 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling Gestalt Visual Reasoning on the Raven's Progressive Matrices Intelligence Test Using Generative Image Inpainting Techniques
Nov 18, 2019


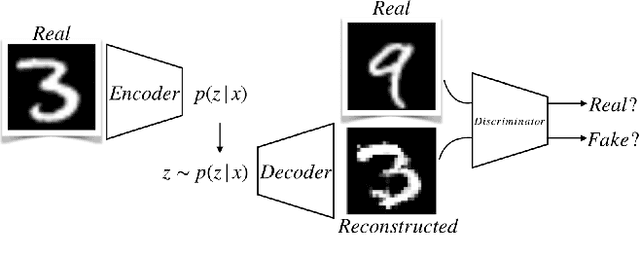
Psychologists recognize Raven's Progressive Matrices as a very effective test of general human intelligence. While many computational models have been developed by the AI community to investigate different forms of top-down, deliberative reasoning on the test, there has been less research on bottom-up perceptual processes, like Gestalt image completion, that are also critical in human test performance. In this work, we investigate how Gestalt visual reasoning on the Raven's test can be modeled using generative image inpainting techniques from computer vision. We demonstrate that a self-supervised inpainting model trained only on photorealistic images of objects achieves a score of 27/36 on the Colored Progressive Matrices, which corresponds to average performance for nine-year-old children. We also show that models trained on other datasets (faces, places, and textures) do not perform as well. Our results illustrate how learning visual regularities in real-world images can translate into successful reasoning about artificial test stimuli. On the flip side, our results also highlight the limitations of such transfer, which may explain why intelligence tests like the Raven's are often sensitive to people's individual sociocultural backgrounds.
SimPoE: Simulated Character Control for 3D Human Pose Estimation
Apr 01, 2021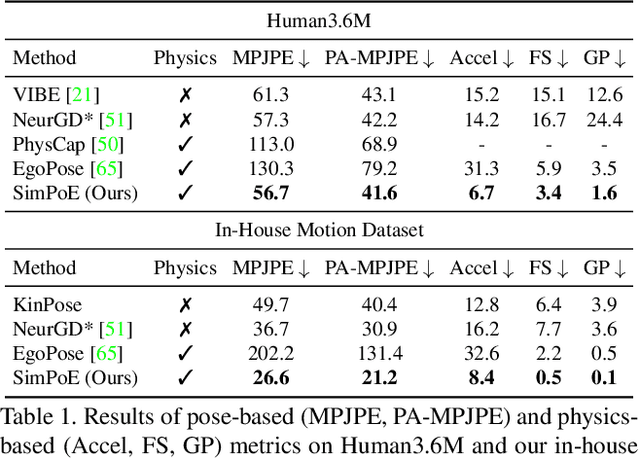
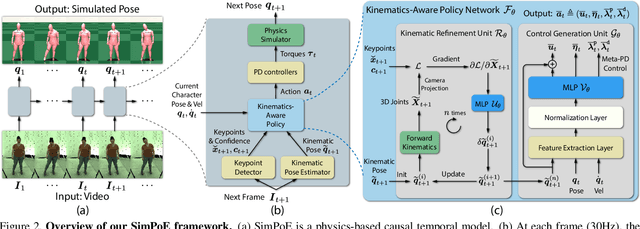
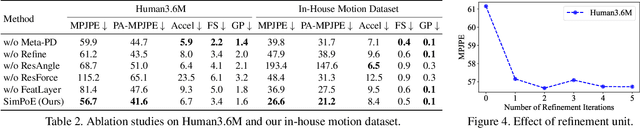
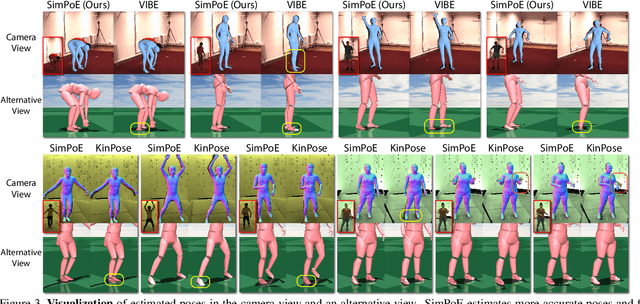
Accurate estimation of 3D human motion from monocular video requires modeling both kinematics (body motion without physical forces) and dynamics (motion with physical forces). To demonstrate this, we present SimPoE, a Simulation-based approach for 3D human Pose Estimation, which integrates image-based kinematic inference and physics-based dynamics modeling. SimPoE learns a policy that takes as input the current-frame pose estimate and the next image frame to control a physically-simulated character to output the next-frame pose estimate. The policy contains a learnable kinematic pose refinement unit that uses 2D keypoints to iteratively refine its kinematic pose estimate of the next frame. Based on this refined kinematic pose, the policy learns to compute dynamics-based control (e.g., joint torques) of the character to advance the current-frame pose estimate to the pose estimate of the next frame. This design couples the kinematic pose refinement unit with the dynamics-based control generation unit, which are learned jointly with reinforcement learning to achieve accurate and physically-plausible pose estimation. Furthermore, we propose a meta-control mechanism that dynamically adjusts the character's dynamics parameters based on the character state to attain more accurate pose estimates. Experiments on large-scale motion datasets demonstrate that our approach establishes the new state of the art in pose accuracy while ensuring physical plausibility.
