 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Energy-Efficient and Federated Meta-Learning via Projected Stochastic Gradient Ascent
May 31, 2021
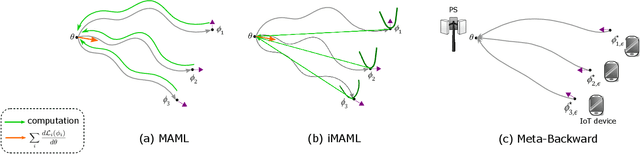
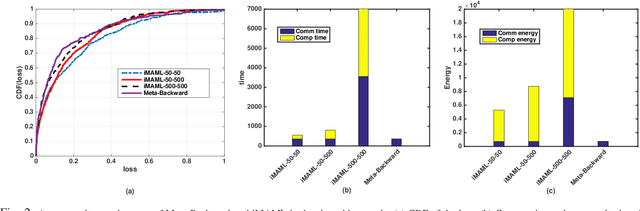
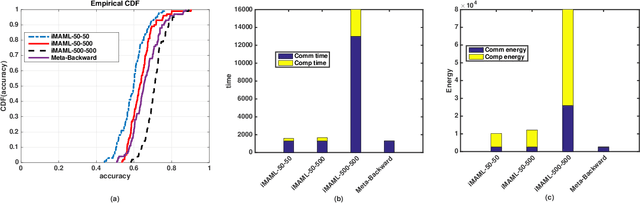
In this paper, we propose an energy-efficient federated meta-learning framework. The objective is to enable learning a meta-model that can be fine-tuned to a new task with a few number of samples in a distributed setting and at low computation and communication energy consumption. We assume that each task is owned by a separate agent, so a limited number of tasks is used to train a meta-model. Assuming each task was trained offline on the agent's local data, we propose a lightweight algorithm that starts from the local models of all agents, and in a backward manner using projected stochastic gradient ascent (P-SGA) finds a meta-model. The proposed method avoids complex computations such as computing hessian, double looping, and matrix inversion, while achieving high performance at significantly less energy consumption compared to the state-of-the-art methods such as MAML and iMAML on conducted experiments for sinusoid regression and image classification tasks.
Towards Training Stronger Video Vision Transformers for EPIC-KITCHENS-100 Action Recognition
Jun 09, 2021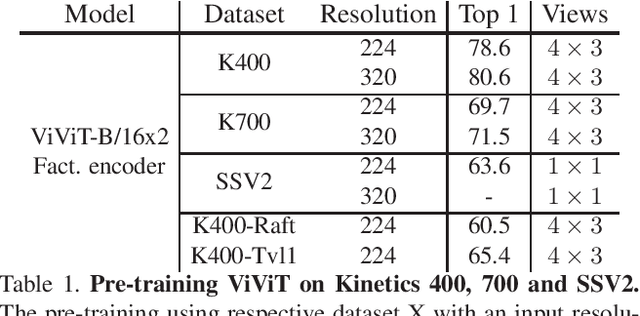
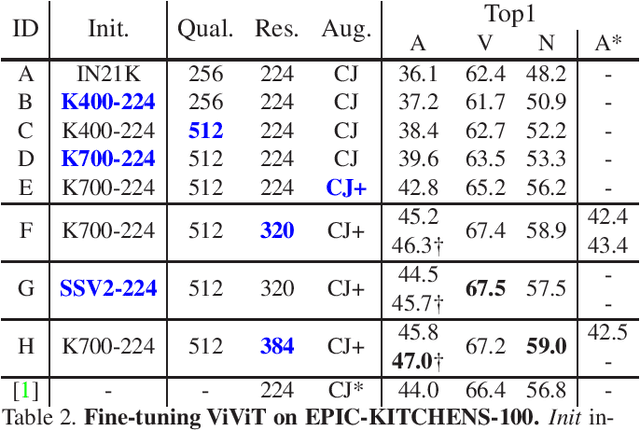
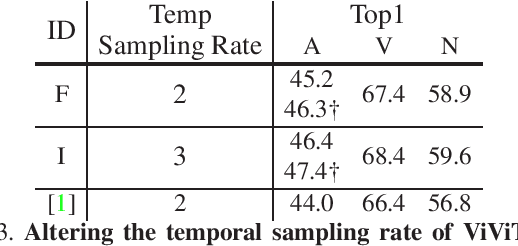
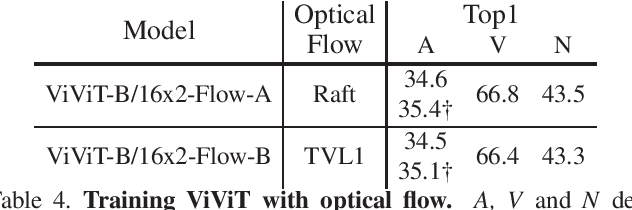
With the recent surge in the research of vision transformers, they have demonstrated remarkable potential for various challenging computer vision applications, such as image recognition, point cloud classification as well as video understanding. In this paper, we present empirical results for training a stronger video vision transformer on the EPIC-KITCHENS-100 Action Recognition dataset. Specifically, we explore training techniques for video vision transformers, such as