 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Communication conditions in virtual acoustic scenes in an underground station
Jun 30, 2021
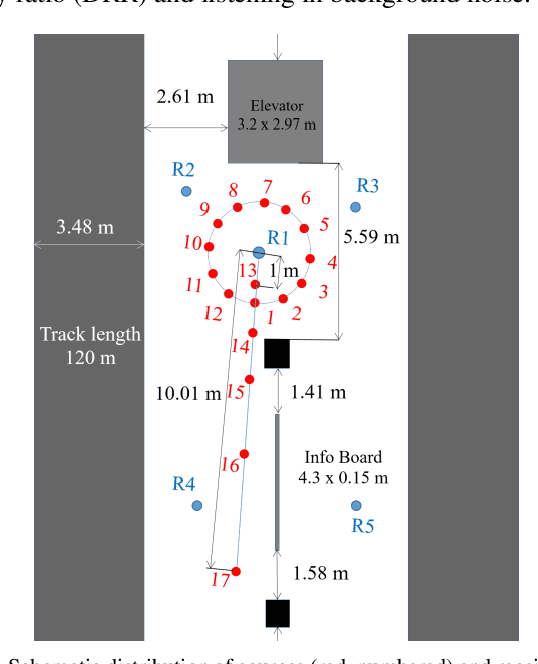
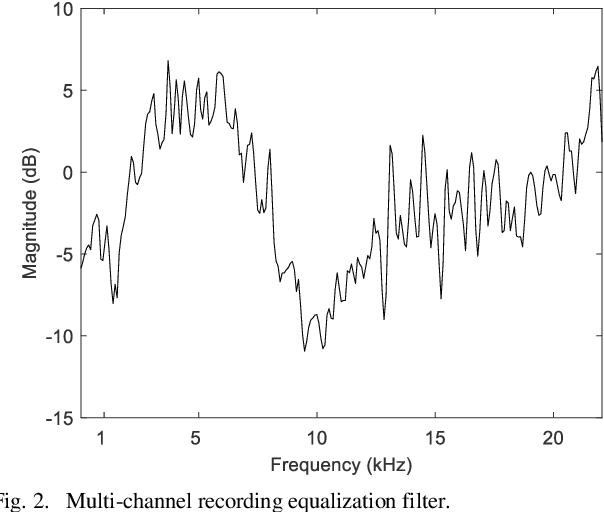
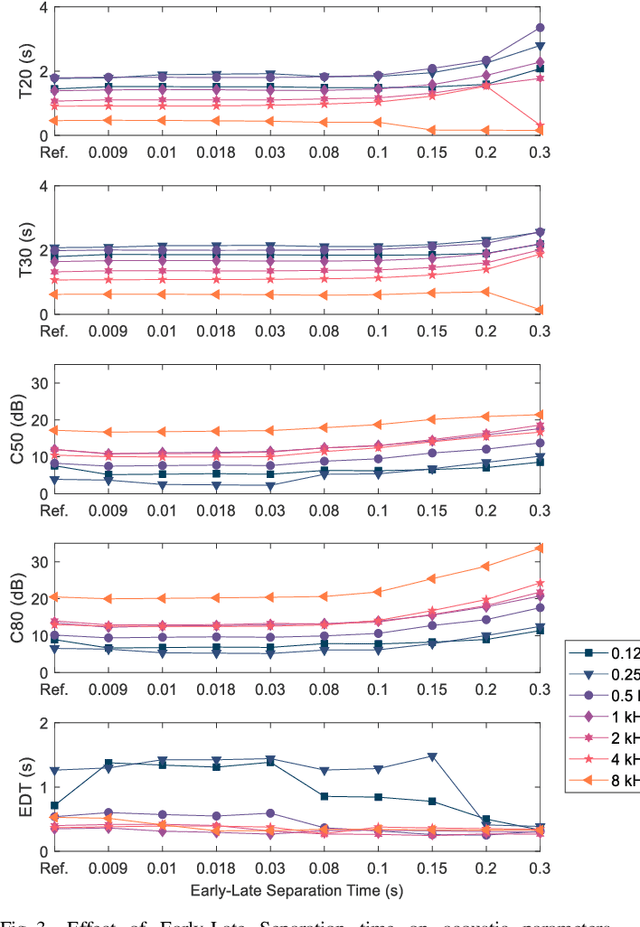
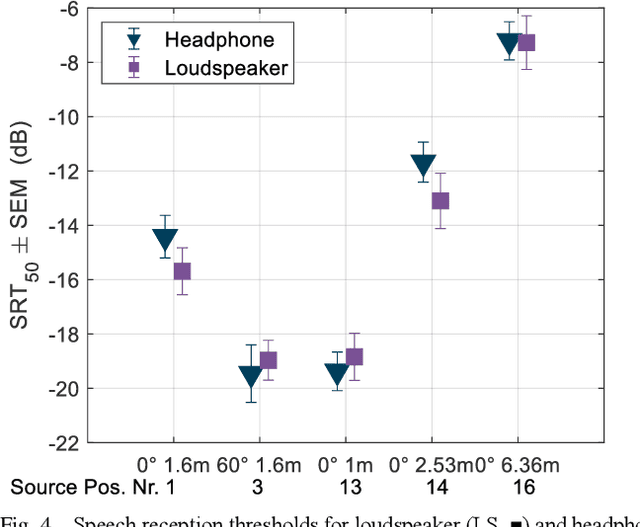
Underground stations are a common communication situation in towns: we talk with friends or colleagues, listen to announcements or shop for titbits while background noise and reverberation are challenging communication. Here, we perform an acoustical analysis of two communication scenes in an underground station in Munich and test speech intelligibility. The acoustical conditions were measured in the station and are compared to simulations in the real-time Simulated Open Field Environment (rtSOFE). We compare binaural room impulse responses measured with an artificial head in the station to modeled impulse responses for free-field auralization via 60 loudspeakers in the rtSOFE. We used the image source method to model early reflections and a set of multi-microphone recordings to model late reverberation. The