 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Slicer Networks
Jan 18, 2024
In medical imaging, scans often reveal objects with varied contrasts but consistent internal intensities or textures. This characteristic enables the use of low-frequency approximations for tasks such as segmentation and deformation field estimation. Yet, integrating this concept into neural network architectures for medical image analysis remains underexplored. In this paper, we propose the Slicer Network, a novel architecture designed to leverage these traits. Comprising an encoder utilizing models like vision transformers for feature extraction and a slicer employing a learnable bilateral grid, the Slicer Network strategically refines and upsamples feature maps via a splatting-blurring-slicing process. This introduces an edge-preserving low-frequency approximation for the network outcome, effectively enlarging the effective receptive field. The enhancement not only reduces computational complexity but also boosts overall performance. Experiments across different medical imaging applications, including unsupervised and keypoints-based image registration and lesion segmentation, have verified the Slicer Network's improved accuracy and efficiency.
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models
Dec 27, 2023In the rapidly evolving domain of digital content generation, the focus has shifted from text-to-image (T2I) models to more advanced video diffusion models, notably text-to-video (T2V) and image-to-video (I2V). This paper addresses the intricate challenge posed by I2V: converting static images into dynamic, lifelike video sequences while preserving the original image fidelity. Traditional methods typically involve integrating entire images into diffusion processes or using pretrained encoders for cross attention. However, these approaches often necessitate altering the fundamental weights of T2I models, thereby restricting their reusability. We introduce a novel solution, namely I2V-Adapter, designed to overcome such limitations. Our approach preserves the structural integrity of T2I models and their inherent motion modules. The I2V-Adapter operates by processing noised video frames in parallel with the input image, utilizing a lightweight adapter module. This module acts as a bridge, efficiently linking the input to the model's self-attention mechanism, thus maintaining spatial details without requiring structural changes to the T2I model. Moreover, I2V-Adapter requires only a fraction of the parameters of conventional models and ensures compatibility with existing community-driven T2I models and controlling tools. Our experimental results demonstrate I2V-Adapter's capability to produce high-quality video outputs. This performance, coupled with its versatility and reduced need for trainable parameters, represents a substantial advancement in the field of AI-driven video generation, particularly for creative applications.
Jewelry Recognition via Encoder-Decoder Models
Jan 15, 2024Jewelry recognition is a complex task due to the different styles and designs of accessories. Precise descriptions of the various accessories is something that today can only be achieved by experts in the field of jewelry. In this work, we propose an approach for jewelry recognition using computer vision techniques and image captioning, trying to simulate this expert human behavior of analyzing accessories. The proposed methodology consist on using different image captioning models to detect the jewels from an image and generate a natural language description of the accessory. Then, this description is also utilized to classify the accessories at different levels of detail. The generated caption includes details such as the type of jewel, color, material, and design. To demonstrate the effectiveness of the proposed method in accurately recognizing different types of jewels, a dataset consisting of images of accessories belonging to jewelry stores in C\'ordoba (Spain) has been created. After testing the different image captioning architectures designed, the final model achieves a captioning accuracy of 95\%. The proposed methodology has the potential to be used in various applications such as jewelry e-commerce, inventory management or automatic jewels recognition to analyze people's tastes and social status.
