 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Captioning with Integrated Bottom-Up and Multi-level Residual Top-Down Attention for Game Scene Understanding
Jun 16, 2019




Image captioning has attracted considerable attention in recent years. However, little work has been done for game image captioning which has some unique characteristics and requirements. In this work we propose a novel game image captioning model which integrates bottom-up attention with a new multi-level residual top-down attention mechanism. Firstly, a lower-level residual top-down attention network is added to the Faster R-CNN based bottom-up attention network to address the problem that the latter may lose important spatial information when extracting regional features. Secondly, an upper-level residual top-down attention network is implemented in the caption generation network to better fuse the extracted regional features for subsequent caption prediction. We create two game datasets to evaluate the proposed model. Extensive experiments show that our proposed model outperforms existing baseline models.
Graph-Based Blind Image Deblurring From a Single Photograph
Feb 22, 2018



Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, we propose a graph-based blind image deblurring algorithm by interpreting an image patch as a signal on a weighted graph. Specifically, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. Then, we design a reweighted graph total variation (RGTV) prior that can efficiently promote a bi-modal edge weight distribution given a blurry patch. Further, to analyze RGTV in the graph frequency domain, we introduce a new weight function to represent RGTV as a graph $l_1$-Laplacian regularizer. This leads to a graph spectral filtering interpretation of the prior with desirable properties, including robustness to noise and blur, strong piecewise smooth (PWS) filtering and sharpness promotion. Minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We leverage the new graph spectral interpretation for RGTV to design an efficient algorithm that solves for the skeleton image and the blur kernel alternately. Specifically for Gaussian blur, we propose a further speedup strategy for blind Gaussian deblurring using accelerated graph spectral filtering. Finally, with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results demonstrate that our algorithm successfully restores latent sharp images and outperforms state-of-the-art methods quantitatively and qualitatively.
Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location Estimation
May 17, 2021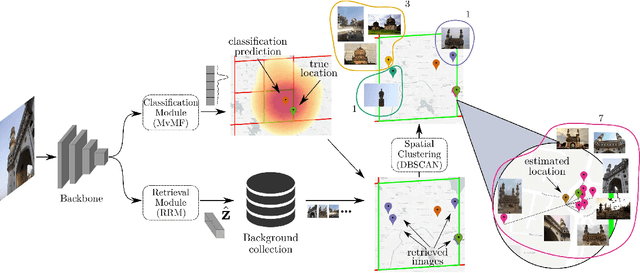
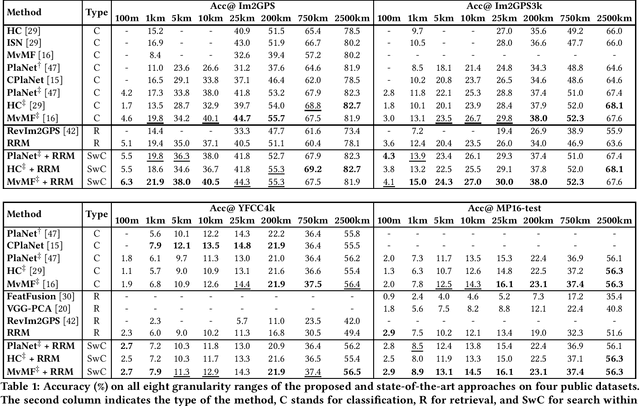
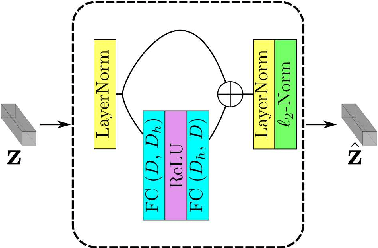
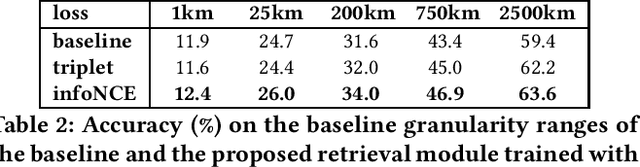
In this paper, we address the problem of global-scale image geolocation, proposing a mixed classification-retrieval scheme. Unlike other methods that strictly tackle the problem as a classification or retrieval task, we combine the two practices in a unified solution leveraging the advantages of each approach with two different modules. The first leverages the EfficientNet architecture to assign images to a specific geographic cell in a robust way. The second introduces a new residual architecture that is trained with contrastive learning to map input images to an embedding space that minimizes the pairwise geodesic distance of same-location images. For the final location estimation, the two modules are combined with a search-within-cell scheme, where the locations of most similar images from the predicted geographic cell are aggregated based on a spatial clustering scheme. Our approach demonstrates very competitive performance on four public datasets, achieving new state-of-the-art performance in fine granularity scales, i.e., 15.0% at 1km range on Im2GPS3k.
