 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Video Synthesis from a Single Image and Motion Stroke
Dec 05, 2018

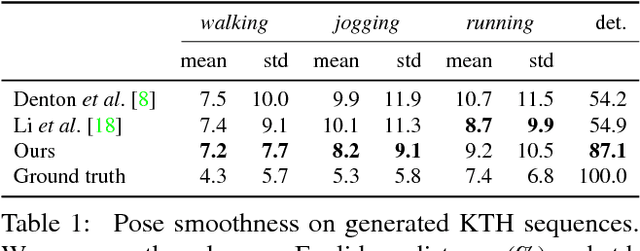
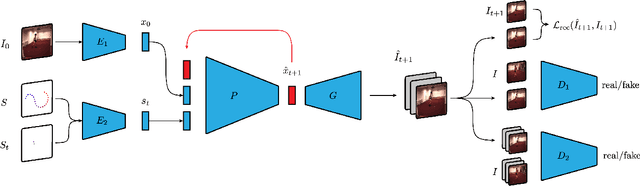

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.
View-Guided Point Cloud Completion
Apr 12, 2021
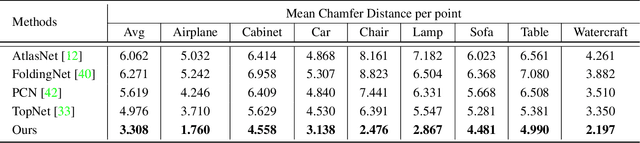
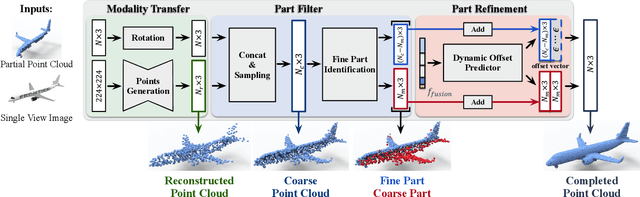
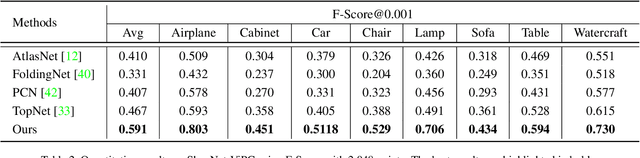
This paper presents a view-guided solution for the task of point cloud completion. Unlike most existing methods directly inferring the missing points using shape priors, we address this task by introducing ViPC (view-guided point cloud completion) that takes the missing crucial global structure information from an extra single-view image. By leveraging a framework that sequentially performs effective cross-modality and cross-level fusions, our method achieves significantly superior results over typical existing solutions on a new large-scale dataset we collect for the view-guided point cloud completion task.
TENGraD: Time-Efficient Natural Gradient Descent with Exact Fisher-Block Inversion
Jun 07, 2021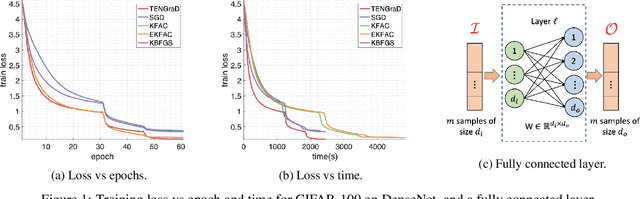

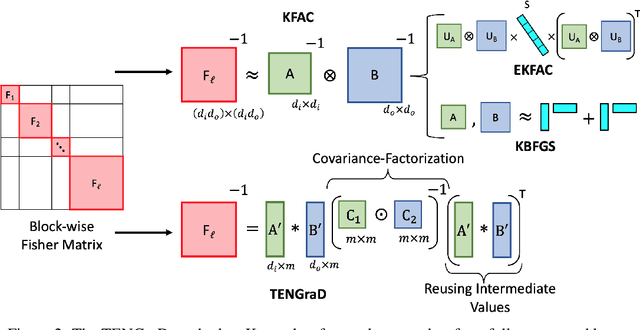
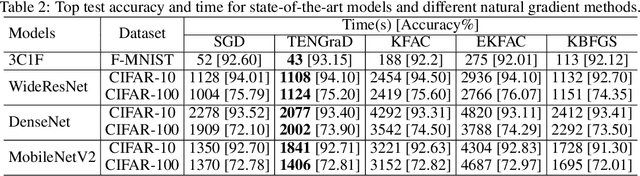
This work proposes a time-efficient Natural Gradient Descent method, called TENGraD, with linear convergence guarantees. Computing the inverse of the neural network's Fisher information matrix is expensive in NGD because the Fisher matrix is large. Approximate NGD methods such as KFAC attempt to improve NGD's running time and practical application by reducing the Fisher matrix inversion cost with approximation. However, the approximations do not reduce the overall time significantly and lead to less accurate parameter updates and loss of curvature information. TENGraD improves