* 6 pages, 5 figures, MetroXRAINE 2023 Conference
Frequency Masking for Universal Deepfake Detection
Jan 17, 2024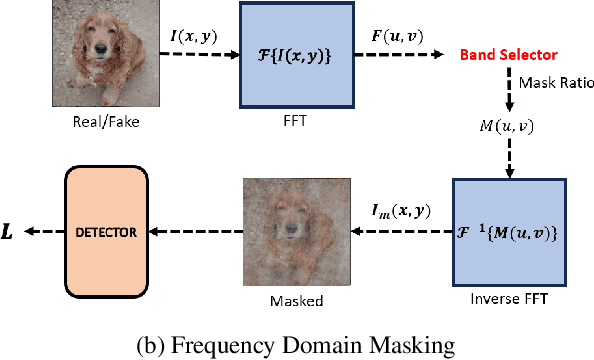
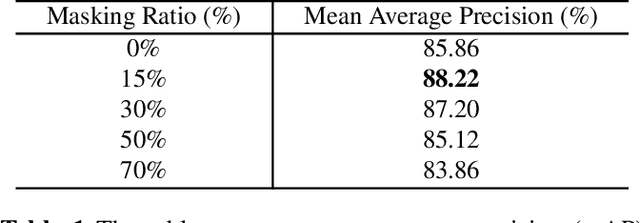
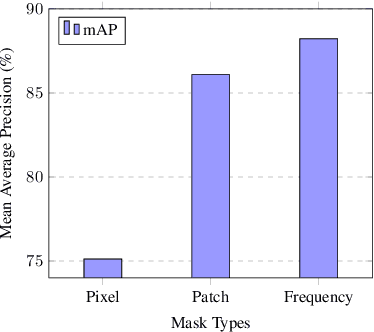
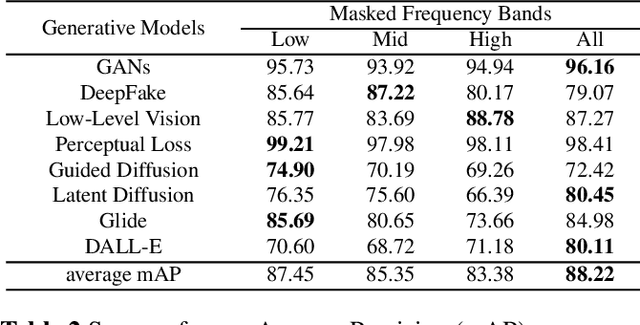
We study universal deepfake detection. Our goal is to detect synthetic images from a range of generative AI approaches, particularly from emerging ones which are unseen during training of the deepfake detector. Universal deepfake detection requires outstanding generalization capability. Motivated by recently proposed masked image modeling which has demonstrated excellent generalization in self-supervised pre-training, we make the first attempt to explore masked image modeling for universal deepfake detection. We study spatial and frequency domain masking in training deepfake detectors. Based on empirical analysis, we propose a novel deepfake detector via frequency masking. Our focus on frequency domain is different from the majority, which primarily target spatial domain detection. Our comparative analyses reveal substantial performance gains over existing methods. Code and models are publicly available.
StyleRetoucher: Generalized Portrait Image Retouching with GAN Priors
Dec 22, 2023Creating fine-retouched portrait images is tedious and time-consuming even for professional artists. There exist automatic retouching methods, but they either suffer from over-smoothing artifacts or lack generalization ability. To address such issues, we present StyleRetoucher, a novel automatic portrait image retouching framework, leveraging StyleGAN's generation and generalization ability to improve an input portrait image's skin condition while preserving its facial details. Harnessing the priors of pretrained StyleGAN, our method shows superior robustness: a). performing stably with fewer training samples and b). generalizing well on the out-domain data. Moreover, by blending the spatial features of the input image and intermediate features of the StyleGAN layers, our method preserves the input characteristics to the largest extent. We further propose a novel blemish-aware feature selection mechanism to effectively identify and remove the skin blemishes, improving the image skin condition. Qualitative and quantitative evaluations validate the great generalization capability of our method. Further experiments show StyleRetoucher's superior performance to the alternative solutions in the image retouching task. We also conduct a user perceptive study to confirm the superior retouching performance of our method over the existing state-of-the-art alternatives.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 16, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.
