 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAG-GAN: Semi-Supervised Attention-Guided GANs for Data Augmentation on Medical Images
Nov 15, 2020
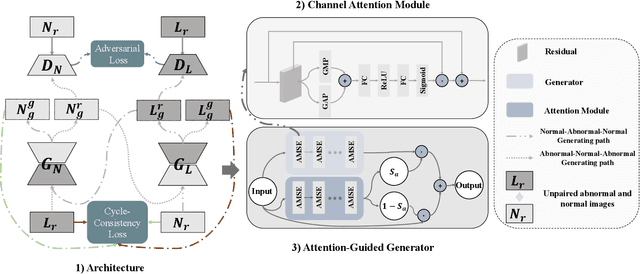
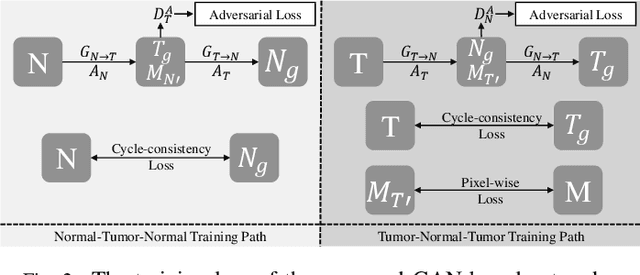
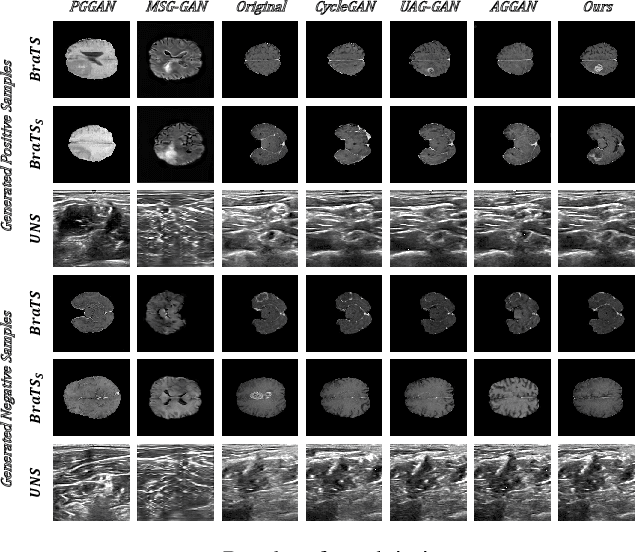
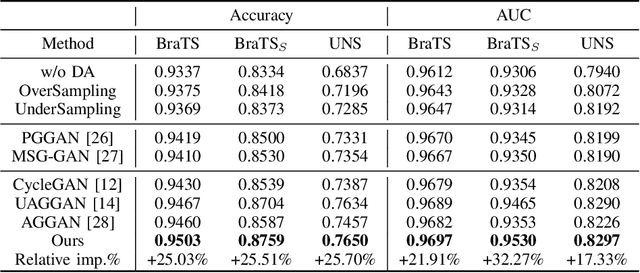
Recently deep learning methods, in particular, convolutional neural networks (CNNs), have led to a massive breakthrough in the range of computer vision. Also, the large-scale annotated dataset is the essential key to a successful training procedure. However, it is a huge challenge to get such datasets in the medical domain. Towards this, we present a data augmentation method for generating synthetic medical images using cycle-consistency Generative Adversarial Networks (GANs). We add semi-supervised attention modules to generate images with convincing details. We treat tumor images and normal images as two domains. The proposed GANs-based model can generate a tumor image from a normal image, and in turn, it can also generate a normal image from a tumor image. Furthermore, we show that generated medical images can be used for improving the performance of ResNet18 for medical image classification. Our model is applied to three limited datasets of tumor MRI images. We first generate MRI images on limited datasets, then we trained three popular classification models to get the best model for tumor classification. Finally, we train the classification model using real images with classic data augmentation methods and classification models using synthetic images. The classification results between those trained models showed that the proposed SAG-GAN data augmentation method can boost Accuracy and AUC compare with classic data augmentation methods. We believe the proposed data augmentation method can apply to other medical image domains, and improve the accuracy of computer-assisted diagnosis.
