 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Longitudinal Quantitative Assessment of COVID-19 Infection Progression from Chest CTs
Mar 12, 2021
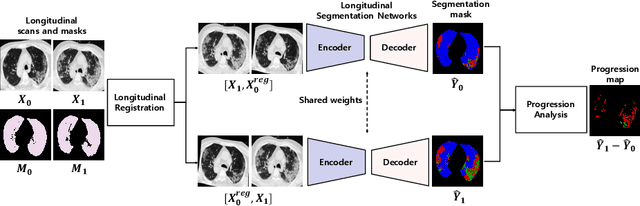


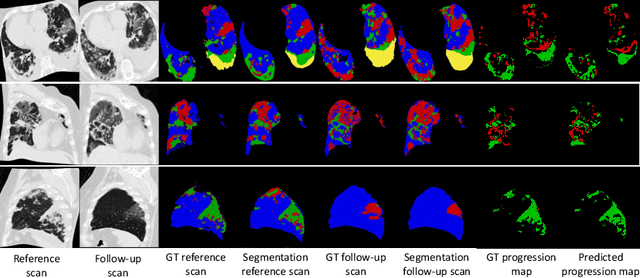
Chest computed tomography (CT) has played an essential diagnostic role in assessing patients with COVID-19 by showing disease-specific image features such as ground-glass opacity and consolidation. Image segmentation methods have proven to help quantify the disease burden and even help predict the outcome. The availability of longitudinal CT series may also result in an efficient and effective method to reliably assess the progression of COVID-19, monitor the healing process and the response to different therapeutic strategies. In this paper, we propose a new framework to identify infection at a voxel level (identification of healthy lung, consolidation, and ground-glass opacity) and visualize the progression of COVID-19 using sequential low-dose non-contrast CT scans. In particular, we devise a longitudinal segmentation network that utilizes the reference scan information to improve the performance of disease identification. Experimental results on a clinical longitudinal dataset collected in our institution show the effectiveness of the proposed method compared to the static deep neural networks for disease quantification.
Deep Learning and Machine Vision for Food Processing: A Survey
Mar 30, 2021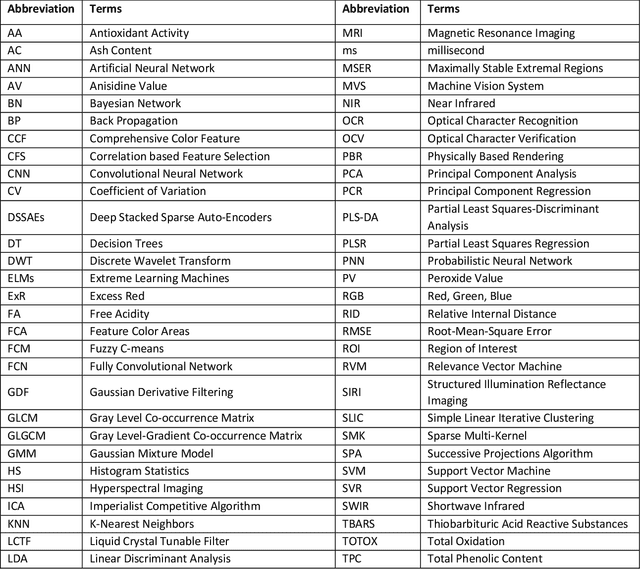
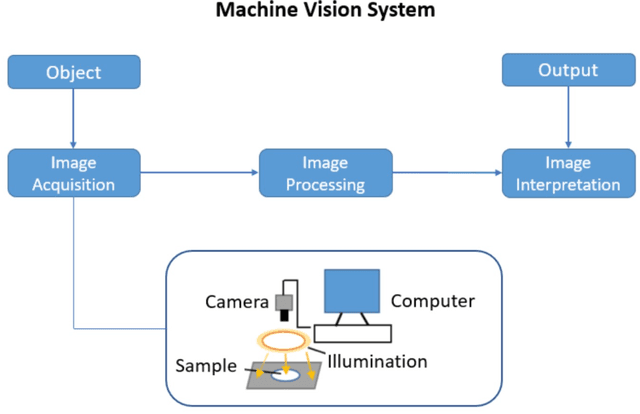

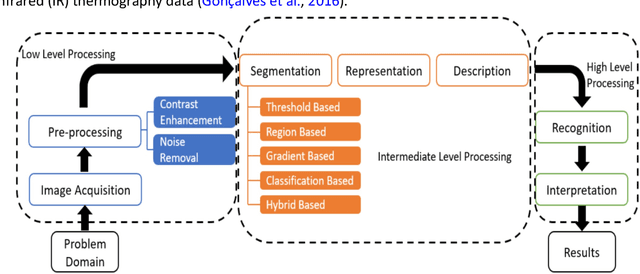