augmentations, resolutions as well as initialization, etc. With our training recipe, a single ViViT model achieves the performance of 47.4\% on the validation set of EPIC-KITCHENS-100 dataset, outperforming what is reported in the original paper by 3.4%. We found that video transformers are especially good at predicting the noun in the verb-noun action prediction task. This makes the overall action prediction accuracy of video transformers notably higher than convolutional ones. Surprisingly, even the best video transformers underperform the convolutional networks on the verb prediction. Therefore, we combine the video vision transformers and some of the convolutional video networks and present our solution to the EPIC-KITCHENS-100 Action Recognition competition.
Low-Dose CT Denoising Using a Structure-Preserving Kernel Prediction Network
May 31, 2021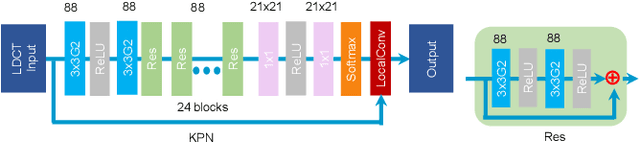
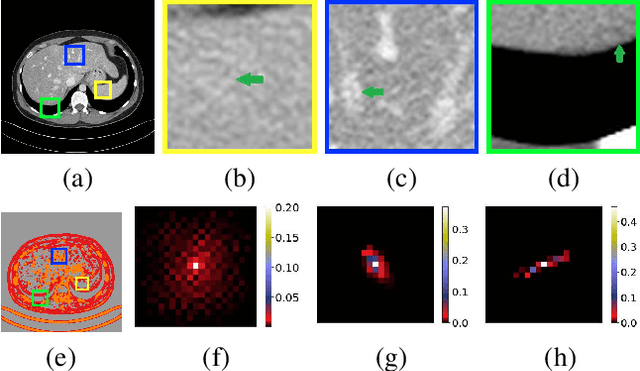


Low-dose CT has been a key diagnostic imaging modality to reduce the potential risk of radiation overdose to patient health. Despite recent advances, CNN-based approaches typically apply filters in a spatially invariant way and adopt similar pixel-level losses, which treat all regions of the CT image equally and can be inefficient when fine-grained structures coexist with non-uniformly distributed noises. To address this issue, we propose a Structure-preserving Kernel Prediction Network (StructKPN) that combines the kernel prediction network with a structure-aware loss function that utilizes the pixel gradient statistics and guides the model towards spatially-variant filters that enhance noise removal, prevent over-smoothing and preserve detailed structures for different regions in CT imaging. Extensive experiments demonstrated that our approach achieved superior performance on both synthetic and non-synthetic datasets, and better preserves structures that are highly desired in clinical screening and low-dose protocol optimization.
