 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predict then Interpolate: A Simple Algorithm to Learn Stable Classifiers
May 26, 2021
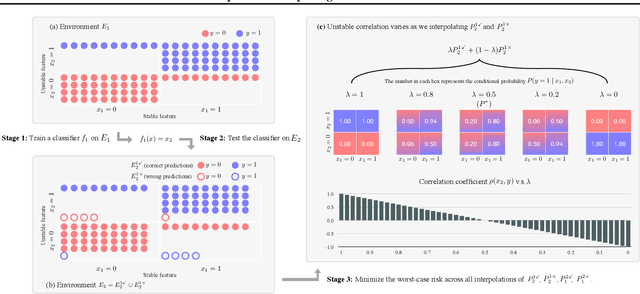
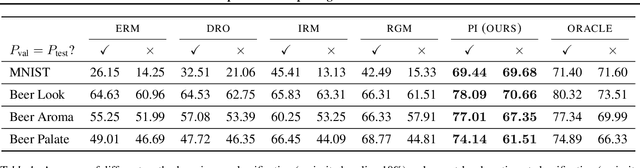
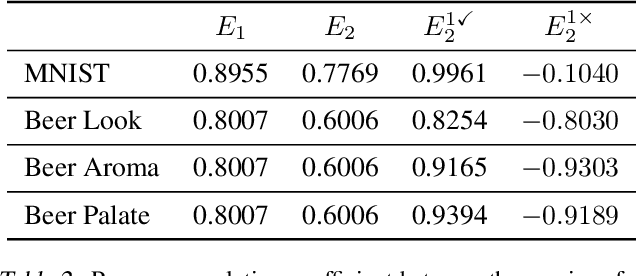
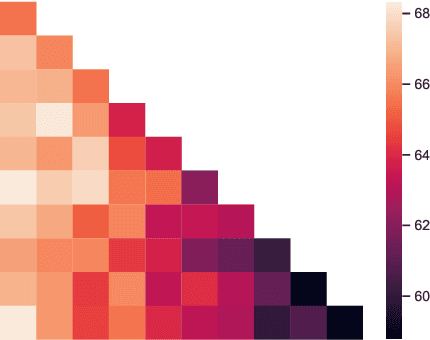
We propose Predict then Interpolate (PI), a simple algorithm for learning correlations that are stable across environments. The algorithm follows from the intuition that when using a classifier trained on one environment to make predictions on examples from another environment, its mistakes are informative as to which correlations are unstable. In this work, we prove that by interpolating the distributions of the correct predictions and the wrong predictions, we can uncover an oracle distribution where the unstable correlation vanishes. Since the oracle interpolation coefficients are not accessible, we use group distributionally robust optimization to minimize the worst-case risk across all such interpolations. We evaluate our method on both text classification and image classification. Empirical results demonstrate that our algorithm is able to learn robust classifiers (outperforms IRM by 23.85% on synthetic environments and 12.41% on natural environments). Our code and data are available at https://github.com/YujiaBao/Predict-then-Interpolate.
