 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Localization and Tracking of User-Defined Points on Deformable Objects for Robotic Manipulation
May 19, 2021
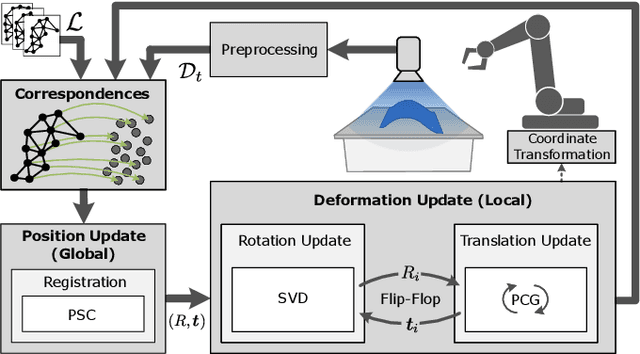
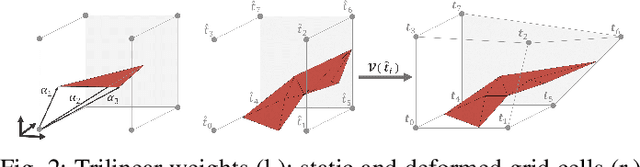
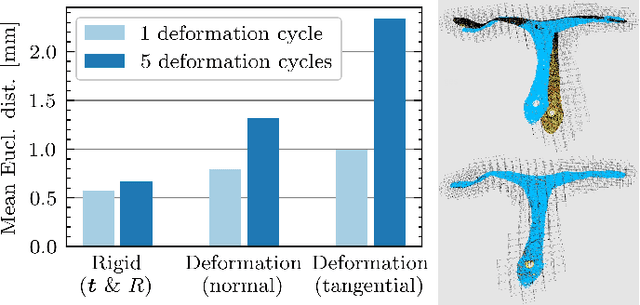

This paper introduces an efficient procedure to localize user-defined points on the surface of deformable objects and track their positions in 3D space over time. To cope with a deformable object's infinite number of DOF, we propose a discretized deformation field, which is estimated during runtime using a multi-step non-linear solver pipeline. The resulting high-dimensional energy minimization problem describes the deviation between an offline-defined reference model and a pre-processed camera image. An additional regularization term allows for assumptions about the object's hidden areas and increases the solver's numerical stability. Our approach is capable of solving the localization problem online in a data-parallel manner, making it ideally suitable for the perception of non-rigid objects in industrial manufacturing processes.
Self-supervised Feature Enhancement: Applying Internal Pretext Task to Supervised Learning
Jun 09, 2021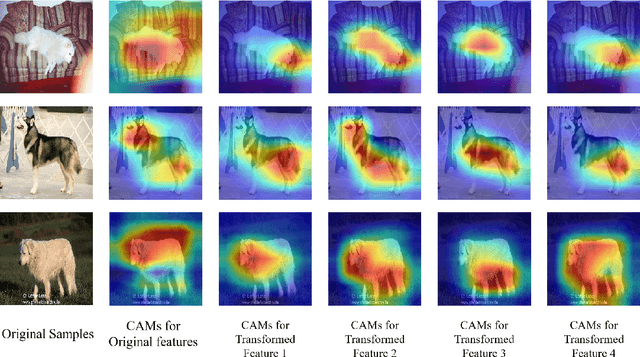
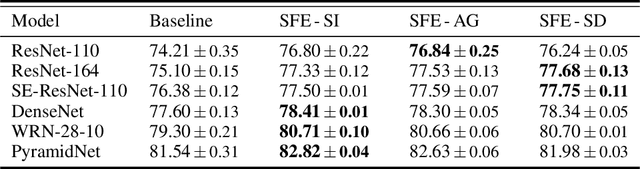
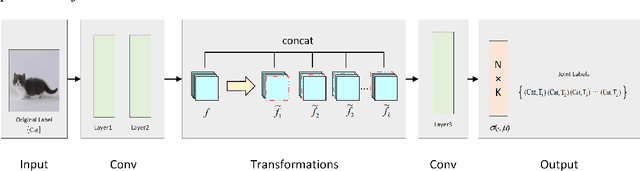

Traditional self-supervised learning requires CNNs using external pretext tasks (i.e., image- or video-based tasks) to encode high-level semantic visual representations. In this paper, we show that feature transformations within CNNs can also be regarded as supervisory signals to construct the self-supervised task, called \emph{internal pretext task}. And such a task can be applied for the enhancement of supervised learning. Specifically, we first transform the internal feature maps by discarding different channels, and then define an additional internal pretext task to identify the discarded channels. CNNs are trained to predict the joint labels generated by the combination of self-supervised labels and original labels. By doing so, we let CNNs know which channels are missing while classifying in the hope to mine richer feature information. Extensive experiments show that our approach is effective on various models and datasets. And it's worth noting that we only incur negligible computational overhead. Furthermore, our approach can also be compatible with other methods to get better results.
