 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DCT-CompCNN: A Novel Image Classification Network Using JPEG Compressed DCT Coefficients
Jul 26, 2019
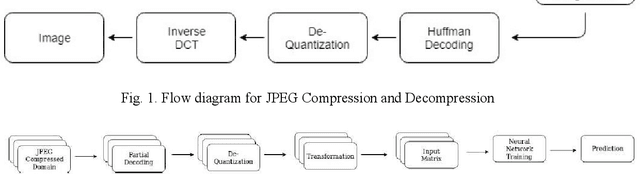
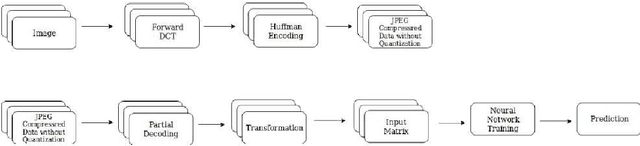
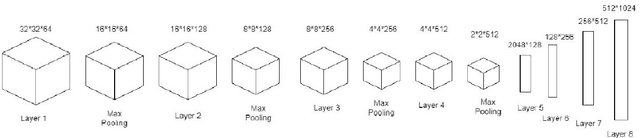
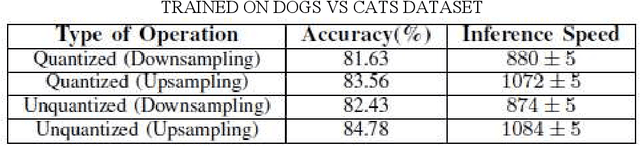
The popularity of Convolutional Neural Network (CNN) in the field of Image Processing and Computer Vision has motivated researchers and industrialist experts across the globe to solve different challenges with high accuracy. The simplest way to train a CNN classifier is to directly feed the original RGB pixels images into the network. However, if we intend to classify images directly with its compressed data, the same approach may not work better, like in case of JPEG compressed images. This research paper investigates the issues of modifying the input representation of the JPEG compressed data, and then feeding into the CNN. The architecture is termed as DCT-CompCNN. This novel approach has shown that CNNs can also be trained with JPEG compressed DCT coefficients, and subsequently can produce a better performance in comparison with the conventional CNN approach. The efficiency of the modified input representation is tested with the existing ResNet-50 architecture and the proposed DCT-CompCNN architecture on a public image classification datasets like Dog Vs Cat and CIFAR-10 datasets, reporting a better performance
Separated-Spectral-Distribution Estimation Based on Bayesian Inference with Single RGB Camera
Jun 01, 2021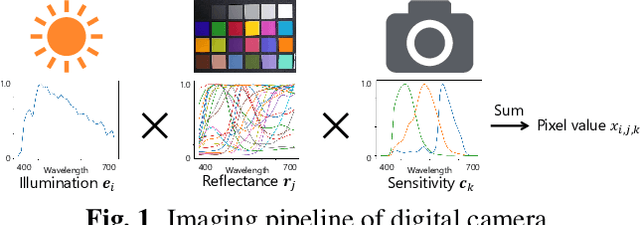
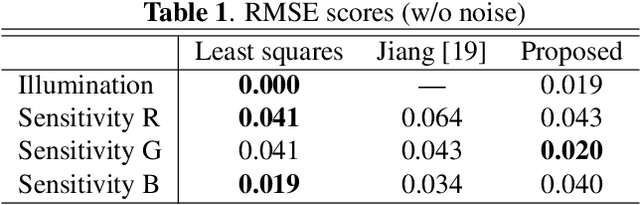
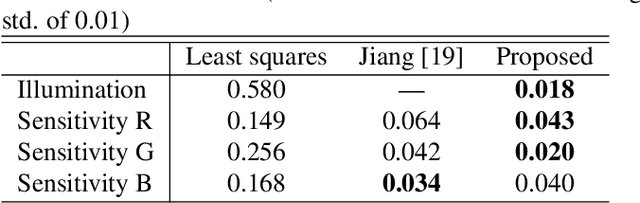
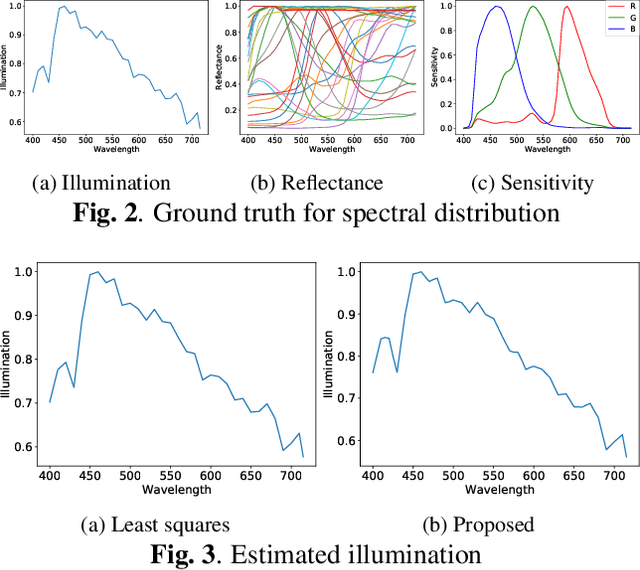
In this paper, we propose a novel method for separately estimating spectral distributions from images captured by a typical RGB camera. The proposed method allows us to separately estimate a spectral distribution of illumination, reflectance, or camera sensitivity, while recent hyperspectral cameras are limited to capturing a joint spectral distribution from