 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data augmentation and pre-trained networks for extremely low data regimes unsupervised visual inspection
Jun 02, 2021
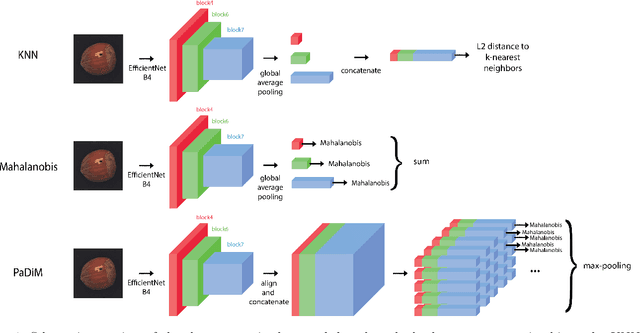
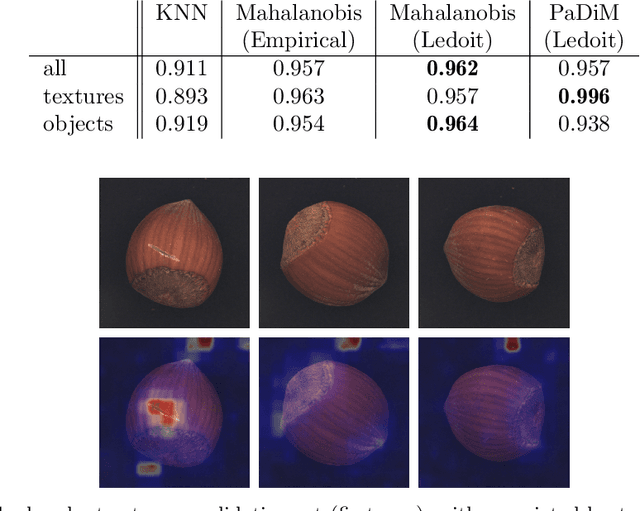
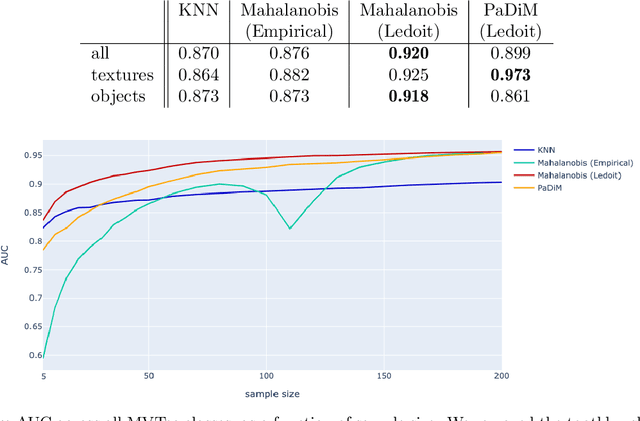
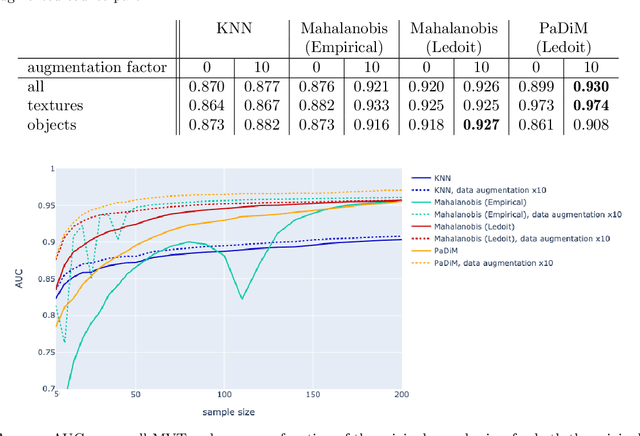
The use of deep features coming from pre-trained neural networks for unsupervised anomaly detection purposes has recently gathered momentum in the computer vision field. In particular, industrial inspection applications can take advantage of such features, as demonstrated by the multiple successes of related methods on the MVTec Anomaly Detection (MVTec AD) dataset. These methods make use of neural networks pre-trained on auxiliary classification tasks such as ImageNet. However, to our knowledge, no comparative study of robustness to the low data regimes between these approaches has been conducted yet. For quality inspection applications, the handling of limited sample sizes may be crucial as large quantities of images are not available for small series. In this work, we aim to compare three approaches based on deep pre-trained features when varying the quantity of available data in MVTec AD: KNN, Mahalanobis, and PaDiM. We show that although these methods are mostly robust to small sample sizes, they still can benefit greatly from using data augmentation in the original image space, which allows to deal with very small production runs.
