 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Domain Car Detection Using Unsupervised Image-to-Image Translation: From Day to Night
Jul 19, 2019
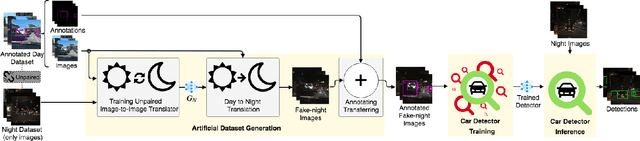
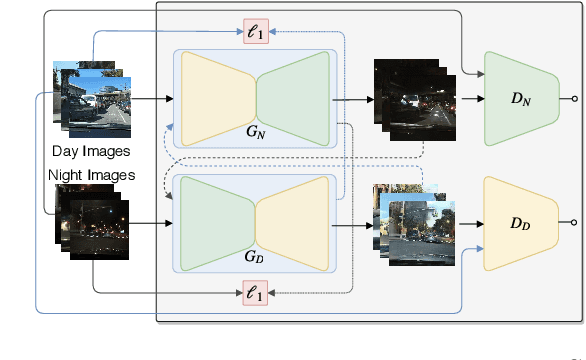


Deep learning techniques have enabled the emergence of state-of-the-art models to address object detection tasks. However, these techniques are data-driven, delegating the accuracy to the training dataset which must resemble the images in the target task. The acquisition of a dataset involves annotating images, an arduous and expensive process, generally requiring time and manual effort. Thus, a challenging scenario arises when the target domain of application has no annotated dataset available, making tasks in such situation to lean on a training dataset of a different domain. Sharing this issue, object detection is a vital task for autonomous vehicles where the large amount of driving scenarios yields several domains of application requiring annotated data for the training process. In this work, a method for training a car detection system with annotated data from a source domain (day images) without requiring the image annotations of the target domain (night images) is presented. For that, a model based on Generative Adversarial Networks (GANs) is explored to enable the generation of an artificial dataset with its respective annotations. The artificial dataset (fake dataset) is created translating images from day-time domain to night-time domain. The fake dataset, which comprises annotated images of only the target domain (night images), is then used to train the car detector model. Experimental results showed that the proposed method achieved significant and consistent improvements, including the increasing by more than 10% of the detection performance when compared to the training with only the available annotated data (i.e., day images).
CoIL: Coordinate-based Internal Learning for Imaging Inverse Problems
Feb 09, 2021
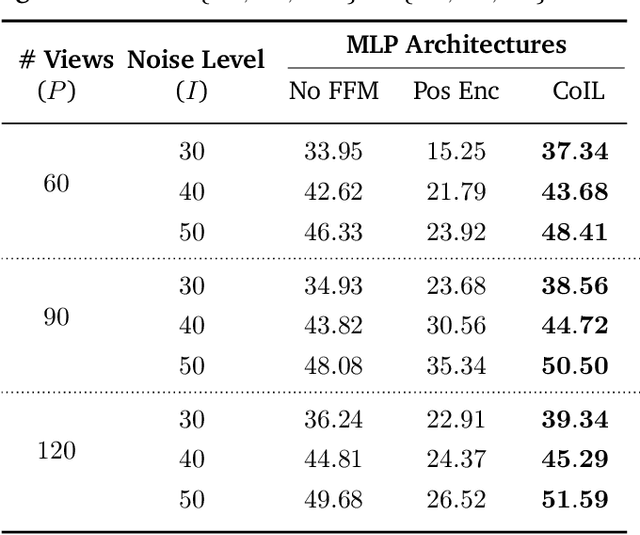
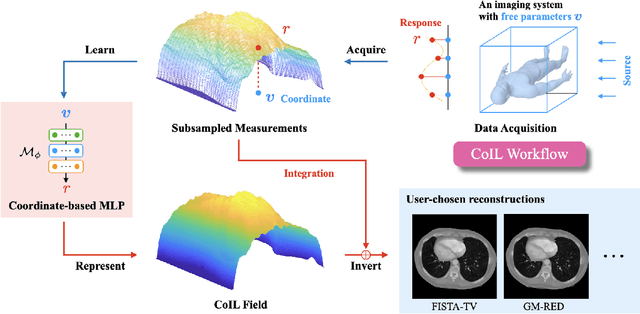
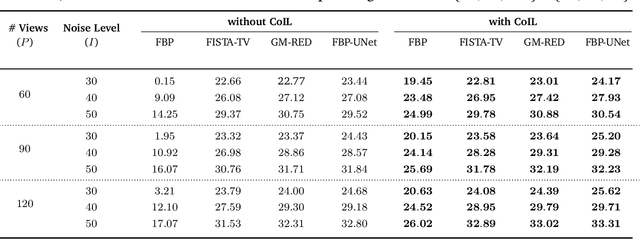