the time efficiency of NGD by computing Fisher block inverses with a computationally efficient covariance factorization and reuse method. It computes the inverse of each block exactly using the Woodbury matrix identity to preserve curvature information while admitting (linear) fast convergence rates. Our experiments on image classification tasks for state-of-the-art deep neural architecture on CIFAR-10, CIFAR-100, and Fashion-MNIST show that TENGraD significantly outperforms state-of-the-art NGD methods and often stochastic gradient descent in wall-clock time.
Multi-Class Classification of Blood Cells -- End to End Computer Vision based diagnosis case study
Jun 23, 2021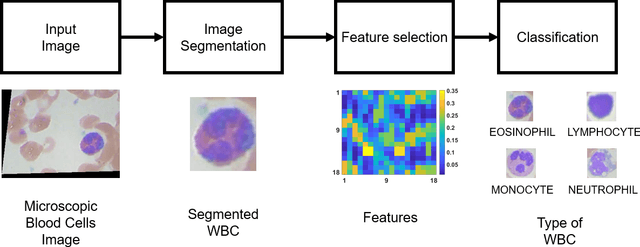
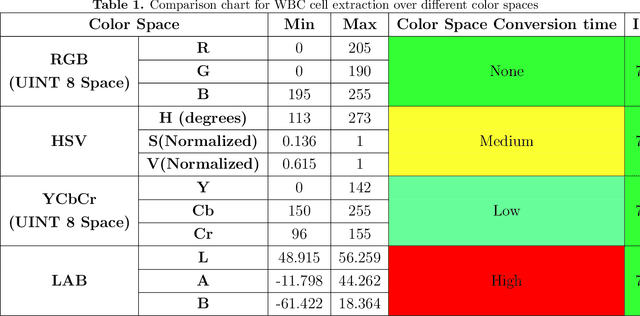
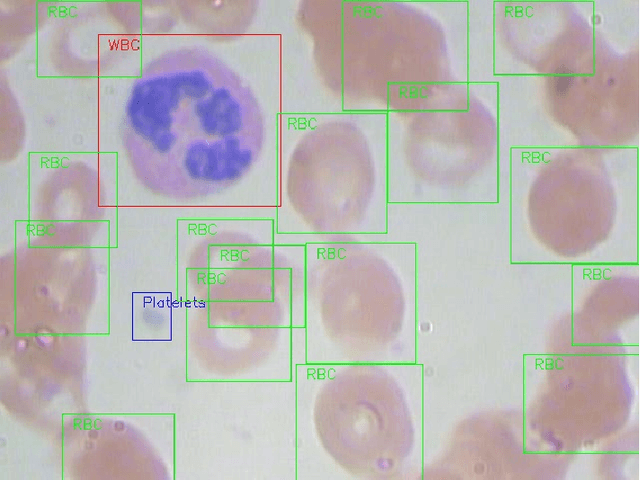
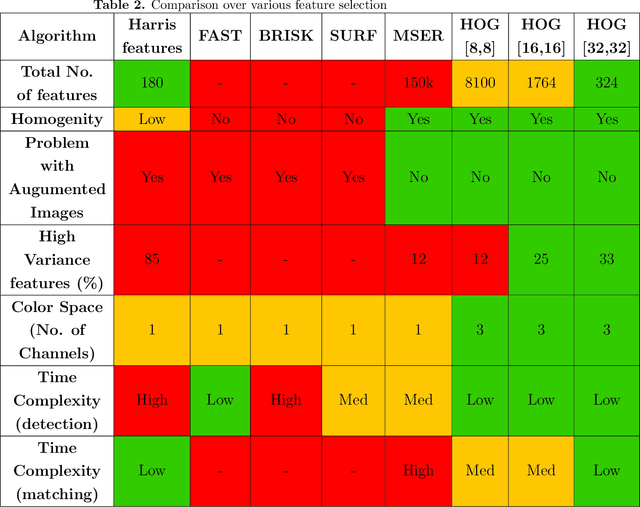
The diagnosis of blood-based diseases often involves identifying and characterizing patient blood samples. Automated methods to detect and classify blood cell subtypes have important medical applications. Automated medical image processing and analysis offers a powerful tool for medical diagnosis. In this work we tackle the problem of white blood cell classification based on the morphological characteristics of their outer contour, color. The work we would explore a set of preprocessing and segmentation (Color-based segmentation, Morphological processing, contouring) algorithms along with a set of features extraction methods (Corner detection algorithms and Histogram of Gradients(HOG)), dimensionality reduction algorithms (Principal Component Analysis(PCA)) that are able to recognize and classify through various Unsupervised(k-nearest neighbors) and Supervised (Support Vector Machine, Decision Trees, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Naive Bayes) algorithms different