a scene. In addition, the use of Bayesian inference makes it possible to take into account prior information of both spectral distributions and image noise as probability distributions. As a result, the proposed method can estimate spectral distributions in a unified way, and it can enhance the robustness of the estimation against noise, which conventional spectral-distribution estimation methods cannot. The use of Bayesian inference also enables us to obtain the confidence of estimation results. In an experiment, the proposed method is shown not only to outperform conventional estimation methods in terms of RMSE but also to be robust against noise.
Neural Affine Grayscale Image Denoising
Sep 17, 2017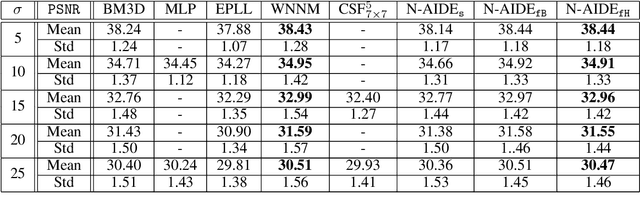
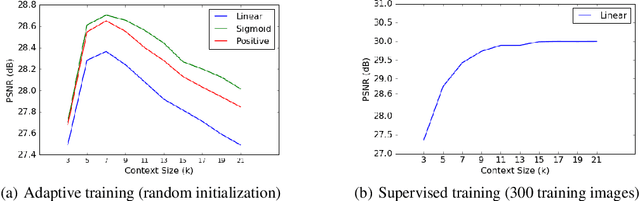
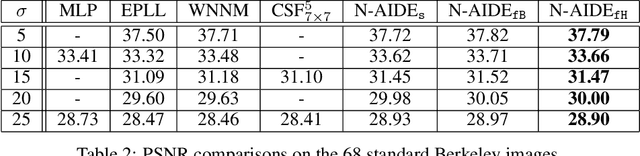
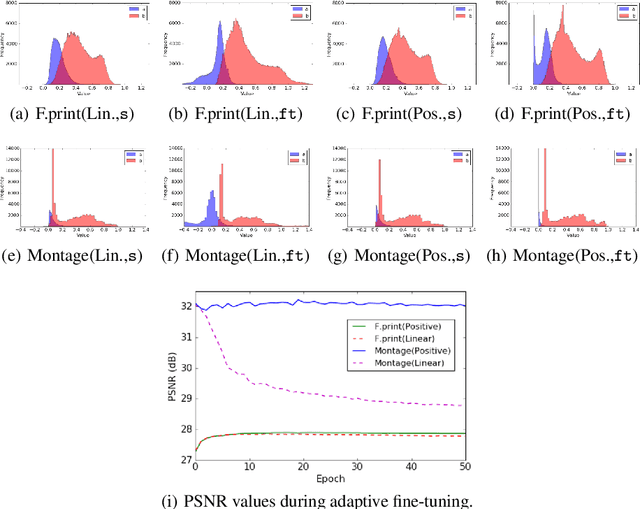
We propose a new grayscale image denoiser, dubbed as Neural Affine Image Denoiser (Neural AIDE), which utilizes neural network in a novel way. Unlike other neural network based image denoising methods, which typically apply simple supervised learning to learn a mapping from a noisy patch to a clean patch, we formulate to train a neural network to learn an \emph{affine} mapping that gets applied to a noisy pixel, based on its context. Our formulation enables both supervised training of the network from the labeled training dataset and adaptive fine-tuning of the network parameters using the given noisy image subject to denoising. The key tool for devising Neural AIDE is to devise an estimated loss function of the MSE of the affine mapping, solely based on the noisy data. As a result, our algorithm can outperform most of the recent state-of-the-art methods in the standard benchmark datasets. Moreover, our fine-tuning method can nicely overcome one of the drawbacks of the patch-level supervised learning methods in image denoising; namely, a supervised trained model with a mismatched noise variance can be mostly corrected as long as we have the matched noise variance during the fine-tuning step.
