 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning a Discriminative Prior for Blind Image Deblurring
Apr 04, 2018

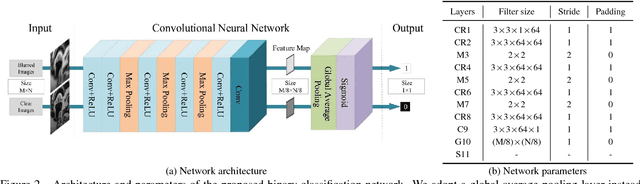
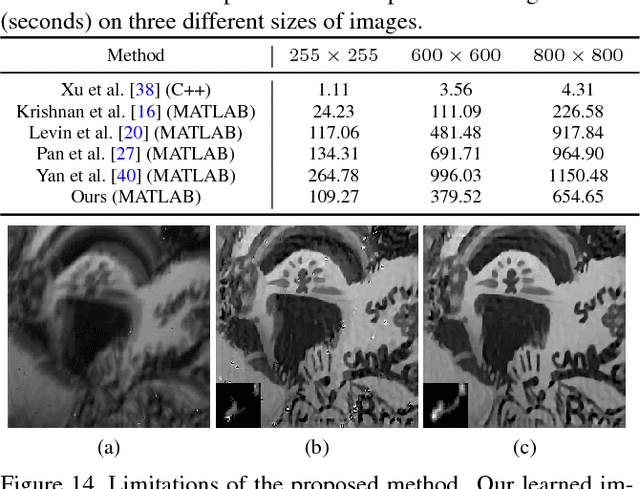
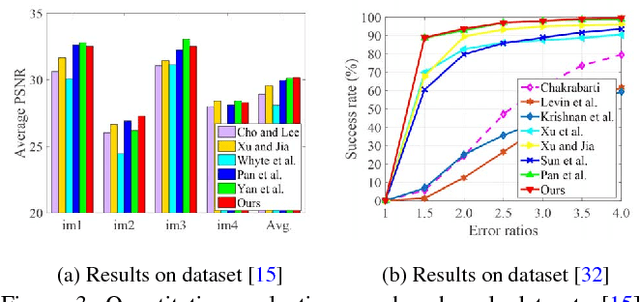
We present an effective blind image deblurring method based on a data-driven discriminative prior.Our work is motivated by the fact that a good image prior should favor clear images over blurred images.In this work, we formulate the image prior as a binary classifier which can be achieved by a deep convolutional neural network (CNN).The learned prior is able to distinguish whether an input image is clear or not.Embedded into the maximum a posterior (MAP) framework, it helps blind deblurring in various scenarios, including natural, face, text, and low-illumination images.However, it is difficult to optimize the deblurring method with the learned image prior as it involves a non-linear CNN.Therefore, we develop an efficient numerical approach based on the half-quadratic splitting method and gradient decent algorithm to solve the proposed model.Furthermore, the proposed model can be easily extended to non-uniform deblurring.Both qualitative and quantitative experimental results show that our method performs favorably against state-of-the-art algorithms as well as domain-specific image deblurring approaches.