A Study of Face Obfuscation in ImageNet
Mar 10, 2021
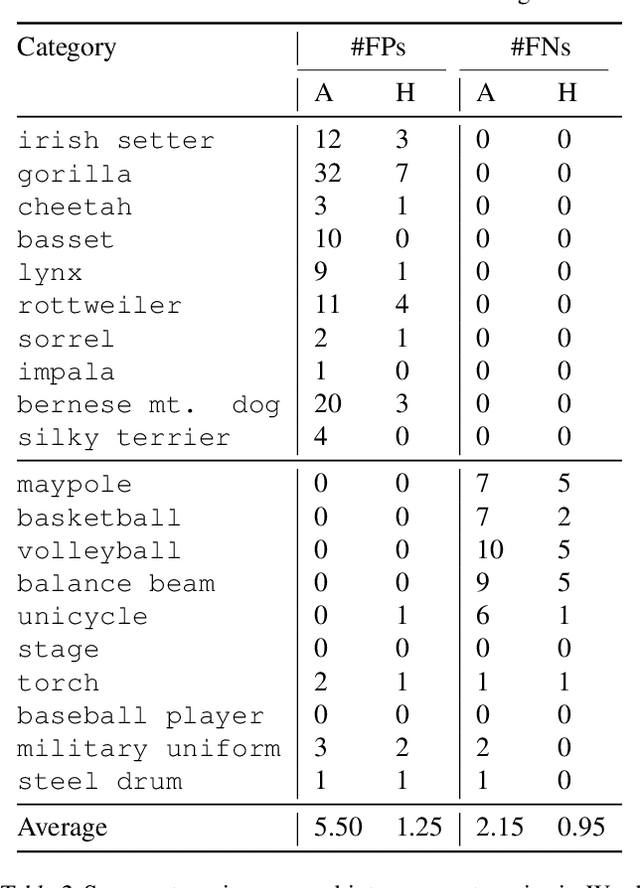
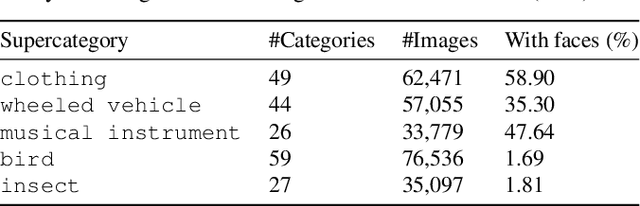
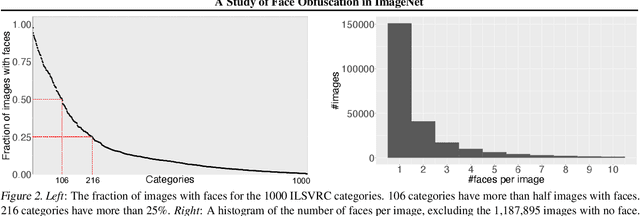
Image obfuscation (blurring, mosaicing, etc.) is widely used for privacy protection. However, computer vision research often overlooks privacy by assuming access to original unobfuscated images. In this paper, we explore image obfuscation in the ImageNet challenge. Most categories in the ImageNet challenge are not people categories; nevertheless, many incidental people are in the images, whose privacy is a concern. We first annotate faces in the dataset. Then we investigate how face blurring -- a typical obfuscation technique -- impacts classification accuracy. We benchmark various deep neural networks on face-blurred images and observe a disparate impact on different categories. Still, the overall accuracy only drops slightly ($\leq 0.68\%$), demonstrating that we can train privacy-aware visual classifiers with minimal impact on accuracy. Further, we experiment with transfer learning to 4 downstream tasks: object recognition, scene recognition, face attribute classification, and object detection. Results show that features learned on face-blurred images are equally transferable. Data and code are available at https://github.com/princetonvisualai/imagenet-face-obfuscation.