H-FL: A Hierarchical Communication-Efficient and Privacy-Protected Architecture for Federated Learning
Jun 01, 2021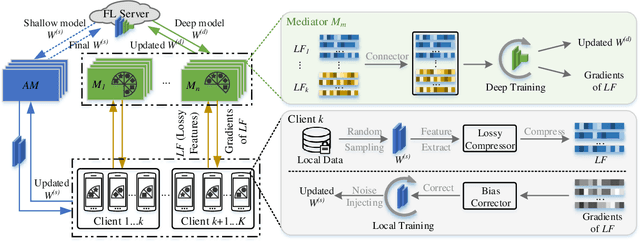

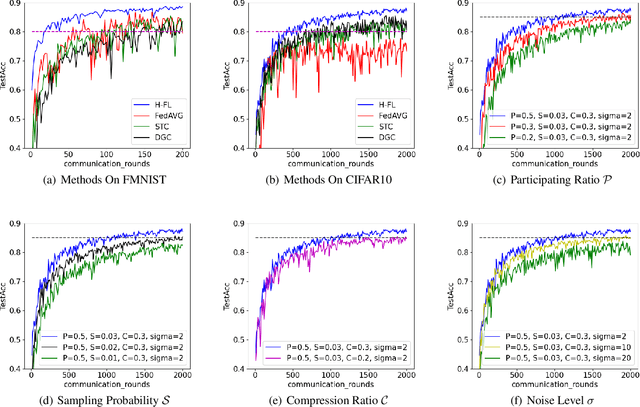

The longstanding goals of federated learning (FL) require rigorous privacy guarantees and low communication overhead while holding a relatively high model accuracy. However, simultaneously achieving all the goals is extremely challenging. In this paper, we propose a novel framework called hierarchical federated learning (H-FL) to tackle this challenge. Considering the degradation of the model performance due to the statistic heterogeneity of the training data, we devise a runtime distribution reconstruction strategy, which reallocates the clients appropriately and utilizes mediators to rearrange the local training of the clients. In addition, we design a compression-correction mechanism incorporated into H-FL to reduce the communication overhead while not sacrificing the model performance. To further provide privacy guarantees, we introduce differential privacy while performing local training, which injects moderate amount of noise into only part of the complete model. Experimental results show that our H-FL framework achieves the state-of-art performance on different datasets for the real-world image recognition tasks.
Connecting Image Denoising and High-Level Vision Tasks via Deep Learning
Sep 06, 2018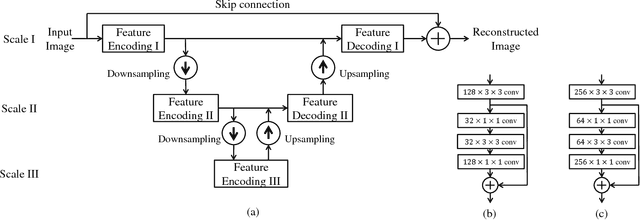
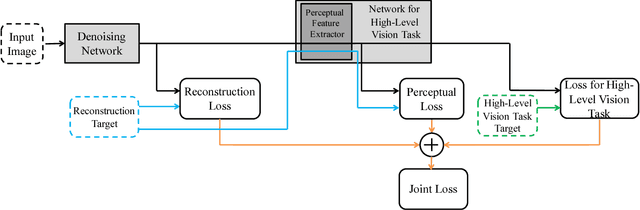

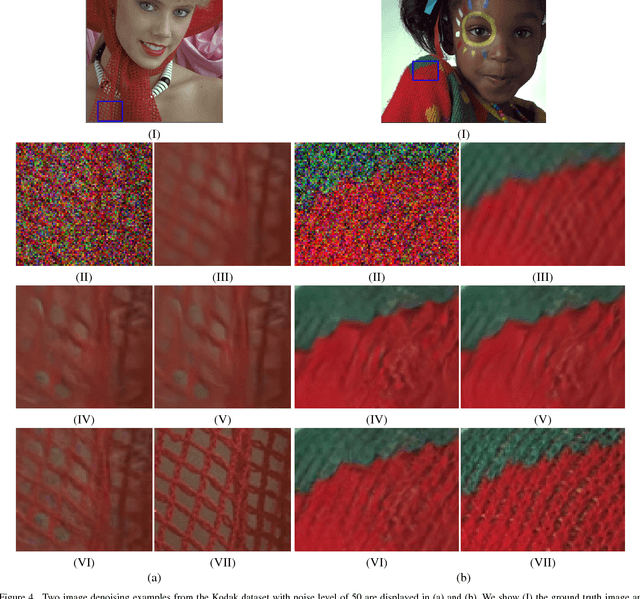
Image denoising and high-level vision tasks are usually handled independently in the conventional practice of computer vision, and their connection is fragile. In this paper, we cope with the two jointly and explore the mutual influence between them with the focus on two questions, namely (1) how image denoising can help improving high-level vision tasks, and (2) how the semantic information from high-level vision tasks can be used to guide image denoising. First for image denoising we propose a convolutional neural network in which convolutions are conducted in