 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A machine learning pipeline for aiding school identification from child trafficking images
Jun 09, 2021

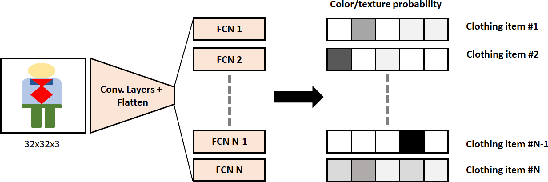
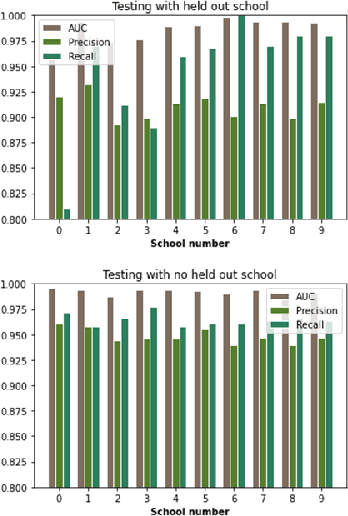
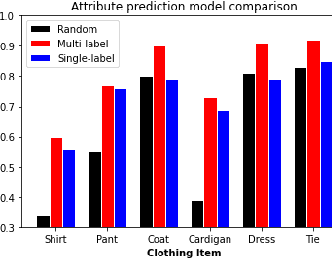
Child trafficking in a serious problem around the world. Every year there are more than 4 million victims of child trafficking around the world, many of them for the purposes of child sexual exploitation. In collaboration with UK Police and a non-profit focused on child abuse prevention, Global Emancipation Network, we developed a proof-of-concept machine learning pipeline to aid the identification of children from intercepted images. In this work, we focus on images that contain children wearing school uniforms to identify the school of origin. In the absence of a machine learning pipeline, this hugely time consuming and labor intensive task is manually conducted by law enforcement personnel. Thus, by automating aspects of the school identification process, we hope to significantly impact the speed of this portion of child identification. Our proposed pipeline consists of two machine learning models: i) to identify whether an image of a child contains a school uniform in it, and ii) identification of attributes of different school uniform items (such as color/texture of shirts, sweaters, blazers etc.). We describe the data collection, labeling, model development and validation process, along with strategies for efficient searching of schools using the model predictions.
Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
Sep 24, 2018
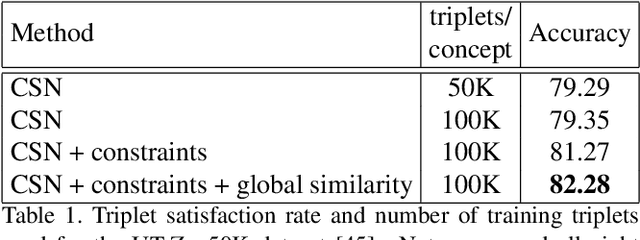
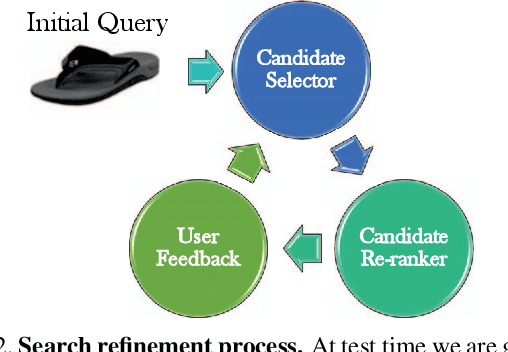
In this paper, we introduce an attribute-based interactive image search which can leverage human-in-the-loop feedback to iteratively refine image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used by prior work which are not typically found in many datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to learn what images are informative rather than rely on hand-crafted measures typically leveraged in prior work. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in more natural transitions as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach, producing compelling results on both active image search and image attribute representation tasks.
