 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Latent Correlation-Based Multiview Learning and Self-Supervision: A Unifying Perspective
Jun 17, 2021
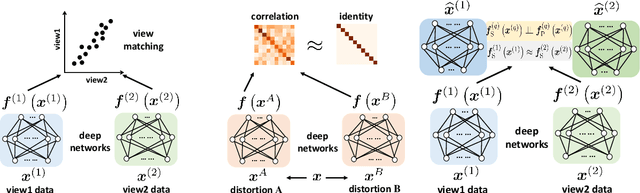
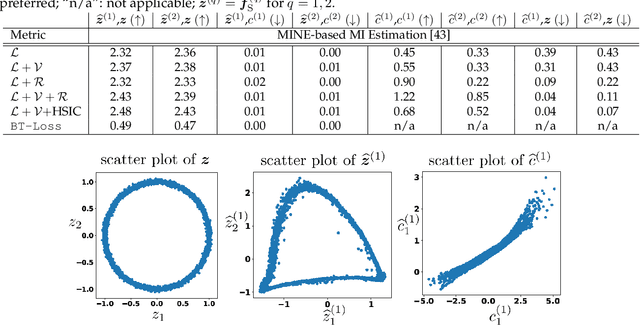
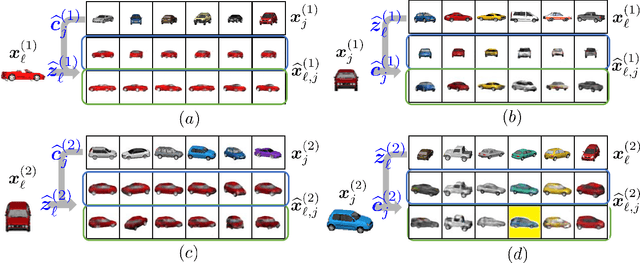
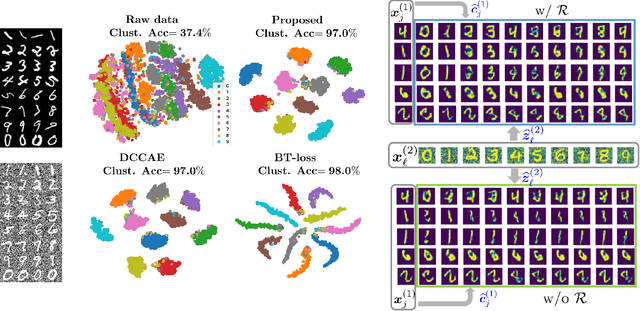
Multiple views of data, both naturally acquired (e.g., image and audio) and artificially produced (e.g., via adding different noise to data samples), have proven useful in enhancing representation learning. Natural views are often handled by multiview analysis tools, e.g., (deep) canonical correlation analysis [(D)CCA], while the artificial ones are frequently used in self-supervised learning (SSL) paradigms, e.g., SimCLR and Barlow Twins. Both types of approaches often involve learning neural feature extractors such that the embeddings of data exhibit high cross-view correlations. Although intuitive, the effectiveness of correlation-based neural embedding is only empirically validated. This work puts forth a theory-backed framework for unsupervised multiview learning. Our development starts with proposing a multiview model, where each view is a nonlinear mixture of shared and private components. Consequently, the learning problem boils down to shared/private component identification and disentanglement. Under this model, latent correlation maximization is shown to guarantee the extraction of the shared components across views (up to certain ambiguities). In addition, the private information in each view can be provably disentangled from the shared using proper regularization design. The method is tested on a series of tasks, e.g., downstream clustering, which all show promising performance. Our development also provides a unifying perspective for understanding various DCCA and SSL schemes.
