 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Semantic Hallucination for Domain Generalized Semantic Segmentation
Jun 08, 2021
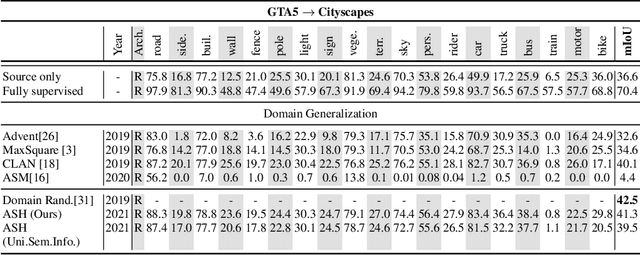
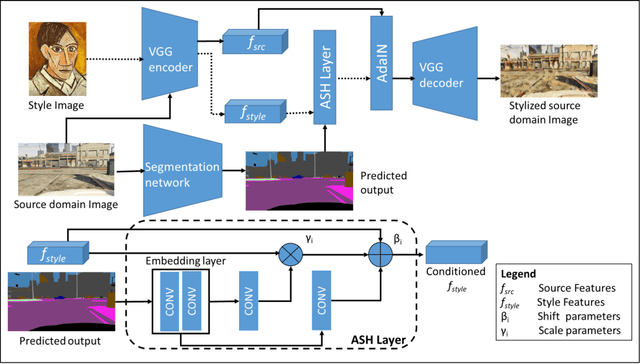
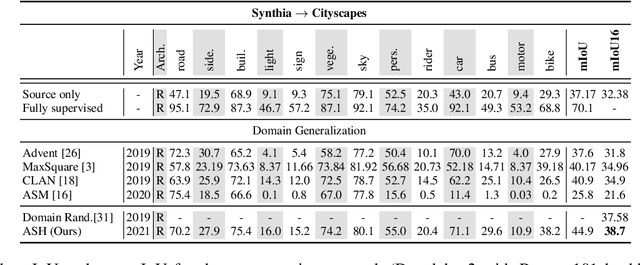
Convolutional neural networks may perform poorly when the test and train data are from different domains. While this problem can be mitigated by using the target domain data to align the source and target domain feature representations, the target domain data may be unavailable due to privacy concerns. Consequently, there is a need for methods that generalize well without access to target domain data during training. In this work, we propose an adversarial hallucination approach, which combines a class-wise hallucination module and a semantic segmentation module. Since the segmentation performance varies across different classes, we design a semantic-conditioned style hallucination layer to adaptively stylize each class. The classwise stylization parameters are generated from the semantic knowledge in the segmentation probability maps of the source domain image. Both modules compete adversarially, with the hallucination module generating increasingly 'difficult' style images to challenge the segmentation module. In response, the segmentation module improves its performance as it is trained with generated samples at an appropriate class-wise difficulty level. Experiments on state of the art domain adaptation work demonstrate the efficacy of our proposed method when no target domain data are available for training.
