 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Premise-based Multimodal Reasoning: A Human-like Cognitive Process
May 15, 2021
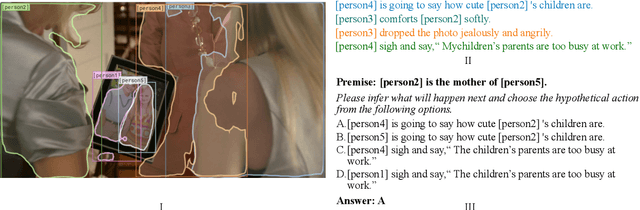
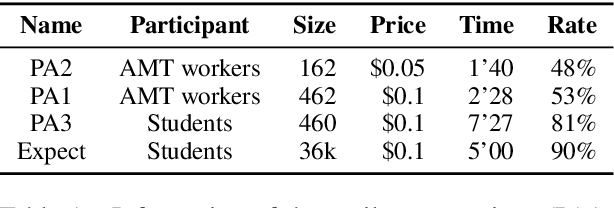
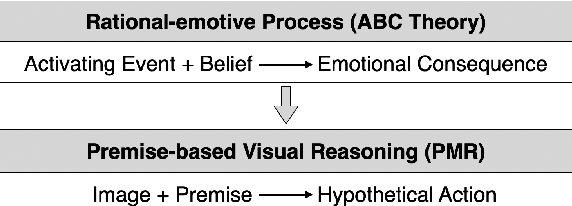

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.
A Simple and Strong Baseline: Progressively Region-based Scene Text Removal Networks
Jun 24, 2021
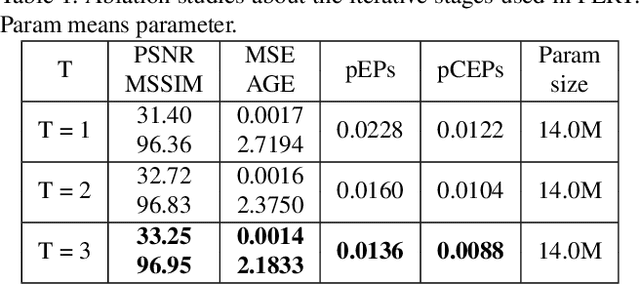
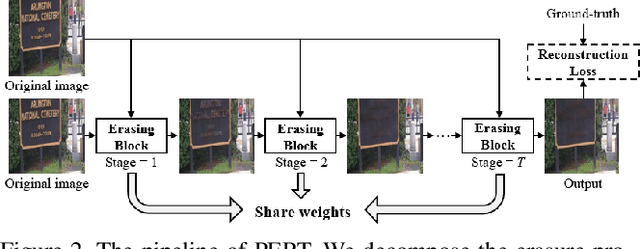
Existing scene text removal methods mainly train an elaborate network with paired images to realize the function of text localization and background reconstruction simultaneously, but there exists two problems: 1) lacking the exhaustive erasure of text region and 2) causing the excessive erasure to text-free areas. To handle these issues, this paper provides a novel ProgrEssively Region-based scene Text eraser (PERT), which introduces region-based modification strategy to progressively erase the pixels in only text region. Firstly, PERT decomposes the STR task to several erasing stages. As each stage aims to take a further step toward the text-removed image rather than directly regress to the final result, the decomposed operation reduces the learning difficulty in each stage, and an exhaustive erasure result can be obtained by iterating over lightweight erasing blocks with shared parameters. Then, PERT introduces a region-based modification strategy to ensure the integrity of text-free areas by decoupling text localization from erasure process to guide the removal. Benefiting from the simplicity architecture, PERT is a simple and strong baseline, and is easy to be followed and developed. Extensive experiments demonstrate that PERT obtains the state-of-the-art results on both synthetic and real-world datasets. Code is available athttps://github.com/wangyuxin87/PERT.