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
Apr 01, 2021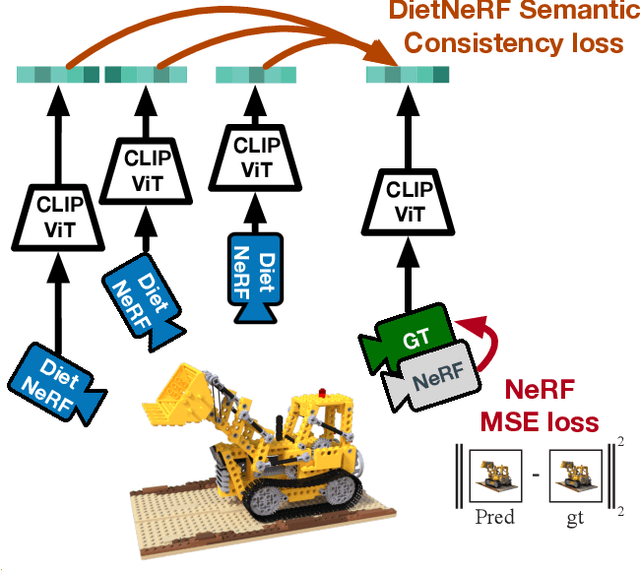
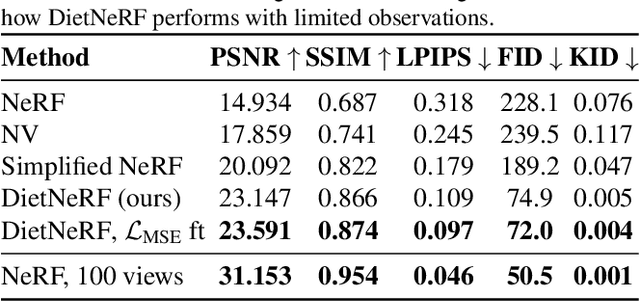

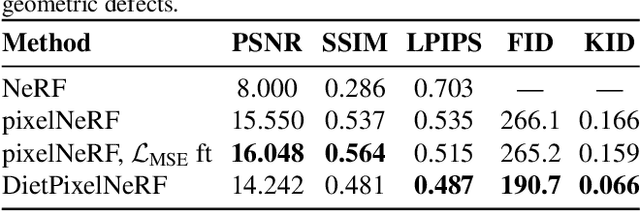
We present DietNeRF, a 3D neural scene representation estimated from a few images. Neural Radiance Fields (NeRF) learn a continuous volumetric representation of a scene through multi-view consistency, and can be rendered from novel viewpoints by ray casting. While NeRF has an impressive ability to reconstruct geometry and fine details given many images, up to 100 for challenging 360{\deg} scenes, it often finds a degenerate solution to its image reconstruction objective when only a few input views are available. To improve few-shot quality, we propose DietNeRF. We introduce an auxiliary semantic consistency loss that encourages realistic renderings at novel poses. DietNeRF is trained on individual scenes to (1) correctly render given input views from the same pose, and (2) match high-level semantic attributes across different, random poses. Our semantic loss allows us to supervise DietNeRF from arbitrary poses. We extract these semantics using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse single-view, 2D photographs mined from the web with natural language supervision. In experiments, DietNeRF improves the perceptual quality of few-shot view synthesis when learned from scratch, can render novel views with as few as one observed image when pre-trained on a multi-view dataset, and produces plausible completions of completely unobserved regions.
