 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cryo-Electron Microscopy Image Analysis Using Multi-Frequency Vector Diffusion Maps
Apr 16, 2019
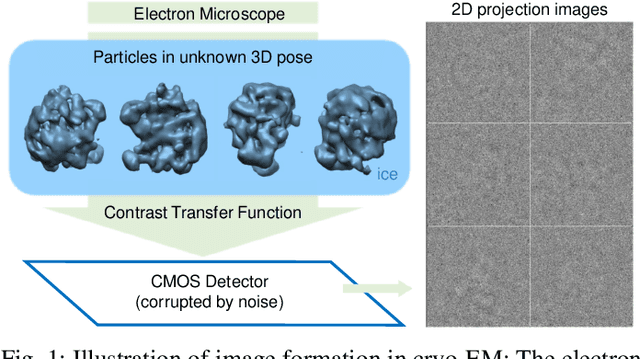
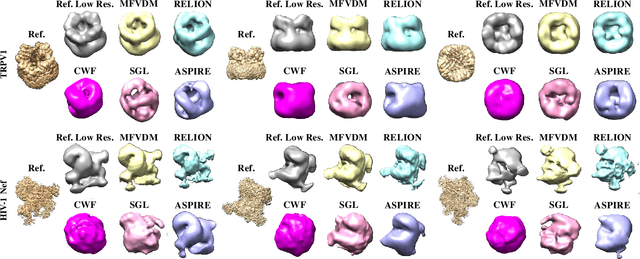
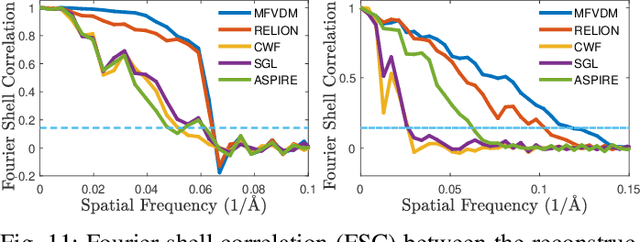

Cryo-electron microscopy (EM) single particle reconstruction is an entirely general technique for 3D structure determination of macromolecular complexes. However, because the images are taken at low electron dose, it is extremely hard to visualize the individual particle with low contrast and high noise level. In this paper, we propose a novel approach called multi-frequency vector diffusion maps (MFVDM) to improve the efficiency and accuracy of cryo-EM 2D image classification and denoising. This framework incorporates different irreducible representations of the estimated alignment between similar images. In addition, we propose a graph filtering scheme to denoise the images using the eigenvalues and eigenvectors of the MFVDM matrices. Through both simulated and publicly available real data, we demonstrate that our proposed method is efficient and robust to noise compared with the state-of-the-art cryo-EM 2D class averaging and image restoration algorithms.
A Pressure Ulcer Care System For Remote Medical Assistance: Residual U-Net with an Attention Model Based for Wound Area Segmentation
Jan 23, 2021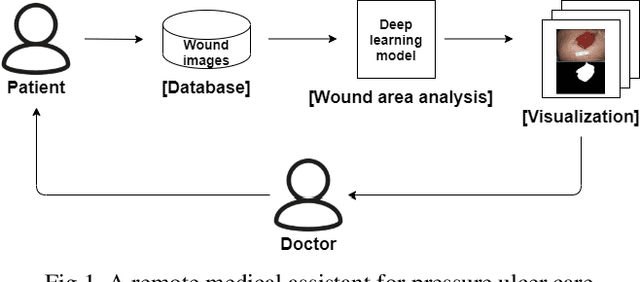

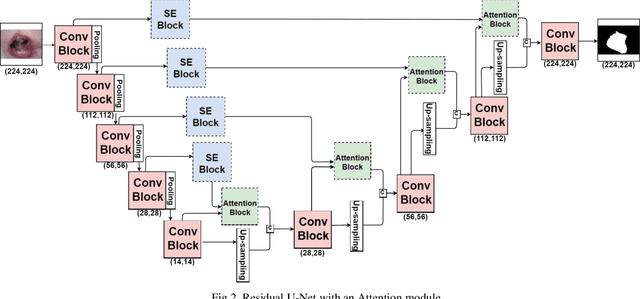

Increasing numbers of patients with disabilities or elderly people with mobility issues often suffer from a pressure ulcer. The affected areas need regular checks, but they have a difficulty in accessing a hospital. Some remote diagnosis systems are being used for them, but there are limitations in checking a patient's status regularly. In this paper, we present a remote medical assistant that can help pressure ulcer management with image processing techniques. The proposed system includes a mobile application with a deep learning model for wound segmentation and analysis. As there are not enough data to train the deep learning model, we make use of a pretrained model from a relevant domain and data augmentation that is appropriate for this task. First of all, an image preprocessing method using bilinear interpolation is used to resize images and normalize the images. Second, for data augmentation, we use rotation, reflection, and a watershed algorithm. Third, we use a pretrained deep learning model generated from skin wound images similar to pressure ulcer images. Finally, we added an attention module that can provide hints on the pressure ulcer image features. The resulting model provides an accuracy of 99.0%, an intersection over union (IoU) of 99.99%, and a dice similarity coefficient (DSC) of 93.4% for pressure ulcer segmentation, which is better than existing results.
