 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Novelty Detection via Contrastive Learning with Negative Data Augmentation
Jun 18, 2021
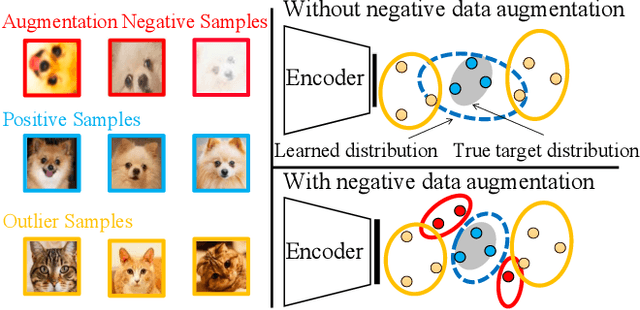

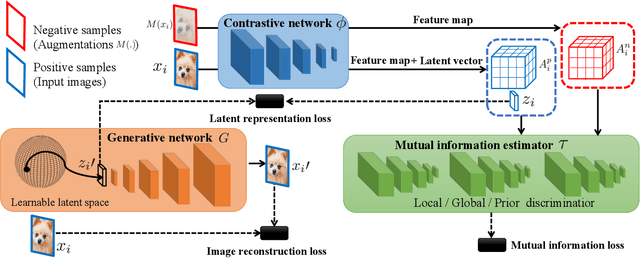
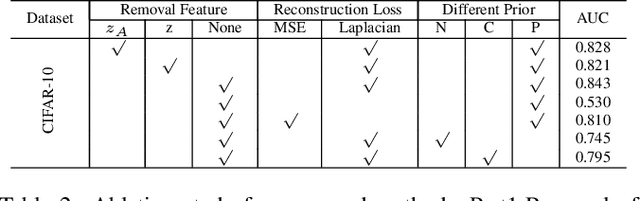
Novelty detection is the process of determining whether a query example differs from the learned training distribution. Previous methods attempt to learn the representation of the normal samples via generative adversarial networks (GANs). However, they will suffer from instability training, mode dropping, and low discriminative ability. Recently, various pretext tasks (e.g. rotation prediction and clustering) have been proposed for self-supervised learning in novelty detection. However, the learned latent features are still low discriminative. We overcome such problems by introducing a novel decoder-encoder framework. Firstly, a generative network (a.k.a. decoder) learns the representation by mapping the initialized latent vector to an image. In particular, this vector is initialized by considering the entire distribution of training data to avoid the problem of mode-dropping. Secondly, a contrastive network (a.k.a. encoder) aims to ``learn to compare'' through mutual information estimation, which directly helps the generative network to obtain a more discriminative representation by using a negative data augmentation strategy. Extensive experiments show that our model has significant superiority over cutting-edge novelty detectors and achieves new state-of-the-art results on some novelty detection benchmarks, e.g. CIFAR10 and DCASE. Moreover, our model is more stable for training in a non-adversarial manner, compared to other adversarial based novelty detection methods.
TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
Jun 25, 2021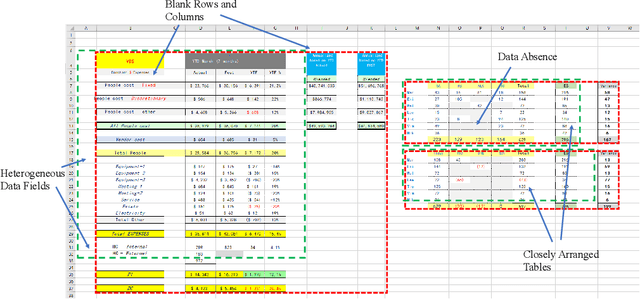
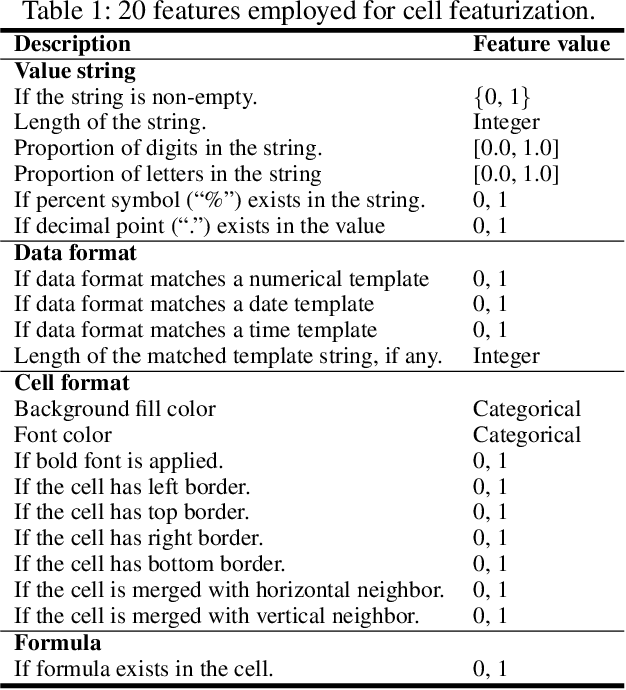

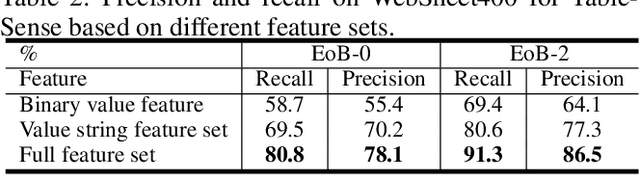
Spreadsheet table detection is the task of detecting all tables on a given sheet and locating their respective ranges. Automatic table detection is a key enabling technique and an initial step in spreadsheet data intelligence. However, the detection task is challenged by the diversity of table structures and table layouts on the spreadsheet. Considering the analogy between a cell matrix as spreadsheet and a pixel matrix as image, and encouraged by the successful application of Convolutional Neural Networks (CNN) in computer vision, we have developed TableSense, a novel end-to-end framework for spreadsheet table detection. First, we devise an effective cell featurization scheme to better leverage the rich information in each cell; second, we develop an enhanced convolutional neural network model for table detection to meet the domain-specific requirement on precise table boundary detection; third, we propose an effective uncertainty metric to guide an active learning based smart sampling algorithm, which enables the efficient build-up of a training dataset with 22,176 tables on 10,220 sheets with broad coverage of diverse table structures and layouts. Our evaluation shows that TableSense is highly effective with 91.3\% recall and 86.5\% precision in EoB-2 metric, a significant improvement over both the current detection algorithm that are used in commodity spreadsheet tools and state-of-the-art convolutional neural networks in computer vision.
An Alternative Practice of Tropical Convolution to Traditional Convolutional Neural Networks
Mar 03, 2021

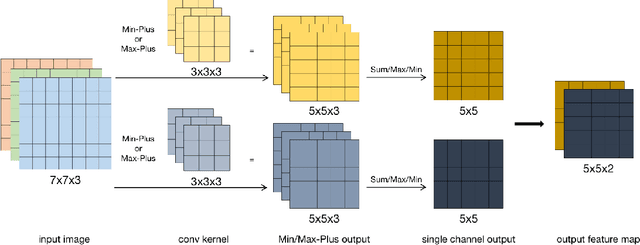
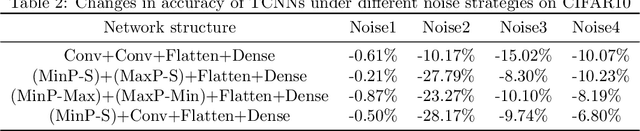
Convolutional neural networks (CNNs) have been used in many machine learning fields. In practical applications, the computational cost of convolutional neural networks is often high with the deepening of the network and the growth of data volume, mostly due to a large amount of multiplication operations of floating-point numbers in convolution operations. To reduce the amount of multiplications, we propose a new type of CNNs called Tropical Convolutional Neural Networks (TCNNs) which are built on tropical convolutions in which the multiplications and additions in conventional convolutional layers are replaced by additions and min/max operations respectively. In addition, since tropical convolution operators are essentially nonlinear operators, we expect TCNNs to have higher nonlinear fitting ability than conventional CNNs. In the experiments, we test and analyze several different architectures of TCNNs for image classification tasks in comparison with similar-sized conventional CNNs. The results show that TCNN can achieve higher expressive power than ordinary convolutional layers on the MNIST and CIFAR10 image data set. In different noise environments, there are wins and losses in the robustness of TCNN and ordinary CNNs.
