 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Multimodal Opinion Summarization
May 27, 2021
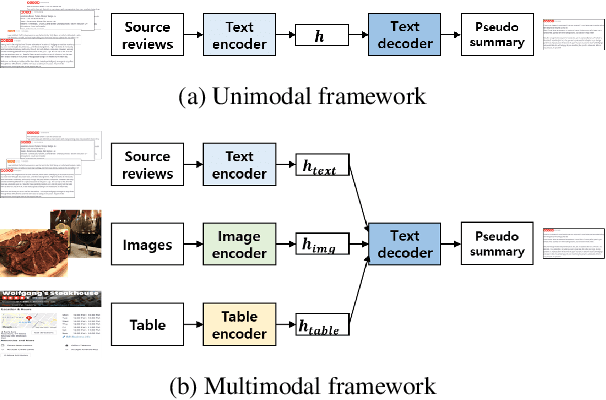
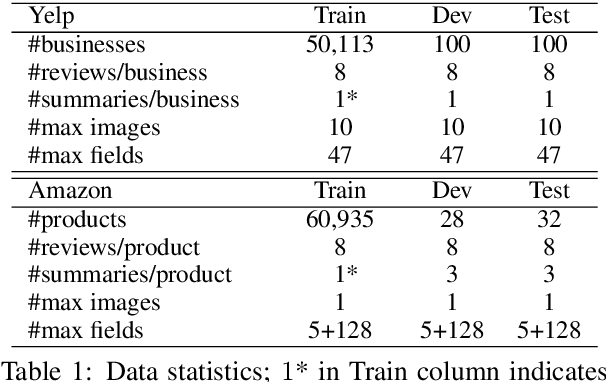
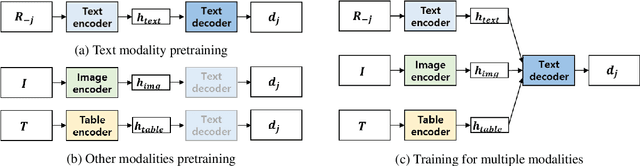
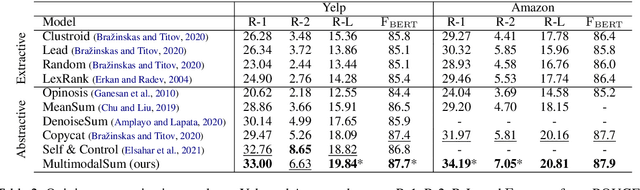
Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder--decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
Preclinical Stage Alzheimer's Disease Detection Using Magnetic Resonance Image Scans
Nov 28, 2020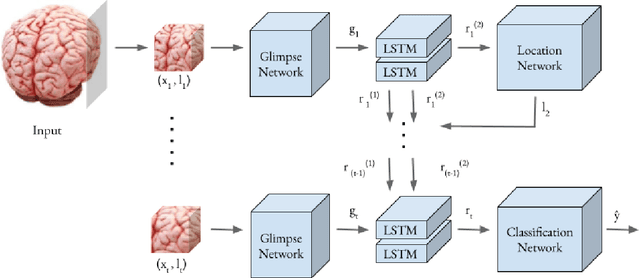
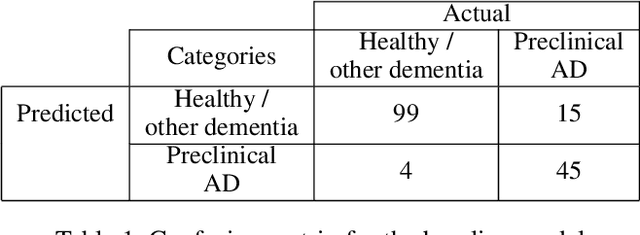
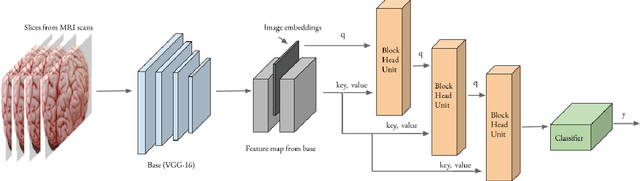

Alzheimer's disease is one of the diseases that mostly affects older people without being a part of aging. The most common symptoms include problems with communicating and abstract thinking, as well as disorientation. It is important to detect Alzheimer's disease in early stages so that cognitive functioning would be improved by medication and training. In this paper, we propose two attention model networks for detecting Alzheimer's disease from MRI images to help early detection efforts at the preclinical stage. We also compare the performance of these two attention network models with a baseline model. Recently available OASIS-3 Longitudinal Neuroimaging, Clinical, and Cognitive Dataset is used to train, evaluate and compare our models. The novelty of this research resides in the fact that we aim to detect Alzheimer's disease when all the parameters, physical assessments, and clinical data state that the patient is healthy and showing no symptoms