We propose Coordinate-based Internal Learning (CoIL) as a new deep-learning (DL) methodology for the continuous representation of measurements. Unlike traditional DL methods that learn a mapping from the measurements to the desired image, CoIL trains a multilayer perceptron (MLP) to encode the complete measurement field by mapping the coordinates of the measurements to their responses. CoIL is a self-supervised method that requires no training examples besides the measurements of the test object itself. Once the MLP is trained, CoIL generates new measurements that can be used within a majority of image reconstruction methods. We validate CoIL on sparse-view computed tomography using several widely-used reconstruction methods, including purely model-based methods and those based on DL. Our results demonstrate the ability of CoIL to consistently improve the performance of all the considered methods by providing high-fidelity measurement fields.
Generating Black-Box Adversarial Examples in Sparse Domain
Jan 22, 2021
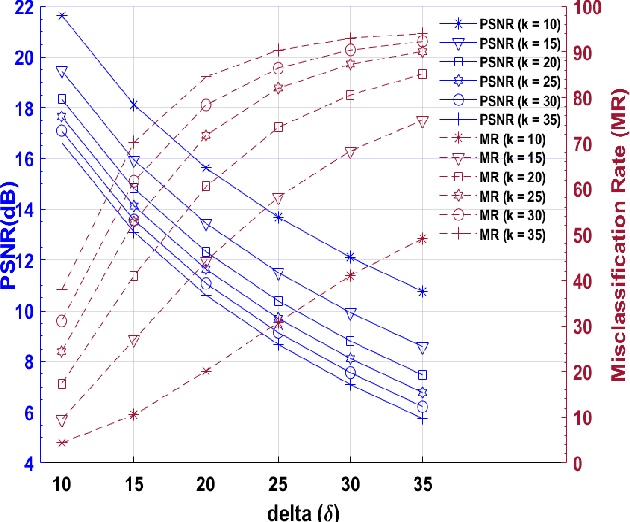
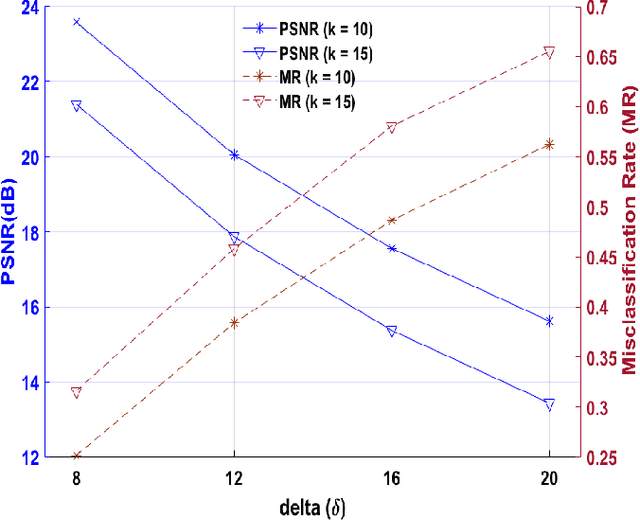
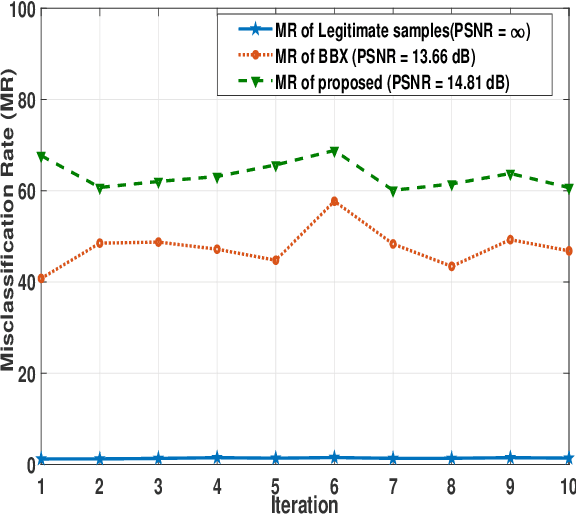
Applications of machine learning (ML) models and convolutional neural networks (CNNs) have been rapidly increased. Although ML models provide high accuracy in many applications, recent investigations show that such networks are highly vulnerable to adversarial attacks. The black-box adversarial attack is one type of attack that the attacker does not have any knowledge about the model or the training dataset. In this paper, we propose a novel approach to generate a black-box attack in sparse domain whereas the most important information of an image can be observed. Our investigation shows that large sparse components play a critical role in the performance of the image classifiers. Under this presumption, to generate adversarial example, we transfer an image into a sparse domain and put a threshold to choose only k largest components. In contrast to the very recent works that randomly perturb k low frequency (LoF) components, we perturb k largest sparse (LaS)components either randomly (query-based) or in the direction of the most correlated sparse signal from a different class. We show that LaS components contain some middle or higher frequency components information which can help us fool the classifiers with a fewer number of queries. We also demonstrate the