Towards Automatic Digital Documentation and Progress Reporting of Mechanical Construction Pipes using Smartphones
Dec 20, 2020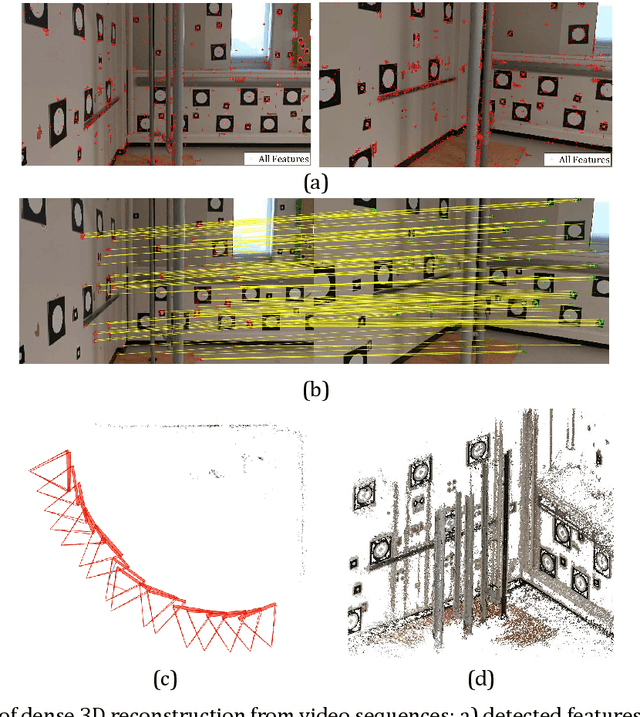
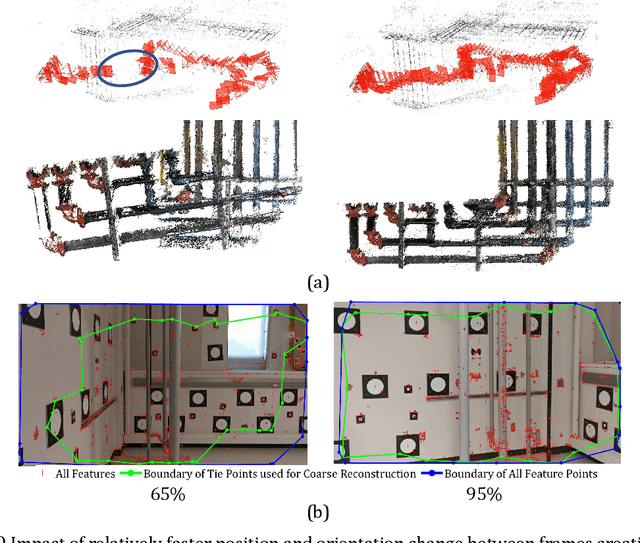
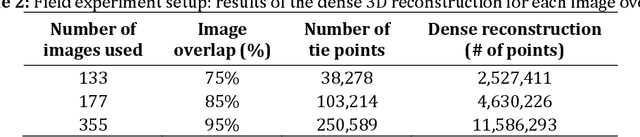
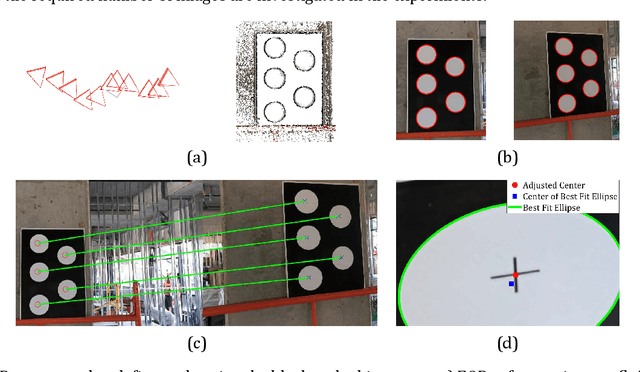
This manuscript presents a framework towards automated 3D digital documentation and progress reporting of mechanical pipes in building construction projects, using smartphones. New methods were proposed to determine the video frame rate required to achieve a desired image overlap; define metric scale for 3D reconstruction; extract pipes from point clouds; and classify pipes according to their planned bill of quantity radii. The effectiveness of the proposed methods in both laboratory (six pipes) and construction site (58 pipes) conditions was evaluated. It was observed that the proposed metric scale definition achieved sub-millimeter pipe radius estimation accuracy. Both laboratory and field experiments revealed that increasing the image overlap improved the pipe classification quality, radius, and length. Overall, using the proposed methods, it was possible to achieve pipe classification F-measure, radius estimation accuracy, and length estimation percent error of 96.4%, 5.4mm, and 5.0%, respectively, on construction sites using at least 95% image overlap.
