 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pseudo Supervised Solar Panel Mapping based on Deep Convolutional Networks with Label Correction Strategy in Aerial Images
Mar 16, 2021
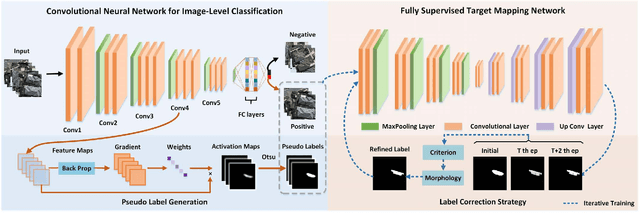

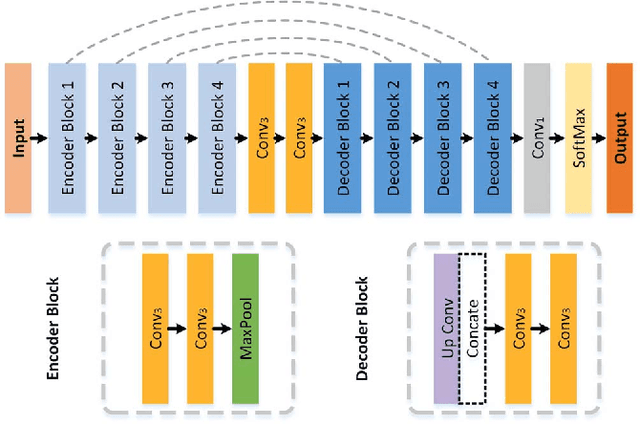

Solar panel mapping has gained a rising interest in renewable energy field with the aid of remote sensing imagery. Significant previous work is based on fully supervised learning with classical classifiers or convolutional neural networks (CNNs), which often require manual annotations of pixel-wise ground-truth to provide accurate supervision. Weakly supervised methods can accept image-wise annotations which can help reduce the cost for pixel-level labelling. Inevitable performance gap, however, exists between weakly and fully supervised methods in mapping accuracy. To address this problem, we propose a pseudo supervised deep convolutional network with label correction strategy (PS-CNNLC) for solar panels mapping. It combines the benefits of both weak and strong supervision to provide accurate solar panel extraction. First, a convolutional neural network is trained with positive and negative samples with image-level labels. It is then used to automatically identify more positive samples from randomly selected unlabeled images. The feature maps of the positive samples are further processed by gradient-weighted class activation mapping to generate initial mapping results, which are taken as initial pseudo labels as they are generally coarse and incomplete. A progressive label correction strategy is designed to refine the initial pseudo labels and train an end-to-end target mapping network iteratively, thereby improving the model reliability. Comprehensive evaluations and ablation study conducted validate the superiority of the proposed PS-CNNLC.
Transformer in Transformer
Feb 27, 2021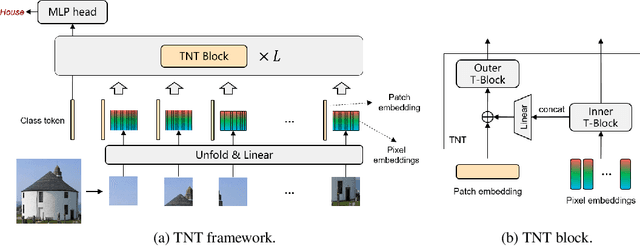

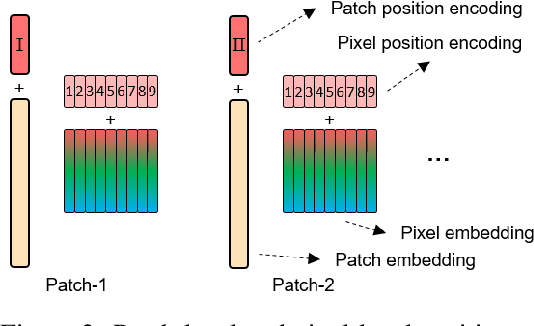
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves $81.3\%$ top-1 accuracy on ImageNet which is $1.5\%$ higher than that of DeiT with similar computational cost. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/TNT.