Multimodal Co-learning: Challenges, Applications with Datasets, Recent Advances and Future Directions
Jul 29, 2021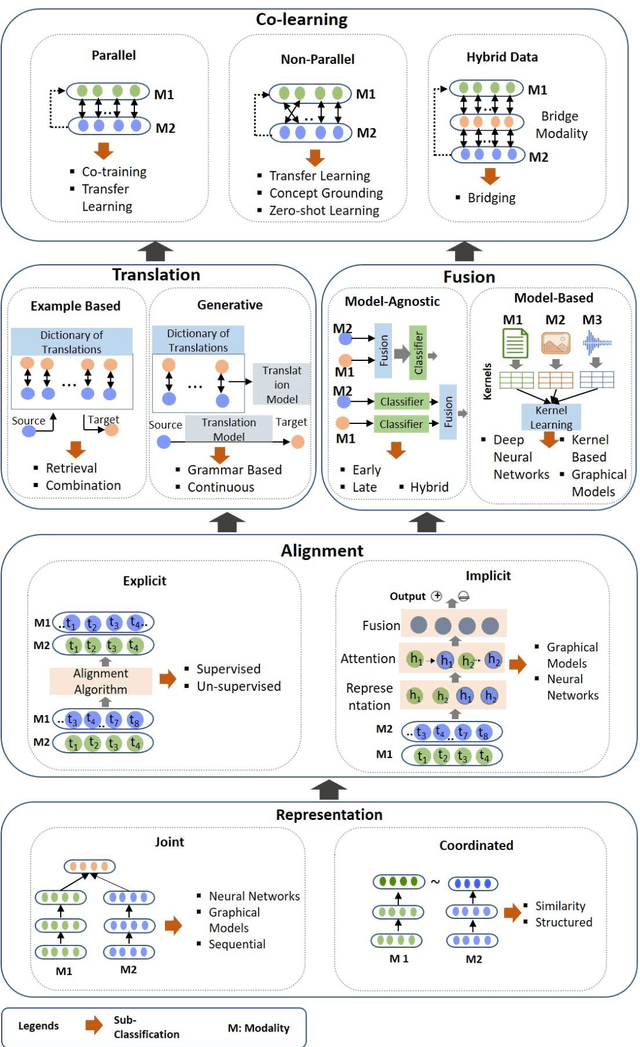
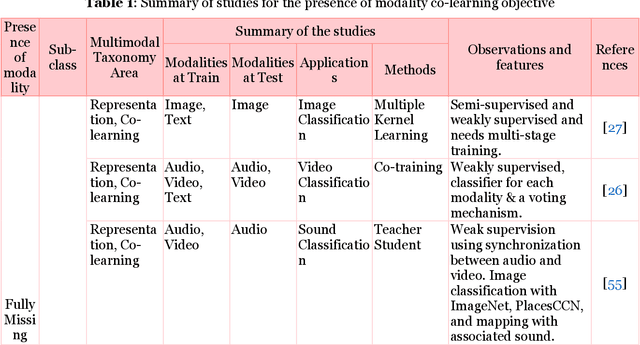
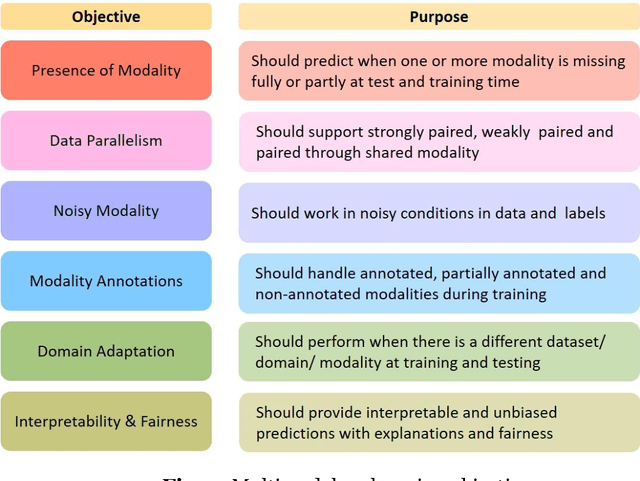
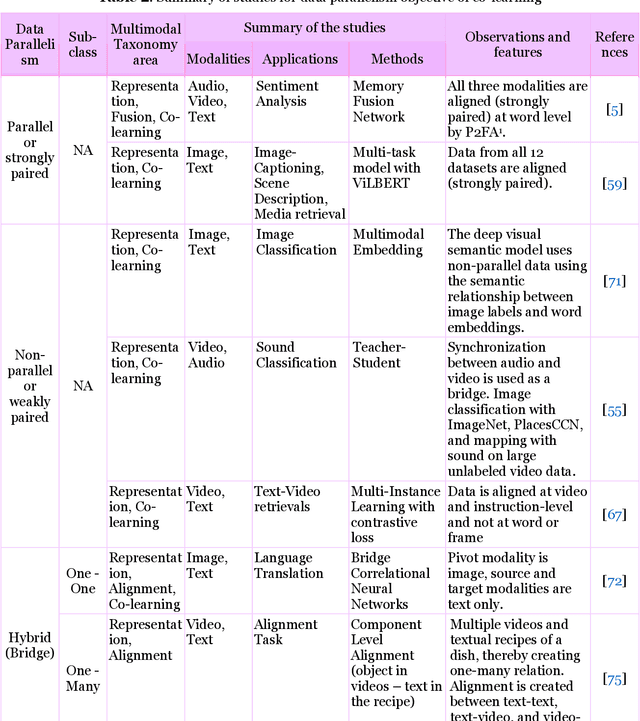
Multimodal deep learning systems which employ multiple modalities like text, image, audio, video, etc., are showing better performance in comparison with individual modalities (i.e., unimodal) systems. Multimodal machine learning involves multiple aspects: representation, translation, alignment, fusion, and co-learning. In the current state of multimodal machine learning, the assumptions are that all modalities are present, aligned, and noiseless during training and testing time. However, in real-world tasks, typically, it is observed that one or more modalities are missing, noisy, lacking annotated data, have unreliable labels, and are scarce in training or testing and or both. This challenge is addressed by a learning paradigm called multimodal co-learning. The modeling of a (resource-poor) modality is aided by exploiting knowledge from another (resource-rich) modality using transfer of knowledge between modalities, including their representations and predictive models. Co-learning being an emerging area, there are no dedicated reviews explicitly focusing on all challenges addressed by co-learning. To that end, in this work, we provide a comprehensive survey on the emerging area of multimodal co-learning that has not been explored in its entirety yet. We review implementations that overcome one or more co-learning challenges without explicitly considering them as co-learning challenges. We present the comprehensive taxonomy of multimodal co-learning based on the challenges addressed by co-learning and associated implementations. The various techniques employed to include the latest ones are reviewed along with some of the applications and datasets. Our final goal is to discuss challenges and perspectives along with the important ideas and directions for future work that we hope to be beneficial for the entire research community focusing on this exciting domain.
