 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contextually Guided Convolutional Neural Networks for Learning Most Transferable Representations
Mar 02, 2021
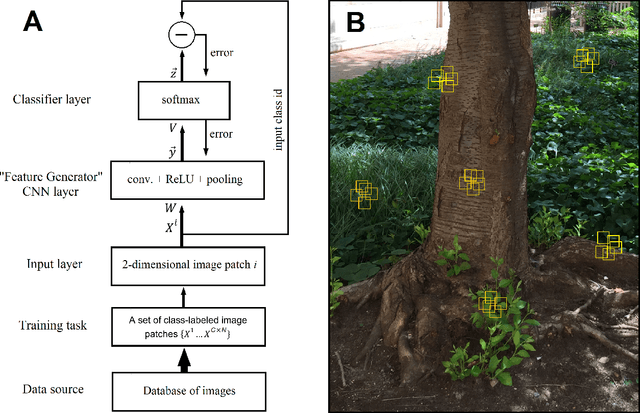
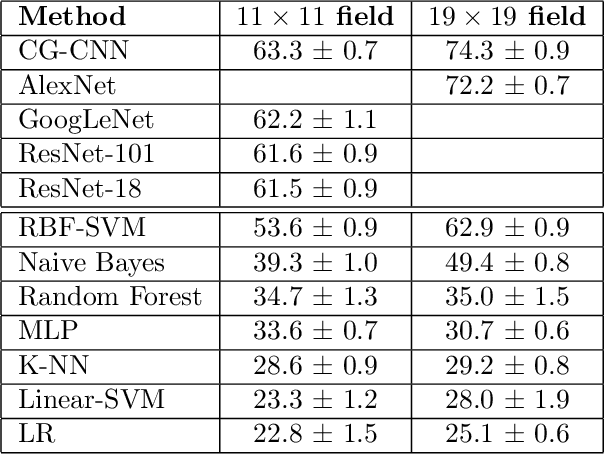
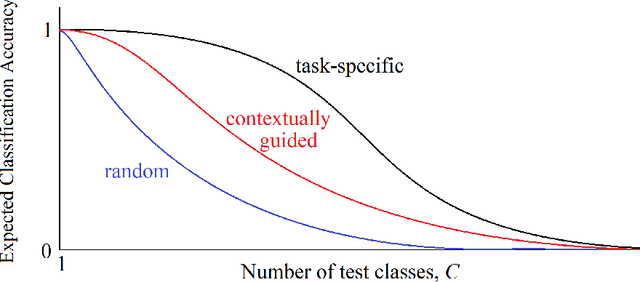

Deep Convolutional Neural Networks (CNNs), trained extensively on very large labeled datasets, learn to recognize inferentially powerful features in their input patterns and represent efficiently their objective content. Such objectivity of their internal representations enables deep CNNs to readily transfer and successfully apply these representations to new classification tasks. Deep CNNs develop their internal representations through a challenging process of error backpropagation-based supervised training. In contrast, deep neural networks of the cerebral cortex develop their even more powerful internal representations in an unsupervised process, apparently guided at a local level by contextual information. Implementing such local contextual guidance principles in a single-layer CNN architecture, we propose an efficient algorithm for developing broad-purpose representations (i.e., representations transferable to new tasks without additional training) in shallow CNNs trained on limited-size datasets. A contextually guided CNN (CG-CNN) is trained on groups of neighboring image patches picked at random image locations in the dataset. Such neighboring patches are likely to have a common context and therefore are treated for the purposes of training as belonging to the same class. Across multiple iterations of such training on different context-sharing groups of image patches, CNN features that are optimized in one iteration are then transferred to the next iteration for further optimization, etc. In this process, CNN features acquire higher pluripotency, or inferential utility for any arbitrary classification task, which we quantify as a transfer utility. In our application to natural images, we find that CG-CNN features show the same, if not higher, transfer utility and classification accuracy as comparable transferable features in the first CNN layer of the well-known deep networks.