Image to Video Domain Adaptation Using Web Supervision
Aug 05, 2019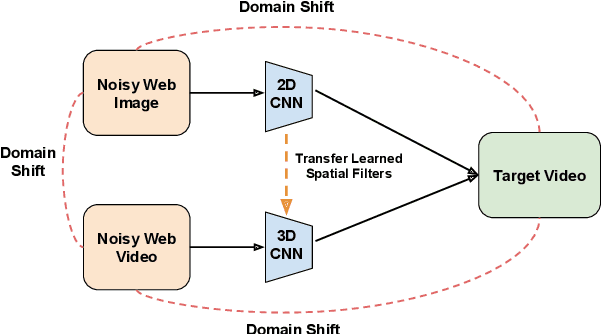
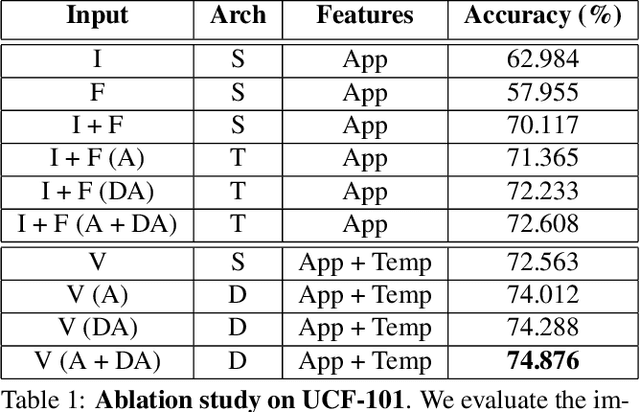
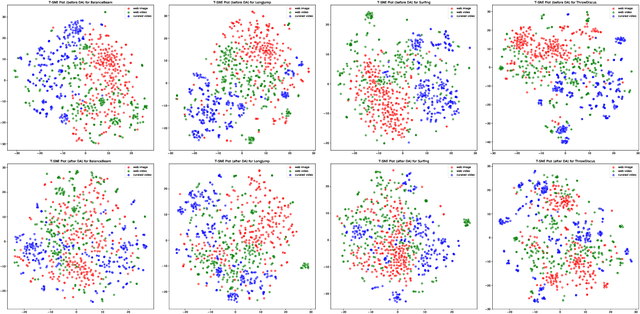
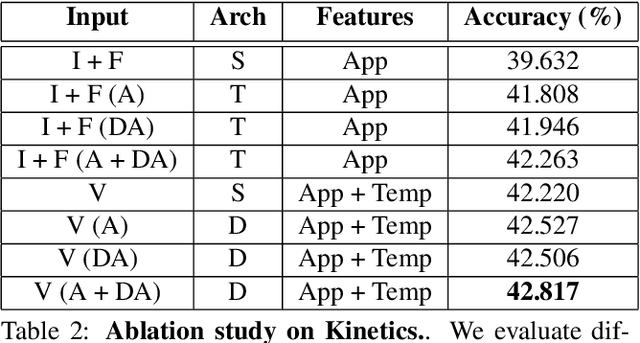
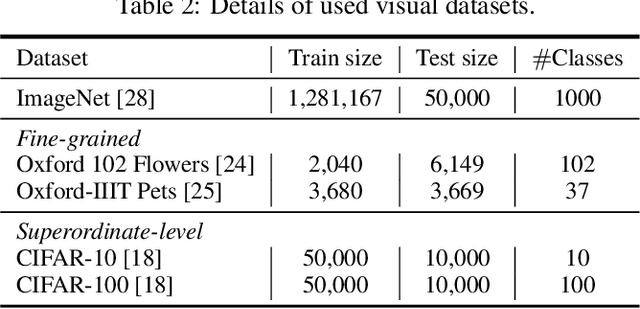
Training deep neural networks typically requires large amounts of labeled data which may be scarce or expensive to obtain for a particular target domain. As an alternative, we can leverage webly-supervised data (i.e. results from a public search engine) which are relatively plentiful but may contain noisy results. In this work, we propose a novel two-stage approach to learn a video classifier using webly-supervised data. We argue that learning appearance features and then temporal features sequentially, rather than simultaneously, is an easier optimization for this task. We show this by first learning an image model from web images, which is used to initialize and train a video model. Our model applies domain adaptation to account for potential domain shift present between the source domain (webly-supervised data) and target domain and also accounts for noise by adding a novel attention component. We report results competitive with state-of-the-art for webly-supervised approaches on UCF-101 (while simplifying the training process) and also evaluate on Kinetics for comparison.