Towards Training Stronger Video Vision Transformers for EPIC-KITCHENS-100 Action Recognition
Jun 09, 2021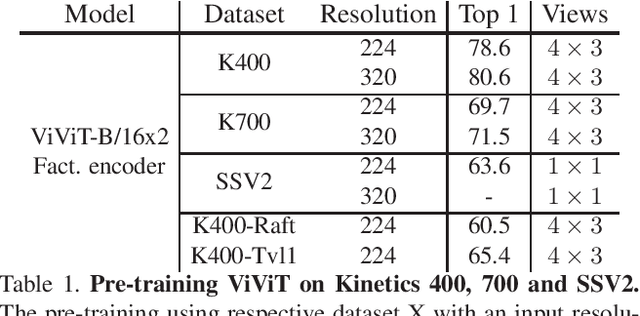
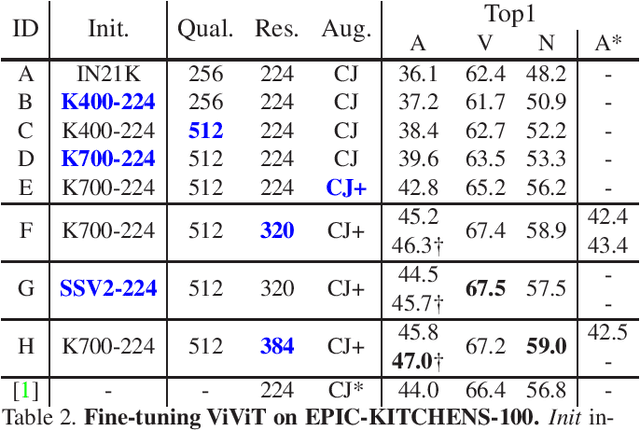
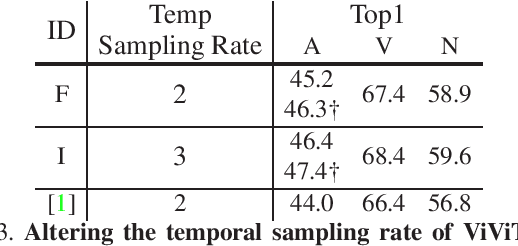
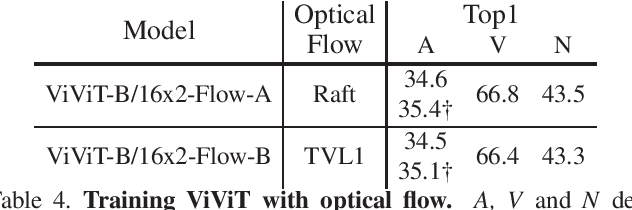
With the recent surge in the research of vision transformers, they have demonstrated remarkable potential for various challenging computer vision applications, such as image recognition, point cloud classification as well as video understanding. In this paper, we present empirical results for training a stronger video vision transformer on the EPIC-KITCHENS-100 Action Recognition dataset. Specifically, we explore training techniques for video vision transformers, such as augmentations, resolutions as well as initialization, etc. With our training recipe, a single ViViT model achieves the performance of 47.4\% on the validation set of EPIC-KITCHENS-100 dataset, outperforming what is reported in the original paper by 3.4%. We found that video transformers are especially good at predicting the noun in the verb-noun action prediction task. This makes the overall action prediction accuracy of video transformers notably higher than convolutional ones. Surprisingly, even the best video transformers underperform the convolutional networks on the verb prediction. Therefore, we combine the video vision transformers and some of the convolutional video networks and present our solution to the EPIC-KITCHENS-100 Action Recognition competition.
Spatiotemporal Entropy Model is All You Need for Learned Video Compression
Apr 13, 2021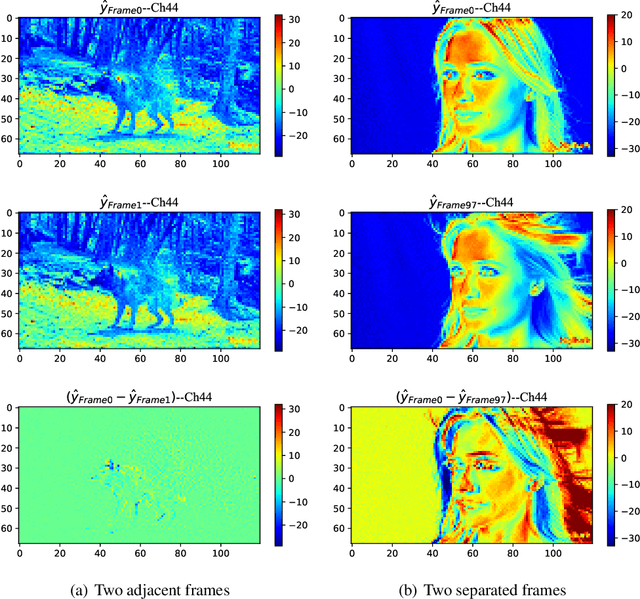

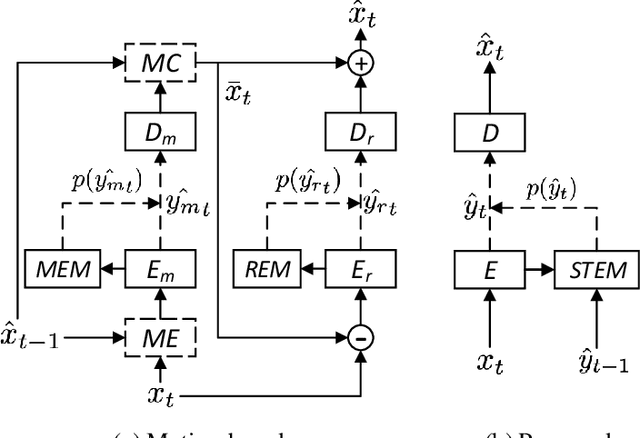
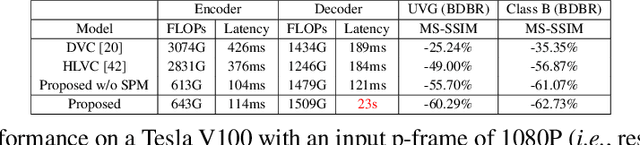
The framework of dominant learned video compression methods is usually composed of motion prediction modules as well as motion vector and residual image compression modules, suffering from its complex structure and error propagation problem. Approaches have been proposed to reduce the complexity by replacing motion prediction modules with implicit flow networks. Error propagation