 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-shot Compressed 3D Imaging by Exploiting Random Scattering and Astigmatism
May 21, 2021
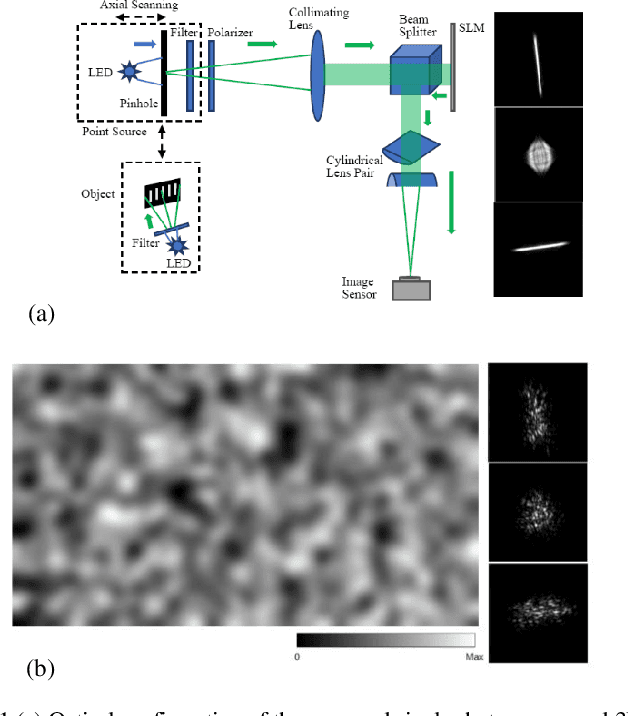
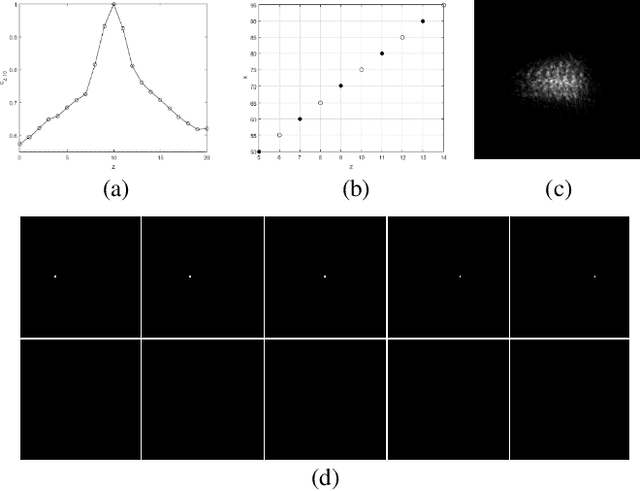

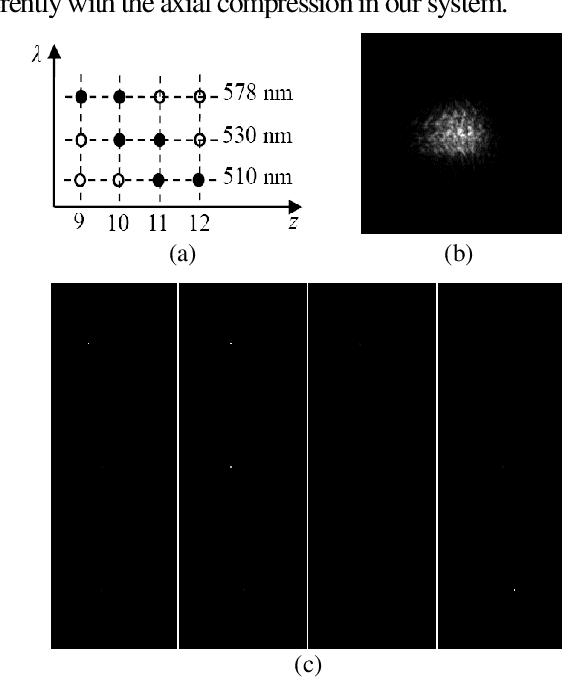
Based on point spread function (PSF) engineering and astigmatism due to a pair of cylindrical lenses, a novel compressed imaging mechanism is proposed to achieve single-shot incoherent 3D imaging. The speckle-like PSF of the imaging system is sensitive to axial shift, which makes it feasible to reconstruct a 3D image by solving an optimization problem with sparsity constraint. With the experimentally calibrated PSFs, the proposed method is demonstrated by a synthetic 3D point object and real 3D object, and the images in different axial slices can be reconstructed faithfully. Moreover, 3D multispectral compressed imaging is explored with the same system, and the result is rather satisfactory with a synthetic point object. Because of the inherent compatibility between the compression in spectral and axial dimensions, the proposed mechanism has the potential to be a unified framework for multi-dimensional compressed imaging.