various spatial resolutions via downsampling and upsampling operations in order to fuse and exploit contextual information on different scales. Second we propose a deep neural network solution that cascades two modules for image denoising and various high-level tasks, respectively, and use the joint loss for updating only the denoising network via back-propagation. We experimentally show that on one hand, the proposed denoiser has the generality to overcome the performance degradation of different high-level vision tasks. On the other hand, with the guidance of high-level vision information, the denoising network produces more visually appealing results. Extensive experiments demonstrate the benefit of exploiting image semantics simultaneously for image denoising and high-level vision tasks via deep learning. The code is available online: https://github.com/Ding-Liu/DeepDenoising
Fuzzy clustering algorithms with distance metric learning and entropy regularization
Feb 18, 2021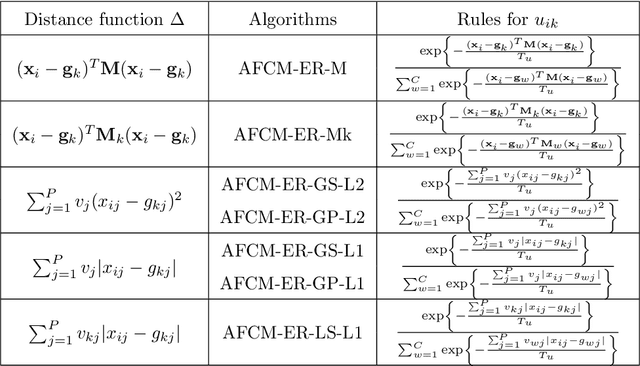
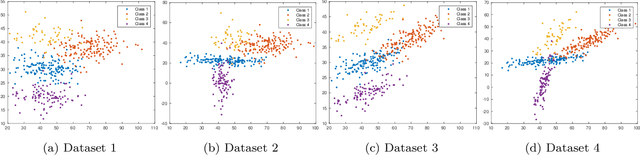
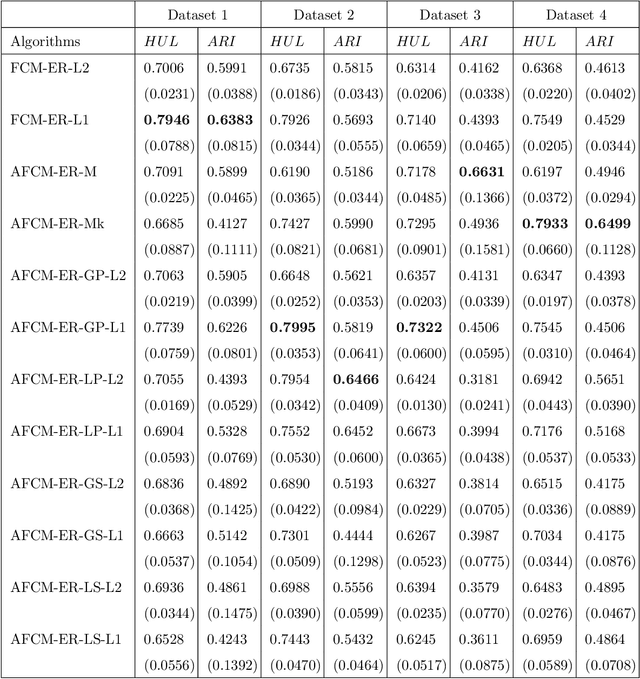
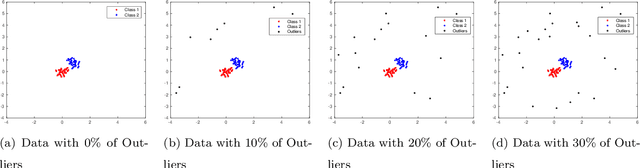
The clustering methods have been used in a variety of fields such as image processing, data mining, pattern recognition, and statistical analysis. Generally, the clustering algorithms consider all variables equally relevant or not correlated for the clustering task. Nevertheless, in real situations, some variables can be correlated or may be more or less relevant or even irrelevant for this task. This paper proposes partitioning fuzzy clustering algorithms based on Euclidean, City-block and Mahalanobis distances and entropy regularization. These methods are an iterative three steps algorithms which provide a fuzzy partition, a representative for each fuzzy cluster, and the relevance weight of the variables or their correlation by minimizing a suitable objective function. Several experiments on synthetic and real datasets, including its application to noisy image texture segmentation, demonstrate the usefulness of these adaptive clustering methods.
