 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VINS: Visual Search for Mobile User Interface Design
Feb 10, 2021
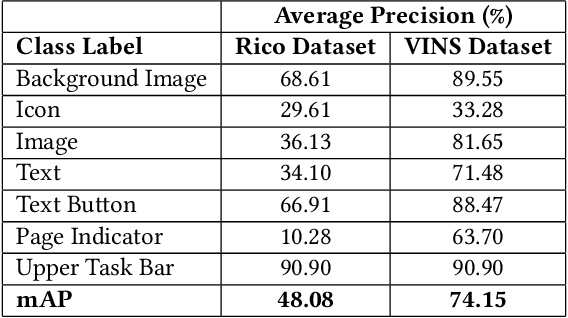
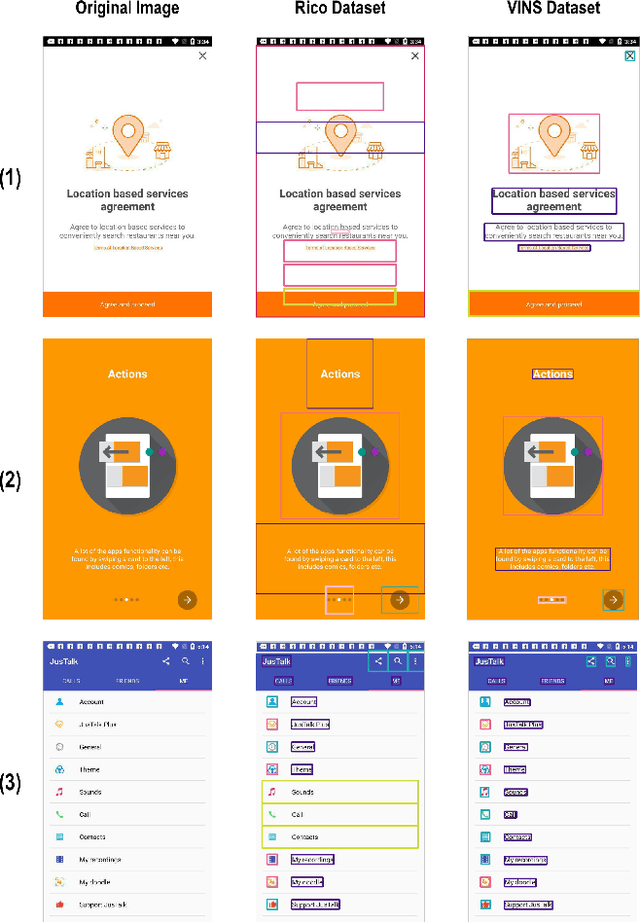
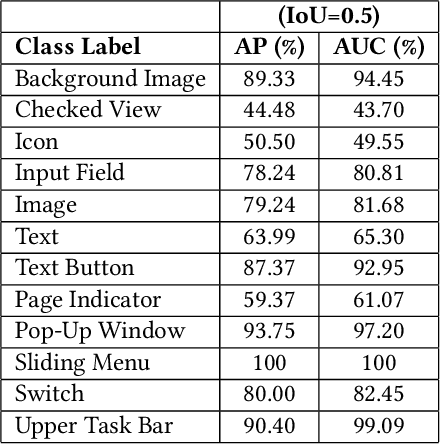
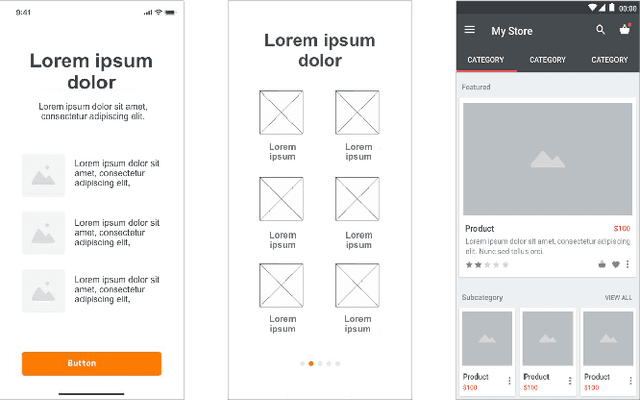
Searching for relative mobile user interface (UI) design examples can aid interface designers in gaining inspiration and comparing design alternatives. However, finding such design examples is challenging, especially as current search systems rely on only text-based queries and do not consider the UI structure and content into account. This paper introduces VINS, a visual search framework, that takes as input a UI image (wireframe, high-fidelity) and retrieves visually similar design examples. We first survey interface designers to better understand their example finding process. We then develop a large-scale UI dataset that provides an accurate specification of the interface's view hierarchy (i.e., all the UI components and their specific location). By utilizing this dataset, we propose an object-detection based image retrieval framework that models the UI context and hierarchical structure. The framework achieves a mean Average Precision of 76.39\% for the UI detection and high performance in querying similar UI designs.