Deep Online Fused Video Stabilization
Feb 02, 2021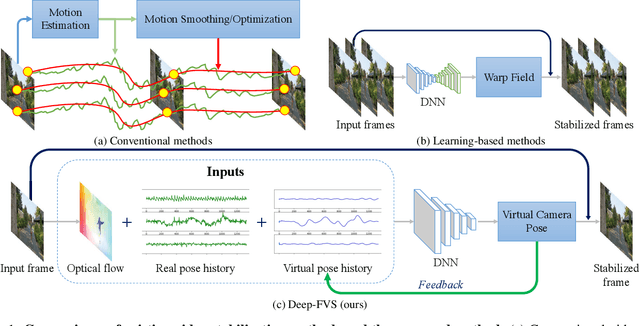
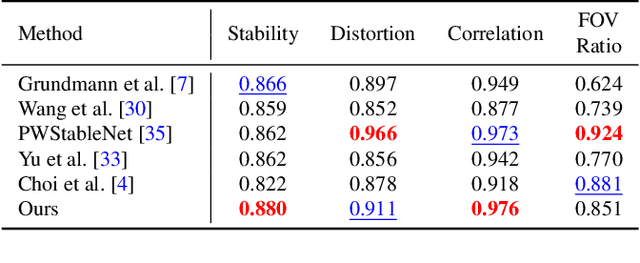
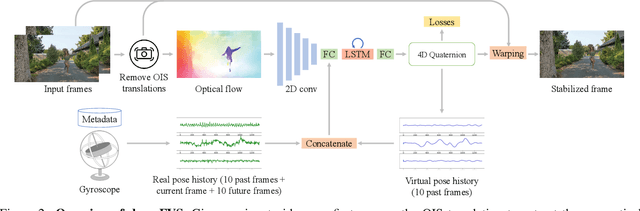
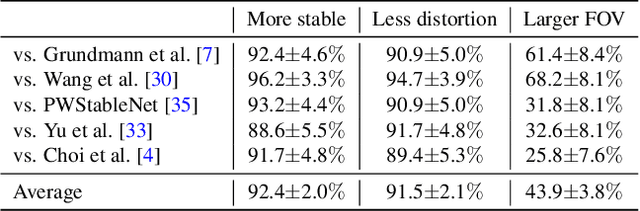
We present a deep neural network (DNN) that uses both sensor data (gyroscope) and image content (optical flow) to stabilize videos through unsupervised learning. The network fuses optical flow with real/virtual camera pose histories into a joint motion representation. Next, the LSTM block infers the new virtual camera pose, and this virtual pose is used to generate a warping grid that stabilizes the frame. Novel relative motion representation as well as a multi-stage training process are presented to optimize our model without any supervision. To the best of our knowledge, this is the first DNN solution that adopts both sensor data and image for stabilization. We validate the proposed framework through ablation studies and demonstrated the proposed method outperforms the state-of-art alternative solutions via quantitative evaluations and a user study.