Size Matters
Feb 09, 2021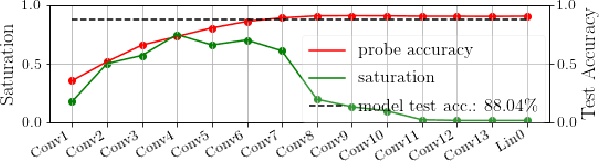
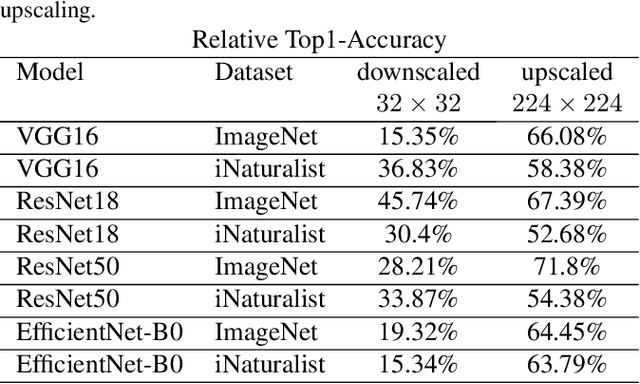
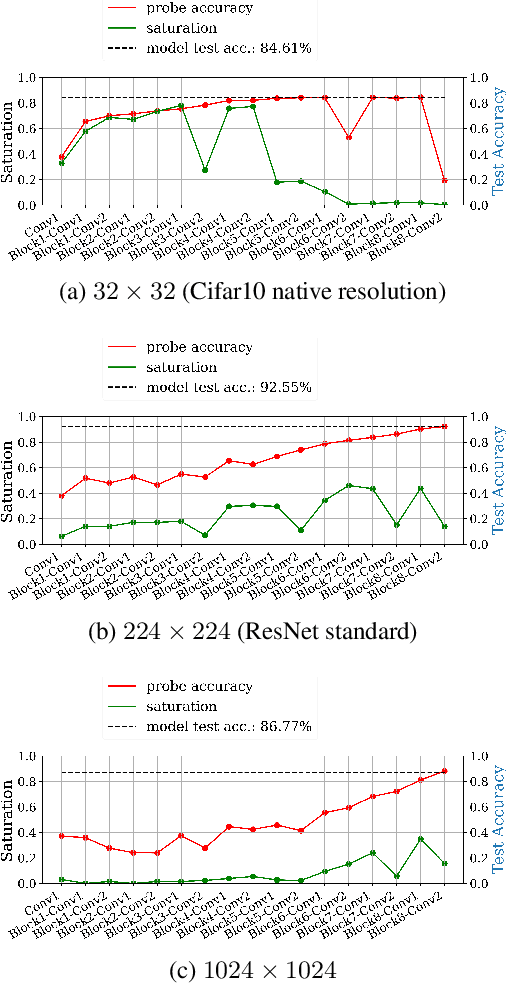
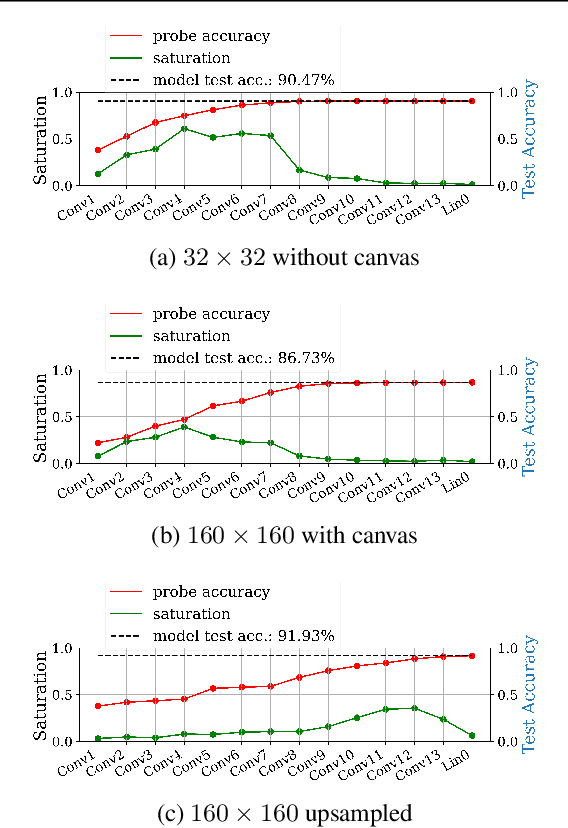
Fully convolutional neural networks can process input of arbitrary size by applying a combination of downsampling and pooling. However, we find that fully convolutional image classifiers are not agnostic to the input size but rather show significant differences in performance: presenting the same image at different scales can result in different outcomes. A closer look reveals that there is no simple relationship between input size and model performance (no `bigger is better'), but that each each network has a preferred input size, for which it shows best results. We investigate this phenomenon by applying different methods, including spectral analysis of layer activations and probe classifiers, showing that there are characteristic features depending on the network architecture. From this we find that the size of discriminatory features is critically influencing how the inference process is distributed among the layers.
