 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Class-Aware Robust Adversarial Training for Object Detection
Mar 31, 2021
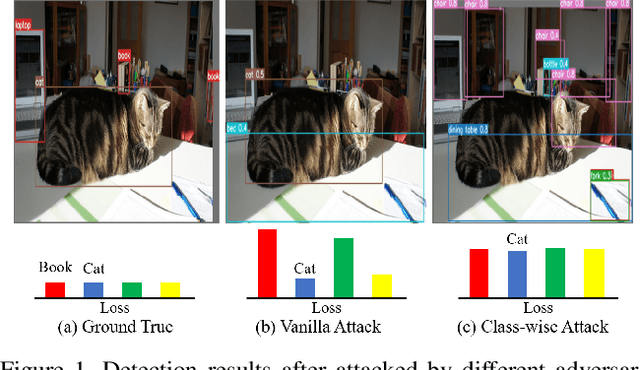
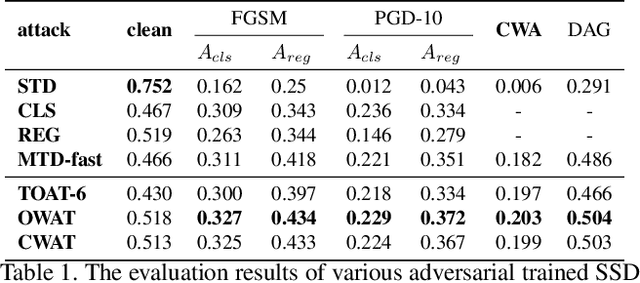
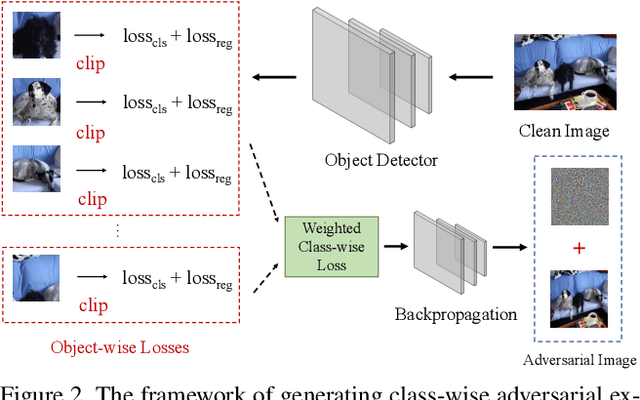
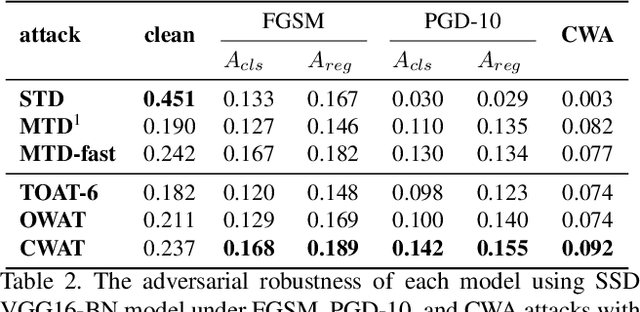
Object detection is an important computer vision task with plenty of real-world applications; therefore, how to enhance its robustness against adversarial attacks has emerged as a crucial issue. However, most of the previous defense methods focused on the classification task and had few analysis in the context of the object detection task. In this work, to address the issue, we present a novel class-aware robust adversarial training paradigm for the object detection task. For a given image, the proposed approach generates an universal adversarial perturbation to simultaneously attack all the occurred objects in the image through jointly maximizing the respective loss for each object. Meanwhile, instead of normalizing the total loss with the number of objects, the proposed approach decomposes the total loss into class-wise losses and normalizes each class loss using the number of objects for the class. The adversarial training based on the class weighted loss can not only balances the influence of each class but also effectively and evenly improves the adversarial robustness of trained models for all the object classes as compared with the previous defense methods. Furthermore, with the recent development of fast adversarial training, we provide a fast version of the proposed algorithm which can be trained faster than the traditional adversarial training while keeping comparable performance. With extensive experiments on the challenging PASCAL-VOC and MS-COCO datasets, the evaluation results demonstrate that the proposed defense methods can effectively enhance the robustness of the object detection models.