Reducing bias and increasing utility by federated generative modeling of medical images using a centralized adversary
Jan 18, 2021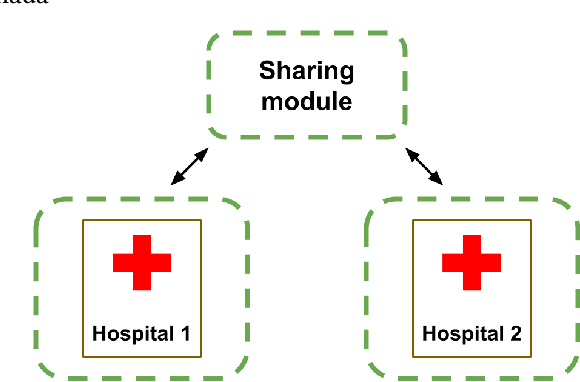
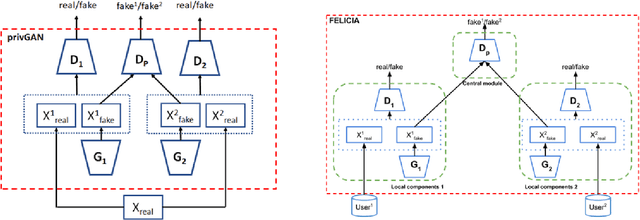
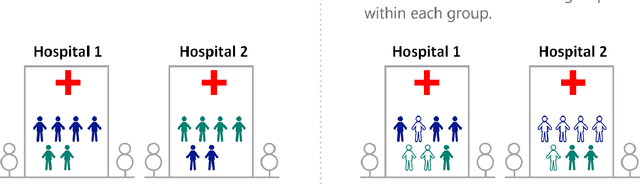
We introduce FELICIA (FEderated LearnIng with a CentralIzed Adversary) a generative mechanism enabling collaborative learning. In particular, we show how a data owner with limited and biased data could benefit from other data owners while keeping data from all the sources private. This is a common scenario in medical image analysis where privacy legislation prevents data from being shared outside local premises. FELICIA works for a large family of Generative Adversarial Networks (GAN) architectures including vanilla and conditional GANs as demonstrated in this work. We show that by using the FELICIA mechanism, a data owner with limited image samples can generate high-quality synthetic images with high utility while neither data owners has to provide access to its data. The sharing happens solely through a central discriminator that has access limited to synthetic data. Here, utility is defined as classification performance on a real test set. We demonstrate these benefits on several realistic healthcare scenarions using benchmark image datasets (MNIST, CIFAR-10) as well as on medical images for the task of skin lesion classification. With multiple experiments, we show that even in the worst cases, combining FELICIA with real data gracefully achieves performance on par with real data while most results significantly improves the utility.