Energy-Efficient Model Compression and Splitting for Collaborative Inference Over Time-Varying Channels
Jun 02, 2021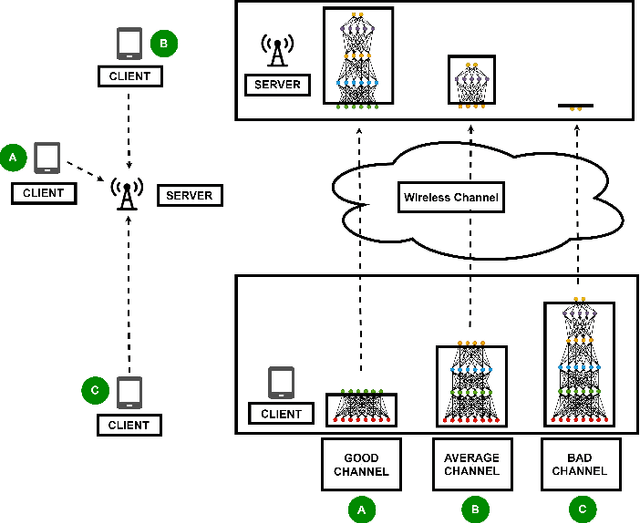
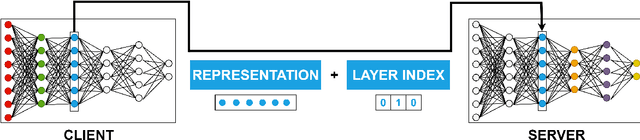
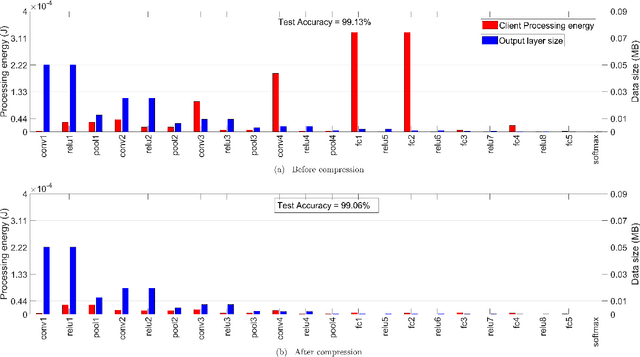
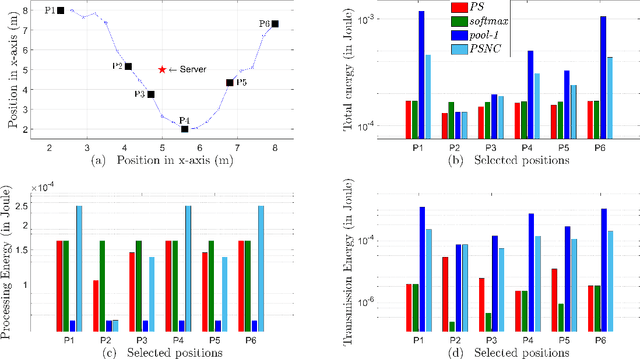
Today's intelligent applications can achieve high performance accuracy using machine learning (ML) techniques, such as deep neural networks (DNNs). Traditionally, in a remote DNN inference problem, an edge device transmits raw data to a remote node that performs the inference task. However, this may incur high transmission energy costs and puts data privacy at risk. In this paper, we propose a technique to reduce the total energy bill at the edge device by utilizing model compression and time-varying model split between the edge and remote nodes. The time-varying representation accounts for time-varying channels and can significantly reduce the total energy at the edge device while maintaining high accuracy (low loss). We implement our approach in an image classification task using the MNIST dataset, and the system environment is simulated as a trajectory navigation scenario to emulate different channel conditions. Numerical simulations show that our proposed solution results in minimal energy consumption and $CO_2$ emission compared to the considered baselines while exhibiting robust performance across different channel conditions and bandwidth regime choices.
