 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autonomous Robotic Endoscope Control based on Semantically Rich Instructions
Jul 05, 2021
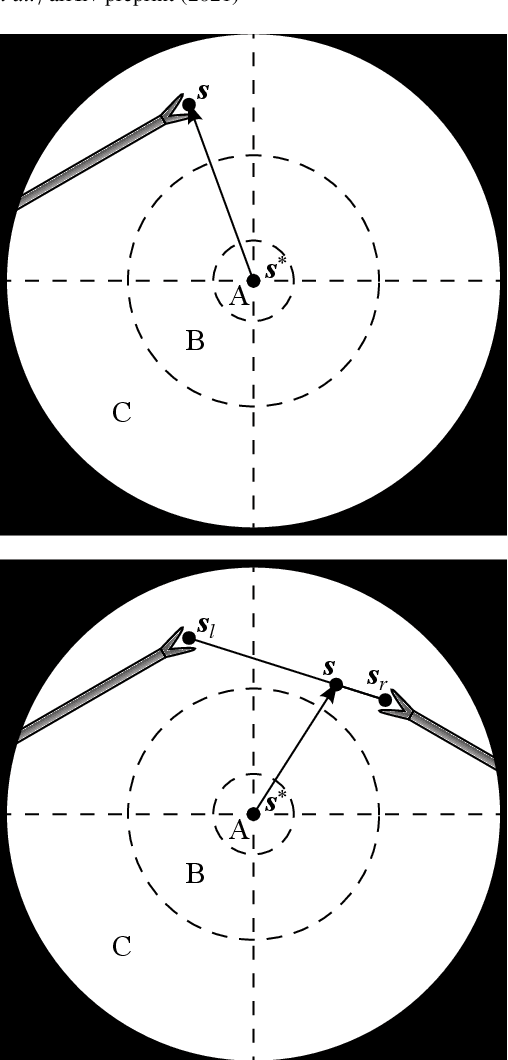
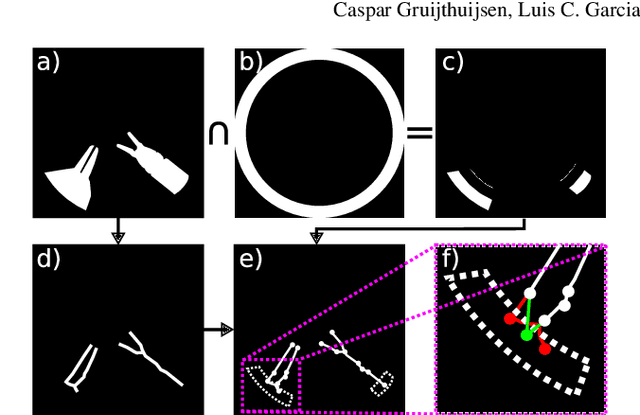
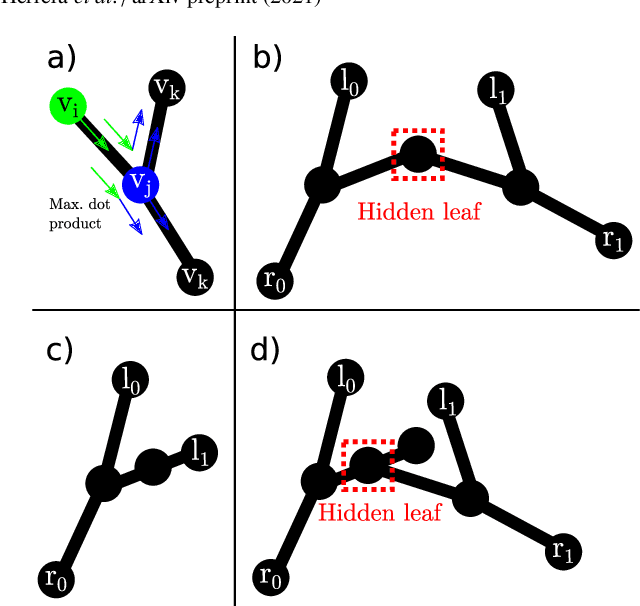
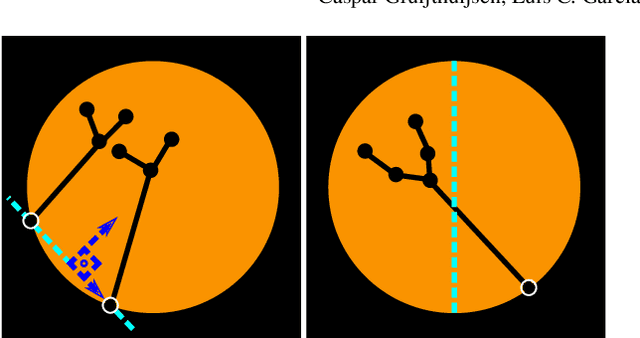
In keyhole interventions, surgeons rely on a colleague to act as a camera assistant when their hands are occupied with surgical instruments. This often leads to reduced image stability, increased task completion times and sometimes errors. Robotic endoscope holders (REHs), controlled by a set of basic instructions, have been proposed as an alternative, but their unnatural handling increases the cognitive load of the surgeon, hindering their widespread clinical acceptance. We propose that REHs collaborate with the operating surgeon via semantically rich instructions that closely resemble those issued to a human camera assistant, such as "focus on my right-hand instrument". As a proof-of-concept, we present a novel system that paves the way towards a synergistic interaction between surgeons and REHs. The proposed platform allows the surgeon to perform a bi-manual coordination and navigation task, while a robotic arm autonomously performs various endoscope positioning tasks. Within our system, we propose a novel tooltip localization method based on surgical tool segmentation, and a novel visual servoing approach that ensures smooth and correct motion of the endoscope camera. We validate our vision pipeline and run a user study of this system. Through successful application in a medically proven bi-manual coordination and navigation task, the framework has shown to be a promising starting point towards broader clinical adoption of REHs.