Localization of Autonomous Vehicles: Proof of Concept for A Computer Vision Approach
Apr 06, 2021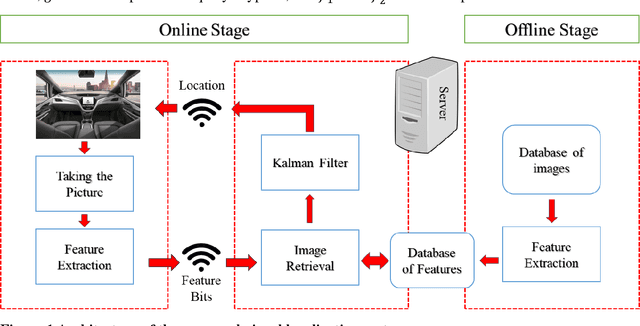


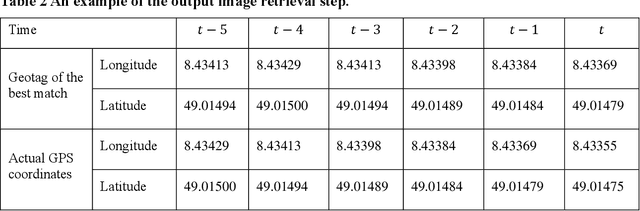
This paper introduces a visual-based localization method for autonomous vehicles (AVs) that operate in the absence of any complicated hardware system but a single camera. Visual localization refers to techniques that aim to find the location of an object based on visual information of its surrounding area. The problem of localization has been of interest for many years. However, visual localization is a relatively new subject in the literature of transportation. Moreover, the inevitable application of this type of localization in the context of autonomous vehicles demands special attention from the transportation community to this problem. This study proposes a two-step localization method that requires a database of geotagged images and a camera mounted on a vehicle that can take pictures while the car is moving. The first step which is image retrieval uses SIFT local feature descriptor to find an initial location for the vehicle using image matching. The next step is to utilize the Kalman filter to estimate a more accurate location for the vehicle as it is moving. All stages of the introduced method are implemented as a complete system using different Python libraries. The proposed system is tested on the KITTI dataset and has shown an average accuracy of 2 meters in finding the final location of the vehicle.
Learning a Discriminative Prior for Blind Image Deblurring
Apr 04, 2018
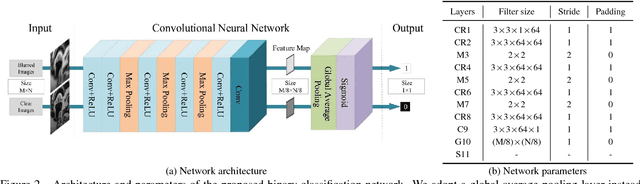
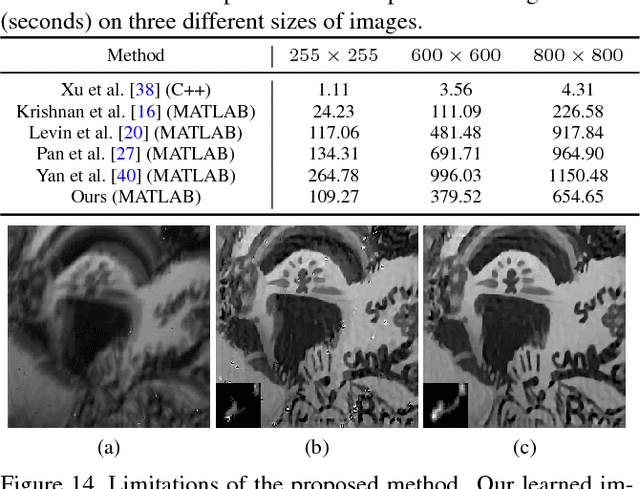
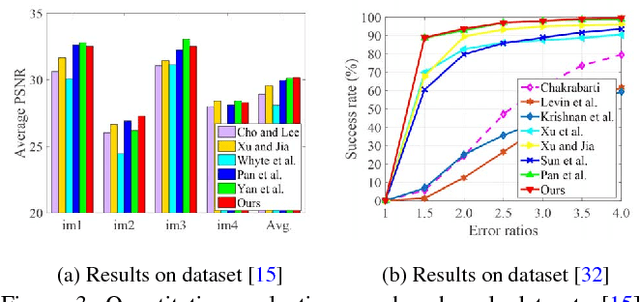
We present an effective blind image deblurring method based on a data-driven discriminative prior.Our work is motivated by the fact that a good image prior should favor clear images over blurred images.In this work, we formulate the image prior as a binary classifier which can be achieved by a deep convolutional neural network (CNN).The learned prior is able to distinguish whether an input image is clear or not.Embedded into the maximum a posterior (MAP) framework, it helps blind deblurring in various scenarios, including natural, face, text, and low-illumination images.However, it is difficult to optimize the deblurring method with the learned image prior as it involves a non-linear CNN.Therefore, we develop an efficient numerical approach based on the half-quadratic splitting method and gradient decent algorithm to solve the proposed model.Furthermore, the proposed model can be easily extended to non-uniform deblurring.Both qualitative and quantitative experimental results show that our method performs favorably against state-of-the-art algorithms as well as domain-specific image deblurring approaches.
