 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PUDLE: Implicit Acceleration of Dictionary Learning by Backpropagation
May 31, 2021
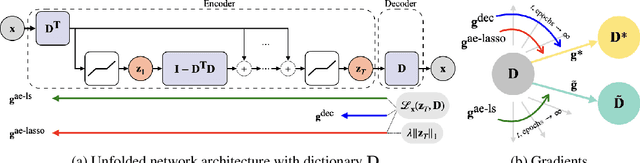
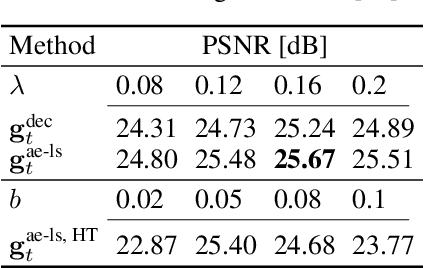
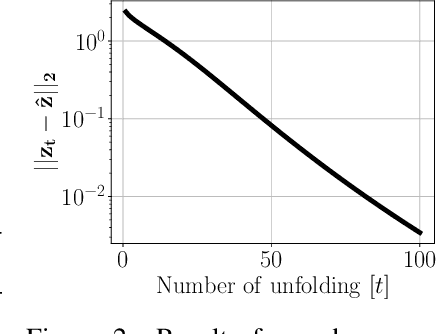
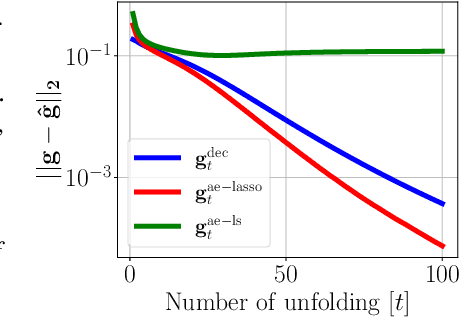
The dictionary learning problem, representing data as a combination of few atoms, has long stood as a popular method for learning representations in statistics and signal processing. The most popular dictionary learning algorithm alternates between sparse coding and dictionary update steps, and a rich literature has studied its theoretical convergence. The growing popularity of neurally plausible unfolded sparse coding networks has led to the empirical finding that backpropagation through such networks performs dictionary learning. This paper offers the first theoretical proof for these empirical results through PUDLE, a Provable Unfolded Dictionary LEarning method. We highlight the impact of loss, unfolding, and backpropagation on convergence. We discover an implicit acceleration: as a function of unfolding, the backpropagated gradient converges faster and is more accurate than the gradient from alternating minimization. We complement our findings through synthetic and image denoising experiments. The findings support the use of accelerated deep learning optimizers and unfolded networks for dictionary learning.
Grafit: Learning fine-grained image representations with coarse labels
Nov 25, 2020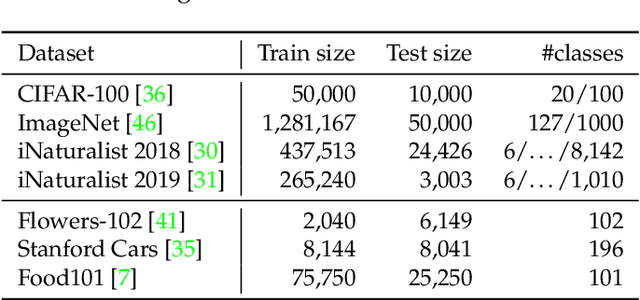
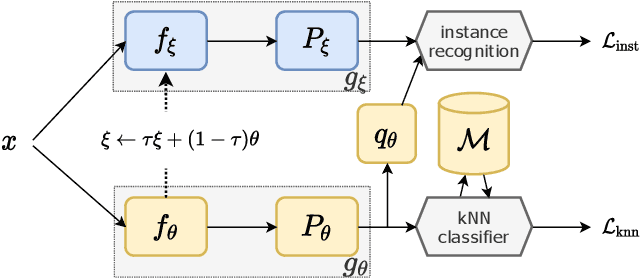
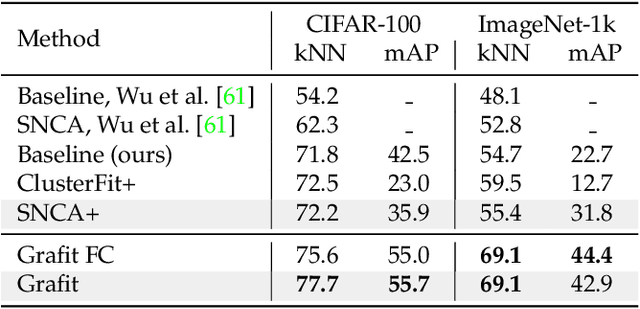
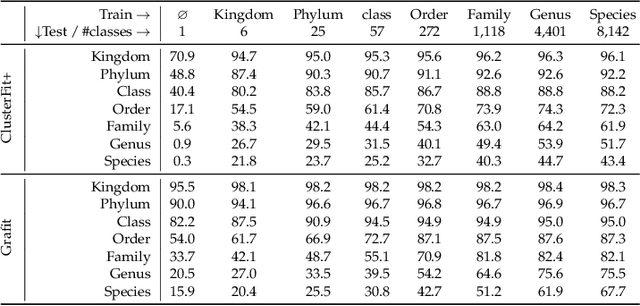