Do Better ImageNet Models Transfer Better... for Image Recommendation?
Sep 25, 2018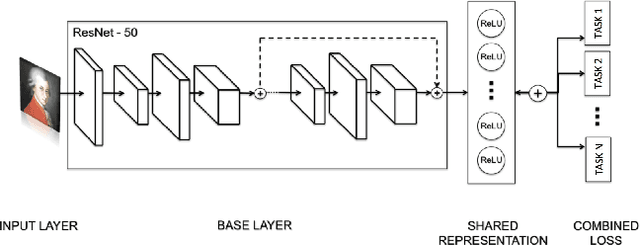
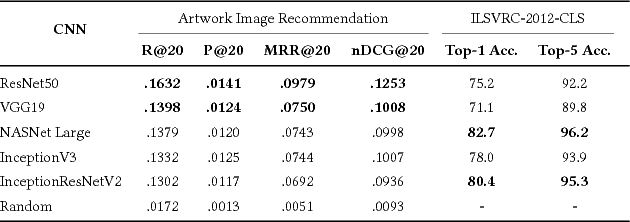
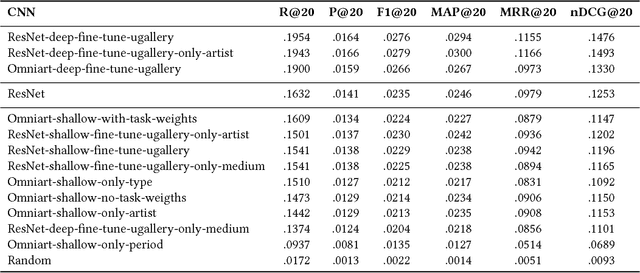
Visual embeddings from Convolutional Neural Networks (CNN) trained on the ImageNet dataset for the ILSVRC challenge have shown consistently good performance for transfer learning and are widely used in several tasks, including image recommendation. However, some important questions have not yet been answered in order to use these embeddings for a larger scope of recommendation domains: a) Do CNNs that perform better in ImageNet are also better for transfer learning in content-based image recommendation?, b) Does fine-tuning help to improve performance? and c) Which is the best way to perform the fine-tuning? In this paper we compare several CNN models pre-trained with ImageNet to evaluate their transfer learning performance to an artwork image recommendation task. Our results indicate that models with better performance in the ImageNet challenge do not always imply better transfer learning for recommendation tasks (e.g. NASNet vs. ResNet). Our results also show that fine-tuning can be helpful even with a small dataset, but not every fine-tuning works. Our results can inform other researchers and practitioners on how to train their CNNs for better transfer learning towards image recommendation systems.