Measurement-Adaptive Sparse Image Sampling and Recovery
Nov 23, 2017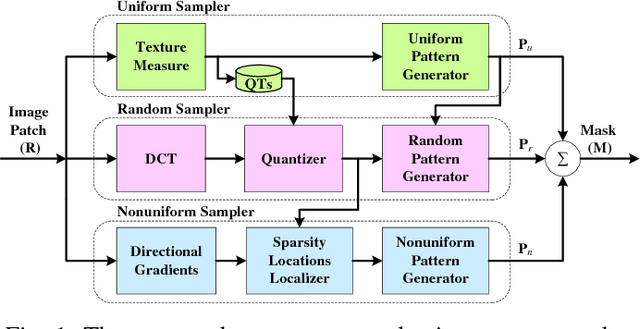
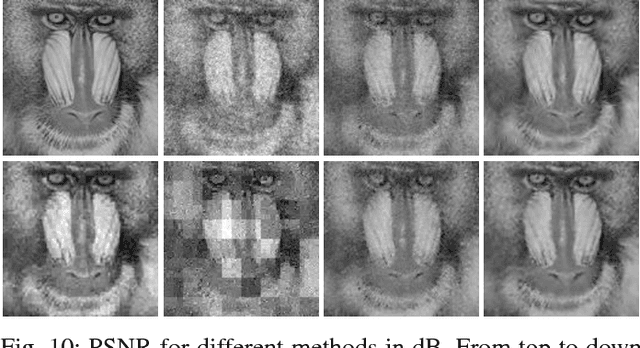
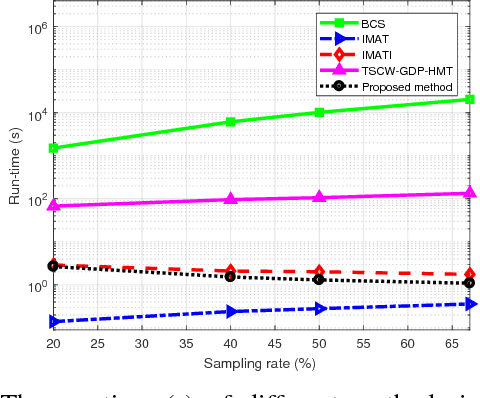

This paper presents an adaptive and intelligent sparse model for digital image sampling and recovery. In the proposed sampler, we adaptively determine the number of required samples for retrieving image based on space-frequency-gradient information content of image patches. By leveraging texture in space, sparsity locations in DCT domain, and directional decomposition of gradients, the sampler structure consists of a combination of uniform, random, and nonuniform sampling strategies. For reconstruction, we model the recovery problem as a two-state cellular automaton to iteratively restore image with scalable windows from generation to generation. We demonstrate the recovery algorithm quickly converges after a few generations for an image with arbitrary degree of texture. For a given number of measurements, extensive experiments on standard image-sets, infra-red, and mega-pixel range imaging devices show that the proposed measurement matrix considerably increases the overall recovery performance, or equivalently decreases the number of sampled pixels for a specific recovery quality compared to random sampling matrix and Gaussian linear combinations employed by the state-of-the-art compressive sensing methods. In practice, the proposed measurement-adaptive sampling/recovery framework includes various applications from intelligent compressive imaging-based acquisition devices to computer vision and graphics, and image processing technology. Simulation codes are available online for reproduction purposes.