aware training strategy is also proposed to alleviate incremental reconstruction errors from previously decoded frames. Although these methods have brought some improvement, little attention has been paid to the framework itself. Inspired by the success of learned image compression through simplifying the framework with a single deep neural network, it is natural to expect a better performance in video compression via a simple yet appropriate framework. Therefore, we propose a framework to directly compress raw-pixel frames (rather than residual images), where no extra motion prediction module is required. Instead, an entropy model is used to estimate the spatiotemporal redundancy in a latent space rather than pixel level, which significantly reduces the complexity of the framework. Specifically, the whole framework is a compression module, consisting of a unified auto-encoder which produces identically distributed latents for all frames, and a spatiotemporal entropy estimation model to minimize the entropy of these latents. Experiments showed that the proposed method outperforms state-of-the-art (SOTA) performance under the metric of multiscale structural similarity (MS-SSIM) and achieves competitive results under the metric of PSNR.
Mixed supervision for surface-defect detection: from weakly to fully supervised learning
Apr 13, 2021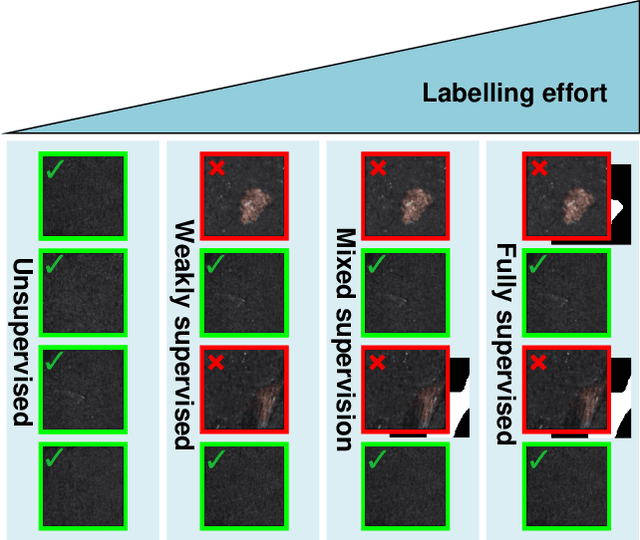
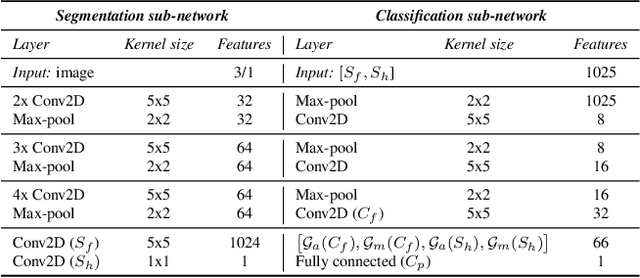
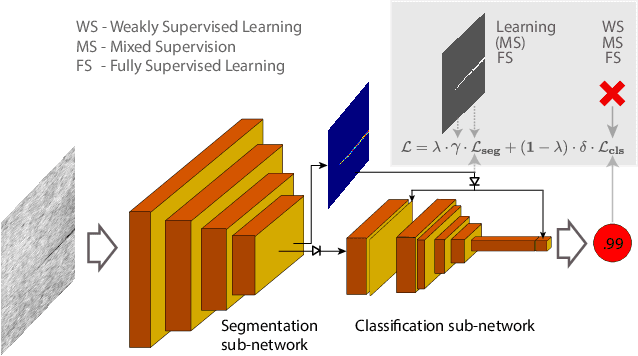
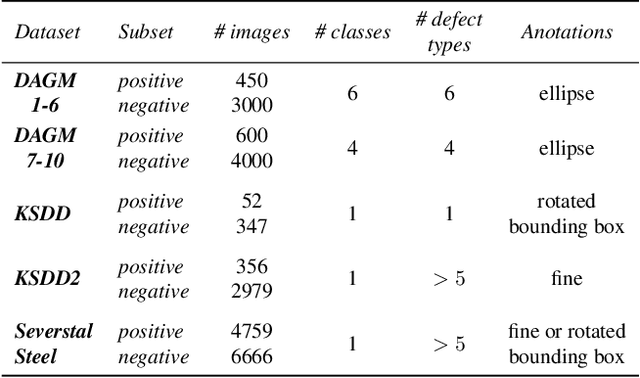
Deep-learning methods have recently started being employed for addressing surface-defect detection problems in industrial quality control. However, with a large amount of data needed for learning, often requiring high-precision labels, many industrial problems cannot be easily solved, or the cost of the solutions would significantly increase due to the annotation requirements. In this work, we relax heavy requirements of fully supervised learning methods and reduce the need for highly detailed annotations. By proposing a deep-learning architecture, we explore the use of annotations of