Measurement-Adaptive Sparse Image Sampling and Recovery
Nov 23, 2017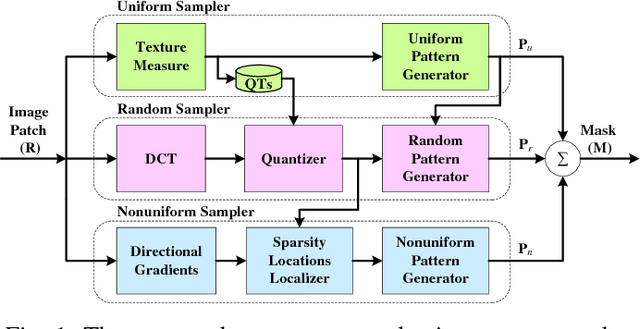
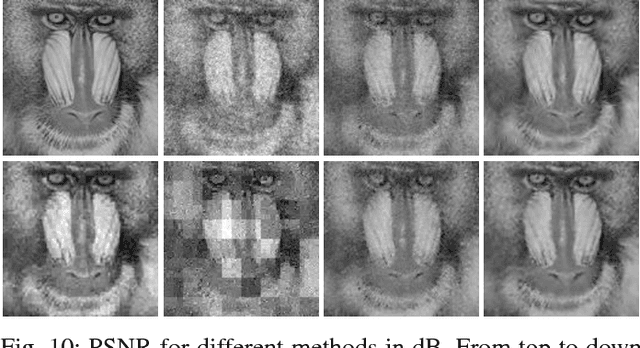
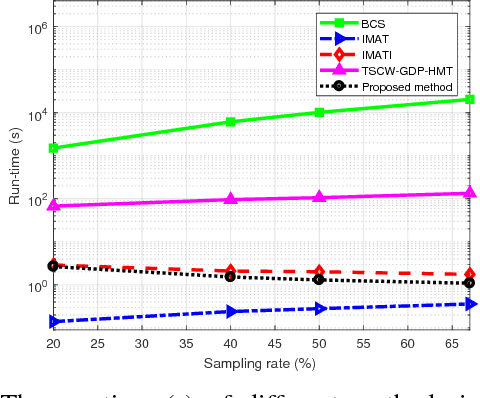

This paper presents an adaptive and intelligent sparse model for digital image sampling and recovery. In the proposed sampler, we adaptively determine the number of required samples for retrieving image based on space-frequency-gradient information content of image patches. By leveraging texture in space, sparsity locations in DCT domain, and directional decomposition of gradients, the sampler structure consists of a combination of uniform, random, and nonuniform sampling strategies. For reconstruction, we model the recovery problem as a two-state cellular automaton to iteratively restore image with scalable windows from generation to generation. We demonstrate the recovery algorithm quickly converges after a few generations for an image with arbitrary degree of texture. For a given number of measurements, extensive experiments on standard image-sets, infra-red, and mega-pixel range imaging devices show that the proposed measurement matrix considerably increases the overall recovery performance, or equivalently decreases the number of sampled pixels for a specific recovery quality compared to random sampling matrix and Gaussian linear combinations employed by the state-of-the-art compressive sensing methods. In practice, the proposed measurement-adaptive sampling/recovery framework includes various applications from intelligent compressive imaging-based acquisition devices to computer vision and graphics, and image processing technology. Simulation codes are available online for reproduction purposes.