Achieving Domain Robustness in Stereo Matching Networks by Removing Shortcut Learning
Jun 15, 2021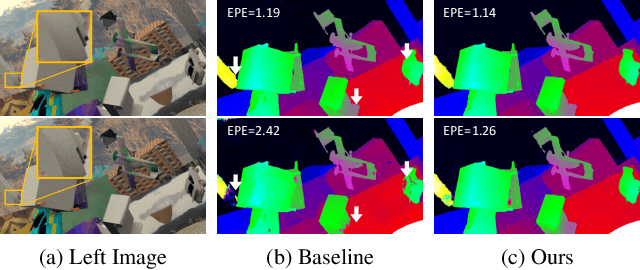
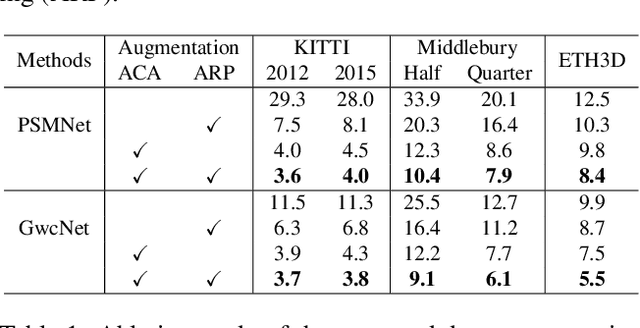

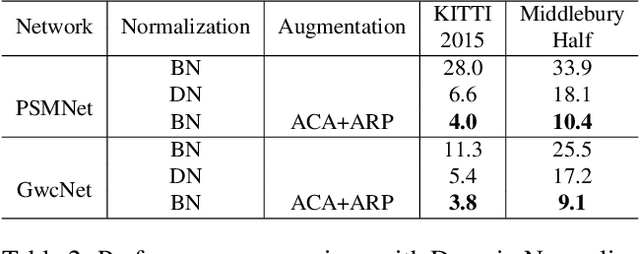
Learning-based stereo matching and depth estimation networks currently excel on public benchmarks with impressive results. However, state-of-the-art networks often fail to generalize from synthetic imagery to more challenging real data domains. This paper is an attempt to uncover hidden secrets of achieving domain robustness and in particular, discovering the important ingredients of generalization success of stereo matching networks by analyzing the effect of synthetic image learning on real data performance. We provide evidence that demonstrates that learning of features in the synthetic domain by a stereo matching network is heavily influenced by two "shortcuts" presented in the synthetic data: (1) identical local statistics (RGB colour features) between matching pixels in the synthetic stereo images and (2) lack of realism in synthetic textures on 3D objects simulated in game engines. We will show that by removing such shortcuts, we can achieve domain robustness in the state-of-the-art stereo matching frameworks and produce a remarkable performance on multiple realistic datasets, despite the fact that the networks were trained on synthetic data, only. Our experimental results point to the fact that eliminating shortcuts from the synthetic data is key to achieve domain-invariant generalization between synthetic and real data domains.
Scan Specific Artifact Reduction in K-space (SPARK) Neural Networks Synergize with Physics-based Reconstruction to Accelerate MRI
Apr 02, 2021
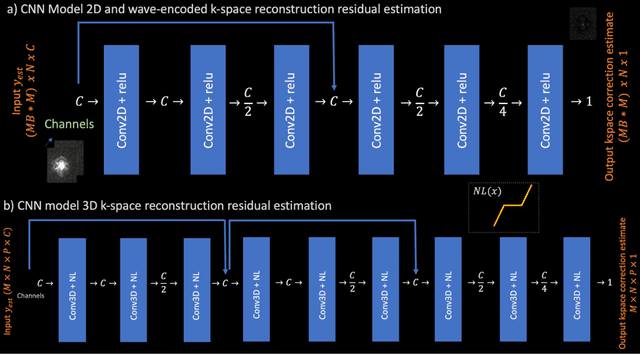
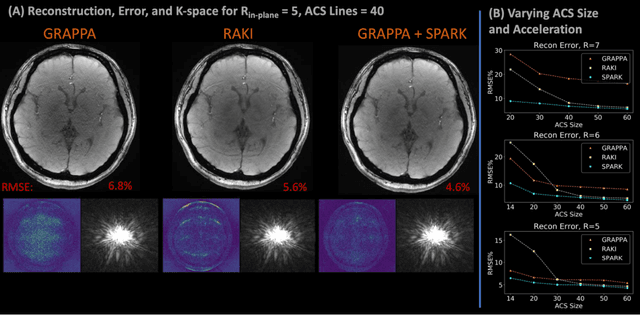
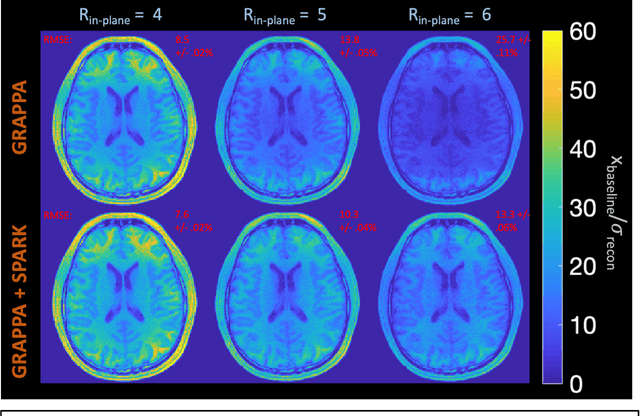
Purpose: To develop a scan-specific model that estimates and corrects k-space errors made when reconstructing accelerated Magnetic Resonance Imaging (MRI) data. Methods: Scan-Specific Artifact Reduction in k-space (SPARK) trains a convolutional neural network to estimate k-space errors made by an input reconstruction technique by back-propagating from the mean-squared-error loss between an auto-calibration signal (ACS) and the input technique's reconstructed ACS. First, SPARK is applied to GRAPPA and demonstrates improved robustness over other scan-specific models. Then, SPARK is shown to synergize with advanced reconstruction techniques by improving image quality when applied to 2D virtual coil (VC-) GRAPPA, 2D LORAKS, 3D GRAPPA without an integrated ACS region, and 2D/3D wave-encoded imaging. Results: SPARK yields 1.5 - 2x RMSE reduction when applied to GRAPPA and improves robustness