different details ranging from weak (image-level) labels through mixed supervision to full (pixel-level) annotations on the task of surface-defect detection. The proposed end-to-end architecture is composed of two sub-networks yielding defect segmentation and classification results. The proposed method is evaluated on several datasets for industrial quality inspection: KolektorSDD, DAGM and Severstal Steel Defect. We also present a new dataset termed KolektorSDD2 with over 3000 images containing several types of defects, obtained while addressing a real-world industrial problem. We demonstrate state-of-the-art results on all four datasets. The proposed method outperforms all related approaches in fully supervised settings and also outperforms weakly-supervised methods when only image-level labels are available. We also show that mixed supervision with only a handful of fully annotated samples added to weakly labelled training images can result in performance comparable to the fully supervised model's performance but at a significantly lower annotation cost.
Incorporating Convolution Designs into Visual Transformers
Apr 20, 2021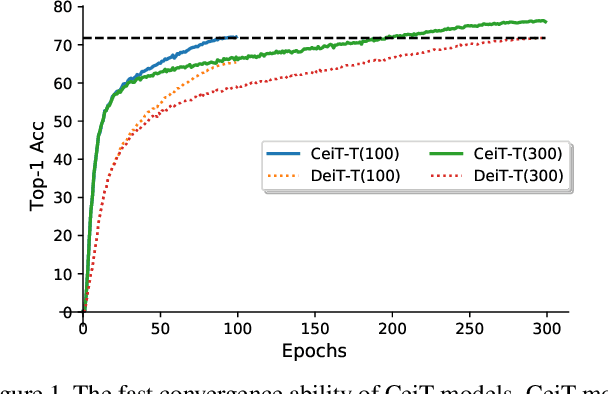

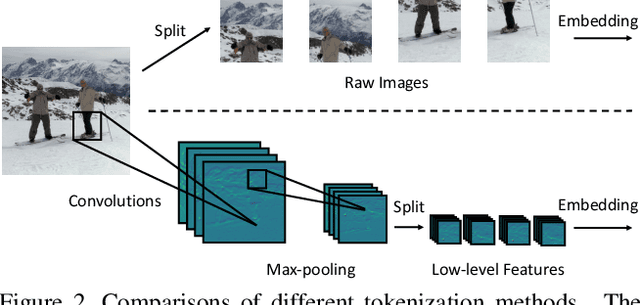

Motivated by the success of Transformers in natural language processing (NLP) tasks, there emerge some attempts (e.g., ViT and DeiT) to apply Transformers to the vision domain. However, pure Transformer architectures often require a large amount of training data or extra supervision to obtain comparable performance with convolutional neural networks (CNNs). To overcome these limitations, we analyze the potential drawbacks when directly borrowing Transformer architectures from NLP. Then we propose a new \textbf{Convolution-enhanced image Transformer (CeiT)} which combines the advantages of CNNs in extracting low-level features, strengthening locality, and the advantages of Transformers in establishing long-range dependencies. Three modifications are made to the original Transformer: \textbf{1)} instead of the straightforward tokenization from raw input images, we design an \textbf{Image-to-Tokens (I2T)} module that extracts patches from generated low-level features; \textbf{2)} the feed-froward network in each encoder block is replaced with a \textbf{Locally-enhanced Feed-Forward (LeFF)} layer that promotes the correlation among neighboring tokens in the spatial dimension; \textbf{3)} a \textbf{Layer-wise Class token Attention (LCA)} is attached at the top of the Transformer that utilizes the multi-level representations. Experimental results on ImageNet and seven downstream tasks show the effectiveness and generalization ability of CeiT compared with previous Transformers and state-of-the-art CNNs, without requiring a large amount of training data and extra CNN teachers. Besides, CeiT models also demonstrate better convergence with $3\times$ fewer training iterations, which can reduce the training cost significantly\footnote{Code and models will be released upon acceptance.}.
Energy-Efficient and Federated Meta-Learning via Projected Stochastic Gradient Ascent
May 31, 2021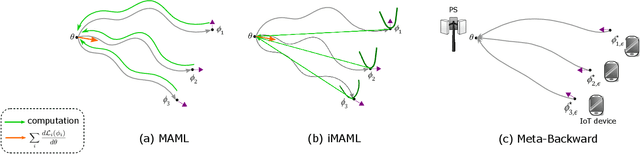
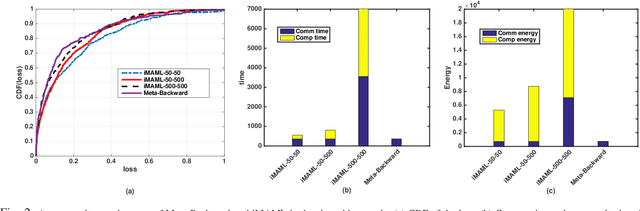
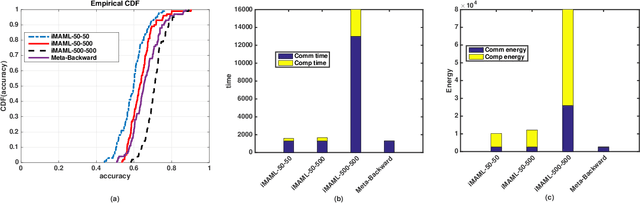
In this paper, we propose an energy-efficient federated meta-learning framework. The objective is to enable learning a meta-model that can be fine-tuned to a new task with a few number of samples in a distributed setting and at low computation and communication energy consumption. We assume that each task is owned by a separate agent, so a limited number of tasks is used to train a meta-model. Assuming each task was trained offline on the agent's local data, we propose a lightweight algorithm that starts from the local models of all agents, and in a backward manner using projected stochastic gradient ascent (P-SGA) finds a meta-model. The proposed method avoids complex computations such as computing hessian, double looping, and matrix inversion, while achieving high performance at significantly less energy consumption compared to the state-of-the-art methods such as MAML and iMAML on conducted experiments for sinusoid regression and image classification tasks.