Infrared and visible image fusion using a novel deep decomposition method
Nov 06, 2018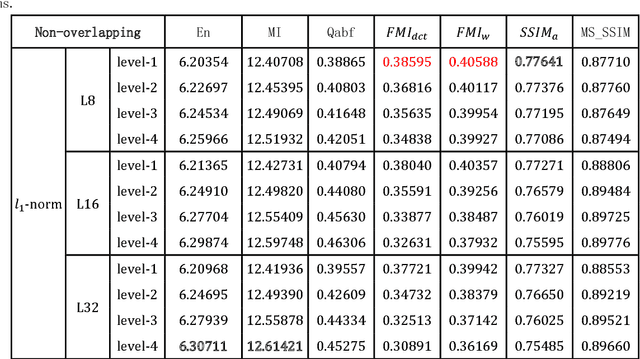
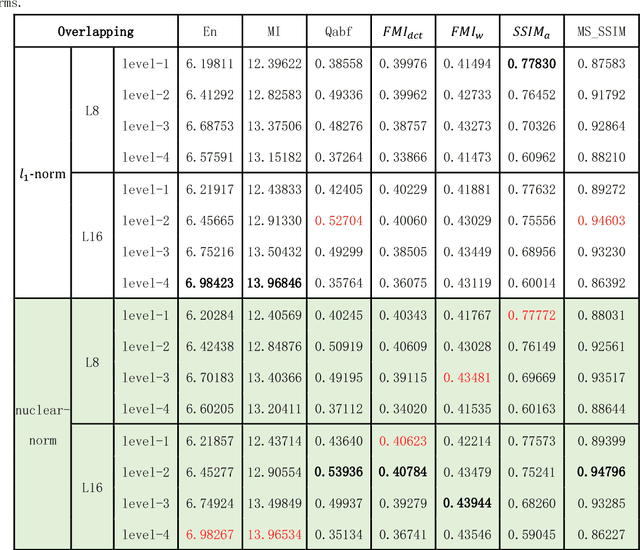
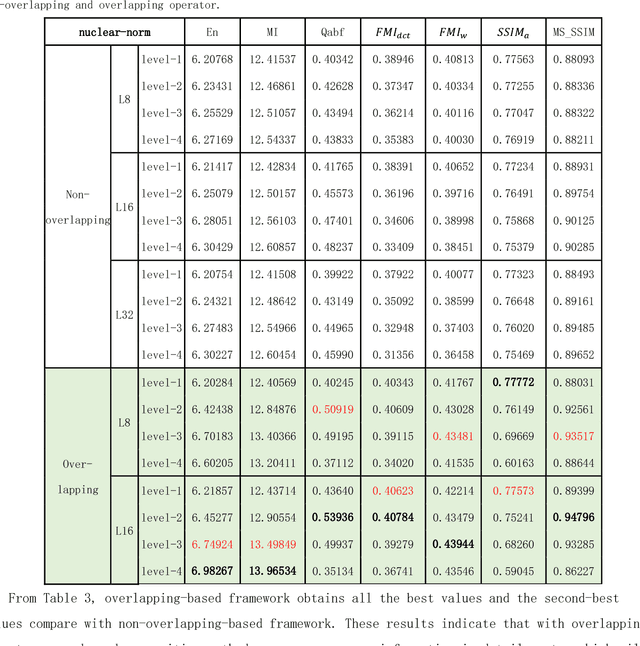
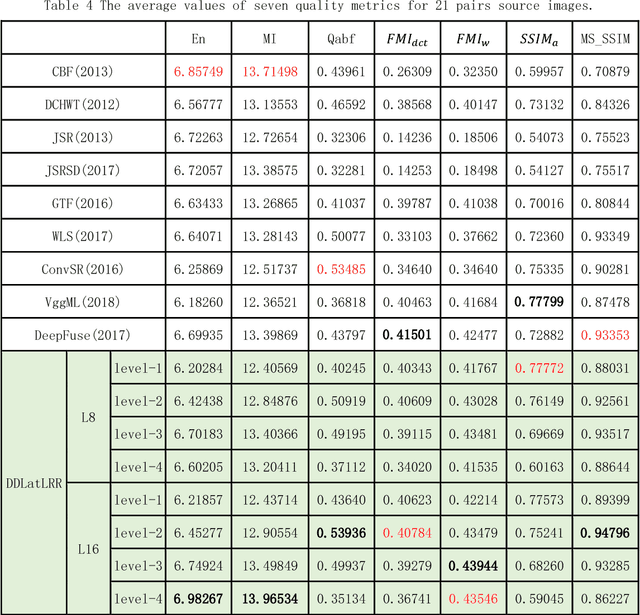
Infrared and visible image fusion is an important problem in image fusion tasks which has been applied widely in many fields. To better preserve the useful information from source images, in this paper, we propose an effective image fusion framework using a novel deep decomposition method which based on Latent Low-Rank Representation(LatLRR). And this decomposition method is also named DDLatLRR. Firstly, the LatLRR is utilized to learn a project matrix which used to extract salient features. Then, the base part and multi-level detail parts are obtained by DDLatLRR. With adaptive fusion strategies, the fused base part and the fused detail parts are reconstructed. Finally, the fused image is obtained by combine the fused base part and the detail