Video Synthesis from a Single Image and Motion Stroke
Dec 05, 2018
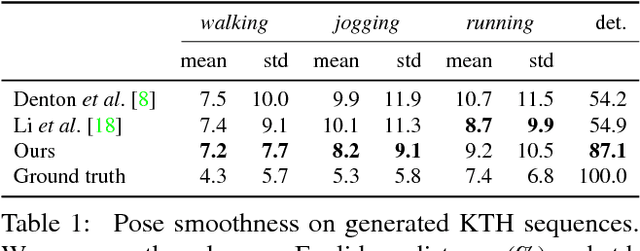
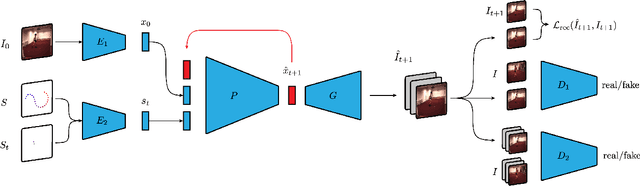

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
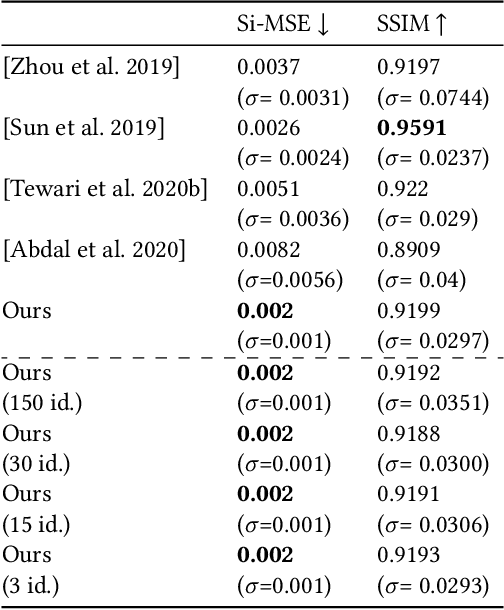
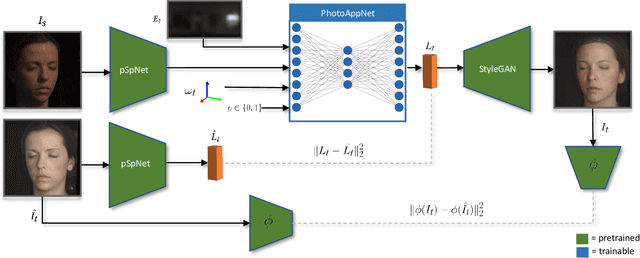
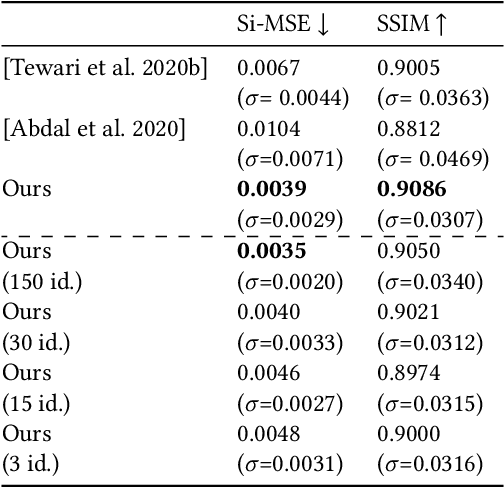
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Evaluating Foveated Video Quality Using Entropic Differencing
Jun 12, 2021
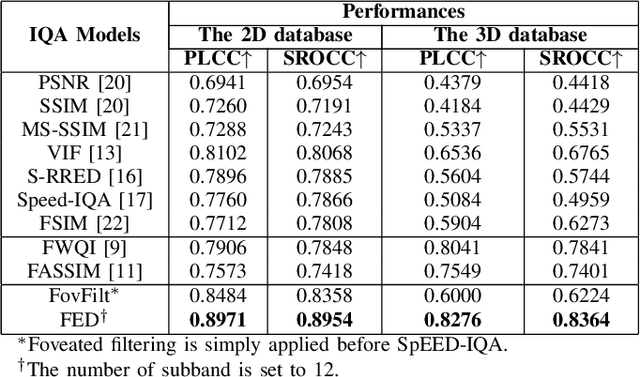
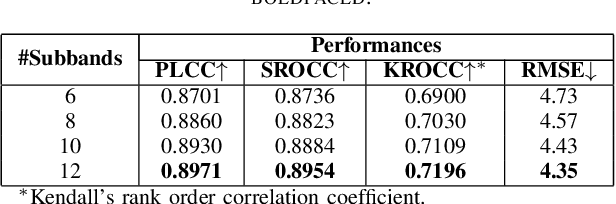
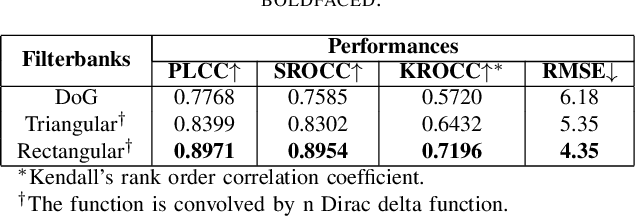
Virtual Reality is regaining attention due to recent advancements in hardware technology. Immersive images / videos are becoming widely adopted to carry omnidirectional visual information. However, due to the requirements for higher spatial and temporal resolution of real video data, immersive videos require significantly larger bandwidth consumption. To reduce stresses on bandwidth, foveated video compression is regaining popularity, whereby the space-variant spatial resolution of the retina is exploited. Towards advancing the progress of foveated video compression, we propose a full reference (FR) foveated image quality assessment algorithm, which we call foveated entropic differencing (FED), which employs the natural scene statistics of bandpass responses by applying differences of local entropies weighted by a foveation-based error sensitivity function. We evaluate the proposed algorithm by measuring the