Between-class Learning for Image Classification
Apr 08, 2018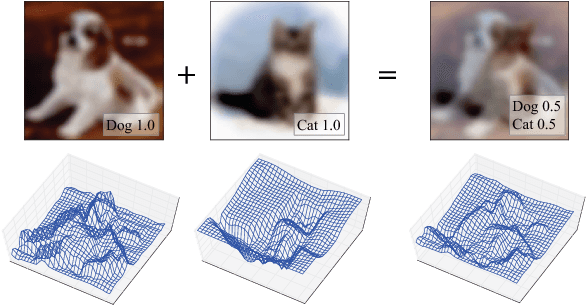
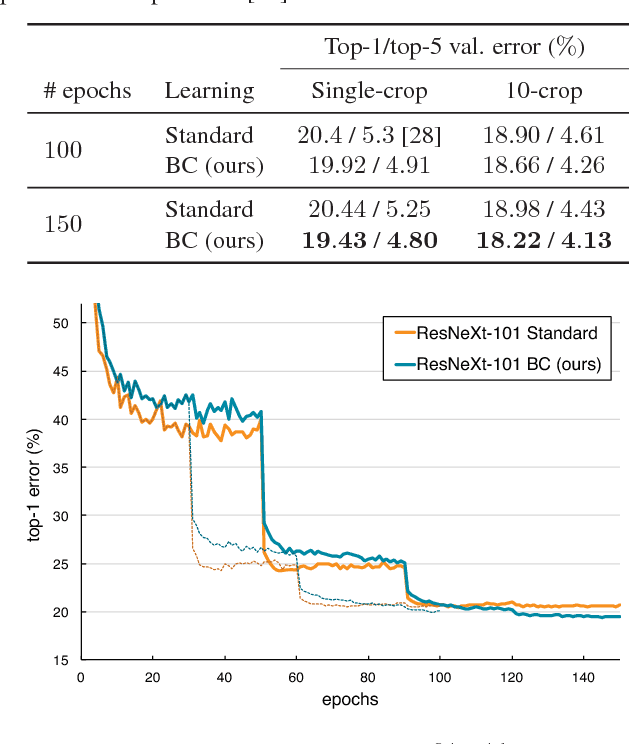
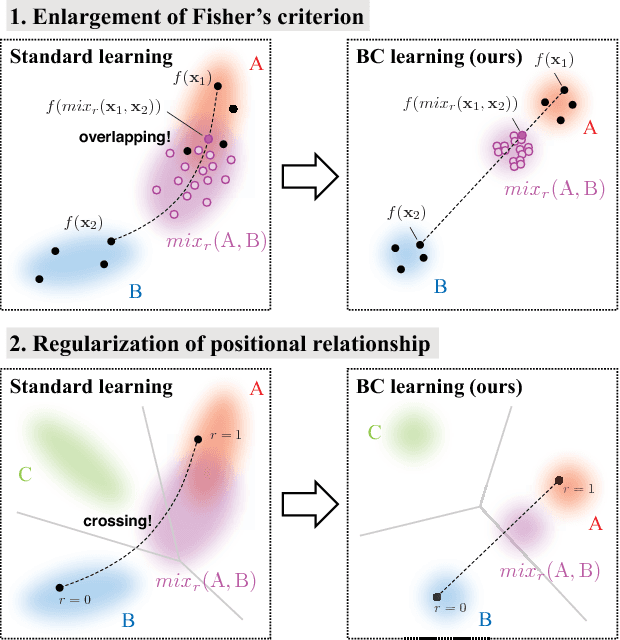
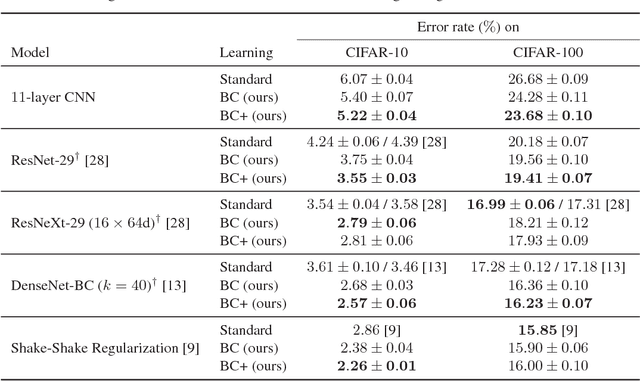
In this paper, we propose a novel learning method for image classification called Between-Class learning (BC learning). We generate between-class images by mixing two images belonging to different classes with a random ratio. We then input the mixed image to the model and train the model to output the mixing ratio. BC learning has the ability to impose constraints on the shape of the feature distributions, and thus the generalization ability is improved. BC learning is originally a method developed for sounds, which can be digitally mixed. Mixing two image data does not appear to make sense; however, we argue that because convolutional neural networks have an aspect of treating input data as waveforms, what works on sounds must also work on images. First, we propose a simple mixing method using internal divisions, which surprisingly proves to significantly improve performance. Second, we propose a mixing method that treats the images as waveforms, which leads to a further improvement in performance. As a result, we achieved 19.4% and 2.26% top-1 errors on ImageNet-1K and CIFAR-10, respectively.