Data augmentation using learned transformations for one-shot medical image segmentation
Apr 06, 2019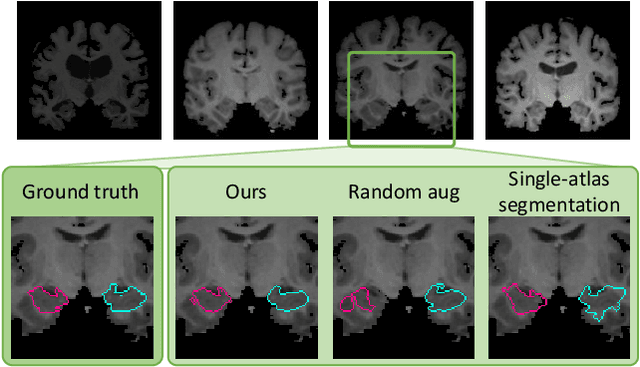
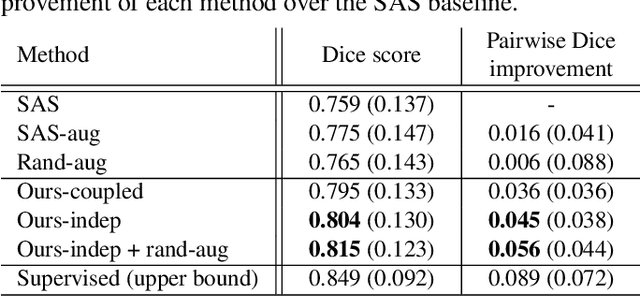
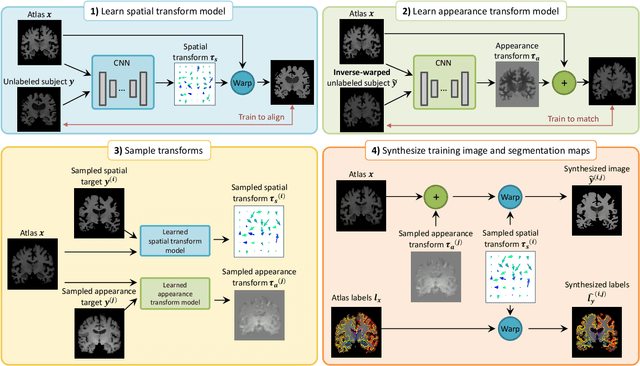
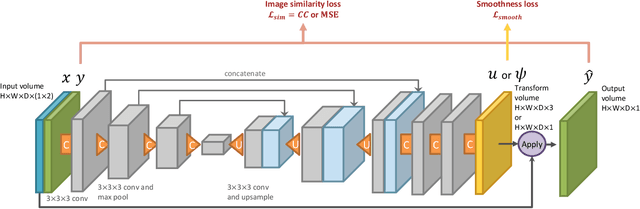
Image segmentation is an important task in many medical applications. Methods based on convolutional neural networks attain state-of-the-art accuracy; however, they typically rely on supervised training with large labeled datasets. Labeling medical images requires significant expertise and time, and typical hand-tuned approaches for data augmentation fail to capture the complex variations in such images. We present an automated data augmentation method for synthesizing labeled medical images. We demonstrate our method on the task of segmenting magnetic resonance imaging (MRI) brain scans. Our method requires only a single segmented scan, and leverages other unlabeled scans in a semi-supervised approach. We learn a model of transformations from the images, and use the model along with the labeled example to synthesize additional labeled examples. Each transformation is comprised of a spatial deformation field and an intensity change, enabling the synthesis of complex effects such as variations in anatomy and image acquisition procedures. We show that training a supervised segmenter with these new examples provides significant improvements over state-of-the-art methods for one-shot biomedical image segmentation. Our code is available at https://github.com/xamyzhao/brainstorm.
A Generative Map for Image-based Camera Localization
Apr 16, 2019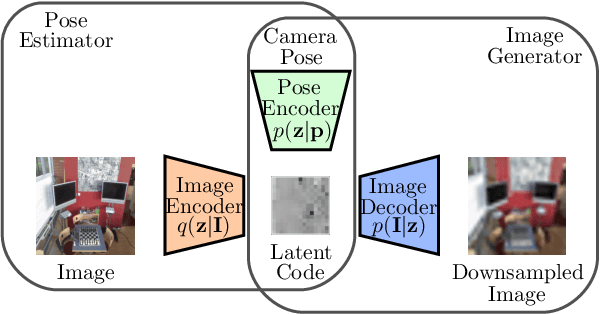
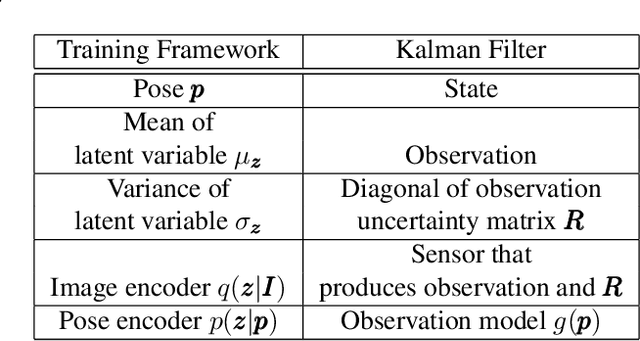
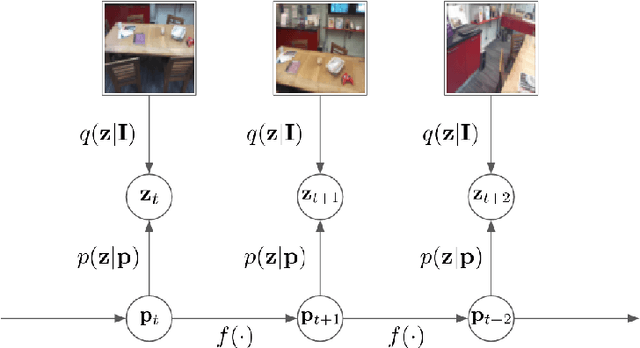
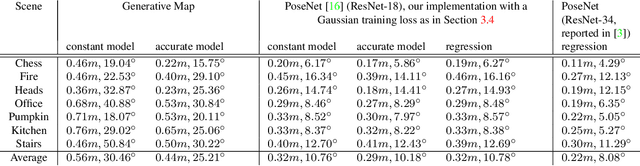
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.