This paper tackles the problem of learning a finer representation than the one provided by training labels. This enables fine-grained category retrieval of images in a collection annotated with coarse labels only. Our network is learned with a nearest-neighbor classifier objective, and an instance loss inspired by self-supervised learning. By jointly leveraging the coarse labels and the underlying fine-grained latent space, it significantly improves the accuracy of category-level retrieval methods. Our strategy outperforms all competing methods for retrieving or classifying images at a finer granularity than that available at train time. It also improves the accuracy for transfer learning tasks to fine-grained datasets, thereby establishing the new state of the art on five public benchmarks, like iNaturalist-2018.
Center Smoothing for Certifiably Robust Vector-Valued Functions
Feb 19, 2021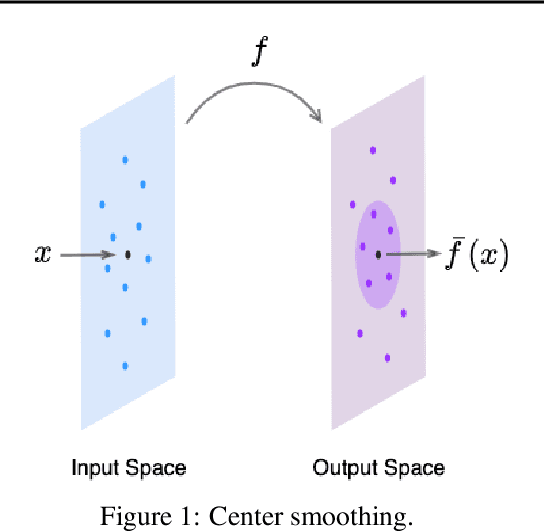
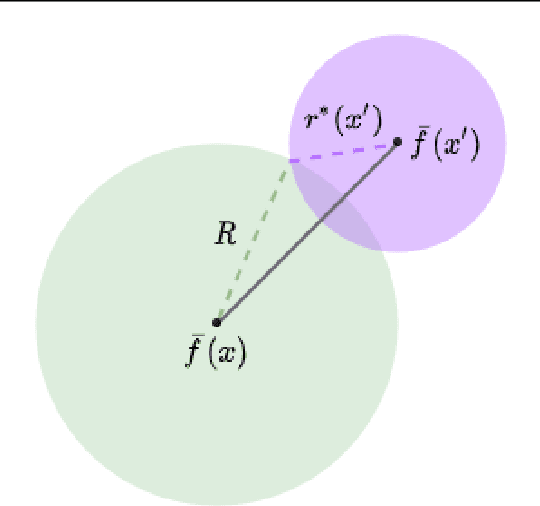

Randomized smoothing has been successfully applied in high-dimensional image classification tasks to obtain models that are provably robust against input perturbations of bounded size. We extend this technique to produce certifiable robustness for vector-valued functions, i.e., bound the change in output caused by a small change in input. These functions are used in many areas of machine learning, such as image reconstruction, dimensionality reduction, super-resolution, etc., but due to the enormous dimensionality of the output space in these problems, generating meaningful robustness guarantees is difficult. We design a smoothing procedure that can leverage the local, potentially low-dimensional, behaviour of the function around an input to obtain probabilistic robustness certificates. We demonstrate the effectiveness of our method on multiple learning tasks involving vector-valued functions with a wide range of input and output dimensionalities.