Representation and Correlation Enhanced Encoder-Decoder Framework for Scene Text Recognition
Jun 13, 2021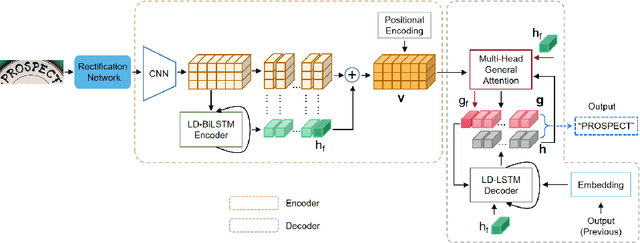
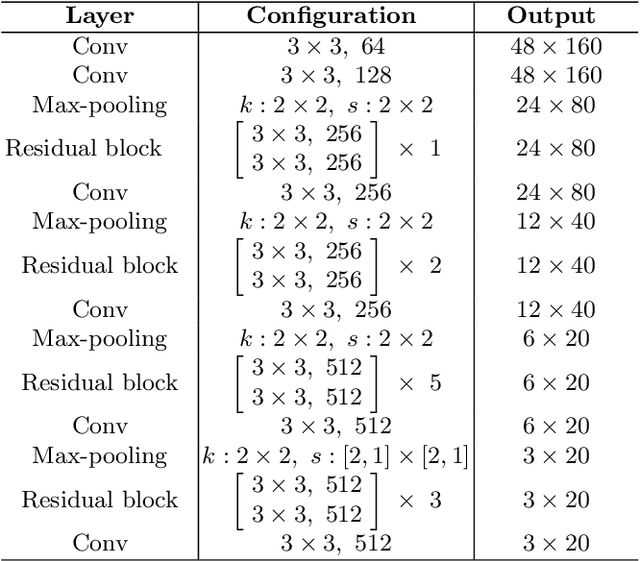

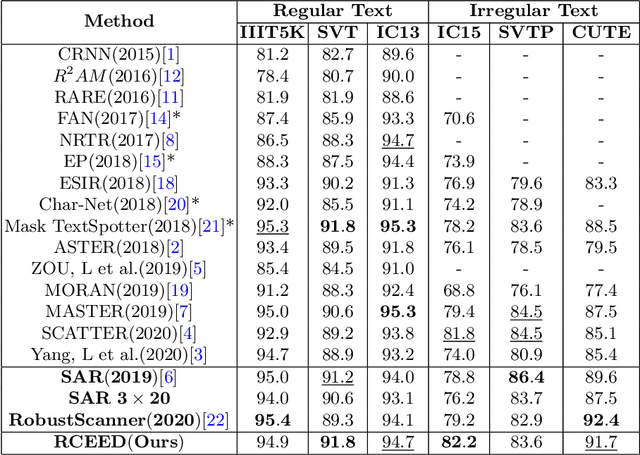
Attention-based encoder-decoder framework is widely used in the scene text recognition task. However, for the current state-of-the-art(SOTA) methods, there is room for improvement in terms of the efficient usage of local visual and global context information of the input text image, as well as the robust correlation between the scene processing module(encoder) and the text processing module(decoder). In this paper, we propose a Representation and Correlation Enhanced Encoder-Decoder Framework(RCEED) to address these deficiencies and break performance bottleneck. In the encoder module, local visual feature, global context feature, and position information are aligned and fused to generate a small-size comprehensive feature map. In the decoder module, two methods are utilized to enhance the correlation between scene and text feature space. 1) The decoder initialization is guided by the holistic feature and global glimpse vector exported from the encoder. 2) The feature enriched glimpse vector produced by the Multi-Head General Attention is used to assist the RNN iteration and the character prediction at each time step. Meanwhile, we also design a Layernorm-Dropout LSTM cell to improve model's generalization towards changeable texts. Extensive experiments on the benchmarks demonstrate the advantageous performance of RCEED in scene text recognition tasks, especially the irregular ones.