first communication scene consists of 12 equidistant (1.6 m) horizontally spaced source positions around a listener, simulating different direction-dependent spatial unmasking conditions. The second scene mimics an approaching speaker across six radially spaced source positions (from 1 m to 10 m) with varying direct sound level and thus direct-to-reverberant energy. The acoustic parameters of the underground station show a moderate amount of reverberation (T30 in octave bands was between 2.3 s and 0.6 s and early-decay times between 1.46 s and 0.46 s). The binaural and energetic parameters of the auralization were in a close match to the measurement. Measured speech reception thresholds were within the error of the speech test, letting us to conclude that the auralized simulation reproduces acoustic and perceptually relevant parameters for speech intelligibility with high accuracy.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 16, 2020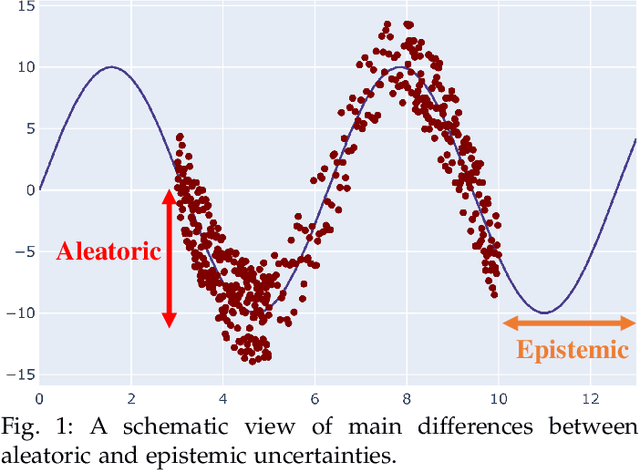
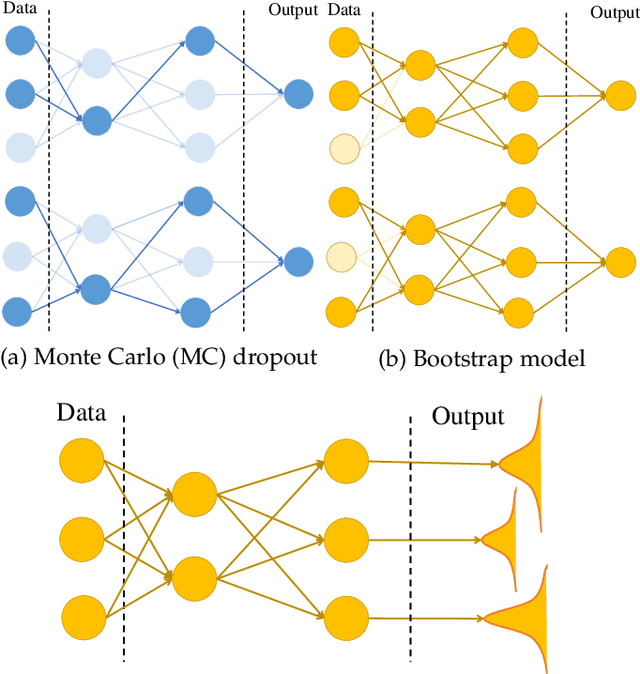
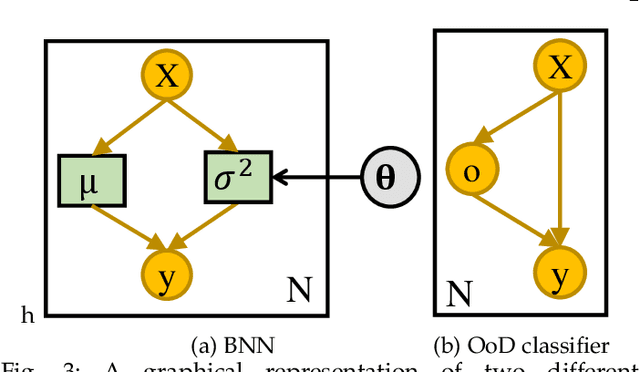
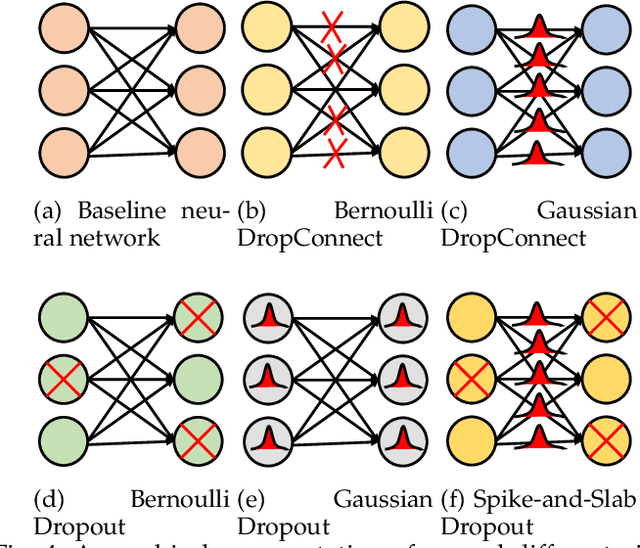