NLP-CUET@DravidianLangTech-EACL2021: Investigating Visual and Textual Features to Identify Trolls from Multimodal Social Media Memes
Feb 28, 2021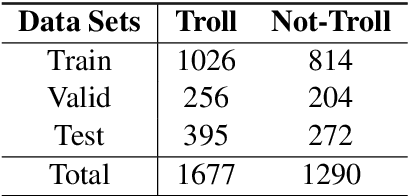
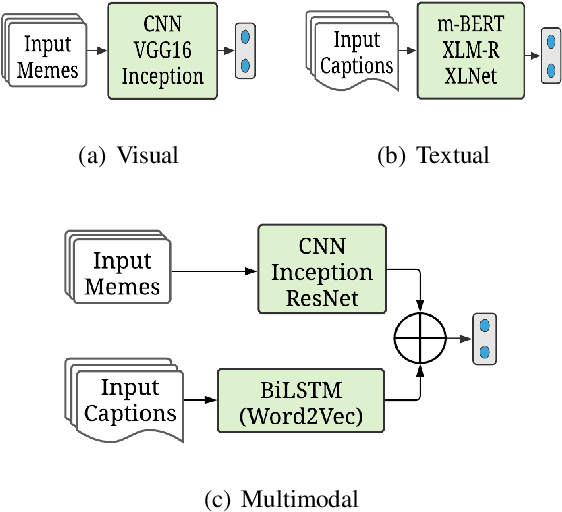
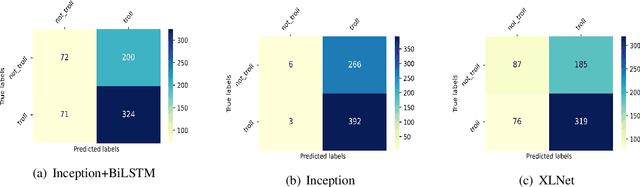
In the past few years, the meme has become a new way of communication on the Internet. As memes are the images with embedded text, it can quickly spread hate, offence and violence. Classifying memes are very challenging because of their multimodal nature and region-specific interpretation. A shared task is organized to develop models that can identify trolls from multimodal social media memes. This work presents a computational model that we have developed as part of our participation in the task. Training data comes in two forms: an image with embedded Tamil code-mixed text and an associated caption given in English. We investigated the visual and textual features using CNN, VGG16, Inception, Multilingual-BERT, XLM-Roberta, XLNet models. Multimodal features are extracted by combining image (CNN, ResNet50, Inception) and text (Long short term memory network) features via early fusion approach. Results indicate that the textual approach with XLNet achieved the highest weighted $f_1$-score of $0.58$, which enabled our model to secure $3^{rd}$ rank in this task.
SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images
Jun 17, 2021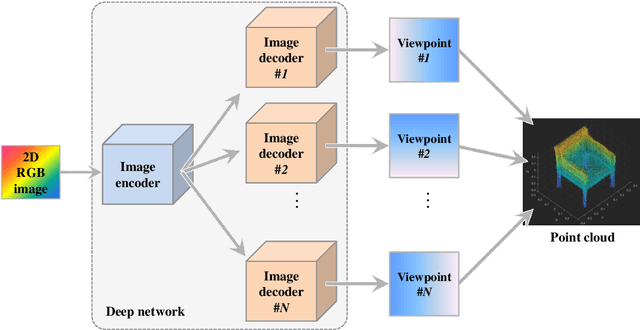



3D model generation from single 2D RGB images is a challenging and actively researched computer vision task. Various techniques using conventional network architectures have been proposed for the same. However, the body of research work is limited and there are various issues like using inefficient 3D representation formats, weak 3D model generation backbones, inability to generate dense point clouds, dependence of post-processing for generation of dense point clouds, and dependence on silhouettes in RGB images. In this paper, a novel 2D RGB image to point cloud conversion technique is proposed, which improves the state of art in the field due to its efficient, robust and simple model by using the concept of parallelization in network architecture. It not only uses the efficient and rich 3D representation