AI for Calcium Scoring
May 24, 2021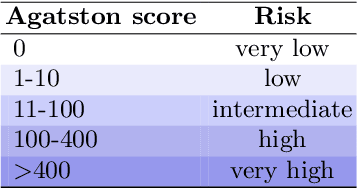
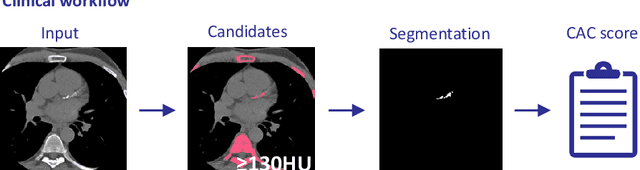
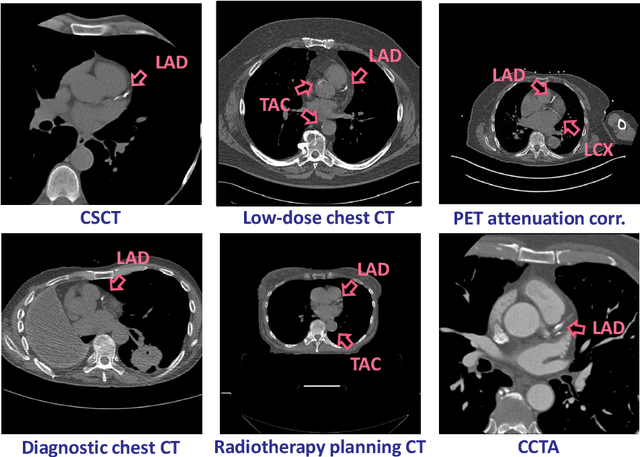
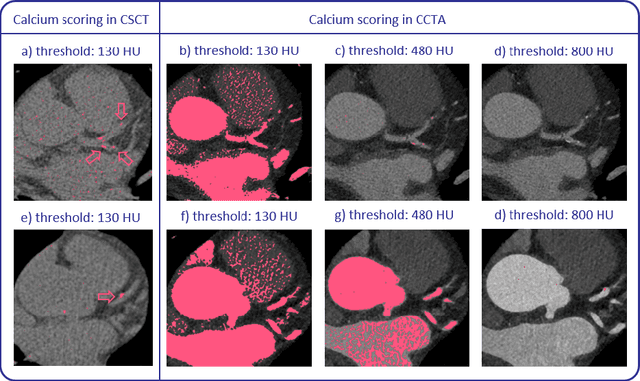
Calcium scoring, a process in which arterial calcifications are detected and quantified in CT, is valuable in estimating the risk of cardiovascular disease events. Especially when used to quantify the extent of calcification in the coronary arteries, it is a strong and independent predictor of coronary heart disease events. Advances in artificial intelligence (AI)-based image analysis have produced a multitude of automatic calcium scoring methods. While most early methods closely follow standard calcium scoring accepted in clinic, recent approaches extend this procedure to enable faster or more reproducible calcium scoring. This chapter provides an introduction to AI for calcium scoring, and an overview of the developed methods and their applications. We conclude with a discussion on AI methods in calcium scoring and propose potential directions for future research.