A New Approach for Automatic Segmentation and Evaluation of Pigmentation Lesion by using Active Contour Model and Speeded Up Robust Features
Jan 18, 2021
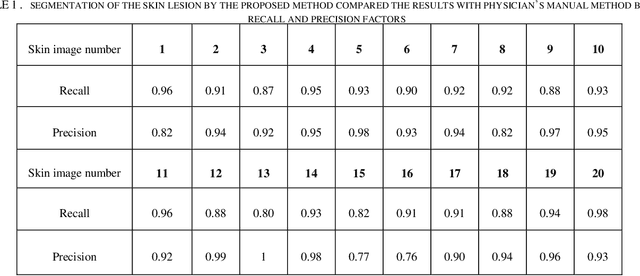
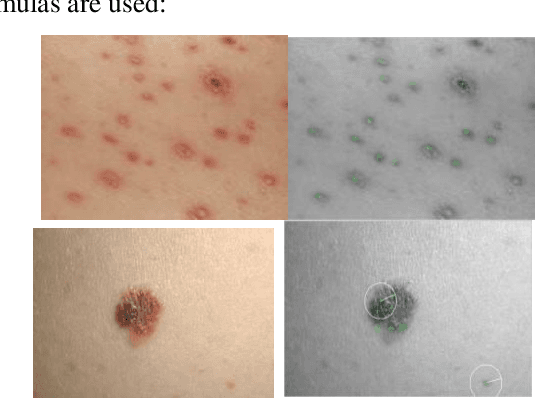
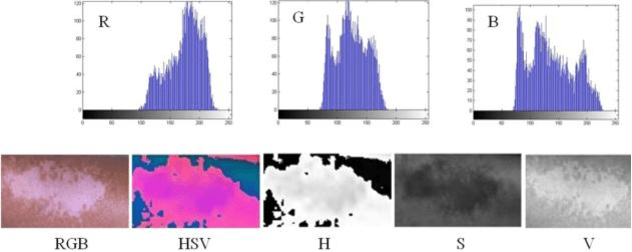
Digital image processing techniques have wide applications in different scientific fields including the medicine. By use of image processing algorithms, physicians have been more successful in diagnosis of different diseases and have achieved much better treatment results. In this paper, we propose an automatic method for segmenting the skin lesions and extracting features that are associated to them. At this aim, a combination of Speeded-Up Robust Features (SURF) and Active Contour Model (ACM), is used. In the suggested method, at first region of skin lesion is segmented from the whole skin image, and then some features like the mean, variance, RGB and HSV parameters are extracted from the segmented region. Comparing the segmentation results, by use of Otsu thresholding, our proposed method, shows the superiority of our procedure over the Otsu theresholding method. Segmentation of the skin lesion by the proposed method and Otsu thresholding compared the results with physician's manual method. The proposed method for skin lesion segmentation, which is a combination of SURF and ACM, gives the best result. For empirical evaluation of our method, we have applied it on twenty different skin lesion images. Obtained results confirm the high performance, speed and accuracy of our method.
Mutual Contrastive Learning for Visual Representation Learning
Apr 26, 2021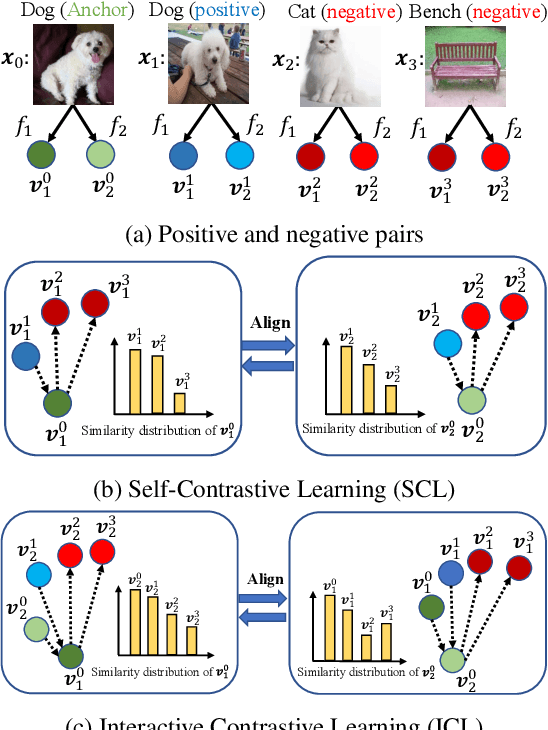
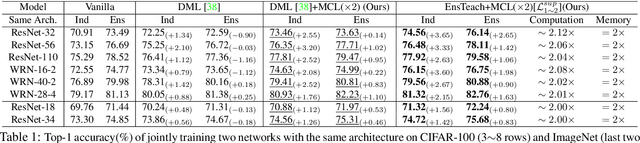
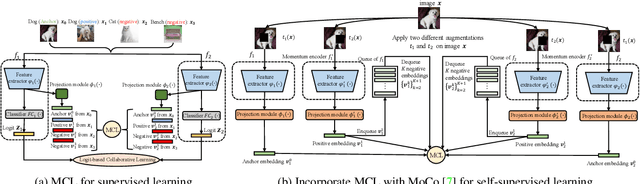
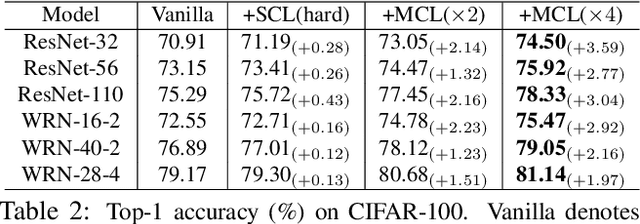
We present a collaborative learning method called Mutual Contrastive Learning (MCL) for general visual representation learning. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of models. Benefiting from MCL, each model can learn extra contrastive knowledge from others, leading to more meaningful feature representations for visual recognition tasks. We emphasize that MCL is conceptually simple yet empirically powerful. It is a generic framework that can be applied to both supervised and self-supervised representation learning. Experimental results on supervised and self-supervised image classification, transfer learning and few-shot learning show that MCL can lead to consistent performance gains, demonstrating that MCL can guide the network to generate better feature representations.