Sound-to-Imagination: Unsupervised Crossmodal Translation Using Deep Dense Network Architecture
Jun 02, 2021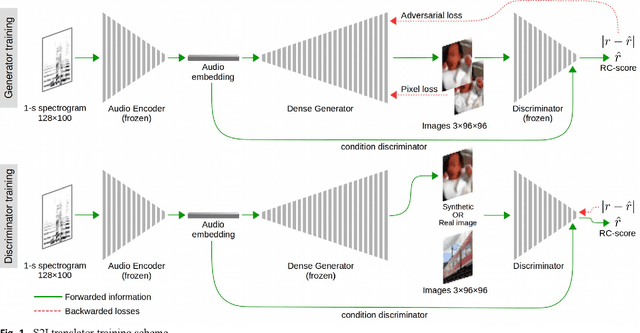

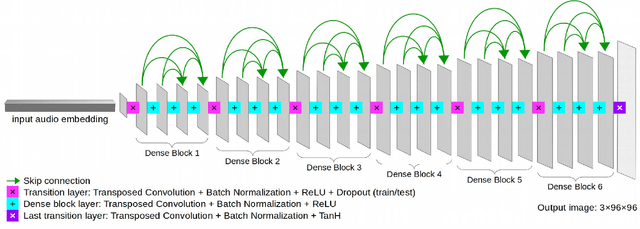
The motivation of our research is to develop a sound-to-image (S2I) translation system for enabling a human receiver to visually infer the occurrence of sound related events. We expect the computer to 'imagine' the scene from the captured sound, generating original images that picture the sound emitting source. Previous studies on similar topics opted for simplified approaches using data with low content diversity and/or strong supervision. Differently, we propose to perform unsupervised S2I translation using thousands of distinct and unknown scenes, with slightly pre-cleaned data, just enough to guarantee aural-visual semantic coherence. To that end, we employ conditional generative adversarial networks (GANs) with a deep densely connected generator. Besides, we implemented a moving-average adversarial loss to address GANs training instability. Though the specified S2I translation problem is quite challenging, we were able to generalize the translator model enough to obtain more than 14%, in average, of interpretable and semantically coherent images translated from unknown sounds. Additionally, we present a solution using informativity classifiers to perform quantitative evaluation of S2I translation.