Self-Supervised Annotation of Seismic Images using Latent Space Factorization
Sep 26, 2020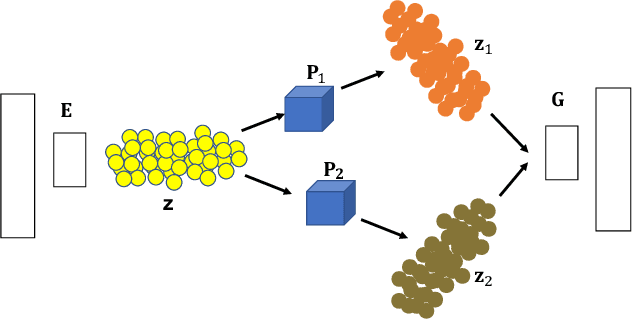
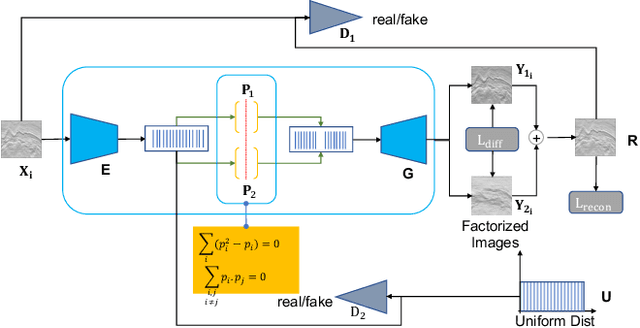
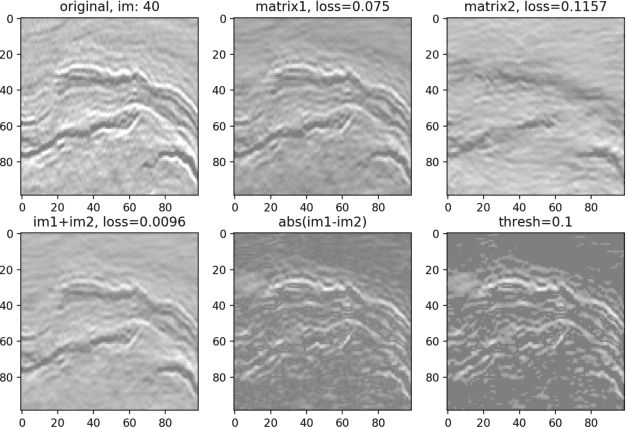
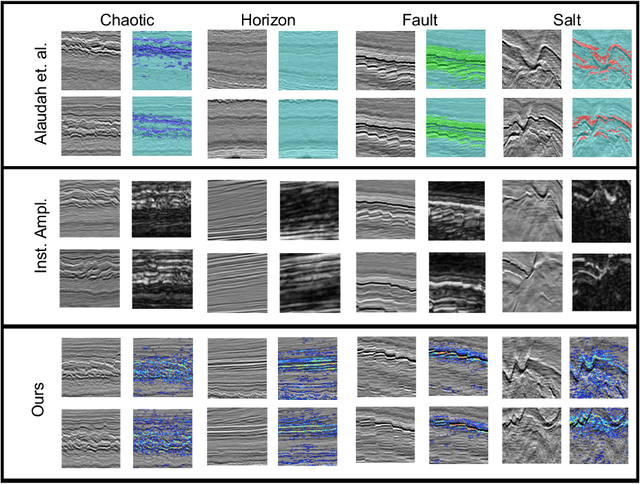
Annotating seismic data is expensive, laborious and subjective due to the number of years required for seismic interpreters to attain proficiency in interpretation. In this paper, we develop a framework to automate annotating pixels of a seismic image to delineate geological structural elements given image-level labels assigned to each image. Our framework factorizes the latent space of a deep encoder-decoder network by projecting the latent space to learned sub-spaces. Using constraints in the pixel space, the seismic image is further factorized to reveal confidence values on pixels associated with the geological element of interest. Details of the annotated image are provided for analysis and qualitative comparison is made with similar frameworks.