Group-Structured Adversarial Training
Jun 18, 2021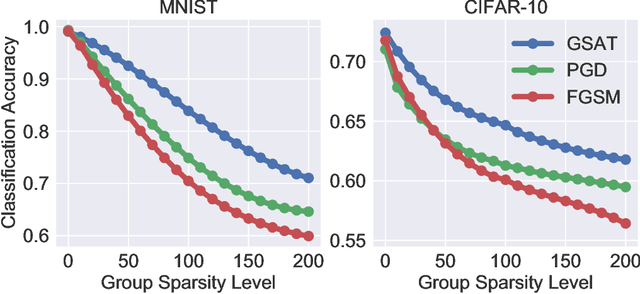
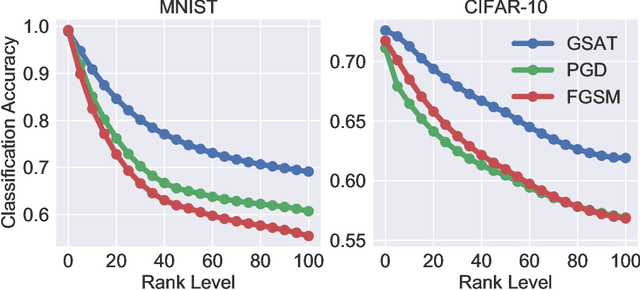
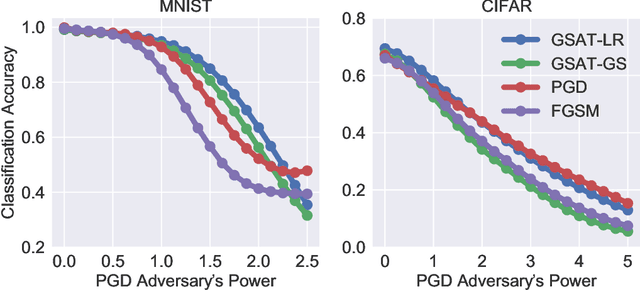
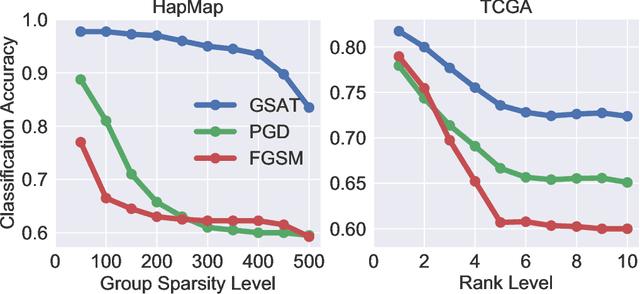
Robust training methods against perturbations to the input data have received great attention in the machine learning literature. A standard approach in this direction is adversarial training which learns a model using adversarially-perturbed training samples. However, adversarial training performs suboptimally against perturbations structured across samples such as universal and group-sparse shifts that are commonly present in biological data such as gene expression levels of different tissues. In this work, we seek to close this optimality gap and introduce Group-Structured Adversarial Training (GSAT) which learns a model robust to perturbations structured across samples. We formulate GSAT as a non-convex concave minimax optimization problem which minimizes a group-structured optimal transport cost. Specifically, we focus on the applications of GSAT for group-sparse and rank-constrained perturbations modeled using group and nuclear norm penalties. In order to solve GSAT's non-smooth optimization problem in those cases, we propose a new minimax optimization algorithm called GDADMM by combining Gradient Descent Ascent (GDA) and Alternating Direction Method of Multipliers (ADMM). We present several applications of the GSAT framework to gain robustness against structured perturbations for image recognition and computational biology datasets.