Decomposition-Based Transfer Distance Metric Learning for Image Classification
Apr 08, 2019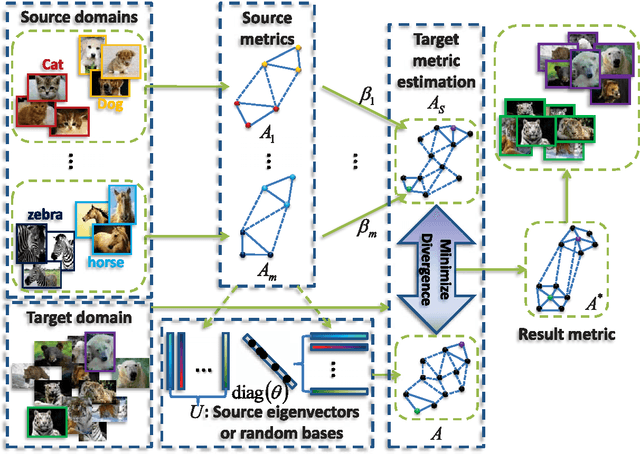
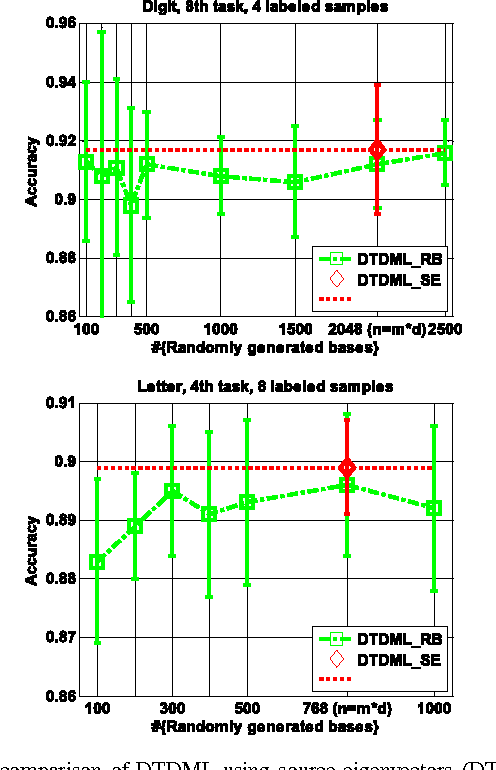
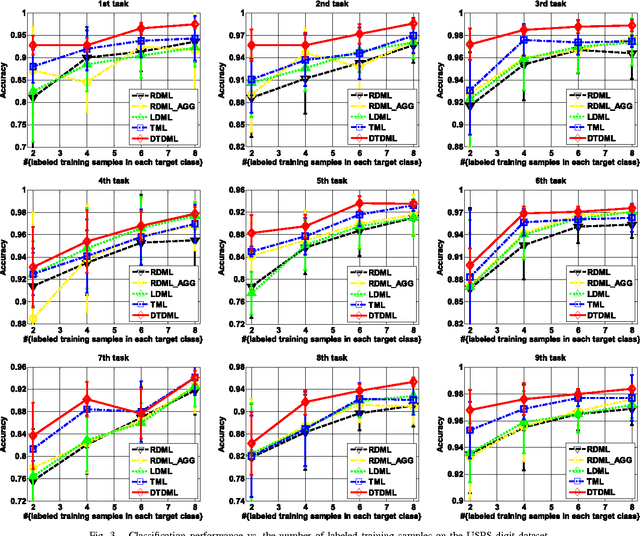
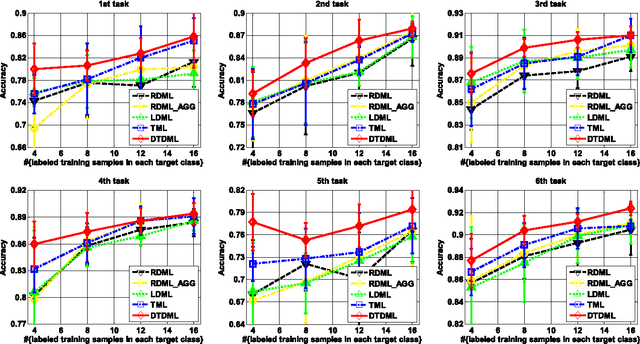
Distance metric learning (DML) is a critical factor for image analysis and pattern recognition. To learn a robust distance metric for a target task, we need abundant side information (i.e., the similarity/dissimilarity pairwise constraints over the labeled data), which is usually unavailable in practice due to the high labeling cost. This paper considers the transfer learning setting by exploiting the large quantity of side information from certain related, but different source tasks to help with target metric learning (with only a little side information). The state-of-the-art metric learning algorithms usually fail in this setting because the data distributions of the source task and target task are often quite different. We address this problem by assuming that the target distance metric lies in the space spanned by the eigenvectors of the source metrics (or other randomly generated bases). The target metric is represented as a combination of the base metrics, which are computed using the decomposed components of the source metrics (or simply a set of random bases); we call the proposed method, decomposition-based transfer DML (DTDML). In particular, DTDML learns a sparse combination of the base metrics to construct the target metric by forcing the target metric to be close to an integration of the source metrics. The main advantage of the proposed method compared with existing transfer metric learning approaches is that we directly learn the base metric coefficients instead of the target metric. To this end, far fewer variables need to be learned. We therefore obtain more reliable solutions given the limited side information and the optimization tends to be faster. Experiments on the popular handwritten image (digit, letter) classification and challenge natural image annotation tasks demonstrate the effectiveness of the proposed method.