parts. Compared with other fusion methods experimentally, the proposed algorithm has better fusion performance than state-of-the-art fusion methods in both subjective and objective evaluation. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_deepdecomposition
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021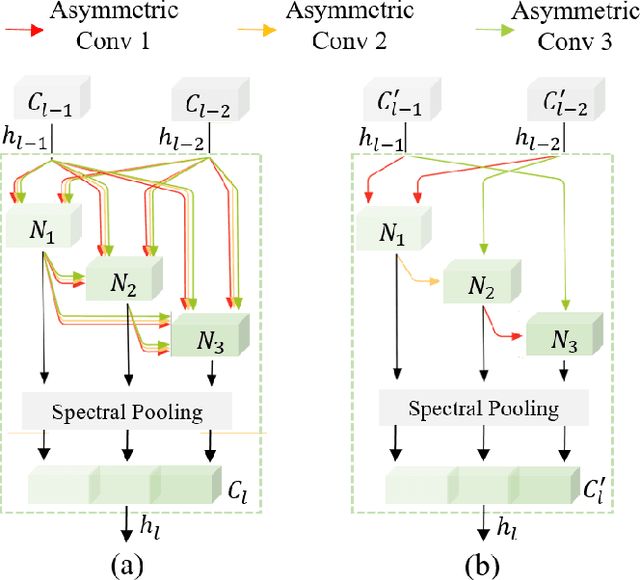
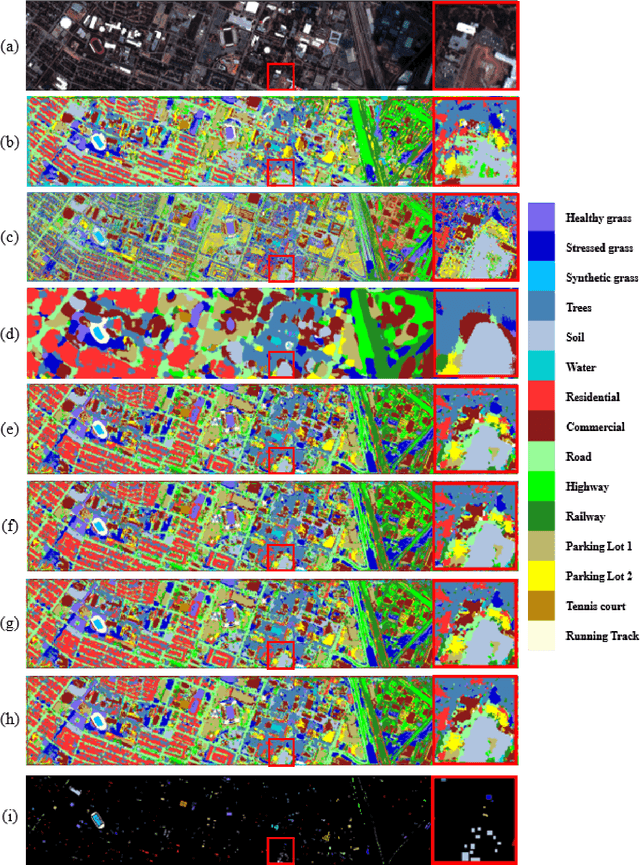
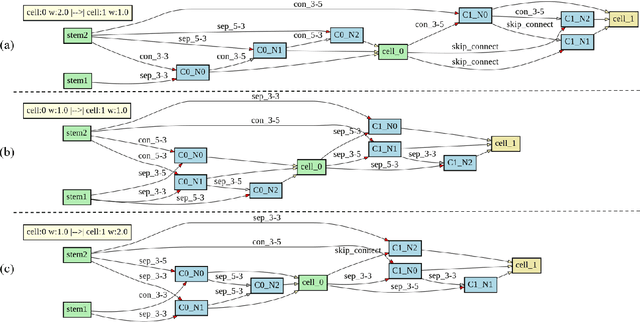
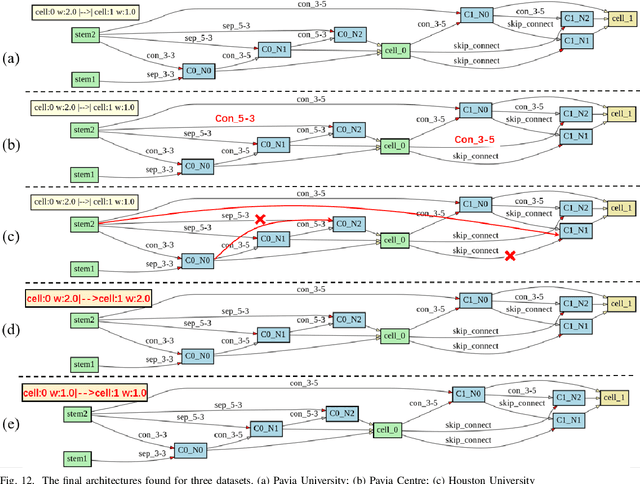
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Hyperspectral and LiDAR data classification based on linear self-attention
Apr 06, 2021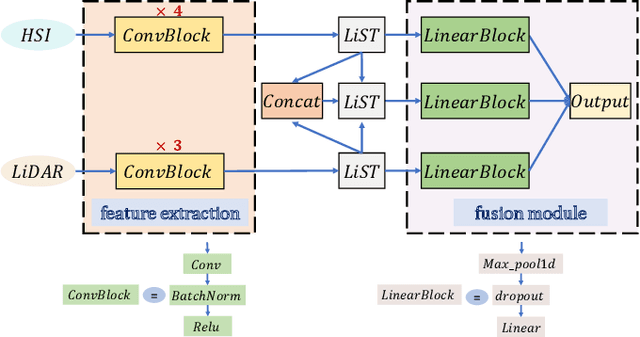
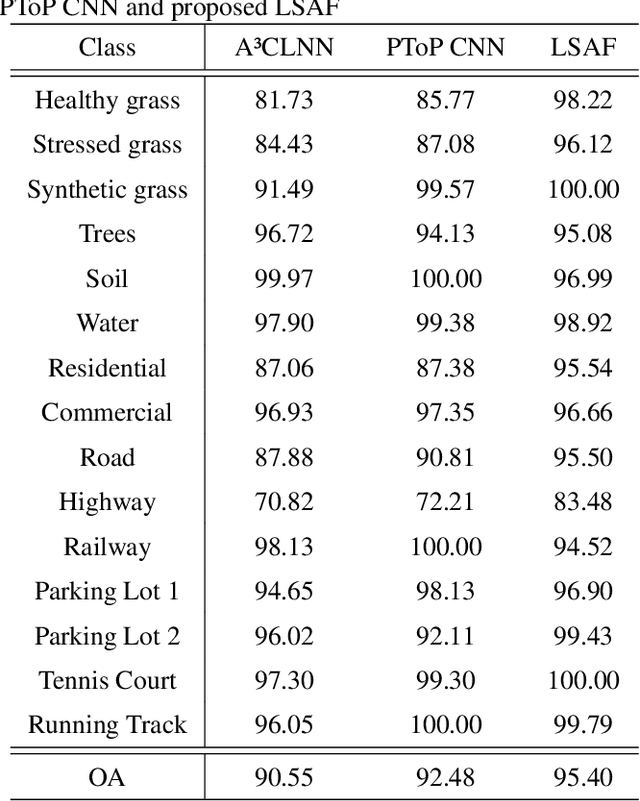
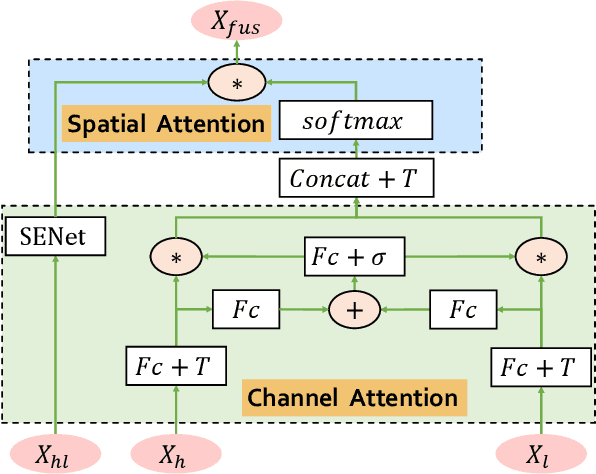
An efficient linear self-attention fusion model is proposed in this paper for the task of hyperspectral image (HSI) and LiDAR data joint classification. The proposed method is comprised of a feature extraction module, an attention module, and a fusion module. The