categories of white blood cells to Eosinophil, Lymphocyte, Monocyte, and Neutrophil. We even take a step forwards to explore various Deep Convolutional Neural network architecture (Sqeezent, MobilenetV1,MobilenetV2, InceptionNet etc.) without preprocessing/segmentation and with preprocessing. We would like to explore many algorithms to identify the robust algorithm with least time complexity and low resource requirement. The outcome of this work can be a cue to selection of algorithms as per requirement for automated blood cell classification.
Deep Proxy Causal Learning and its Application to Confounded Bandit Policy Evaluation
Jun 07, 2021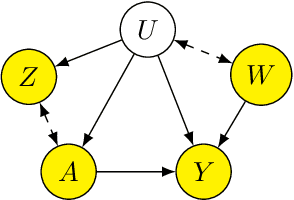
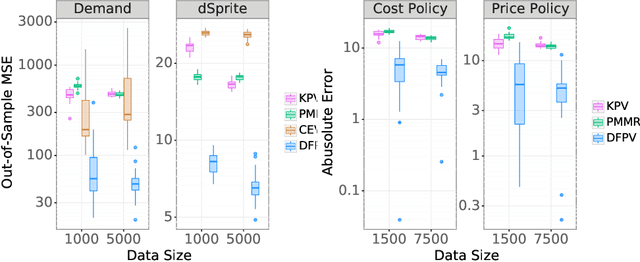

Proxy causal learning (PCL) is a method for estimating the causal effect of treatments on outcomes in the presence of unobserved confounding, using proxies (structured side information) for the confounder. This is achieved via two-stage regression: in the first stage, we model relations among the treatment and proxies; in the second stage, we use this model to learn the effect of treatment on the outcome, given the context provided by the proxies. PCL guarantees recovery of the true causal effect, subject to identifiability conditions. We propose a novel method for PCL, the deep feature proxy variable method (DFPV), to address the case where the proxies, treatments, and outcomes are high-dimensional and have nonlinear complex relationships, as represented by deep neural network features. We show that DFPV outperforms recent state-of-the-art PCL methods on challenging synthetic benchmarks, including settings involving high dimensional image data. Furthermore, we show that PCL can be applied to off-policy evaluation for the confounded bandit problem, in which DFPV also exhibits competitive performance.