Multi-modality super-resolution loss for GAN-based super-resolution of clinical CT images using micro CT image database
Dec 30, 2019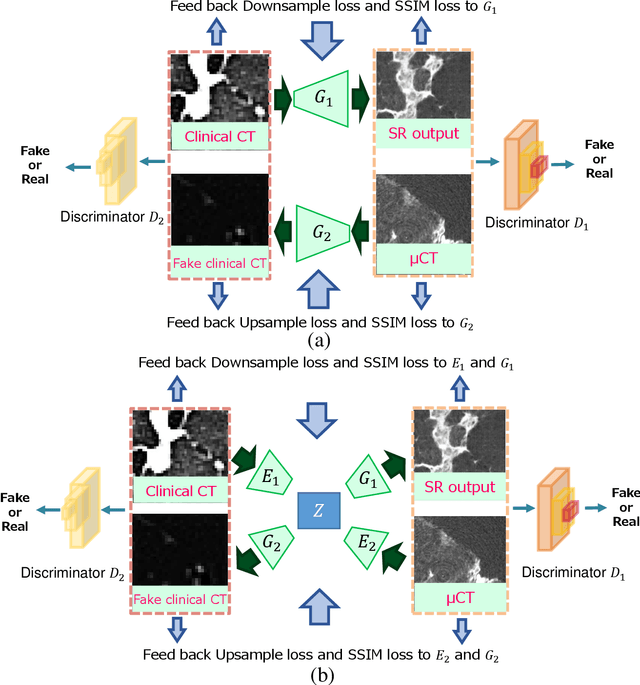
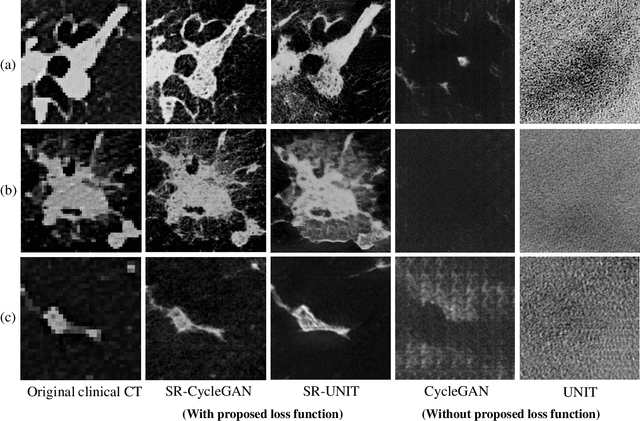
This paper newly introduces multi-modality loss function for GAN-based super-resolution that can maintain image structure and intensity on unpaired training dataset of clinical CT and micro CT volumes. Precise non-invasive diagnosis of lung cancer mainly utilizes 3D multidetector computed-tomography (CT) data. On the other hand, we can take micro CT images of resected lung specimen in 50 micro meter or higher resolution. However, micro CT scanning cannot be applied to living human imaging. For obtaining highly detailed information such as cancer invasion area from pre-operative clinical CT volumes of lung cancer patients, super-resolution (SR) of clinical CT volumes to $\mu$CT level might be one of substitutive solutions. While most SR methods require paired low- and high-resolution images for training, it is infeasible to obtain precisely paired clinical CT and micro CT volumes. We aim to propose unpaired SR approaches for clincial CT using micro CT images based on unpaired image translation methods such as CycleGAN or UNIT. Since clinical CT and micro CT are very different in structure and intensity, direct application of GAN-based unpaired image translation methods in super-resolution tends to generate arbitrary images. Aiming to solve this problem, we propose new loss function called multi-modality loss function to maintain the similarity of input images and