Dual Recovery Network with Online Compensation for Image Super-Resolution
Jun 18, 2018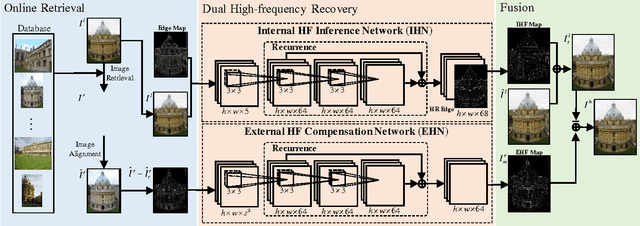
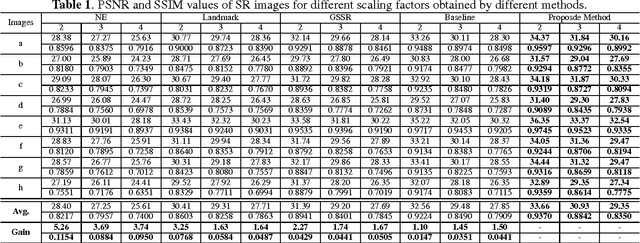

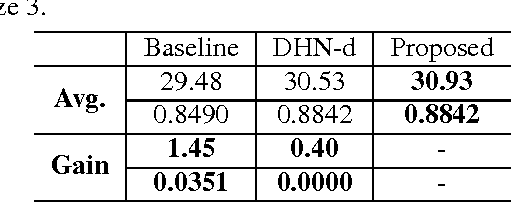
Image super-resolution (SR) methods essentially lead to a loss of some high-frequency (HF) information when predicting high-resolution (HR) images from low-resolution (LR) images without using external references. To address this issue, we additionally utilize online retrieved data to facilitate image SR in a unified deep framework. A novel dual high-frequency recovery network (DHN) is proposed to predict an HR image with three parts: an LR image, an internal inferred HF (IHF) map (HF missing part inferred solely from the LR image) and an external extracted HF (EHF) map. In particular, we infer the HF information based on both the LR image and similar HR references which are retrieved online. For the EHF map, we align the references with affine transformation and then in the aligned references, part of HF signals are extracted by the proposed DHN to compensate for the HF loss. Extensive experimental results demonstrate that our DHN achieves notably better performance than state-of-the-art SR methods.
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Jan 16, 2020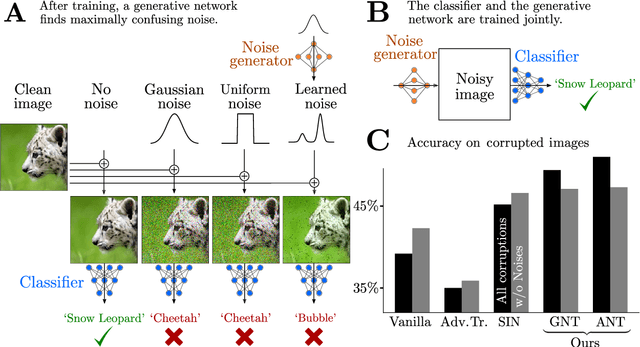
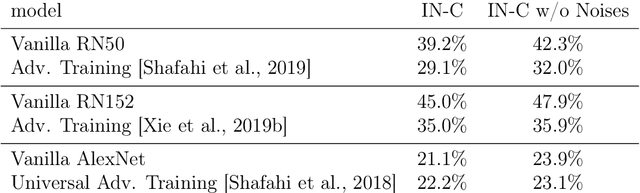
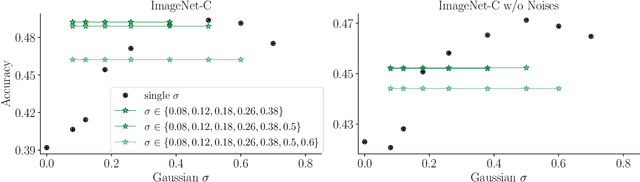
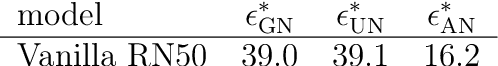
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.