Instance and Pair-Aware Dynamic Networks for Re-Identification
Mar 09, 2021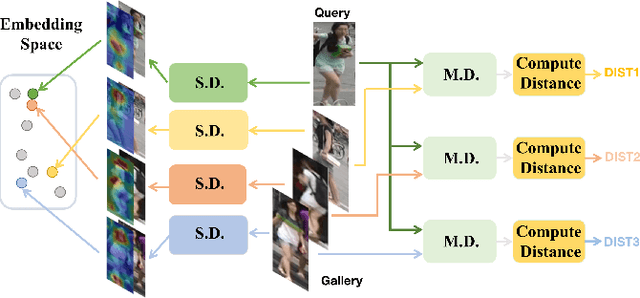
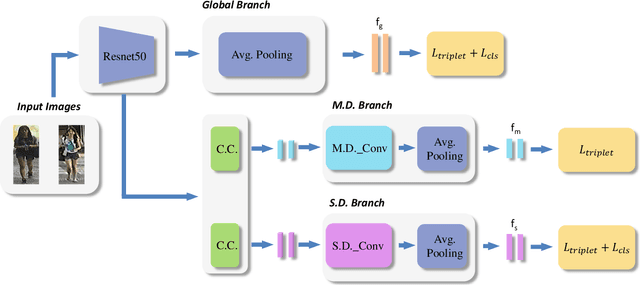
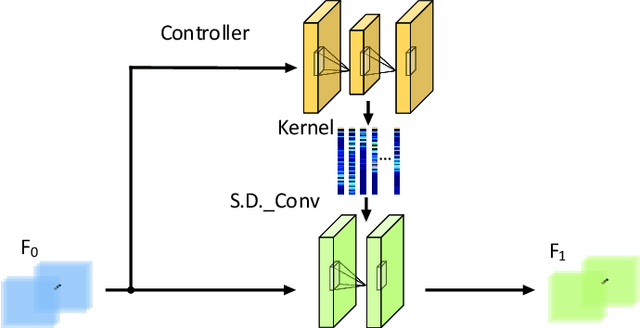

Re-identification (ReID) is to identify the same instance across different cameras. Existing ReID methods mostly utilize alignment-based or attention-based strategies to generate effective feature representations. However, most of these methods only extract general feature by employing single input image itself, overlooking the exploration of relevance between comparing images. To fill this gap, we propose a novel end-to-end trainable dynamic convolution framework named Instance and Pair-Aware Dynamic Networks in this paper. The proposed model is composed of three main branches where a self-guided dynamic branch is constructed to strengthen instance-specific features, focusing on every single image. Furthermore, we also design a mutual-guided dynamic branch to generate pair-aware features for each pair of images to be compared. Extensive experiments are conducted in order to verify the effectiveness of our proposed algorithm. We evaluate our algorithm in several mainstream person and vehicle ReID datasets including CUHK03, DukeMTMCreID, Market-1501, VeRi776 and VehicleID. In some datasets our algorithm outperforms state-of-the-art methods and in others, our algorithm achieves a comparable performance.
Counterfactual Maximum Likelihood Estimation for Training Deep Networks
Jun 07, 2021
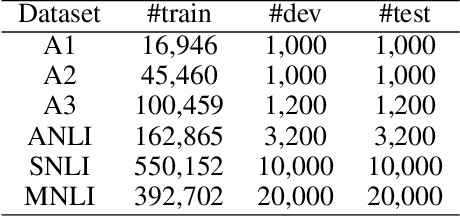

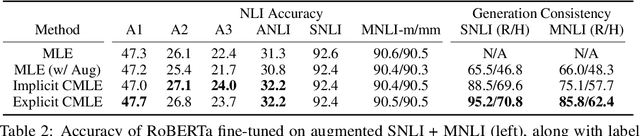
Although deep learning models have driven state-of-the-art performance on a wide array of tasks, they are prone to learning spurious correlations that should not be learned as predictive clues. To mitigate this problem, we propose a causality-based training framework to reduce the spurious correlations caused by observable confounders. We give theoretical analysis on the underlying general Structural Causal Model (SCM) and propose to perform Maximum Likelihood Estimation (MLE) on the interventional distribution instead of the observational distribution, namely Counterfactual Maximum Likelihood Estimation (CMLE). As the interventional distribution, in general, is hidden from the observational data, we then derive two different upper bounds of the expected negative log-likelihood and propose two general algorithms, Implicit CMLE and Explicit CMLE, for causal predictions of deep learning models using observational data. We conduct experiments on two real-world tasks: Natural Language Inference (NLI) and Image Captioning. The results show that CMLE methods outperform the regular MLE method in terms of out-of-domain generalization performance and reducing spurious correlations, while maintaining comparable performance on the regular evaluations.