A Dark Flash Normal Camera
Dec 11, 2020
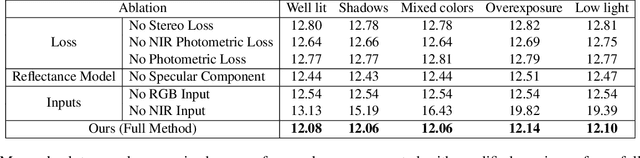


Casual photography is often performed in uncontrolled lighting that can result in low quality images and degrade the performance of downstream processing. We consider the problem of estimating surface normal and reflectance maps of scenes depicting people despite these conditions by supplementing the available visible illumination with a single near infrared (NIR) light source and camera, a so-called "dark flash image". Our method takes as input a single color image captured under arbitrary visible lighting and a single dark flash image captured under controlled front-lit NIR lighting at the same viewpoint, and computes a normal map, a diffuse albedo map, and a specular intensity map of the scene. Since ground truth normal and reflectance maps of faces are difficult to capture, we propose a novel training technique that combines information from two readily available and complementary sources: a stereo depth signal and photometric shading cues. We evaluate our method over a range of subjects and lighting conditions and describe two applications: optimizing stereo geometry and filling the shadows in an image.
GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
Mar 09, 2021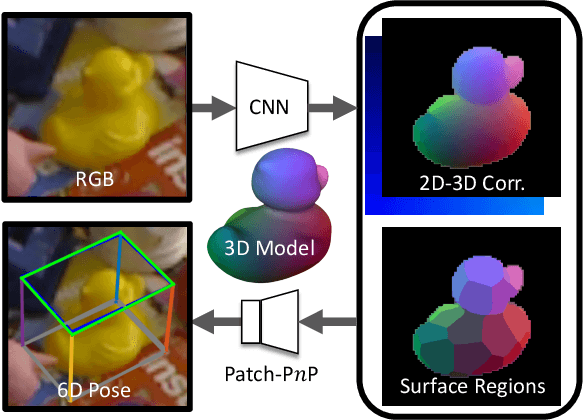
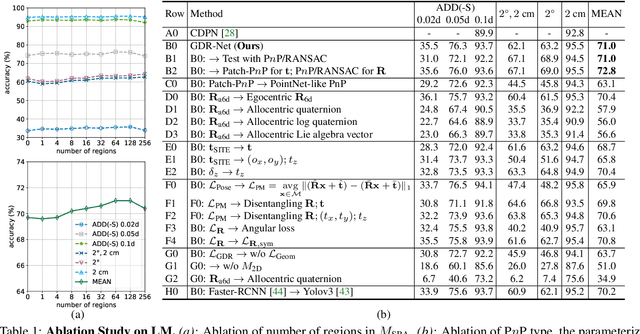
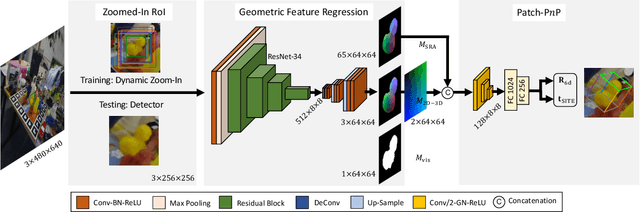
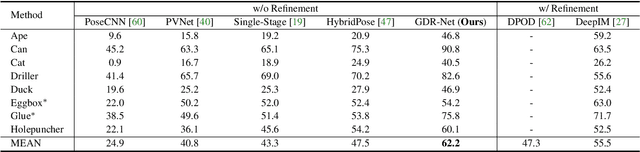
6D pose estimation from a single RGB image is a fundamental task in computer vision. The current top-performing deep learning-based methods rely on an indirect strategy, i.e., first establishing 2D-3D correspondences between the coordinates in the image plane and object coordinate system, and then applying a variant of the P$n$P/RANSAC algorithm. However, this two-stage pipeline is not end-to-end trainable, thus is hard to be employed for many tasks requiring differentiable poses. On the other hand, methods based on direct regression are currently inferior to geometry-based methods. In this work, we perform an in-depth investigation on both direct and indirect methods, and propose a simple yet effective Geometry-guided Direct Regression Network (GDR-Net) to learn the 6D pose in an end-to-end manner from dense correspondence-based intermediate geometric representations. Extensive experiments show that our approach remarkably outperforms state-of-the-art methods on LM, LM-O and YCB-V datasets. Code is available at https://git.io/GDR-Net.