Model-Centric Volumetric Point Cloud Attributes
Jun 29, 2021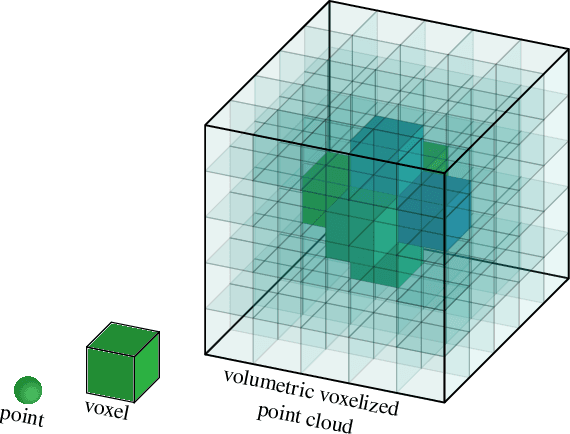


Point clouds have recently gained interest, especially for real-time applications and for 3D-scanned material, such as is used in autonomous driving, architecture, and engineering, to model real estate for renovation or display. Point clouds are associated with geometry information and attributes such as color. Be the color unique or direction-dependent (in the case of plenoptic point clouds), it reflects the colors observed by cameras displaced around the object. Hence, not only are the viewing references assumed, but the illumination spectrum and illumination geometry is also implicit. We propose a model-centric description of the 3D object, that is independent of the illumination and of the position of the cameras. We want to be able to describe the objects themselves such that, at a later stage, the rendering of the model may decide where to place illumination, from which it may calculate the image viewed by a given camera. We want to be able to describe transparent or translucid objects, mirrors, fishbowls, fog and smoke. Volumetric clouds may allow us to describe the air, however ``empty'', and introduce air particles, in a manner independent of the viewer position. For that, we rely on some eletromagnetic properties to arrive at seven attributes per voxel that would describe the material and its color or transparency. Three attributes are for the transmissivity of each color, three are for the attenuation of each color, and another attribute is for diffuseness. These attributes give information about the object to the renderer, with whom lies the decision on how to render and depict each object.