Explainable AI for medical imaging: Explaining pneumothorax diagnoses with Bayesian Teaching
Jun 08, 2021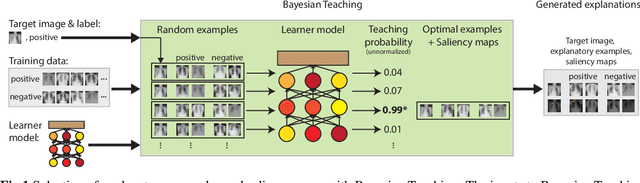
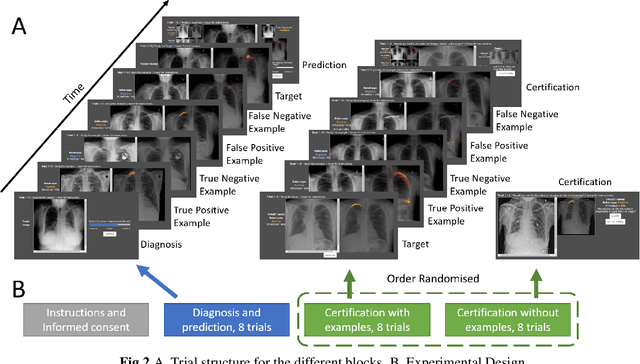
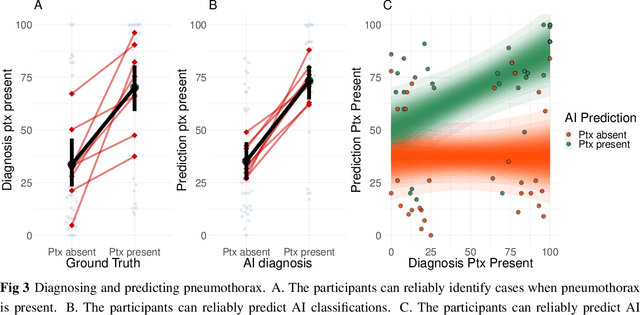
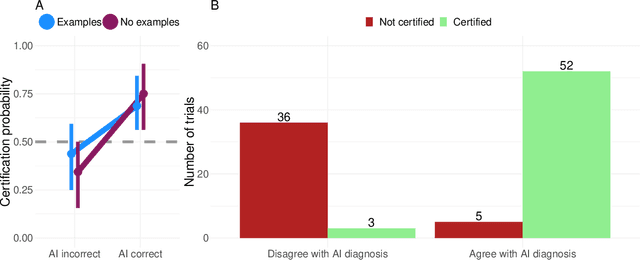
Limited expert time is a key bottleneck in medical imaging. Due to advances in image classification, AI can now serve as decision-support for medical experts, with the potential for great gains in radiologist productivity and, by extension, public health. However, these gains are contingent on building and maintaining experts' trust in the AI agents. Explainable AI may build such trust by helping medical experts to understand the AI decision processes behind diagnostic judgements. Here we introduce and evaluate explanations based on Bayesian Teaching, a formal account of explanation rooted in the cognitive science of human learning. We find that medical experts exposed to explanations generated by Bayesian Teaching successfully predict the AI's diagnostic decisions and are more likely to certify the AI for cases when the AI is correct than when it is wrong, indicating appropriate trust. These results show that Explainable AI can be used to support human-AI collaboration in medical imaging.
