and detect bias in the deep learning-based medical image analysis system. Specifically, we propose to add a discrimination module against bias and a critical module that predicts unfairness within the base classification model. We further impose an orthogonality regularization to force the two modules to be independent during training. Hence, we can keep these deep learning tasks distinct from one another, and avoid collapsing them into a singular point on the manifold. Through this adversarial training method, the data from the underprivileged group, which is vulnerable to bias because of attributes such as sex and skin tone, are transferred into a domain that is neutral relative to these attributes. Furthermore, the critical module can predict fairness scores for the data with unknown sensitive attributes. We evaluate our framework on a large-scale public-available skin lesion dataset under various fairness evaluation metrics. The experiments demonstrate the effectiveness of our proposed method for estimating and improving fairness in the deep learning-based medical image analysis system.
Deep Matching Prior: Test-Time Optimization for Dense Correspondence
Jun 06, 2021
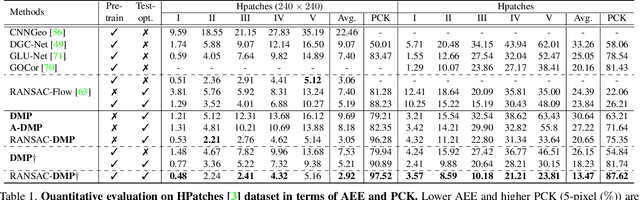
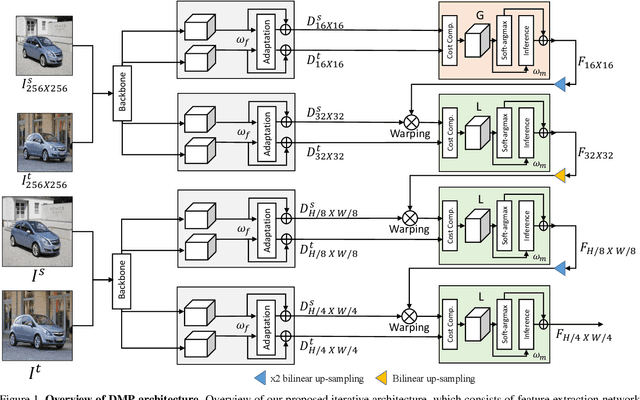
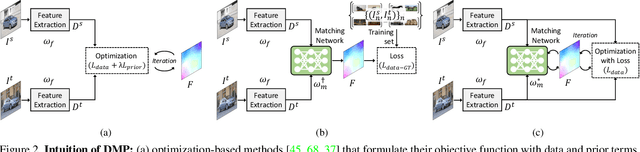
Conventional techniques to establish dense correspondences across visually or semantically similar images focused on designing a task-specific matching prior, which is difficult to model. To overcome this, recent learning-based methods have attempted to learn a good matching prior within a model itself on large training data. The performance improvement was apparent, but the need for sufficient training data and intensive learning hinders their applicability. Moreover, using the fixed model at test time does not account for the fact that a pair of images may require their own prior, thus providing limited performance and poor generalization to unseen images. In this paper, we show that an image pair-specific prior can be captured by solely optimizing the untrained matching networks on an input pair of images. Tailored for such test-time optimization for dense correspondence, we present a residual matching network and a confidence-aware contrastive loss to guarantee a meaningful convergence. Experiments demonstrate that our framework, dubbed Deep Matching Prior (DMP), is competitive, or even outperforms, against the latest learning-based methods on several benchmarks for geometric matching and semantic matching, even though it requires neither large training data nor intensive learning. With the networks pre-trained, DMP attains state-of-the-art performance on all benchmarks.