A Hierarchical Grocery Store Image Dataset with Visual and Semantic Labels
Jan 03, 2019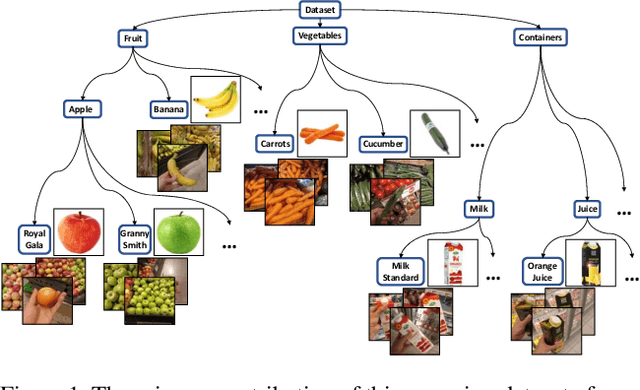
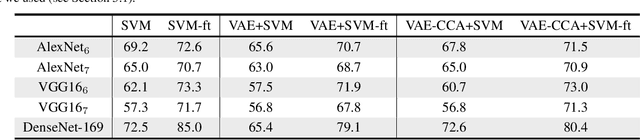

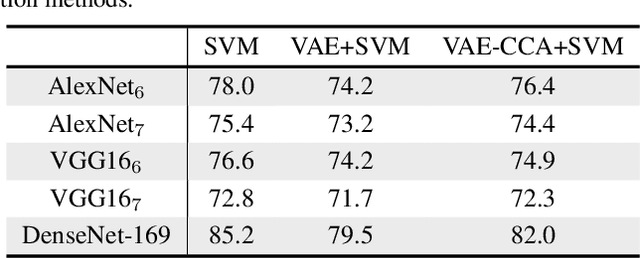
Image classification models built into visual support systems and other assistive devices need to provide accurate predictions about their environment. We focus on an application of assistive technology for people with visual impairments, for daily activities such as shopping or cooking. In this paper, we provide a new benchmark dataset for a challenging task in this application - classification of fruits, vegetables, and refrigerated products, e.g. milk packages and juice cartons, in grocery stores. To enable the learning process to utilize multiple sources of structured information, this dataset not only contains a large volume of natural images but also includes the corresponding information of the product from an online shopping website. Such information encompasses the hierarchical structure of the object classes, as well as an iconic image of each type of object. This dataset can be used to train and evaluate image classification models for helping visually impaired people in natural environments. Additionally, we provide benchmark results evaluated on pretrained convolutional neural networks often used for image understanding purposes, and also a multi-view variational autoencoder, which is capable of utilizing the rich product information in the dataset.
Low-Dose CT Denoising Using a Structure-Preserving Kernel Prediction Network
May 31, 2021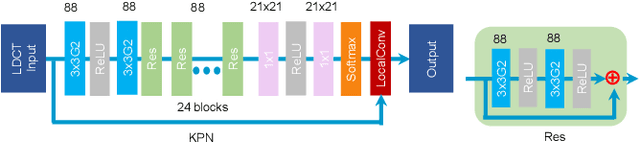
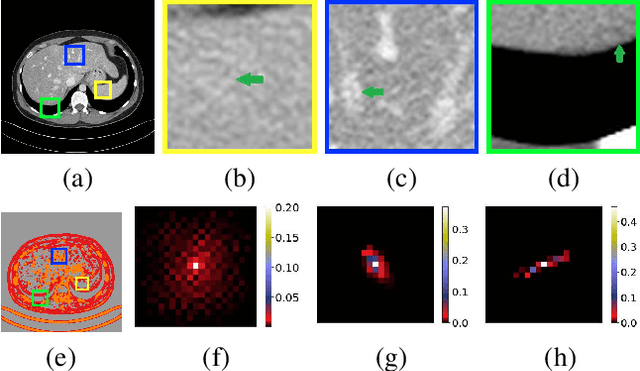


Low-dose CT has been a key diagnostic imaging modality to reduce the potential risk of radiation overdose to patient health. Despite recent advances, CNN-based approaches typically apply filters in a spatially invariant way and adopt similar pixel-level losses, which treat all regions of the CT image equally and can be inefficient when fine-grained structures coexist with non-uniformly distributed noises. To address this issue, we propose a Structure-preserving Kernel Prediction Network (StructKPN) that combines the kernel prediction network with a structure-aware loss function that utilizes the pixel gradient statistics and guides the model towards spatially-variant filters that enhance noise removal, prevent over-smoothing and preserve detailed structures for different regions in CT imaging. Extensive experiments demonstrated that our approach achieved superior performance on both synthetic and non-synthetic datasets, and better preserves structures that are highly desired in clinical screening and low-dose protocol optimization.