3D human tongue reconstruction from single "in-the-wild" images
Jun 23, 2021

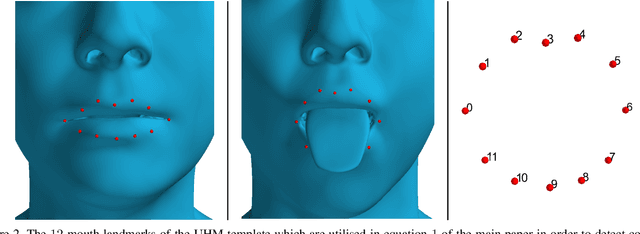

3D face reconstruction from a single image is a task that has garnered increased interest in the Computer Vision community, especially due to its broad use in a number of applications such as realistic 3D avatar creation, pose invariant face recognition and face hallucination. Since the introduction of the 3D Morphable Model in the late 90's, we witnessed an explosion of research aiming at particularly tackling this task. Nevertheless, despite the increasing level of detail in the 3D face reconstructions from single images mainly attributed to deep learning advances, finer and highly deformable components of the face such as the tongue are still absent from all 3D face models in the literature, although being very important for the realness of the 3D avatar representations. In this work we present the first, to the best of our knowledge, end-to-end trainable pipeline that accurately reconstructs the 3D face together with the tongue. Moreover, we make this pipeline robust in "in-the-wild" images by introducing a novel GAN method tailored for 3D tongue surface generation. Finally, we make publicly available to the community the first diverse tongue dataset, consisting of 1,800 raw scans of 700 individuals varying in gender, age, and ethnicity backgrounds. As we demonstrate in an extensive series of quantitative as well as qualitative experiments, our model proves to be robust and realistically captures the 3D tongue structure, even in adverse "in-the-wild" conditions.
Automatic Main Character Recognition for Photographic Studies
Jun 16, 2021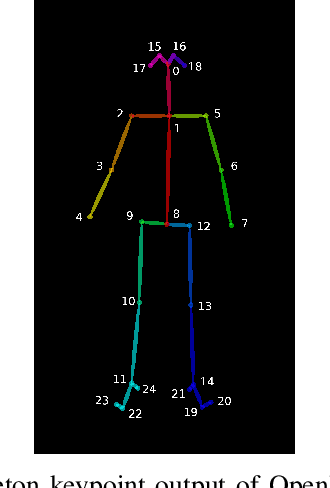


Main characters in images are the most important humans that catch the viewer's attention upon first look, and they are emphasized by properties such as size, position, color saturation, and sharpness of focus. Identifying the main character in images plays an important role in traditional photographic studies and media analysis, but the task is performed manually and can be slow and laborious. Furthermore, selection of main characters can be sometimes subjective. In this paper, we analyze the feasibility of solving the main character recognition needed for photographic studies automatically and propose a method for identifying the main characters. The proposed method uses machine learning based human pose estimation along with traditional computer vision approaches for this task. We approach the task as a binary classification problem where each detected human is classified either as a main character or not. To evaluate both the subjectivity of the task and the performance of our method, we collected a dataset of 300 varying images from multiple sources and asked five people, a photographic researcher and four other persons, to annotate the main characters. Our analysis showed a relatively high agreement between different annotators. The proposed method achieved a promising F1 score of 0.83 on the full image set and 0.96 on a subset evaluated as most clear and important cases by the photographic researcher.
Deep learning based geometric registration for medical images: How accurate can we get without visual features?