Learning to Jointly Deblur, Demosaick and Denoise Raw Images
Apr 13, 2021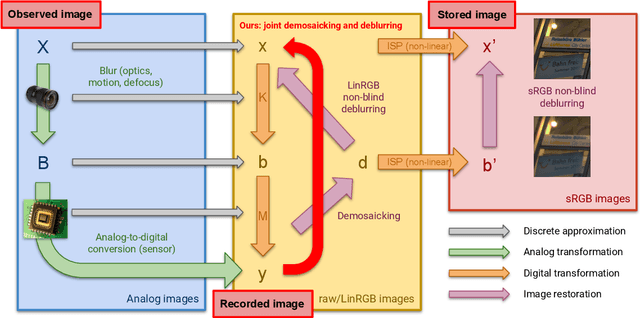
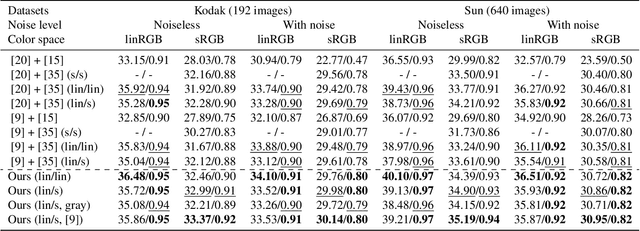
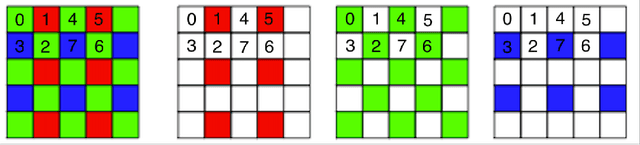
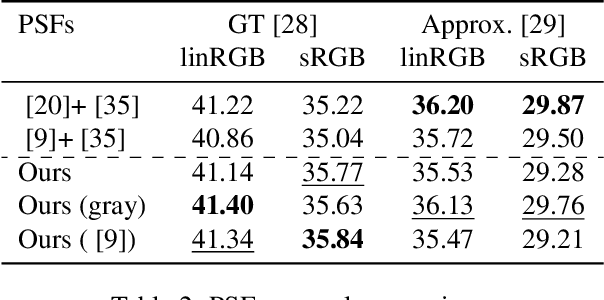
We address the problem of non-blind deblurring and demosaicking of noisy raw images. We adapt an existing learning-based approach to RGB image deblurring to handle raw images by introducing a new interpretable module that jointly demosaicks and deblurs them. We train this model on RGB images converted into raw ones following a realistic invertible camera pipeline. We demonstrate the effectiveness of this model over two-stage approaches stacking demosaicking and deblurring modules on quantitive benchmarks. We also apply our approach to remove a camera's inherent blur (its color-dependent point-spread function) from real images, in essence deblurring sharp images.
Deep Learning Radio Frequency Signal Classification with Hybrid Images
May 19, 2021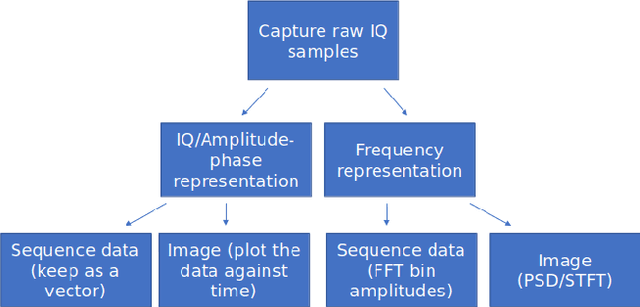
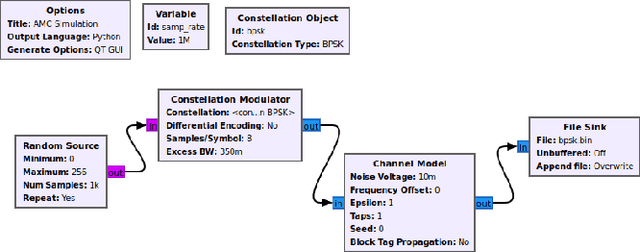
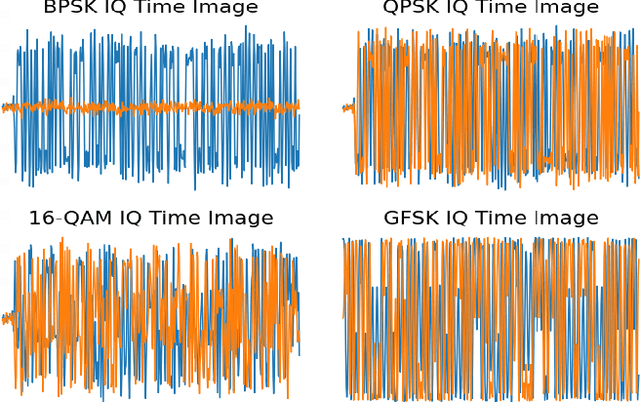
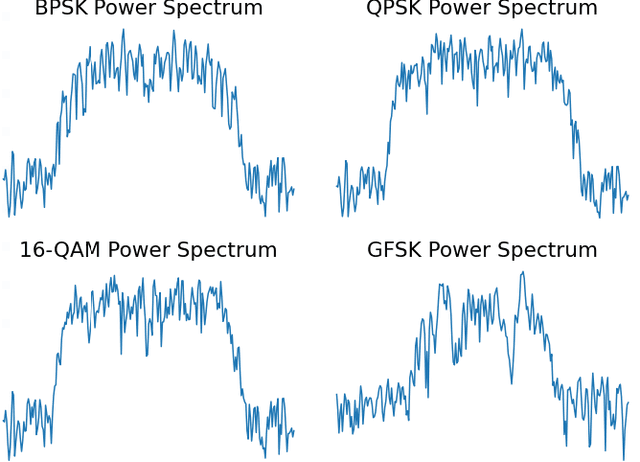
In recent years, Deep Learning (DL) has been successfully applied to detect and classify Radio Frequency (RF) Signals. A DL approach is especially useful since it identifies the presence of a signal without needing full protocol information, and can also detect and/or classify non-communication waveforms, such as radar signals. In this work, we focus on the different pre-processing steps that can be used