Deep Snapshot HDR Imaging Using Multi-Exposure Color Filter Array
Nov 20, 2020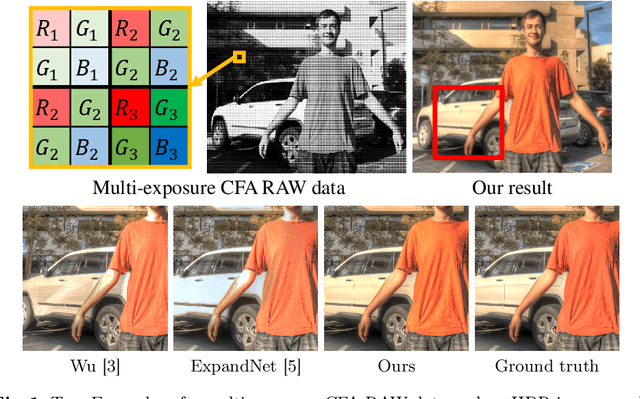
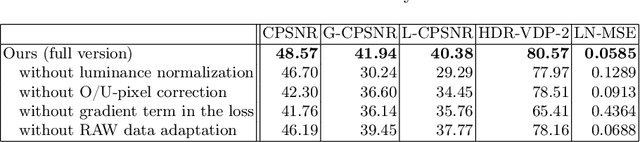
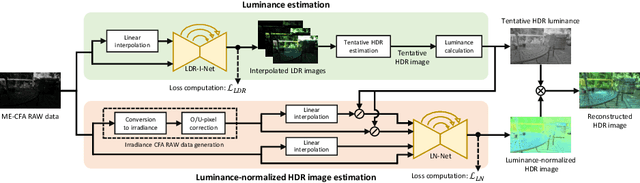

In this paper, we propose a deep snapshot high dynamic range (HDR) imaging framework that can effectively reconstruct an HDR image from the RAW data captured using a multi-exposure color filter array (ME-CFA), which consists of a mosaic pattern of RGB filters with different exposure levels. To effectively learn the HDR image reconstruction network, we introduce the idea of luminance normalization that simultaneously enables effective loss computation and input data normalization by considering relative local contrasts in the "normalized-by-luminance" HDR domain. This idea makes it possible to equally handle the errors in both bright and dark areas regardless of absolute luminance levels, which significantly improves the visual image quality in a tone-mapped domain. Experimental results using two public HDR image datasets demonstrate that our framework outperforms other snapshot methods and produces high-quality HDR images with fewer visual artifacts.
Semantic annotation for computational pathology: Multidisciplinary experience and best practice recommendations
Jun 25, 2021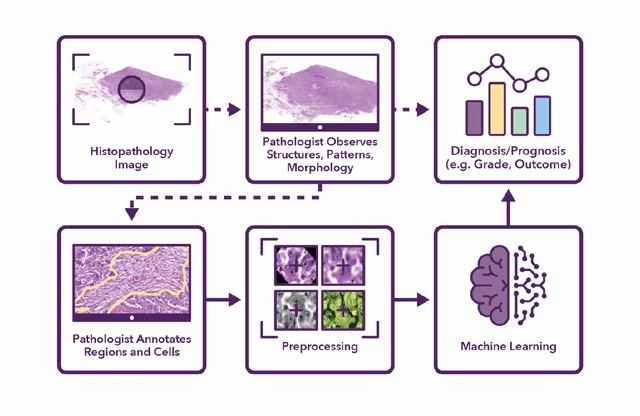

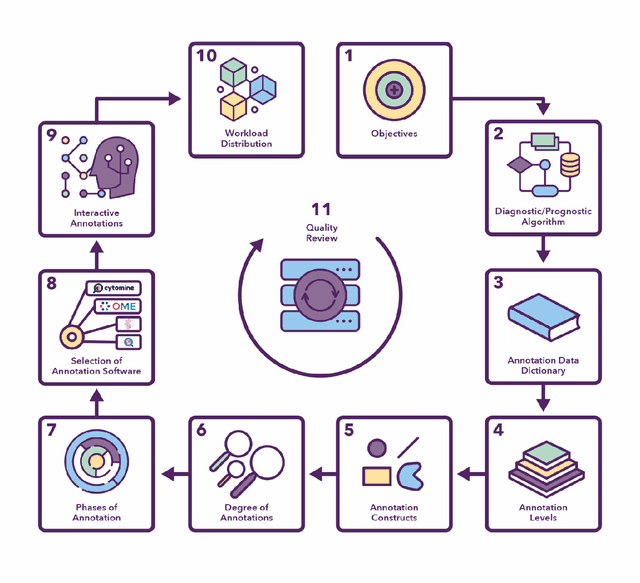
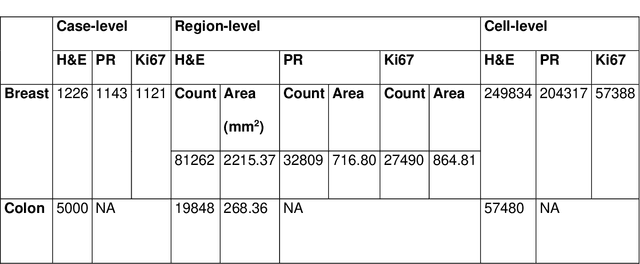
Recent advances in whole slide imaging (WSI) technology have led to the development of a myriad of computer vision and artificial intelligence (AI) based diagnostic, prognostic, and predictive algorithms. Computational Pathology (CPath) offers an integrated solution to utilize information embedded in pathology WSIs beyond what we obtain through visual assessment. For automated analysis of WSIs and validation of machine learning (ML) models, annotations at the slide, tissue and cellular levels are required. The annotation of important visual constructs in pathology images