attention module is a plug-and-play linear self-attention module that can be extensively used in any model. The proposed model has achieved the overall accuracy of 95.40\% on the Houston dataset. The experimental results demonstrate the superiority of the proposed method over other state-of-the-art models.
Reducing Racial Bias in Facial Age Prediction using Unsupervised Domain Adaptation in Regression
Apr 05, 2021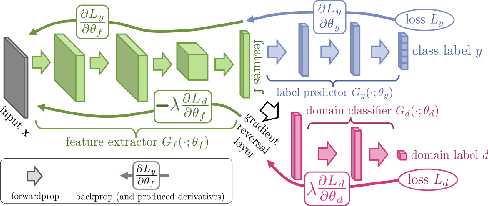


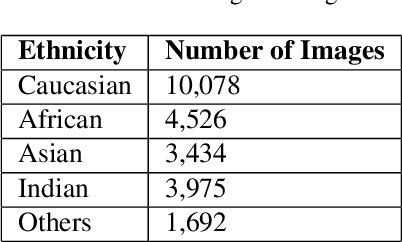
We propose an approach for unsupervised domain adaptation for the task of estimating someone's age from a given face image. In order to avoid the propagation of racial bias in most publicly available face image datasets into the inefficacy of models trained on them, we perform domain adaptation to motivate the predictor to learn features that are invariant to ethnicity, enhancing the generalization performance across faces of people from different ethnic backgrounds. Exploiting the ordinality of age, we also impose ranking constraints on the prediction of the model and design our model such that it takes as input a pair of images, and outputs both the relative age difference and the rank of the first identity with respect to the other in terms of their ages. Furthermore, we implement Multi-Dimensional Scaling to retrieve absolute ages from the predicted age differences from as few as two labeled images from the domain to be adapted to. We experiment with a publicly available dataset with age labels, dividing it into subsets based on the ethnicity labels, and evaluating the performance of our approach on the data from an ethnicity different from the one that the model is trained on. Additionally, we impose a constraint to preserve the sanity of the predictions with respect to relative and absolute ages, and another to ensure the smoothness of the predictions with respect to the input. We experiment extensively and compare various domain adaptation approaches for the task of regression.