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021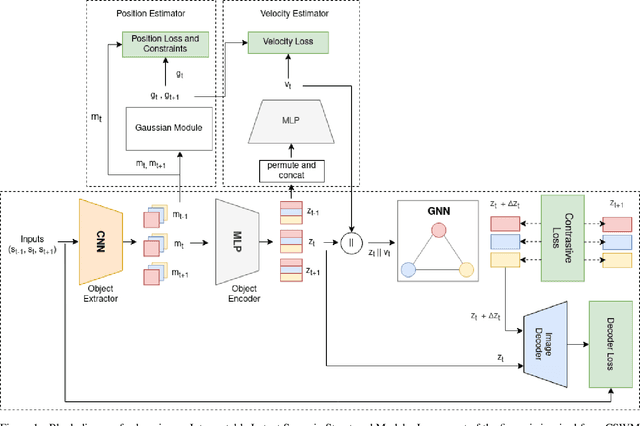
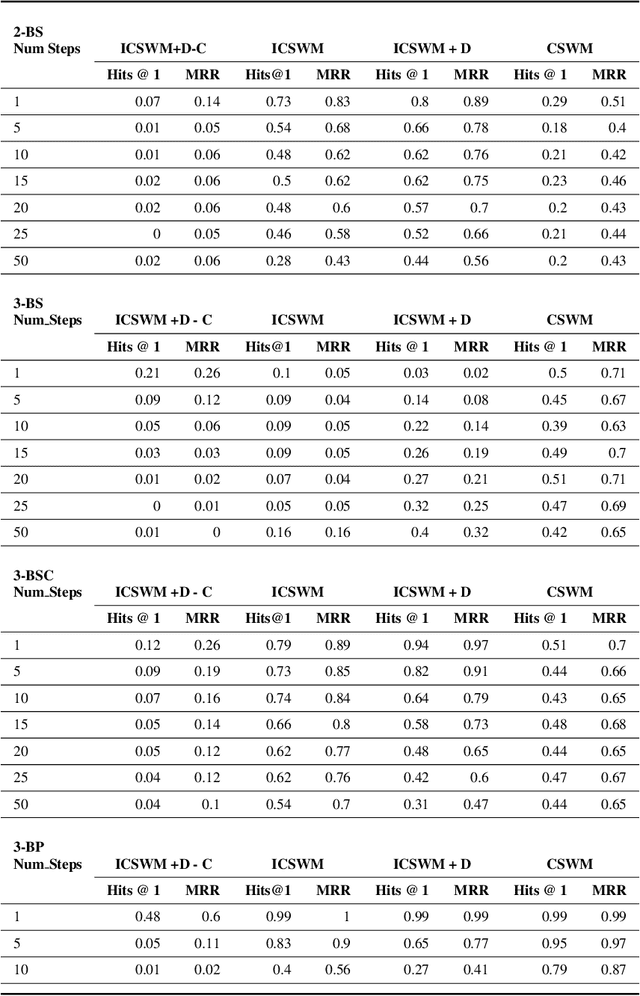
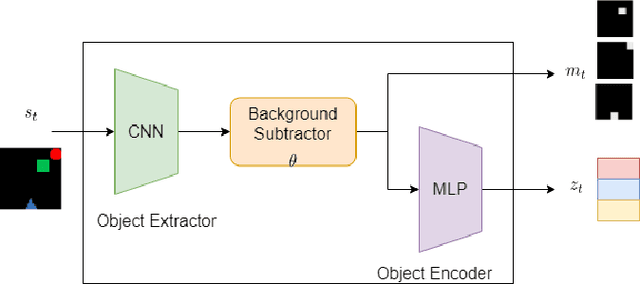
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.