Unsupervised Domain Adaptation for Semantic Segmentation by Content Transfer
Dec 23, 2020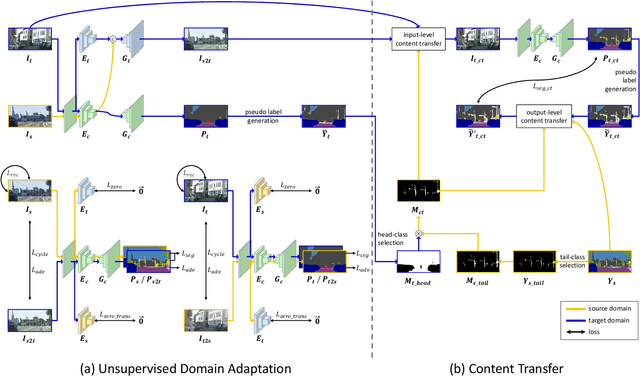
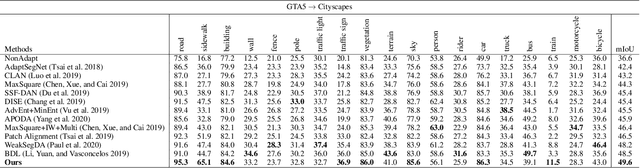
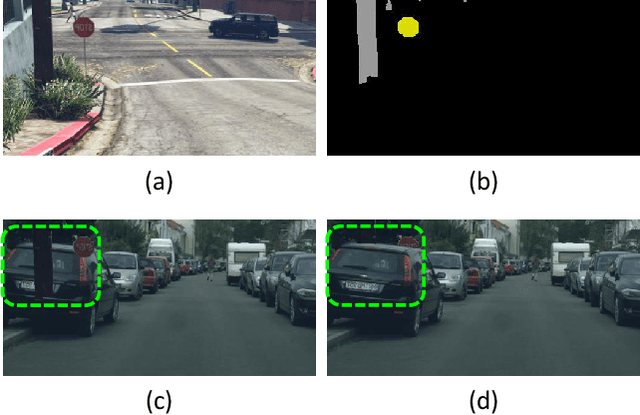
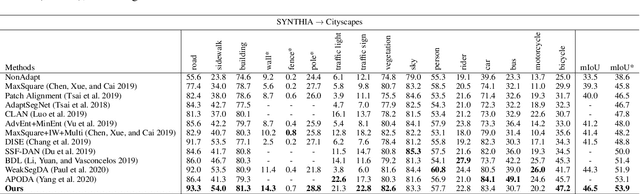
In this paper, we tackle the unsupervised domain adaptation (UDA) for semantic segmentation, which aims to segment the unlabeled real data using labeled synthetic data. The main problem of UDA for semantic segmentation relies on reducing the domain gap between the real image and synthetic image. To solve this problem, we focused on separating information in an image into content and style. Here, only the content has cues for semantic segmentation, and the style makes the domain gap. Thus, precise separation of content and style in an image leads to effect as supervision of real data even when learning with synthetic data. To make the best of this effect, we propose a zero-style loss. Even though we perfectly extract content for semantic segmentation in the real domain, another main challenge, the class imbalance problem, still exists in UDA for semantic segmentation. We address this problem by transferring the contents of tail classes from synthetic to real domain. Experimental results show that the proposed method achieves the state-of-the-art performance in semantic segmentation on the major two UDA settings.