SemanticSLAM: Learning based Semantic Map Construction and Robust Camera Localization
Jan 23, 2024Current techniques in Visual Simultaneous Localization and Mapping (VSLAM) estimate camera displacement by comparing image features of consecutive scenes. These algorithms depend on scene continuity, hence requires frequent camera inputs. However, processing images frequently can lead to significant memory usage and computation overhead. In this study, we introduce SemanticSLAM, an end-to-end visual-inertial odometry system that utilizes semantic features extracted from an RGB-D sensor. This approach enables the creation of a semantic map of the environment and ensures reliable camera localization. SemanticSLAM is scene-agnostic, which means it doesn't require retraining for different environments. It operates effectively in indoor settings, even with infrequent camera input, without prior knowledge. The strength of SemanticSLAM lies in its ability to gradually refine the semantic map and improve pose estimation. This is achieved by a convolutional long-short-term-memory (ConvLSTM) network, trained to correct errors during map construction. Compared to existing VSLAM algorithms, SemanticSLAM improves pose estimation by 17%. The resulting semantic map provides interpretable information about the environment and can be easily applied to various downstream tasks, such as path planning, obstacle avoidance, and robot navigation. The code will be publicly available at https://github.com/Leomingyangli/SemanticSLAM
* 2023 IEEE Symposium Series on Computational Intelligence (SSCI) 6 pages
DeepCERES: A Deep learning method for cerebellar lobule segmentation using ultra-high resolution multimodal MRI
Jan 23, 2024This paper introduces a novel multimodal and high-resolution human brain cerebellum lobule segmentation method. Unlike current tools that operate at standard resolution ($1 \text{ mm}^{3}$) or using mono-modal data, the proposed method improves cerebellum lobule segmentation through the use of a multimodal and ultra-high resolution ($0.125 \text{ mm}^{3}$) training dataset. To develop the method, first, a database of semi-automatically labelled cerebellum lobules was created to train the proposed method with ultra-high resolution T1 and T2 MR images. Then, an ensemble of deep networks has been designed and developed, allowing the proposed method to excel in the complex cerebellum lobule segmentation task, improving precision while being memory efficient. Notably, our approach deviates from the traditional U-Net model by exploring alternative architectures. We have also integrated deep learning with classical machine learning methods incorporating a priori knowledge from multi-atlas segmentation, which improved precision and robustness. Finally, a new online pipeline, named DeepCERES, has been developed to make available the proposed method to the scientific community requiring as input only a single T1 MR image at standard resolution.
APLe: Token-Wise Adaptive for Multi-Modal Prompt Learning
Jan 23, 2024Pre-trained Vision-Language (V-L) models set the benchmark for generalization to downstream tasks among the noteworthy contenders. Many characteristics of the V-L model have been explored in existing research including the challenge of the sensitivity to text input and the tuning process across multi-modal prompts. With the advanced utilization of the V-L model like CLIP, recent approaches deploy learnable prompts instead of hand-craft prompts to boost the generalization performance and address the aforementioned challenges. Inspired by layer-wise training, which is wildly used in image fusion, we note that using a sequential training process to adapt different modalities branches of CLIP efficiently facilitates the improvement of generalization. In the context of addressing the multi-modal prompting challenge, we propose Token-wise Adaptive for Multi-modal Prompt Learning (APLe) for tuning both modalities prompts, vision and language, as tokens in a sequential manner. APLe addresses the challenges in V-L models to promote prompt learning across both modalities, which indicates a competitive generalization performance in line with the state-of-the-art. Preeminently, APLe shows robustness and favourable performance in prompt-length experiments with an absolute advantage in adopting the V-L models.
Learning from the Best: Active Learning for Wireless Communications
Jan 23, 2024Collecting an over-the-air wireless communications training dataset for deep learning-based communication tasks is relatively simple. However, labeling the dataset requires expert involvement and domain knowledge, may involve private intellectual properties, and is often computationally and financially expensive. Active learning is an emerging area of research in machine learning that aims to reduce the labeling overhead without accuracy degradation. Active learning algorithms identify the most critical and informative samples in an unlabeled dataset and label only those samples, instead of the complete set. In this paper, we introduce active learning for deep learning applications in wireless communications, and present its different categories. We present a case study of deep learning-based mmWave beam selection, where labeling is performed by a compute-intensive algorithm based on exhaustive search. We evaluate the performance of different active learning algorithms on a publicly available multi-modal dataset with different modalities including image and LiDAR. Our results show that using an active learning algorithm for class-imbalanced datasets can reduce labeling overhead by up to 50% for this dataset while maintaining the same accuracy as classical training.