Rolling-Shutter-Aware Differential SfM and Image Rectification
Mar 10, 2019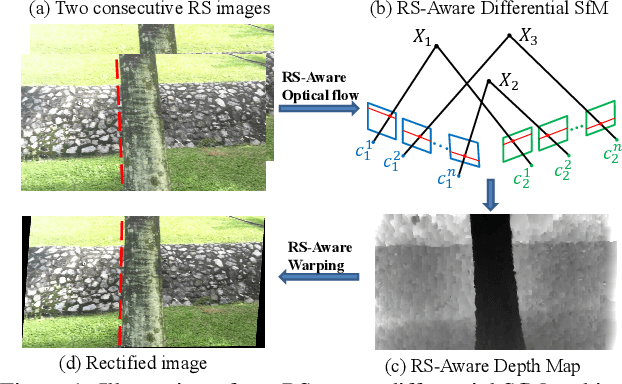
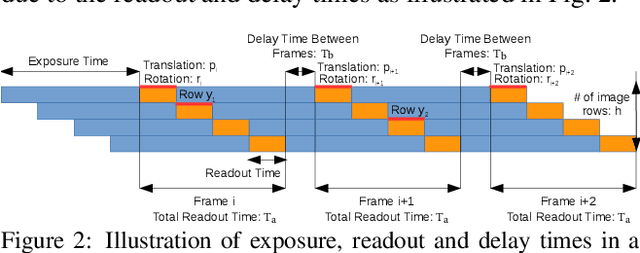

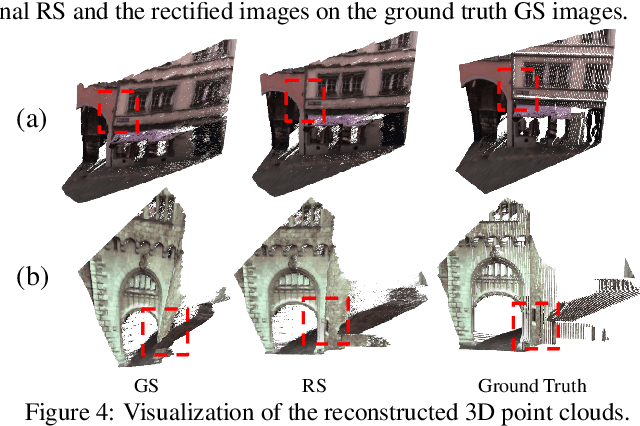
In this paper, we develop a modified differential Structure from Motion (SfM) algorithm that can estimate relative pose from two consecutive frames despite of Rolling Shutter (RS) artifacts. In particular, we show that under constant velocity assumption, the errors induced by the rolling shutter effect can be easily rectified by a linear scaling operation on each optical flow. We further propose a 9-point algorithm to recover the relative pose of a rolling shutter camera that undergoes constant acceleration motion. We demonstrate that the dense depth maps recovered from the relative pose of the RS camera can be used in a RS-aware warping for image rectification to recover high-quality Global Shutter (GS) images. Experiments on both synthetic and real RS images show that our RS-aware differential SfM algorithm produces more accurate results on relative pose estimation and 3D reconstruction from images distorted by RS effect compared to standard SfM algorithms that assume a GS camera model. We also demonstrate that our RS-aware warping for image rectification method outperforms state-of-the-art commercial software products, i.e. Adobe After Effects and Apple Imovie, at removing RS artifacts.
Learning to Disambiguate Strongly Interacting Hands via Probabilistic Per-pixel Part Segmentation
Jul 01, 2021
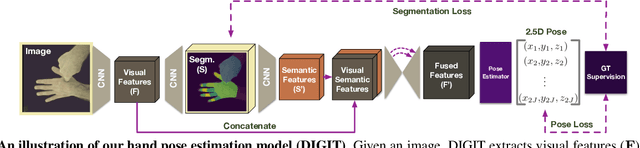

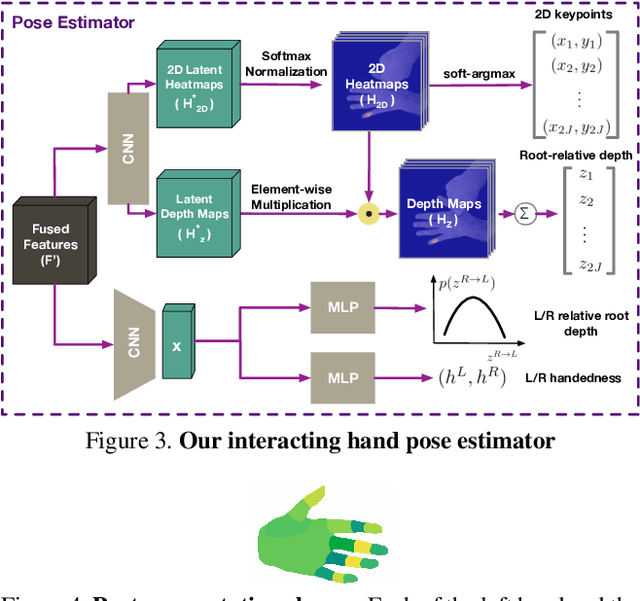
In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.