on the input training data, and test the results on a fixed DL architecture. While previous works have mostly focused exclusively on either time-domain or frequency domain approaches, we propose a hybrid image that takes advantage of both time and frequency domain information, and tackles the classification as a Computer Vision problem. Our initial results point out limitations to classical pre-processing approaches while also showing that it's possible to build a classifier that can leverage the strengths of multiple signal representations.
Universal Rate-Distortion-Perception Representations for Lossy Compression
Jun 18, 2021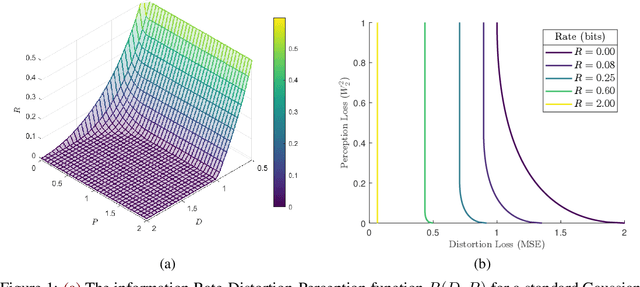
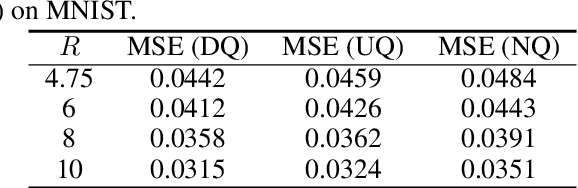
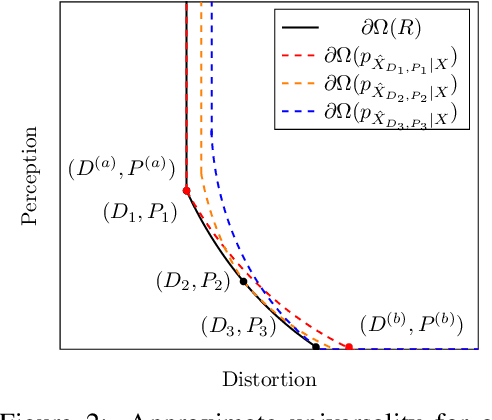
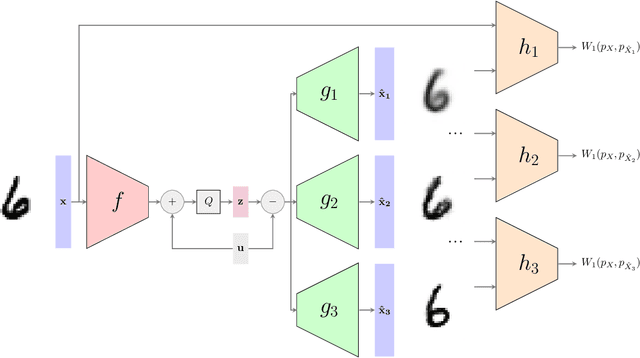
In the context of lossy compression, Blau & Michaeli (2019) adopt a mathematical notion of perceptual quality and define the information rate-distortion-perception function, generalizing the classical rate-distortion tradeoff. We consider the notion of universal representations in which one may fix an encoder and vary the decoder to achieve any point within a collection of distortion and perception constraints. We prove that the corresponding information-theoretic universal rate-distortion-perception function is operationally achievable in an approximate sense. Under MSE distortion, we show that the entire distortion-perception tradeoff of a Gaussian source can be achieved by a single encoder of the same rate asymptotically. We then characterize the