Bayesian Kernelised Test of (In)dependence with Mixed-type Variables
May 09, 2021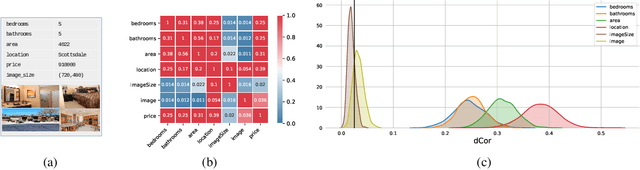
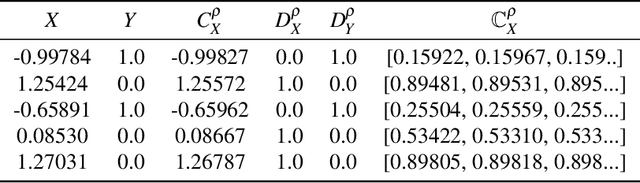
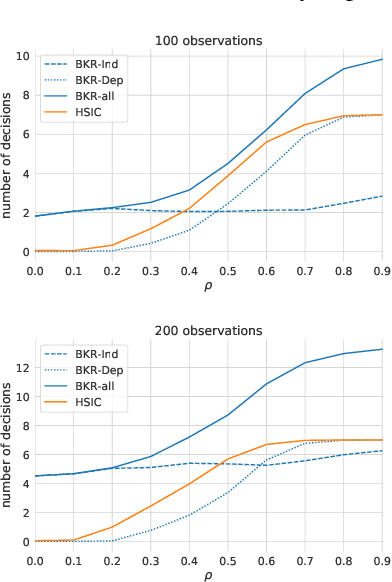
A fundamental task in AI is to assess (in)dependence between mixed-type variables (text, image, sound). We propose a Bayesian kernelised correlation test of (in)dependence using a Dirichlet process model. The new measure of (in)dependence allows us to answer some fundamental questions: Based on data, are (mixed-type) variables independent? How likely is dependence/independence to hold? How high is the probability that two mixed-type variables are more than just weakly dependent? We theoretically show the properties of the approach, as well as algorithms for fast computation with it. We empirically demonstrate the effectiveness of the proposed method by analysing its performance and by comparing it with other frequentist and Bayesian approaches on a range of datasets and tasks with mixed-type variables.
Toward a Procedural Fruit Tree Rendering Framework for Image Analysis
Jul 10, 2019
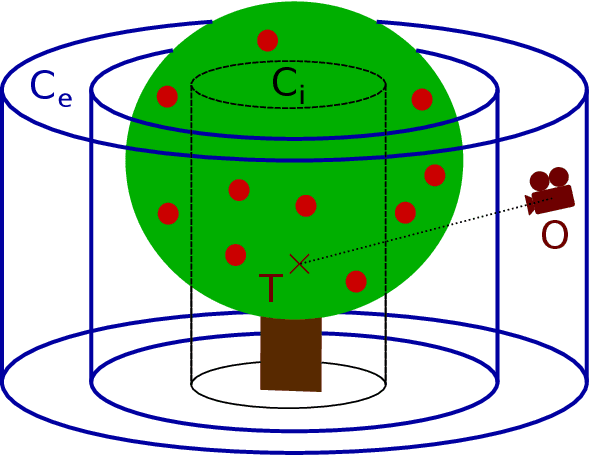
We propose a procedural fruit tree rendering framework, based on Blender and Python scripts allowing to generate quickly labeled dataset (i.e. including ground truth semantic segmentation). It is designed to train image analysis deep learning methods (e.g. in a robotic fruit harvesting context), where real labeled training datasets are usually scarce and existing synthetic ones are too specialized. Moreover, the framework includes the possibility to introduce parametrized variations in the model (e.g. lightning conditions, background), producing a dataset with embedded Domain Randomization aspect.