Anchors based method for fingertips position from a monocular RGB image using Deep Neural Network
May 04, 2020
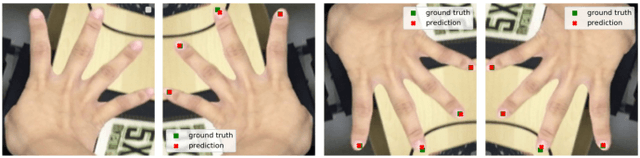
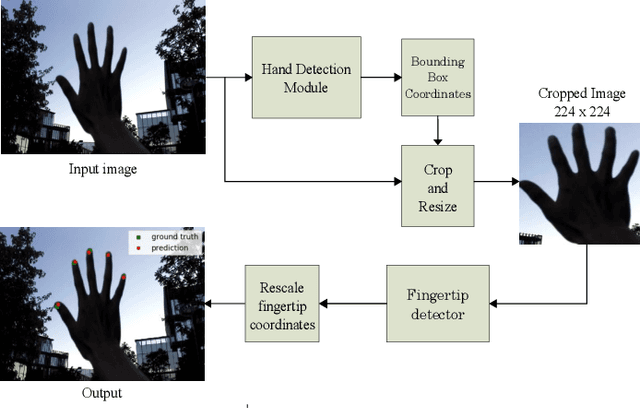

In Virtual, augmented, and mixed reality, the use of hand gestures is increasingly becoming popular to reduce the difference between the virtual and real world. The precise location of the fingertip is essential/crucial for a seamless experience. Much of the research work is based on using depth information for the estimation of the fingertips position. However, most of the work using RGB images for fingertips detection is limited to a single finger. The detection of multiple fingertips from a single RGB image is very challenging due to various factors. In this paper, we propose a deep neural network (DNN) based methodology to estimate the fingertips position. We christened this methodology as an Anchor based Fingertips Position Estimation (ABFPE), and it is a two-step process. The fingertips location is estimated using regression by computing the difference in the location of a fingertip from the nearest anchor point. The proposed framework performs the best with limited dependence on hand detection results. In our experiments on the SCUT-Ego-Gesture dataset, we achieved the fingertips detection error of 2.3552 pixels on a video frame with a resolution of $640 \times 480$ and about $92.98\%$ of test images have average pixel errors of five pixels.