is an important component of CPath projects. Improper annotations can result in algorithms which are hard to interpret and can potentially produce inaccurate and inconsistent results. Despite the crucial role of annotations in CPath projects, there are no well-defined guidelines or best practices on how annotations should be carried out. In this paper, we address this shortcoming by presenting the experience and best practices acquired during the execution of a large-scale annotation exercise involving a multidisciplinary team of pathologists, ML experts and researchers as part of the Pathology image data Lake for Analytics, Knowledge and Education (PathLAKE) consortium. We present a real-world case study along with examples of different types of annotations, diagnostic algorithm, annotation data dictionary and annotation constructs. The analyses reported in this work highlight best practice recommendations that can be used as annotation guidelines over the lifecycle of a CPath project.
Self-EMD: Self-Supervised Object Detection without ImageNet
Dec 08, 2020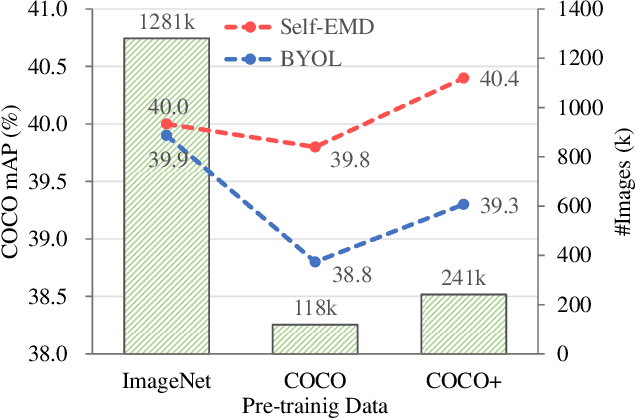
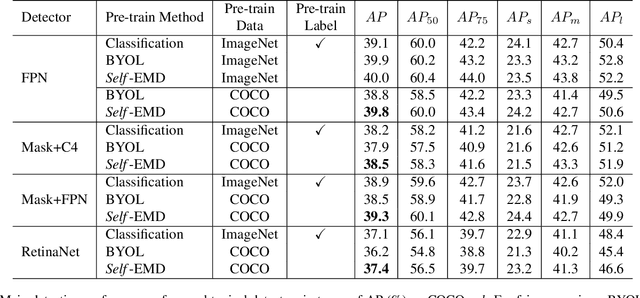

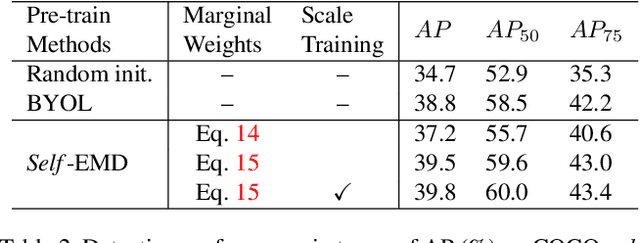
In this paper, we propose a novel self-supervised representation learning method, Self-EMD, for object detection. Our method directly trained on unlabeled non-iconic image dataset like COCO, instead of commonly used iconic-object image dataset like ImageNet. We keep the convolutional feature maps as the image embedding to preserve spatial structures and adopt Earth Mover's Distance (EMD) to compute the similarity between two embeddings. Our Faster R-CNN (ResNet50-FPN) baseline achieves 39.8% mAP on COCO, which is on par with the state of the art self-supervised methods pre-trained on ImageNet. More importantly, it can be further improved to 40.4% mAP with more unlabeled images, showing its great potential for leveraging more easily obtained unlabeled data. Code will be made available.