On the Diversity of Realistic Image Synthesis
Dec 20, 2017


Many image processing tasks can be formulated as translating images between two image domains, such as colorization, super resolution and conditional image synthesis. In most of these tasks, an input image may correspond to multiple outputs. However, current existing approaches only show very minor diversity of the outputs. In this paper, we present a novel approach to synthesize diverse realistic images corresponding to a semantic layout. We introduce a diversity loss objective, which maximizes the distance between synthesized image pairs and links the input noise to the semantic segments in the synthesized images. Thus, our approach can not only produce diverse images, but also allow users to manipulate the output images by adjusting the noise manually. Experimental results show that images synthesized by our approach are significantly more diverse than that of the current existing works and equipping our diversity loss does not degrade the reality of the base networks.
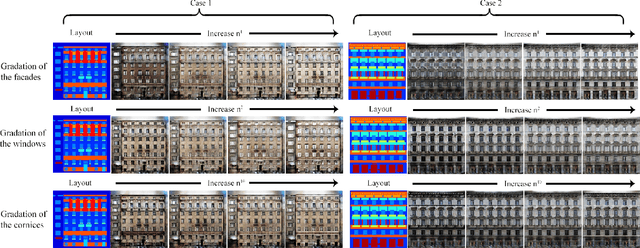
AGORA: Avatars in Geography Optimized for Regression Analysis
Apr 29, 2021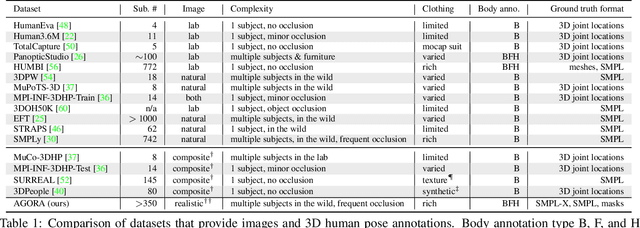
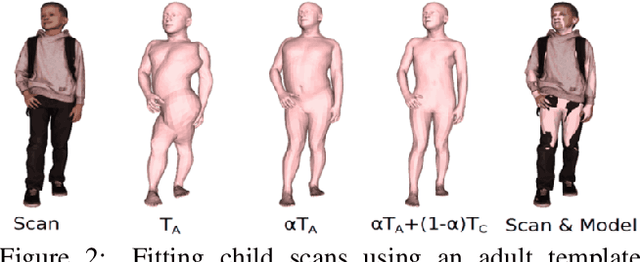
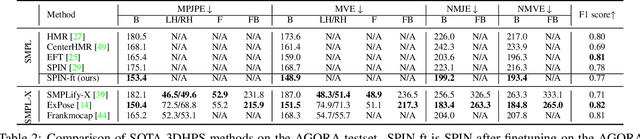
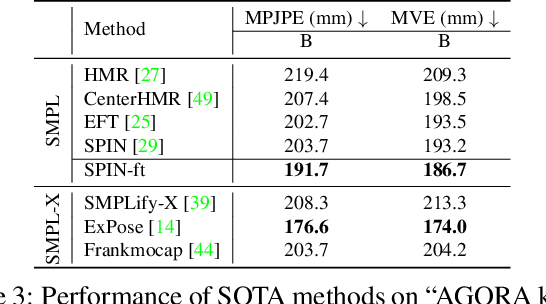
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To obtain ground-truth 3D pose, current datasets limit the complexity of clothing, environmental conditions, number of subjects, and occlusion. Moreover, current datasets evaluate sparse 3D joint locations corresponding to the major joints of the body, ignoring the hand pose and the face shape. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. Here we use 4240 commercially-available, high-quality, textured human scans in diverse poses and natural clothing; this includes 257 scans of children. We create reference 3D poses and body shapes by fitting the SMPL-X body model (with face and hands) to the 3D scans, taking into account clothing. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops. We evaluate existing state-of-the-art methods for 3D human pose estimation on this dataset and find that most methods perform poorly on images of children. Hence, we extend the SMPL-X model to better capture the shape of children. Additionally, we fine-tune methods on AGORA and show improved performance on both AGORA and 3DPW, confirming the realism of the dataset. We provide all the registered 3D reference training data, rendered images, and a web-based evaluation site at https://agora.is.tue.mpg.de/.