to ACS size for various acceleration rates in comparison to other scan-specific techniques. When applied to advanced parallel imaging techniques such as 2D VC-GRAPPA and LORAKS, SPARK achieves up to 20% RMSE improvement. SPARK with 3D GRAPPA also improves RMSE performance and perceived image quality without a fully sampled ACS region. Finally, SPARK synergizes with non-cartesian, 2D and 3D wave-encoding imaging by reducing RMSE between 20 - 25% and providing qualitative improvements. Conclusion: SPARK synergizes with physics-based reconstruction techniques to improve accelerated MRI by training scan-specific models to estimate and correct reconstruction errors in k-space.
Walk2Map: Extracting Floor Plans from Indoor Walk Trajectories
Feb 27, 2021

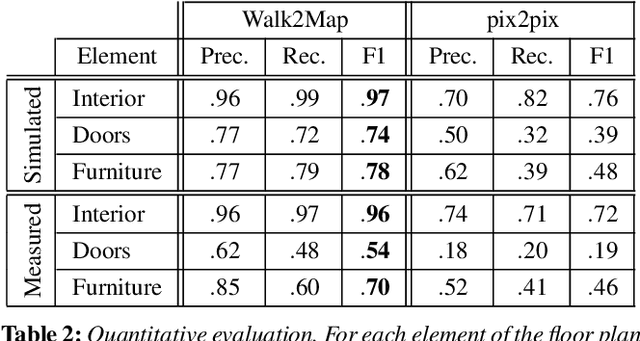
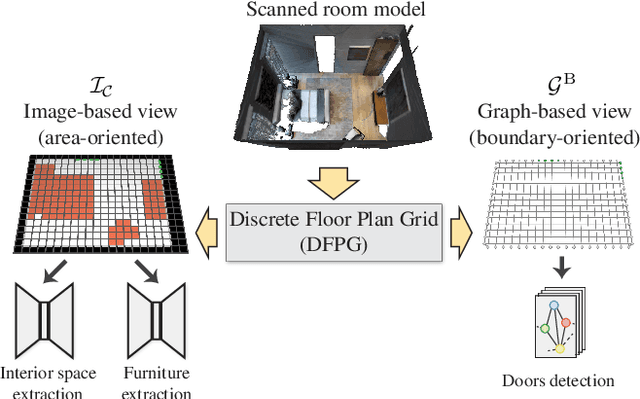
Recent years have seen a proliferation of new digital products for the efficient management of indoor spaces, with important applications like emergency management, virtual property showcasing and interior design. These products rely on accurate 3D models of the environments considered, including information on both architectural and non-permanent elements. These models must be created from measured data such as RGB-D images or 3D point clouds, whose capture and consolidation involves lengthy data workflows. This strongly limits the rate at which 3D models can be produced, preventing the adoption of many digital services for indoor space management. We provide an alternative to such data-intensive procedures by presenting Walk2Map, a data-driven approach to generate floor plans only from trajectories of a person walking inside the rooms. Thanks to recent advances in data-driven inertial odometry, such minimalistic input data can be acquired from the IMU readings of consumer-level smartphones, which allows for an effortless and scalable mapping of real-world indoor spaces. Our work is based on learning the latent relation between an indoor walk trajectory and the information represented in a floor plan: interior space footprint, portals, and furniture. We distinguish between recovering area-related (interior footprint, furniture) and wall-related (doors) information and use two different neural architectures for the two tasks: an image-based Encoder-Decoder and a Graph Convolutional Network, respectively. We train our networks using scanned 3D indoor models and apply them in a cascaded fashion on an indoor walk trajectory at inference time. We perform a qualitative and quantitative evaluation using both simulated and measured, real-world trajectories, and compare against a baseline method for image-to-image translation. The experiments confirm the feasibility of our approach.