View-Guided Point Cloud Completion
Apr 12, 2021
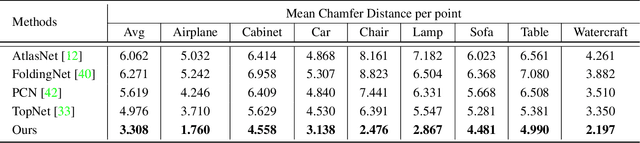
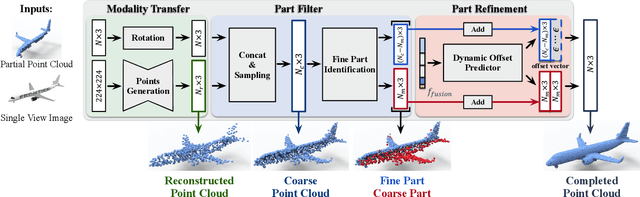
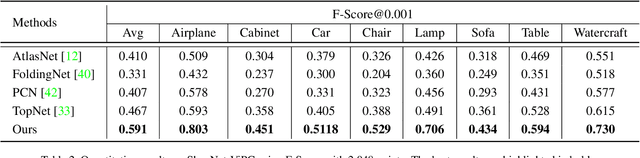
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
Statistical Measures For Defining Curriculum Scoring Function
Feb 27, 2021
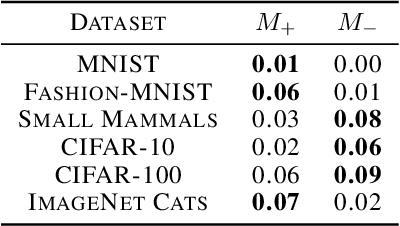

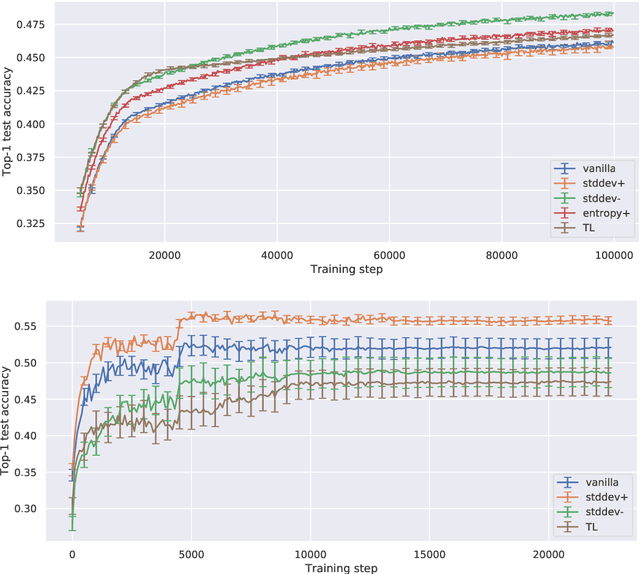
Curriculum learning is a training strategy that sorts the training examples by some measure of their difficulty and gradually exposes them to the learner to improve the network performance. In this work, we propose two novel curriculum learning algorithms, and empirically show their improvements in performance with convolutional and fully-connected neural networks on multiple real image datasets. Motivated by our insights from implicit curriculum ordering, we introduce a simple curriculum learning strategy that uses statistical measures such as standard deviation and entropy values to score the difficulty of data points for real image classification tasks. We also propose and study the performance of a dynamic curriculum learning algorithm. Our dynamic curriculum algorithm tries to reduce the distance between the network weight and an optimal weight at any training step by greedily sampling examples with gradients that are directed towards the optimal weight. Further, we also use our algorithms to discuss why curriculum learning is helpful.