Know Your Surroundings: Panoramic Multi-Object Tracking by Multimodality Collaboration
May 31, 2021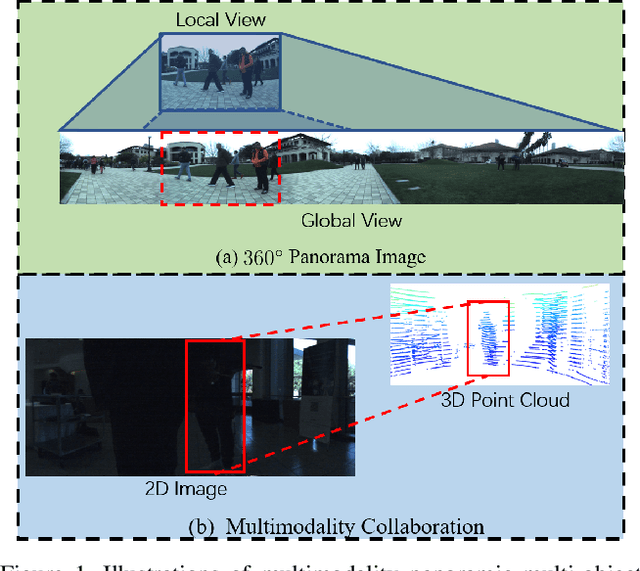
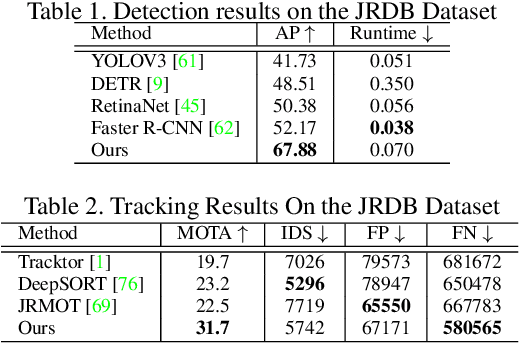


In this paper, we focus on the multi-object tracking (MOT) problem of automatic driving and robot navigation. Most existing MOT methods track multiple objects using a singular RGB camera, which are prone to camera field-of-view and suffer tracking failures in complex scenarios due to background clutters and poor light conditions. To meet these challenges, we propose a MultiModality PAnoramic multi-object Tracking framework (MMPAT), which takes both 2D panorama images and 3D point clouds as input and then infers target trajectories using the multimodality data. The proposed method contains four major modules, a panorama image detection module, a multimodality data fusion module, a data association module and a trajectory inference model. We evaluate the proposed method on the JRDB dataset, where the MMPAT achieves the top performance in both the detection and tracking tasks and significantly outperforms state-of-the-art methods by a large margin (15.7 and 8.5 improvement in terms of AP and MOTA, respectively).
Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription
Jul 02, 2021
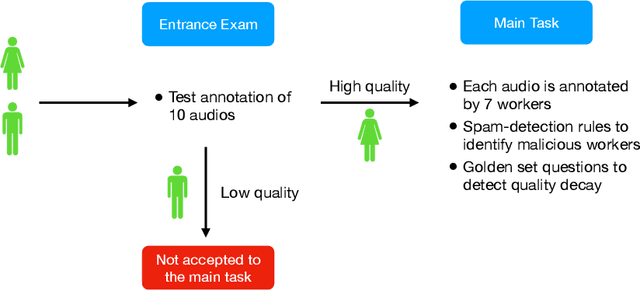
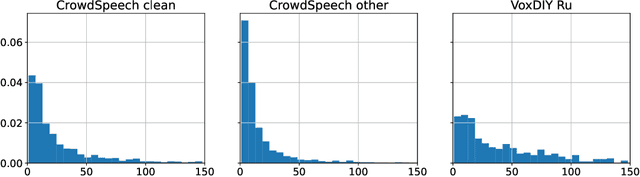
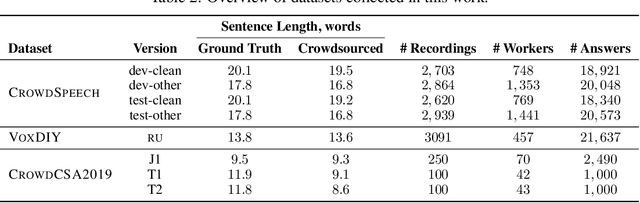
Domain-specific data is the crux of the successful transfer of machine learning systems from benchmarks to real life. Crowdsourcing has become one of the standard tools for cheap and time-efficient data collection for simple problems such as image classification: thanks in large part to advances in research on aggregation methods. However, the applicability of crowdsourcing to more complex tasks (e.g., speech recognition) remains limited due to the lack of principled aggregation methods for these modalities. The main obstacle towards designing advanced aggregation methods is the absence of training data, and in this work, we focus on bridging this gap in speech recognition. For this, we collect and release CrowdSpeech -- the first publicly available large-scale dataset of crowdsourced audio transcriptions. Evaluation of existing aggregation methods on our data shows room for improvement, suggesting that our work may entail the design of better algorithms. At a higher level, we also contribute to the more general challenge of collecting high-quality datasets using crowdsourcing: we develop a principled pipeline for constructing datasets of crowdsourced audio transcriptions in any novel domain. We show its applicability on an under-resourced language by constructing VoxDIY -- a counterpart of CrowdSpeech for the Russian language. We also release the code that allows a full replication of our data collection pipeline and share various insights on best practices of data collection via crowdsourcing.