Saliency Driven Image Manipulation
Jan 17, 2018
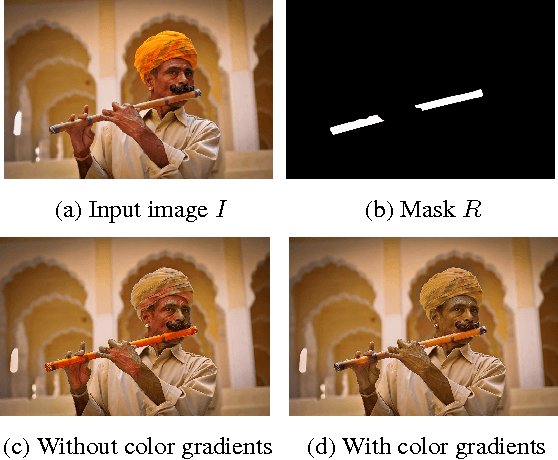
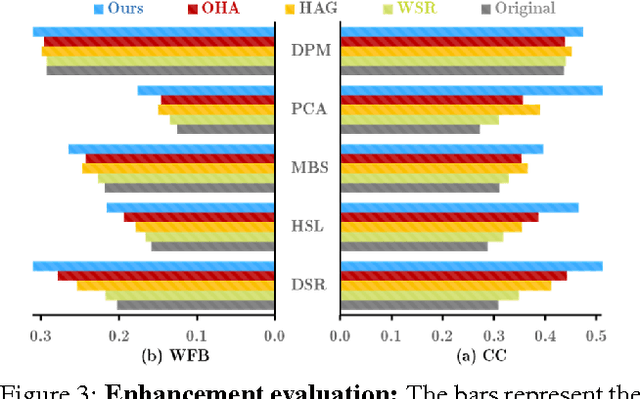
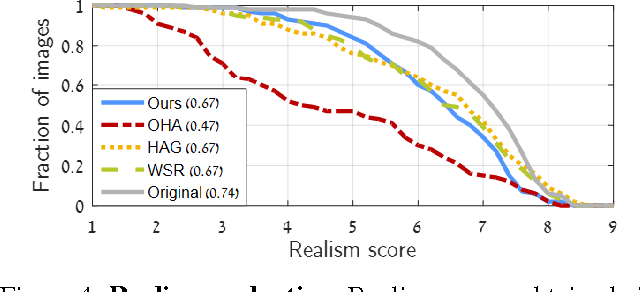
Have you ever taken a picture only to find out that an unimportant background object ended up being overly salient? Or one of those team sports photos where your favorite player blends with the rest? Wouldn't it be nice if you could tweak these pictures just a little bit so that the distractor would be attenuated and your favorite player will stand-out among her peers? Manipulating images in order to control the saliency of objects is the goal of this paper. We propose an approach that considers the internal color and saliency properties of the image. It changes the saliency map via an optimization framework that relies on patch-based manipulation using only patches from within the same image to achieve realistic looking results. Applications include object enhancement, distractors attenuation and background decluttering. Comparing our method to previous ones shows significant improvement, both in the achieved saliency manipulation and in the realistic appearance of the resulting images.
Block-optimized Variable Bit Rate Neural Image Compression
May 28, 2018
In this work, we propose an end-to-end block-based auto-encoder system for image compression. We introduce novel contributions to neural-network based image compression, mainly in achieving binarization simulation, variable bit rates with multiple networks, entropy-friendly representations, inference-stage code optimization and performance-improving normalization layers in the auto-encoder. We evaluate and show the incremental performance increase of each of our contributions.