Lighter Stacked Hourglass Human Pose Estimation
Jul 28, 2021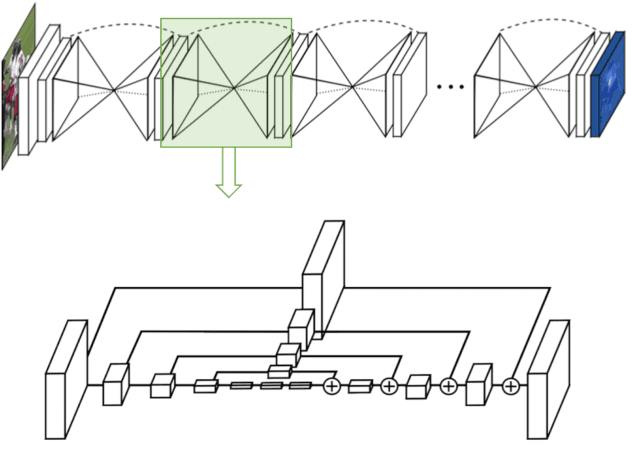
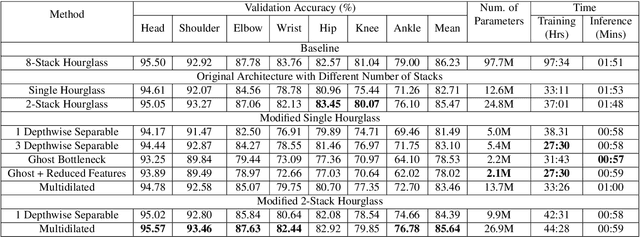
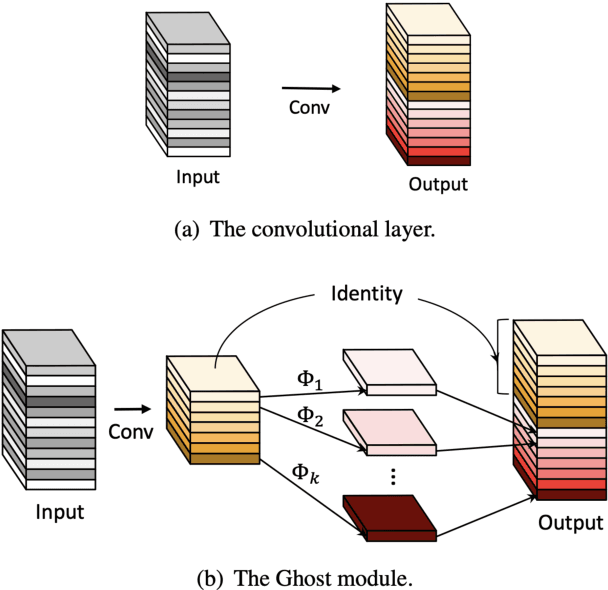
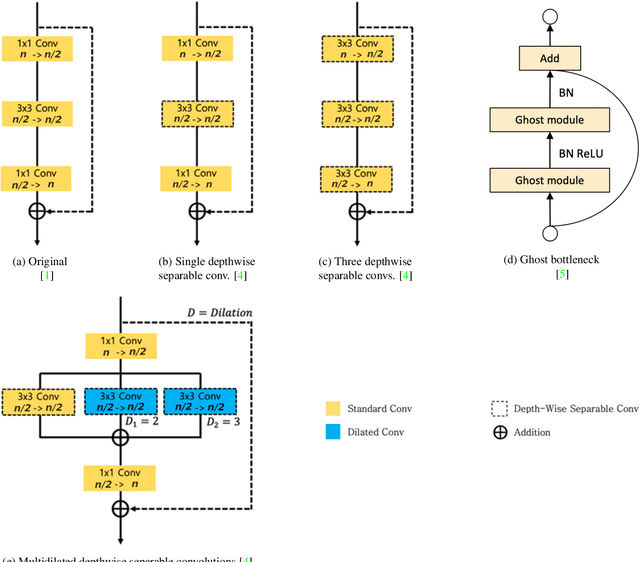
Human pose estimation (HPE) is one of the most challenging tasks in computer vision as humans are deformable by nature and thus their pose has so much variance. HPE aims to correctly identify the main joint locations of a single person or multiple people in a given image or video. Locating joints of a person in images or videos is an important task that can be applied in action recognition and object tracking. As have many computer vision tasks, HPE has advanced massively with the introduction of deep learning to the field. In this paper, we focus on one of the deep learning-based approaches of HPE proposed by Newell et al., which they named the stacked hourglass network. Their approach is widely used in many applications and is regarded as one of the best works in this area. The main focus of their approach is to capture as much information as it can at all possible scales so that a coherent understanding of the local features and full-body location is achieved. Their findings demonstrate that important cues such as orientation of a person, arrangement of limbs, and adjacent joints' relative location can be identified from multiple scales at different resolutions. To do so, they makes use of a single pipeline to process images in multiple resolutions, which comprises a skip layer to not lose spatial information at each resolution. The resolution of the images stretches as lower as 4x4 to make sure that a smaller spatial feature is included. In this study, we study the effect of architectural modifications on the computational speed and accuracy of the network.