Image Denoising with Graph-Convolutional Neural Networks
May 29, 2019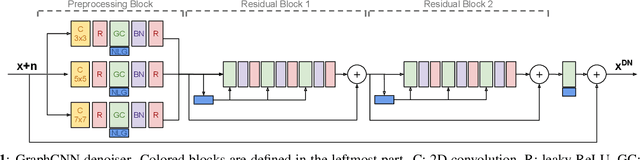
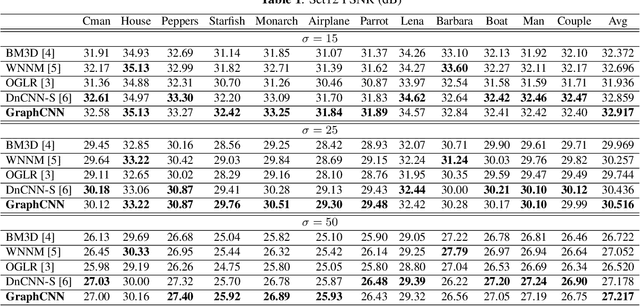
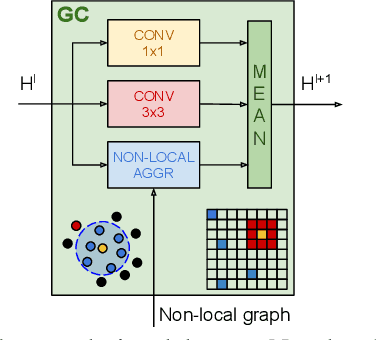

Recovering an image from a noisy observation is a key problem in signal processing. Recently, it has been shown that data-driven approaches employing convolutional neural networks can outperform classical model-based techniques, because they can capture more powerful and discriminative features. However, since these methods are based on convolutional operations, they are only capable of exploiting local similarities without taking into account non-local self-similarities. In this paper we propose a convolutional neural network that employs graph-convolutional layers in order to exploit both local and non-local similarities. The graph-convolutional layers dynamically construct neighborhoods in the feature space to detect latent correlations in the feature maps produced by the hidden layers. The experimental results show that the proposed architecture outperforms classical convolutional neural networks for the denoising task.
DeepObjStyle: Deep Object-based Photo Style Transfer
Dec 11, 2020
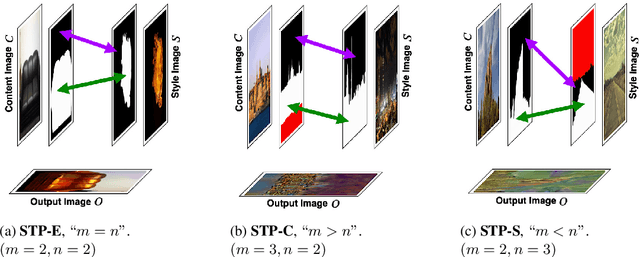


One of the major challenges of style transfer is the appropriate image features supervision between the output image and the input (style and content) images. An efficient strategy would be to define an object map between the objects of the style and the content images. However, such a mapping is not well established when there are semantic objects of different types and numbers in the style and the content images. It also leads to content mismatch in the style transfer output, which could reduce the visual quality of the results. We propose an object-based style transfer approach, called DeepObjStyle, for the style supervision in the training data-independent framework. DeepObjStyle preserves the semantics of the objects and achieves better style transfer in the challenging scenario when the style and the content images have a mismatch of image features. We also perform style transfer of images containing a word cloud to demonstrate that DeepObjStyle enables an appropriate image features supervision. We validate the results using quantitative comparisons and user studies.