Transferable Sparse Adversarial Attack
May 31, 2021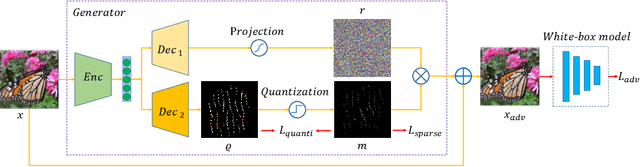
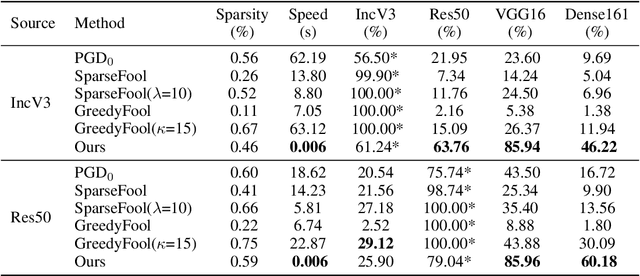
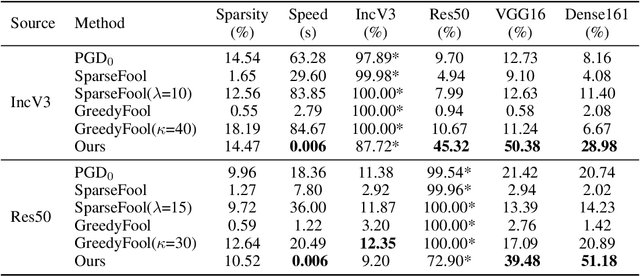
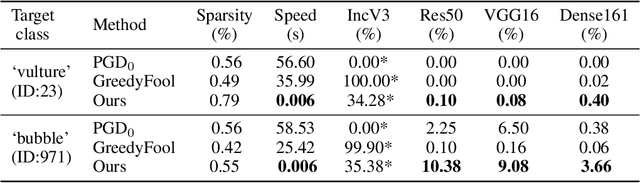
Deep neural networks have shown their vulnerability to adversarial attacks. In this paper, we focus on sparse adversarial attack based on the $\ell_0$ norm constraint, which can succeed by only modifying a few pixels of an image. Despite a high attack success rate, prior sparse attack methods achieve a low transferability under the black-box protocol due to overfitting the target model. Therefore, we introduce a generator architecture to alleviate the overfitting issue and thus efficiently craft transferable sparse adversarial examples. Specifically, the generator decouples the sparse perturbation into amplitude and position components. We carefully design a random quantization operator to optimize these two components jointly in an end-to-end way. The experiment shows that our method has improved the transferability by a large margin under a similar sparsity setting compared with state-of-the-art methods. Moreover, our method achieves superior inference speed, 700$\times$ faster than other optimization-based methods. The code is available at https://github.com/shaguopohuaizhe/TSAA.
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Feb 24, 2020
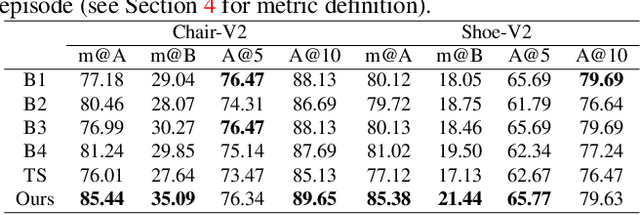
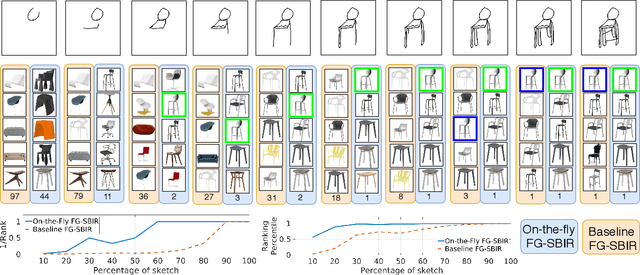
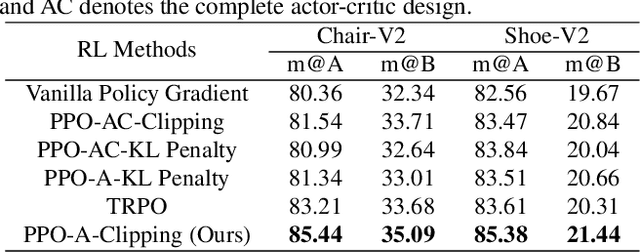
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.