Deep Learning for Scene Classification: A Survey
Feb 20, 2021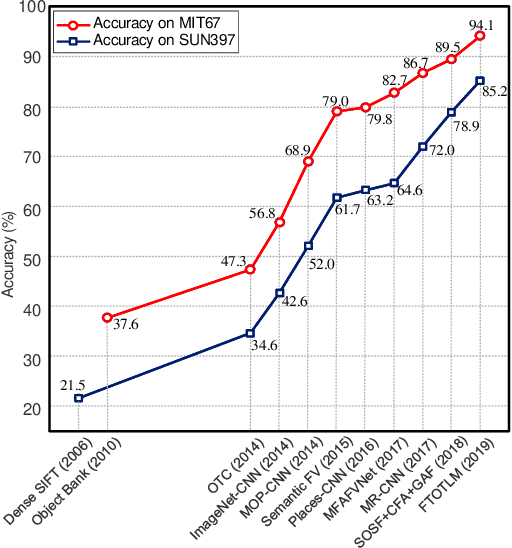
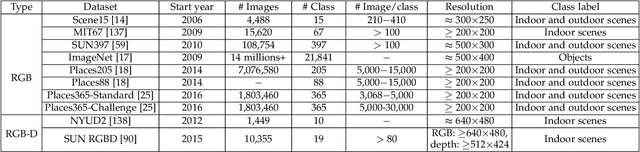

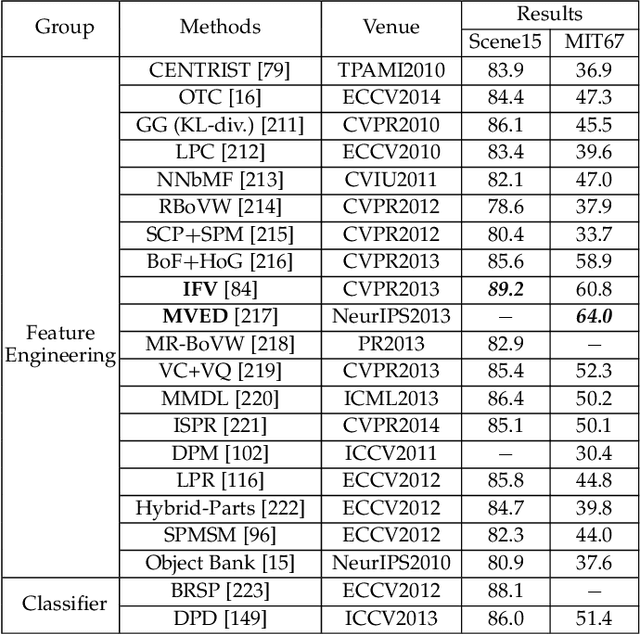
Scene classification, aiming at classifying a scene image to one of the predefined scene categories by comprehending the entire image, is a longstanding, fundamental and challenging problem in computer vision. The rise of large-scale datasets, which constitute the corresponding dense sampling of diverse real-world scenes, and the renaissance of deep learning techniques, which learn powerful feature representations directly from big raw data, have been bringing remarkable progress in the field of scene representation and classification. To help researchers master needed advances in this field, the goal of this paper is to provide a comprehensive survey of recent achievements in scene classification using deep learning. More than 200 major publications are included in this survey covering different aspects of scene classification, including challenges, benchmark datasets, taxonomy, and quantitative performance comparisons of the reviewed methods. In retrospect of what has been achieved so far, this paper is also concluded with a list of promising research opportunities.