View-Guided Point Cloud Completion
Apr 13, 2021
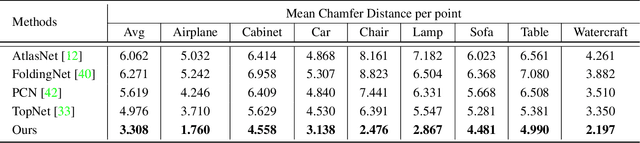
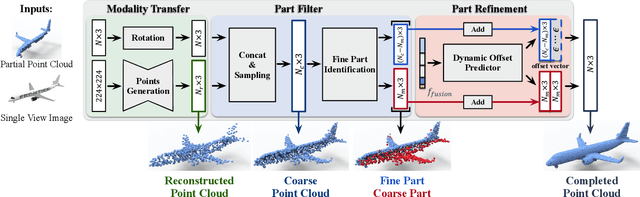
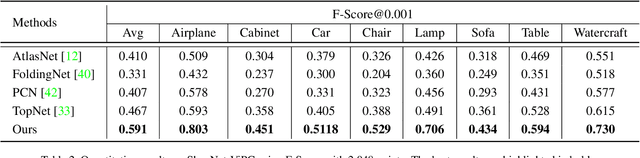
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
Provably Convergent Learned Inexact Descent Algorithm for Low-Dose CT Reconstruction
Apr 27, 2021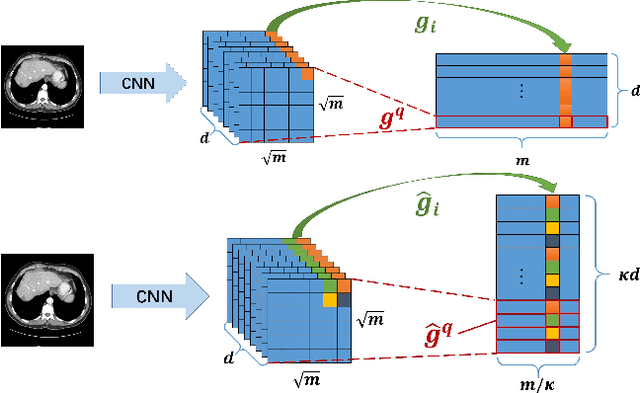
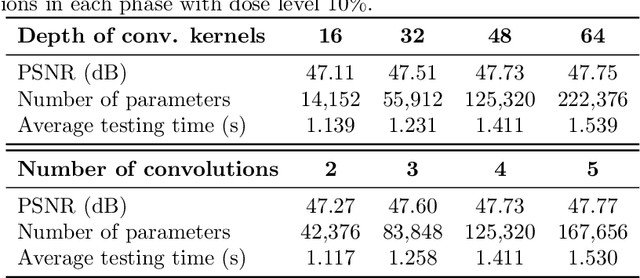
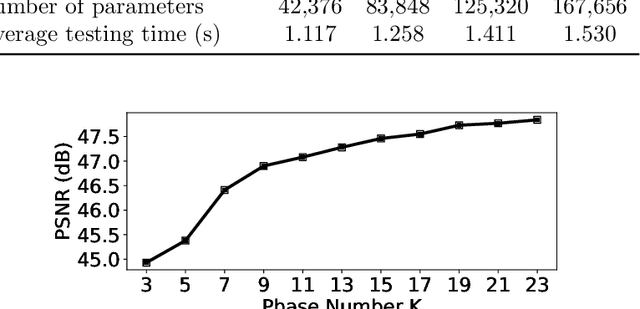
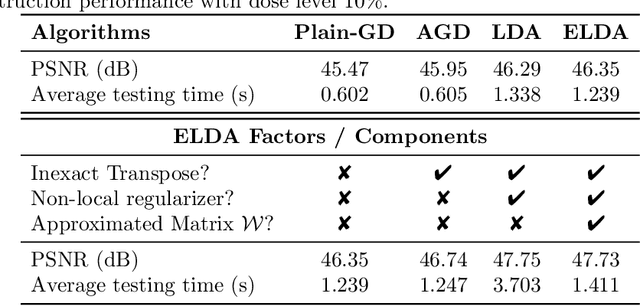
We propose a provably convergent method, called Efficient Learned Descent Algorithm (ELDA), for low-dose CT (LDCT) reconstruction. ELDA is a highly interpretable neural network architecture with learned parameters and meanwhile retains convergence guarantee as classical optimization algorithms. To improve reconstruction quality, the proposed ELDA also employs a new non-local feature mapping and an associated regularizer. We compare ELDA with several state-of-the-art deep image methods, such as RED-CNN and Learned Primal-Dual, on a set of LDCT reconstruction problems. Numerical experiments demonstrate improvement of reconstruction quality using ELDA with merely 19 layers, suggesting the promising performance of ELDA in solution accuracy and parameter efficiency.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
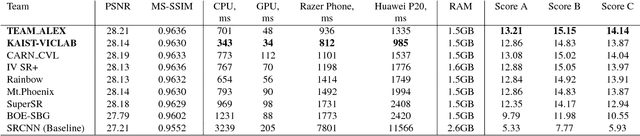

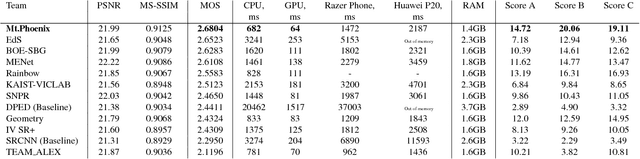
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.