corresponding output images in super-resolution task. Experimental results demonstrated that the newly proposed loss function made CycleGAN and UNIT to successfully perform SR of clinical CT images of lung cancer patients into micro CT level resolution, while original CycleGAN and UNIT failed in super-resolution.
Audio Attacks and Defenses against AED Systems -- A Practical Study
Jun 25, 2021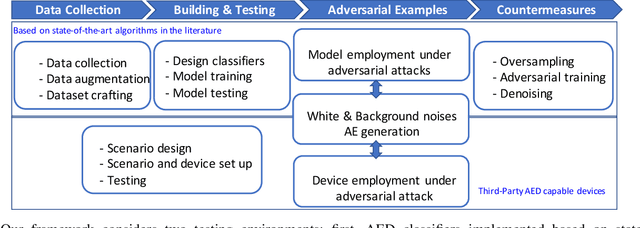
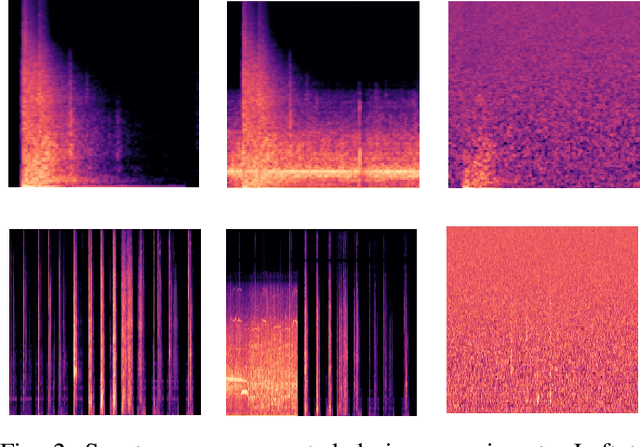
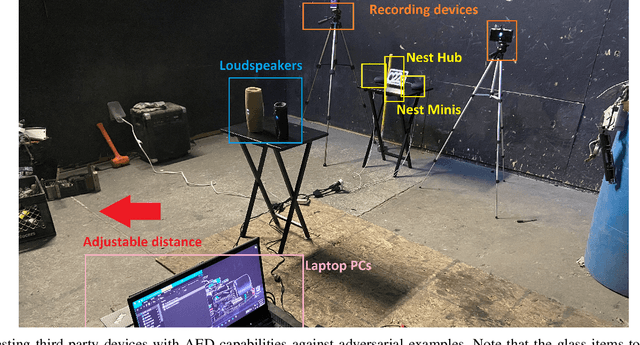
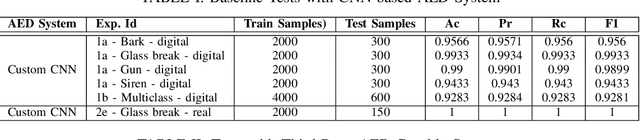
Audio Event Detection (AED) Systems capture audio from the environment and employ some deep learning algorithms for detecting the presence of a specific sound of interest. In this paper, we evaluate deep learning-based AED systems against evasion attacks through adversarial examples. We run multiple security critical AED tasks, implemented as CNNs classifiers, and then generate audio adversarial examples using two different types of noise, namely background and white noise, that can be used by the adversary to evade detection. We also examine the robustness of existing third-party AED capable devices, such as Nest devices manufactured by Google, which run their own black-box deep learning models. We show that an adversary can focus on audio adversarial inputs to cause AED systems to misclassify, similarly to what has been previously done by works focusing on adversarial examples from the image domain. We then, seek to improve classifiers' robustness through countermeasures to the attacks. We employ adversarial training and a custom denoising technique. We show that these countermeasures, when applied to audio input, can be successful, either in isolation or in combination, generating relevant increases of nearly fifty percent in the performance of the classifiers when these are under attack.