of point clouds, but also uses a novel and robust point cloud generation backbone in order to address the prevalent issues. This involves using a single-encoder multiple-decoder deep network architecture wherein each decoder generates certain fixed viewpoints. This is followed by fusing all the viewpoints to generate a dense point cloud. Various experiments are conducted on the technique and its performance is compared with those of other state of the art techniques and impressive gains in performance are demonstrated. Code is available at https://github.com/mueedhafiz1982/
Cluster-to-Conquer: A Framework for End-to-End Multi-Instance Learning for Whole Slide Image Classification
Mar 19, 2021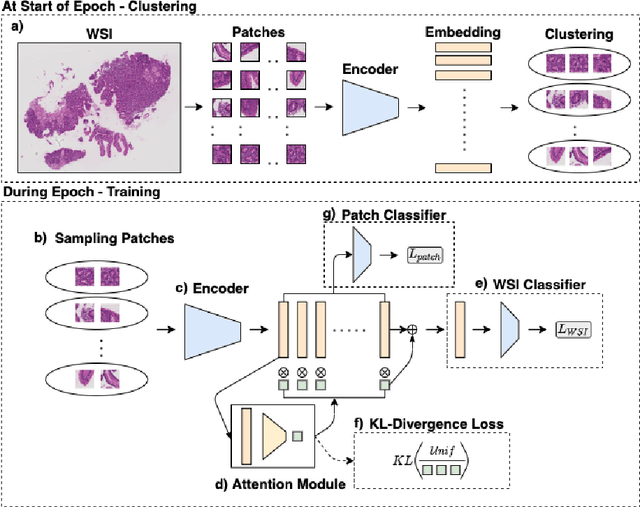
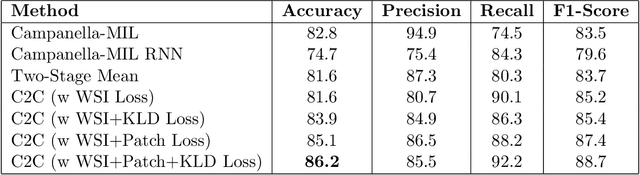
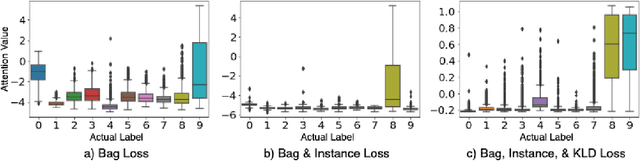

In recent years, the availability of digitized Whole Slide Images (WSIs) has enabled the use of deep learning-based computer vision techniques for automated disease diagnosis. However, WSIs present unique computational and algorithmic challenges. WSIs are gigapixel-sized ($\sim$100K pixels), making them infeasible to be used directly for training deep neural networks. Also, often only slide-level labels are available for training as detailed annotations are tedious and can be time-consuming for experts. Approaches using multiple-instance learning (MIL) frameworks have been shown to overcome these challenges. Current state-of-the-art approaches divide the learning framework into two decoupled parts: a convolutional neural network (CNN) for encoding the patches followed by an independent aggregation approach for slide-level prediction. In this approach, the aggregation step has no bearing on the representations learned by the CNN encoder. We have proposed an end-to-end framework that clusters the patches from a WSI into ${k}$-groups, samples ${k}'$ patches from each group for training, and uses an adaptive attention mechanism for slide level prediction; Cluster-to-Conquer (C2C). We have demonstrated that dividing a WSI into clusters can improve the model training by exposing it to diverse discriminative features extracted from the patches. We regularized the clustering mechanism by introducing a KL-divergence loss between the attention weights of patches in a cluster and the uniform distribution. The framework is optimized end-to-end on slide-level cross-entropy, patch-level cross-entropy, and KL-divergence loss (Implementation: https://github.com/YashSharma/C2C).