Domain Specific Transporter Framework to Detect Fractures in Ultrasound
Jun 09, 2021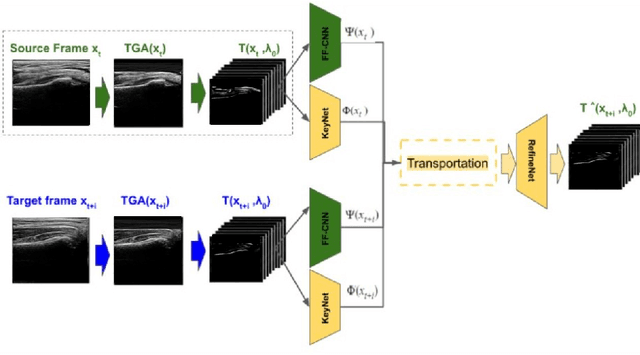
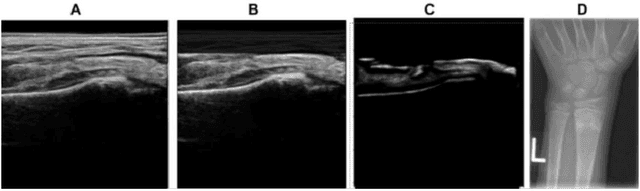
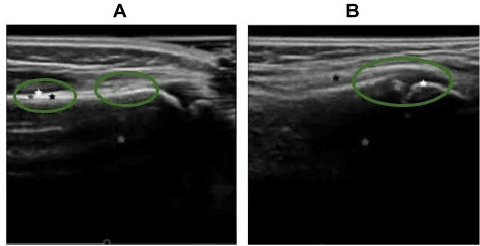
Ultrasound examination for detecting fractures is ideally suited for Emergency Departments (ED) as it is relatively fast, safe (from ionizing radiation), has dynamic imaging capability and is easily portable. High interobserver variability in manual assessment of ultrasound scans has piqued research interest in automatic assessment techniques using Deep Learning (DL). Most DL techniques are supervised and are trained on large numbers of labeled data which is expensive and requires many hours of careful annotation by experts. In this paper, we propose an unsupervised, domain specific transporter framework to identify relevant keypoints from wrist ultrasound scans. Our framework provides a concise geometric representation highlighting regions with high structural variation in a 3D ultrasound (3DUS) sequence. We also incorporate domain specific information represented by instantaneous local phase (LP) which detects bone features from 3DUS. We validate the technique on 3DUS videos obtained from 30 subjects. Each ultrasound scan was independently assessed by three readers to identify fractures along with the corresponding x-ray. Saliency of keypoints detected in the image\ are compared against manual assessment based on distance from relevant features.The transporter neural network was able to accurately detect 180 out of 250 bone regions sampled from wrist ultrasound videos. We expect this technique to increase the applicability of ultrasound in fracture detection.
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021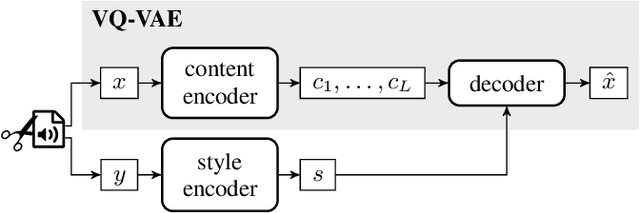
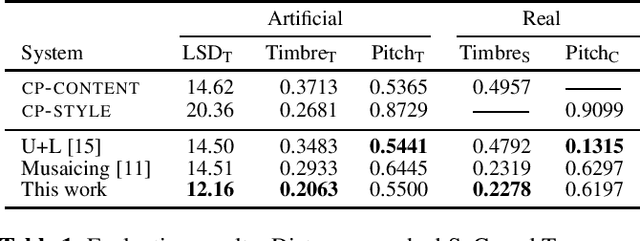
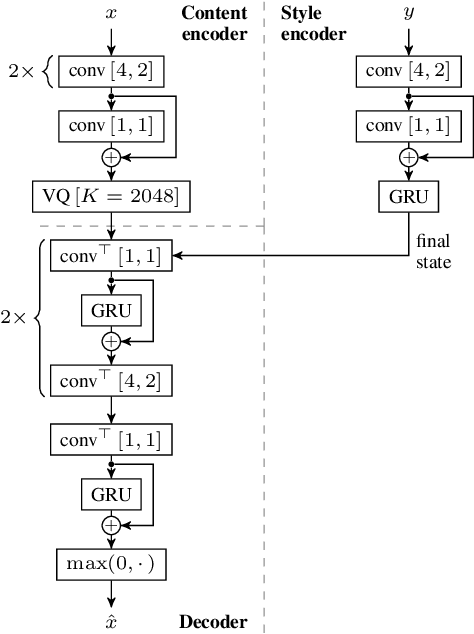