Do Not Escape From the Manifold: Discovering the Local Coordinates on the Latent Space of GANs
Jun 13, 2021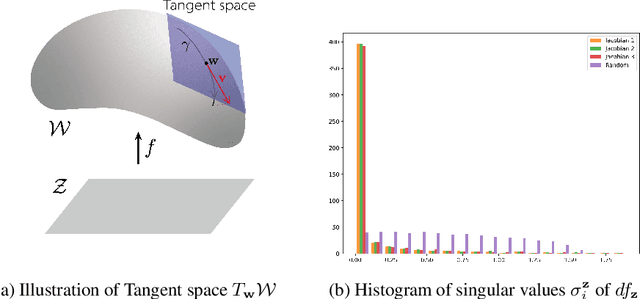



In this paper, we propose a method to find local-geometry-aware traversal directions on the intermediate latent space of Generative Adversarial Networks (GANs). These directions are defined as an ordered basis of tangent space at a latent code. Motivated by the intrinsic sparsity of the latent space, the basis is discovered by solving the low-rank approximation problem of the differential of the partial network. Moreover, the local traversal basis leads to a natural iterative traversal on the latent space. Iterative Curve-Traversal shows stable traversal on images, since the trajectory of latent code stays close to the latent space even under the strong perturbations compared to the linear traversal. This stability provides far more diverse variations of the given image. Although the proposed method can be applied to various GAN models, we focus on the W-space of the StyleGAN2, which is renowned for showing the better disentanglement of the latent factors of variation. Our quantitative and qualitative analysis provides evidence showing that the W-space is still globally warped while showing a certain degree of global consistency of interpretable variation. In particular, we introduce some metrics on the Grassmannian manifolds to quantify the global warpage of the W-space and the subspace traversal to test the stability of traversal directions.
Deep Learning Methods for Event Verification and Image Repurposing Detection
Feb 11, 2019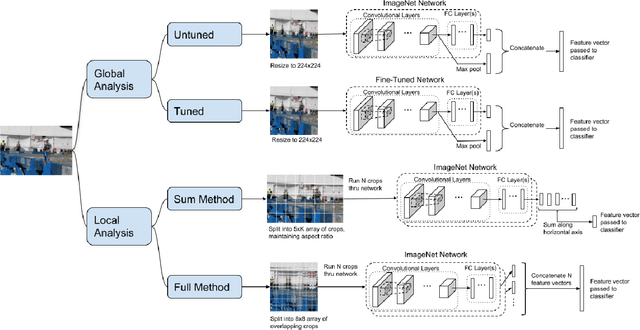


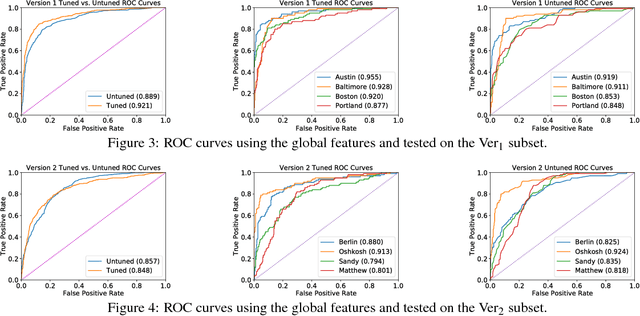
The authenticity of images posted on social media is an issue of growing concern. Many algorithms have been developed to detect manipulated images, but few have investigated the ability of deep neural network based approaches to verify the authenticity of image labels, such as event names. In this paper, we propose several novel methods to predict if an image was captured at one of several noteworthy events. We use a set of images from several recorded events such as storms, marathons, protests, and other large public gatherings. Two strategies of applying pre-trained Imagenet network for event verification are presented, with two modifications for each strategy. The first method uses the features from the last convolutional layer of a pre-trained network as input to a classifier. We also consider the effects of tuning the convolutional weights of the pre-trained network to improve classification. The second method combines many features extracted from smaller scales and uses the output of a pre-trained network as the input to a second classifier. For both methods, we investigated several different classifiers and tested many different pre-trained networks. Our experiments demonstrate both these approaches are effective for event verification and image re-purposing detection. The classification at the global scale tends to marginally outperform our tested local methods and fine tuning the network further improves the results.