Deep Online Fused Video Stabilization
Feb 02, 2021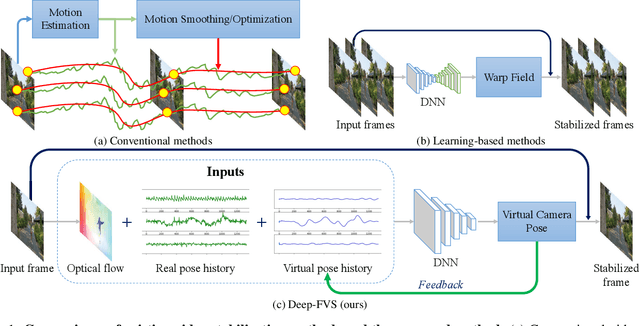
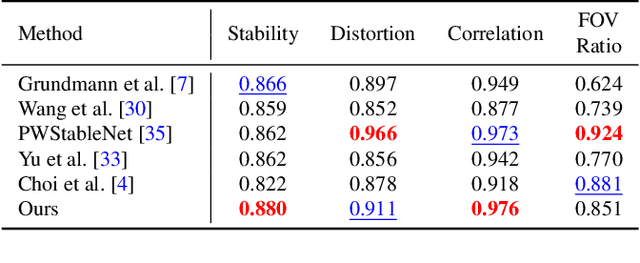
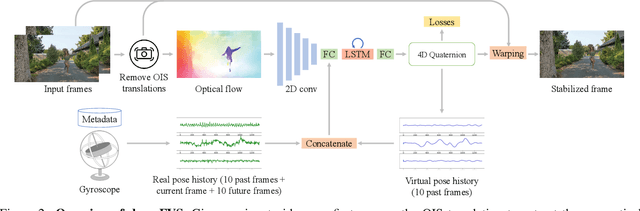
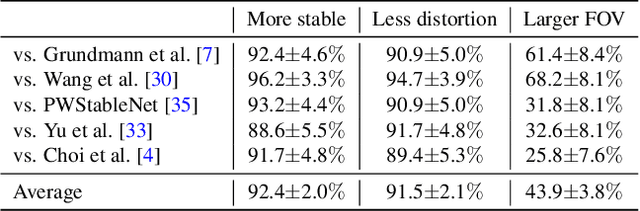
We present a deep neural network (DNN) that uses both sensor data (gyroscope) and image content (optical flow) to stabilize videos through unsupervised learning. The network fuses optical flow with real/virtual camera pose histories into a joint motion representation. Next, the LSTM block infers the new virtual camera pose, and this virtual pose is used to generate a warping grid that stabilizes the frame. Novel relative motion representation as well as a multi-stage training process are presented to optimize our model without any supervision. To the best of our knowledge, this is the first DNN solution that adopts both sensor data and image for stabilization. We validate the proposed framework through ablation studies and demonstrated the proposed method outperforms the state-of-art alternative solutions via quantitative evaluations and a user study.