EEG-GNN: Graph Neural Networks for Classification of Electroencephalogram (EEG) Signals
Jun 16, 2021



Convolutional neural networks (CNN) have been frequently used to extract subject-invariant features from electroencephalogram (EEG) for classification tasks. This approach holds the underlying assumption that electrodes are equidistant analogous to pixels of an image and hence fails to explore/exploit the complex functional neural connectivity between different electrode sites. We overcome this limitation by tailoring the concepts of convolution and pooling applied to 2D grid-like inputs for the functional network of electrode sites. Furthermore, we develop various graph neural network (GNN) models that project electrodes onto the nodes of a graph, where the node features are represented as EEG channel samples collected over a trial, and nodes can be connected by weighted/unweighted edges according to a flexible policy formulated by a neuroscientist. The empirical evaluations show that our proposed GNN-based framework outperforms standard CNN classifiers across ErrP, and RSVP datasets, as well as allowing neuroscientific interpretability and explainability to deep learning methods tailored to EEG related classification problems. Another practical advantage of our GNN-based framework is that it can be used in EEG channel selection, which is critical for reducing computational cost, and designing portable EEG headsets.
VinDr-SpineXR: A deep learning framework for spinal lesions detection and classification from radiographs
Jun 24, 2021
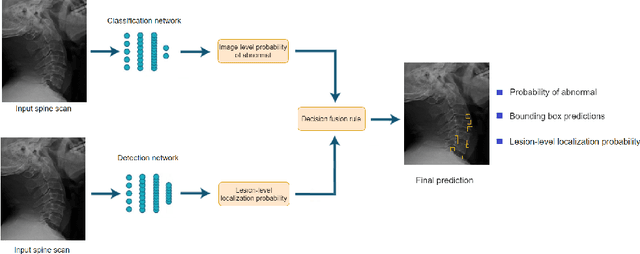
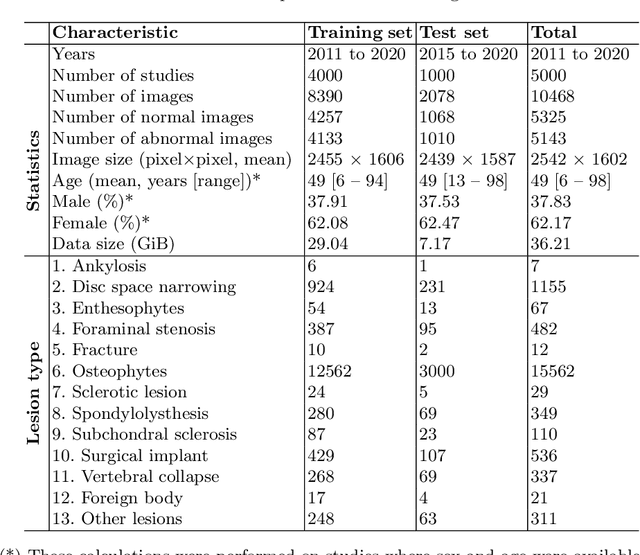

Radiographs are used as the most important imaging tool for identifying spine anomalies in clinical practice. The evaluation of spinal bone lesions, however, is a challenging task for radiologists. This work aims at developing and evaluating a deep learning-based framework, named VinDr-SpineXR, for the classification and localization of abnormalities from spine X-rays. First, we build a large dataset, comprising 10,468 spine X-ray images from 5,000 studies, each of which is manually annotated by an experienced radiologist with bounding boxes around abnormal findings in 13 categories. Using this dataset, we then train a deep learning classifier to determine whether a spine scan is abnormal and a detector to localize 7 crucial findings amongst the total 13. The VinDr-SpineXR is evaluated on a test set of 2,078 images from 1,000 studies, which is kept separate from the training set. It demonstrates an area under the receiver operating characteristic curve (AUROC) of 88.61% (95% CI 87.19%, 90.02%) for the image-level classification task and a mean average precision (mAP@0.5) of 33.56% for the lesion-level localization task. These results serve as a proof of concept and set a baseline for future research in this direction. To encourage advances, the dataset, codes, and trained deep learning models are made publicly available.