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
May 12, 2021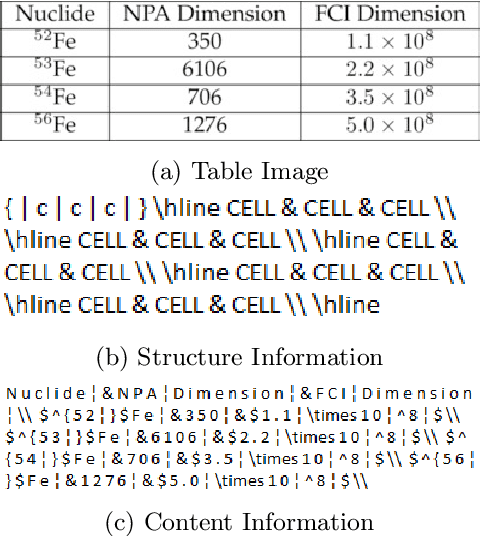
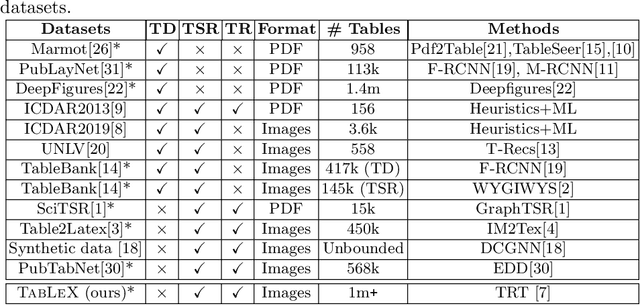
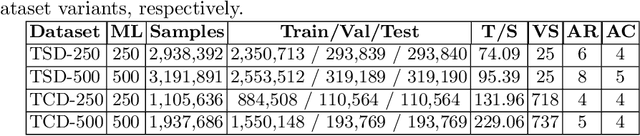
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.
Tracking 6-DoF Object Motion from Events and Frames
Mar 29, 2021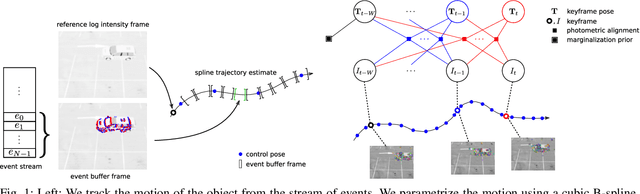
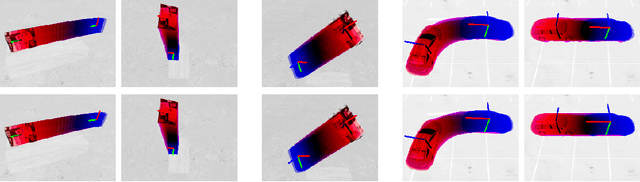
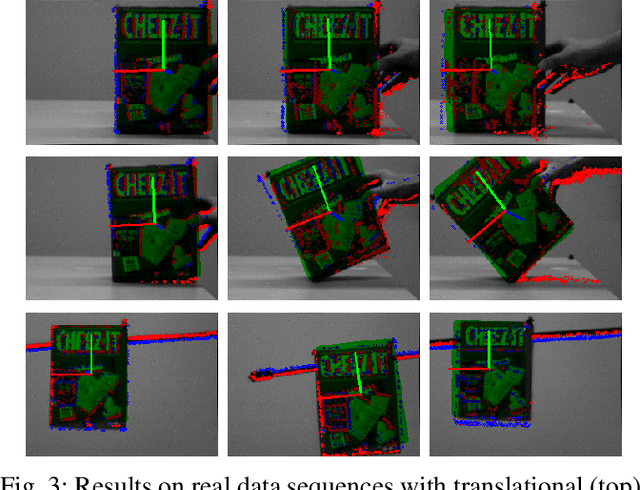

Event cameras are promising devices for lowlatency tracking and high-dynamic range imaging. In this paper,we propose a novel approach for 6 degree-of-freedom (6-DoF)object motion tracking that combines measurements of eventand frame-based cameras. We formulate tracking from highrate events with a probabilistic generative model of the eventmeasurement process of the object. On a second layer, we refinethe object trajectory in slower rate image frames through directimage alignment. We evaluate the accuracy of our approach inseveral object tracking scenarios with synthetic data, and alsoperform experiments with real data.