Synthesize-It-Classifier: Learning a Generative Classifier through RecurrentSelf-analysis
Mar 26, 2021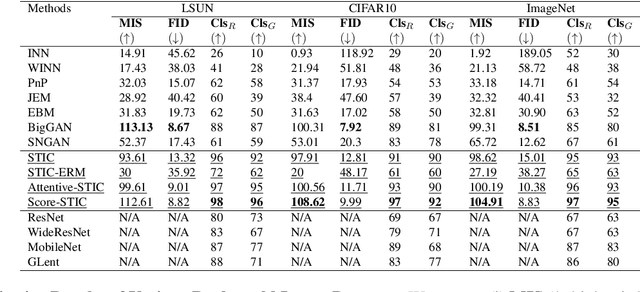
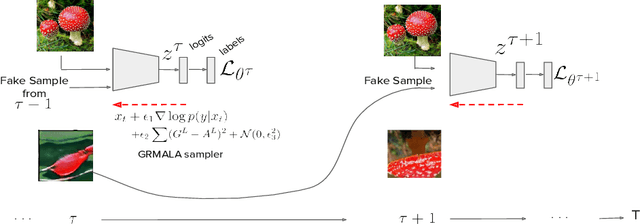


In this work, we show the generative capability of an image classifier network by synthesizing high-resolution, photo-realistic, and diverse images at scale. The overall methodology, called Synthesize-It-Classifier (STIC), does not require an explicit generator network to estimate the density of the data distribution and sample images from that, but instead uses the classifier's knowledge of the boundary to perform gradient ascent w.r.t. class logits and then synthesizes images using Gram Matrix Metropolis Adjusted Langevin Algorithm (GRMALA) by drawing on a blank canvas. During training, the classifier iteratively uses these synthesized images as fake samples and re-estimates the class boundary in a recurrent fashion to improve both the classification accuracy and quality of synthetic images. The STIC shows the mixing of the hard fake samples (i.e. those synthesized by the one hot class conditioning), and the soft fake samples (which are synthesized as a convex combination of classes, i.e. a mixup of classes) improves class interpolation. We demonstrate an Attentive-STIC network that shows an iterative drawing of synthesized images on the ImageNet dataset that has thousands of classes. In addition, we introduce the synthesis using a class conditional score classifier (Score-STIC) instead of a normal image classifier and show improved results on several real-world datasets, i.e. ImageNet, LSUN, and CIFAR 10.
CloudifierNet -- Deep Vision Models for Artificial Image Processing
Nov 04, 2019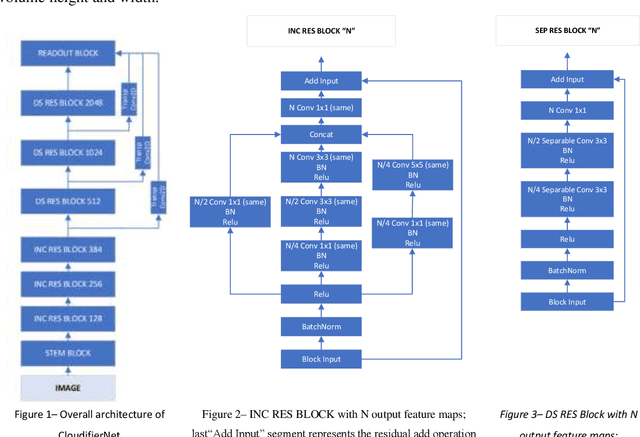
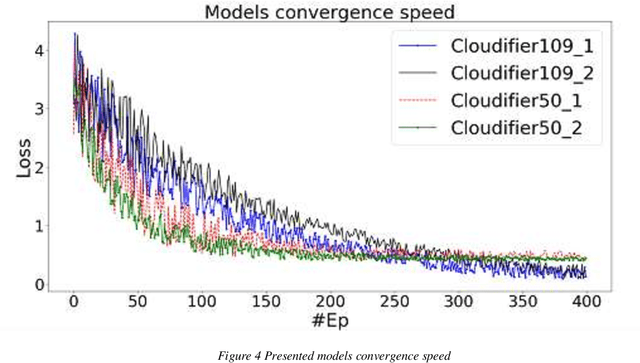
Today, more and more, it is necessary that most applications and documents developed in previous or current technologies to be accessible online on cloud-based infrastructures. That is why the migration of legacy systems including their hosts of documents to new technologies and online infrastructures, using modern Artificial Intelligence techniques, is absolutely necessary. With the advancement of Artificial Intelligence and Deep Learning with its multitude of applications, a new area of research is emerging - that of automated systems development and maintenance. The underlying work objective that led to this paper aims to research and develop truly intelligent systems able to analyze user interfaces from various sources and generate real and usable inferences ranging from architecture analysis to actual code generation. One key element of such systems is that of artificial scene detection and analysis based on deep learning computer vision systems. Computer vision models and particularly deep directed acyclic graphs based on convolutional modules are generally constructed and trained based on natural images datasets. Due to this fact, the models will develop during the training process natural image feature detectors apart from the base graph modules that will learn basic primitive features. In the current paper, we will present the base principles of a deep neural pipeline for computer vision applied to artificial scenes (scenes generated by user interfaces or similar). Finally, we will present the conclusions based on experimental development and benchmarking against state-of-the-art transfer-learning implemented deep vision models.
Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse
Apr 16, 2021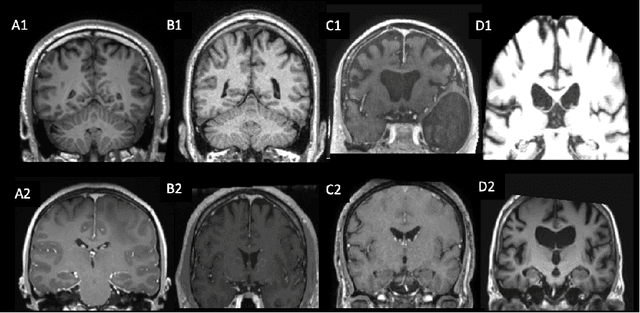
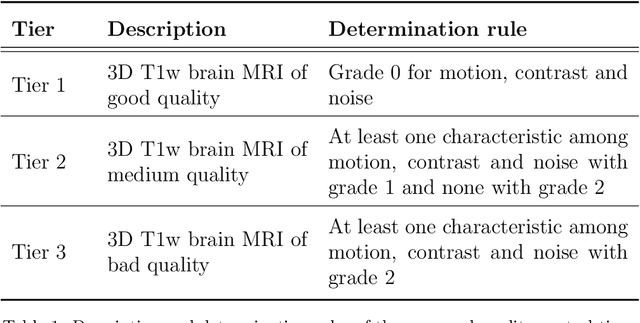
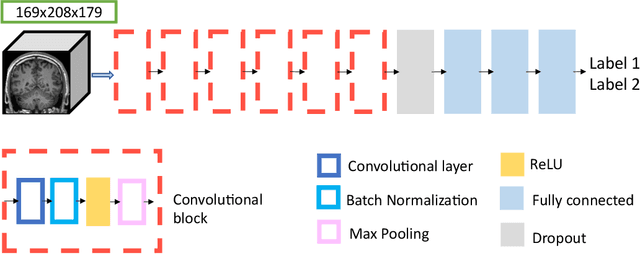
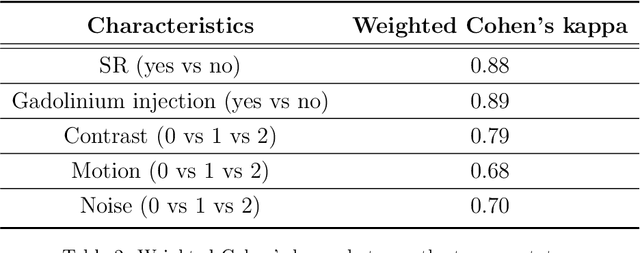
Many studies on machine learning (ML) for computer-aided diagnosis have so far been mostly restricted to high-quality research data. Clinical data warehouses, gathering routine examinations from hospitals, offer great promises for training and validation of ML models in a realistic setting. However, the use of such clinical data warehouses requires quality control (QC) tools. Visual QC by experts is time-consuming and does not scale to large datasets. In this paper, we propose a convolutional neural network (CNN) for the automatic QC of 3D T1-weighted brain MRI for a large heterogeneous clinical data warehouse. To that purpose, we used the data warehouse of the hospitals of the Greater Paris area (Assistance Publique-H\^opitaux de Paris [AP-HP]). Specifically, the objectives were: 1) to identify images which are not proper T1-weighted brain MRIs; 2) to identify acquisitions for which gadolinium was injected; 3) to rate the overall image quality. We used 5000 images for training and validation and a separate set of 500 images for testing. In order to train/validate the CNN, the data were annotated by two trained raters according to a visual QC protocol that we specifically designed for application in the setting of a data warehouse. For objectives 1 and 2, our approach achieved excellent accuracy (balanced accuracy and F1-score \textgreater 90\%), similar to the human raters. For objective 3, the performance was good but substantially lower than that of human raters. Nevertheless, the automatic approach accurately identified (balanced accuracy and F1-score \textgreater 80\%) low quality images, which would typically need to be excluded. Overall, our approach shall be useful for exploiting hospital data warehouses in medical image computing.