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
Mar 24, 2021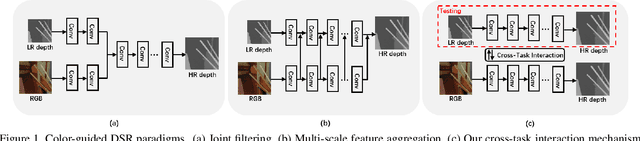
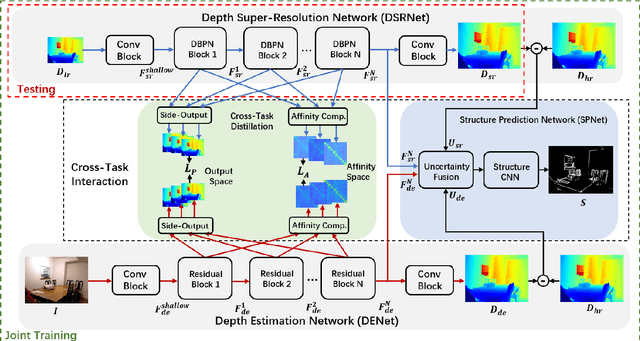
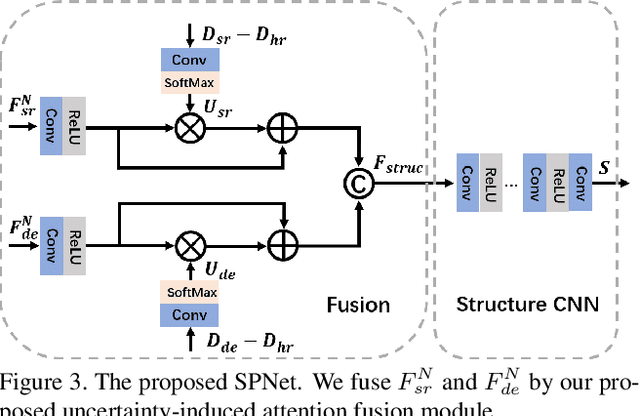

Existing color-guided depth super-resolution (DSR) approaches require paired RGB-D data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, we explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Our key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, we construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross task knowledge transfer. First, we design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, we advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that our scheme achieves superior performance in comparison with other DSR methods.