Incorporating Orientations into End-to-end Driving Model for Steering Control
Mar 10, 2021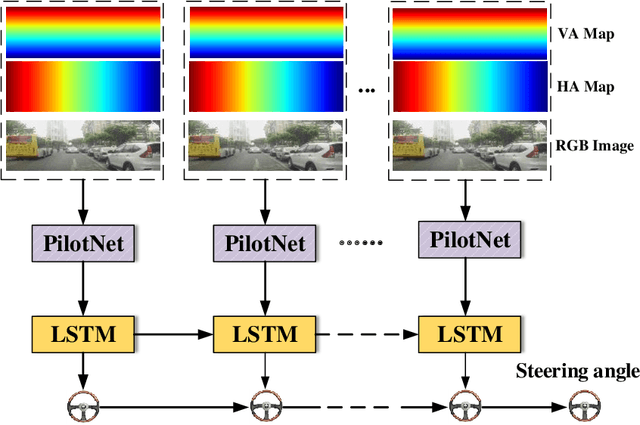
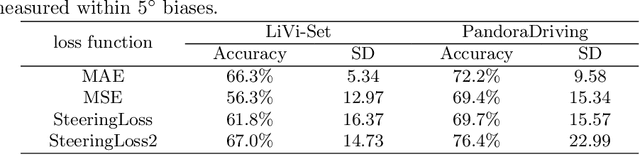
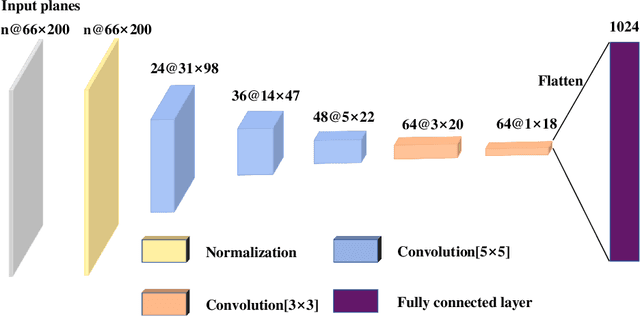

In this paper, we present a novel end-to-end deep neural network model for autonomous driving that takes monocular image sequence as input, and directly generates the steering control angle. Firstly, we model the end-to-end driving problem as a local path planning process. Inspired by the environmental representation in the classical planning algorithms(i.e. the beam curvature method), pixel-wise orientations are fed into the network to learn direction-aware features. Next, to handle the imbalanced distribution of steering values in training datasets, we propose an improvement on a cost-sensitive loss function named SteeringLoss2. Besides, we also present a new end-to-end driving dataset, which provides corresponding LiDAR and image sequences, as well as standard driving behaviors. Our dataset includes multiple driving scenarios, such as urban, country, and off-road. Numerous experiments are conducted on both public available LiVi-Set and our own dataset, and the results show that the model using our proposed methods can predict steering angle accurately.