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
Decoupled Box Proposal and Featurization with Ultrafine-Grained Semantic Labels Improve Image Captioning and Visual Question Answering
Sep 04, 2019
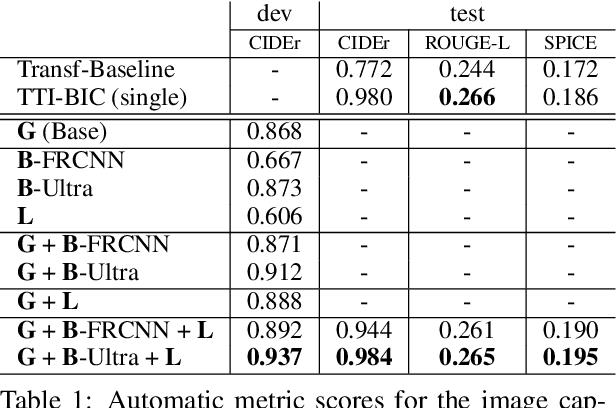

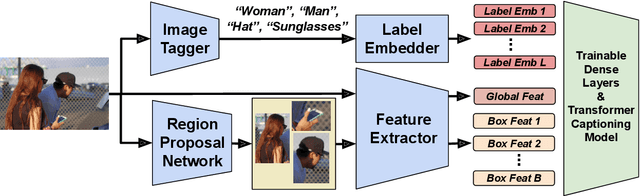
Object detection plays an important role in current solutions to vision and language tasks like image captioning and visual question answering. However, popular models like Faster R-CNN rely on a costly process of annotating ground-truths for both the bounding boxes and their corresponding semantic labels, making it less amenable as a primitive task for transfer learning. In this paper, we examine the effect of decoupling box proposal and featurization for down-stream tasks. The key insight is that this allows us to leverage a large amount of labeled annotations that were previously unavailable for standard object detection benchmarks. Empirically, we demonstrate that this leads to effective transfer learning and improved image captioning and visual question answering models, as measured on publicly available benchmarks.