Provably Convergent Learned Inexact Descent Algorithm for Low-Dose CT Reconstruction
Apr 27, 2021
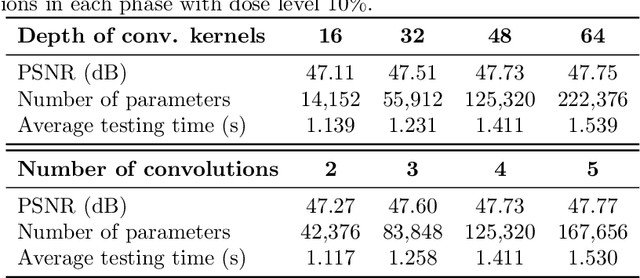
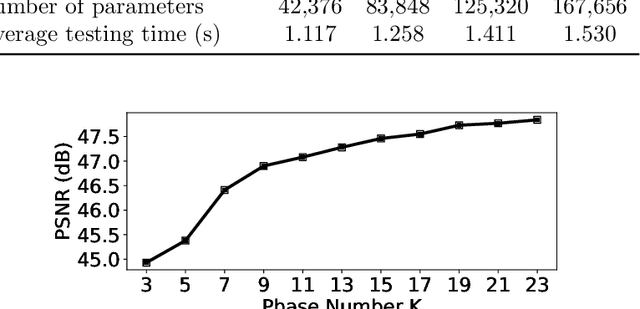
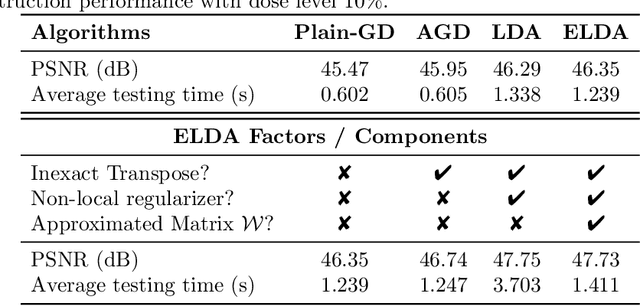
We propose a provably convergent method, called Efficient Learned Descent Algorithm (ELDA), for low-dose CT (LDCT) reconstruction. ELDA is a highly interpretable neural network architecture with learned parameters and meanwhile retains convergence guarantee as classical optimization algorithms. To improve reconstruction quality, the proposed ELDA also employs a new non-local feature mapping and an associated regularizer. We compare ELDA with several state-of-the-art deep image methods, such as RED-CNN and Learned Primal-Dual, on a set of LDCT reconstruction problems. Numerical experiments demonstrate improvement of reconstruction quality using ELDA with merely 19 layers, suggesting the promising performance of ELDA in solution accuracy and parameter efficiency.