Full-reference image quality assessment-based B-mode ultrasound image similarity measure
Jan 17, 2017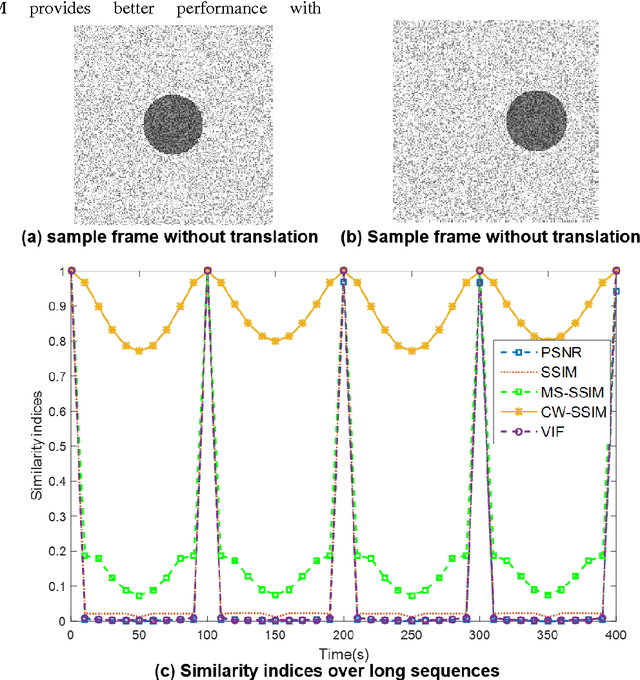
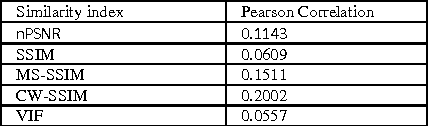
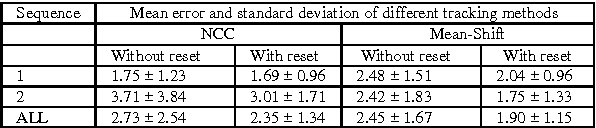
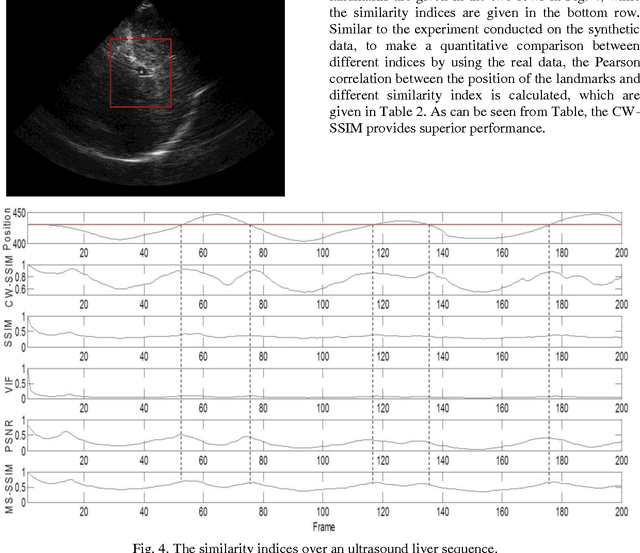
During the last decades, the number of new full-reference image quality assessment algorithms has been increasing drastically. Yet, despite of the remarkable progress that has been made, the medical ultrasound image similarity measurement remains largely unsolved due to a high level of speckle noise contamination. Potential applications of the ultrasound image similarity measurement seem evident in several aspects. To name a few, ultrasound imaging quality assessment, abnormal function region detection, etc. In this paper, a comparative study was made on full-reference image quality assessment methods for ultrasound image visual structural similarity measure. Moreover, based on the image similarity index, a generic ultrasound motion tracking re-initialization framework is given in this work. The experiments are conducted on synthetic data and real-ultrasound liver data and the results demonstrate that, with proposed similarity-based tracking re-initialization, the mean error of landmarks tracking can be decreased from 2 mm to about 1.5 mm in the ultrasound liver sequence.