correlations of the predictions that FED makes against human judgements on the newly created 2D and 3D LIVE-FBT-FCVR databases for Virtual Reality (VR). The performance of the proposed algorithm yields state-of-the-art as compared with other existing full reference algorithms. Software for FED has been made available at: http://live.ece.utexas.edu/research/Quality/FED.zip
Improved OOD Generalization via Adversarial Training and Pre-training
May 24, 2021
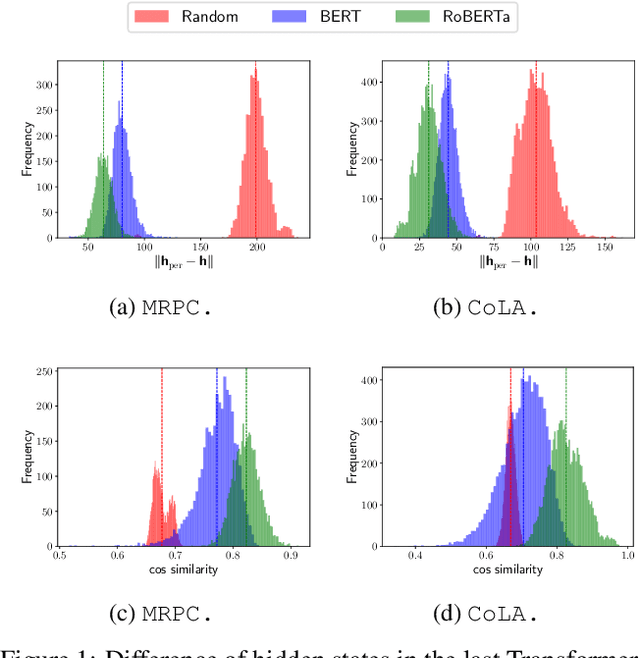
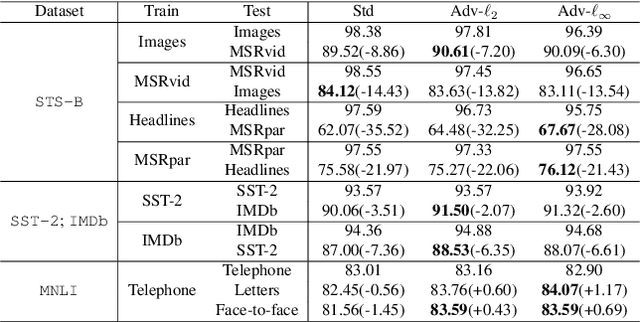
Recently, learning a model that generalizes well on out-of-distribution (OOD) data has attracted great attention in the machine learning community. In this paper, after defining OOD generalization via Wasserstein distance, we theoretically show that a model robust to input perturbation generalizes well on OOD data. Inspired by previous findings that adversarial training helps improve input-robustness, we theoretically show that adversarially trained models have converged excess risk on OOD data, and empirically verify it on both image classification and natural language understanding tasks. Besides, in the paradigm of first pre-training and then fine-tuning, we theoretically show that a pre-trained model that is more robust to input perturbation provides a better initialization for generalization on downstream OOD data. Empirically, after fine-tuning, this better-initialized model from adversarial pre-training also has better OOD generalization.