Multi-Exposure Image Fusion Based on Exposure Compensation
Jun 23, 2018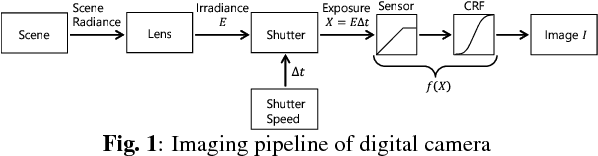


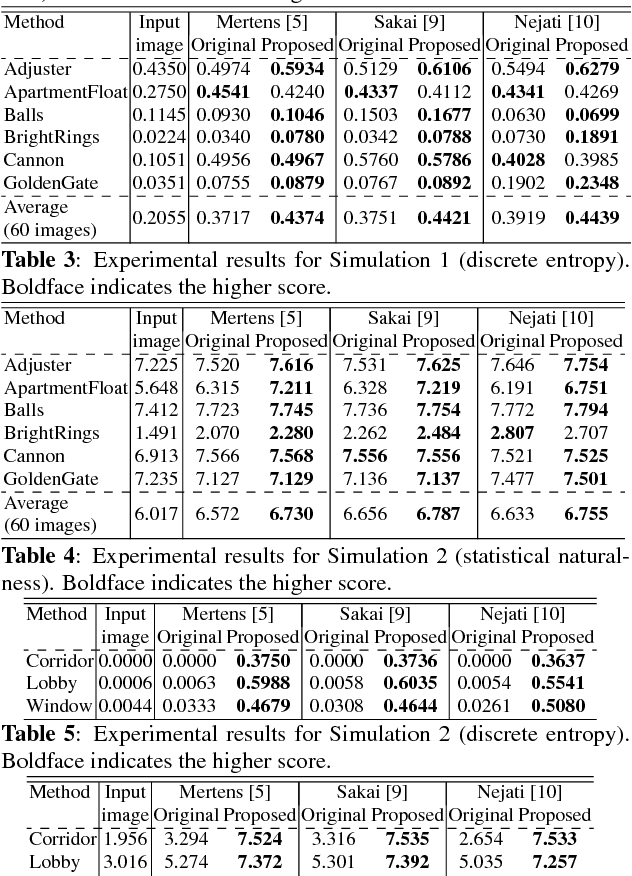
This paper proposes a novel multi-exposure image fusion method based on exposure compensation. Multi-exposure image fusion is a method to produce images without color saturation regions, by using photos with different exposures. However, in conventional works, it is unclear how to determine appropriate exposure values, and moreover, it is difficult to set appropriate exposure values at the time of photographing due to time constraints. In the proposed method, the luminance of the input multi-exposure images is adjusted on the basis of the relationship between exposure values and pixel values, where the relationship is obtained by assuming that a digital camera has a linear response function. The use of a local contrast enhancement method is also considered to improve input multi-exposure images. The compensated images are finally combined by one of existing multi-exposure image fusion methods. In some experiments, the effectiveness of the proposed method are evaluated in terms of the tone mapped image quality index, statistical naturalness, and discrete entropy, by comparing the proposed one with conventional ones.