Developing a Fidelity Evaluation Approach for Interpretable Machine Learning
Jun 16, 2021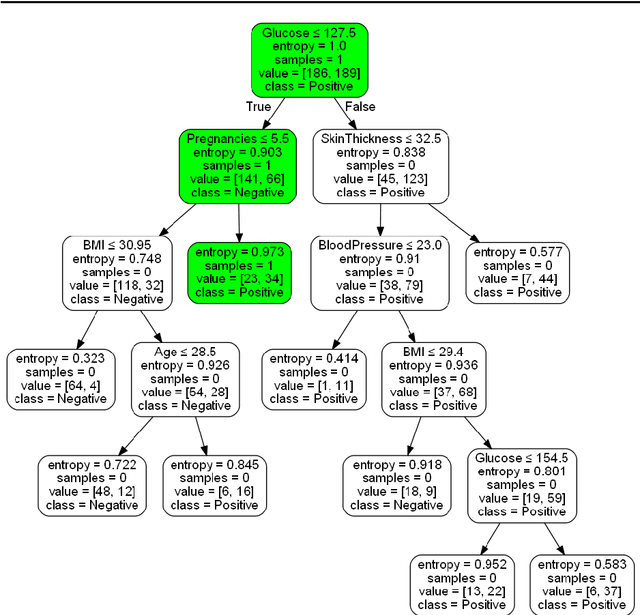
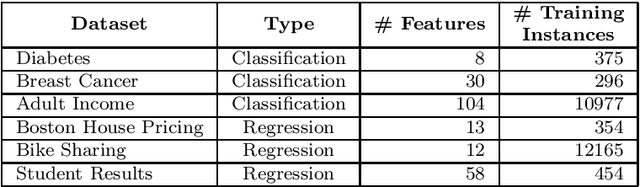
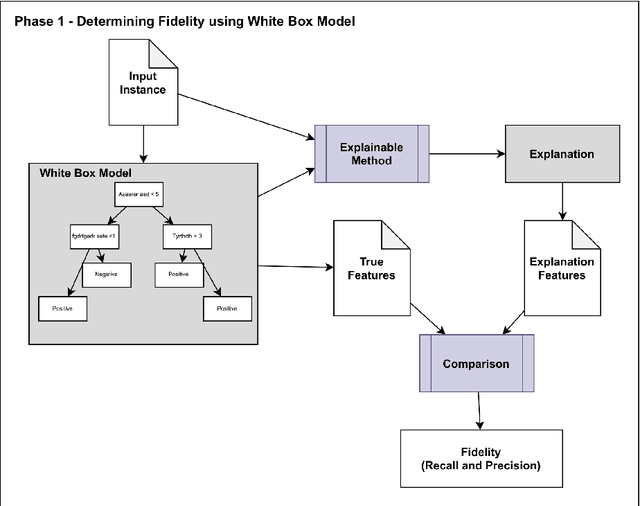
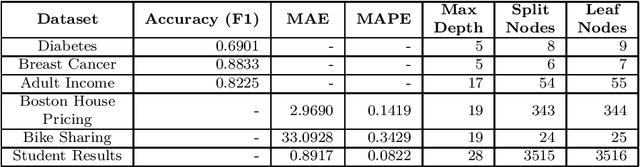
Although modern machine learning and deep learning methods allow for complex and in-depth data analytics, the predictive models generated by these methods are often highly complex, and lack transparency. Explainable AI (XAI) methods are used to improve the interpretability of these complex models, and in doing so improve transparency. However, the inherent fitness of these explainable methods can be hard to evaluate. In particular, methods to evaluate the fidelity of the explanation to the underlying black box require further development, especially for tabular data. In this paper, we (a) propose a three phase approach to developing an evaluation method; (b) adapt an existing evaluation method primarily for image and text data to evaluate models trained on tabular data; and (c) evaluate two popular explainable methods using this evaluation method. Our evaluations suggest that the internal mechanism of the underlying predictive model, the internal mechanism of the explainable method used and model and data complexity all affect explanation fidelity. Given that explanation fidelity is so sensitive to context and tools and data used, we could not clearly identify any specific explainable method as being superior to another.
FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection
Jun 23, 2021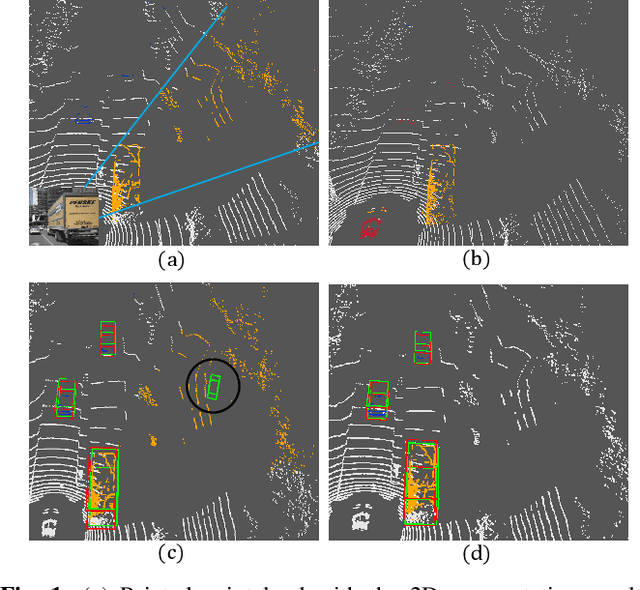
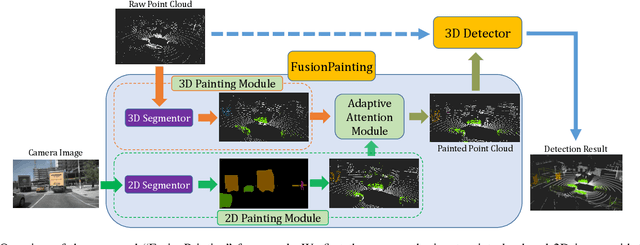
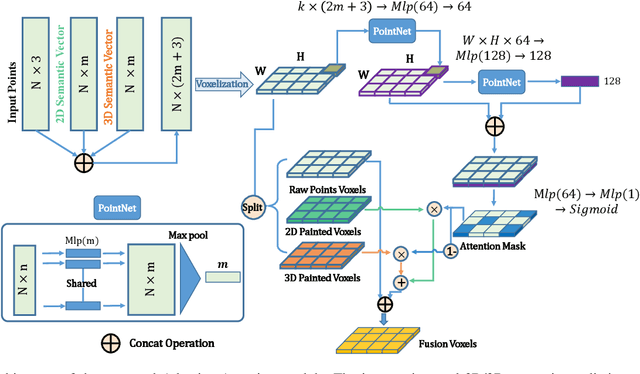
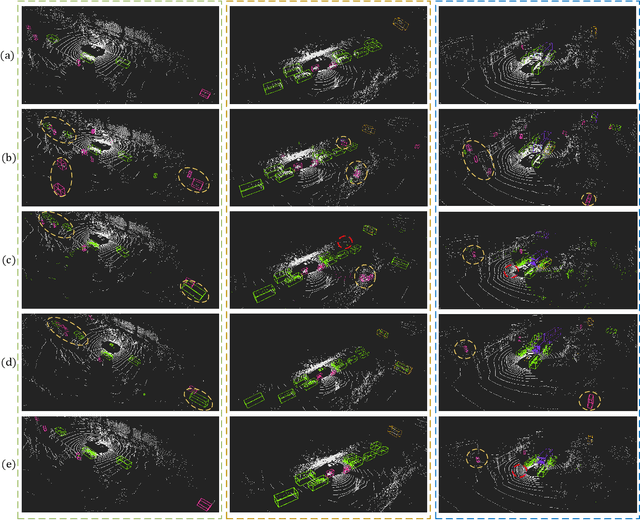
Accurate detection of obstacles in 3D is an essential task for autonomous driving and intelligent transportation. In this work, we propose a general multimodal fusion framework FusionPainting to fuse the 2D RGB image and 3D point clouds at a semantic level for boosting the 3D object detection task. Especially, the FusionPainting framework consists of three main modules: a multi-modal semantic segmentation module, an adaptive attention-based semantic fusion module, and a 3D object detector. First, semantic information is obtained for 2D images and 3D Lidar point clouds based on 2D and 3D segmentation approaches. Then the segmentation results from different sensors are adaptively fused based on the proposed attention-based semantic fusion module. Finally, the point clouds painted with the fused semantic label are sent to the 3D detector for obtaining the 3D objection results. The effectiveness of the proposed framework has been verified on the large-scale nuScenes detection benchmark by comparing it with three different baselines. The experimental results show that the fusion strategy can significantly improve the detection performance compared to the methods using only point clouds, and the methods using point clouds only painted with 2D segmentation information. Furthermore, the proposed approach outperforms other state-of-the-art methods on the nuScenes testing benchmark.