The Chan-Vese Model with Elastica and Landmark Constraints for Image Segmentation
May 27, 2019
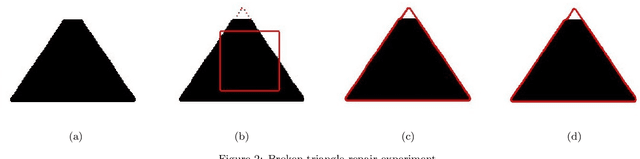
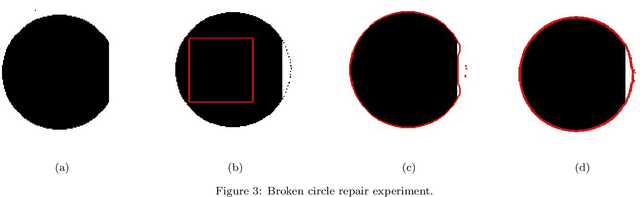
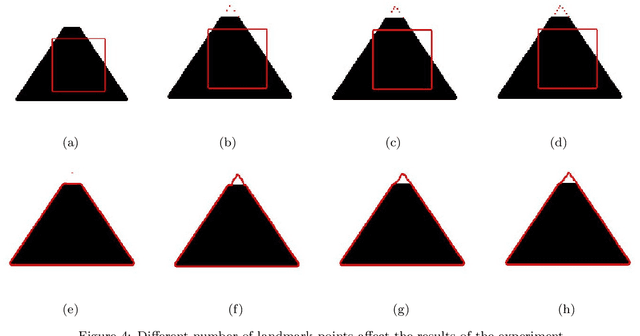
In order to separate completely the objects with larger occluded boundaries in an image, we devise a new variational level set model for image segmentation combing the recently proposed Chan-Vese-Euler model with elastica and landmark constraints. For computational efficiency, we deign its Augmented Lagrangian Method(ALM) or Alternating Direction Method of Multiplier(ADMM) method by introducing some auxiliary variables, Lagrange multipliers and penalty parameters. In each loop of alternating iterative optimization, the sub-problems of minimization can be solved via simple Gauss-Seidel iterative method, or generalized soft thresholding formulas with projection methods respectively. Numerical experiments show that the proposed model not only can recover larger broken boundaries, but also can improve segmentation efficiency, decrease the dependence of segmentation on tuning parameters and initialization.