Consistency-aware Shading Orders Selective Fusion for Intrinsic Image Decomposition
Oct 23, 2018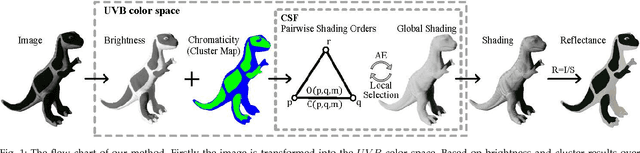
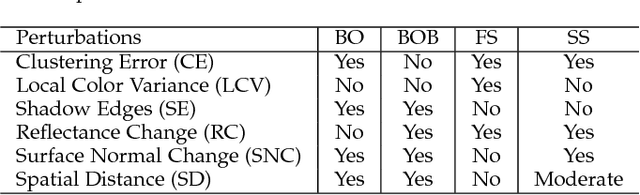
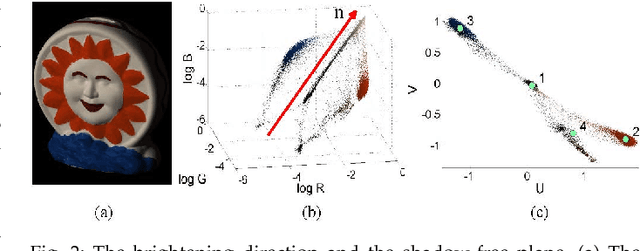
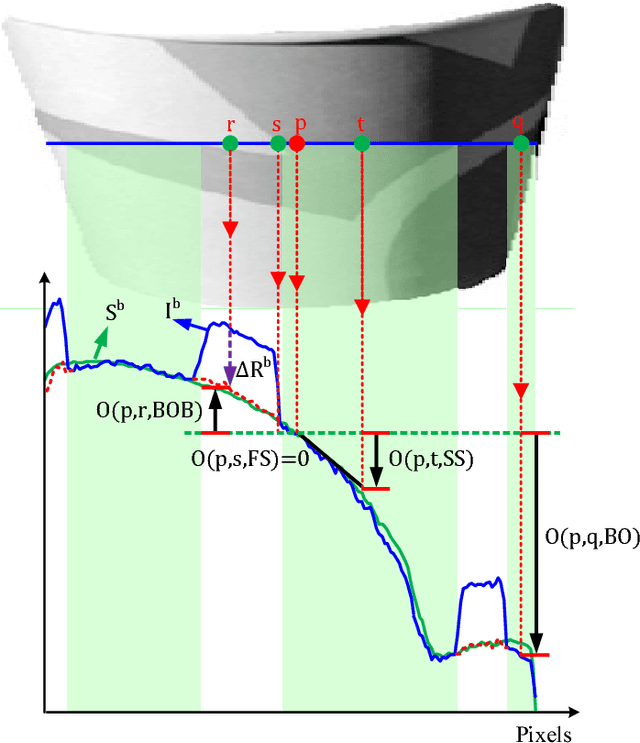
We address the problem of decomposing a single image into reflectance and shading. The difficulty comes from the fact that the components of image---the surface albedo, the direct illumination, and the ambient illumination---are coupled heavily in observed image. We propose to infer the shading by ordering pixels by their relative brightness, without knowing the absolute values of the image components beforehand. The pairwise shading orders are estimated in two ways: brightness order and low-order fittings of local shading field. The brightness order is a non-local measure, which can be applied to any pair of pixels including those whose reflectance and shading are both different. The low-order fittings are used for pixel pairs within local regions of smooth shading. Together, they can capture both global order structure and local variations of the shading. We propose a Consistency-aware Selective Fusion (CSF) to integrate the pairwise orders into a globally consistent order. The iterative selection process solves the conflicts between the pairwise orders obtained by different estimation methods. Inconsistent or unreliable pairwise orders will be automatically excluded from the fusion to avoid polluting the global order. Experiments on the MIT Intrinsic Image dataset show that the proposed model is effective at recovering the shading including deep shadows. Our model also works well on natural images from the IIW dataset, the UIUC Shadow dataset and the NYU-Depth dataset, where the colors of direct lights and ambient lights are quite different.