Data augmentation using learned transformations for one-shot medical image segmentation
Apr 06, 2019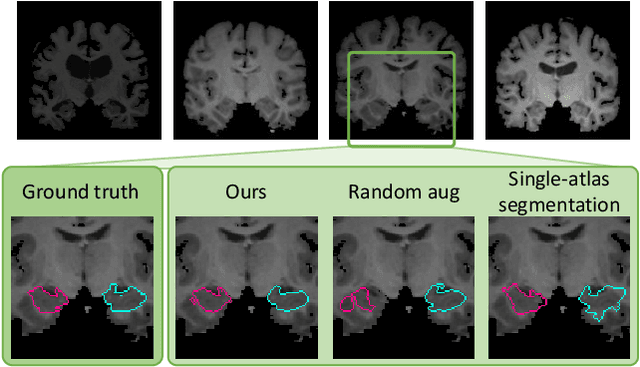
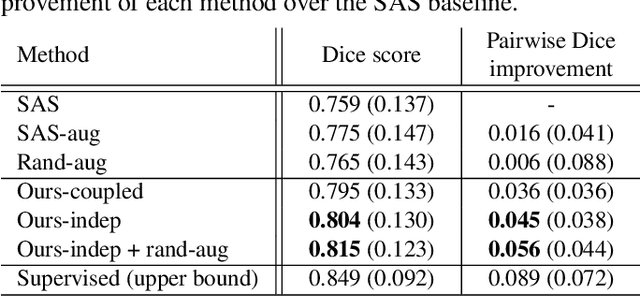
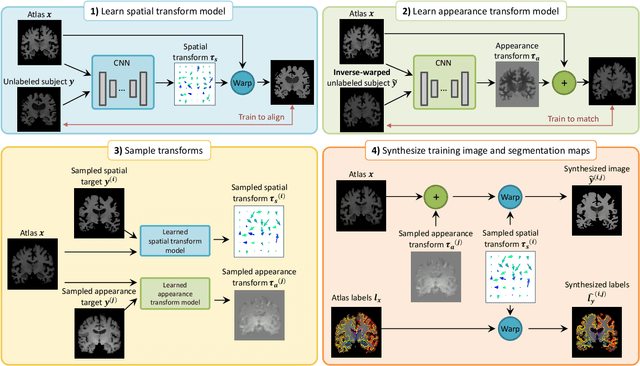
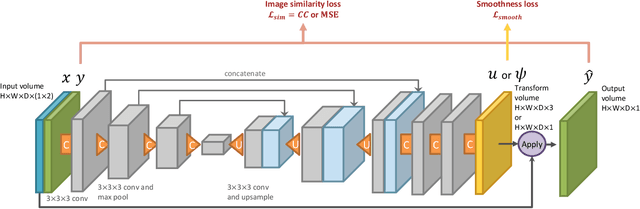
Image segmentation is an important task in many medical applications. Methods based on convolutional neural networks attain state-of-the-art accuracy; however, they typically rely on supervised training with large labeled datasets. Labeling medical images requires significant expertise and time, and typical hand-tuned approaches for data augmentation fail to capture the complex variations in such images. We present an automated data augmentation method for synthesizing labeled medical images. We demonstrate our method on the task of segmenting magnetic resonance imaging (MRI) brain scans. Our method requires only a single segmented scan, and leverages other unlabeled scans in a semi-supervised approach. We learn a model of transformations from the images, and use the model along with the labeled example to synthesize additional labeled examples. Each transformation is comprised of a spatial deformation field and an intensity change, enabling the synthesis of complex effects such as variations in anatomy and image acquisition procedures. We show that training a supervised segmenter with these new examples provides significant improvements over state-of-the-art methods for one-shot biomedical image segmentation. Our code is available at https://github.com/xamyzhao/brainstorm.