Image segmentation of liver stage malaria infection with spatial uncertainty sampling
Nov 30, 2019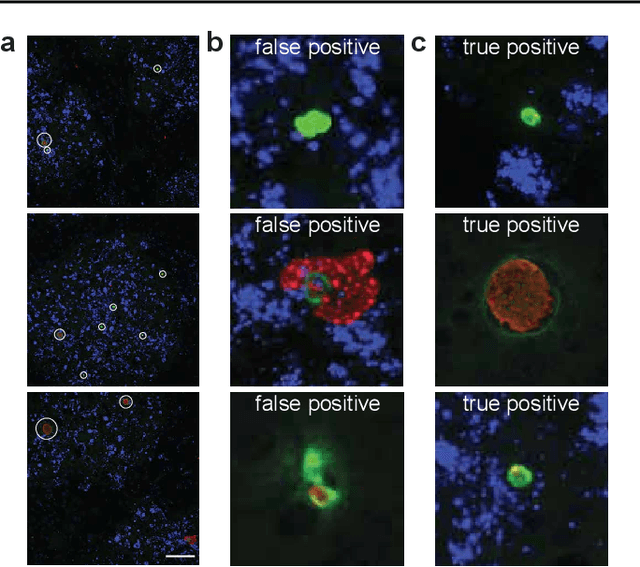
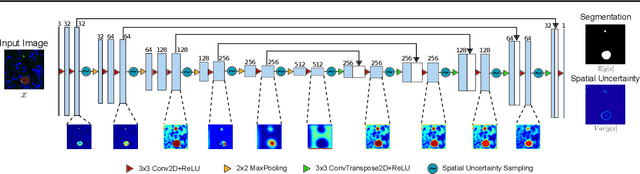
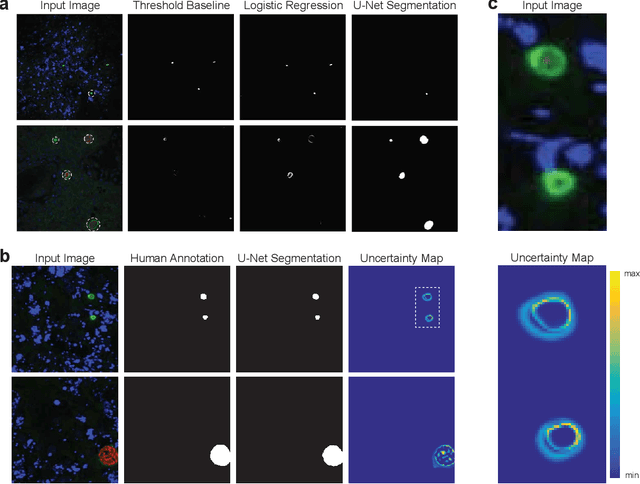
Global eradication of malaria depends on the development of drugs effective against the silent, yet obligate liver stage of the disease. The gold standard in drug development remains microscopic imaging of liver stage parasites in in vitro cell culture models. Image analysis presents a major bottleneck in this pipeline since the parasite has significant variability in size, shape, and density in these models. As with other highly variable datasets, traditional segmentation models have poor generalizability as they rely on hand-crafted features; thus, manual annotation of liver stage malaria images remains standard. To address this need, we develop a convolutional neural network architecture that utilizes spatial dropout sampling for parasite segmentation and epistemic uncertainty estimation in images of liver stage malaria. Our pipeline produces high-precision segmentations nearly identical to expert annotations, generalizes well on a diverse dataset of liver stage malaria parasites, and promotes independence between learned feature maps to model the uncertainty of generated predictions.