Uncertainty guided semi-supervised segmentation of retinal layers in OCT images
Mar 02, 2021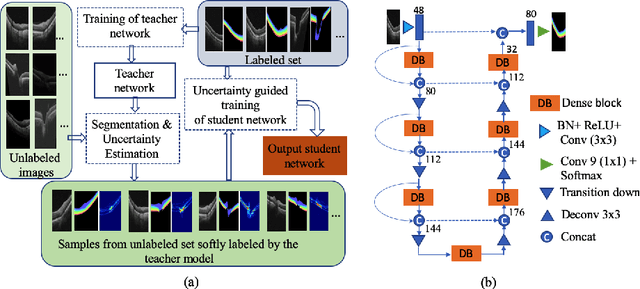
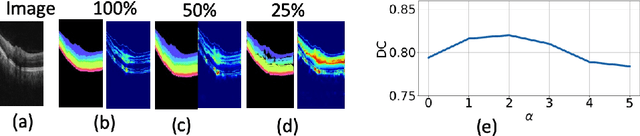
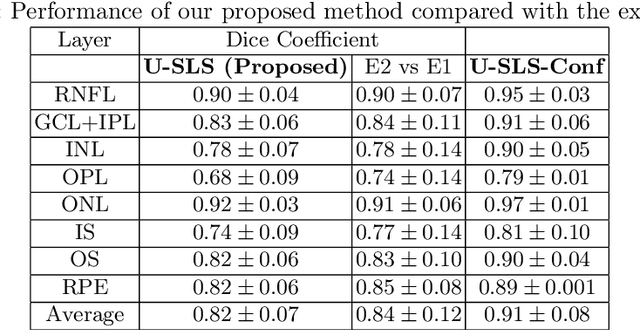
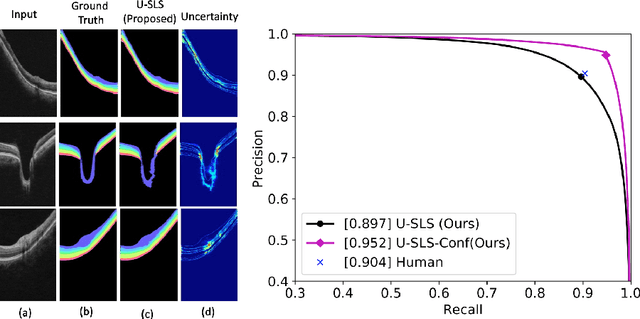
Deep convolutional neural networks have shown outstanding performance in medical image segmentation tasks. The usual problem when training supervised deep learning methods is the lack of labeled data which is time-consuming and costly to obtain. In this paper, we propose a novel uncertainty-guided semi-supervised learning based on a student-teacher approach for training the segmentation network using limited labeled samples and a large number of unlabeled images. First, a teacher segmentation model is trained from the labeled samples using Bayesian deep learning. The trained model is used to generate soft segmentation labels and uncertainty maps for the unlabeled set. The student model is then updated using the softly segmented samples and the corresponding pixel-wise confidence of the segmentation quality estimated from the uncertainty of the teacher model using a newly designed loss function. Experimental results on a retinal layer segmentation task show that the proposed method improves the segmentation performance in comparison to the fully supervised approach and is on par with the expert annotator. The proposed semi-supervised segmentation framework is a key contribution and applicable for biomedical image segmentation across various imaging modalities where access to annotated medical images is challenging