Cluster-to-Conquer: A Framework for End-to-End Multi-Instance Learning for Whole Slide Image Classification
Mar 19, 2021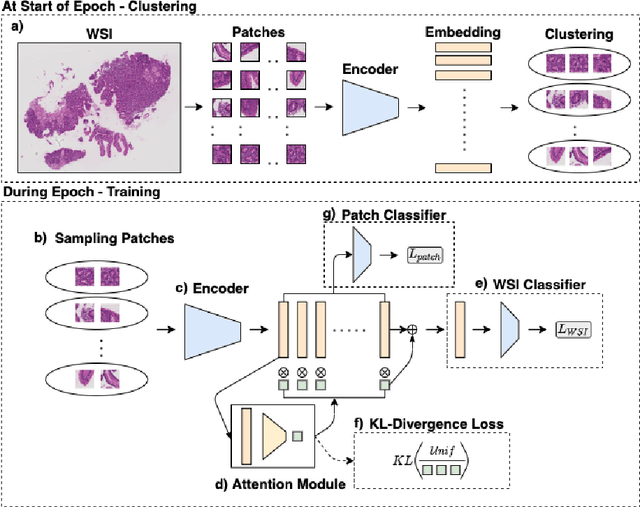
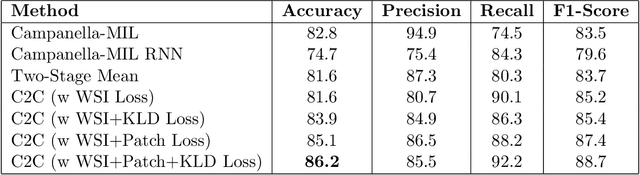
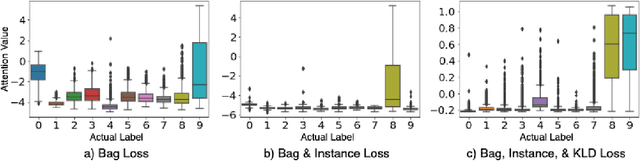

In recent years, the availability of digitized Whole Slide Images (WSIs) has enabled the use of deep learning-based computer vision techniques for automated disease diagnosis. However, WSIs present unique computational and algorithmic challenges. WSIs are gigapixel-sized ($\sim$100K pixels), making them infeasible to be used directly for training deep neural networks. Also, often only slide-level labels are available for training as detailed annotations are tedious and can be time-consuming for experts. Approaches using multiple-instance learning (MIL) frameworks have been shown to overcome these challenges. Current state-of-the-art approaches divide the learning framework into two decoupled parts: a convolutional neural network (CNN) for encoding the patches followed by an independent aggregation approach for slide-level prediction. In this approach, the aggregation step has no bearing on the representations learned by the CNN encoder. We have proposed an end-to-end framework that clusters the patches from a WSI into ${k}$-groups, samples ${k}'$ patches from each group for training, and uses an adaptive attention mechanism for slide level prediction; Cluster-to-Conquer (C2C). We have demonstrated that dividing a WSI into clusters can improve the model training by exposing it to diverse discriminative features extracted from the patches. We regularized the clustering mechanism by introducing a KL-divergence loss between the attention weights of patches in a cluster and the uniform distribution. The framework is optimized end-to-end on slide-level cross-entropy, patch-level cross-entropy, and KL-divergence loss (Implementation: https://github.com/YashSharma/C2C).
Unsupervised Learning of Depth and Depth-of-Field Effect from Natural Images with Aperture Rendering Generative Adversarial Networks
Jun 24, 2021
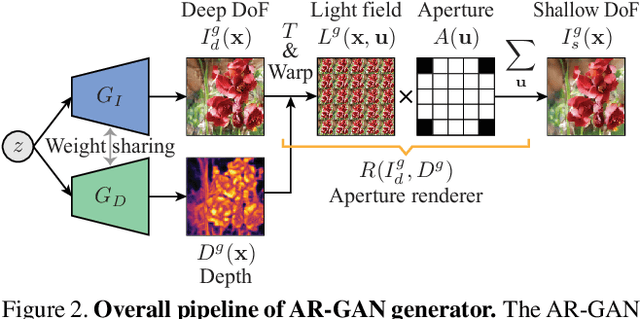
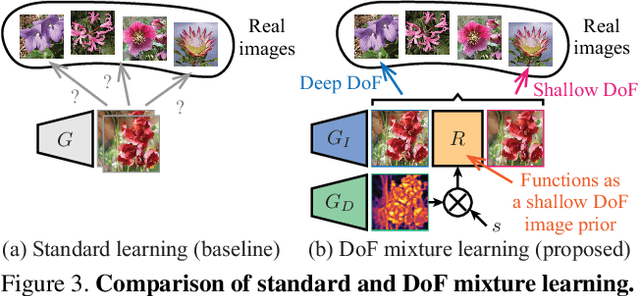
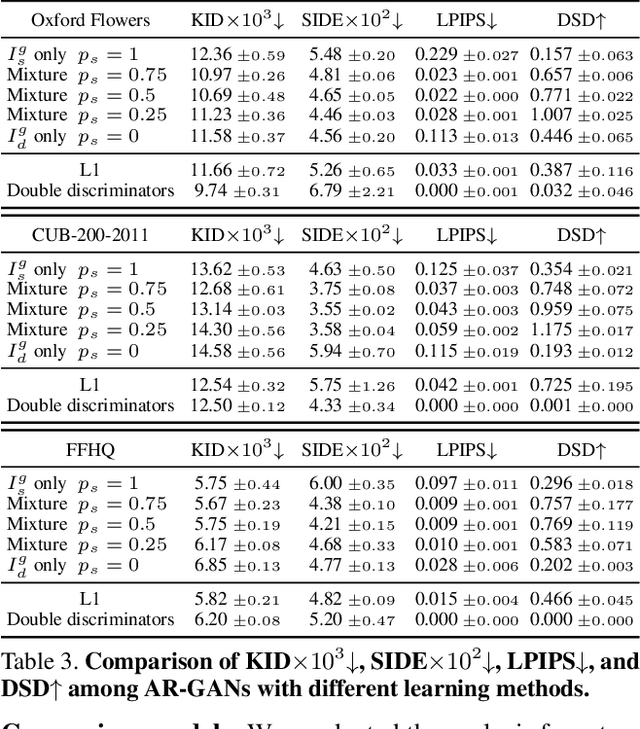