Latent Variable Models for Visual Question Answering
Jan 16, 2021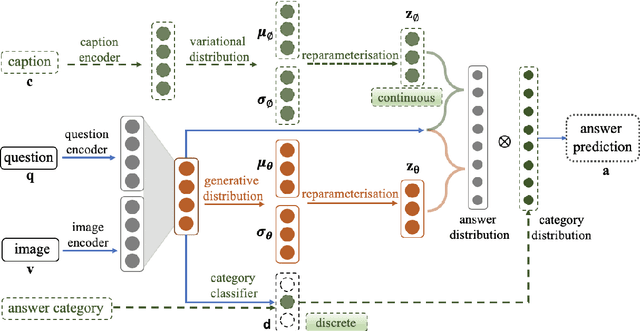
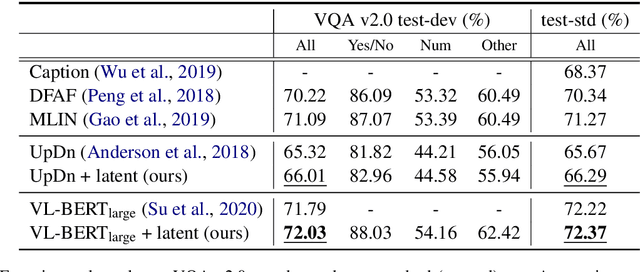

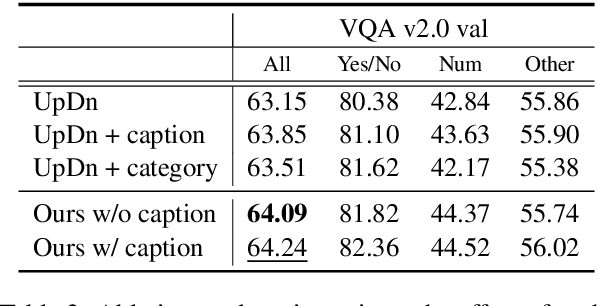
Conventional models for Visual Question Answering (VQA) explore deterministic approaches with various types of image features, question features, and attention mechanisms. However, there exist other modalities that can be explored in addition to image and question pairs to bring extra information to the models. In this work, we propose latent variable models for VQA where extra information (e.g. captions and answer categories) are incorporated as latent variables to improve inference, which in turn benefits question-answering performance. Experiments on the VQA v2.0 benchmarking dataset demonstrate the effectiveness of our proposed models in that they improve over strong baselines, especially those that do not rely on extensive language-vision pre-training.
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021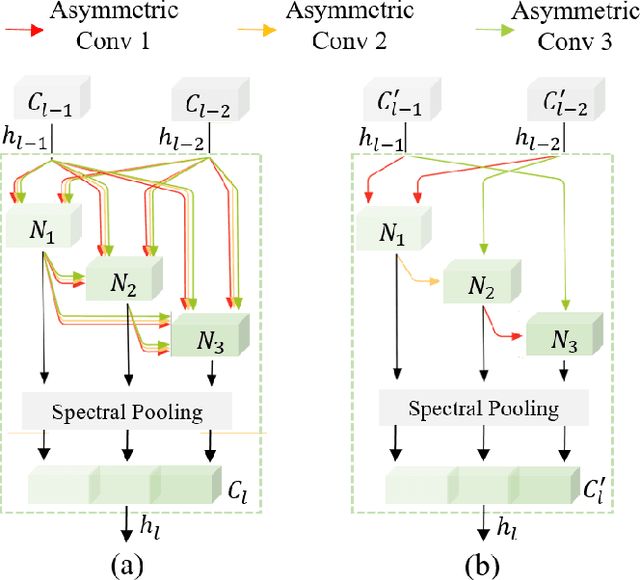