Weakly-Supervised Convolutional Neural Networks for Multimodal Image Registration
Jul 09, 2018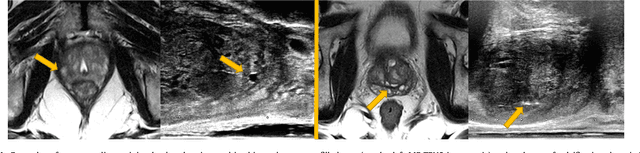
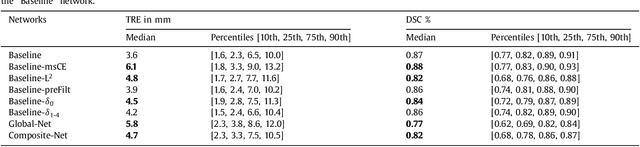
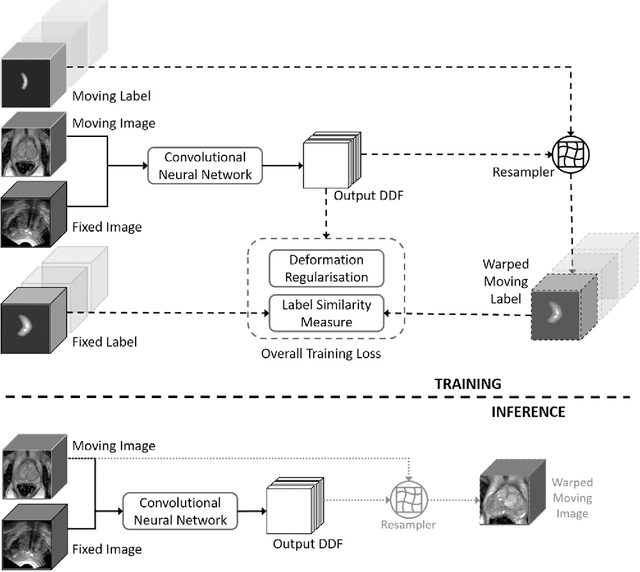
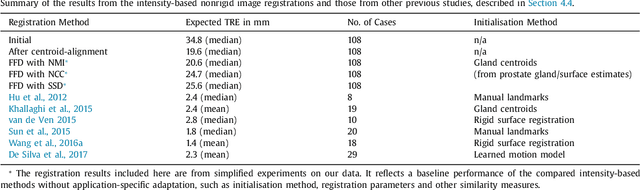
One of the fundamental challenges in supervised learning for multimodal image registration is the lack of ground-truth for voxel-level spatial correspondence. This work describes a method to infer voxel-level transformation from higher-level correspondence information contained in anatomical labels. We argue that such labels are more reliable and practical to obtain for reference sets of image pairs than voxel-level correspondence. Typical anatomical labels of interest may include solid organs, vessels, ducts, structure boundaries and other subject-specific ad hoc landmarks. The proposed end-to-end convolutional neural network approach aims to predict displacement fields to align multiple labelled corresponding structures for individual image pairs during the training, while only unlabelled image pairs are used as the network input for inference. We highlight the versatility of the proposed strategy, for training, utilising diverse types of anatomical labels, which need not to be identifiable over all training image pairs. At inference, the resulting 3D deformable image registration algorithm runs in real-time and is fully-automated without requiring any anatomical labels or initialisation. Several network architecture variants are compared for registering T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients. A median target registration error of 3.6 mm on landmark centroids and a median Dice of 0.87 on prostate glands are achieved from cross-validation experiments, in which 108 pairs of multimodal images from 76 patients were tested with high-quality anatomical labels.
Plot and Rework: Modeling Storylines for Visual Storytelling
May 14, 2021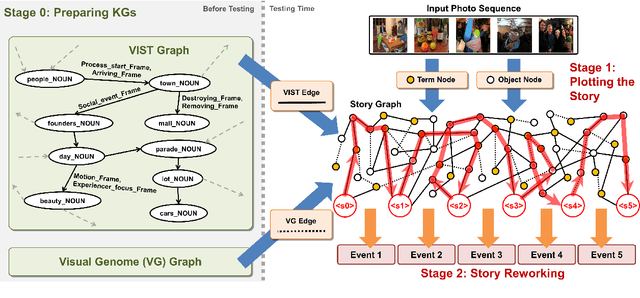


Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.