Neural Mixture Models with Expectation-Maximization for End-to-end Deep Clustering
Jul 06, 2021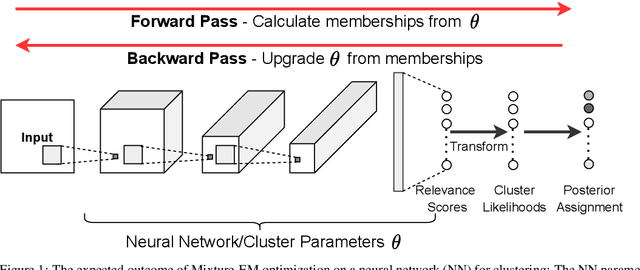

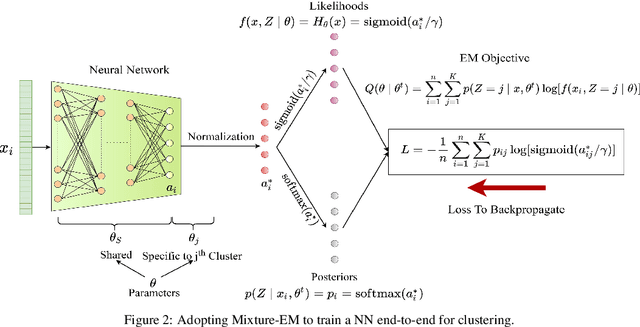

Any clustering algorithm must synchronously learn to model the clusters and allocate data to those clusters in the absence of labels. Mixture model-based methods model clusters with pre-defined statistical distributions and allocate data to those clusters based on the cluster likelihoods. They iteratively refine those distribution parameters and member assignments following the Expectation-Maximization (EM) algorithm. However, the cluster representability of such hand-designed distributions that employ a limited amount of parameters is not adequate for most real-world clustering tasks. In this paper, we realize mixture model-based clustering with a neural network where the final layer neurons, with the aid of an additional transformation, approximate cluster distribution outputs. The network parameters pose as the parameters of those distributions. The result is an elegant, much-generalized representation of clusters than a restricted mixture of hand-designed distributions. We train the network end-to-end via batch-wise EM iterations where the forward pass acts as the E-step and the backward pass acts as the M-step. In image clustering, the mixture-based EM objective can be used as the clustering objective along with existing representation learning methods. In particular, we show that when mixture-EM optimization is fused with consistency optimization, it improves the sole consistency optimization performance in clustering. Our trained networks outperform single-stage deep clustering methods that still depend on k-means, with unsupervised classification accuracy of 63.8% in STL10, 58% in CIFAR10, 25.9% in CIFAR100, and 98.9% in MNIST.
Segmentation with Multiple Acceptable Annotations: A Case Study of Myocardial Segmentation in Contrast Echocardiography
Jun 29, 2021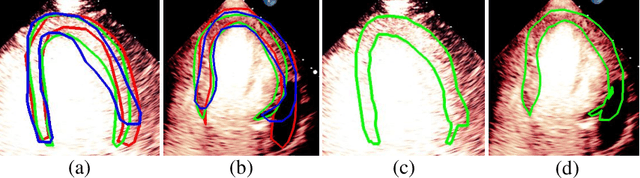
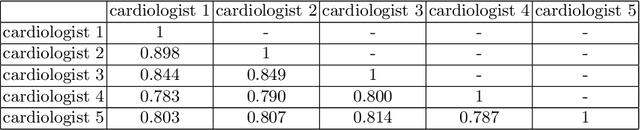
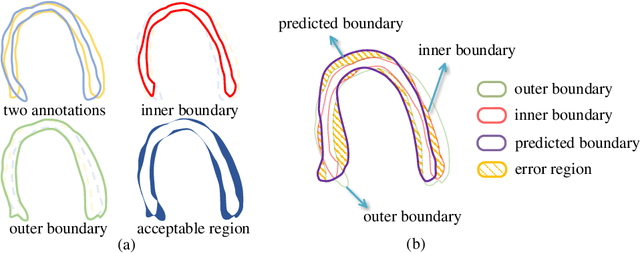
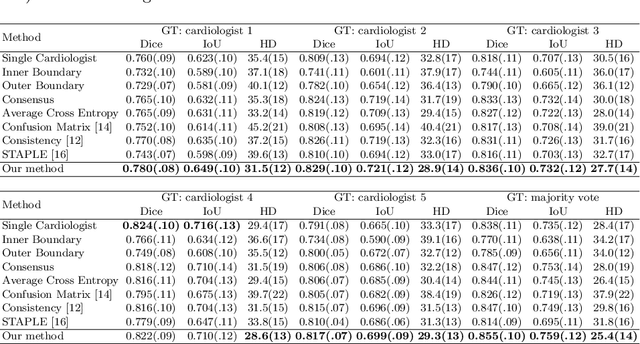