Manifold Topology Divergence: a Framework for Comparing Data Manifolds
Jun 08, 2021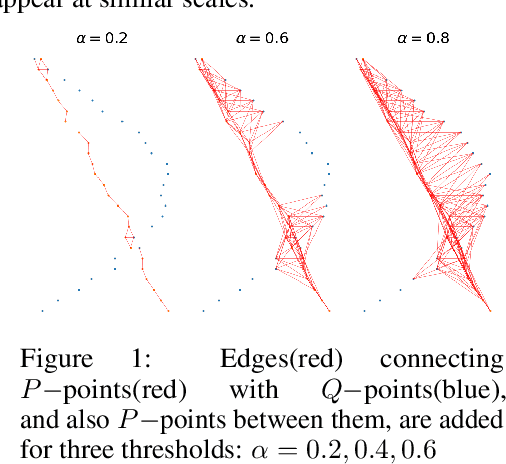
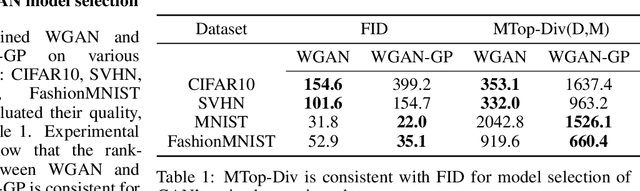
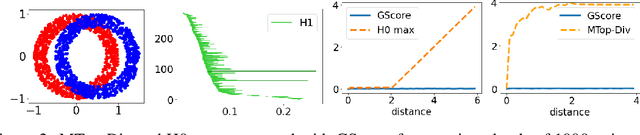
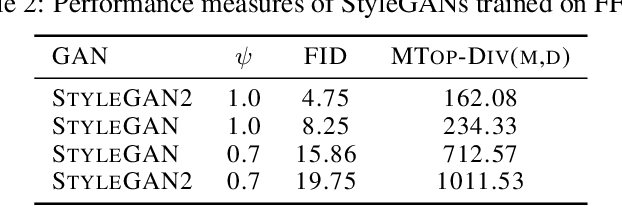
We develop a framework for comparing data manifolds, aimed, in particular, towards the evaluation of deep generative models. We describe a novel tool, Cross-Barcode(P,Q), that, given a pair of distributions in a high-dimensional space, tracks multiscale topology spacial discrepancies between manifolds on which the distributions are concentrated. Based on the Cross-Barcode, we introduce the Manifold Topology Divergence score (MTop-Divergence) and apply it to assess the performance of deep generative models in various domains: images, 3D-shapes, time-series, and on different datasets: MNIST, Fashion MNIST, SVHN, CIFAR10, FFHQ, chest X-ray images, market stock data, ShapeNet. We demonstrate that the MTop-Divergence accurately detects various degrees of mode-dropping, intra-mode collapse, mode invention, and image disturbance. Our algorithm scales well (essentially linearly) with the increase of the dimension of the ambient high-dimensional space. It is one of the first TDA-based practical methodologies that can be applied universally to datasets of different sizes and dimensions, including the ones on which the most recent GANs in the visual domain are trained. The proposed method is domain agnostic and does not rely on pre-trained networks.