Local Propagation for Few-Shot Learning
Jan 05, 2021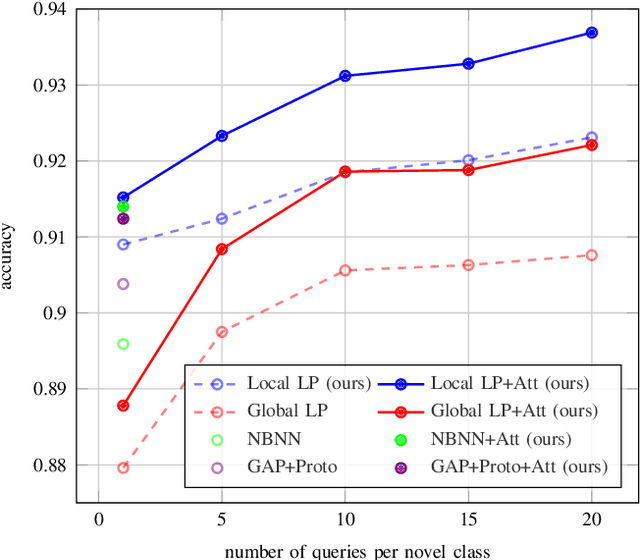
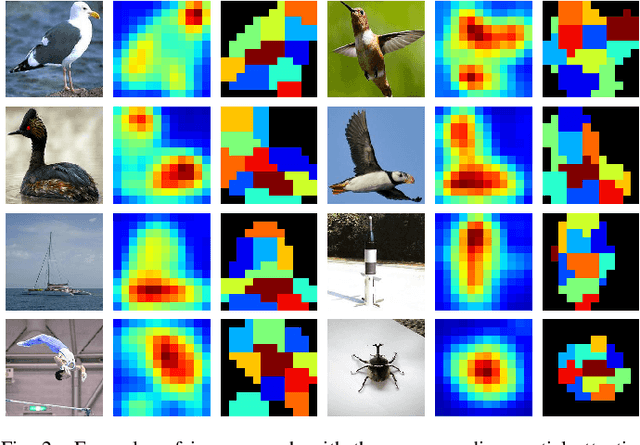

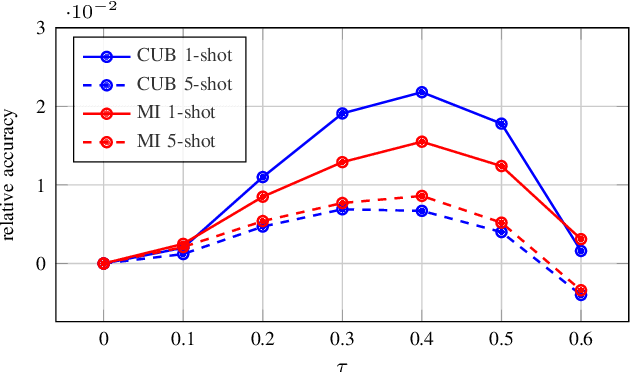
The challenge in few-shot learning is that available data is not enough to capture the underlying distribution. To mitigate this, two emerging directions are (a) using local image representations, essentially multiplying the amount of data by a constant factor, and (b) using more unlabeled data, for instance by transductive inference, jointly on a number of queries. In this work, we bring these two ideas together, introducing \emph{local propagation}. We treat local image features as independent examples, we build a graph on them and we use it to propagate both the features themselves and the labels, known and unknown. Interestingly, since there is a number of features per image, even a single query gives rise to transductive inference. As a result, we provide a universally safe choice for few-shot inference under both non-transductive and transductive settings, improving accuracy over corresponding methods. This is in contrast to existing solutions, where one needs to choose the method depending on the quantity of available data.