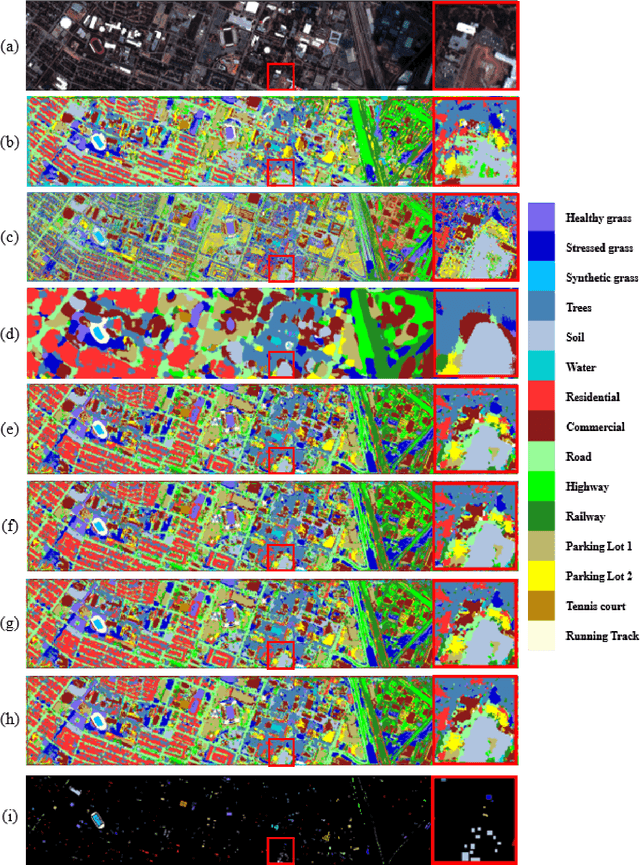
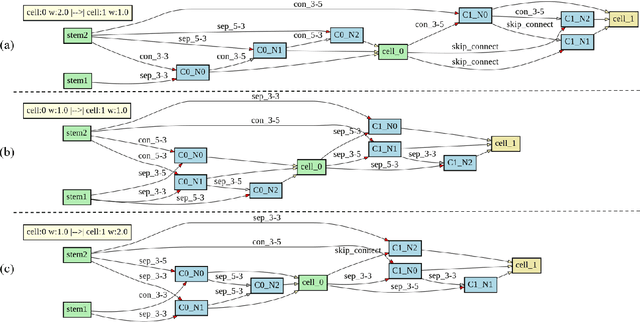
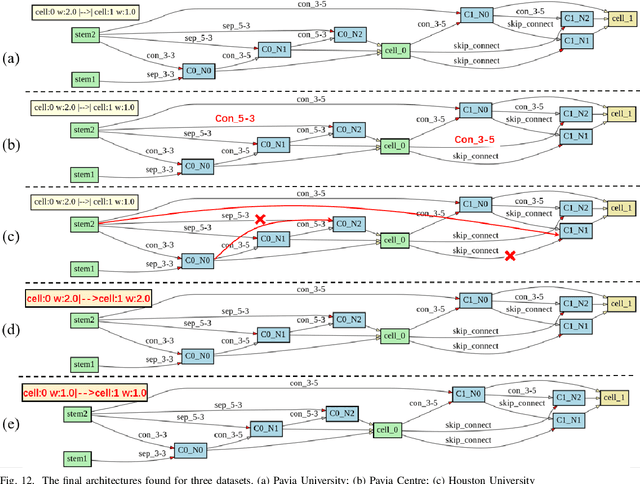
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Infrared Beacons for Robust Localization
Apr 19, 2021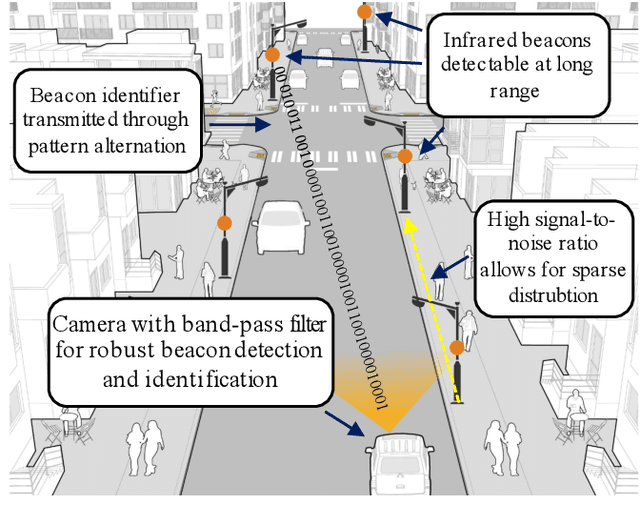
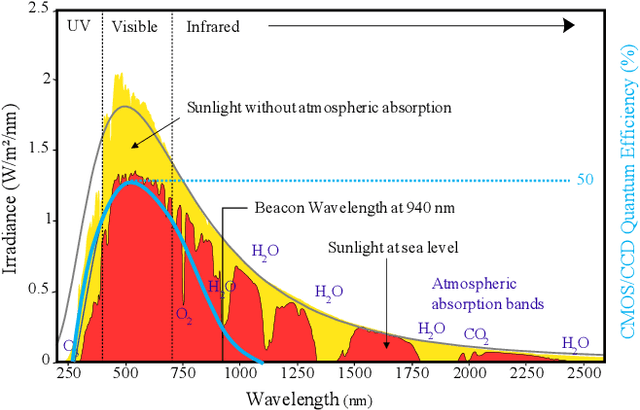


This paper presents a localization system that uses infrared beacons and a camera equipped with an optical band-pass filter. Our system can reliably detect and identify individual beacons at 100m distance regardless of lighting conditions. We describe the camera and beacon design as well as the image processing pipeline in detail. In our experiments, we investigate and demonstrate the ability of the system to recognize our beacons in both daytime and nighttime conditions. High precision localization is a key enabler for automated vehicles but remains unsolved, despite strong recent improvements. Our low-cost, infrastructure-based approach helps solve the localization problem. All datasets are made available.