Understanding the 3D world from 2D projected natural images is a fundamental challenge in computer vision and graphics. Recently, an unsupervised learning approach has garnered considerable attention owing to its advantages in data collection. However, to mitigate training limitations, typical methods need to impose assumptions for viewpoint distribution (e.g., a dataset containing various viewpoint images) or object shape (e.g., symmetric objects). These assumptions often restrict applications; for instance, the application to non-rigid objects or images captured from similar viewpoints (e.g., flower or bird images) remains a challenge. To complement these approaches, we propose aperture rendering generative adversarial networks (AR-GANs), which equip aperture rendering on top of GANs, and adopt focus cues to learn the depth and depth-of-field (DoF) effect of unlabeled natural images. To address the ambiguities triggered by unsupervised setting (i.e., ambiguities between smooth texture and out-of-focus blurs, and between foreground and background blurs), we develop DoF mixture learning, which enables the generator to learn real image distribution while generating diverse DoF images. In addition, we devise a center focus prior to guiding the learning direction. In the experiments, we demonstrate the effectiveness of AR-GANs in various datasets, such as flower, bird, and face images, demonstrate their portability by incorporating them into other 3D representation learning GANs, and validate their applicability in shallow DoF rendering.
SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images
Jun 17, 2021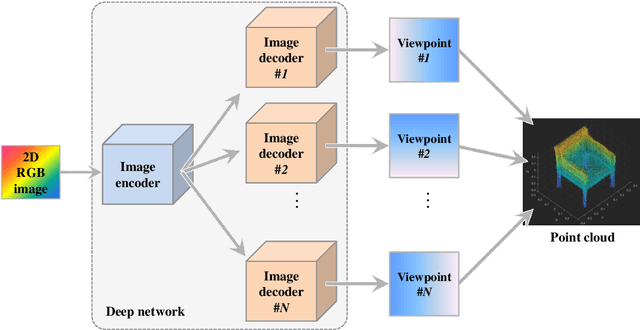



3D model generation from single 2D RGB images is a challenging and actively researched computer vision task. Various techniques using conventional network architectures have been proposed for the same. However, the body of research work is limited and there are various issues like using inefficient 3D representation formats, weak 3D model generation backbones, inability to generate dense point clouds, dependence of post-processing for generation of dense point clouds, and dependence on silhouettes in RGB images. In this paper, a novel 2D RGB image to point cloud conversion technique is proposed, which improves the state of art in the field due