Channel-Based Attention for LCC Using Sentinel-2 Time Series
Mar 31, 2021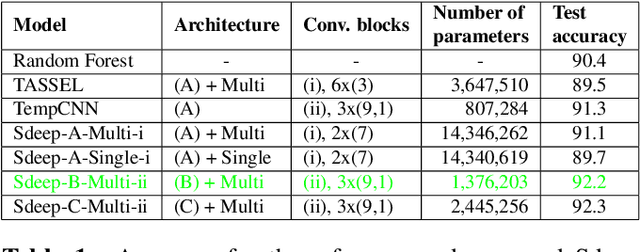
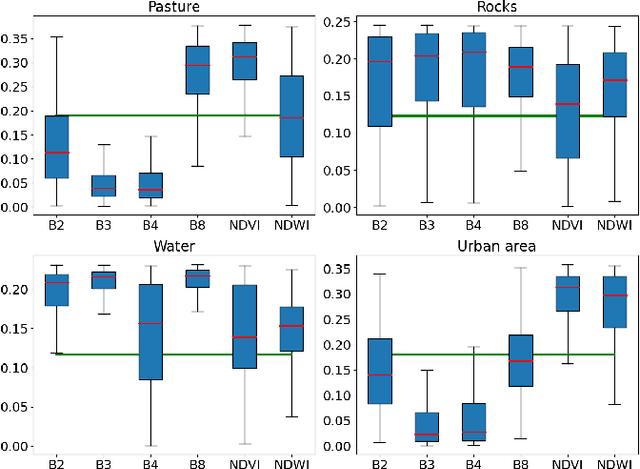
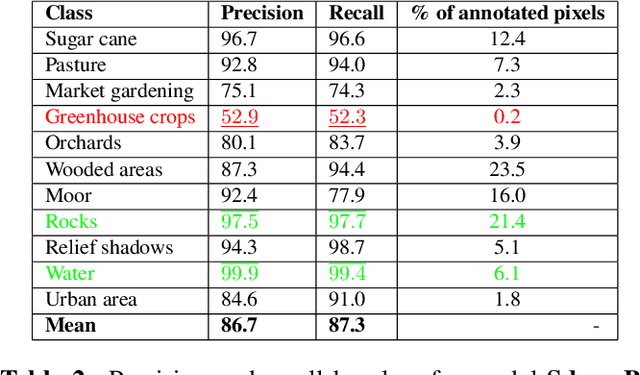
Deep Neural Networks (DNNs) are getting increasing attention to deal with Land Cover Classification (LCC) relying on Satellite Image Time Series (SITS). Though high performances can be achieved, the rationale of a prediction yielded by a DNN often remains unclear. An architecture expressing predictions with respect to input channels is thus proposed in this paper. It relies on convolutional layers and an attention mechanism weighting the importance of each channel in the final classification decision. The correlation between channels is taken into account to set up shared kernels and lower model complexity. Experiments based on a Sentinel-2 SITS show promising results.
Deep Semi-Supervised Learning for Time Series Classification
Feb 06, 2021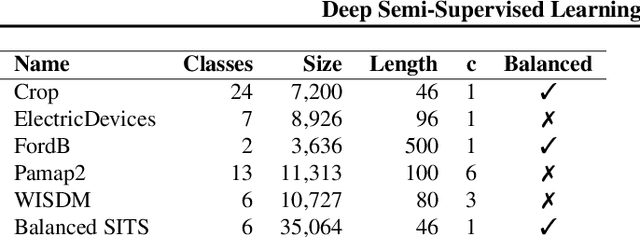
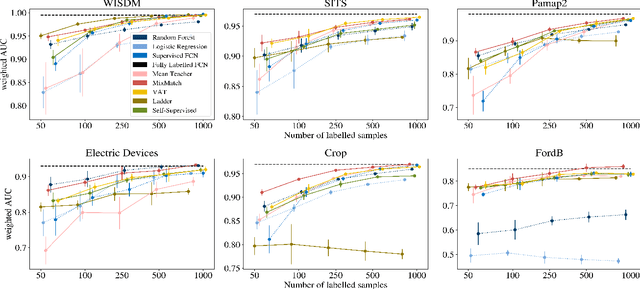
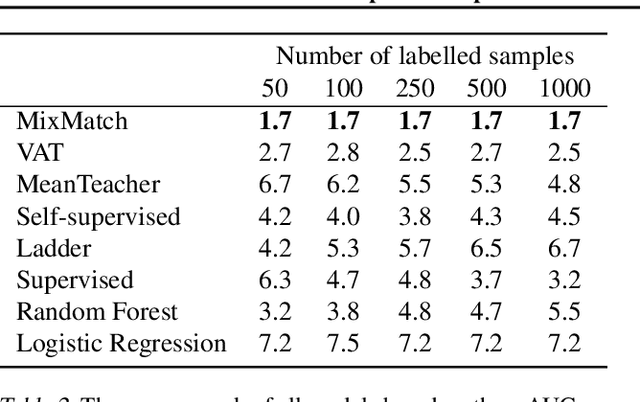