Spectrum Congruency of Multiscale Local Patches for Edge Detection
Mar 10, 2021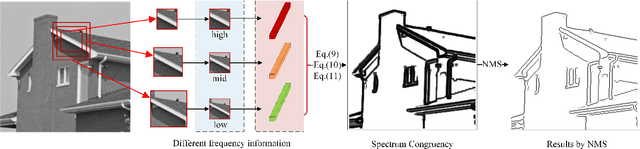

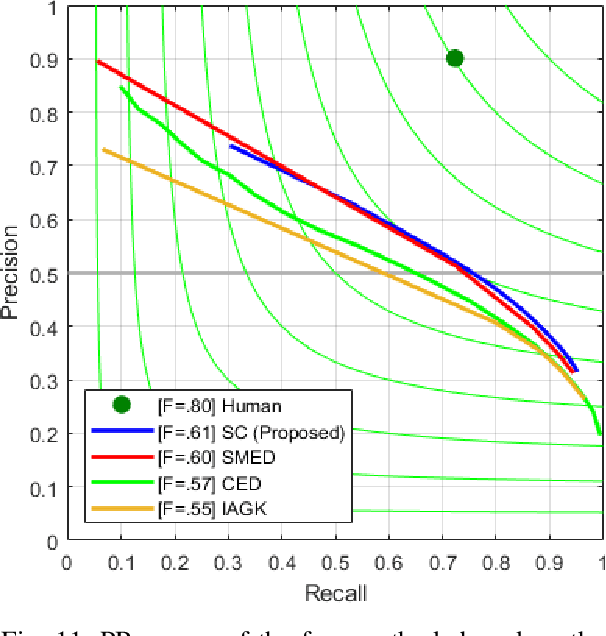
This paper proposes a novel feature called spectrum congruency for describing edges in images. The spectrum congruency is a generalization of the phase congruency, which depicts how much each Fourier components of the image are congruent in phase. Instead of using fixed bases in phase congruency, the spectrum congruency measures the congruency of the energy distribution of multiscale patches in a data-driven transform domain, which is more adaptable to the input images. Multiscale image patches are used to acquire different frequency components for modeling the local energy and amplitude. The spectrum congruency coincides nicely with human visions of perceiving features and provides a more reliable way of detecting edges. Unlike most existing differential-based multiscale edge detectors which simply combine the multiscale information, our method focuses on exploiting the correlation of the multiscale patches based on their local energy. We test our proposed method on synthetic and real images, and the results demonstrate that our approach is practical and highly robust to noise.
OIAD: One-for-all Image Anomaly Detection with Disentanglement Learning
Jan 18, 2020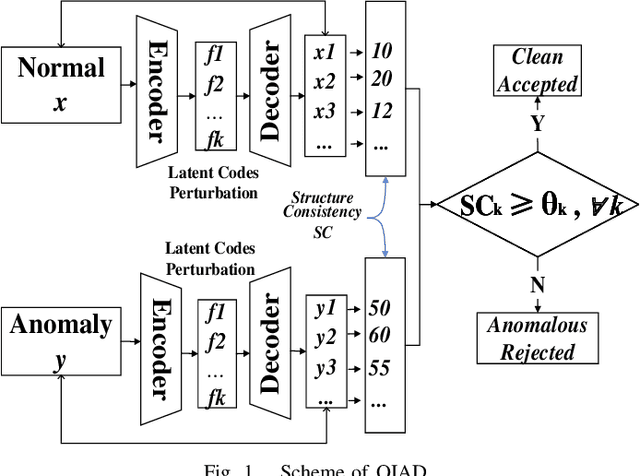
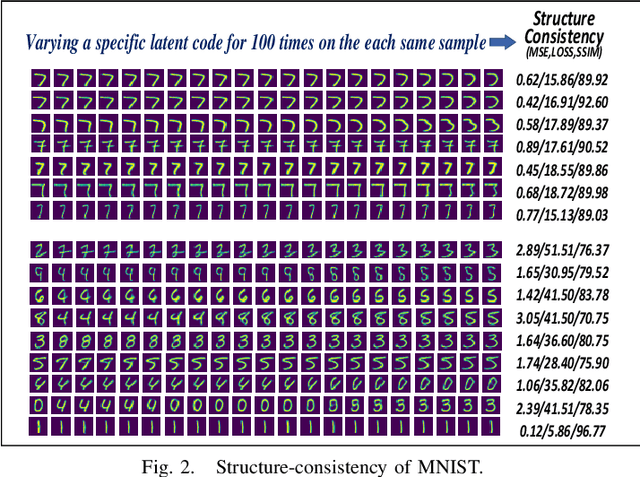
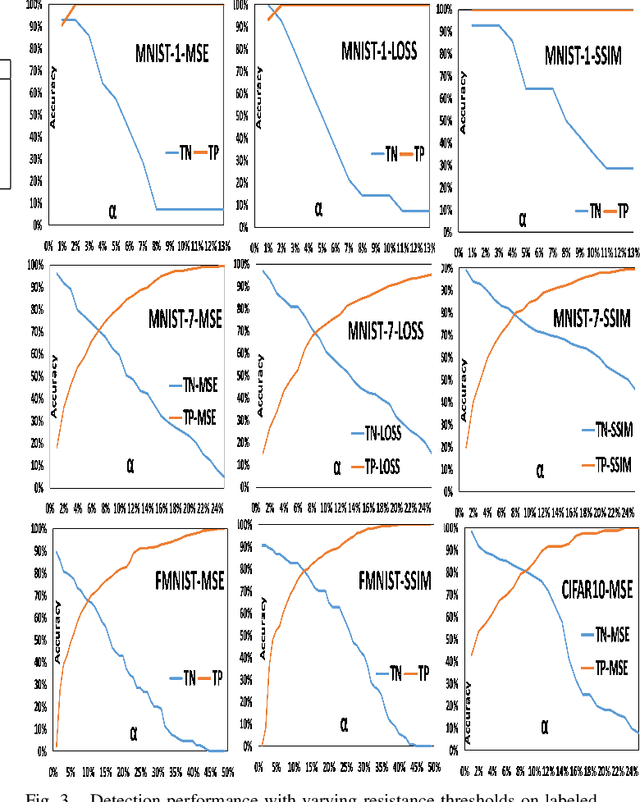
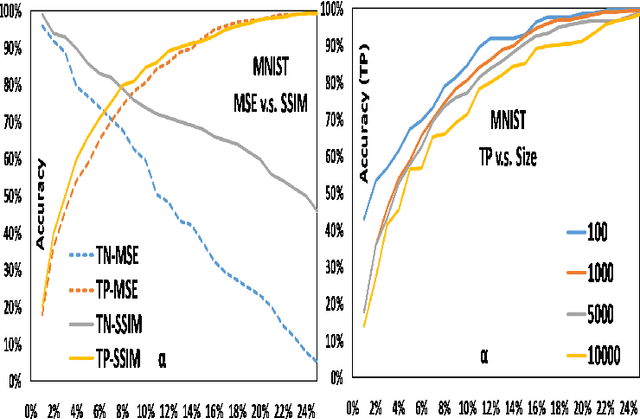
Anomaly detection aims to recognize samples with anomalous and unusual patterns with respect to a set of normal data, which is significant for numerous domain applications, e.g. in industrial inspection, medical imaging, and security enforcement. There are two key research challenges associated with existing anomaly detention approaches: (1) many of them perform well on low-dimensional problems however the performance on high-dimensional instances is limited, such as images; (2) many of them depend on often still rely on traditional supervised approaches and manual engineering of