effectiveness of this approach by fooling the TensorFlow Lite (TFLite) model of Google Cloud Vision platform. Mean squared error (MSE) and peak signal to noise ratio (PSNR) are used as quality metrics. We present a theoretical proof to connect these metrics to the level of perturbation in the sparse domain. We tested our adversarial examples to the state-of-the-art CNNs and support vector machine (SVM) classifiers on color and grayscale image datasets. The results show the proposed method can highly increase the misclassification rate of the classifiers.
Measurement-Adaptive Sparse Image Sampling and Recovery
Nov 23, 2017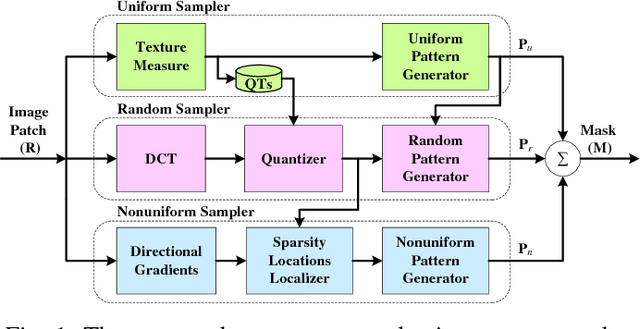
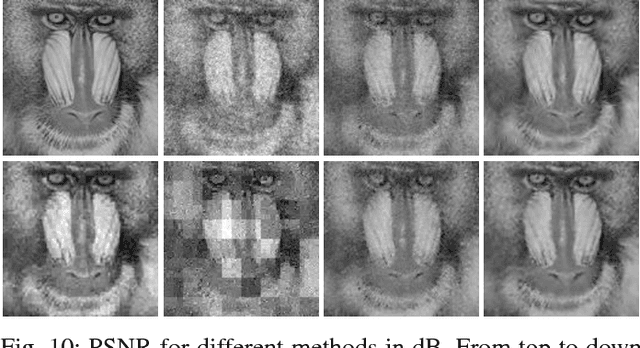
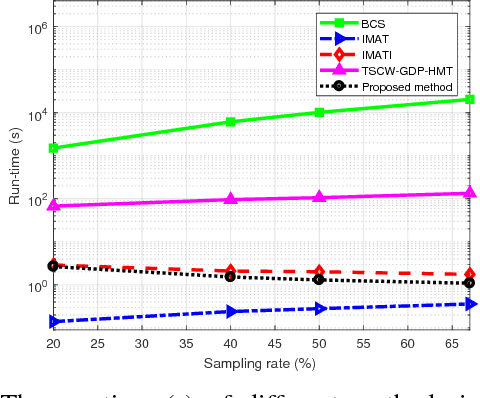

This paper presents an adaptive and intelligent sparse model for digital image sampling and recovery. In the proposed sampler, we adaptively determine the number of required samples for retrieving image based on space-frequency-gradient information content of image patches. By leveraging texture in space, sparsity locations in DCT domain, and directional decomposition of gradients, the sampler structure consists of a combination of uniform, random, and nonuniform sampling strategies. For reconstruction, we model the recovery problem as a two-state cellular automaton to iteratively restore image with scalable windows from generation to generation. We demonstrate the recovery algorithm quickly converges after a few generations for an image with arbitrary degree of texture. For a given number of measurements, extensive experiments on standard image-sets, infra-red, and mega-pixel range imaging devices show that the proposed measurement matrix considerably increases the overall recovery performance, or equivalently decreases the number of sampled pixels for a specific recovery quality compared to random sampling matrix and Gaussian linear combinations employed by the state-of-the-art compressive sensing methods. In practice, the proposed measurement-adaptive sampling/recovery framework includes various applications from intelligent compressive imaging-based acquisition devices to computer vision and graphics, and image processing technology. Simulation codes are available online for reproduction purposes.