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Jun 20, 2021
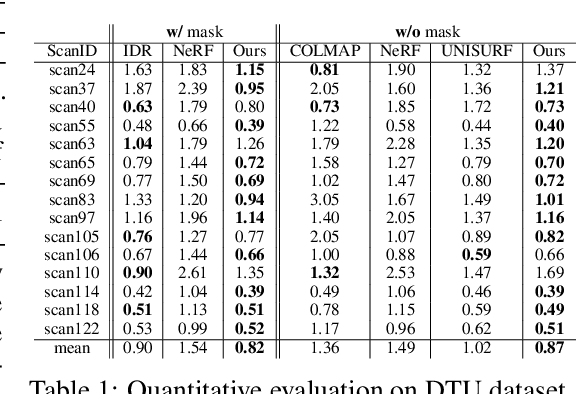
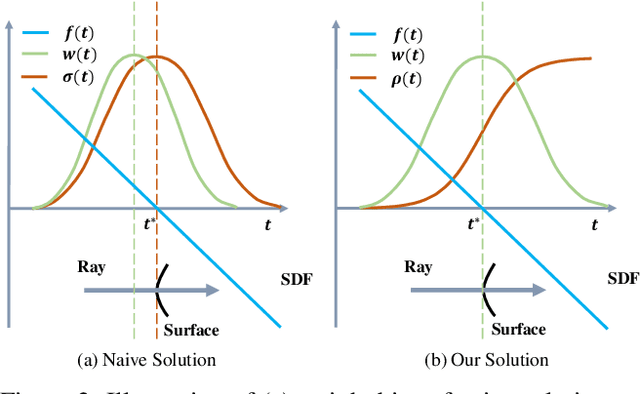
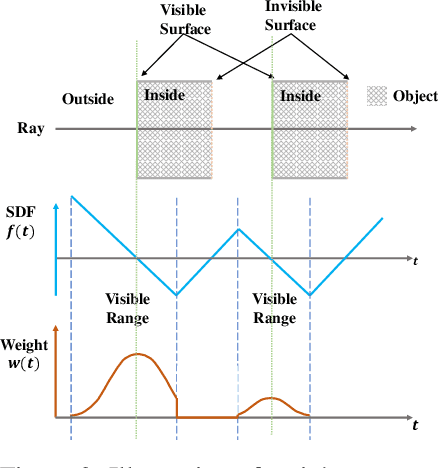
We present a novel neural surface reconstruction method, called NeuS, for reconstructing objects and scenes with high fidelity from 2D image inputs. Existing neural surface reconstruction approaches, such as DVR and IDR, require foreground mask as supervision, easily get trapped in local minima, and therefore struggle with the reconstruction of objects with severe self-occlusion or thin structures. Meanwhile, recent neural methods for novel view synthesis, such as NeRF and its variants, use volume rendering to produce a neural scene representation with robustness of optimization, even for highly complex objects. However, extracting high-quality surfaces from this learned implicit representation is difficult because there are not sufficient surface constraints in the representation. In NeuS, we propose to represent a surface as the zero-level set of a signed distance function (SDF) and develop a new volume rendering method to train a neural SDF representation. We observe that the conventional volume rendering method causes inherent geometric errors (i.e. bias) for surface reconstruction, and therefore propose a new formulation that is free of bias in the first order of approximation, thus leading to more accurate surface reconstruction even without the mask supervision. Experiments on the DTU dataset and the BlendedMVS dataset show that NeuS outperforms the state-of-the-arts in high-quality surface reconstruction, especially for objects and scenes with complex structures and self-occlusion.