to its efficient, robust and simple model by using the concept of parallelization in network architecture. It not only uses the efficient and rich 3D representation of point clouds, but also uses a novel and robust point cloud generation backbone in order to address the prevalent issues. This involves using a single-encoder multiple-decoder deep network architecture wherein each decoder generates certain fixed viewpoints. This is followed by fusing all the viewpoints to generate a dense point cloud. Various experiments are conducted on the technique and its performance is compared with those of other state of the art techniques and impressive gains in performance are demonstrated. Code is available at https://github.com/mueedhafiz1982/
I Don't Need $\mathbf{u}$: Identifiable Non-Linear ICA Without Side Information
Jun 09, 2021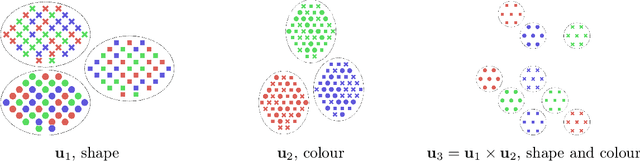
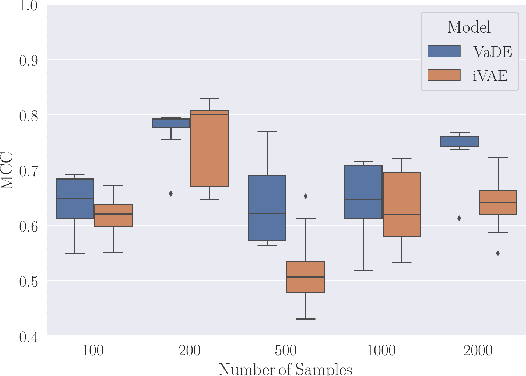

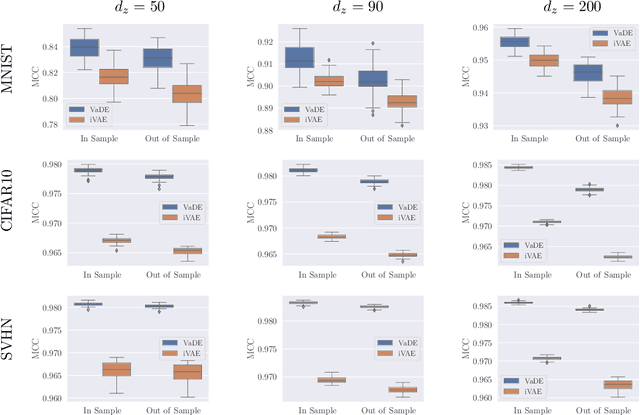
In this work we introduce a new approach for identifiable non-linear ICA models. Recently there has been a renaissance in identifiability results in deep generative models, not least for non-linear ICA. These prior works, however, have assumed access to a sufficiently-informative auxiliary set of observations, denoted $\mathbf{u}$. We show here how identifiability can be obtained in the absence of this side-information, rendering possible fully-unsupervised identifiable non-linear ICA. While previous theoretical results have established the impossibility of identifiable non-linear ICA in the presence of infinitely-flexible universal function approximators, here we rely on the intrinsically-finite modelling capacity of any particular chosen parameterisation of a deep generative model. In particular, we focus on generative models which perform clustering in their latent space -- a model structure which matches previous identifiable models, but with the learnt clustering providing a synthetic form of auxiliary information. We evaluate our proposals using VAEs, on synthetic and image datasets, and find that the learned clusterings function effectively: deep generative models with latent clusterings are empirically identifiable, to the same degree as models which rely on side information.