While Semi-supervised learning has gained much attention in computer vision on image data, yet limited research exists on its applicability in the time series domain. In this work, we investigate the transferability of state-of-the-art deep semi-supervised models from image to time series classification. We discuss the necessary model adaptations, in particular an appropriate model backbone architecture and the use of tailored data augmentation strategies. Based on these adaptations, we explore the potential of deep semi-supervised learning in the context of time series classification by evaluating our methods on large public time series classification problems with varying amounts of labelled samples. We perform extensive comparisons under a decidedly realistic and appropriate evaluation scheme with a unified reimplementation of all algorithms considered, which is yet lacking in the field. We find that these transferred semi-supervised models show significant performance gains over strong supervised, semi-supervised and self-supervised alternatives, especially for scenarios with very few labelled samples.
A Framework using Contrastive Learning for Classification with Noisy Labels
Apr 19, 2021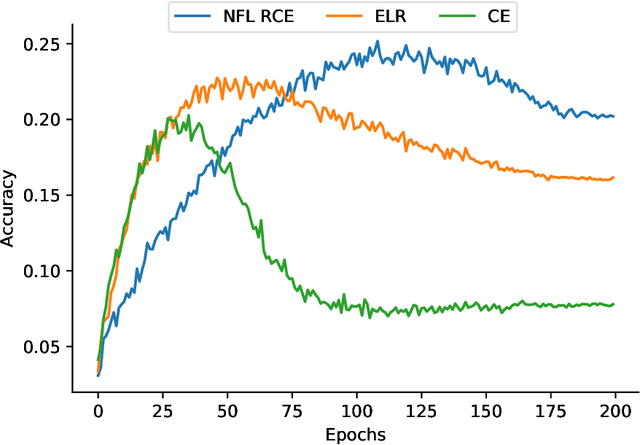