Multi-Facet Clustering Variational Autoencoders
Jun 09, 2021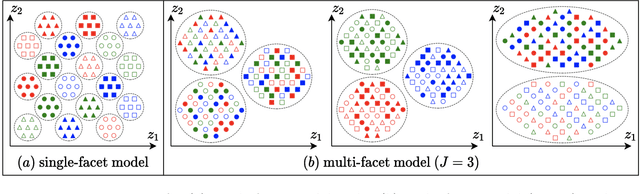
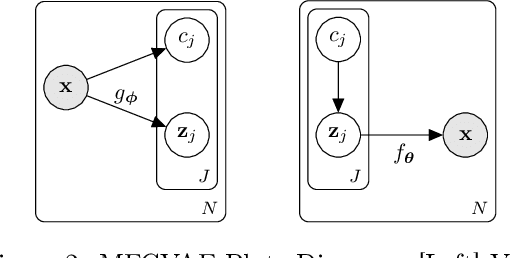

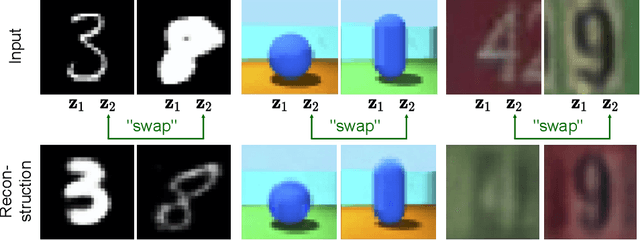
Work in deep clustering focuses on finding a single partition of data. However, high-dimensional data, such as images, typically feature multiple interesting characteristics one could cluster over. For example, images of objects against a background could be clustered over the shape of the object and separately by the colour of the background. In this paper, we introduce Multi-Facet Clustering Variational Autoencoders (MFCVAE), a novel class of variational autoencoders with a hierarchy of latent variables, each with a Mixture-of-Gaussians prior, that learns multiple clusterings simultaneously, and is trained fully unsupervised and end-to-end. MFCVAE uses a progressively-trained ladder architecture which leads to highly stable performance. We provide novel theoretical results for optimising the ELBO analytically with respect to the categorical variational posterior distribution, and corrects earlier influential theoretical work. On image benchmarks, we demonstrate that our approach separates out and clusters over different aspects of the data in a disentangled manner. We also show other advantages of our model: the compositionality of its latent space and that it provides controlled generation of samples.
MorphGAN: One-Shot Face Synthesis GAN for Detecting Recognition Bias
Dec 10, 2020
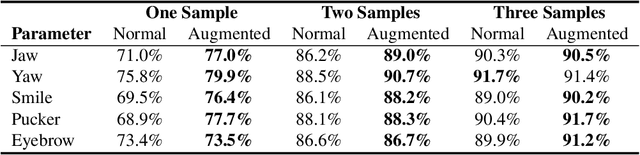
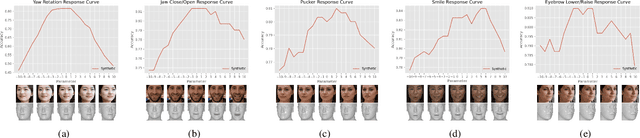

To detect bias in face recognition networks, it can be useful to probe a network under test using samples in which only specific attributes vary in some controlled way. However, capturing a sufficiently large dataset with specific control over the attributes of interest is difficult. In this work, we describe a simulator that applies specific head pose and facial expression adjustments to images of previously unseen people. The simulator first fits a 3D morphable model to a provided image, applies the desired head pose and facial expression controls, then renders the model into an image. Next, a conditional Generative Adversarial Network (GAN) conditioned on the original image and the rendered morphable model is used to produce the image of the original person with the new facial expression and head pose. We call this conditional GAN -- MorphGAN. Images generated using MorphGAN conserve the identity of the person in the original image, and the provided control over head pose and facial expression allows test sets to be created to identify robustness issues of a facial recognition deep network with respect to pose and expression. Images generated by MorphGAN can also serve as data augmentation when training data are scarce. We show that by augmenting small datasets of faces with new poses and expressions improves the recognition performance by up to 9% depending on the augmentation and data scarcity.
SNIPS: Solving Noisy Inverse Problems Stochastically
May 31, 2021


In this work we introduce a novel stochastic algorithm dubbed SNIPS, which draws samples from the posterior distribution of any linear inverse problem, where the observation is assumed to be contaminated by additive white Gaussian noise. Our solution incorporates ideas from Langevin dynamics and Newton's method, and exploits a pre-trained minimum mean squared error (MMSE) Gaussian denoiser. The proposed approach relies on an intricate derivation of the posterior score function that includes a singular value decomposition (SVD) of the degradation operator, in order to obtain a tractable iterative algorithm for the desired sampling. Due to its stochasticity, the algorithm can produce multiple high perceptual quality samples for the same noisy observation. We demonstrate the abilities of the proposed paradigm for image deblurring, super-resolution, and compressive sensing. We show that the samples produced are sharp, detailed and consistent with the given measurements, and their diversity exposes the inherent uncertainty in the inverse problem being solved.