Mar 01, 2021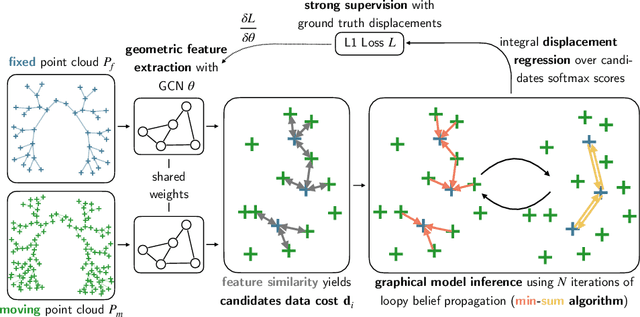
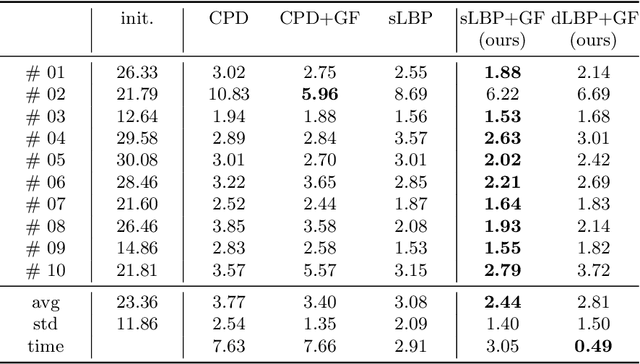
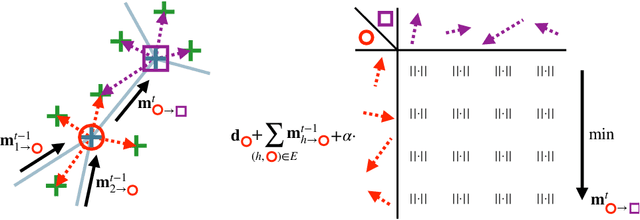
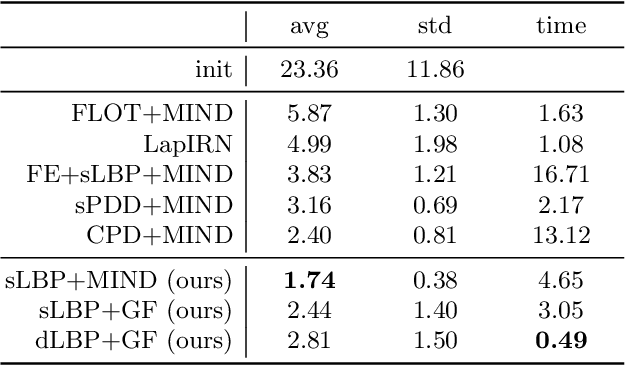
As in other areas of medical image analysis, e.g. semantic segmentation, deep learning is currently driving the development of new approaches for image registration. Multi-scale encoder-decoder network architectures achieve state-of-the-art accuracy on tasks such as intra-patient alignment of abdominal CT or brain MRI registration, especially when additional supervision, such as anatomical labels, is available. The success of these methods relies to a large extent on the outstanding ability of deep CNNs to extract descriptive visual features from the input images. In contrast to conventional methods, the explicit inclusion of geometric information plays only a minor role, if at all. In this work we take a look at an exactly opposite approach by investigating a deep learning framework for registration based solely on geometric features and optimisation. We combine graph convolutions with loopy belief message passing to enable highly accurate 3D point cloud registration. Our experimental validation is conducted on complex key-point graphs of inner lung structures, strongly outperforming dense encoder-decoder networks and other point set registration methods. Our code is publicly available at https://github.com/multimodallearning/deep-geo-reg.