ShuffleBlock: Shuffle to Regularize Deep Convolutional Neural Networks
Jun 17, 2021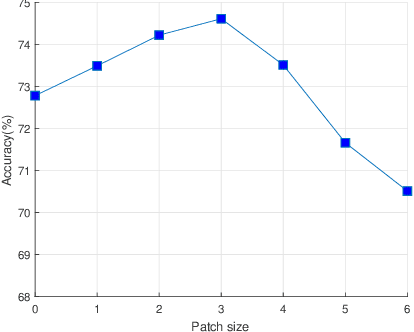
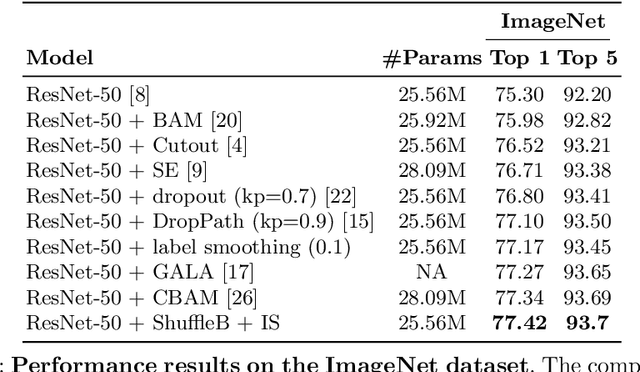
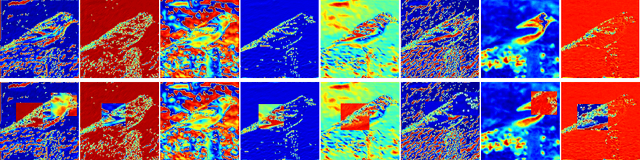
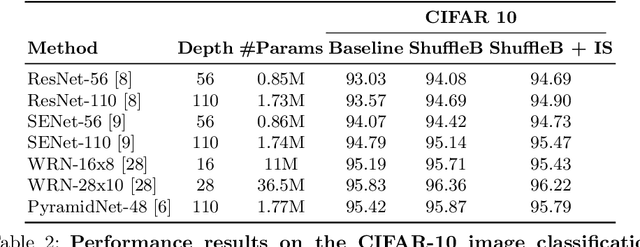
Deep neural networks have enormous representational power which leads them to overfit on most datasets. Thus, regularizing them is important in order to reduce overfitting and enhance their generalization capabilities. Recently, channel shuffle operation has been introduced for mixing channels in group convolutions in resource efficient networks in order to reduce memory and computations. This paper studies the operation of channel shuffle as a regularization technique in deep convolutional networks. We show that while random shuffling of channels during training drastically reduce their performance, however, randomly shuffling small patches between channels significantly improves their performance. The patches to be shuffled are picked from the same spatial locations in the feature maps such that a patch, when transferred from one channel to another, acts as structured noise for the later channel. We call this method "ShuffleBlock". The proposed ShuffleBlock module is easy to implement and improves the performance of several baseline networks on the task of image classification on CIFAR and ImageNet datasets. It also achieves comparable and in many cases better performance than many other regularization methods. We provide several ablation studies on selecting various hyperparameters of the ShuffleBlock module and propose a new scheduling method that further enhances its performance.
Rethinking Pseudo Labels for Semi-Supervised Object Detection
Jun 01, 2021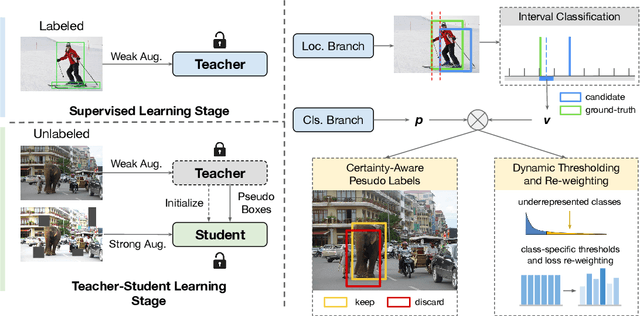
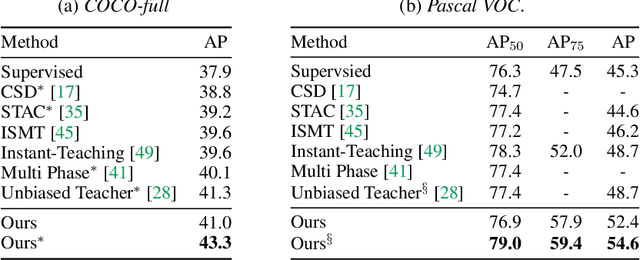
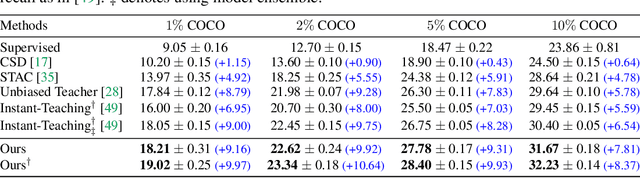
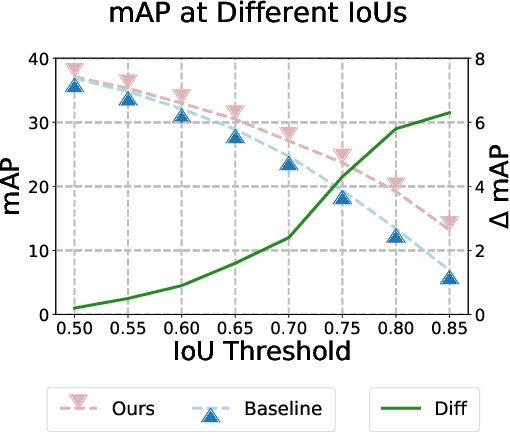