DeepSeagrass Dataset
Mar 09, 2021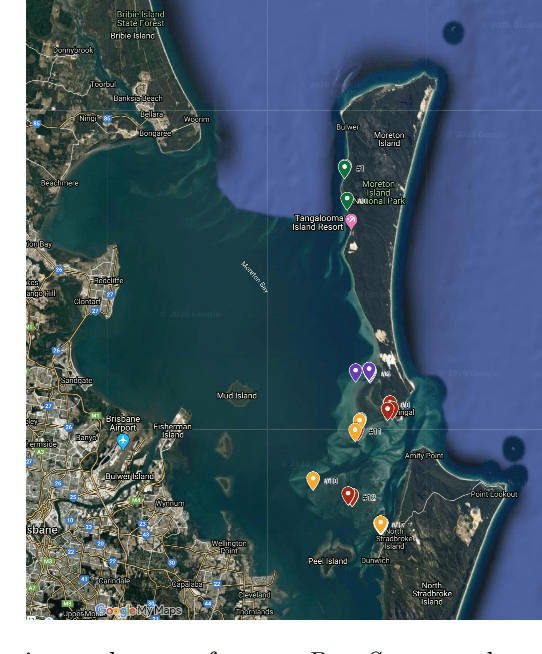
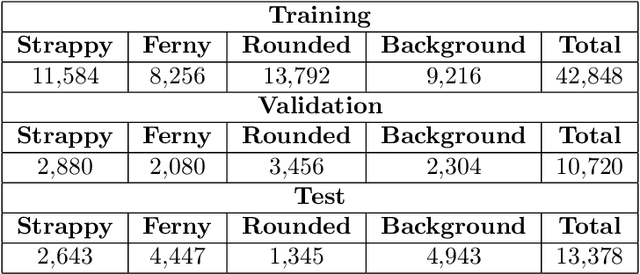
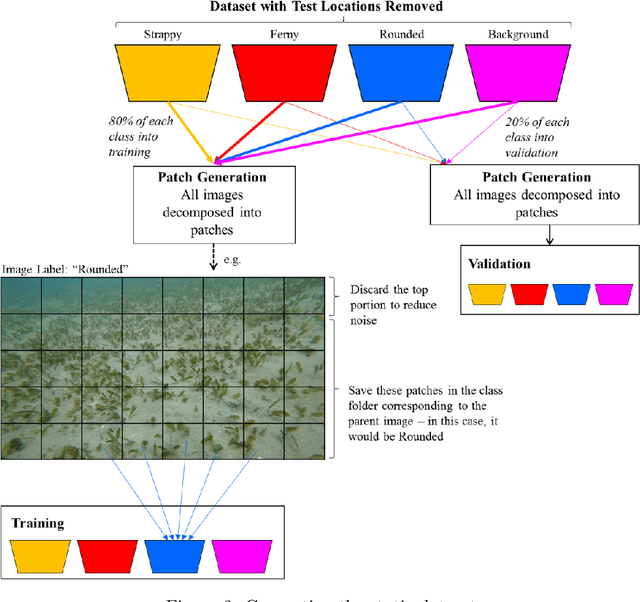

We introduce a dataset of seagrass images collected by a biologist snorkelling in Moreton Bay, Queensland, Australia, as described in our publication: arXiv:2009.09924. The images are labelled at the image-level by collecting images of the same morphotype in a folder hierarchy. We also release pre-trained models and training codes for detection and classification of seagrass species at the patch level at https://github.com/csiro-robotics/deepseagrass.