More About Covariance Descriptors for Image Set Coding: Log-Euclidean Framework based Kernel Matrix Representation
Sep 16, 2019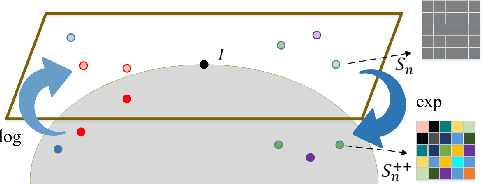
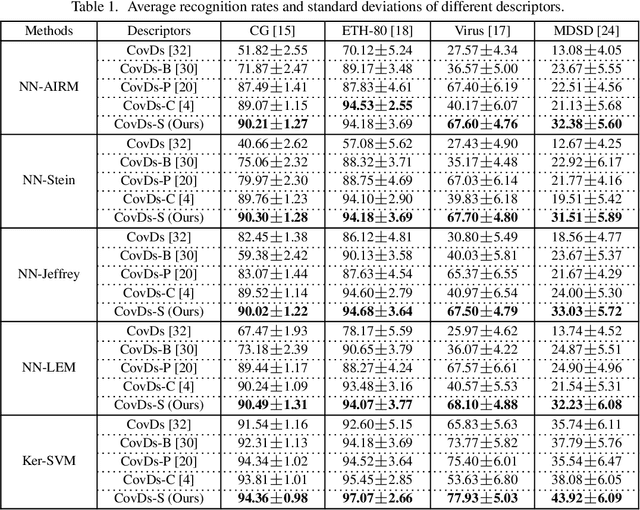
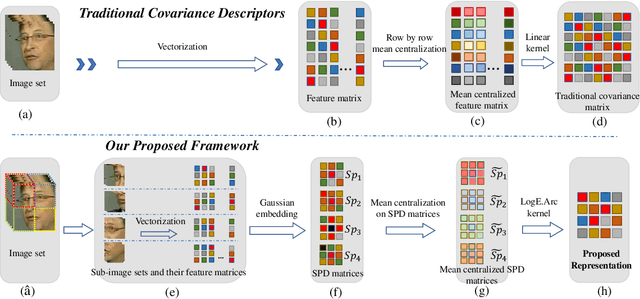
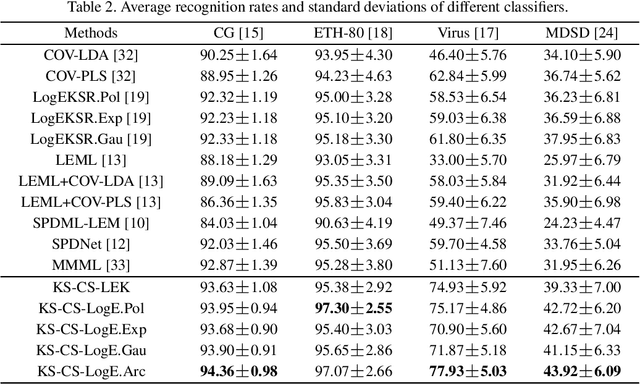
We consider a family of structural descriptors for visual data, namely covariance descriptors (CovDs) that lie on a non-linear symmetric positive definite (SPD) manifold, a special type of Riemannian manifolds. We propose an improved version of CovDs for image set coding by extending the traditional CovDs from Euclidean space to the SPD manifold. Specifically, the manifold of SPD matrices is a complete inner product space with the operations of logarithmic multiplication and scalar logarithmic multiplication defined in the Log-Euclidean framework. In this framework, we characterise covariance structure in terms of the arc-cosine kernel which satisfies Mercer's condition and propose the operation of mean centralization on SPD matrices. Furthermore, we combine arc-cosine kernels of different orders using mixing parameters learnt by kernel alignment in a supervised manner. Our proposed framework provides a lower-dimensional and more discriminative data representation for the task of image set classification. The experimental results demonstrate its superior performance, measured in terms of recognition accuracy, as compared with the state-of-the-art methods.
* 10 pages
Image Inpainting via Generative Multi-column Convolutional Neural Networks
Oct 20, 2018

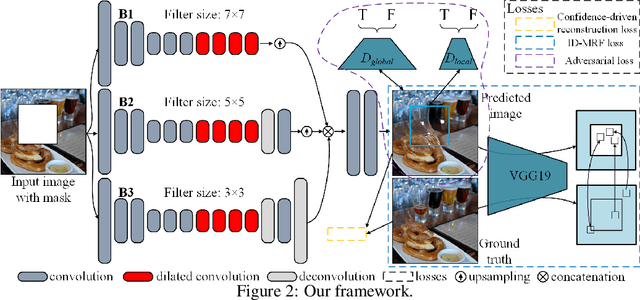

In this paper, we propose a generative multi-column network for image inpainting. This network synthesizes different image components in a parallel manner within one stage. To better characterize global structures, we design a confidence-driven reconstruction loss while an implicit diversified MRF regularization is adopted to enhance local details. The multi-column network combined with the reconstruction and MRF loss propagates local and global information derived from context to the target inpainting regions. Extensive experiments on challenging street view, face, natural objects and scenes manifest that our method produces visual compelling results even without previously common post-processing.