Phase retrieval from 4-dimensional electron diffraction datasets
Jun 15, 2021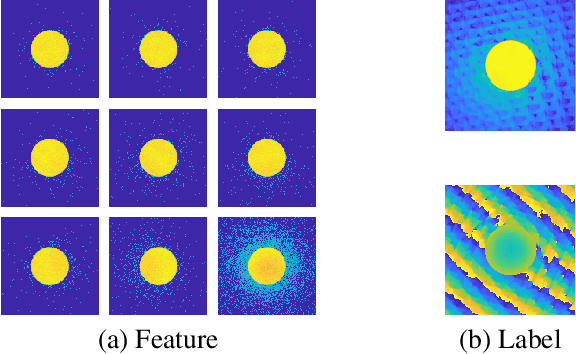
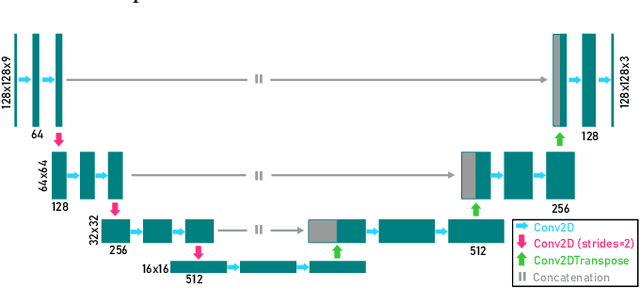
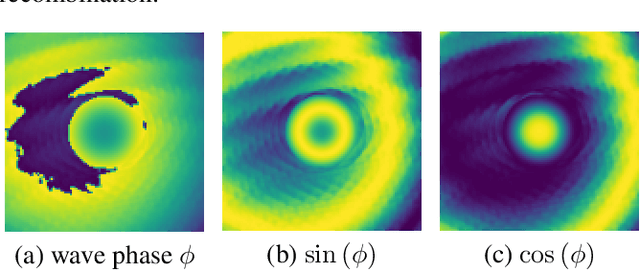
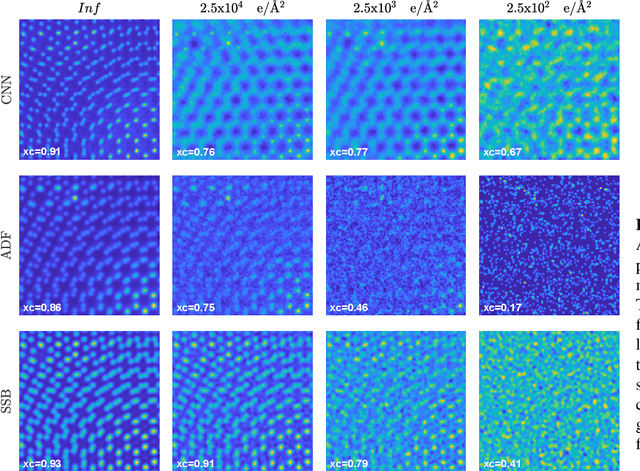
We present a computational imaging mode for large scale electron microscopy data, which retrieves a complex wave from noisy/sparse intensity recordings using a deep learning approach and subsequently reconstructs an image of the specimen from the Convolutional Neural Network (CNN) predicted exit waves. We demonstrate that an appropriate forward model in combination with open data frameworks can be used to generate large synthetic datasets for training. In combination with augmenting the data with Poisson noise corresponding to varying dose-values, we effectively eliminate overfitting issues. The U-NET based architecture of the CNN is adapted to the task at hand and performs well while maintaining a relatively small size and fast performance. The validity of the approach is confirmed by comparing the reconstruction to well-established methods using simulated, as well as real electron microscopy data. The proposed method is shown to be effective particularly in the low dose range, evident by strong suppression of noise, good spatial resolution, and sensitivity to different atom types, enabling the simultaneous visualisation of light and heavy elements and making different atomic species distinguishable. Since the method acts on a very local scale and is comparatively fast it bears the potential to be used for near-real-time reconstruction during data acquisition.