The quality and safety of food is an important issue to the whole society, since it is at the basis of human health, social development and stability. Ensuring food quality and safety is a complex process, and all stages of food processing must be considered, from cultivating, harvesting and storage to preparation and consumption. However, these processes are often labour-intensive. Nowadays, the development of machine vision can greatly assist researchers and industries in improving the efficiency of food processing. As a result, machine vision has been widely used in all aspects of food processing. At the same time, image processing is an important component of machine vision. Image processing can take advantage of machine learning and deep learning models to effectively identify the type and quality of food. Subsequently, follow-up design in the machine vision system can address tasks such as food grading, detecting locations of defective spots or foreign objects, and removing impurities. In this paper, we provide an overview on the traditional machine learning and deep learning methods, as well as the machine vision techniques that can be applied to the field of food processing. We present the current approaches and challenges, and the future trends.
Learning Uncertainty For Safety-Oriented Semantic Segmentation In Autonomous Driving
May 28, 2021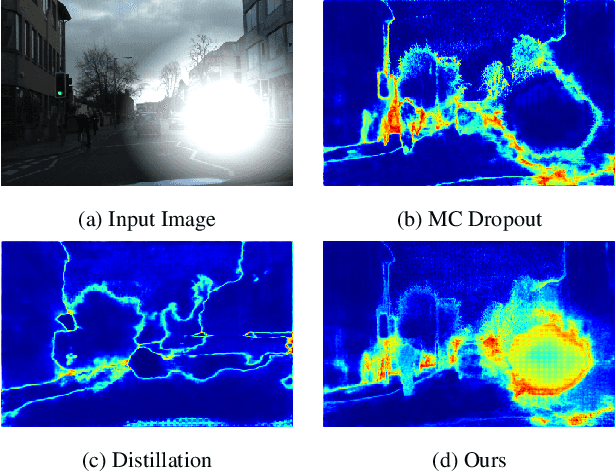
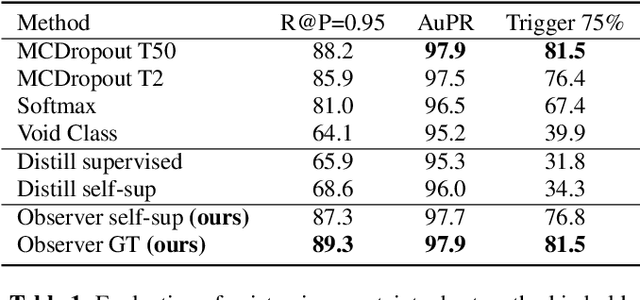
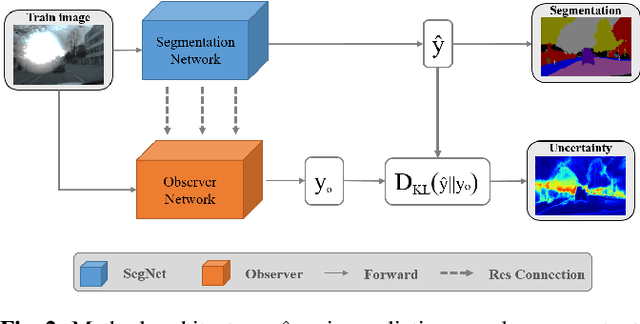
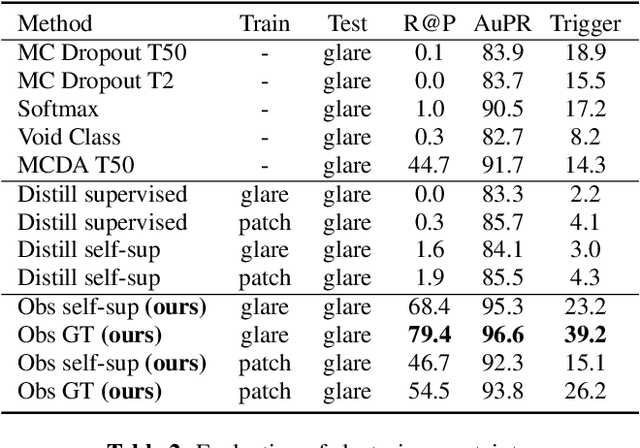
In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. We show experimentally that our proposed approach is much less computationally intensive at inference time than competing methods (e.g. MCDropout), while delivering better results on safety-oriented evaluation metrics on the CamVid dataset, especially in the case of glare artifacts.
Bridge the Gap Between Model-based and Model-free Human Reconstruction
Jun 11, 2021
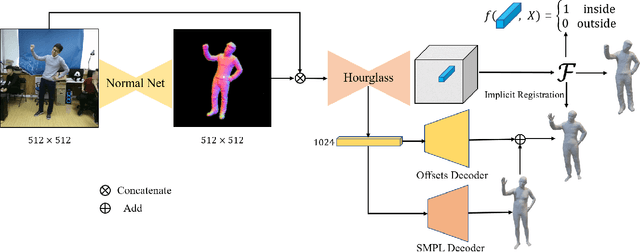

It is challenging to directly estimate the geometry of human from a single image due to the high diversity and complexity of body shapes with the various clothing styles. Most of model-based approaches are limited to predict the shape and pose of a minimally clothed body with over-smoothing surface. Although capturing the fine detailed geometries, the model-free methods are lack of the fixed mesh topology. To address these issues, we propose a novel topology-preserved human reconstruction approach by bridging the gap between model-based and model-free human reconstruction. We present an end-to-end neural network that simultaneously predicts the pixel-aligned implicit surface and the explicit mesh model built by graph convolutional neural network. Moreover, an extra graph convolutional neural network is employed to estimate the vertex offsets between the implicit surface and parametric mesh model. Finally, we suggest an efficient implicit registration method to refine the neural network output in implicit space. Experiments on DeepHuman dataset showed that our approach is effective.
Correlated Logistic Model With Elastic Net Regularization for Multilabel Image Classification
Apr 17, 2019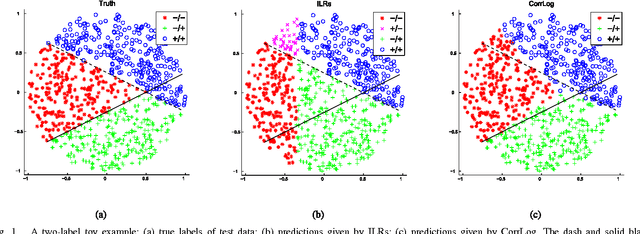

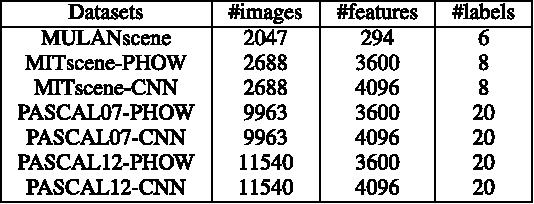
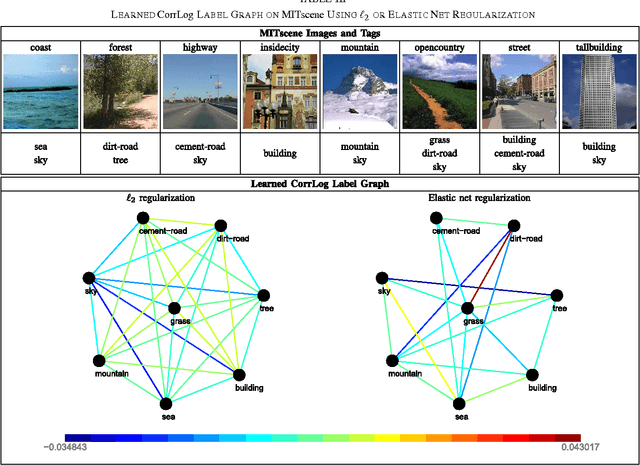
In this paper, we present correlated logistic (CorrLog) model for multilabel image classification. CorrLog extends conventional logistic regression model into multilabel cases, via explicitly modeling the pairwise correlation between labels. In addition, we propose to learn the model parameters of CorrLog with elastic net regularization, which helps exploit the sparsity in feature selection and label correlations and thus further boost the performance of multilabel classification. CorrLog can be efficiently learned, though approximately, by regularized maximum pseudo likelihood estimation, and it enjoys a satisfying generalization bound that is independent of the number of labels. CorrLog performs competitively for multilabel image classification on benchmark data sets MULAN scene, MIT outdoor scene, PASCAL VOC 2007, and PASCAL VOC 2012, compared with the state-of-the-art multilabel classification algorithms.
Data Augmentation using Random Image Cropping and Patching for Deep CNNs
Nov 22, 2018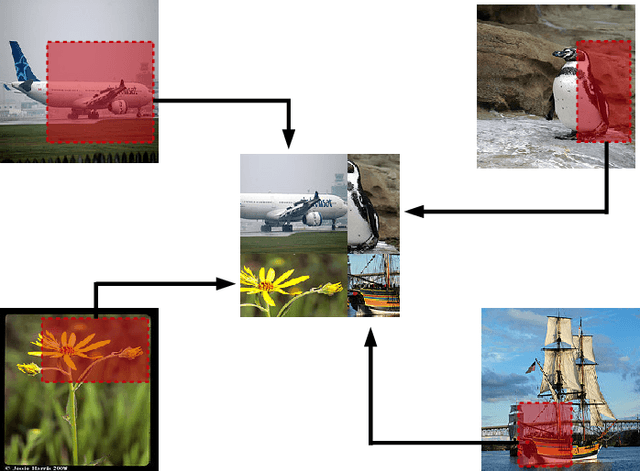
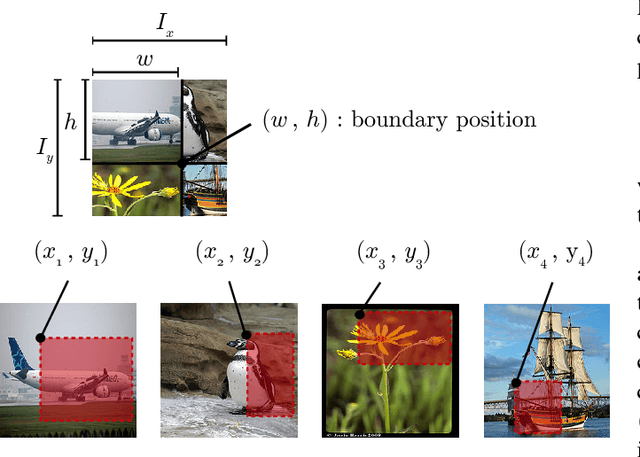
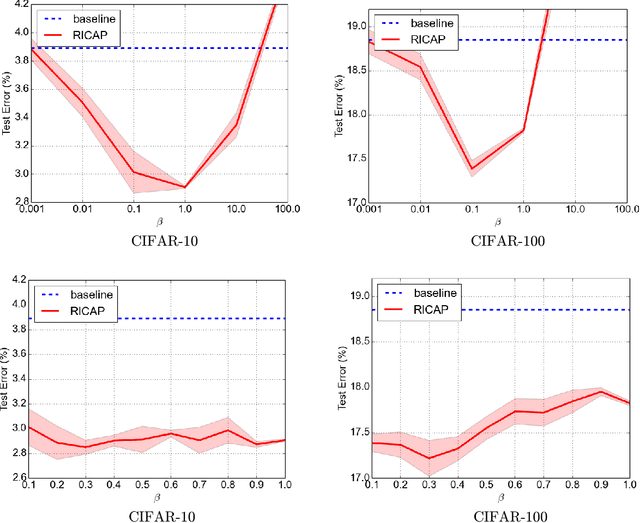

Deep convolutional neural networks (CNNs) have achieved remarkable results in image processing tasks. However, their high expression ability risks overfitting. Consequently, data augmentation techniques have been proposed to prevent overfitting while enriching datasets. Recent CNN architectures with more parameters are rendering traditional data augmentation techniques insufficient. In this study, we propose a new data augmentation technique called random image cropping and patching (RICAP) which randomly crops four images and patches them to create a new training image. Moreover, RICAP mixes the class labels of the four images, resulting in an advantage similar to label smoothing. We evaluated RICAP with current state-of-the-art CNNs (e.g., the shake-shake regularization model) by comparison with competitive data augmentation techniques such as cutout and mixup. RICAP achieves a new state-of-the-art test error of $2.19\%$ on CIFAR-10. We also confirmed that deep CNNs with RICAP achieve better results on classification tasks using CIFAR-100 and ImageNet and an image-caption retrieval task using Microsoft COCO.
Hand Gesture Recognition Based on a Nonconvex Regularization
Apr 29, 2021


Recognition of hand gestures is one of the most fundamental tasks in human-robot interaction. Sparse representation based methods have been widely used due to their efficiency and low requirements on the training data. Recently, nonconvex regularization techniques including the $\ell_{1-2}$ regularization have been proposed in the image processing community to promote sparsity while achieving efficient performance. In this paper, we propose a vision-based human arm gesture recognition model based on the $\ell_{1-2}$ regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on realistic data sets have shown the effectiveness of this method in identifying arm gestures.
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Feb 24, 2020
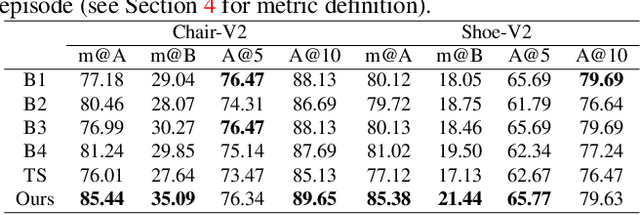
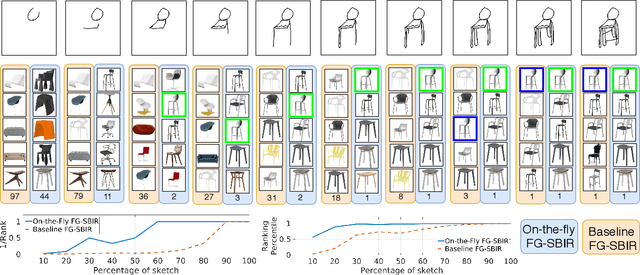
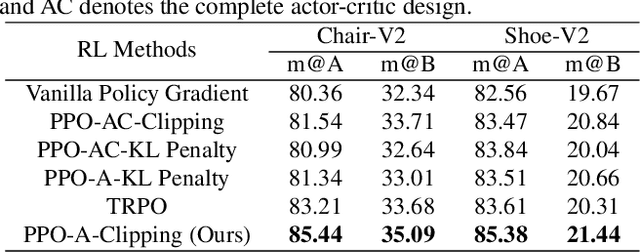
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
MS-UNIQUE: Multi-model and Sharpness-weighted Unsupervised Image Quality Estimation
Nov 21, 2018
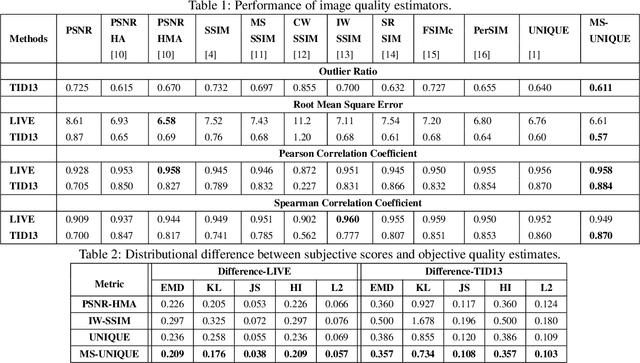
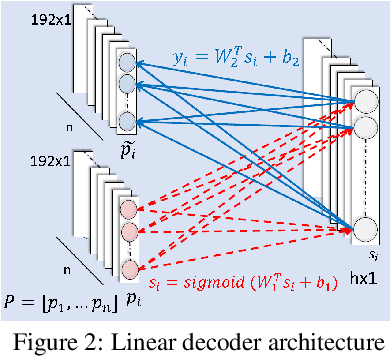
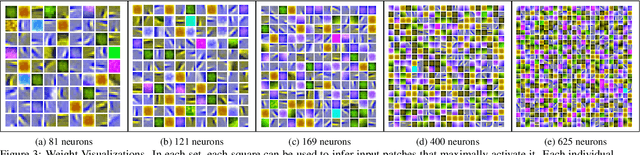
In this paper, we train independent linear decoder models to estimate the perceived quality of images. More specifically, we calculate the responses of individual non-overlapping image patches to each of the decoders and scale these responses based on the sharpness characteristics of filter set. We use multiple linear decoders to capture different abstraction levels of the image patches. Training each model is carried out on 100,000 image patches from the ImageNet database in an unsupervised fashion. Color space selection and ZCA Whitening are performed over these patches to enhance the descriptiveness of the data. The proposed quality estimator is tested on the LIVE and the TID 2013 image quality assessment databases. Performance of the proposed method is compared against eleven other state of the art methods in terms of accuracy, consistency, linearity, and monotonic behavior. Based on experimental results, the proposed method is generally among the top performing quality estimators in all categories.
* Paper: 6 pages, 6 figures, 2 tables and Presentation: 21 slides [Ancillary files]
Dual Residual Networks Leveraging the Potential of Paired Operations for Image Restoration
Apr 07, 2019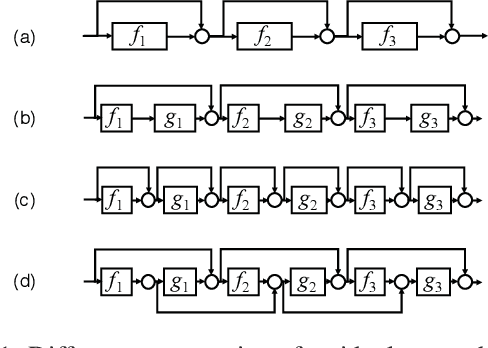


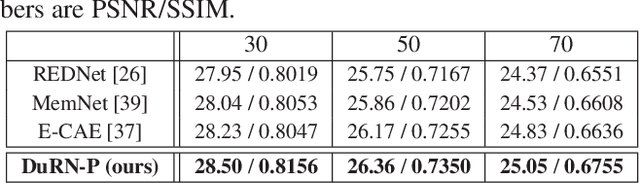
In this paper, we study design of deep neural networks for tasks of image restoration. We propose a novel style of residual connections dubbed "dual residual connection", which exploits the potential of paired operations, e.g., up- and down-sampling or convolution with large- and small-size kernels. We design a modular block implementing this connection style; it is equipped with two containers to which arbitrary paired operations are inserted. Adopting the "unraveled" view of the residual networks proposed by Veit et al., we point out that a stack of the proposed modular blocks allows the first operation in a block interact with the second operation in any subsequent blocks. Specifying the two operations in each of the stacked blocks, we build a complete network for each individual task of image restoration. We experimentally evaluate the proposed approach on five image restoration tasks using nine datasets. The results show that the proposed networks with properly chosen paired operations outperform previous methods on almost all of the tasks and datasets.