Video Synthesis from a Single Image and Motion Stroke
Dec 05, 2018
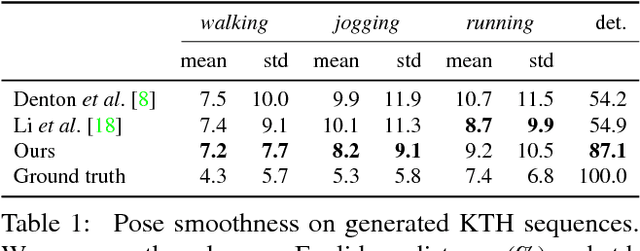
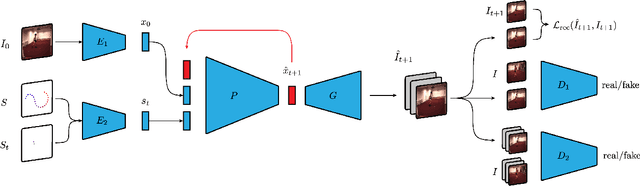

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.
Pyramid-Focus-Augmentation: Medical Image Segmentation with Step-Wise Focus
Dec 14, 2020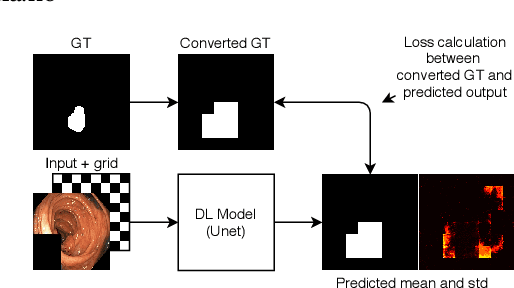
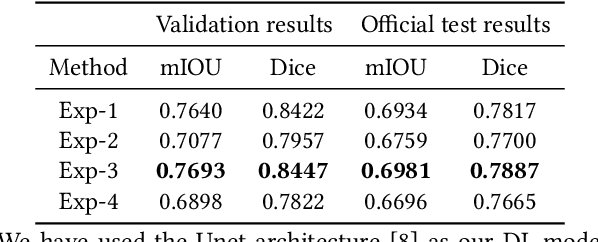

Segmentation of findings in the gastrointestinal tract is a challenging but also an important task which is an important building stone for sufficient automatic decision support systems. In this work, we present our solution for the Medico 2020 task, which focused on the problem of colon polyp segmentation. We present our simple but efficient idea of using an augmentation method that uses grids in a pyramid-like manner (large to small) for segmentation. Our results show that the proposed methods work as indented and can also lead to comparable results when competing with other methods.
Federated Learning with Downlink Device Selection
Jul 07, 2021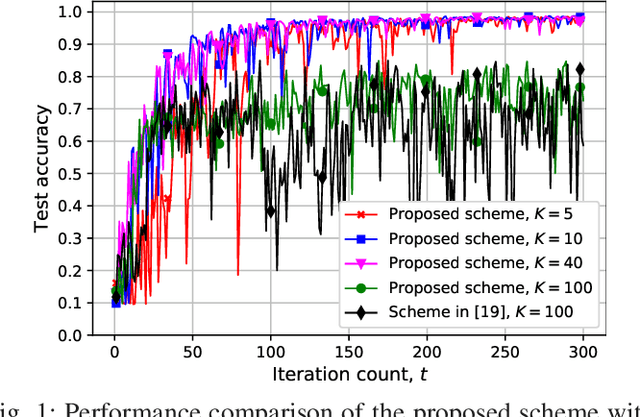
We study federated edge learning, where a global model is trained collaboratively using privacy-sensitive data at the edge of a wireless network. A parameter server (PS) keeps track of the global model and shares it with the wireless edge devices for training using their private local data. The devices then transmit their local model updates, which are used to update the global model, to the PS. The algorithm, which involves transmission over PS-to-device and device-to-PS links, continues until the convergence of the global model or lack of any participating devices. In this study, we consider device selection based on downlink channels over which the PS shares the global model with the devices. Performing digital downlink transmission, we design a partial device participation framework where a subset of the devices is selected for training at each iteration. Therefore, the participating devices can have a better estimate of the global model compared to the full device participation case which is due to the shared nature of the broadcast channel with the price of updating the global model with respect to a smaller set of data. At each iteration, the PS broadcasts different quantized global model updates to different participating devices based on the last global model estimates available at the devices. We investigate the best number of participating devices through experimental results for image classification using the MNIST dataset with biased distribution.