Scene Retrieval for Contextual Visual Mapping
Feb 25, 2021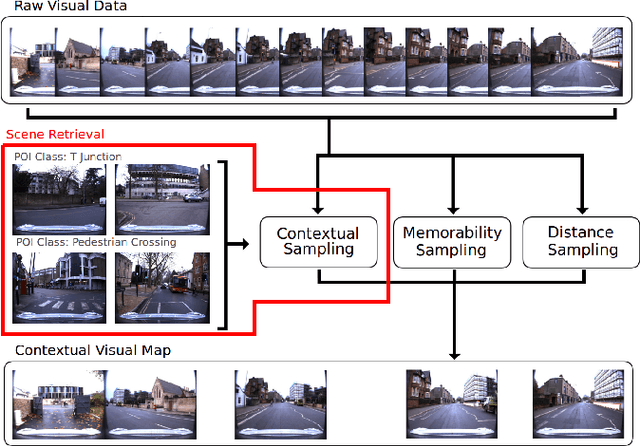

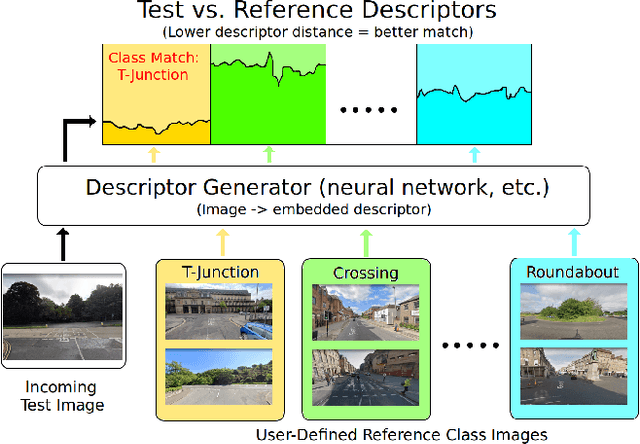
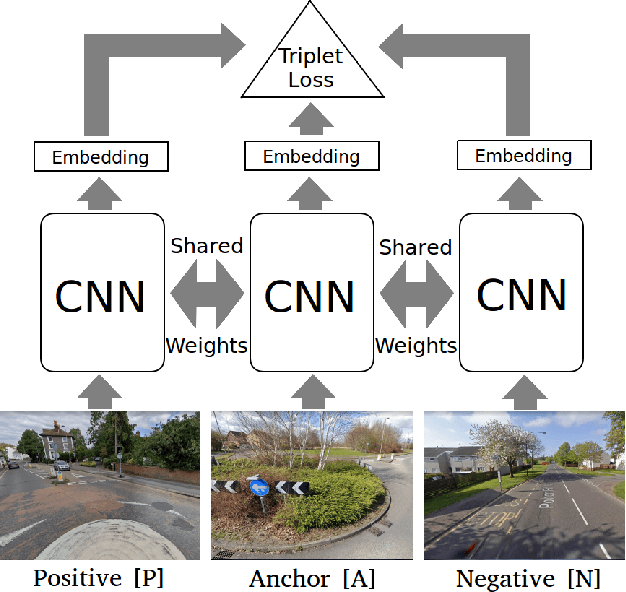
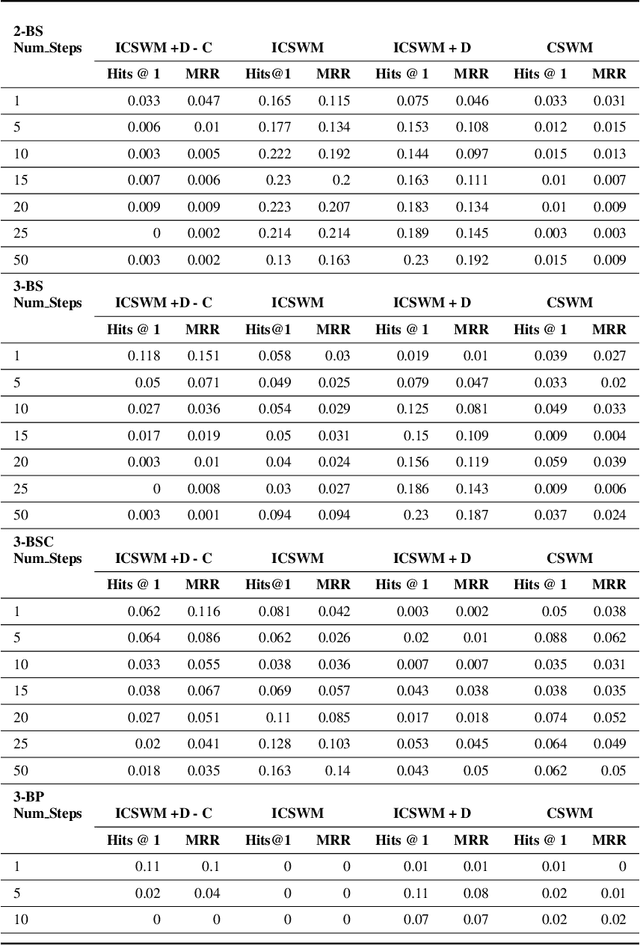
Visual navigation localizes a query place image against a reference database of place images, also known as a `visual map'. Localization accuracy requirements for specific areas of the visual map, `scene classes', vary according to the context of the environment and task. State-of-the-art visual mapping is unable to reflect these requirements by explicitly targetting scene classes for inclusion in the map. Four different scene classes, including pedestrian crossings and stations, are identified in each of the Nordland and St. Lucia datasets. Instead of re-training separate scene classifiers which struggle with these overlapping scene classes we make our first contribution: defining the problem of `scene retrieval'. Scene retrieval extends image retrieval to classification of scenes defined at test time by associating a single query image to reference images of scene classes. Our second contribution is a triplet-trained convolutional neural network (CNN) to address this problem which increases scene classification accuracy by up to 7% against state-of-the-art networks pre-trained for scene recognition. The second contribution is an algorithm `DMC' that combines our scene classification with distance and memorability for visual mapping. Our analysis shows that DMC includes 64% more images of our chosen scene