Deep Robust Single Image Depth Estimation Neural Network Using Scene Understanding
Jun 07, 2019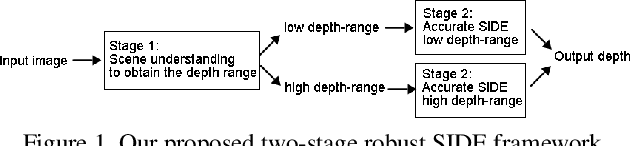
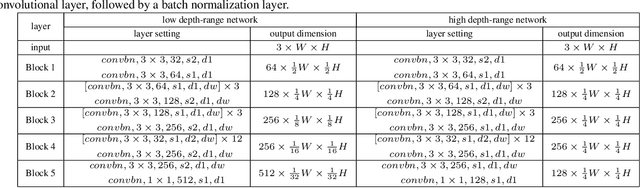
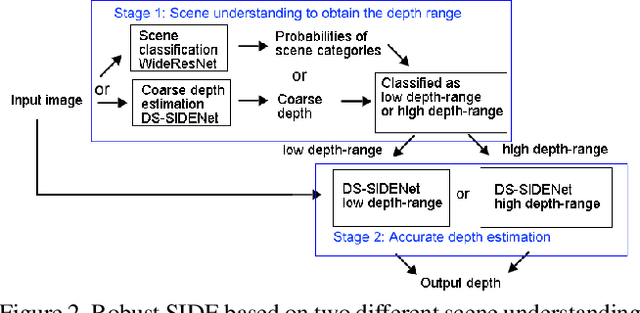
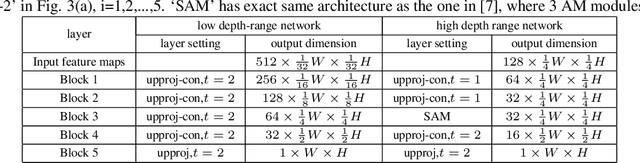
Single image depth estimation (SIDE) plays a crucial role in 3D computer vision. In this paper, we propose a two-stage robust SIDE framework that can perform blind SIDE for both indoor and outdoor scenes. At the first stage, the scene understanding module will categorize the RGB image into different depth-ranges. We introduce two different scene understanding modules based on scene classification and coarse depth estimation respectively. At the second stage, SIDE networks trained by the images of specific depth-range are applied to obtain an accurate depth map. In order to improve the accuracy, we further design a multi-task encoding-decoding SIDE network DS-SIDENet based on depthwise separable convolutions. DS-SIDENet is optimized to minimize both depth classification and depth regression losses. This improves the accuracy compared to a single-task SIDE network. Experimental results demonstrate that training DS-SIDENet on an individual dataset such as NYU achieves competitive performance to the state-of-art methods with much better efficiency. Ours proposed robust SIDE framework also shows good performance for the ScanNet indoor images and KITTI outdoor images simultaneously. It achieves the top performance compared to the Robust Vision Challenge (ROB) 2018 submissions.
Two-Stage Self-Supervised Cycle-Consistency Network for Reconstruction of Thin-Slice MR Images
Jun 29, 2021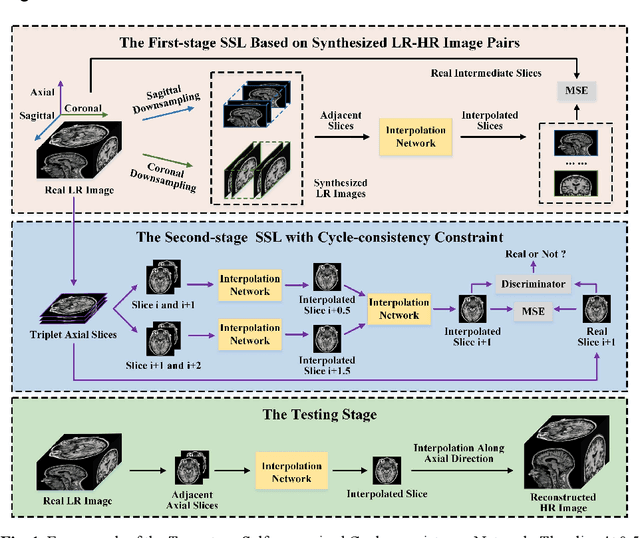
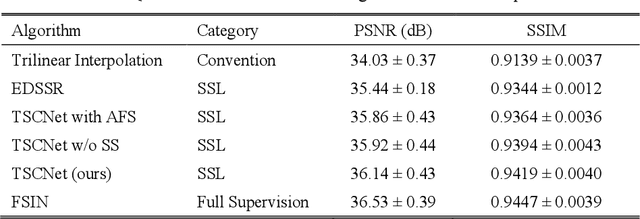