* MICCAI,19
Towards Automatic Digital Documentation and Progress Reporting of Mechanical Construction Pipes using Smartphones
Dec 20, 2020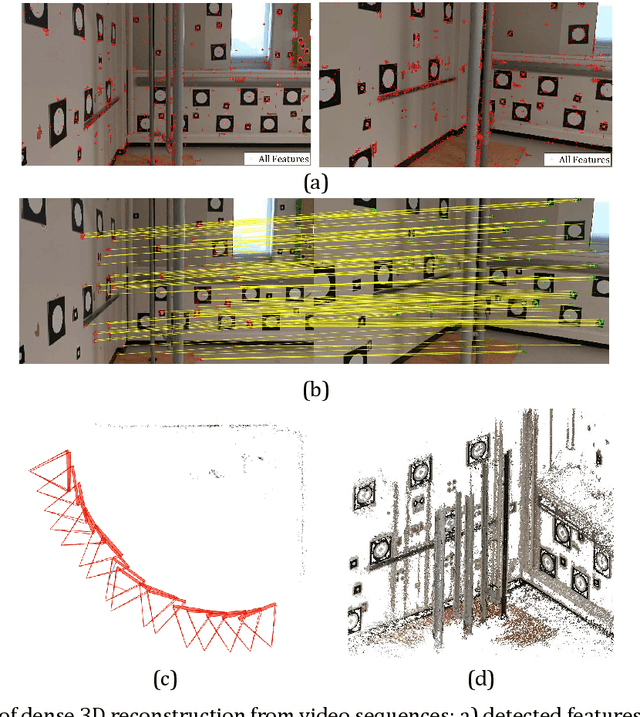
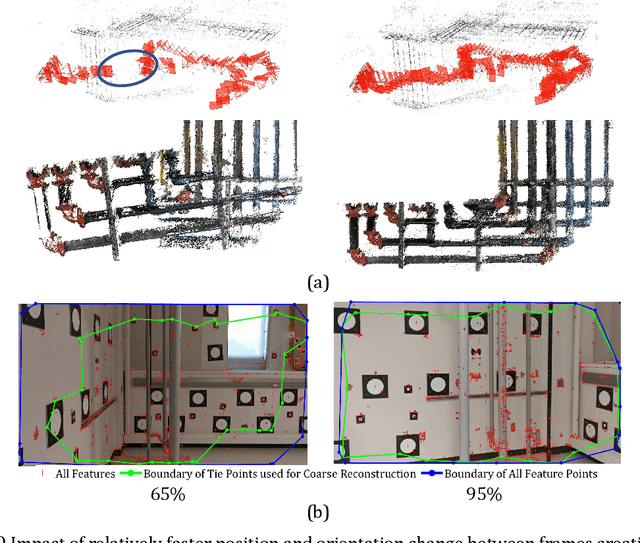
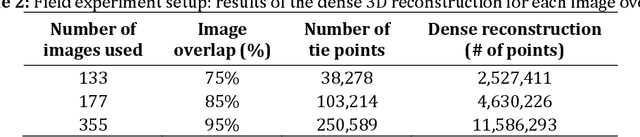
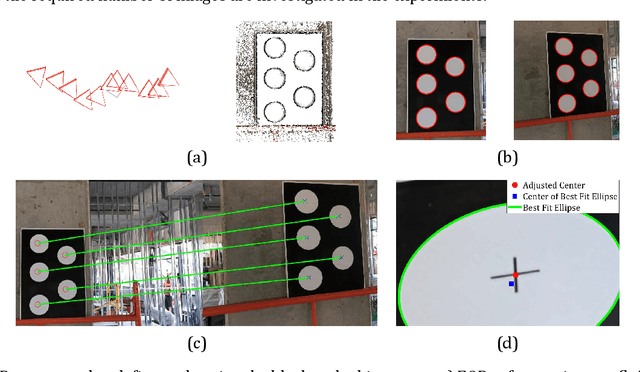
This manuscript presents a framework towards automated 3D digital documentation and progress reporting of mechanical pipes in building construction projects, using smartphones. New methods were proposed to determine the video frame rate required to achieve a desired image overlap; define metric scale for 3D reconstruction; extract pipes from point clouds; and classify pipes according to their planned bill of quantity radii. The effectiveness of the proposed methods in both laboratory (six pipes) and construction site (58 pipes) conditions was evaluated. It was observed that the proposed metric scale definition achieved sub-millimeter pipe radius estimation accuracy. Both laboratory and field experiments revealed that increasing the image overlap improved the pipe classification quality, radius, and length. Overall, using the proposed methods, it was possible to achieve pipe classification F-measure, radius estimation accuracy, and length estimation percent error of 96.4%, 5.4mm, and 5.0%, respectively, on construction sites using at least 95% image overlap.
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

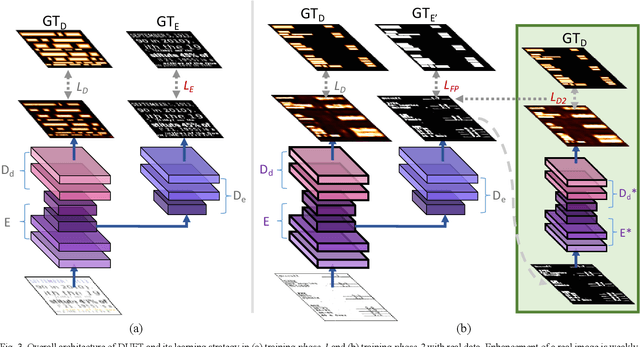

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.