Novelty Detection via Contrastive Learning with Negative Data Augmentation
Jun 18, 2021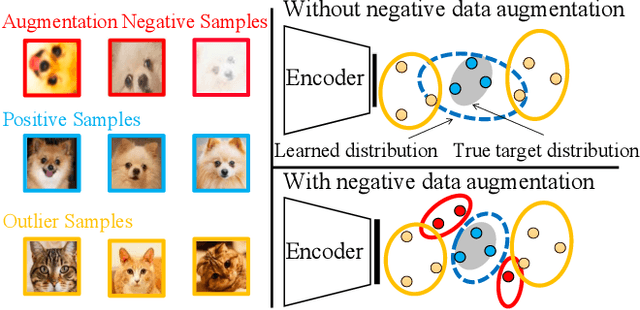

Novelty detection is the process of determining whether a query example differs from the learned training distribution. Previous methods attempt to learn the representation of the normal samples via generative adversarial networks (GANs). However, they will suffer from instability training, mode dropping, and low discriminative ability. Recently, various pretext tasks (e.g. rotation prediction and clustering) have been proposed for self-supervised learning in novelty detection. However, the learned latent features are still low discriminative. We overcome such problems by introducing a novel decoder-encoder framework. Firstly, a generative network (a.k.a. decoder) learns the representation by mapping the initialized latent vector to an image. In particular, this vector is initialized by considering the entire distribution of training data to avoid the problem of mode-dropping. Secondly, a contrastive network (a.k.a. encoder) aims to ``learn to compare'' through mutual information estimation, which directly helps the generative network to obtain a more discriminative representation by using a negative data augmentation strategy. Extensive experiments show that our model has significant superiority over cutting-edge novelty detectors and achieves new state-of-the-art results on some novelty detection benchmarks, e.g. CIFAR10 and DCASE. Moreover, our model is more stable for training in a non-adversarial manner, compared to other adversarial based novelty detection methods.
Cycle-Consistent Generative Rendering for 2D-3D Modality Translation
Nov 16, 2020

For humans, visual understanding is inherently generative: given a 3D shape, we can postulate how it would look in the world; given a 2D image, we can infer the 3D structure that likely gave rise to it. We can thus translate between the 2D visual and 3D structural modalities of a given object. In the context of computer vision, this corresponds to a learnable module that serves two purposes: (i) generate a realistic rendering of a 3D object (shape-to-image translation) and (ii) infer a realistic 3D shape from an image (image-to-shape translation). In this paper, we learn such a module while being conscious of the difficulties in obtaining large paired 2D-3D datasets. By leveraging generative domain translation methods, we are able to define a learning algorithm that requires only weak supervision, with unpaired data. The resulting model is not only able to perform 3D shape, pose, and texture inference from 2D images, but can also generate novel textured 3D shapes and renders, similar to a graphics pipeline. More specifically, our method (i) infers an explicit 3D mesh representation, (ii) utilizes example shapes to regularize inference, (iii) requires only an image mask (no keypoints or camera extrinsics), and (iv) has generative capabilities. While prior work explores subsets of these properties, their combination is novel. We demonstrate the utility of our learned representation, as well as its performance on image generation and unpaired 3D shape inference tasks.
Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors
Dec 21, 2018

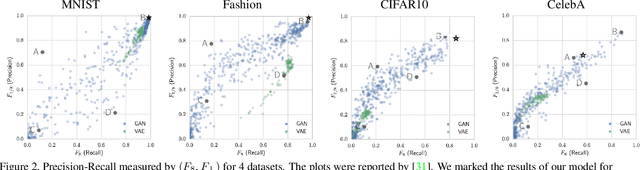

Unconditional image generation has recently been dominated by generative adversarial networks (GANs). GAN methods train a generator which regresses images from random noise vectors, as well as a discriminator that attempts to differentiate between the generated images and a training set of real images. GANs have shown amazing results at generating realistic looking images. Despite their success, GANs suffer from critical drawbacks including: unstable training and mode-dropping. The weaknesses in GANs have motivated research into alternatives including: variational auto-encoders (VAEs), latent embedding learning methods (e.g. GLO) and nearest-neighbor based implicit maximum likelihood estimation (IMLE). Unfortunately at the moment, GANs still significantly outperform the alternative methods for image generation. In this work, we present a novel method - Generative Latent Nearest Neighbors (GLANN) - for training generative models without adversarial training. GLANN combines the strengths of IMLE and GLO in a way that overcomes the main drawbacks of each method. Consequently, GLANN generates images that are far better than GLO and IMLE. Our method does not suffer from mode collapse which plagues GAN training and is much more stable. Qualitative results show that GLANN outperforms a baseline consisting of 800 GANs and VAEs on commonly used datasets. Our models are also shown to be effective for training truly non-adversarial unsupervised image translation.
TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
Jun 25, 2021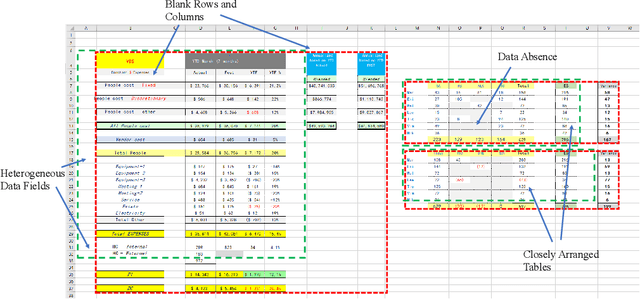
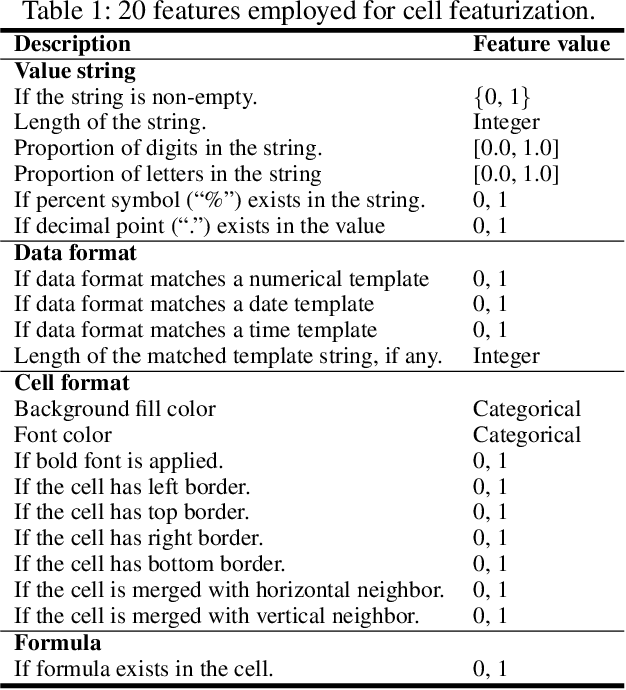

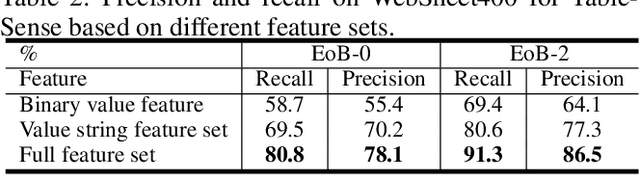
Spreadsheet table detection is the task of detecting all tables on a given sheet and locating their respective ranges. Automatic table detection is a key enabling technique and an initial step in spreadsheet data intelligence. However, the detection task is challenged by the diversity of table structures and table layouts on the spreadsheet. Considering the analogy between a cell matrix as spreadsheet and a pixel matrix as image, and encouraged by the successful application of Convolutional Neural