ShuffleBlock: Shuffle to Regularize Deep Convolutional Neural Networks
Jun 17, 2021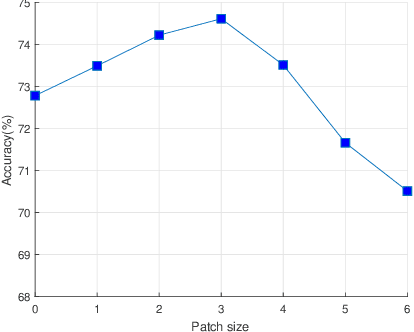
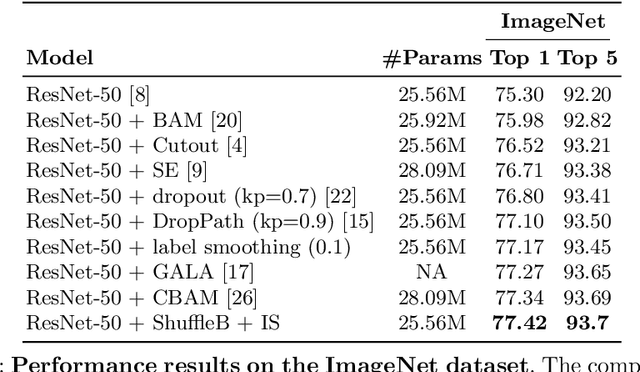
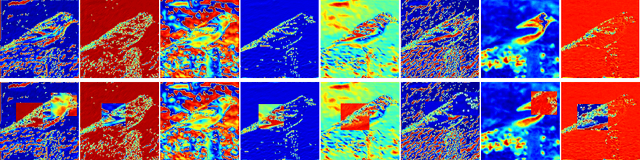
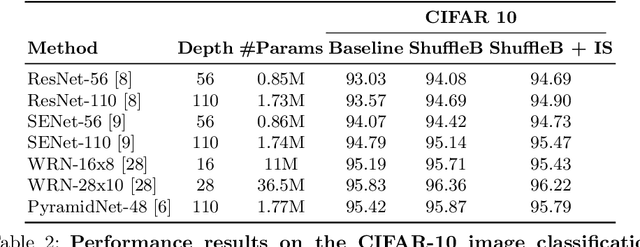
Deep neural networks have enormous representational power which leads them to overfit on most datasets. Thus, regularizing them is important in order to reduce overfitting and enhance their generalization capabilities. Recently, channel shuffle operation has been introduced for mixing channels in group convolutions in resource efficient networks in order to reduce memory and computations. This paper studies the operation of channel shuffle as a regularization technique in deep convolutional networks. We show that while random shuffling of channels during training drastically reduce their performance, however, randomly shuffling small patches between channels significantly improves their performance. The patches to be shuffled are picked from the same spatial locations in the feature maps such that a patch, when transferred from one channel to another, acts as structured noise for the later channel. We call this method "ShuffleBlock". The proposed ShuffleBlock module is easy to implement and improves the performance of several baseline networks on the task of image classification on CIFAR and ImageNet datasets. It also achieves comparable and in many cases better performance than many other regularization methods. We provide several ablation studies on selecting various hyperparameters of the ShuffleBlock module and propose a new scheduling method that further enhances its performance.