GPS-Denied Navigation Using SAR Images and Neural Networks
Oct 22, 2020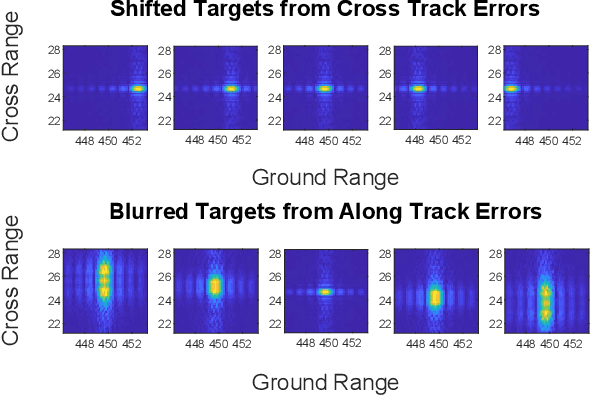
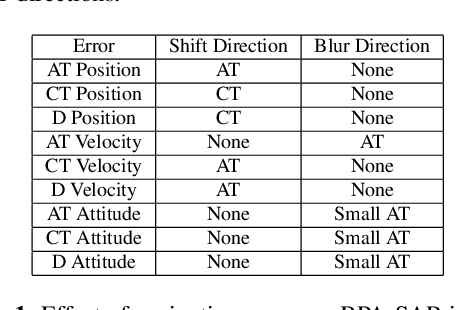
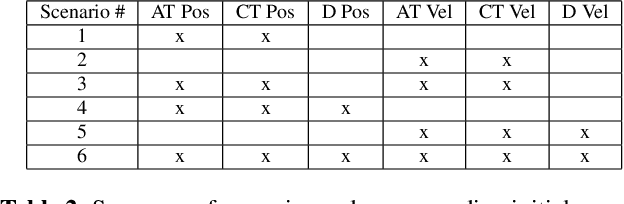
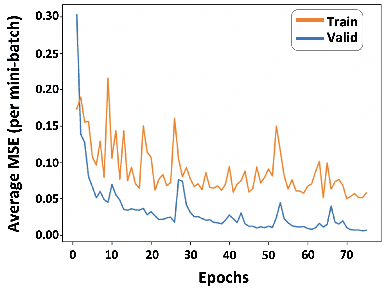
Unmanned aerial vehicles (UAV) often rely on GPS for navigation. GPS signals, however, are very low in power and easily jammed or otherwise disrupted. This paper presents a method for determining the navigation errors present at the beginning of a GPS-denied period utilizing data from a synthetic aperture radar (SAR) system. This is accomplished by comparing an online-generated SAR image with a reference image obtained a priori. The distortions relative to the reference image are learned and exploited with a convolutional neural network to recover the initial navigational errors, which can be used to recover the true flight trajectory throughout the synthetic aperture. The proposed neural network approach is able to learn to predict the initial errors on both simulated and real SAR image data.
Detecting floodwater on roadways from image data with handcrafted features and deep transfer learning
Aug 31, 2019
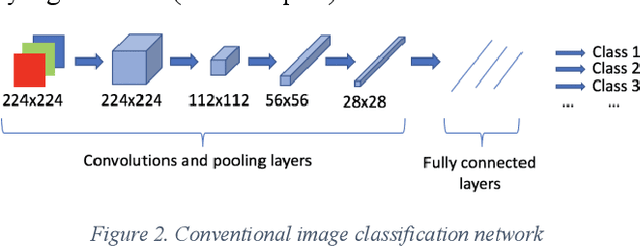
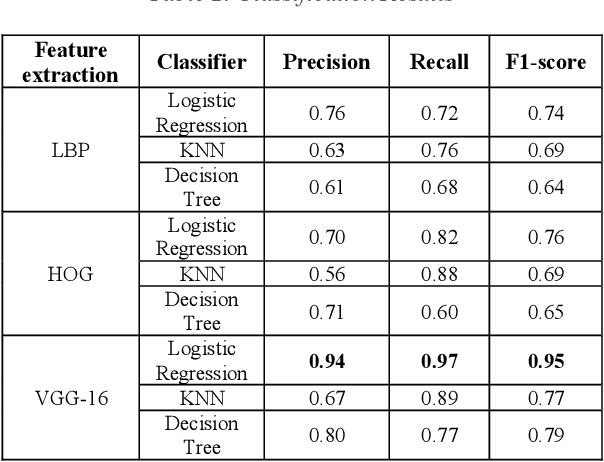
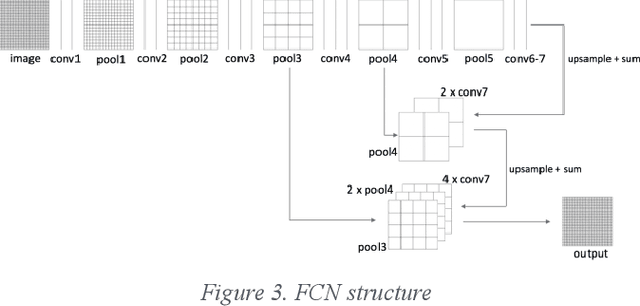
Detecting roadway segments inundated due to floodwater has important applications for vehicle routing and traffic management decisions. This paper proposes a set of algorithms to automatically detect floodwater that may be present in an image captured by mobile phones or other types of optical cameras. For this purpose, image classification and flood area segmentation methods are developed. For the classification task, we used Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG) and pre-trained deep neural network (VGG-16) as feature extractors and trained logistic regression, k-nearest neighbors, and decision tree classifiers on the extracted features. Pre-trained VGG-16 network with logistic regression classifier outperformed all other methods. For the flood area segmentation task, we investigated superpixel based methods and Fully Convolutional Neural Network (FCN). Similar to the classification task, we trained logistic regression and k-nearest neighbors classifiers on the superpixel areas and compared that with an end-to-end trained FCN. Conditional Random Fields (CRF) method was applied after both segmentation methods to post-process coarse segmentation results. FCN offered the highest scores in all metrics; it was followed by superpixel-based logistic regression and then superpixel-based KNN.