Transferable Sparse Adversarial Attack
May 31, 2021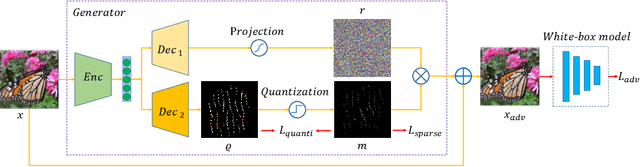
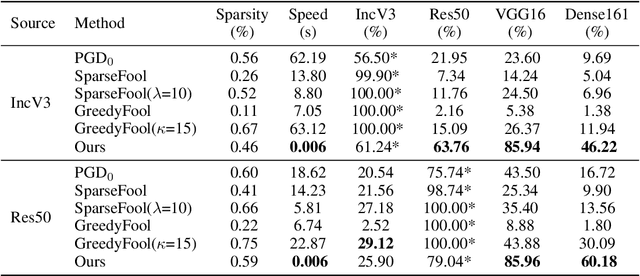
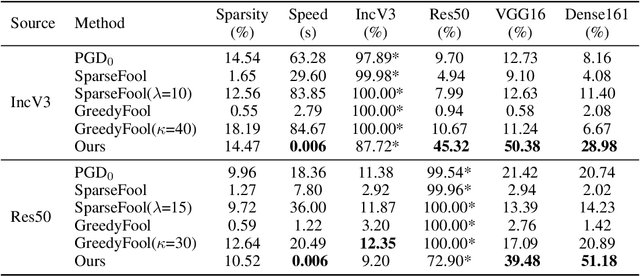
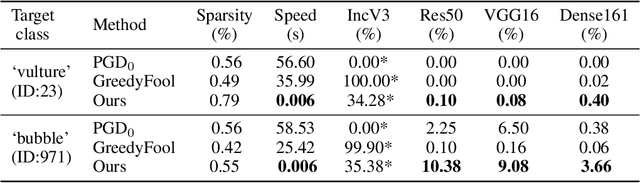
Deep neural networks have shown their vulnerability to adversarial attacks. In this paper, we focus on sparse adversarial attack based on the $\ell_0$ norm constraint, which can succeed by only modifying a few pixels of an image. Despite a high attack success rate, prior sparse attack methods achieve a low transferability under the black-box protocol due to overfitting the target model. Therefore, we introduce a generator architecture to alleviate the overfitting issue and thus efficiently craft transferable sparse adversarial examples. Specifically, the generator decouples the sparse perturbation into amplitude and position components. We carefully design a random quantization operator to optimize these two components jointly in an end-to-end way. The experiment shows that our method has improved the transferability by a large margin under a similar sparsity setting compared with state-of-the-art methods. Moreover, our method achieves superior inference speed, 700$\times$ faster than other optimization-based methods. The code is available at https://github.com/shaguopohuaizhe/TSAA.