Adversarial Manifold Matching via Deep Metric Learning for Generative Modeling
Jun 20, 2021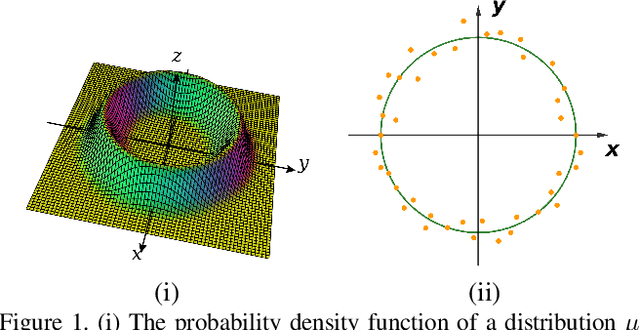
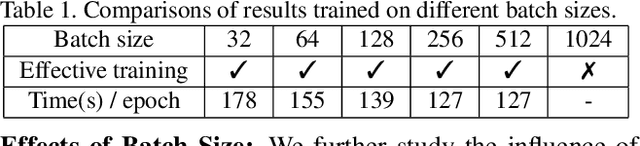
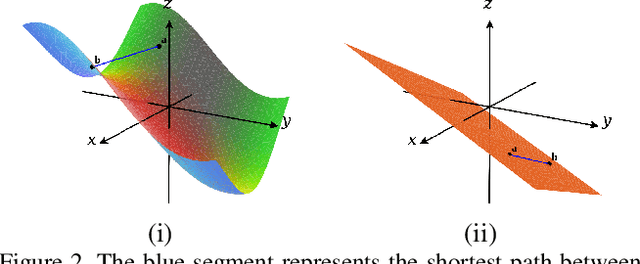
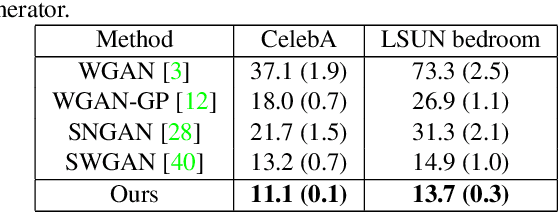
We propose a manifold matching approach to generative models which includes a distribution generator (or data generator) and a metric generator. In our framework, we view the real data set as some manifold embedded in a high-dimensional Euclidean space. The distribution generator aims at generating samples that follow some distribution condensed around the real data manifold. It is achieved by matching two sets of points using their geometric shape descriptors, such as centroid and $p$-diameter, with learned distance metric; the metric generator utilizes both real data and generated samples to learn a distance metric which is close to some intrinsic geodesic distance on the real data manifold. The produced distance metric is further used for manifold matching. The two networks are learned simultaneously during the training process. We apply the approach on both unsupervised and supervised learning tasks: in unconditional image generation task, the proposed method obtains competitive results compared with existing generative models; in super-resolution task, we incorporate the framework in perception-based models and improve visual qualities by producing samples with more natural textures. Both theoretical analysis and real data experiments guarantee the feasibility and effectiveness of the proposed framework.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021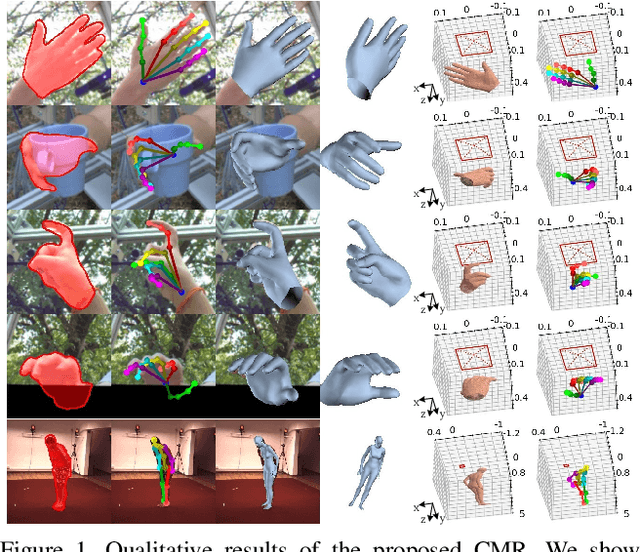
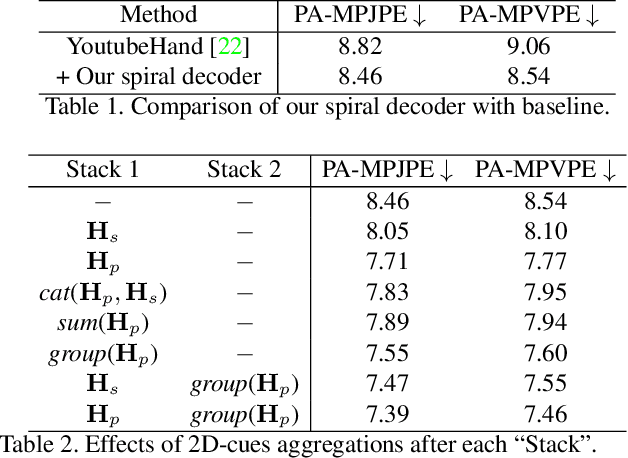
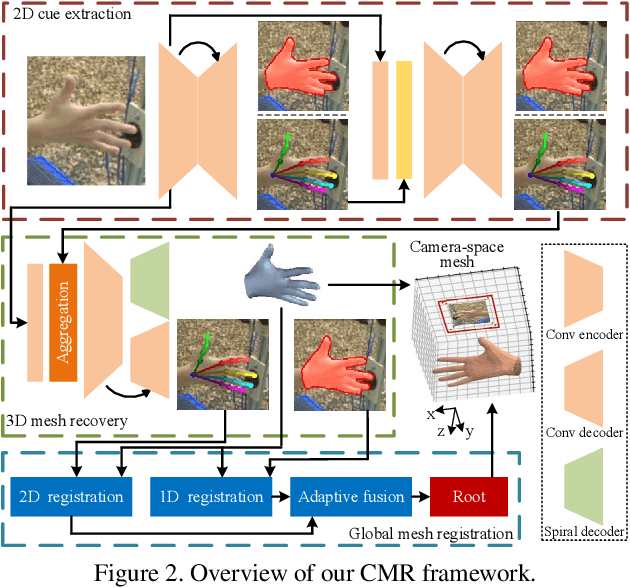
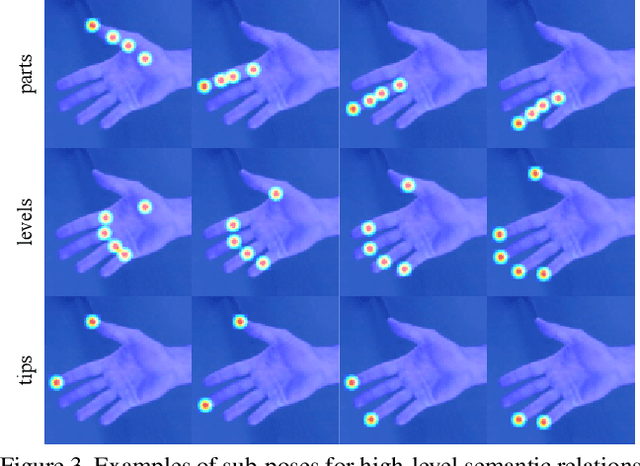
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Tiled Squeeze-and-Excite: Channel Attention With Local Spatial Context
Jul 05, 2021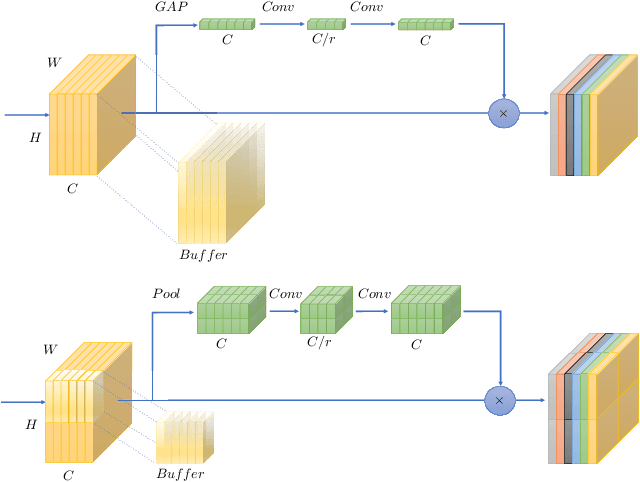
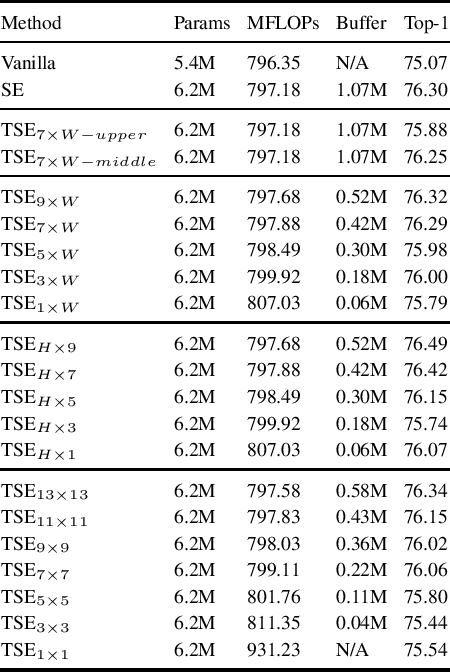
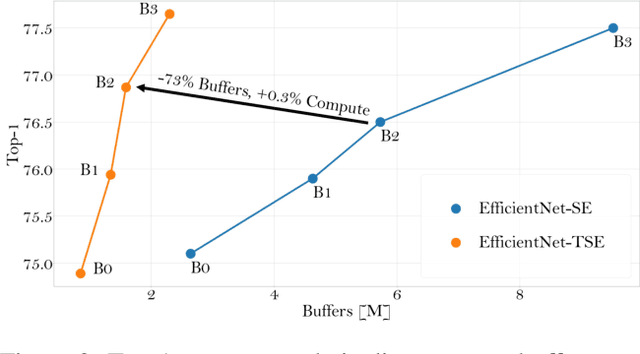
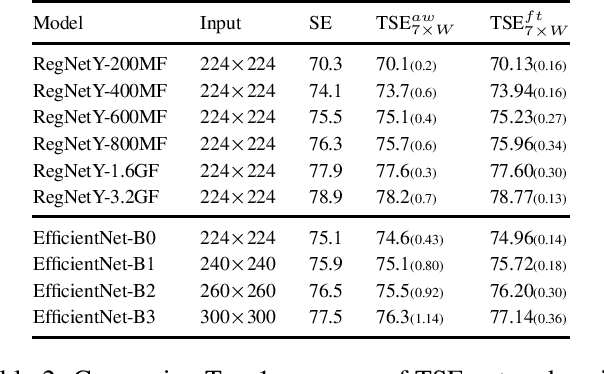
In this paper we investigate the amount of spatial context required for channel attention. To this end we study the popular squeeze-and-excite (SE) block which is a simple and lightweight channel attention mechanism. SE blocks and its numerous variants commonly use global average pooling (GAP) to create a single descriptor for each channel. Here, we empirically analyze the amount of spatial context needed for effective channel attention and find that limited localcontext on the order of seven rows or columns of the original image is sufficient to match the performance of global context. We propose tiled squeeze-and-excite (TSE), which is a framework for building SE-like blocks that employ several descriptors per channel, with each descriptor based on local context only. We further show that TSE is a drop-in replacement for the SE block and can be used in existing SE networks without re-training. This implies that local context descriptors are similar both to each other and to the global context descriptor. Finally, we show that TSE has important practical implications for deployment of SE-networks to dataflow AI accelerators due to their reduced pipeline buffering requirements. For example, using TSE reduces the amount of activation pipeline buffering in EfficientDetD2 by 90% compared to SE (from 50M to 4.77M) without loss of accuracy. Our code and pre-trained models will be publicly available.
Attention Map-guided Two-stage Anomaly Detection using Hard Augmentation
Mar 31, 2021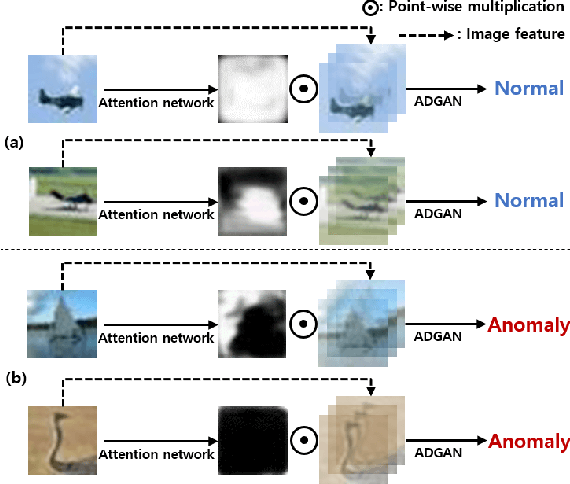
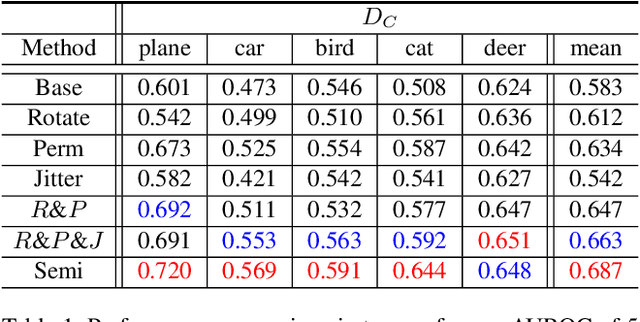
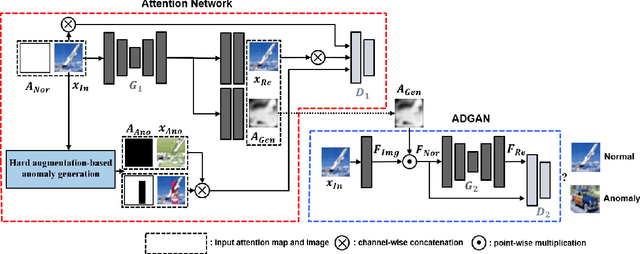

Anomaly detection is a task that recognizes whether an input sample is included in the distribution of a target normal class or an anomaly class. Conventional generative adversarial network (GAN)-based methods utilize an entire image including foreground and background as an input. However, in these methods, a useless region unrelated to the normal class (e.g., unrelated background) is learned as normal class distribution, thereby leading to false detection. To alleviate this problem, this paper proposes a novel two-stage network consisting of an attention network and an anomaly detection GAN (ADGAN). The attention network generates an attention map that can indicate the region representing the normal class distribution. To generate an accurate attention map, we propose the attention loss and the adversarial anomaly loss based on synthetic anomaly samples generated from hard augmentation. By applying the attention map to an image feature map, ADGAN learns the normal class distribution from which the useless region is removed, and it is possible to greatly reduce the problem difficulty of the anomaly detection task. Additionally, the estimated attention map can be used for anomaly segmentation because it can distinguish between normal and anomaly regions. As a result, the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for widely used datasets.