A comparative study of semi- and self-supervised semantic segmentation of biomedical microscopy data
Nov 11, 2020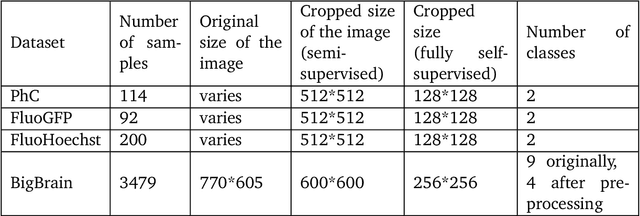
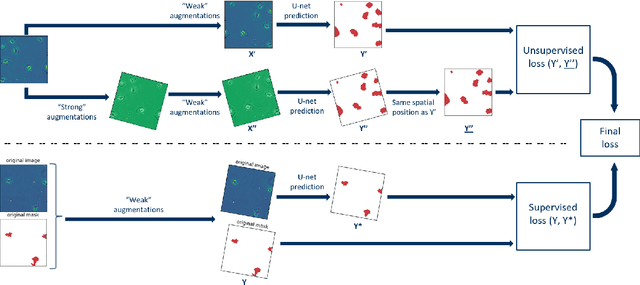

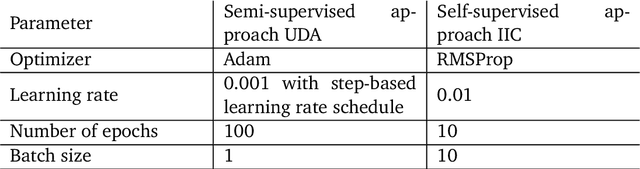
In recent years, Convolutional Neural Networks (CNNs) have become the state-of-the-art method for biomedical image analysis. However, these networks are usually trained in a supervised manner, requiring large amounts of labelled training data. These labelled data sets are often difficult to acquire in the biomedical domain. In this work, we validate alternative ways to train CNNs with fewer labels for biomedical image segmentation using. We adapt two semi- and self-supervised image classification methods and analyse their performance for semantic segmentation of biomedical microscopy images.
Grid Cell Path Integration For Movement-Based Visual Object Recognition
Feb 17, 2021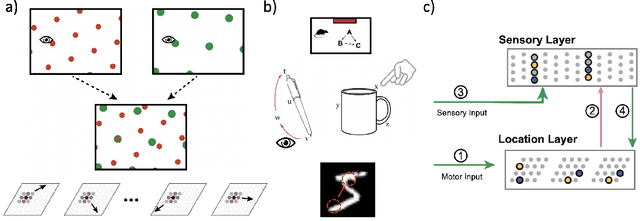
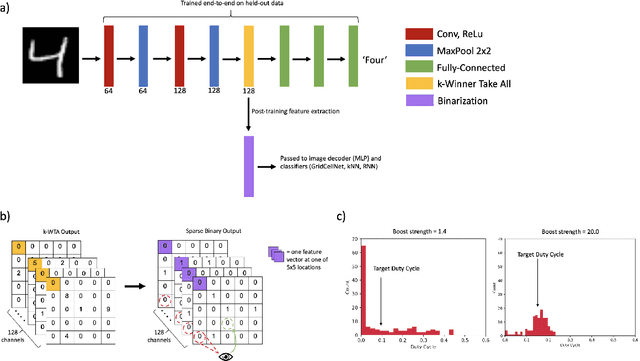
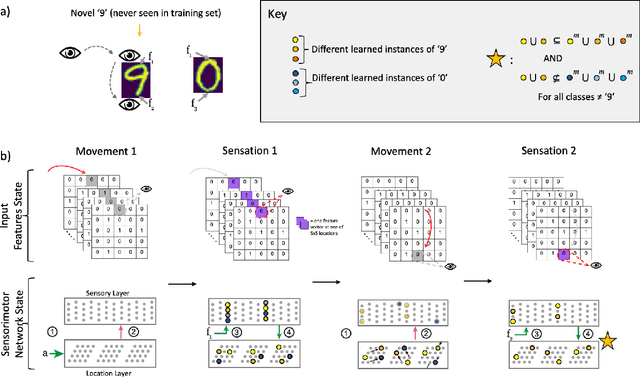
Grid cells enable the brain to model the physical space of the world and navigate effectively via path integration, updating self-position using information from self-movement. Recent proposals suggest that the brain might use similar mechanisms to understand the structure of objects