Deep Robust Single Image Depth Estimation Neural Network Using Scene Understanding
Jun 07, 2019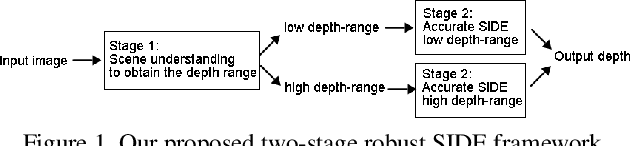
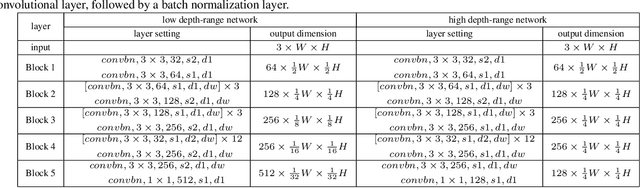
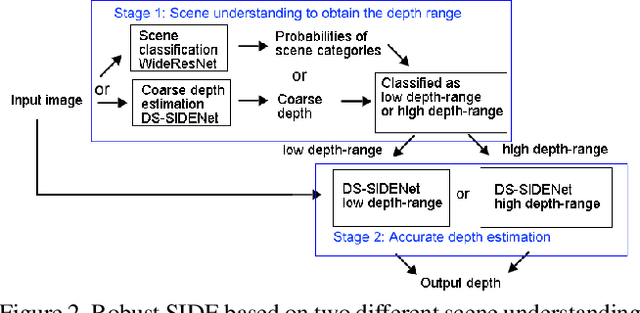
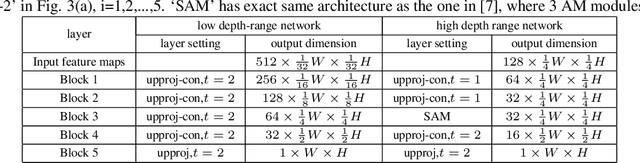
Single image depth estimation (SIDE) plays a crucial role in 3D computer vision. In this paper, we propose a two-stage robust SIDE framework that can perform blind SIDE for both indoor and outdoor scenes. At the first stage, the scene understanding module will categorize the RGB image into different depth-ranges. We introduce two different scene understanding modules based on scene classification and coarse depth estimation respectively. At the second stage, SIDE networks trained by the images of specific depth-range are applied to obtain an accurate depth map. In order to improve the accuracy, we further design a multi-task encoding-decoding SIDE network DS-SIDENet based on depthwise separable convolutions. DS-SIDENet is optimized to minimize both depth classification and depth regression losses. This improves the accuracy compared to a single-task SIDE network. Experimental results demonstrate that training DS-SIDENet on an individual dataset such as NYU achieves competitive performance to the state-of-art methods with much better efficiency. Ours proposed robust SIDE framework also shows good performance for the ScanNet indoor images and KITTI outdoor images simultaneously. It achieves the top performance compared to the Robust Vision Challenge (ROB) 2018 submissions.
The Mutex Watershed and its Objective: Efficient, Parameter-Free Image Partitioning
Apr 25, 2019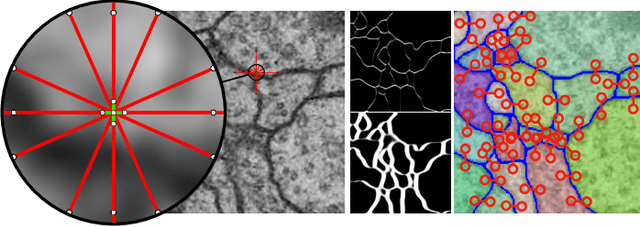
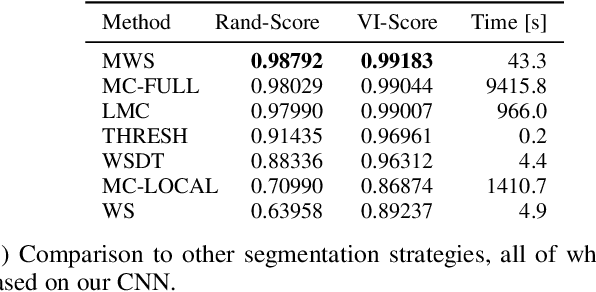
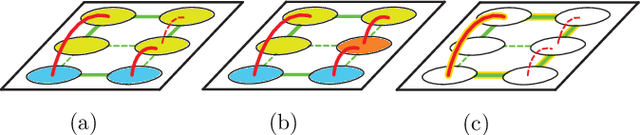
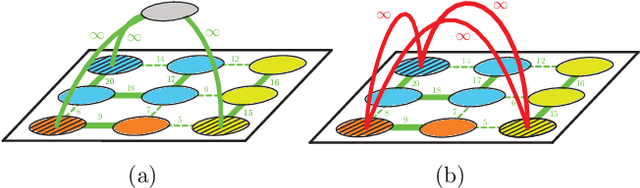