Transferable Adversarial Attacks for Image and Video Object Detection
Dec 13, 2018
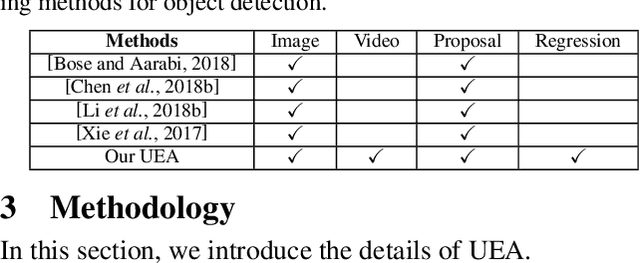
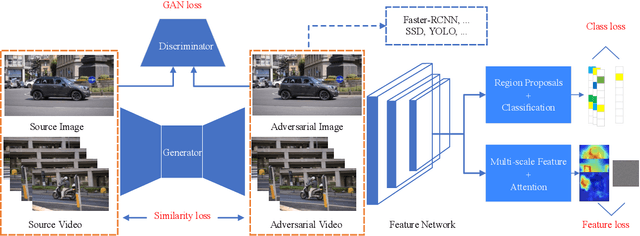
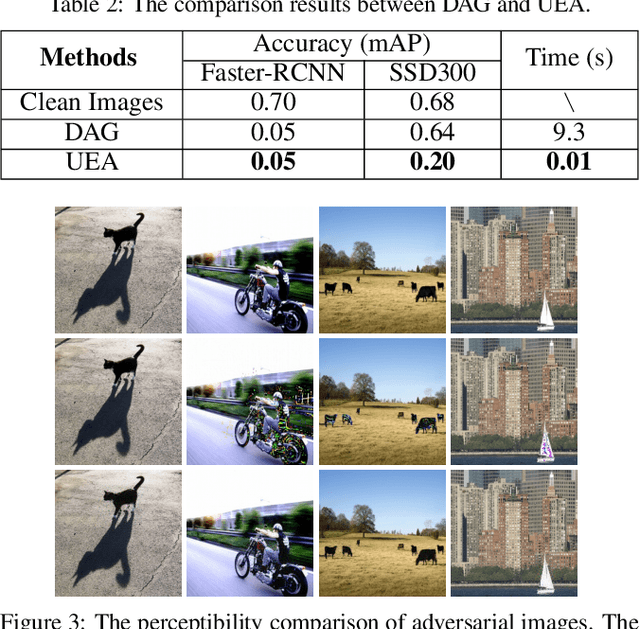
Adversarial examples have been demonstrated to threaten many computer vision tasks including object detection. However, the existing attacking methods for object detection have two limitations: poor transferability, which denotes that the generated adversarial examples have low success rate to attack other kinds of detection methods, and high computation cost, which means that they need more time to generate an adversarial image, and therefore are difficult to deal with the video data. To address these issues, we utilize a generative mechanism to obtain the adversarial image and video. In this way, the processing time is reduced. To enhance the transferability, we destroy the feature maps extracted from the feature network, which usually constitutes the basis of object detectors. The proposed method is based on the Generative Adversarial Network (GAN) framework, where we combine the high-level class loss and low-level feature loss to jointly train the adversarial example generator. A series of experiments conducted on PASCAL VOC and ImageNet VID datasets show that our method can efficiently generate image and video adversarial examples, and more importantly, these adversarial examples have better transferability, and thus, are able to simultaneously attack two kinds of representative object detection models: proposal based models like Faster-RCNN, and regression based models like SSD.