classes in a visual map than just using distance interval mapping. State-of-the-art visual place descriptors AMOS-Net, Hybrid-Net and NetVLAD are finally used to show that DMC improves scene class localization accuracy by a mean of 3% and localization accuracy of the remaining map images by a mean of 10% across both datasets.
Hybrid Generative Models for Two-Dimensional Datasets
Jun 01, 2021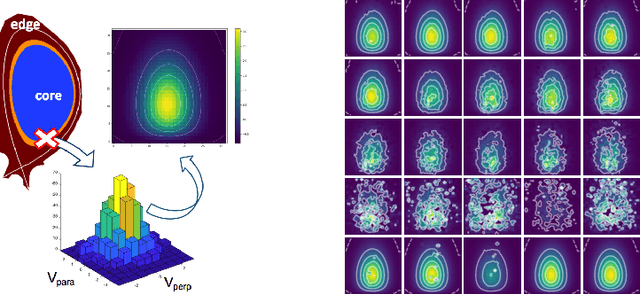
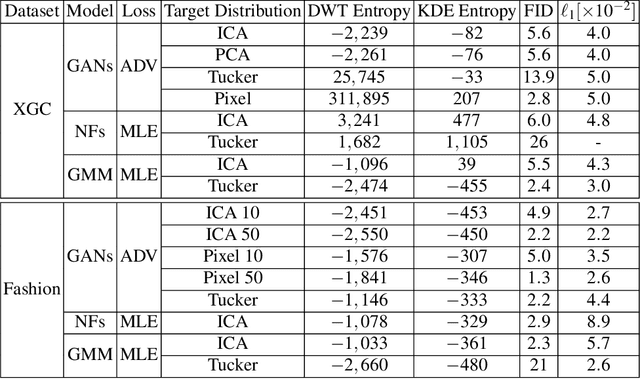

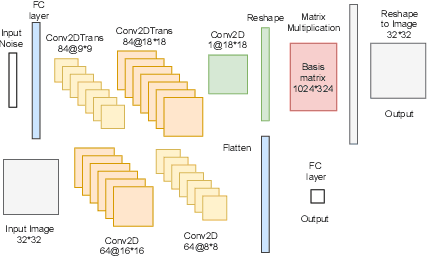
Two-dimensional array-based datasets are pervasive in a variety of domains. Current approaches for generative modeling have typically been limited to conventional image datasets and performed in the pixel domain which do not explicitly capture the correlation between pixels. Additionally, these approaches do not extend to scientific and other applications where each element value is continuous and is not limited to a fixed range. In this paper, we propose a novel approach for generating two-dimensional datasets by moving the computations to the space of representation bases and show its usefulness for two different datasets, one from imaging and another from scientific computing. The proposed approach is general and can be applied to any dataset, representation basis, or generative model. We provide a comprehensive performance comparison of various combinations of generative models and representation basis spaces. We also propose a new evaluation metric which captures the deficiency of generating images in pixel space.