A Hybrid Approach Between Adversarial Generative Networks and Actor-Critic Policy Gradient for Low Rate High-Resolution Image Compression
Jun 13, 2019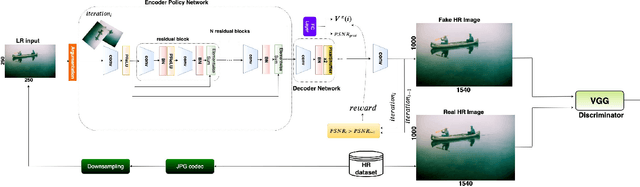
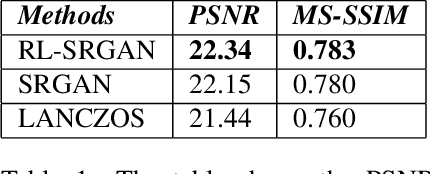

Image compression is an essential approach for decreasing the size in bytes of the image without deteriorating the quality of it. Typically, classic algorithms are used but recently deep-learning has been successfully applied. In this work, is presented a deep super-resolution work-flow for image compression that maps low-resolution JPEG image to the high-resolution. The pipeline consists of two components: first, an encoder-decoder neural network learns how to transform the downsampling JPEG images to high resolution. Second, a combination between Generative Adversarial Networks (GANs) and reinforcement learning Actor-Critic (A3C) loss pushes the encoder-decoder to indirectly maximize High Peak Signal-to-Noise Ratio (PSNR). Although PSNR is a fully differentiable metric, this work opens the doors to new solutions for maximizing non-differential metrics through an end-to-end approach between encoder-decoder networks and reinforcement learning policy gradient methods.
Unsupervised 3D End-to-End Medical Image Registration with Volume Tweening Network
Feb 13, 2019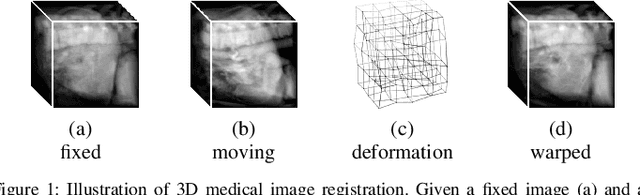
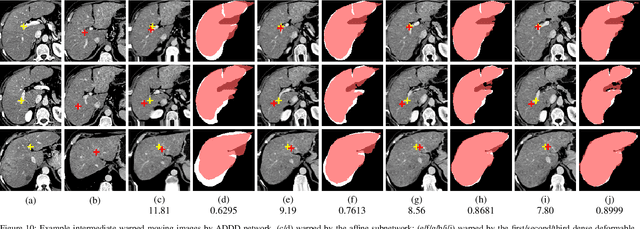
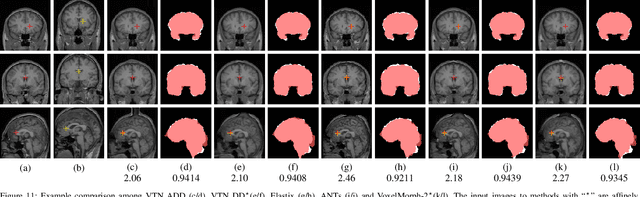
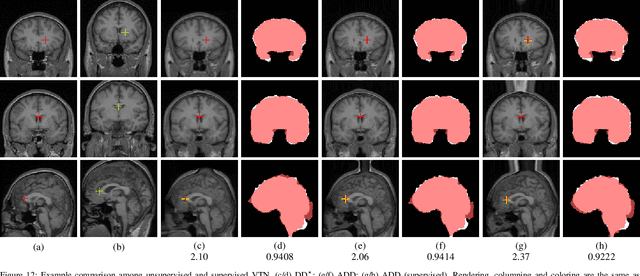
3D medical image registration is of great clinical importance. However, supervised learning methods require a large amount of accurately annotated corresponding control points (or morphing). The ground truth for 3D medical images is very difficult to obtain. Unsupervised learning methods ease the burden of manual annotation by exploiting unlabeled data without supervision. In this paper, we propose a new unsupervised learning method using convolutional neural networks under an end-to-end framework, Volume Tweening Network (VTN), to register 3D medical images. Three technical components ameliorate our unsupervised learning system for 3D end-to-end medical image registration: (1) We cascade the registration subnetworks; (2) We integrate affine registration into our network; and (3) We incorporate an additional invertibility loss into the training process. Experimental results demonstrate that our algorithm is 880x faster (or 3.3x faster without GPU acceleration) than traditional optimization-based methods and achieves state-of-the-art performance in medical image registration.