Image partitioning, or segmentation without semantics, is the task of decomposing an image into distinct segments, or equivalently to detect closed contours. Most prior work either requires seeds, one per segment; or a threshold; or formulates the task as multicut / correlation clustering, an NP-hard problem. Here, we propose a greedy algorithm for signed graph partitioning, the "Mutex Watershed". Unlike seeded watershed, the algorithm can accommodate not only attractive but also repulsive cues, allowing it to find a previously unspecified number of segments without the need for explicit seeds or a tunable threshold. We also prove that this simple algorithm solves to global optimality an objective function that is intimately related to the multicut / correlation clustering integer linear programming formulation. The algorithm is deterministic, very simple to implement, and has empirically linearithmic complexity. When presented with short-range attractive and long-range repulsive cues from a deep neural network, the Mutex Watershed gives the best results currently known for the competitive ISBI 2012 EM segmentation benchmark.
Generate What You Can't See - a View-dependent Image Generation
Mar 15, 2019

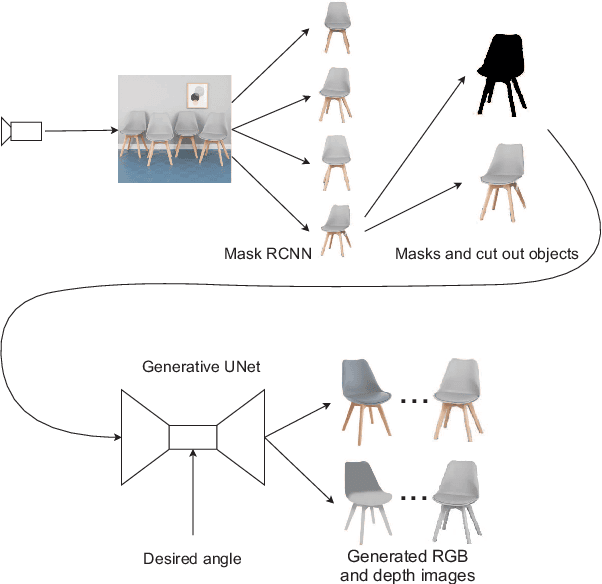
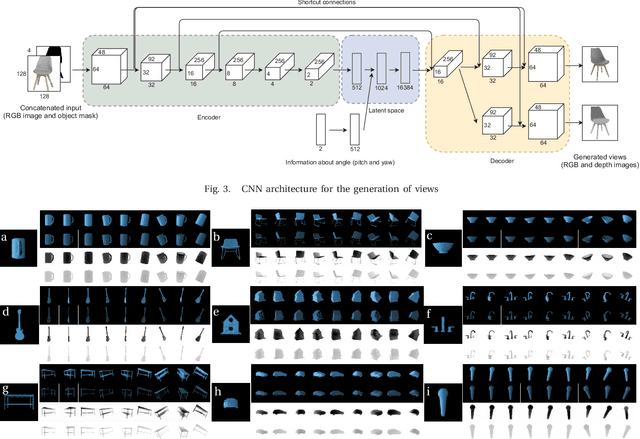
In order to operate autonomously, a robot should explore the environment and build a model of each of the surrounding objects. A common approach is to carefully scan the whole workspace. This is time-consuming. It is also often impossible to reach all the viewpoints required to acquire full knowledge about the environment. Humans can perform shape completion of occluded objects by relying on past experience. Therefore, we propose a method that generates images of an object from various viewpoints using a single input RGB image. A deep neural network is trained to imagine the object appearance from many viewpoints. We present the whole pipeline, which takes a single RGB image as input and returns a sequence of RGB and depth images of the object. The method utilizes a CNN-based object detector to extract the object from the natural scene. Then, the proposed network generates a set of RGB and depth images. We show the results both on a synthetic dataset and on real images.