achievable distortion-perception region for a fixed representation in the case of arbitrary distributions, identify conditions under which the aforementioned results continue to hold approximately, and study the case when the rate is not fixed in advance. This motivates the study of practical constructions that are approximately universal across the RDP tradeoff, thereby alleviating the need to design a new encoder for each objective. We provide experimental results on MNIST and SVHN suggesting that on image compression tasks, the operational tradeoffs achieved by machine learning models with a fixed encoder suffer only a small penalty when compared to their variable encoder counterparts.
An Alternative Practice of Tropical Convolution to Traditional Convolutional Neural Networks
Mar 03, 2021

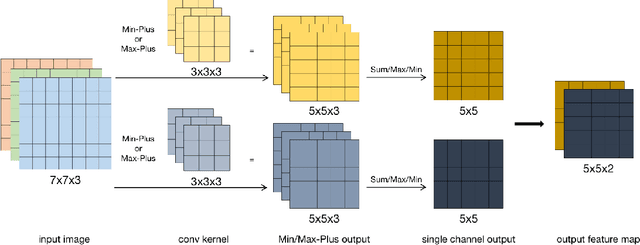
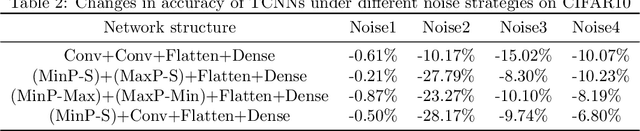
Convolutional neural networks (CNNs) have been used in many machine learning fields. In practical applications, the computational cost of convolutional neural networks is often high with the deepening of the network and the growth of data volume, mostly due to a large amount of multiplication operations of floating-point numbers in convolution operations. To reduce the amount of multiplications, we propose a new type of CNNs called Tropical Convolutional Neural Networks (TCNNs) which are built on tropical convolutions in which the multiplications and additions in conventional convolutional layers are replaced by additions and min/max operations respectively. In