Single-shot Compressed 3D Imaging by Exploiting Random Scattering and Astigmatism
May 21, 2021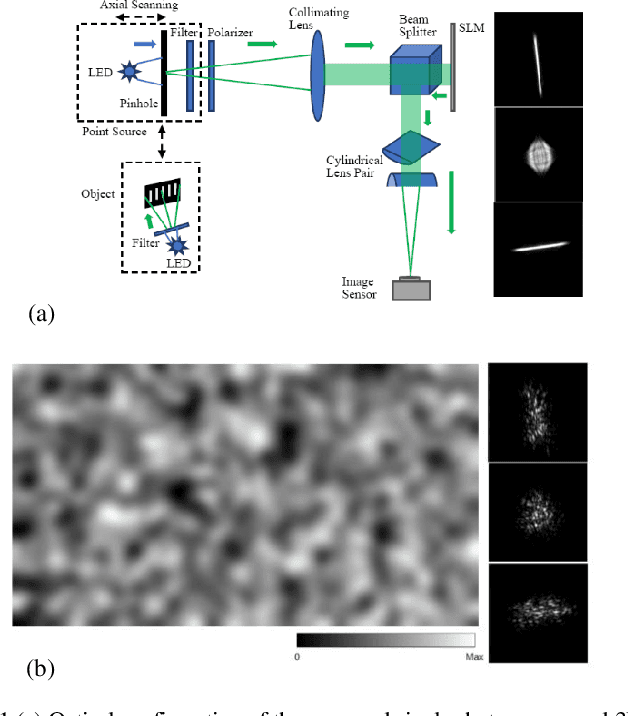
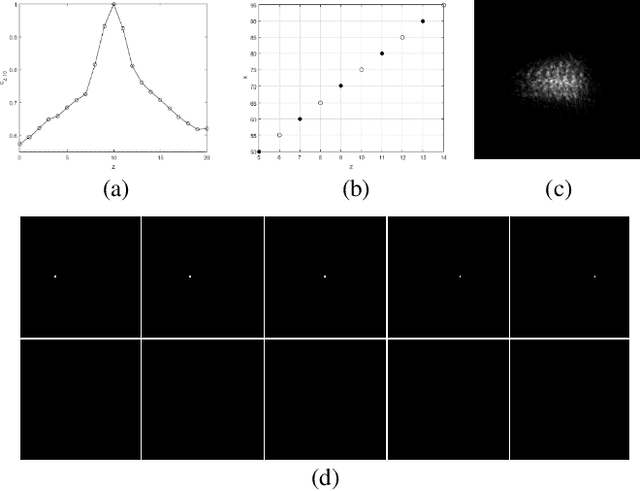

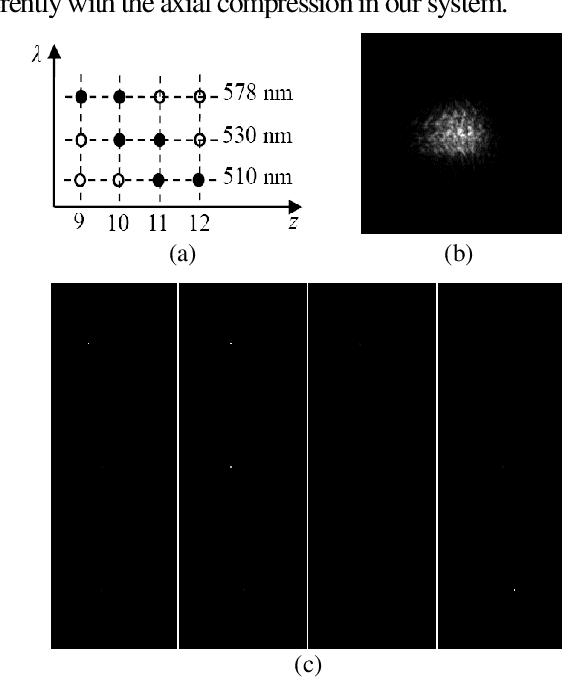
Based on point spread function (PSF) engineering and astigmatism due to a pair of cylindrical lenses, a novel compressed imaging mechanism is proposed to achieve single-shot incoherent 3D imaging. The speckle-like PSF of the imaging system is sensitive to axial shift, which makes it feasible to reconstruct a 3D image by solving an optimization problem with sparsity constraint. With the experimentally calibrated PSFs, the proposed method is demonstrated by a synthetic 3D point object and real 3D object, and the images in different axial slices can be reconstructed faithfully. Moreover, 3D multispectral compressed imaging is explored with the same system, and the result is rather satisfactory with a synthetic point object. Because of the inherent compatibility between the compression in spectral and axial dimensions, the proposed mechanism has the potential to be a unified framework for multi-dimensional compressed imaging.