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
3D human tongue reconstruction from single "in-the-wild" images
Jun 23, 2021

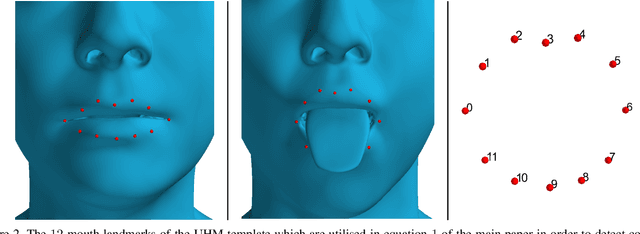

3D face reconstruction from a single image is a task that has garnered increased interest in the Computer Vision community, especially due to its broad use in a number of applications such as realistic 3D avatar creation, pose invariant face recognition and face hallucination. Since the introduction of the 3D Morphable Model in the late 90's, we witnessed an explosion of research aiming at particularly tackling this task. Nevertheless, despite the increasing level of detail in the 3D face reconstructions from single images mainly attributed to deep learning advances, finer and highly deformable components of the face such as the tongue are still absent from all 3D face models in the literature, although being very important for the realness of the 3D avatar representations. In this work we present the first, to the best of our knowledge, end-to-end trainable pipeline that accurately reconstructs the 3D face together with the tongue. Moreover, we make this pipeline robust in "in-the-wild" images by introducing a novel GAN method tailored for 3D tongue surface generation. Finally, we make publicly available to the community the first diverse tongue dataset, consisting of 1,800 raw scans of 700 individuals varying in gender, age, and ethnicity backgrounds. As we demonstrate in an extensive series of quantitative as well as qualitative experiments, our model proves to be robust and realistically captures the 3D tongue structure, even in adverse "in-the-wild" conditions.
Efficient and Generic 1D Dilated Convolution Layer for Deep Learning
Apr 16, 2021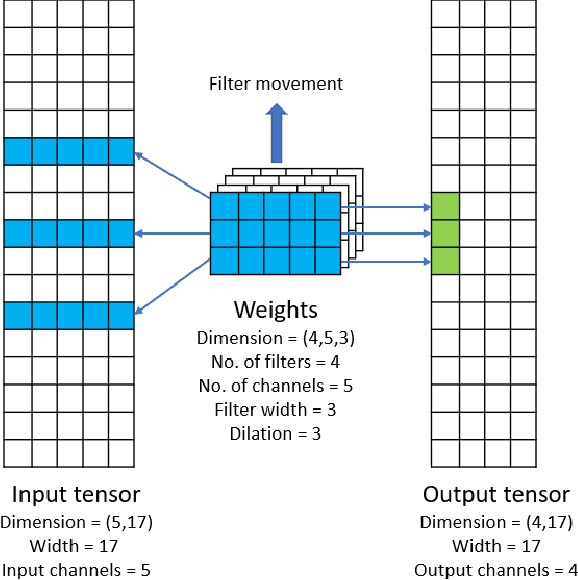
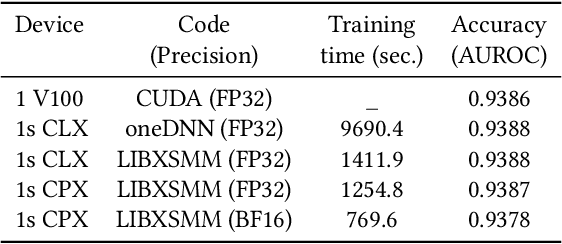
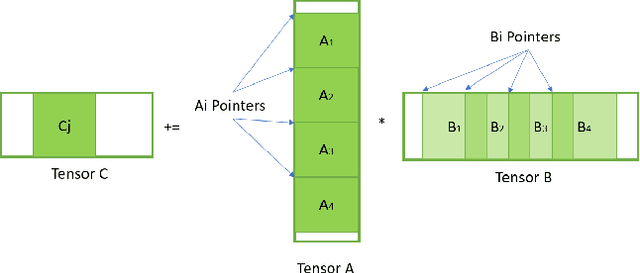
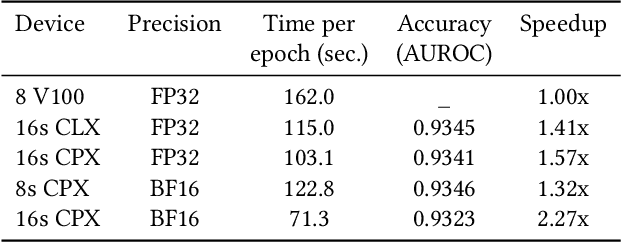