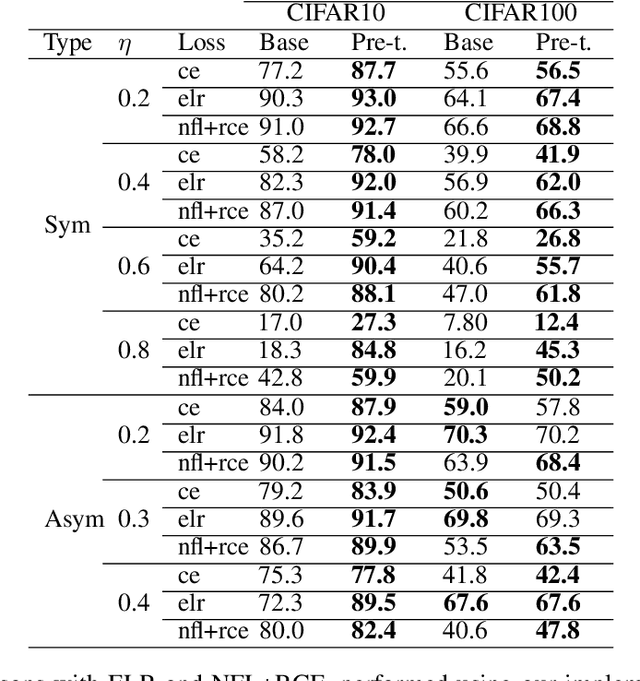
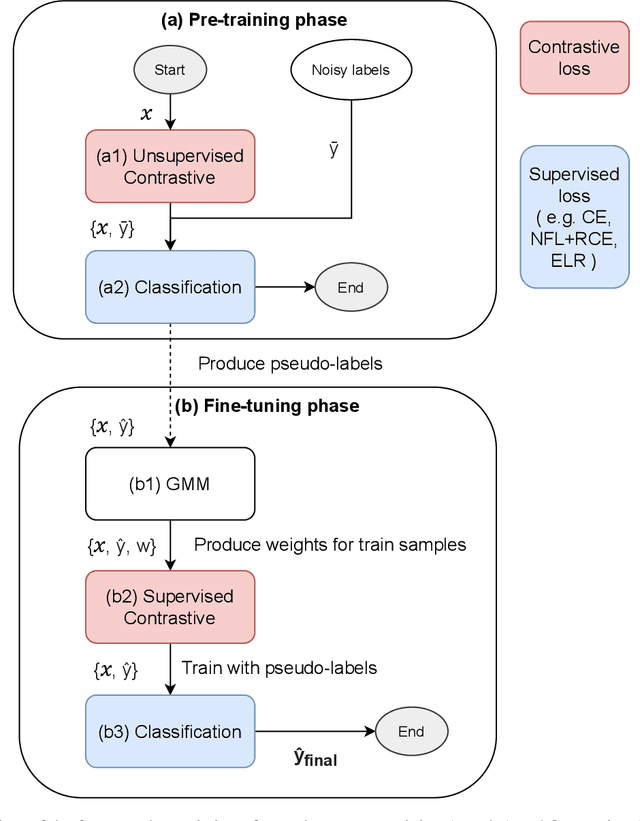
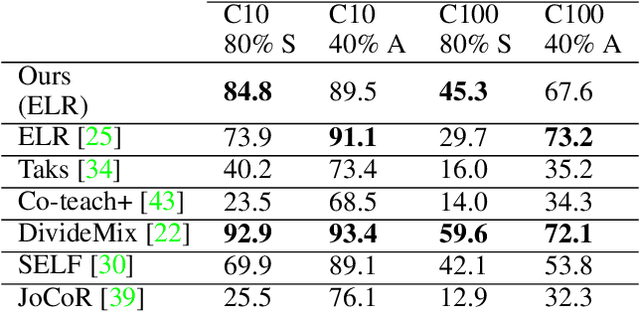
We propose a framework using contrastive learning as a pre-training task to perform image classification in the presence of noisy labels. Recent strategies such as pseudo-labeling, sample selection with Gaussian Mixture models, weighted supervised contrastive learning have been combined into a fine-tuning phase following the pre-training. This paper provides an extensive empirical study showing that a preliminary contrastive learning step brings a significant gain in performance when using different loss functions: non-robust, robust, and early-learning regularized. Our experiments performed on standard benchmarks and real-world datasets demonstrate that: i) the contrastive pre-training increases the robustness of any loss function to noisy labels and ii) the additional fine-tuning phase can further improve accuracy but at the cost of additional complexity.
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018

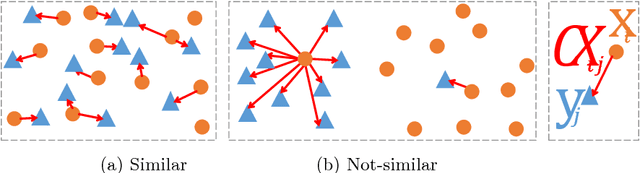
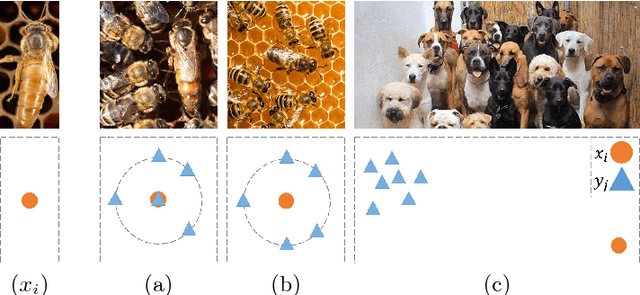
Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss