 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Storyboard Artist: Visualizing Stories with Coherent Image Sequences
Nov 24, 2019
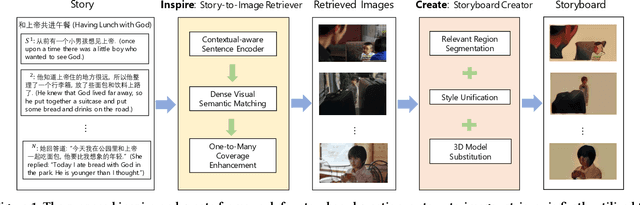
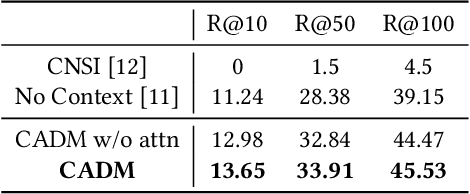
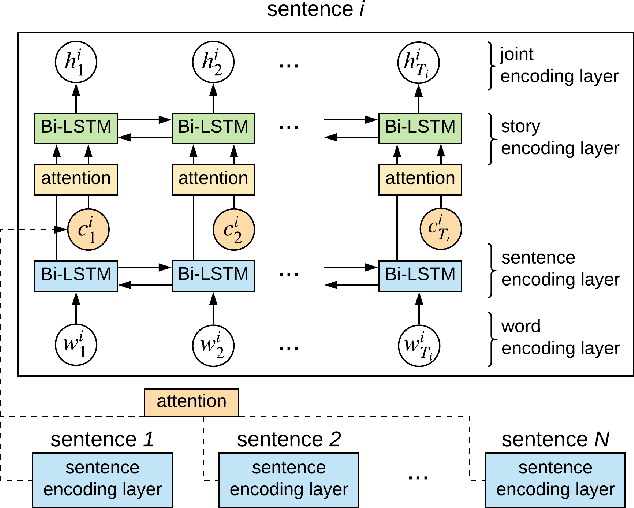
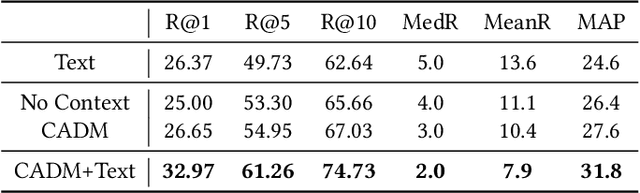
A storyboard is a sequence of images to illustrate a story containing multiple sentences, which has been a key process to create different story products. In this paper, we tackle a new multimedia task of automatic storyboard creation to facilitate this process and inspire human artists. Inspired by the fact that our understanding of languages is based on our past experience, we propose a novel inspire-and-create framework with a story-to-image retriever that selects relevant cinematic images for inspiration and a storyboard creator that further refines and renders images to improve the relevancy and visual consistency. The proposed retriever dynamically employs contextual information in the story with hierarchical attentions and applies dense visual-semantic matching to accurately retrieve and ground images. The creator then employs three rendering steps to increase the flexibility of retrieved images, which include erasing irrelevant regions, unifying styles of images and substituting consistent characters. We carry out extensive experiments on both in-domain and out-of-domain visual story datasets. The proposed model achieves better quantitative performance than the state-of-the-art baselines for storyboard creation. Qualitative visualizations and user studies further verify that our approach can create high-quality storyboards even for stories in the wild.
Deep Bayesian Unsupervised Lifelong Learning
Jun 13, 2021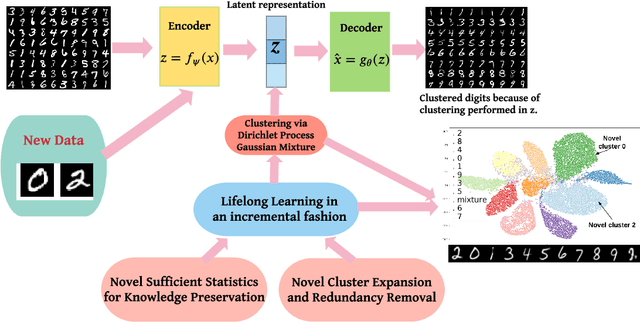

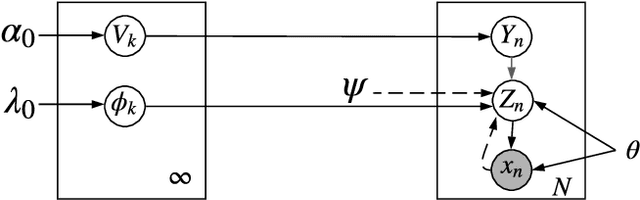
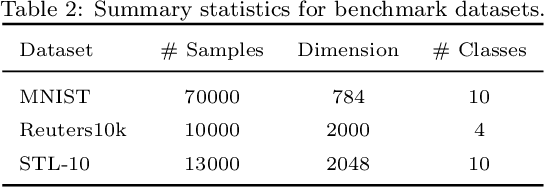
Lifelong Learning (LL) refers to the ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Much attention has been given lately to Supervised Lifelong Learning (SLL) with a stream of labelled data. In contrast, we focus on resolving challenges in Unsupervised Lifelong Learning (ULL) with streaming unlabelled data when the data distribution and the unknown class labels evolve over time. Bayesian framework is natural to incorporate past knowledge and sequentially update the belief with new data. We develop a fully Bayesian inference framework for ULL with a novel end-to-end Deep Bayesian Unsupervised Lifelong Learning (DBULL) algorithm, which can progressively discover new clusters without forgetting the past with unlabelled data while learning latent representations. To efficiently maintain past knowledge, we develop a novel knowledge preservation mechanism via sufficient statistics of the latent representation for raw data. To detect the potential new clusters on the fly, we develop an automatic cluster discovery and redundancy removal strategy in our inference inspired by Nonparametric Bayesian statistics techniques. We demonstrate the effectiveness of our approach using image and text corpora benchmark datasets in both LL and batch settings.
Fused Deep Features Based Classification Framework for COVID-19 Classification with Optimized MLP
Mar 15, 2021
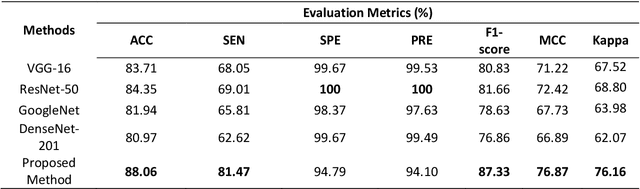
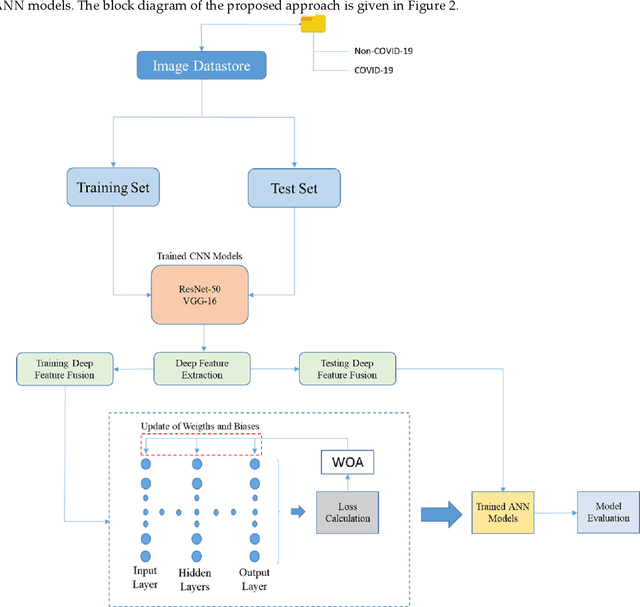
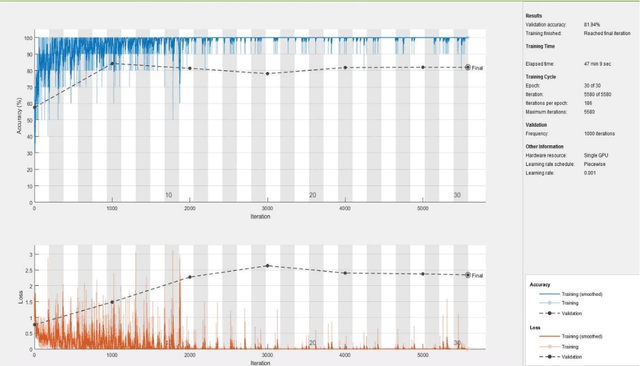
The new type of Coronavirus disease called COVID-19 continues to spread quite rapidly. Although it shows some specific symptoms, this disease, which can show different symptoms in almost every individual, has caused hundreds of thousands of patients to die. Although healthcare professionals work hard to prevent further loss of life, the rate of disease spread is very high. For this reason, the help of computer aided diagnosis (CAD) and artificial intelligence (AI) algorithms is vital. In this study, a method based on optimization of convolutional neural network (CNN) architecture, which is the most effective image analysis method of today, is proposed to fulfill the mentioned COVID-19 detection needs. First, COVID-19 images are trained using ResNet-50 and VGG-16 architectures. Then, features in the last layer of these two architectures are combined with feature fusion. These new image features matrices obtained with feature fusion are classified for COVID detection. A multi-layer perceptron (MLP) structure optimized by the whale optimization algorithm is used for the classification process. The obtained results show that the performance of the proposed framework is almost 4.5% higher than VGG-16 performance and almost 3.5% higher than ResNet-50 performance.
MR elasticity reconstruction using statistical physical modeling and explicit data-driven denoising regularizer
May 27, 2021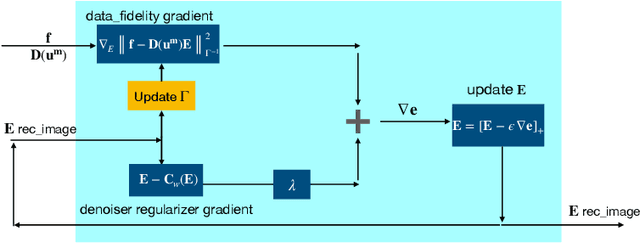
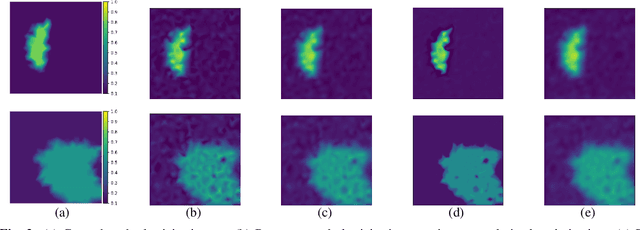
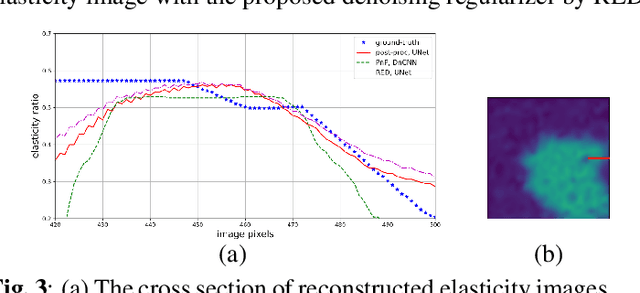
Elasticity image, visualizing the quantitative map of tissue stiffness, can be reconstructed by solving an inverse problem. Classical methods for magnetic resonance elastography (MRE) try to solve a regularized optimization problem comprising a deterministic physical model and a prior constraint as data-fidelity term and regularization term, respectively. For improving the elasticity reconstructions, appropriate prior about the underlying elasticity distribution is required which is not unique. This article proposes an infused approach for MRE reconstruction by integrating the statistical representation of the physical laws of harmonic motions and learning-based prior. For data-fidelity term, we use a statistical linear-algebraic model of equilibrium equations and for the regularizer, data-driven regularization by denoising (RED) is utilized. In the proposed optimization paradigm, the regularizer gradient is simply replaced by the residual of learned denoiser leading to time-efficient computation and convex explicit objective function. Simulation results of elasticity reconstruction verify the effectiveness of the proposed approach.
Rectified Meta-Learning from Noisy Labels for Robust Image-based Plant Disease Diagnosis
Mar 18, 2020
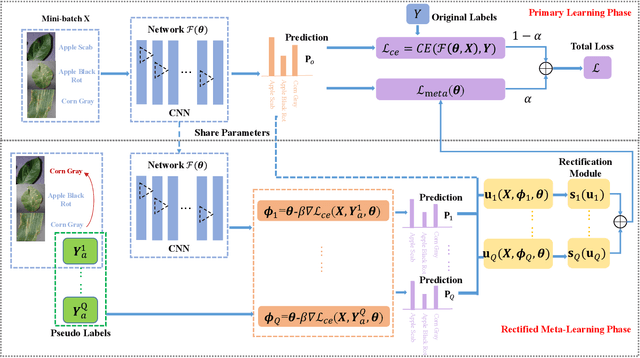
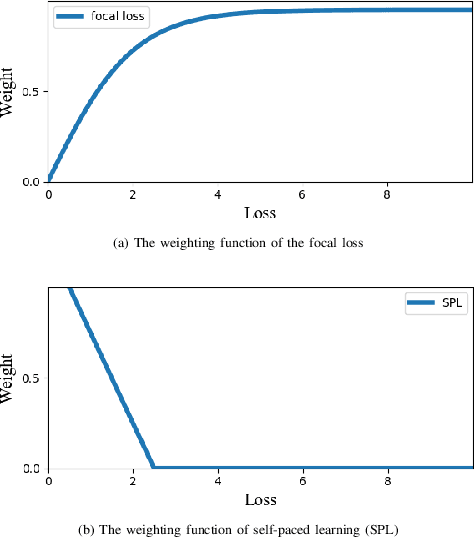

Plant diseases serve as one of main threats to food security and crop production. It is thus valuable to exploit recent advances of artificial intelligence to assist plant disease diagnosis. One popular approach is to transform this problem as a leaf image classification task, which can be then addressed by the powerful convolutional neural networks (CNNs). However, the performance of CNN-based classification approach depends on a large amount of high-quality manually labeled training data, which are inevitably introduced noise on labels in practice, leading to model overfitting and performance degradation. To overcome this problem, we propose a novel framework that incorporates rectified meta-learning module into common CNN paradigm to train a noise-robust deep network without using extra supervision information. The proposed method enjoys the following merits: i) A rectified meta-learning is designed to pay more attention to unbiased samples, leading to accelerated convergence and improved classification accuracy. ii) Our method is free on assumption of label noise distribution, which works well on various kinds of noise. iii) Our method serves as a plug-and-play module, which can be embedded into any deep models optimized by gradient descent based method. Extensive experiments are conducted to demonstrate the superior performance of our algorithm over the state-of-the-arts.
Scalable Marginal Likelihood Estimation for Model Selection in Deep Learning
May 11, 2021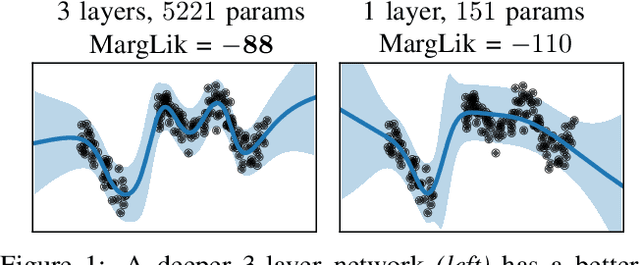
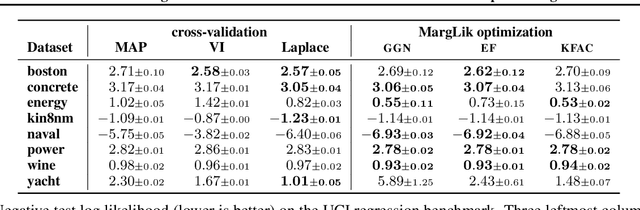
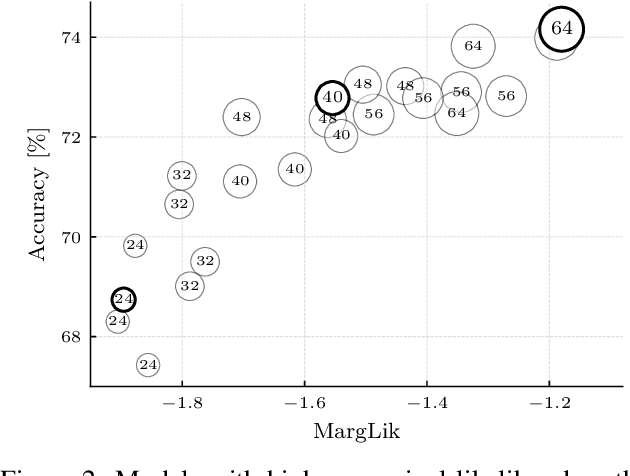
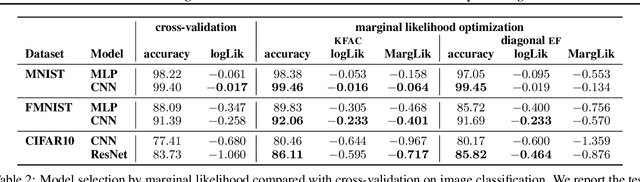
Marginal-likelihood based model-selection, even though promising, is rarely used in deep learning due to estimation difficulties. Instead, most approaches rely on validation data, which may not be readily available. In this work, we present a scalable marginal-likelihood estimation method to select both the hyperparameters and network architecture based on the training data alone. Some hyperparameters can be estimated online during training, simplifying the procedure. Our marginal-likelihood estimate is based on Laplace's method and Gauss-Newton approximations to the Hessian, and it outperforms cross-validation and manual-tuning on standard regression and image classification datasets, especially in terms of calibration and out-of-distribution detection. Our work shows that marginal likelihoods can improve generalization and be useful when validation data is unavailable (e.g., in nonstationary settings).
Anatomy of Domain Shift Impact on U-Net Layers in MRI Segmentation
Jul 10, 2021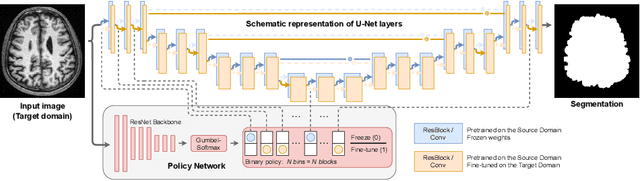
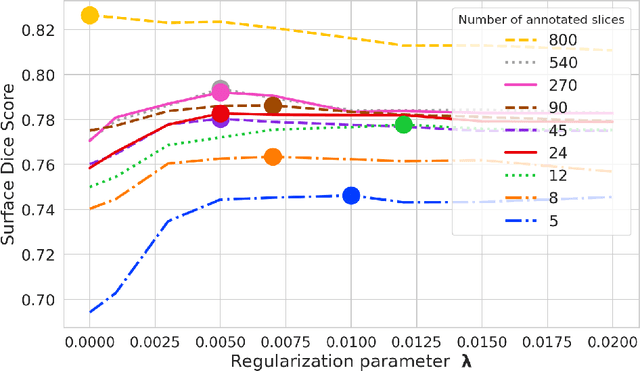
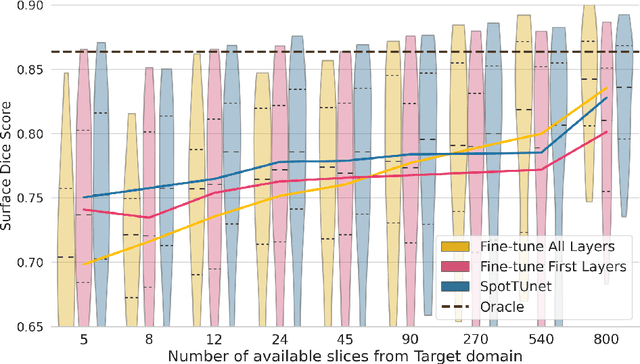
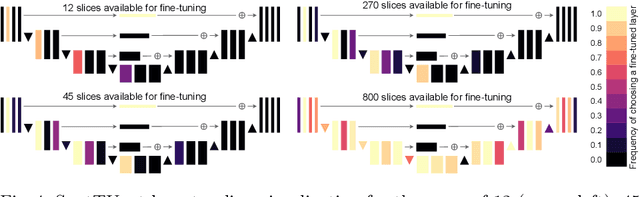
Domain Adaptation (DA) methods are widely used in medical image segmentation tasks to tackle the problem of differently distributed train (source) and test (target) data. We consider the supervised DA task with a limited number of annotated samples from the target domain. It corresponds to one of the most relevant clinical setups: building a sufficiently accurate model on the minimum possible amount of annotated data. Existing methods mostly fine-tune specific layers of the pretrained Convolutional Neural Network (CNN). However, there is no consensus on which layers are better to fine-tune, e.g. the first layers for images with low-level domain shift or the deeper layers for images with high-level domain shift. To this end, we propose SpotTUnet - a CNN architecture that automatically chooses the layers which should be optimally fine-tuned. More specifically, on the target domain, our method additionally learns the policy that indicates whether a specific layer should be fine-tuned or reused from the pretrained network. We show that our method performs at the same level as the best of the nonflexible fine-tuning methods even under the extreme scarcity of annotated data. Secondly, we show that SpotTUnet policy provides a layer-wise visualization of the domain shift impact on the network, which could be further used to develop robust domain generalization methods. In order to extensively evaluate SpotTUnet performance, we use a publicly available dataset of brain MR images (CC359), characterized by explicit domain shift. We release a reproducible experimental pipeline.
Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
Dec 24, 2020

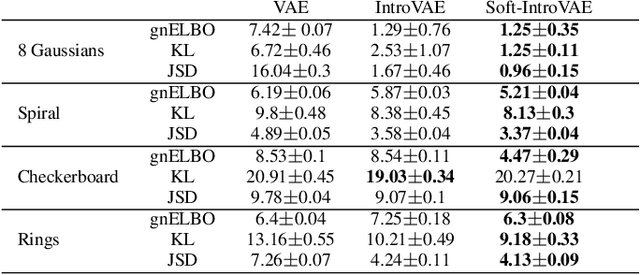
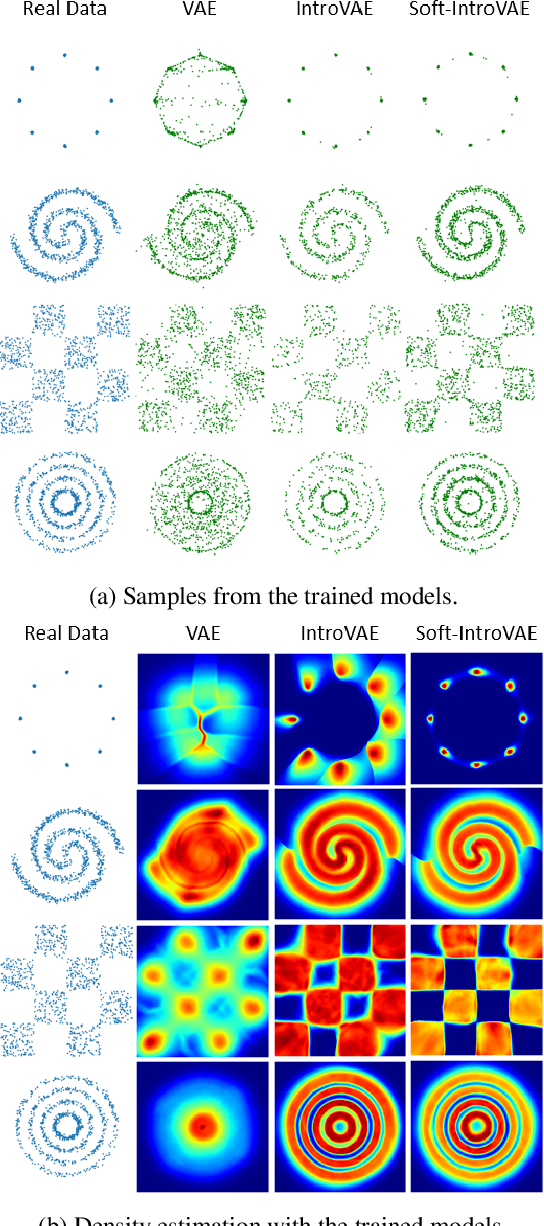
The recently introduced introspective variational autoencoder (IntroVAE) exhibits outstanding image generations, and allows for amortized inference using an image encoder. The main idea in IntroVAE is to train a VAE adversarially, using the VAE encoder to discriminate between generated and real data samples. However, the original IntroVAE loss function relied on a particular hinge-loss formulation that is very hard to stabilize in practice, and its theoretical convergence analysis ignored important terms in the loss. In this work, we take a step towards better understanding of the IntroVAE model, its practical implementation, and its applications. We propose the Soft-IntroVAE, a modified IntroVAE that replaces the hinge-loss terms with a smooth exponential loss on generated samples. This change significantly improves training stability, and also enables theoretical analysis of the complete algorithm. Interestingly, we show that the IntroVAE converges to a distribution that minimizes a sum of KL distance from the data distribution and an entropy term. We discuss the implications of this result, and demonstrate that it induces competitive image generation and reconstruction. Finally, we describe two applications of Soft-IntroVAE to unsupervised image translation and out-of-distribution detection, and demonstrate compelling results. Code and additional information is available on the project website -- https://taldatech.github.io/soft-intro-vae-web
Dual Recovery Network with Online Compensation for Image Super-Resolution
Jun 18, 2018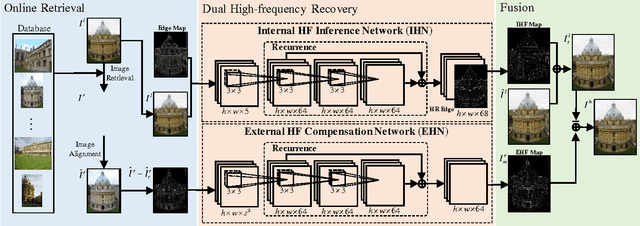
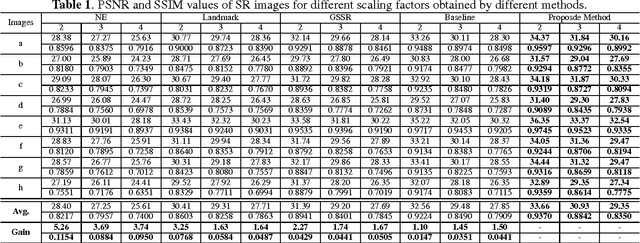

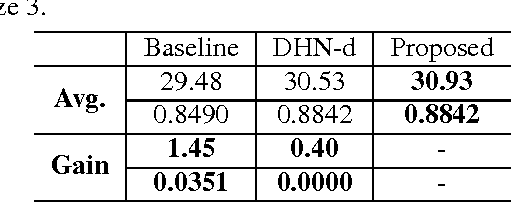
Image super-resolution (SR) methods essentially lead to a loss of some high-frequency (HF) information when predicting high-resolution (HR) images from low-resolution (LR) images without using external references. To address this issue, we additionally utilize online retrieved data to facilitate image SR in a unified deep framework. A novel dual high-frequency recovery network (DHN) is proposed to predict an HR image with three parts: an LR image, an internal inferred HF (IHF) map (HF missing part inferred solely from the LR image) and an external extracted HF (EHF) map. In particular, we infer the HF information based on both the LR image and similar HR references which are retrieved online. For the EHF map, we align the references with affine transformation and then in the aligned references, part of HF signals are extracted by the proposed DHN to compensate for the HF loss. Extensive experimental results demonstrate that our DHN achieves notably better performance than state-of-the-art SR methods.
Multi-Agent Image Classification via Reinforcement Learning
May 13, 2019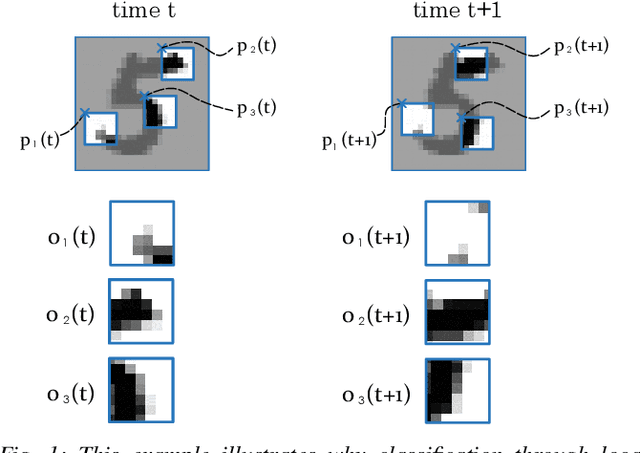
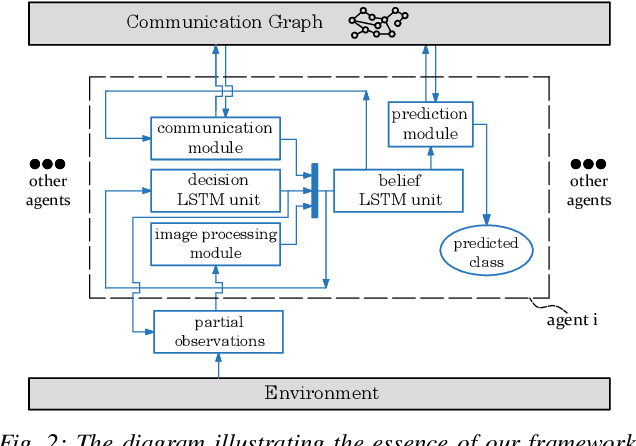
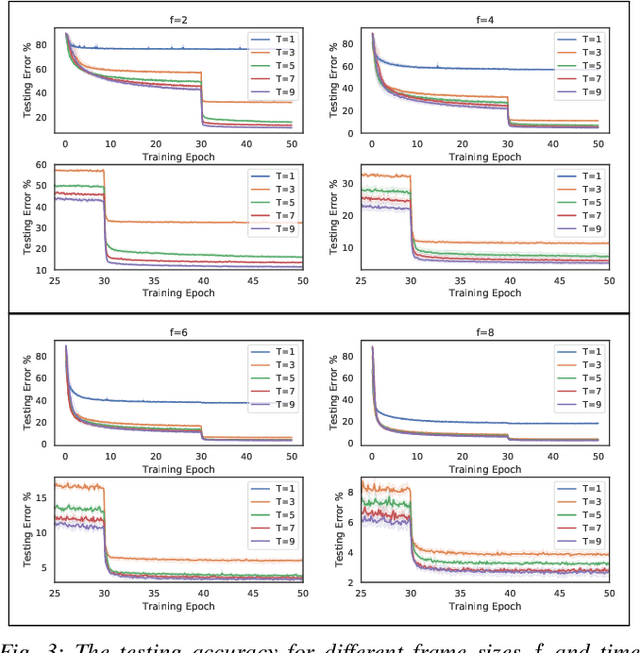
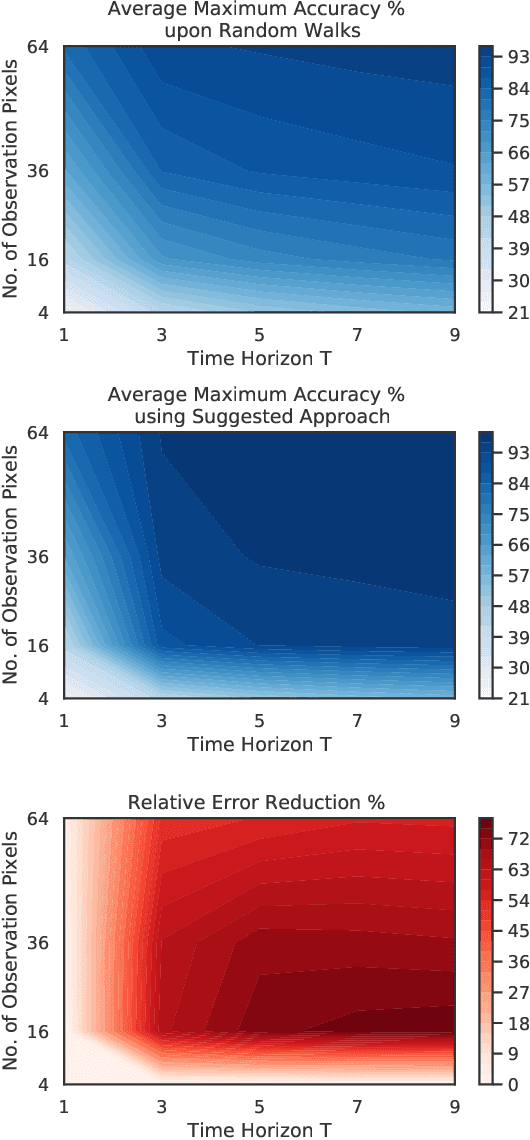
We investigate a classification problem using multiple mobile agents that are capable of collecting (partial) pose-dependent observations of an unknown environment. The objective is to classify an image (e.g, map of a large area) over a finite time horizon. We propose a network architecture on how agents should form a local belief, take local actions, extract relevant features and specification from their raw partial observations. Agents are allowed to exchange information with their neighboring agents and run a decentralized consensus protocol to update their own beliefs. It is shown how reinforcement learning techniques can be utilized to achieve decentralized implementation of the classification problem. Our experimental results on MNIST handwritten digit dataset demonstrates the effectiveness of our proposed framework.