Networks (CNN) in computer vision, we have developed TableSense, a novel end-to-end framework for spreadsheet table detection. First, we devise an effective cell featurization scheme to better leverage the rich information in each cell; second, we develop an enhanced convolutional neural network model for table detection to meet the domain-specific requirement on precise table boundary detection; third, we propose an effective uncertainty metric to guide an active learning based smart sampling algorithm, which enables the efficient build-up of a training dataset with 22,176 tables on 10,220 sheets with broad coverage of diverse table structures and layouts. Our evaluation shows that TableSense is highly effective with 91.3\% recall and 86.5\% precision in EoB-2 metric, a significant improvement over both the current detection algorithm that are used in commodity spreadsheet tools and state-of-the-art convolutional neural networks in computer vision.
Image segmentation of liver stage malaria infection with spatial uncertainty sampling
Nov 30, 2019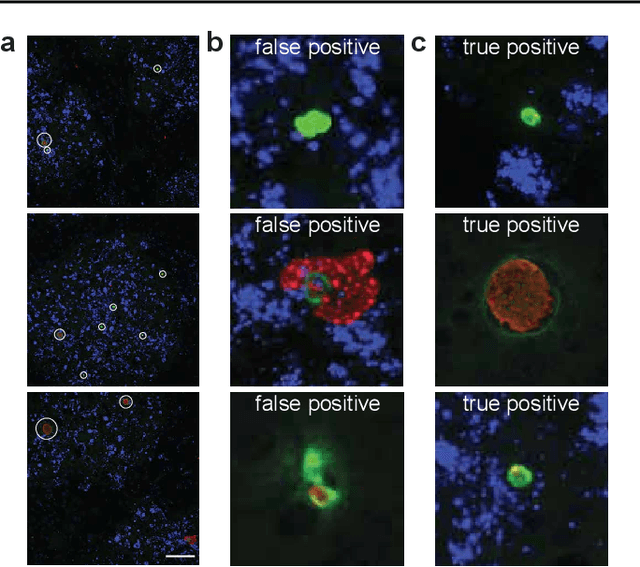
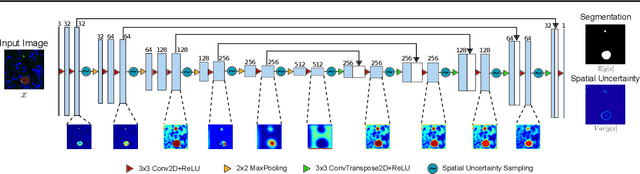
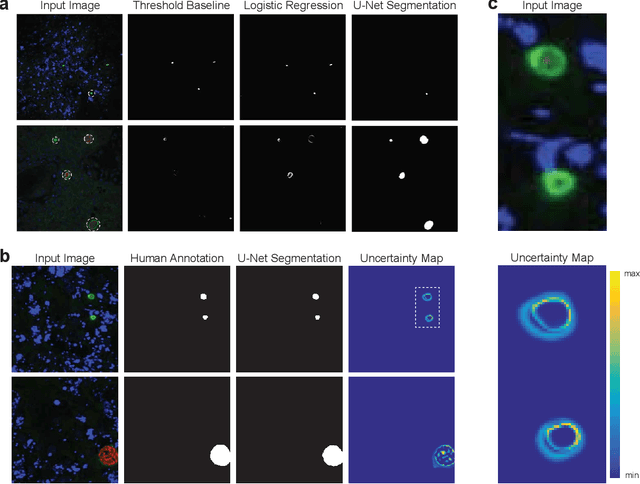
Global eradication of malaria depends on the development of drugs effective against the silent, yet obligate liver stage of the disease. The gold standard in drug development remains microscopic imaging of liver stage parasites in in vitro cell culture models. Image analysis presents a major bottleneck in this pipeline since the parasite has significant variability in size, shape, and density in these models. As with other highly variable datasets, traditional segmentation models have poor generalizability as they rely on hand-crafted features; thus, manual annotation of liver stage malaria images remains standard. To address this need, we develop a convolutional neural network architecture that utilizes spatial dropout sampling for parasite segmentation and epistemic uncertainty estimation in images of liver stage malaria. Our pipeline produces high-precision segmentations nearly identical to expert annotations, generalizes well on a diverse dataset of liver stage malaria parasites, and promotes independence between learned feature maps to model the uncertainty of generated predictions.