Recent advances in semi-supervised object detection (SSOD) are largely driven by consistency-based pseudo-labeling methods for image classification tasks, producing pseudo labels as supervisory signals. However, when using pseudo labels, there is a lack of consideration in localization precision and amplified class imbalance, both of which are critical for detection tasks. In this paper, we introduce certainty-aware pseudo labels tailored for object detection, which can effectively estimate the classification and localization quality of derived pseudo labels. This is achieved by converting conventional localization as a classification task followed by refinement. Conditioned on classification and localization quality scores, we dynamically adjust the thresholds used to generate pseudo labels and reweight loss functions for each category to alleviate the class imbalance problem. Extensive experiments demonstrate that our method improves state-of-the-art SSOD performance by 1-2% and 4-6% AP on COCO and PASCAL VOC, respectively. In the limited-annotation regime, our approach improves supervised baselines by up to 10% AP using only 1-10% labeled data from COCO.
Unknown-box Approximation to Improve Optical Character Recognition Performance
May 17, 2021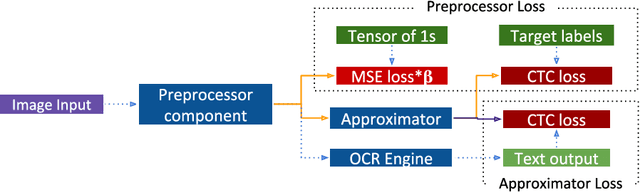
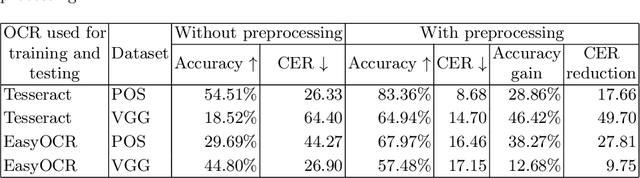
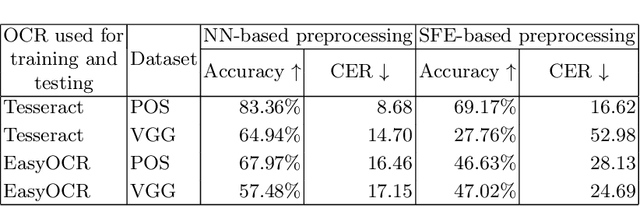

Optical character recognition (OCR) is a widely used pattern recognition application in numerous domains. There are several feature-rich, general-purpose OCR solutions available for consumers, which can provide moderate to excellent accuracy levels. However, accuracy can diminish with difficult and uncommon document domains. Preprocessing of document images can be used to minimize the effect of domain shift. In this paper, a novel approach is presented for creating a customized preprocessor for a given OCR engine. Unlike the previous OCR agnostic preprocessing techniques, the proposed approach approximates the gradient of a particular OCR engine to train a preprocessor module. Experiments with two datasets and two OCR engines show that the presented preprocessor is able to improve the accuracy of the OCR up to 46% from the baseline by applying pixel-level manipulations to the document image. The implementation of the proposed method and the enhanced public datasets are available for download.