Most existing deep learning-based frameworks for image segmentation assume that a unique ground truth is known and can be used for performance evaluation. This is true for many applications, but not all. Myocardial segmentation of Myocardial Contrast Echocardiography (MCE), a critical task in automatic myocardial perfusion analysis, is an example. Due to the low resolution and serious artifacts in MCE data, annotations from different cardiologists can vary significantly, and it is hard to tell which one is the best. In this case, how can we find a good way to evaluate segmentation performance and how do we train the neural network? In this paper, we address the first problem by proposing a new extended Dice to effectively evaluate the segmentation performance when multiple accepted ground truth is available. Then based on our proposed metric, we solve the second problem by further incorporating the new metric into a loss function that enables neural networks to flexibly learn general features of myocardium. Experiment results on our clinical MCE data set demonstrate that the neural network trained with the proposed loss function outperforms those existing ones that try to obtain a unique ground truth from multiple annotations, both quantitatively and qualitatively. Finally, our grading study shows that using extended Dice as an evaluation metric can better identify segmentation results that need manual correction compared with using Dice.
Analysis of Information Flow Through U-Nets
Jan 21, 2021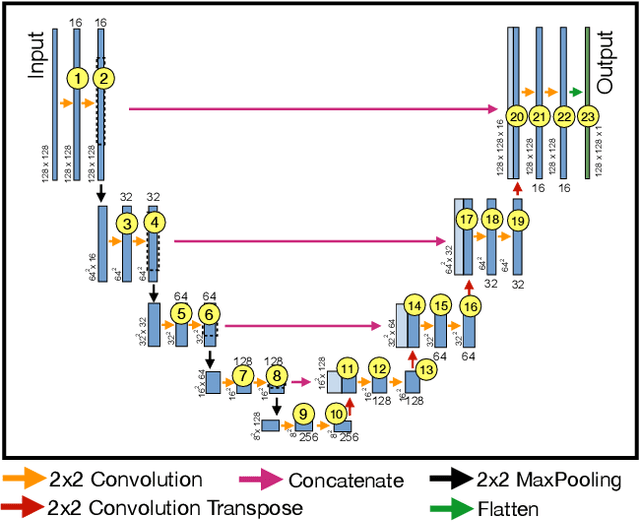

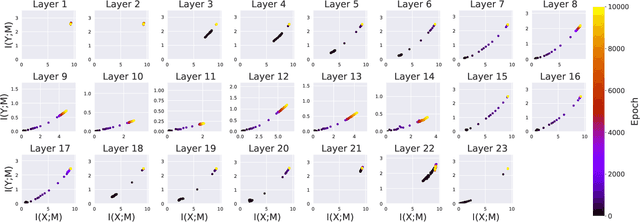
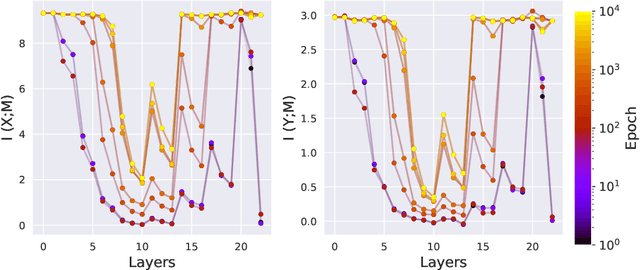
Deep Neural Networks (DNNs) have become ubiquitous in medical image processing and analysis. Among them, U-Nets are very popular in various image segmentation tasks. Yet, little is known about how information flows through these networks and whether they are indeed properly designed for the tasks they are being proposed for. In this paper, we employ information-theoretic tools in order to gain insight into information flow through U-Nets. In particular, we show how mutual information between input/output and an intermediate layer can be a useful tool to understand information flow through various portions of a U-Net, assess its architectural efficiency, and even propose more efficient designs.