in diverse sensory modalities, including vision. In machine vision, object recognition given a sequence of sensory samples of an image, such as saccades, is a challenging problem when the sequence does not follow a consistent, fixed pattern - yet this is something humans do naturally and effortlessly. We explore how grid cell-based path integration in a cortical network can support reliable recognition of objects given an arbitrary sequence of inputs. Our network (GridCellNet) uses grid cell computations to integrate visual information and make predictions based on movements. We use local Hebbian plasticity rules to learn rapidly from a handful of examples (few-shot learning), and consider the task of recognizing MNIST digits given only a sequence of image feature patches. We compare GridCellNet to k-Nearest Neighbour (k-NN) classifiers as well as recurrent neural networks (RNNs), both of which lack explicit mechanisms for handling arbitrary sequences of input samples. We show that GridCellNet can reliably perform classification, generalizing to both unseen examples and completely novel sequence trajectories. We further show that inference is often successful after sampling a fraction of the input space, enabling the predictive GridCellNet to reconstruct the rest of the image given just a few movements. We propose that dynamically moving agents with active sensors can use grid cell representations not only for navigation, but also for efficient recognition and feature prediction of seen objects.
Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
Sep 24, 2018
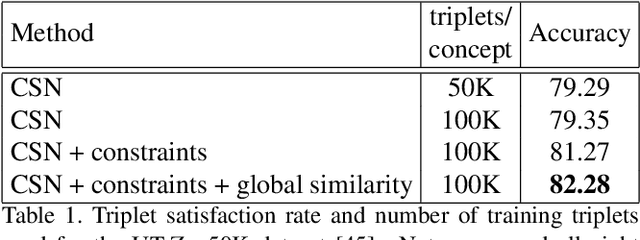
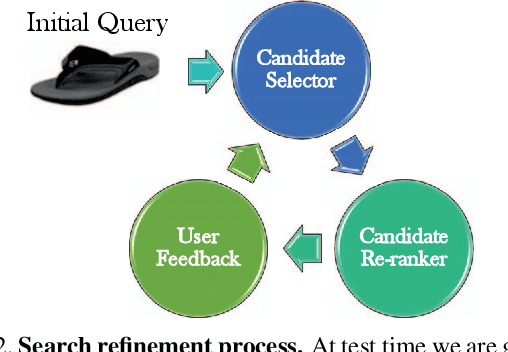
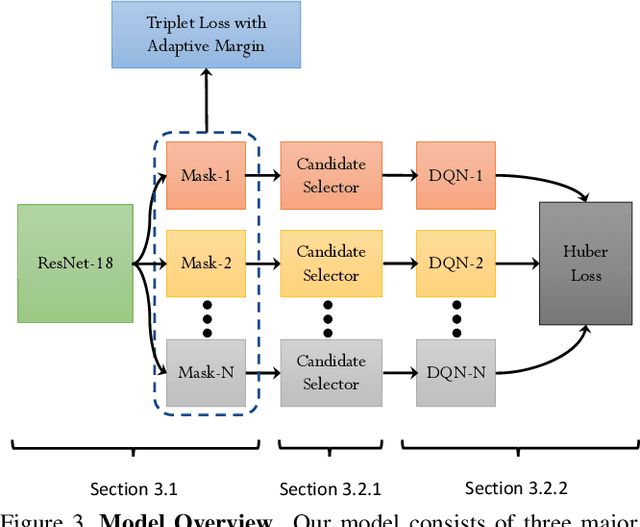
In this paper, we introduce an attribute-based interactive image search which can leverage human-in-the-loop feedback to iteratively refine image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used by prior work which are not typically found in many datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to learn what images are informative rather than rely on hand-crafted measures typically leveraged in prior work. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in more natural transitions as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach, producing compelling results on both active image search and image attribute representation tasks.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021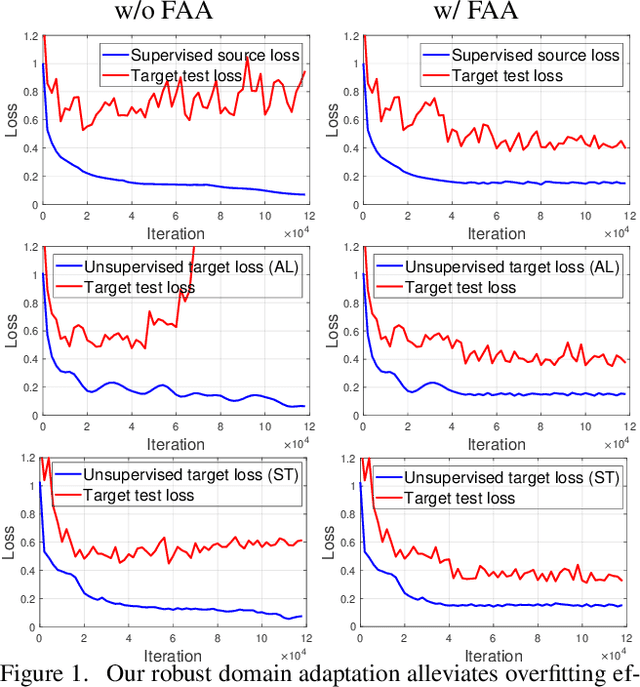
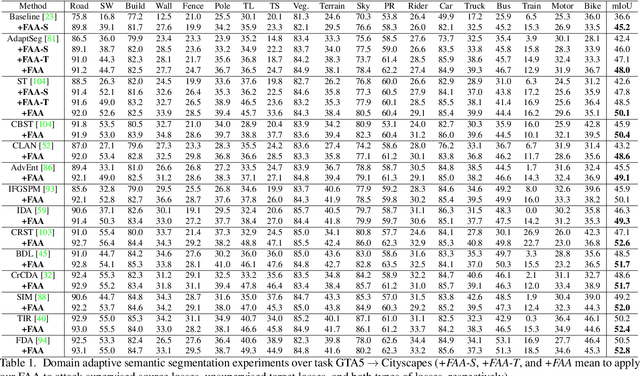
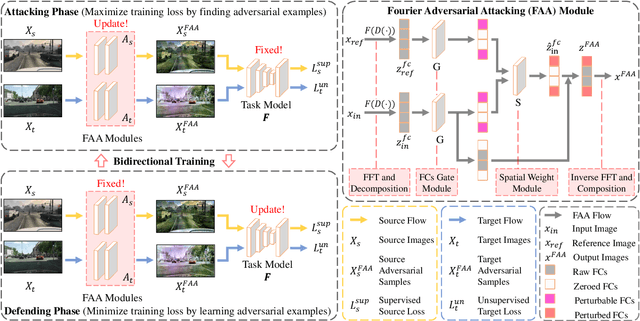
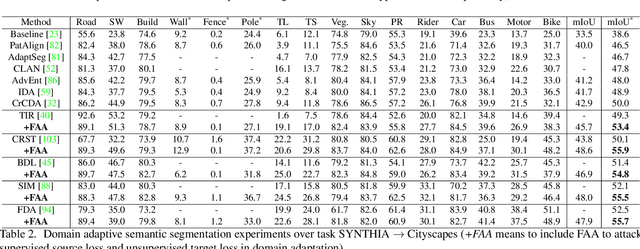
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.