Deep Burst Super-Resolution
Jan 26, 2021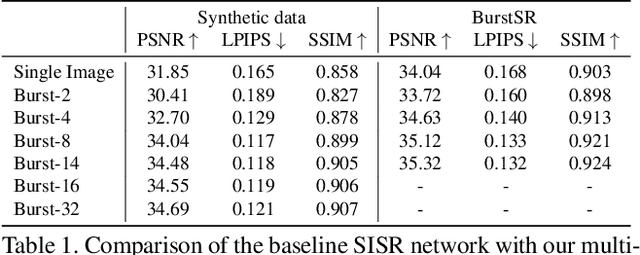
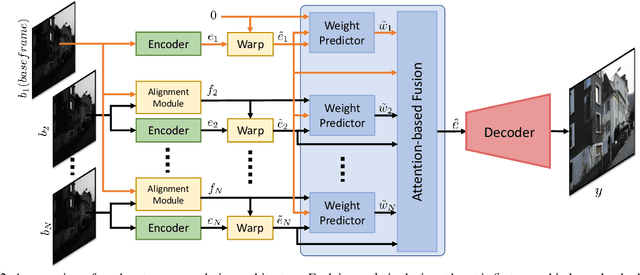
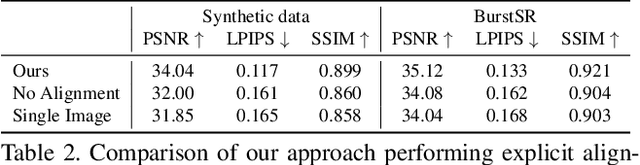
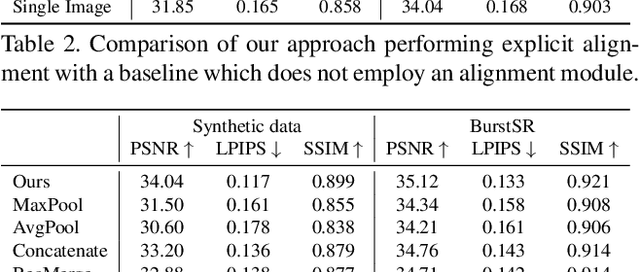
While single-image super-resolution (SISR) has attracted substantial interest in recent years, the proposed approaches are limited to learning image priors in order to add high frequency details. In contrast, multi-frame super-resolution (MFSR) offers the possibility of reconstructing rich details by combining signal information from multiple shifted images. This key advantage, along with the increasing popularity of burst photography, have made MFSR an important problem for real-world applications. We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. We perform comprehensive experimental analysis, demonstrating the effectiveness of the proposed architecture.
A Generative Map for Image-based Camera Localization
Apr 16, 2019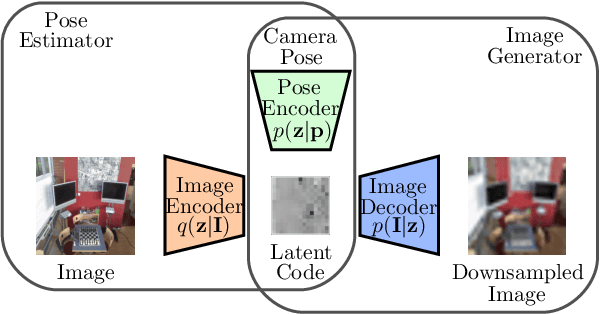
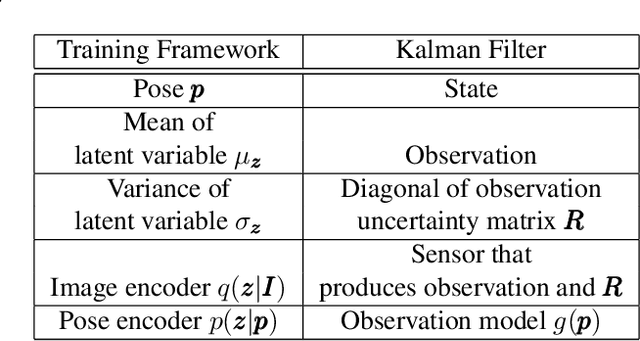
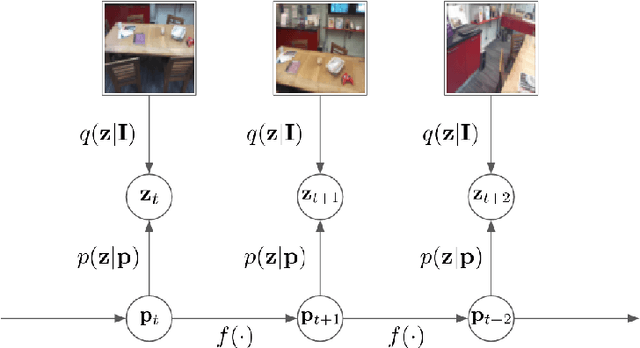
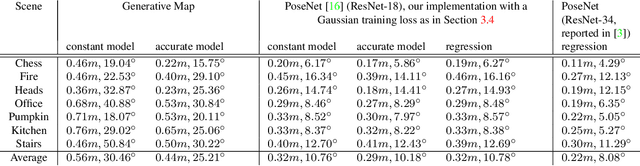
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.