Deep Spectral Correspondence for Matching Disparate Image Pairs
Sep 12, 2018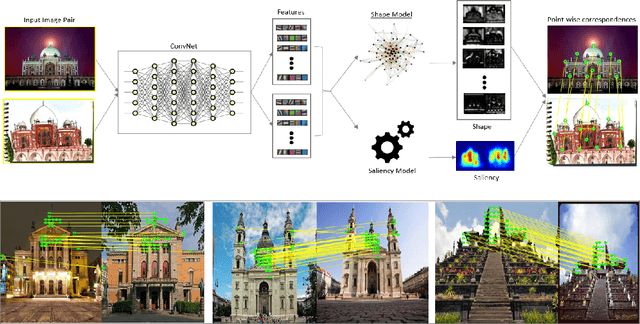
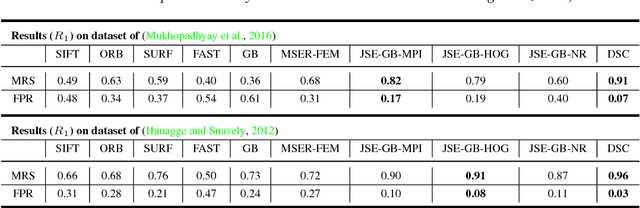

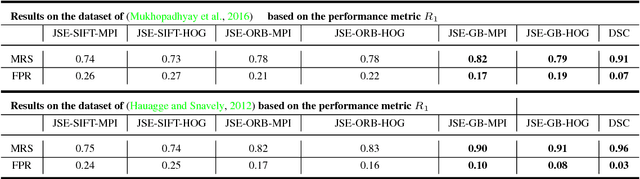
A novel, non-learning-based, saliency-aware, shape-cognizant correspondence determination technique is proposed for matching image pairs that are significantly disparate in nature. Images in the real world often exhibit high degrees of variation in scale, orientation, viewpoint, illumination and affine projection parameters, and are often accompanied by the presence of textureless regions and complete or partial occlusion of scene objects. The above conditions confound most correspondence determination techniques by rendering impractical the use of global contour-based descriptors or local pixel-level features for establishing correspondence. The proposed deep spectral correspondence (DSC) determination scheme harnesses the representational power of local feature descriptors to derive a complex high-level global shape representation for matching disparate images. The proposed scheme reasons about correspondence between disparate images using high-level global shape cues derived from low-level local feature descriptors. Consequently, the proposed scheme enjoys the best of both worlds, i.e., a high degree of invariance to affine parameters such as scale, orientation, viewpoint, illumination afforded by the global shape cues and robustness to occlusion provided by the low-level feature descriptors. While the shape-based component within the proposed scheme infers what to look for, an additional saliency-based component dictates where to look at thereby tackling the noisy correspondences arising from the presence of textureless regions and complex backgrounds. In the proposed scheme, a joint image graph is constructed using distances computed between interest points in the appearance (i.e., image) space. Eigenspectral decomposition of the joint image graph allows for reasoning about shape similarity to be performed jointly, in the appearance space and eigenspace.
Improved dual channel pulse coupled neural network and its application to multi-focus image fusion
Feb 04, 2020



This paper presents an improved dual channel pulse coupled neural network (IDC-PCNN) model for image fusion. The model can overcome some defects of standard PCNN model. In this fusion scheme, the multiplication rule is replaced by addition rule in the information fusion pool of dual channel PCNN (DC-PCNN) model. Meanwhile the sum of modified Laplacian (SML) measure is adopted, which is better than other focus measures. This method not only inherits the good characteristics of the standard PCNN model but also enhances the computing efficiency and fusion quality. The performance of the proposed method is evaluated by using four criteria including average cross entropy, root mean square error, peak value signal to noise ratio and structure similarity index. Comparative studies show that the proposed fusion algorithm outperforms the standard PCNN method and the DC-PCNN method.