Predictive coding feedback results in perceived illusory contours in a recurrent neural network
Feb 03, 2021
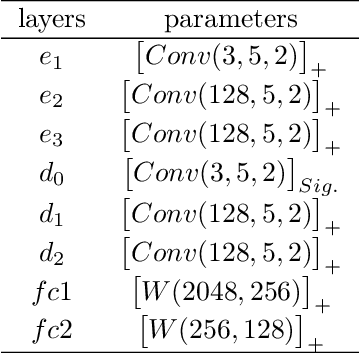
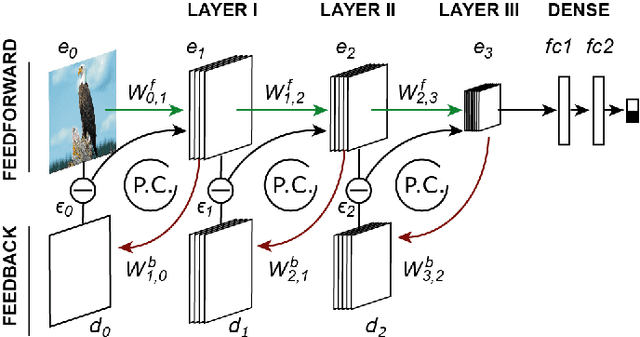
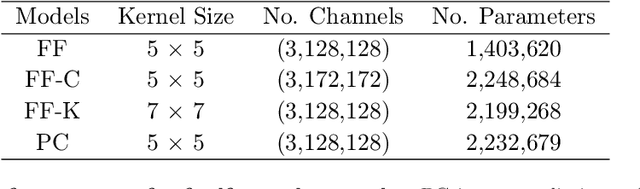
Modern feedforward convolutional neural networks (CNNs) can now solve some computer vision tasks at super-human levels. However, these networks only roughly mimic human visual perception. One difference from human vision is that they do not appear to perceive illusory contours (e.g. Kanizsa squares) in the same way humans do. Physiological evidence from visual cortex suggests that the perception of illusory contours could involve feedback connections. Would recurrent feedback neural networks perceive illusory contours like humans? In this work we equip a deep feedforward convolutional network with brain-inspired recurrent dynamics. The network was first pretrained with an unsupervised reconstruction objective on a natural image dataset, to expose it to natural object contour statistics. Then, a classification decision layer was added and the model was finetuned on a form discrimination task: squares vs. randomly oriented inducer shapes (no illusory contour). Finally, the model was tested with the unfamiliar "illusory contour" configuration: inducer shapes oriented to form an illusory square. Compared with feedforward baselines, the iterative "predictive coding" feedback resulted in more illusory contours being classified as physical squares. The perception of the illusory contour was measurable in the luminance profile of the image reconstructions produced by the model, demonstrating that the model really "sees" the illusion. Ablation studies revealed that natural image pretraining and feedback error correction are both critical to the perception of the illusion. Finally we validated our conclusions in a deeper network (VGG): adding the same predictive coding feedback dynamics again leads to the perception of illusory contours.