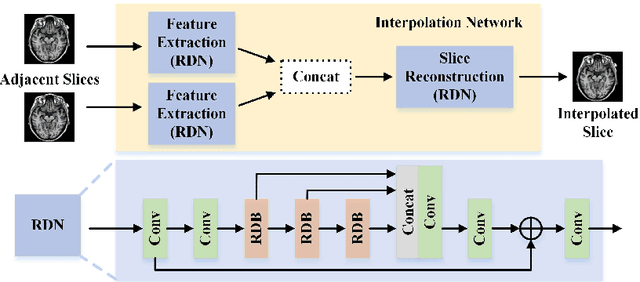
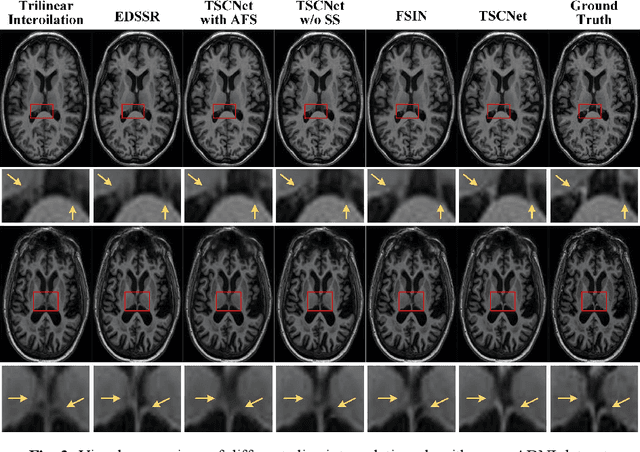
The thick-slice magnetic resonance (MR) images are often structurally blurred in coronal and sagittal views, which causes harm to diagnosis and image post-processing. Deep learning (DL) has shown great potential to re-construct the high-resolution (HR) thin-slice MR images from those low-resolution (LR) cases, which we refer to as the slice interpolation task in this work. However, since it is generally difficult to sample abundant paired LR-HR MR images, the classical fully supervised DL-based models cannot be effectively trained to get robust performance. To this end, we propose a novel Two-stage Self-supervised Cycle-consistency Network (TSCNet) for MR slice interpolation, in which a two-stage self-supervised learning (SSL) strategy is developed for unsupervised DL network training. The paired LR-HR images are synthesized along the sagittal and coronal directions of input LR images for network pretraining in the first-stage SSL, and then a cyclic in-terpolation procedure based on triplet axial slices is designed in the second-stage SSL for further refinement. More training samples with rich contexts along all directions are exploited as guidance to guarantee the improved in-terpolation performance. Moreover, a new cycle-consistency constraint is proposed to supervise this cyclic procedure, which encourages the network to reconstruct more realistic HR images. The experimental results on a real MRI dataset indicate that TSCNet achieves superior performance over the conventional and other SSL-based algorithms, and obtains competitive quali-tative and quantitative results compared with the fully supervised algorithm.
CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents
Apr 27, 2020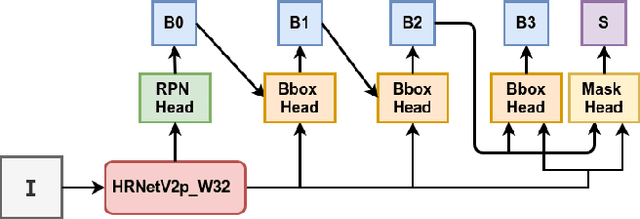
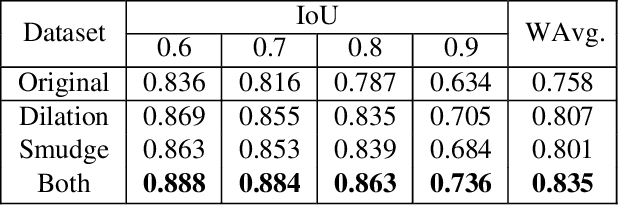
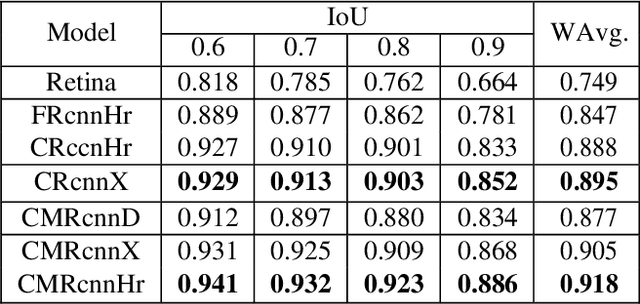
An automatic table recognition method for interpretation of tabular data in document images majorly involves solving two problems of table detection and table structure recognition. The prior work involved solving both problems independently using two separate approaches. More recent works signify the use of deep learning-based solutions while also attempting to design an end to end solution. In this paper, we present an improved deep learning-based end to end approach for solving both problems of table detection and structure recognition using a single Convolution Neural Network (CNN) model. We propose CascadeTabNet: a Cascade mask Region-based CNN High-Resolution Network (Cascade mask R-CNN HRNet) based model that detects the regions of tables and recognizes the structural body cells from the detected tables at the same time. We evaluate our results on ICDAR 2013, ICDAR 2019 and TableBank public datasets. We achieved 3rd rank in ICDAR 2019 post-competition results for table detection while attaining the best accuracy results for the ICDAR 2013 and TableBank dataset. We also attain the highest accuracy results on the ICDAR 2019 table structure recognition dataset. Additionally, we demonstrate effective transfer learning and image augmentation techniques that enable CNNs to achieve very accurate table detection results. Code and dataset has been made available at: https://github.com/DevashishPrasad/CascadeTabNet
A 3D model-based approach for fitting masks to faces in the wild
Mar 01, 2021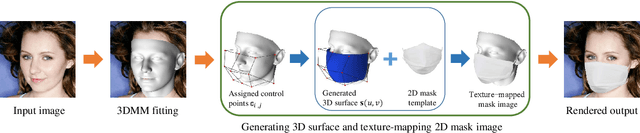
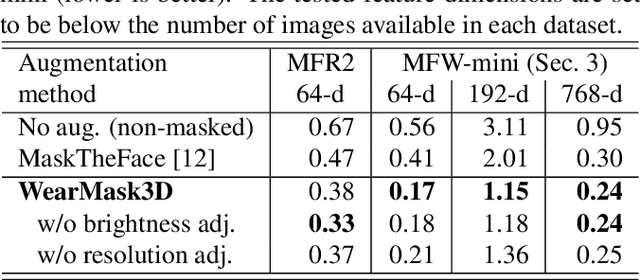

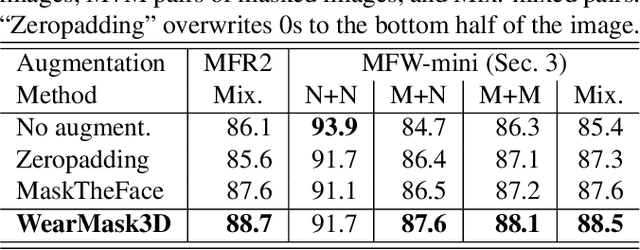
Face recognition research now requires a large number of labelled masked face images in the era of this unprecedented COVID-19 pandemic. Unfortunately, the rapid spread of the virus has left us little time to prepare for such dataset in the wild. To circumvent this issue, we present a 3D model-based approach called WearMask3D for augmenting face images of various poses to the masked face counterparts. Our method proceeds by first fitting a 3D morphable model on the input image, second overlaying the mask surface onto the face model and warping the respective mask texture, and last projecting the 3D mask back to 2D. The mask texture is adapted based on the brightness and resolution of the input image. By working in 3D, our method can produce more natural masked faces of diverse poses from a single mask texture. To compare precisely between different augmentation approaches, we have constructed a dataset comprising masked and unmasked faces with labels called MFW-mini. Experimental results demonstrate WearMask3D, which will be made publicly available, produces more realistic masked images, and utilizing these images for training leads to improved recognition accuracy of masked faces compared to the state-of-the-art.