Deep Learning for Scene Classification: A Survey
Feb 20, 2021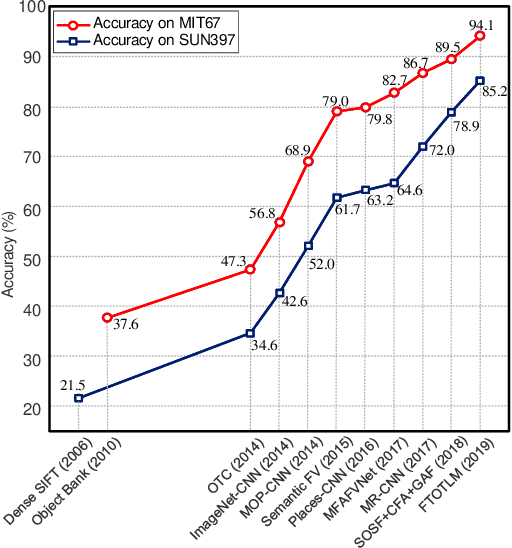
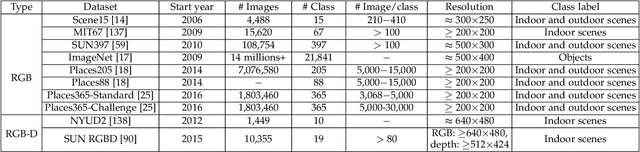

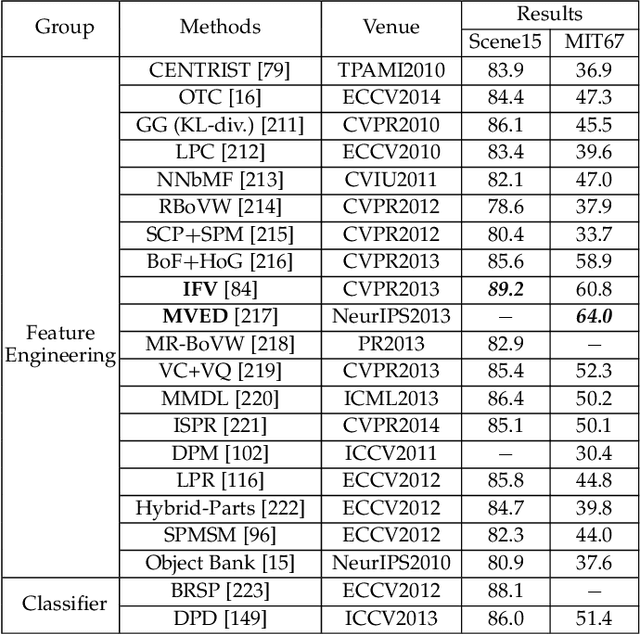
Scene classification, aiming at classifying a scene image to one of the predefined scene categories by comprehending the entire image, is a longstanding, fundamental and challenging problem in computer vision. The rise of large-scale datasets, which constitute the corresponding dense sampling of diverse real-world scenes, and the renaissance of deep learning techniques, which learn powerful feature representations directly from big raw data, have been bringing remarkable progress in the field of scene representation and classification. To help researchers master needed advances in this field, the goal of this paper is to provide a comprehensive survey of recent achievements in scene classification using deep learning. More than 200 major publications are included in this survey covering different aspects of scene classification, including challenges, benchmark datasets, taxonomy, and quantitative performance comparisons of the reviewed methods. In retrospect of what has been achieved so far, this paper is also concluded with a list of promising research opportunities.