addition, since tropical convolution operators are essentially nonlinear operators, we expect TCNNs to have higher nonlinear fitting ability than conventional CNNs. In the experiments, we test and analyze several different architectures of TCNNs for image classification tasks in comparison with similar-sized conventional CNNs. The results show that TCNN can achieve higher expressive power than ordinary convolutional layers on the MNIST and CIFAR10 image data set. In different noise environments, there are wins and losses in the robustness of TCNN and ordinary CNNs.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

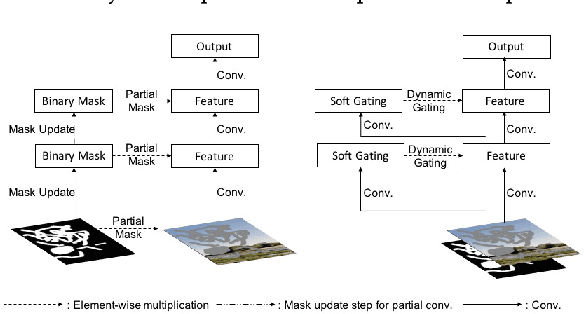

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
Recent Advances and Trends in Multimodal Deep Learning: A Review
May 24, 2021
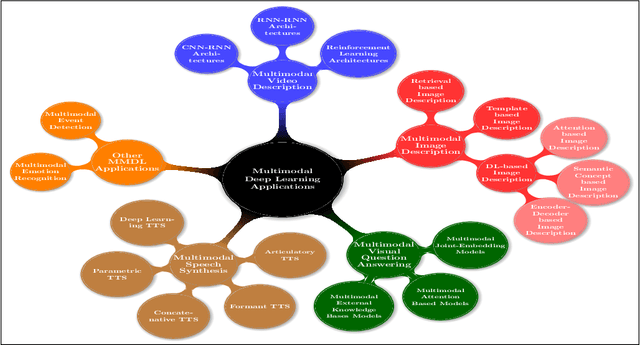

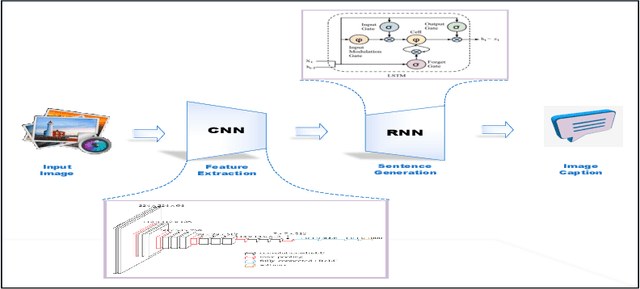
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.
Protecting the Intellectual Properties of Deep Neural Networks with an Additional Class and Steganographic Images
Apr 19, 2021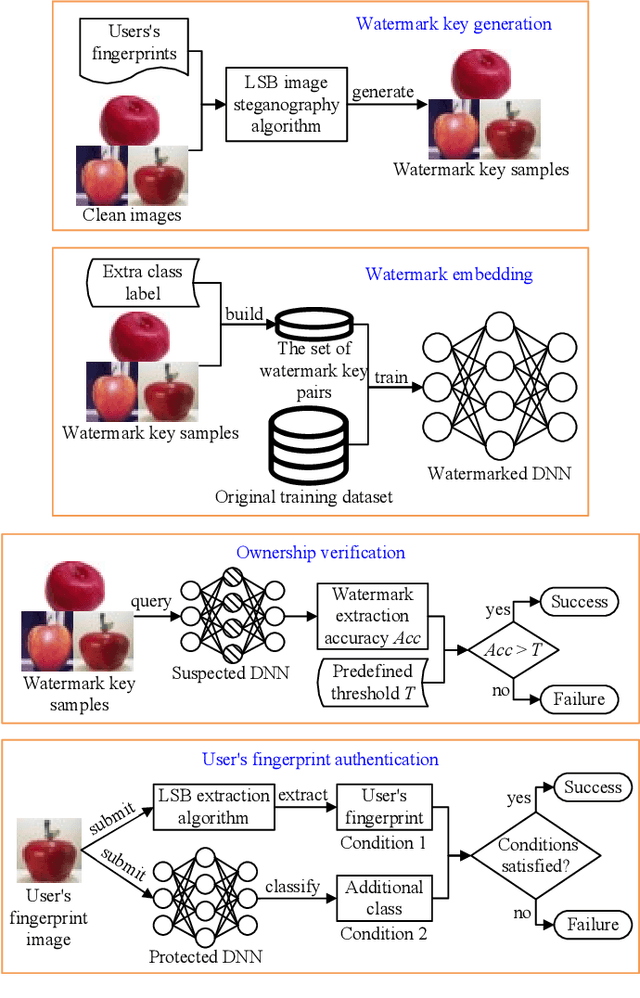
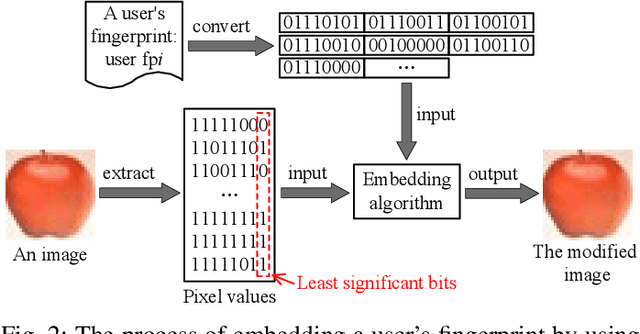
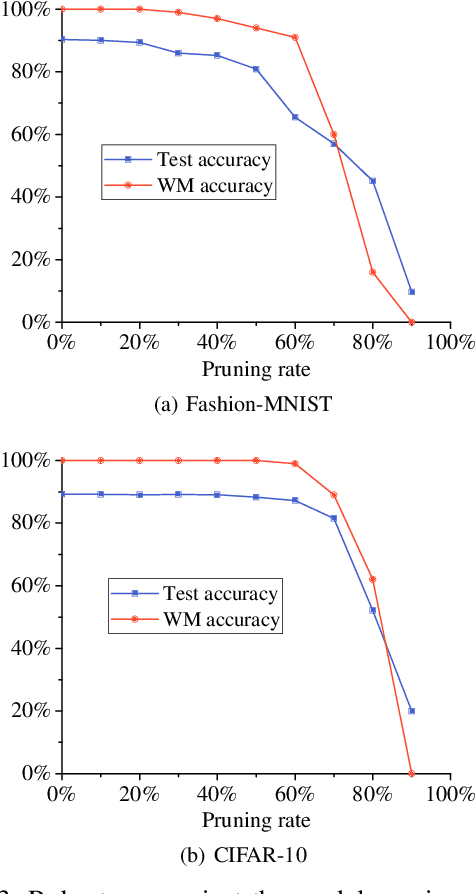
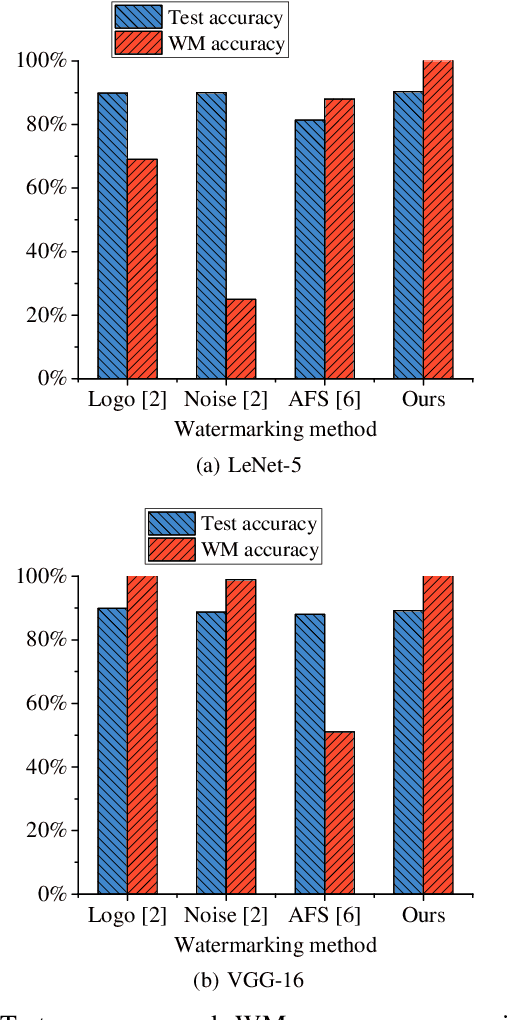
Recently, the research on protecting the intellectual properties (IP) of deep neural networks (DNN) has attracted serious concerns. A number of DNN copyright protection methods have been proposed. However, most of the existing watermarking methods focus on verifying the copyright of the model, which do not support the authentication and management of users' fingerprints, thus can not satisfy the requirements of commercial copyright protection. In addition, the query modification attack which was proposed recently can invalidate most of the existing backdoor-based watermarking methods. To address these challenges, in this paper, we propose a method to protect the intellectual properties of DNN models by using an additional class and steganographic images. Specifically, we use a set of watermark key samples to embed an additional class into the DNN, so that the watermarked DNN will classify the watermark key sample as the predefined additional class in the copyright verification stage. We adopt the least significant bit (LSB) image steganography to embed users' fingerprints into watermark key images. Each user will be assigned with a unique fingerprint image so that the user's identity can be authenticated later. Experimental results demonstrate that, the proposed method can protect the copyright of DNN models effectively. On Fashion-MNIST and CIFAR-10 datasets, the proposed method can obtain 100% watermark accuracy and 100% fingerprint authentication success rate. In addition, the proposed method is demonstrated to be robust to the model fine-tuning attack, model pruning attack, and the query modification attack. Compared with three existing watermarking methods (the logo-based, noise-based, and adversarial frontier stitching watermarking methods), the proposed method has better performance on watermark accuracy and robustness against the query modification attack.