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
Jun 10, 2021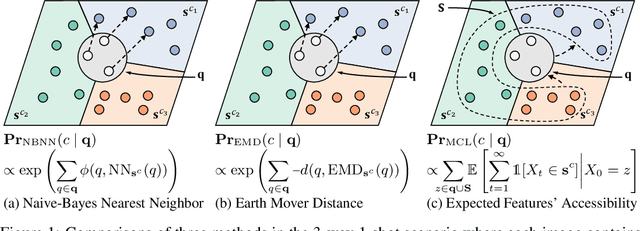
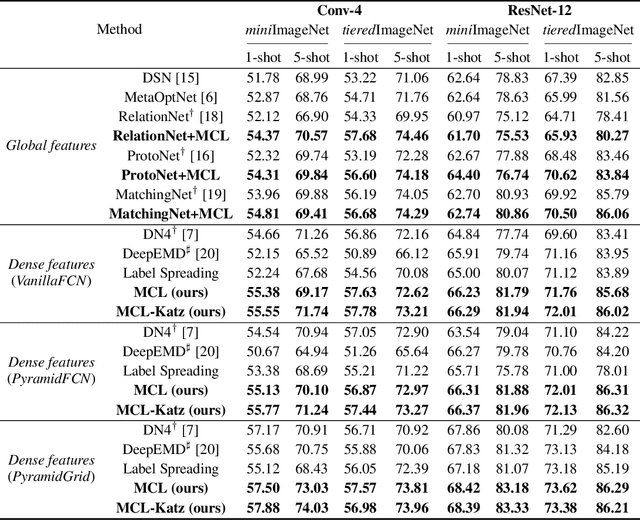
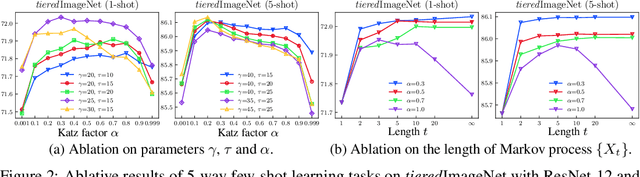
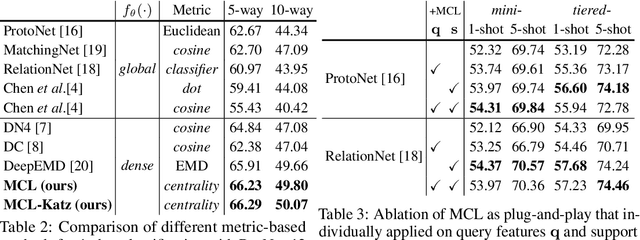
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to accommodate new tasks not seen during training, given only a few examples. To handle the limited-data problem in few-shot regimes, recent methods tend to collectively use a set of local features to densely represent an image instead of using a mixed global feature. They generally explore a unidirectional query-to-support paradigm in FSL, e.g., find the nearest/optimal support feature for each query feature and aggregate these local matches for a joint classification. In this paper, we propose a new method Mutual Centralized Learning (MCL) to fully affiliate the two disjoint sets of dense features in a bidirectional paradigm. We associate each local feature with a particle that can bidirectionally random walk in a discrete feature space by the affiliations. To estimate the class probability, we propose the features' accessibility that measures the expected number of visits to the support features of that class in a Markov process. We relate our method to learning a centrality on an affiliation network and demonstrate its capability to be plugged in existing methods by highlighting centralized local features. Experiments show that our method achieves the state-of-the-art on both miniImageNet and tieredImageNet.