Unsupervised Learning of Depth and Depth-of-Field Effect from Natural Images with Aperture Rendering Generative Adversarial Networks
Jun 24, 2021
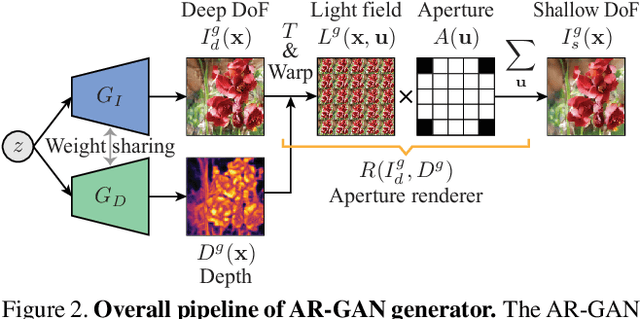
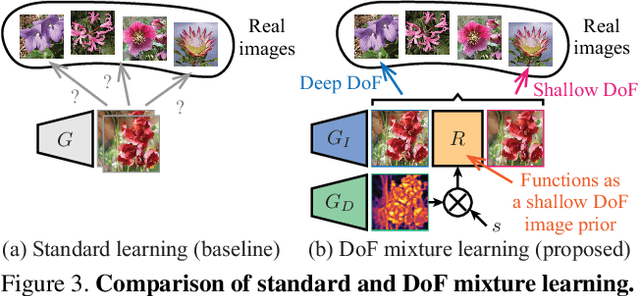
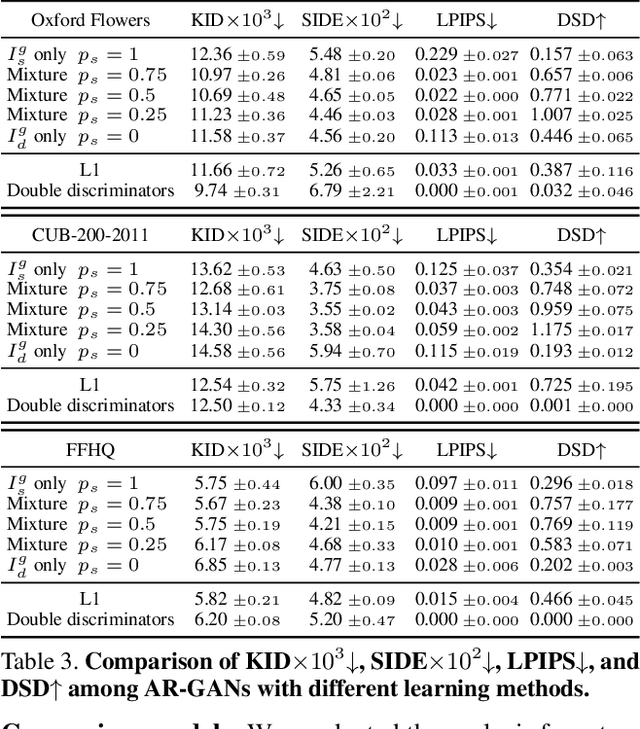
Understanding the 3D world from 2D projected natural images is a fundamental challenge in computer vision and graphics. Recently, an unsupervised learning approach has garnered considerable attention owing to its advantages in data collection. However, to mitigate training limitations, typical methods need to impose assumptions for viewpoint distribution (e.g., a dataset containing various viewpoint images) or object shape (e.g., symmetric objects). These assumptions often restrict applications; for instance, the application to non-rigid objects or images captured from similar viewpoints (e.g., flower or bird images) remains a challenge. To complement these approaches, we propose aperture rendering generative adversarial networks (AR-GANs), which equip aperture rendering on top of GANs, and adopt focus cues to learn the depth and depth-of-field (DoF) effect of unlabeled natural images. To address the ambiguities triggered by unsupervised setting (i.e., ambiguities between smooth texture and out-of-focus blurs, and between foreground and background blurs), we develop DoF mixture learning, which enables the generator to learn real image distribution while generating diverse DoF images. In addition, we devise a center focus prior to guiding the learning direction. In the experiments, we demonstrate the effectiveness of AR-GANs in various datasets, such as flower, bird, and face images, demonstrate their portability by incorporating them into other 3D representation learning GANs, and validate their applicability in shallow DoF rendering.