Priority prediction of Asian Hornet sighting report using machine learning methods
Jun 28, 2021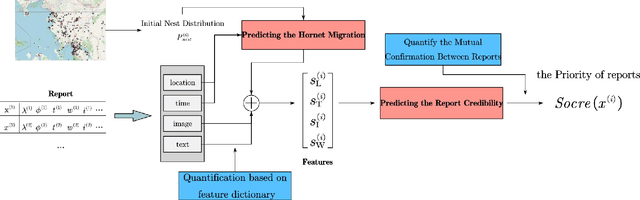
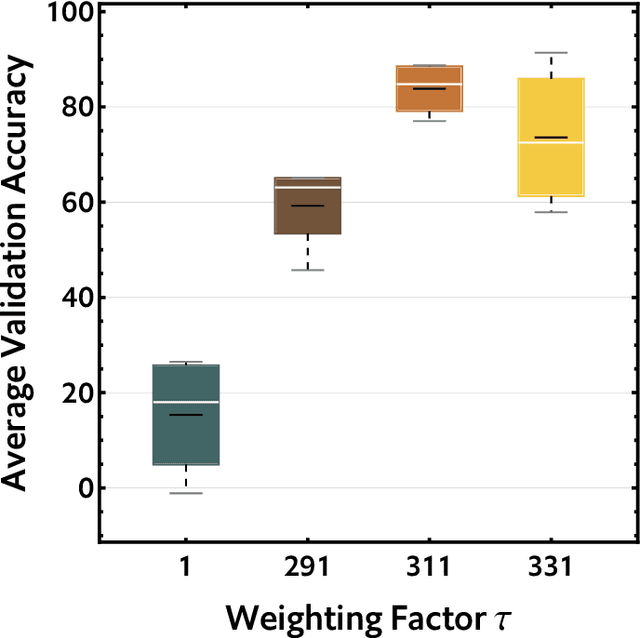
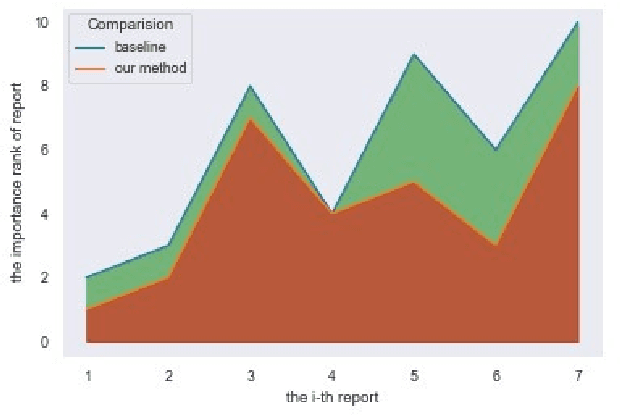
As infamous invaders to the North American ecosystem, the Asian giant hornet (Vespa mandarinia) is devastating not only to native bee colonies, but also to local apiculture. One of the most effective way to combat the harmful species is to locate and destroy their nests. By mobilizing the public to actively report possible sightings of the Asian giant hornet, the governmentcould timely send inspectors to confirm and possibly destroy the nests. However, such confirmation requires lab expertise, where manually checking the reports one by one is extremely consuming of human resources. Further given the limited knowledge of the public about the Asian giant hornet and the randomness of report submission, only few of the numerous reports proved positive, i.e. existing nests. How to classify or prioritize the reports efficiently and automatically, so as to determine the dispatch of personnel, is of great significance to the control of the Asian giant hornet. In this paper, we propose a method to predict the priority of sighting reports based on machine learning. We model the problem of optimal prioritization of sighting reports as a problem of classification and prediction. We extracted a variety of rich features in the report: location, time, image(s), and textual description. Based on these characteristics, we propose a classification model based on logistic regression to predict the credibility of a certain report. Furthermore, our model quantifies the impact between reports to get the priority ranking of the reports. Extensive experiments on the public dataset from the WSDA (the Washington State Department of Agriculture) have proved the effectiveness of our method.