Convolutional neural networks (CNNs) have found many applications in tasks involving two-dimensional (2D) data, such as image classification and image processing. Therefore, 2D convolution layers have been heavily optimized on CPUs and GPUs. However, in many applications - for example genomics and speech recognition, the data can be one-dimensional (1D). Such applications can benefit from optimized 1D convolution layers. In this work, we introduce our efficient implementation of a generic 1D convolution layer covering a wide range of parameters. It is optimized for x86 CPU architectures, in particular, for architectures containing Intel AVX-512 and AVX-512 BFloat16 instructions. We use the LIBXSMM library's batch-reduce General Matrix Multiplication (BRGEMM) kernel for FP32 and BFloat16 precision. We demonstrate that our implementation can achieve up to 80% efficiency on Intel Xeon Cascade Lake and Cooper Lake CPUs. Additionally, we show the generalization capability of our BRGEMM based approach by achieving high efficiency across a range of parameters. We consistently achieve higher efficiency than the 1D convolution layer with Intel oneDNN library backend for varying input tensor widths, filter widths, number of channels, filters, and dilation parameters. Finally, we demonstrate the performance of our optimized 1D convolution layer by utilizing it in the end-to-end neural network training with real genomics datasets and achieve up to 6.86x speedup over the oneDNN library-based implementation on Cascade Lake CPUs. We also demonstrate the scaling with 16 sockets of Cascade/Cooper Lake CPUs and achieve significant speedup over eight V100 GPUs using a similar power envelop. In the end-to-end training, we get a speedup of 1.41x on Cascade Lake with FP32, 1.57x on Cooper Lake with FP32, and 2.27x on Cooper Lake with BFloat16 over eight V100 GPUs with FP32.