features, while the topic has not been fully explored yet using modern deep learning approaches, even when the well-label samples are limited. In this paper, we propose a One-for-all Image Anomaly Detection system (OIAD) based on disentangled learning using only clean samples. Our key insight is that the impact of small perturbation on the latent representation can be bounded for normal samples while anomaly images are usually outside such bounded intervals, called structure consistency. We implement this idea and evaluate its performance for anomaly detention. Our experiments with three datasets show that OIAD can detect over $90\%$ of anomalies while maintaining a high low false alarm rate. It can also detect suspicious samples from samples labeled as clean, coincided with what humans would deem unusual.
Discovering Relationships between Object Categories via Universal Canonical Maps
Jun 17, 2021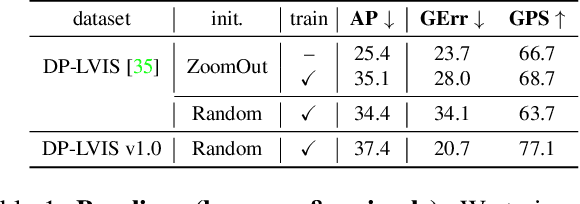



We tackle the problem of learning the geometry of multiple categories of deformable objects jointly. Recent work has shown that it is possible to learn a unified dense pose predictor for several categories of related objects. However, training such models requires to initialize inter-category correspondences by hand. This is suboptimal and the resulting models fail to maintain correct correspondences as individual categories are learned. In this paper, we show that improved correspondences can be learned automatically as a natural byproduct of learning category-specific dense pose predictors. To do this, we express correspondences between different categories and between images and categories using a unified embedding. Then, we use the latter to enforce two constraints: symmetric inter-category cycle consistency and a new asymmetric image-to-category cycle consistency. Without any manual annotations for the inter-category correspondences, we obtain state-of-the-art alignment results, outperforming dedicated methods for matching 3D shapes. Moreover, the new model is also better at the task of dense pose prediction than prior work.