FD-GAN: Face-demorphing generative adversarial network for restoring accomplice's facial image
Nov 19, 2018
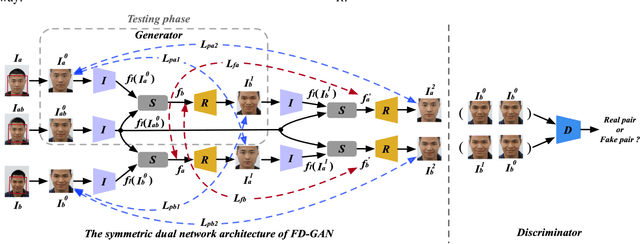
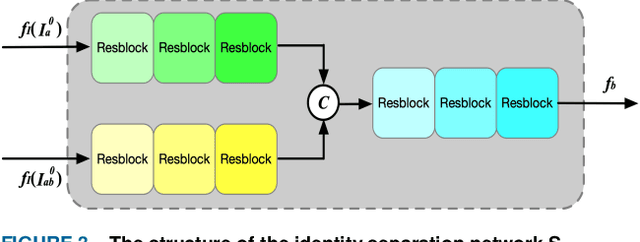

Face morphing attack is proved to be a serious threat to the existing face recognition systems. Although a few face morphing detection methods have been put forward, the face morphing accomplice's facial restoration remains a challenging problem. In this paper, a face-demorphing generative adversarial network (FD-GAN) is proposed to restore the accomplice's facial image. It utilizes a symmetric dual network architecture and two levels of restoration losses to separate the identity feature of the morphing accomplice. By exploiting the captured face image (containing the criminal's identity) from the face recognition system and the morphed image stored in the e-passport system (containing both criminal and accomplice's identities), the FD-GAN can effectively restore the accomplice's facial image. Experimental results and analysis demonstrate the effectiveness of the proposed scheme. It has great potential to be implemented for detecting the face morphing accomplice in a real identity verification scenario.
Brain over Brawn -- Using a Stereo Camera to Detect, Track and Intercept a Faster UAV by Reconstructing Its Trajectory
Jul 02, 2021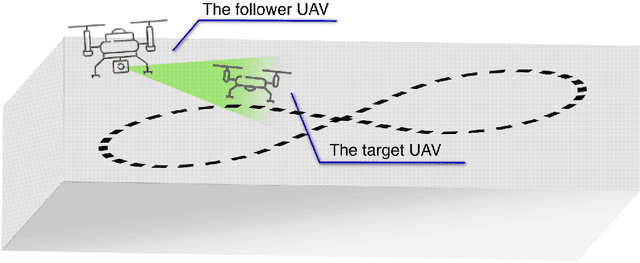
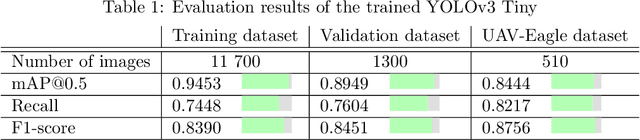

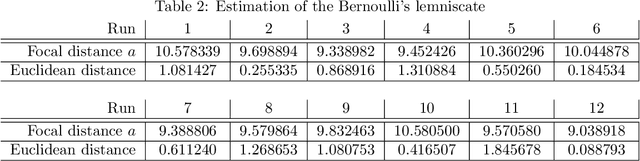
The work presented in this paper demonstrates our approach to intercepting a faster intruder UAV, inspired by the MBZIRC2020 Challenge 1. By leveraging the knowledge of the shape of the intruder's trajectory we are able to calculate the interception point. Target tracking is based on image processing by a YOLOv3 Tiny convolutional neural network, combined with depth calculation using a gimbal-mounted ZED Mini stereo camera. We use RGB and depth data from ZED Mini to extract the 3D position of the target, for which we devise a histogram-of-depth based processing to reduce noise. Obtained 3D measurements of target's position are used to calculate the position, the orientation and the size of a figure-eight shaped trajectory, which we approximate using lemniscate of Bernoulli. Once the approximation is deemed sufficiently precise, measured by Hausdorff distance between measurements and the approximation, an interception point is calculated to position the intercepting UAV right on the path of the target. The proposed method, which has been significantly improved based on the experience gathered during the MBZIRC competition, has been validated in simulation and through field experiments. The results confirmed that an efficient visual perception module which extracts information related to the motion of the target UAV as a basis for the interception, has been developed. The system is able to track and intercept the target which is 30% faster than the interceptor in majority of simulation experiments. Tests in the unstructured environment yielded 9 out of 12 successful results.