Two-Stage Self-Supervised Cycle-Consistency Network for Reconstruction of Thin-Slice MR Images
Jun 29, 2021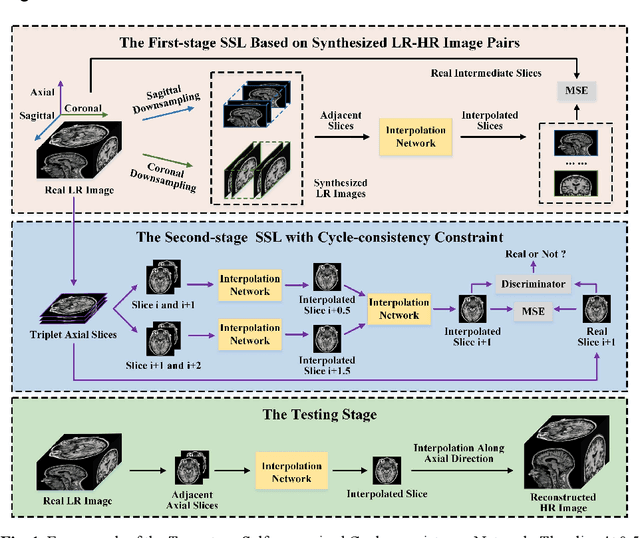
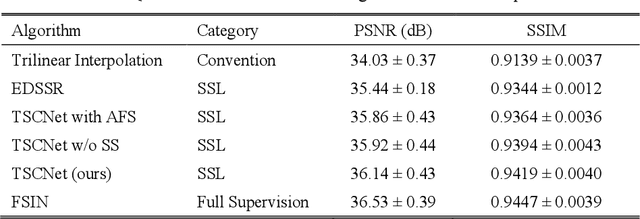
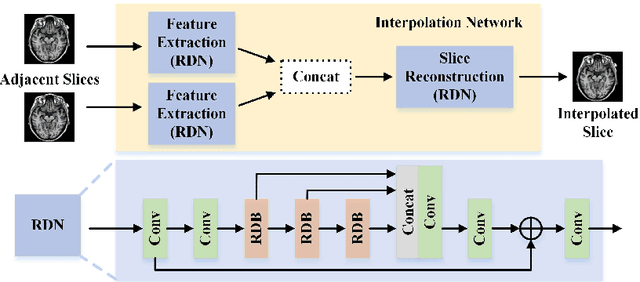
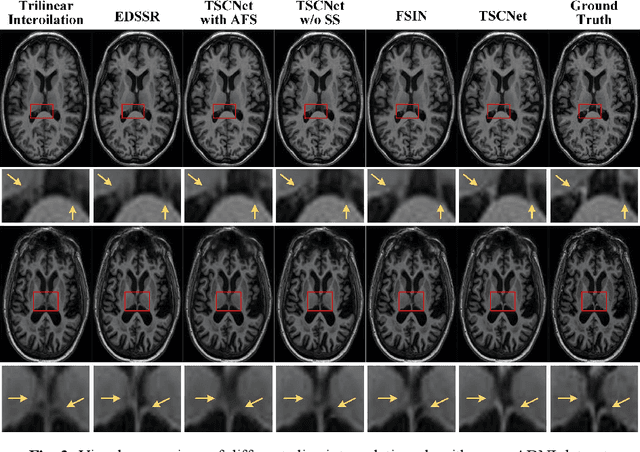
The thick-slice magnetic resonance (MR) images are often structurally blurred in coronal and sagittal views, which causes harm to diagnosis and image post-processing. Deep learning (DL) has shown great potential to re-construct the high-resolution (HR) thin-slice MR images from those low-resolution (LR) cases, which we refer to as the slice interpolation task in this work. However, since it is generally difficult to sample abundant paired LR-HR MR images, the classical fully supervised DL-based models cannot be effectively trained to get robust performance. To this end, we propose a novel Two-stage Self-supervised Cycle-consistency Network (TSCNet) for MR slice interpolation, in which a two-stage self-supervised learning (SSL) strategy is developed for unsupervised DL network training. The paired LR-HR images are synthesized along the sagittal and coronal directions of input LR images for network pretraining in the first-stage SSL, and then a cyclic in-terpolation procedure based on triplet axial slices is designed in the second-stage SSL for further refinement. More training samples with rich contexts along all directions are exploited as guidance to guarantee the improved in-terpolation performance. Moreover, a new cycle-consistency constraint is proposed to supervise this cyclic procedure, which encourages the network to reconstruct more realistic HR images. The experimental results on a real MRI dataset indicate that TSCNet achieves superior performance over the conventional and other SSL-based algorithms, and obtains competitive quali-tative and quantitative results compared with the fully supervised algorithm.
CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents
Apr 27, 2020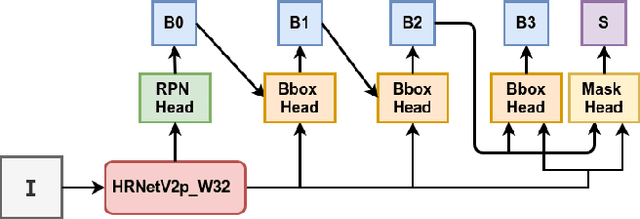
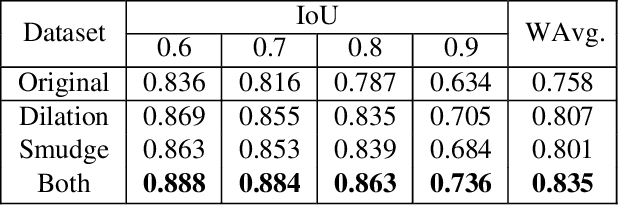
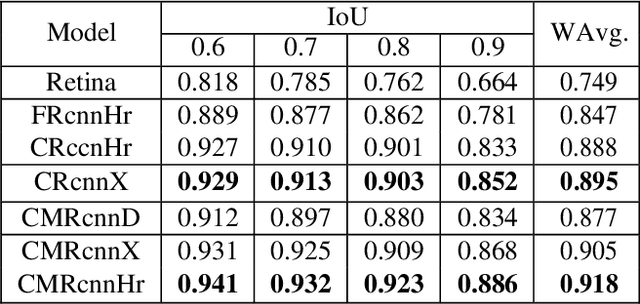
An automatic table recognition method for interpretation of tabular data in document images majorly involves solving two problems of table detection and table structure recognition. The prior work involved solving both problems independently using two separate approaches. More recent works signify the use of deep learning-based solutions while also attempting to design an end to end solution. In this paper, we present an improved deep learning-based end to end approach for solving both problems of table detection and structure recognition using a single Convolution Neural Network (CNN) model. We propose CascadeTabNet: a Cascade mask Region-based CNN High-Resolution Network (Cascade mask R-CNN HRNet) based model that detects the regions of tables and recognizes the structural body cells from the detected tables at the same time. We evaluate our results on ICDAR 2013, ICDAR 2019 and TableBank public datasets. We achieved 3rd rank in ICDAR 2019 post-competition results for table detection while attaining the best accuracy results for the ICDAR 2013 and TableBank dataset. We also attain the highest accuracy results on the ICDAR 2019 table structure recognition dataset. Additionally, we demonstrate effective transfer learning and image augmentation techniques that enable CNNs to achieve very accurate table detection results. Code and dataset has been made available at: https://github.com/DevashishPrasad/CascadeTabNet
Automatic Main Character Recognition for Photographic Studies
Jun 16, 2021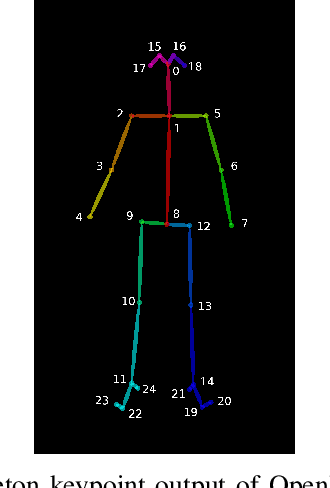
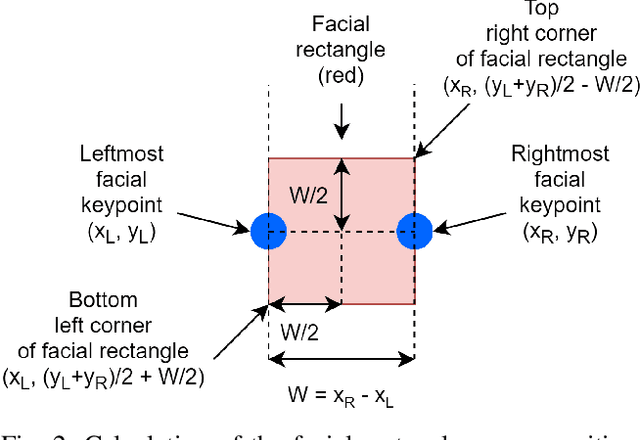


Main characters in images are the most important humans that catch the viewer's attention upon first look, and they are emphasized by properties such as size, position, color saturation, and sharpness of focus. Identifying the main character in images plays an important role in traditional photographic studies and media analysis, but the task is performed manually and can be slow and laborious. Furthermore, selection of main characters can be sometimes subjective. In this paper, we analyze the feasibility of solving the main character recognition needed for photographic studies automatically and propose a method for identifying the main characters. The proposed method uses machine learning based human pose estimation along with traditional computer vision approaches for this task. We approach the task as a binary classification problem where each detected human is classified either as a main character or not. To evaluate both the subjectivity of the task and the performance of our method, we collected a dataset of 300 varying images from multiple sources and asked five people, a photographic researcher and four other persons, to annotate the main characters. Our analysis showed a relatively high agreement between different annotators. The proposed method achieved a promising F1 score of 0.83 on the full image set and 0.96 on a subset evaluated as most clear and important cases by the photographic researcher.