Bayesian Kernelised Test of (In)dependence with Mixed-type Variables
May 09, 2021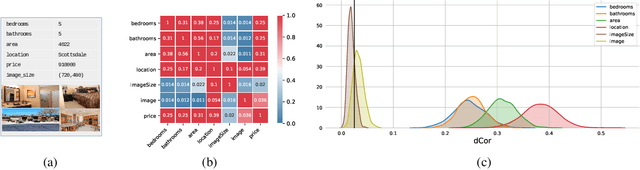
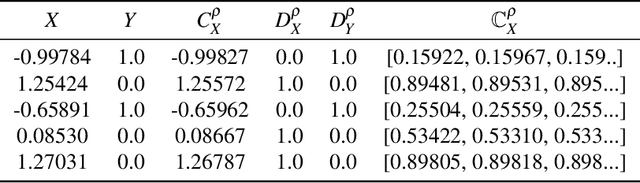
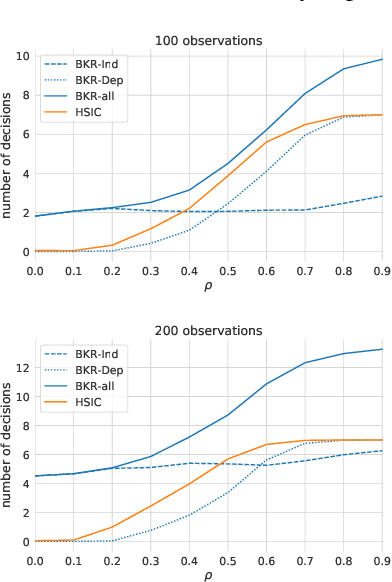
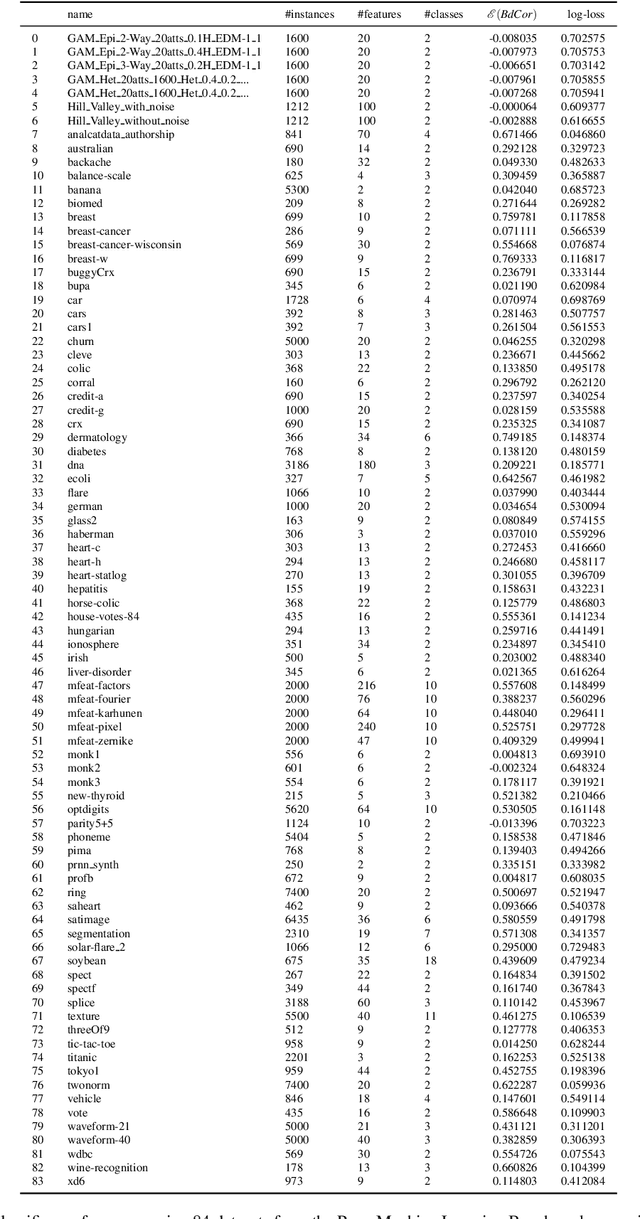
A fundamental task in AI is to assess (in)dependence between mixed-type variables (text, image, sound). We propose a Bayesian kernelised correlation test of (in)dependence using a Dirichlet process model. The new measure of (in)dependence allows us to answer some fundamental questions: Based on data, are (mixed-type) variables independent? How likely is dependence/independence to hold? How high is the probability that two mixed-type variables are more than just weakly dependent? We theoretically show the properties of the approach, as well as algorithms for fast computation with it. We empirically demonstrate the effectiveness of the proposed method by analysing its performance and by comparing it with other frequentist and Bayesian approaches on a range of datasets and tasks with mixed-type variables.