Visual Navigation with Spatial Attention
Apr 20, 2021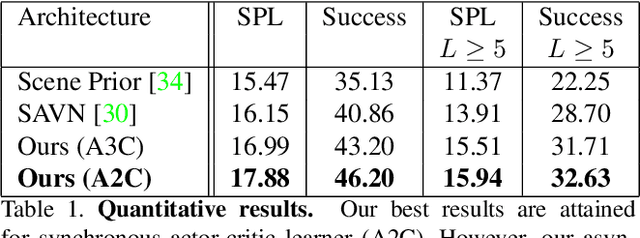
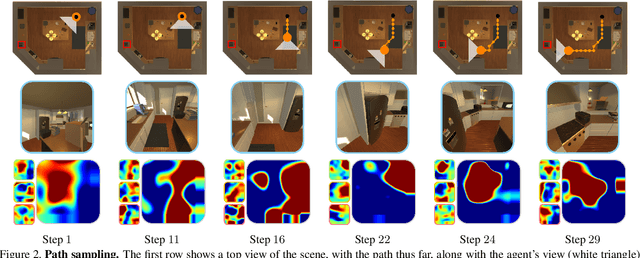
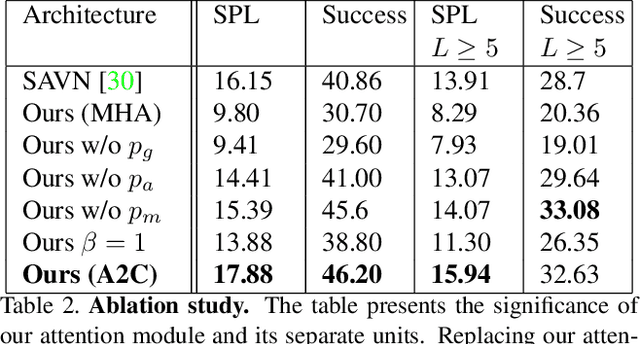
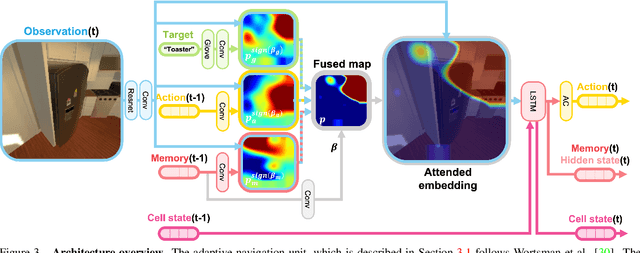
This work focuses on object goal visual navigation, aiming at finding the location of an object from a given class, where in each step the agent is provided with an egocentric RGB image of the scene. We propose to learn the agent's policy using a reinforcement learning algorithm. Our key contribution is a novel attention probability model for visual navigation tasks. This attention encodes semantic information about observed objects, as well as spatial information about their place. This combination of the "what" and the "where" allows the agent to navigate toward the sought-after object effectively. The attention model is shown to improve the agent's policy and to achieve state-of-the-art results on commonly-used datasets.