Image Segmentation Based on Multiscale Fast Spectral Clustering
Dec 12, 2018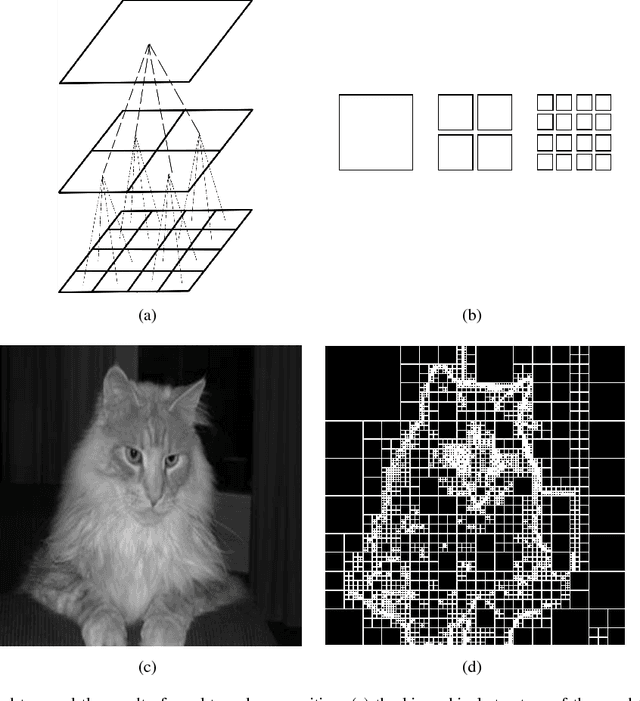
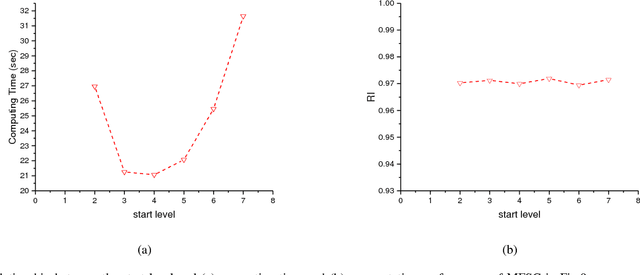
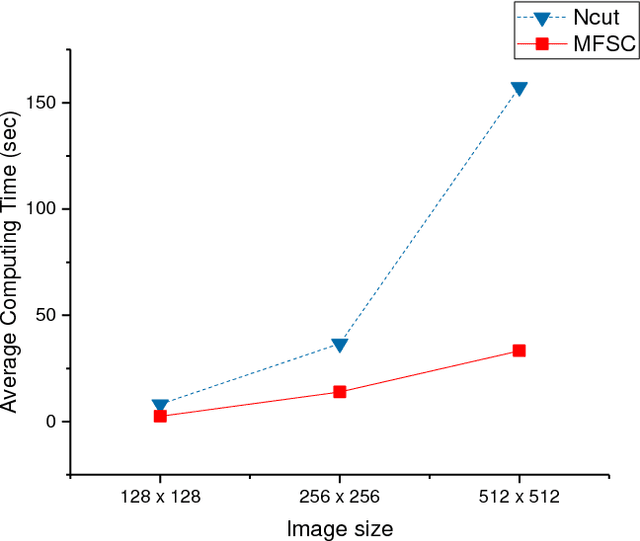
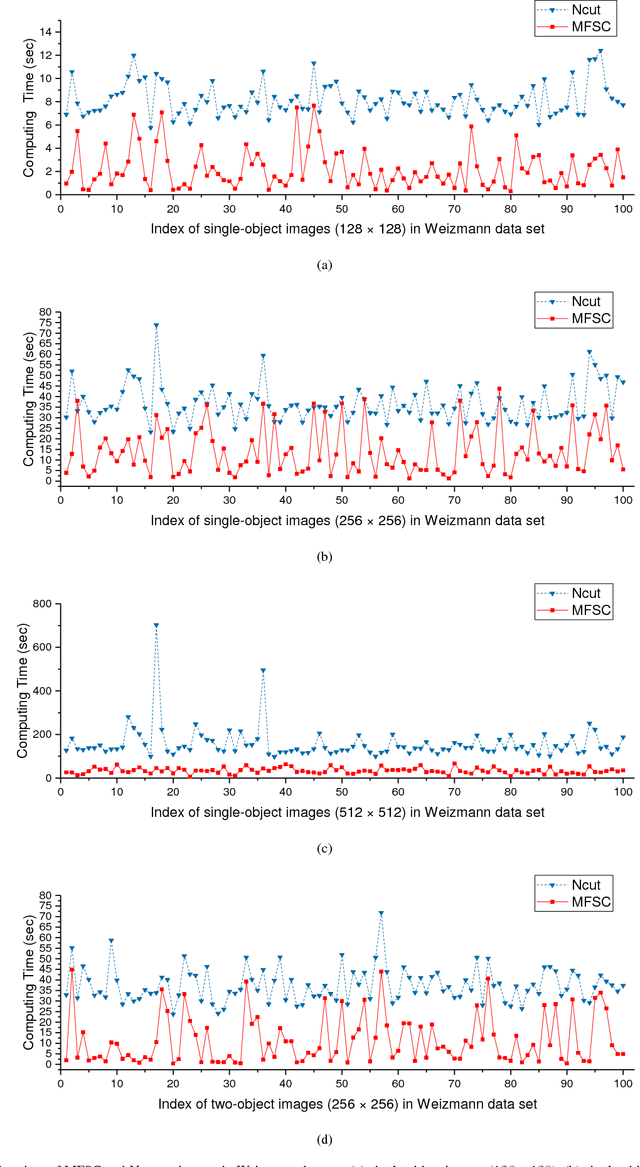
In recent years, spectral clustering has become one of the most popular clustering algorithms for image segmentation. However, it has restricted applicability to large-scale images due to its high computational complexity. In this paper, we first propose a novel algorithm called Fast Spectral Clustering based on quad-tree decomposition. The algorithm focuses on the spectral clustering at superpixel level and its computational complexity is O(nlogn) + O(m) + O(m^(3/2)); its memory cost is O(m), where n and m are the numbers of pixels and the superpixels of a image. Then we propose Multiscale Fast Spectral Clustering by improving Fast Spectral Clustering, which is based on the hierarchical structure of the quad-tree. The computational complexity of Multiscale Fast Spectral Clustering is O(nlogn) and its memory cost is O(m). Extensive experiments on real large-scale images demonstrate that Multiscale Fast Spectral Clustering outperforms Normalized cut in terms of lower computational complexity and memory cost, with comparable clustering accuracy.