Automatic Document Image Binarization using Bayesian Optimization
Oct 21, 2017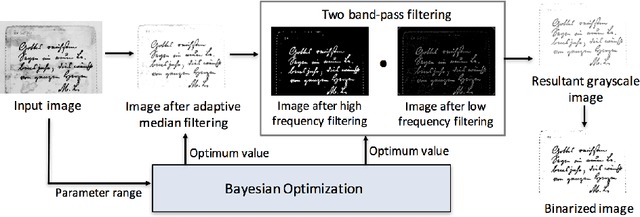
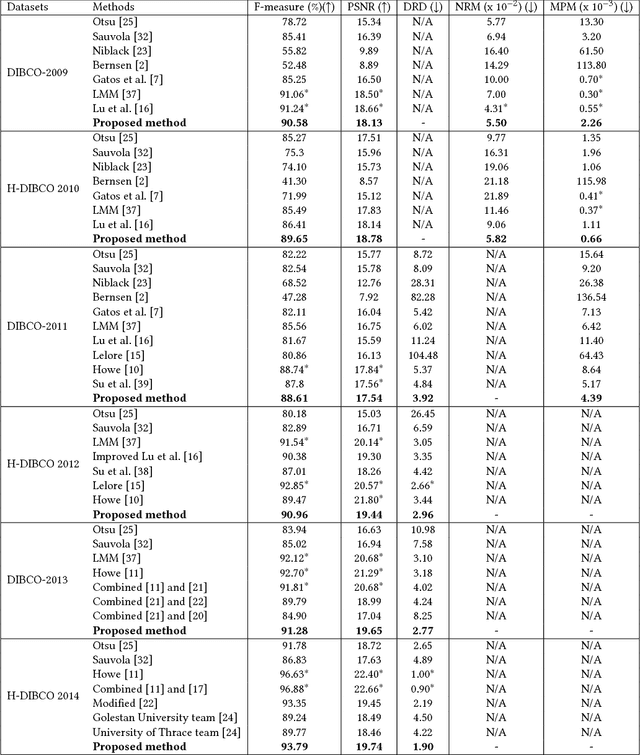

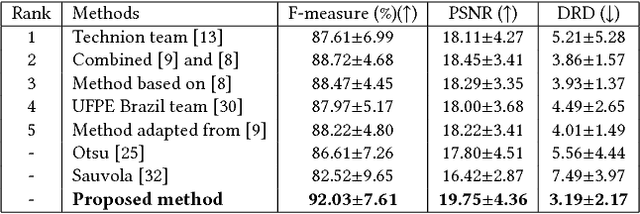
Document image binarization is often a challenging task due to various forms of degradation. Although there exist several binarization techniques in literature, the binarized image is typically sensitive to control parameter settings of the employed technique. This paper presents an automatic document image binarization algorithm to segment the text from heavily degraded document images. The proposed technique uses a two band-pass filtering approach for background noise removal, and Bayesian optimization for automatic hyperparameter selection for optimal results. The effectiveness of the proposed binarization technique is empirically demonstrated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.