Content-Preserving Unpaired Translation from Simulated to Realistic Ultrasound Images
Mar 09, 2021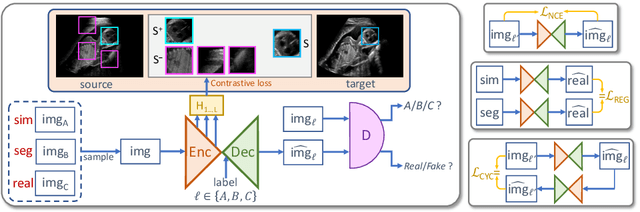



Interactive simulation of ultrasound imaging greatly facilitates sonography training. Although ray-tracing based methods have shown promising results, obtaining realistic images requires substantial modeling effort and manual parameter tuning. In addition, current techniques still result in a significant appearance gap between simulated images and real clinical scans. In this work we introduce a novel image translation framework to bridge this appearance gap, while preserving the anatomical layout of the simulated scenes. We achieve this goal by leveraging both simulated images with semantic segmentations and unpaired in-vivo ultrasound scans. Our framework is based on recent contrastive unpaired translation techniques and we propose a regularization approach by learning an auxiliary segmentation-to-real image translation task, which encourages the disentanglement of content and style. In addition, we extend the generator to be class-conditional, which enables the incorporation of additional losses, in particular a cyclic consistency loss, to further improve the translation quality. Qualitative and quantitative comparisons against state-of-the-art unpaired translation methods demonstrate the superiority of our proposed framework.
Know Your Surroundings: Panoramic Multi-Object Tracking by Multimodality Collaboration
May 31, 2021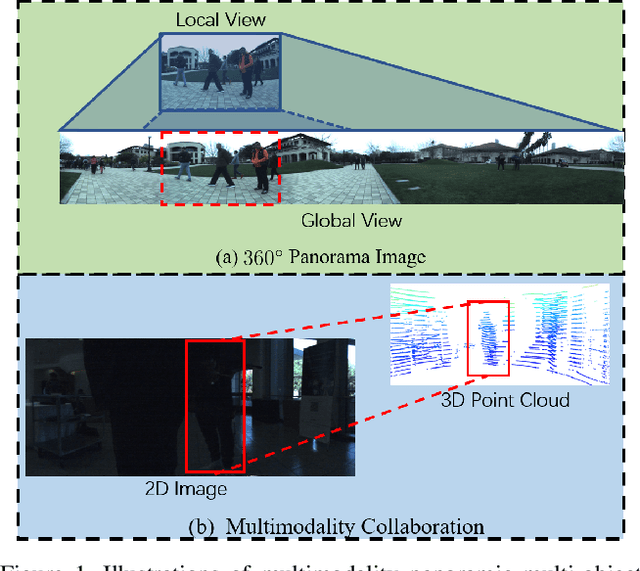
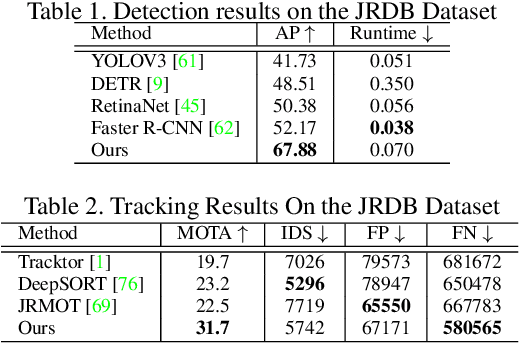


In this paper, we focus on the multi-object tracking (MOT) problem of automatic driving and robot navigation. Most existing MOT methods track multiple objects using a singular RGB camera, which are prone to camera field-of-view and suffer tracking failures in complex scenarios due to background clutters and poor light conditions. To meet these challenges, we propose a MultiModality PAnoramic multi-object Tracking framework (MMPAT), which takes both 2D panorama images and 3D point clouds as input and then infers target trajectories using the multimodality data. The proposed method contains four major modules, a panorama image detection module, a multimodality data fusion module, a data association module and a trajectory inference model. We evaluate the proposed method on the JRDB dataset, where the MMPAT achieves the top performance in both the detection and tracking tasks and significantly outperforms state-of-the-art methods by a large margin (15.7 and 8.5 improvement in terms of AP and MOTA, respectively).