Energy-Based Generative Cooperative Saliency Prediction
Jun 25, 2021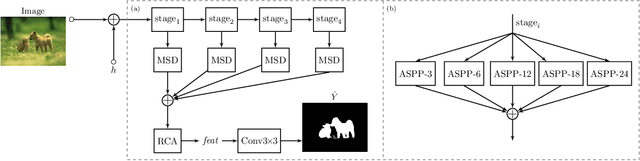
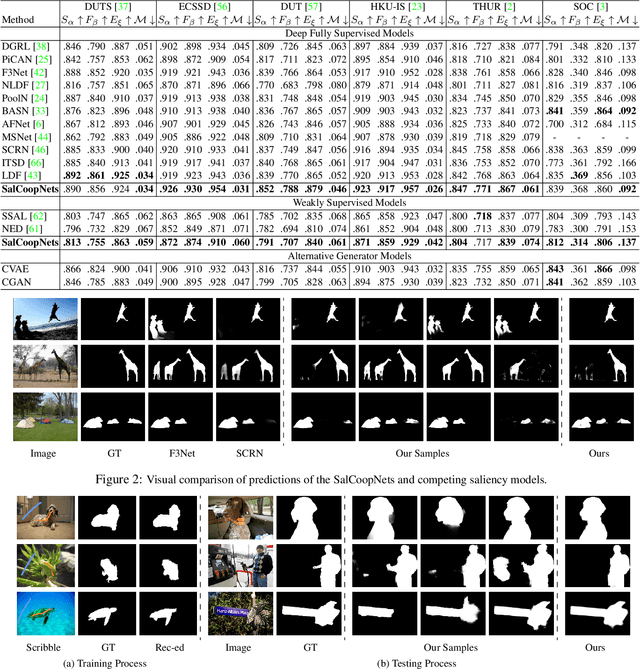
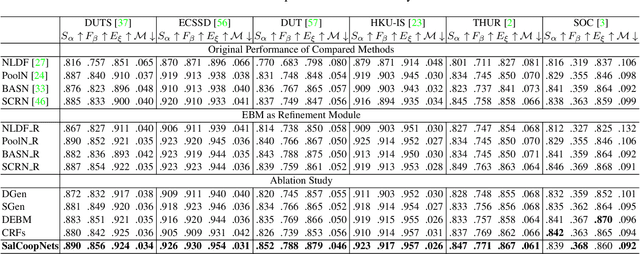
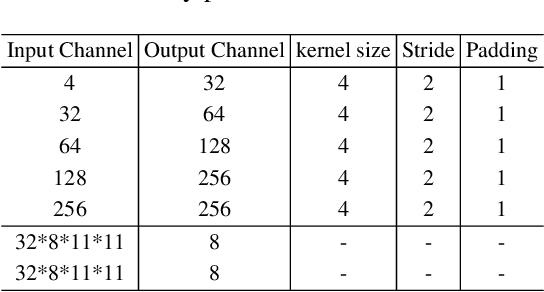
Conventional saliency prediction models typically learn a deterministic mapping from images to the corresponding ground truth saliency maps. In this paper, we study the saliency prediction problem from the perspective of generative models by learning a conditional probability distribution over saliency maps given an image, and treating the prediction as a sampling process. Specifically, we propose a generative cooperative saliency prediction framework based on the generative cooperative networks, where a conditional latent variable model and a conditional energy-based model are jointly trained to predict saliency in a cooperative manner. We call our model the SalCoopNets. The latent variable model serves as a fast but coarse predictor to efficiently produce an initial prediction, which is then refined by the iterative Langevin revision of the energy-based model that serves as a fine predictor. Such a coarse-to-fine cooperative saliency prediction strategy offers the best of both worlds. Moreover, we generalize our framework to the scenario of weakly supervised saliency prediction, where saliency annotation of training images is partially observed, by proposing a cooperative learning while recovering strategy. Lastly, we show that the learned energy function can serve as a refinement module that can refine the results of other pre-trained saliency prediction models. Experimental results show that our generative model can achieve state-of-the-art performance. Our code is publicly available at: \url{https://github.com/JingZhang617/SalCoopNets}.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

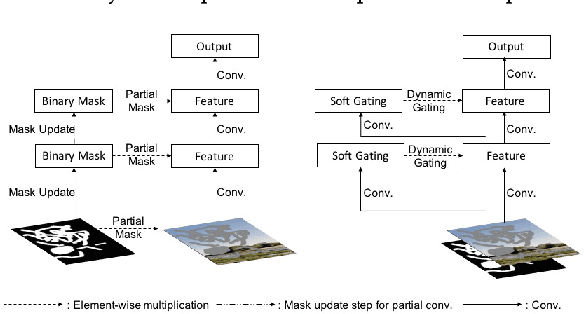

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2