A machine learning pipeline for aiding school identification from child trafficking images
Jun 09, 2021
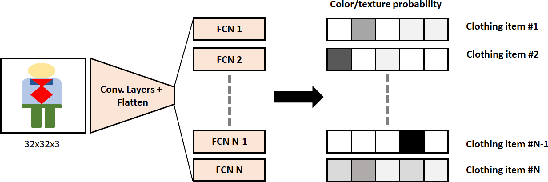
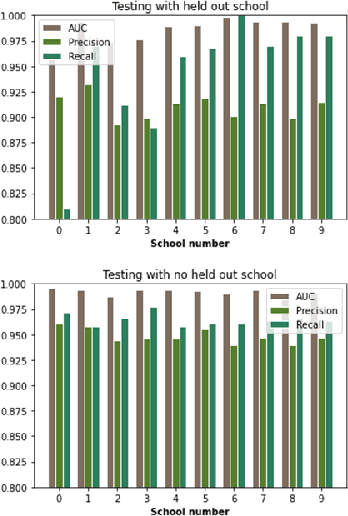
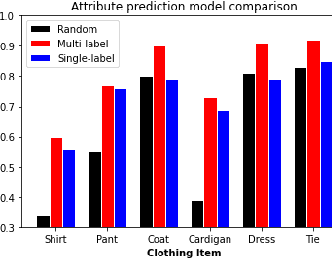
Child trafficking in a serious problem around the world. Every year there are more than 4 million victims of child trafficking around the world, many of them for the purposes of child sexual exploitation. In collaboration with UK Police and a non-profit focused on child abuse prevention, Global Emancipation Network, we developed a proof-of-concept machine learning pipeline to aid the identification of children from intercepted images. In this work, we focus on images that contain children wearing school uniforms to identify the school of origin. In the absence of a machine learning pipeline, this hugely time consuming and labor intensive task is manually conducted by law enforcement personnel. Thus, by automating aspects of the school identification process, we hope to significantly impact the speed of this portion of child identification. Our proposed pipeline consists of two machine learning models: i) to identify whether an image of a child contains a school uniform in it, and ii) identification of attributes of different school uniform items (such as color/texture of shirts, sweaters, blazers etc.). We describe the data collection, labeling, model development and validation process, along with strategies for efficient searching of schools using the model predictions.
ReshapeGAN: Object Reshaping by Providing A Single Reference Image
May 16, 2019

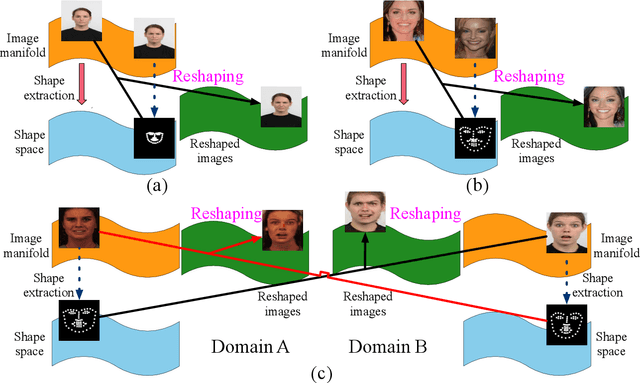
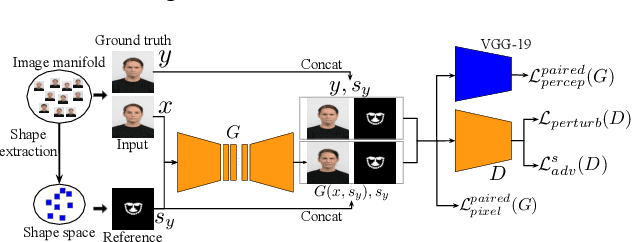
The aim of this work is learning to reshape the object in an input image to an arbitrary new shape, by just simply providing a single reference image with an object instance in the desired shape. We propose a new Generative Adversarial Network (GAN) architecture for such an object reshaping problem, named ReshapeGAN. The network can be tailored for handling all kinds of problem settings, including both within-domain (or single-dataset) reshaping and cross-domain (typically across mutiple datasets) reshaping, with paired or unpaired training data. The appearance of the input object is preserved in all cases, and thus it is still identifiable after reshaping, which has never been achieved as far as we are aware. We present the tailored models of the proposed ReshapeGAN for all the problem settings, and have them tested on 8 kinds of reshaping tasks with 13 different datasets, demonstrating the ability of ReshapeGAN on generating convincing and superior results for object reshaping. To the best of our knowledge, we are the first to be able to make one GAN framework work on all such object reshaping tasks, especially the cross-domain tasks on handling multiple diverse datasets. We present here both ablation studies on our proposed ReshapeGAN models and comparisons with the state-of-the-art models when they are made comparable, using all kinds of applicable metrics that we are aware of.