Tight-Integration of Feature-Based Relocalization in Monocular Direct Visual Odometry
Feb 01, 2021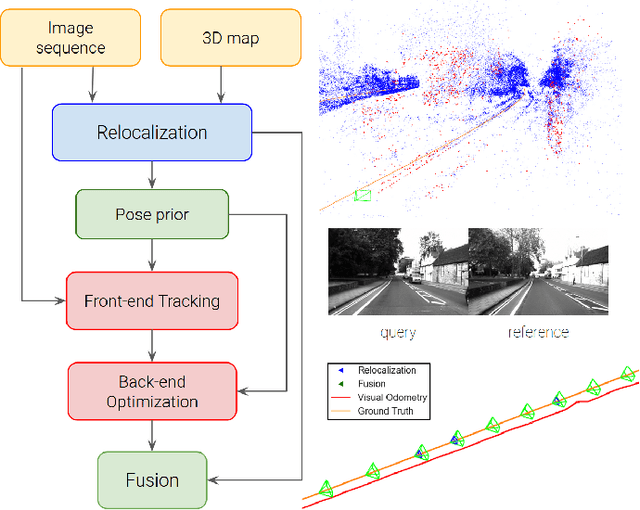
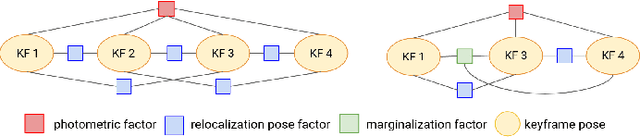
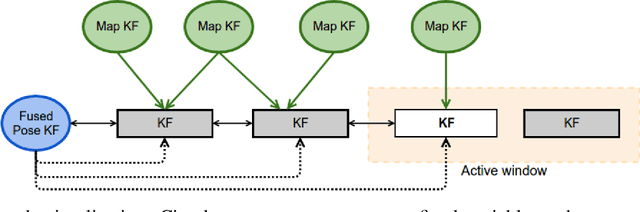
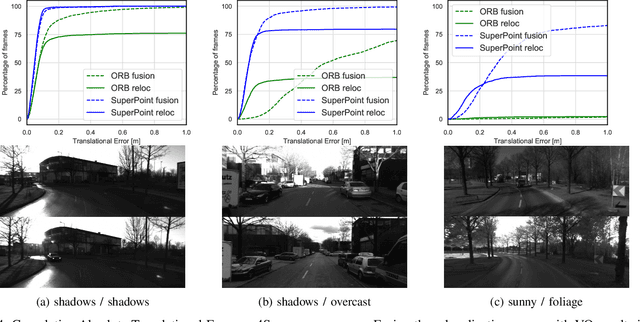
In this paper we propose a framework for integrating map-based relocalization into online direct visual odometry. To achieve map-based relocalization for direct methods, we integrate image features into Direct Sparse Odometry (DSO) and rely on feature matching to associate online visual odometry (VO) with a previously built map. The integration of the relocalization poses is threefold. Firstly, they are treated as pose priors and tightly integrated into the direct image alignment of the front-end tracking. Secondly, they are also tightly integrated into the back-end bundle adjustment. An online fusion module is further proposed to combine relative VO poses and global relocalization poses in a pose graph to estimate keyframe-wise smooth and globally accurate poses. We evaluate our method on two multi-weather datasets showing the benefits of integrating different handcrafted and learned features and demonstrating promising improvements on camera tracking accuracy.